Andrew Cormack (16/4/1963 - 13/4/2023) was the Chief Regulatory Advisor at Jisc. Prior to this he was Head of JANET CERT, and had worked at Cardiff University and NERC. Andrew was recognised as an expert in the legal, security, and policy issues that affected networks and education. He was first receipient of the Vietsch Foundation medal for his contributions towards trust and security within European research and education.
This is a collection of blog posts by Andrew, originally published on a number of UKERNA/Janet, and Jisc platforms.
Originally posted: 4 April 2023 in category
Articles
Looking at discussions of Regulating Artificial Intelligence it struck me that a lot isn’t new, and a lot isn’t specific to AI. Jisc already has a slightly formal
Pathway
document to help you identify issues with activities that might involve AI. But here are some topics that seem to often come up in those discussions. Thinking about these, or even realizing you already have thought about them, might reassure you that just because something has the marketing label “AI”, it might not be either as new or as uncertain, as you thought.
Context
. Rather than the technology, think about the situation and process in which you are proposing to use it. Is it a situation where human empathy is critical, or is it more important that actions and decisions reflect what the data and statistics tell us? Make sure systems and processes bring components together in an appropriate way.
Bias
. If a situation does involve data, do you understand the characteristics of what you have, and the effects of how you might use it? Biased data and processes may be most obvious when they result in discrimination, but data quality and meaning can also be affected by different learning or teaching styles, access to systems or equipment. That may not be a bad thing (focused actions may be what we want), so long as we understand what those effects are and can justify and account for them. But if data or actions exclude certain groups or situations, this should be deliberate, not accidental.
The term “Artificial Intelligence” creates a high risk of different kinds of (self-)
deception
. Just because something can communicate in natural language doesn’t mean it is human, has any other human attributes or understands the sequence of letters it produces; just because something looks like a photograph or video doesn’t mean it actually happened. Think whether the context around your technology is likely to encourage this kind of misunderstanding: most AI Principles require that technology must declare itself, but that doesn’t always seem to be effective.
Finally, an area that
does
need new thinking is where technology
replaces
a human that has a particular legal role, presumptions and responsibilities. Non-human “drivers”, “authors”, “performers”, etc. leave gaps in existing legal frameworks that could produce a nasty surprise. Rather than grand “
AI laws
”, however, these typically need specific solutions, maybe in the form of interpretive guidance (“authors’ legal rights pass to X”) rather than laws. The EU’s proposal on
AI liability
is an interesting approach: essentially suggesting a starting point for discussions of where displaced liabilities might land.
Originally posted: 27 March 2023 in category
Articles
Looking at the contents of the
Government’s new Bill
suggests it may be more about Digital Information than Data Protection:
Personal Data Processing (1-23)
National Security & Intelligence Services (24-6)
Information Commissioner’s Role etc. (27-43)
Miscellaneous (44-5)
Digital Verification Services (46-60)
Customer & Business Data (a general framework for services like Open Banking) (61-77)
Privacy and Electronic Communications (78-86)
Trust services (87-91)
Public service data sharing etc (92-99)
Information Commission Governance (100-106)
Even those first 23 clauses, which are about the day-to-day processing of personal data, are largely clarifications or re-phrasings of existing (UK) GDPR and Data Protection Act provisions, so seem unlikely to result in organisations changing their existing processes.
The Act is presented as a series of amendments to existing laws, which makes it hard to interpret, but things I spotted include:
New (narrower) definition of personal data (c1). The original GDPR definition (Art.4(1)) depends on the phrase “identifiable natural person” but didn’t answer the question “identifiable by whom?”. For a while there were two conflicting German cases, one saying “by the data controller”, the other “by anyone in the world”. The DPDIB goes for the former. As far as I know this was never resolved at EU level: perhaps because, when designing processes, it doesn’t really matter. Any collection of data is likely to include some people who the data controller can identify – customers, staff, those who have self-identified, … – so you have to have a process for people “identifiable by me” anyway. And if you have such a process it seems like a lot of work to develop a parallel process to work out which records are “not identifiable by me” and handle those differently.
Research and Statistical Purposes (c2,3,9&22). These sections largely consist of text copied or redrafted from the GDPR’s many Recitals (notably 156-162) and Articles (principally 89) on “scientific research”. It has been suggested that the new definition in c2 expands such research to cover both commercial and non-commercial activity, but I can’t see anything in the original GDPR (several different language versions) that currently limits those provisions to “non-commercial” activities. Indeed the current ICO guidance says “
It can also include research carried out in commercial settings, and technological development, innovation and demonstration
”.
Recognised legitimate interests (c5 & Annex 1). These seem to be a list of purposes that could have been covered by the existing “public interest” and “legitimate interest” justifications. Worryingly, although the category name still mentions “legitimate interest”, there doesn’t seem to be any requirement to consider the interests or fundamental rights and freedoms of individuals, as under the old Article 6(1)(f) Legitimate Interests. We have found that balancing test really useful to reassure both ourselves and our users that we are applying appropriate safeguards, for example when
processing to ensure system, network and data security
.
Automated decision-making (ADM) (c11). This seems to answer another long-standing (since 1995!) open question: whether a “right not to be subject” to ADM is a preemptive ban on making such decisions, or creates a right of human review of individual decisions. In the UK, under the DPDIB, the answer seems to be a ban on ADM using special-category data (unless “necessary for reasons of substantial public interest”, in Art.9(2)(g)) but a right of review otherwise.
Data Protection Impact Assessments (c17&18). These have been relabelled as Assessments of High Risk Processing, and several sources of guidance have been removed, but the basic idea remains: when planning processing the controller must think about potential risks to individuals’ rights and freedoms and take documented measures to ensure any high risks are mitigated. Jisc has found this a very useful tool in planning our own services and reassuring their users (see for example our published DPIAs on
network security
and
learning analytics
).
Originally posted: 17 March 2023 in category
Articles
In going through the new (2023)
Data Protection and Digital Information (No.2) Bill
I noticed that it does actually make a change to UK law on cookies: according to clause 79(2A), consent will no longer be needed to store or access information in the user’s terminal equipment if this is
done by the person who operates the website, and
the sole purpose is to collect statistical information to improve either the website or the service it offers, and
that information is not shared with any other person for any other purpose.
Otherwise the new clause 79 pretty much reproduces the
existing rules
dating back to 2009. And this new exemption (colloquially known as first-party analytics) was actually
proposed by European regulators
in late 2012. To be fair, European legislators didn’t get around to proposing the change till 2017 and their law
still hasn’t passed
. So although both legislations are still declaring this a solution to “consent fatigue”, it doesn’t seem as if there’s much enthusiasm for it.
I think there might be some broader lessons here for the capabilities and limitations of “regulation”, whether at organisational, national or international scale.
Have we already got a regulation that could cover this harm?
Back in 2009, the concern wasn’t primarily the storage of cookies, but the privacy invasions enabled by tracking individual users. Cookies were the main way that was then done, but many other technologies can be, and are, now used. Cross-site tracking was considered particularly harmful, hence the long-standing distinction between first- and third-party analytics. Privacy harms are, of course, the remit of privacy and data protection laws, and (as I discussed in a
journal paper
) European data protection law already contained a framework that could have been used to develop a limited, and technology-neutral, framework for website improvement (an obvious “legitimate interest”) in ways that safeguarded users’ rights and freedoms. But, instead, a solution was sought in new provisions on storage and access which, by some accounts, were actually intended to deal with spyware. Rather than spending the last decade (and counting) discussing what is and is not acceptable behaviour by websites, we’ve been producing ever less relevant technical distinctions.
Is the harm controlled by someone responsive to our regulation anyway?
That 2009 “spyware” provision had the simple idea that users should be free to accept or refuse the addition of additional software they hadn’t asked for. But, as the market developed, it quickly became apparent that how/whether that choice was offered to users depended on the website, the browser and, particularly, plugins and add-ons to both. It’s still uncommon for consent interfaces to give equal prominence to “accept all cookies” and “reject all cookies”, even though this has been a clear requirement of European law since 2018 (“It shall be as easy to withdraw as to give consent” (GDPR Art 7(3)). It seems the providers of that software are more responsive to other pressures.
Will the reaction to regulation actually deliver what we want?
Where cookie banners have responded to changes in law, this typically involves making them larger, more frequent and more intrusive. The term “consent fatigue” quickly emerged. I can’t believe this was the intention of the regulators, but I think it could have been foreseen. When proposing a change to law or policy or any other kind of “rules”, it’s worth role-playing how people and organisations might respond. If that doesn’t help the original problem, maybe it’s worth considering another – maybe even an existing – approach?
#576 - Transparency: about Choices, not just Algorithms
Originally posted: 24 February 2023 in category
Articles
Whether you refer to your technology as “data-driven”, “machine learning” or “artificial intelligence”, questions about “algorithmic transparency” are likely to come up. The finest example is perhaps the ICO’s heroic
analysis of different statistical techniques
. But it seems to me that there’s a more fruitful aspect of transparency earlier in the adoption process: why was a particular mix of technology, theory and human skill chosen, and what contribution does each of these make to a successful process? Thinking about that might help both deployers of technology, and those it is intended to help, to find better approaches.
Where a process draws insights from existing data there’s also a question about why that particular aspect of the past was considered informative. This doesn’t have to be as fundamental as concerns over ChatGPT’s
selection of source material
, but can be a helpful reminder of likely limits. If a target measure of student engagement was derived from text-based courses, it’s worth checking whether that measure is also appropriate for more practical activities. Does it still reflect the desired balance of participation and autonomous learning? Or, if our aim is to improve a process, does it make sense to still use data from an older, pre-improved, version of that process to inform our activities?
This sort of transparency seems to add value to another popular idea: “
AI registers
”. A public explanation of why an organisation decided to use automation in its delivery of services would help me – even as a lapsed mathematician – much more than a statement that it uses “random forest” algorithms. And I’d hope that writing that explanation would help the organisation build confidence in its choices, too.
Originally posted: 21 February 2023 in category
Presentations
A few weeks ago I presented on “ORCID and GDPR” at a
UK Consortium
event. I hope this was reassuring: I’ve always been very impressed with ORCID’s approach to
Data Protection
(in the European sense of “managed processing”, not the more limited one of “security”), but take it from the
German Consortium’s lawyers
, back in 2018:
The data protection assessment of ORCID has not been able to identify any serious deficiencies. On the contrary, with its privacy functionalities, the system supports users in exercising their right to informational self-determination and at times has a role model in this regard
The one circumstance where “a risk-free forecast cannot be made” – a remarkably high standard – was where individual researchers could not freely consent to processing of their ORCID IDs: for example where this was required by employers or funders.
Here, it’s important to recall that researchers’ personal data is already being processed by institutions, funders, publishers. And usually much more of it than is required for a functional ORCID record. Those data controllers ought to have identified a GDPR lawful basis for that processing, so the simplest approach is to consider the same lawful basis for ORCID IDs. As the Germans noted, Consent is unlikely to be valid, but there are at least three other possibilities:
Necessary for (employment) Contract: in the sense that the substance of the contract can’t be achieved with any less processing;
Necessary for Public Task;
Necessary for organisation’s Legitimate Interest.
Each of those includes requirements to reduce both risk and – because they all include the word “necessary” – processing, and it may well be that an “ORCIDised” (sorry!) version of the process can deliver both of those. To check that, and to reassure individuals and regulators, I’d suggest following and documenting the following steps:
What is the
purpose
of processing?
Is that purpose
legitimate
?
Can the purpose be achieved less
intrusively
(for example, can we let researchers choose whether or not to populate/release some fields in their records, using ORCID’s fine-grained controls?)?
What organisational and technical
safeguards
can we apply?
Does the remaining
risk to the individual
override the benefit of the purpose?
Those familiar with data protection will recognise this as the Article 6(1)(f) Legitimate Interest Assessment (which is effectively a superset of the requirements for the other lawful bases) and indeed an
LIA
or Data Protection Impact Assessment (
DPIA
) might be good ways to document this thinking.
This approach should also highlight opportunities to use ORCID itself as a safeguard: an ORCID ID already has the technical characteristics of a pseudonym (GDPR Art 4(5)). Using ORCID in your systems should also help with organisational safeguards, for example by reducing the need for re-typing, and the risk of confusing different researchers with similar names.
#574 - Goodguys “Possess Illegally Obtained Data” too
Originally posted: 15 February 2023 in category
Articles
The Home Office
consultation on
Computer Misuse Act
(CMA) reform
raises the possibility of a new offence of “possessing or using illegally obtained data”. This is presumably in response to the growing complexity of cyber-crime supply chains. It’s good to see immediate recognition that this will need “appropriate safeguards”. This post looks at why someone in possession of information obtained through crime may not be a criminal and, indeed, may be engaged in activities that society (and victims) should encourage.
Information obtained through cyber-attacks is often left, or made, publicly available. Most simply, the criminal may not wish to send information direct from the victim system to their home base, which could leave a direct trail to their identity. Instead, information is often exfiltrated to third-party storage: either deliberately or accidentally this often has no access restrictions. At a later stage, various ways of converting information into money require the criminal to demonstrate publicly the quality of what they have, either to strengthen a blackmail demand or to demonstrate to potential buyers that they have something of current value.
Incident response teams often seek out these public collections of “illegally obtained data”, to obtain early warning of successful attacks, to directly help victims reduce damage (for example by changing passwords or cancelling credit cards) and because it may help to determine how and when the attack occurred. Obtaining and sharing information “to contain the effects of incidents and recover more efficiently” is recognised by the
NIS2 Directive
(Recitals 119 and following) as something to be encouraged, so clear safeguards are essential to ensure there is no fear that it might be challenged under any new law. Indeed it is not clear that such a law is needed: there are already criminal offences under
s3A of the current CMA
(for “making, supplying or obtaining articles for use in offence”, which was justified at the time as covering lists of passwords and credit card numbers) and
s170 of the Data Protection Act 2018
(for “unlawful obtaining etc. of personal data”, which includes “retaining”), which may well be sufficient to address the harms identified without creating any new perverse incentives. With so few cases under these provisions being reported, it’s hard to know whether what’s needed is more laws or more investigation and enforcement. In the meantime, it’s essential not to discourage the protective mechanisms we do have.
Originally posted: 14 February 2023 in category
Articles
When the Internet first came to legislators’ notice, there was a tendency to propose all-encompassing “laws of internet” for this apparently new domain. A celebrated
paper by Frank Easterbrook
argued that (my summary) there wasn’t a separate body of new harms to address and that existing laws might well prove sufficiently flexible to deal with many of them. The title pointed out that studying (or creating) the “law of the horse” would ignore a lot of the legal and social principles that are already widely established. Looking at proposals for “AI laws”, I wonder whether we might be back in similar territory?
The
proposed EU AI Act
doesn’t seem self-confident. First, it has to define “AI”, then it declares that most of that definition doesn’t need regulating anyway and, for the rest, proposes something that looks a lot like a traditional product safety law. The Act is already being criticized for
an over-simplified view of supply chains
. Perhaps starting with a scope that encompasses everything from speech recognition to probation recommendations was too ambitious? Lack of an AI law doesn’t seem to have hindered courts, which have applied everything from data protection to discrimination laws to reach apparently satisfactory conclusions to harms caused by AI. A very different approach is taken by the
proposed EU AI Liability Directive
: rather than creating new laws this suggests how existing ones might be applied in complex AI supply chains.
So, for both legislators and developers of new technologies, the message seems to be to check how existing laws will apply. If that doesn’t seem right, try to work out an interpretation that fills the gap (or addresses any genuinely new harms) in the spirit and objectives of the existing rules. A
recent review
of “The Law of the Horse” considers this in more detail. For those developing or applying “AI”, make sure you understand how existing laws on personal data, discrimination and safety will apply to your idea. You may well find more guidance there than you expect.
Originally posted: 13 February 2023 in category
Articles
The recent rash of ransomware incidents has been linked to the availability of crypto-currencies – as a way that victims can pay ransoms to anonymous attackers – so Trend Micro reviewed
the economic models for ransomware
and, among many other aspects, whether changes in the crypto-currency world might have knock-on effects. Their conclusions are mixed: successful intrusions can be monetised in other ways, but defences that focus on initial access and lateral movement should help against those too.
Crypto-currencies have been in the news themselves: some collapsing for internal reasons, others being proposed for regulation. Some crypto-currency and ransomware groups have been made subject to sanctions. However Trend see these as long-term developments that may, at most, increase the costs to cyber-criminals who continue to use ransoms to monetise their access to organisations’ systems. In any case, extortion is not the only way that profits can be extracted: fake invoices and bank instructions are much more plausible if sent from the organisation’s own systems, for public companies there are signs of intruders using “inside information” to distort share prices in profitable ways.
The good news for defenders is that these other monetisation techniques still depend on initial access plus lateral movement/privilege escalation to reach sensitive information and systems. So preventing, detecting and eliminating either of these earlier stages should continue to be effective even if the eventual monetisation technique changes.
#571 - Online Safety Bill: effect on small services
Originally posted: 9 January 2023 in category
Articles
Over the past few months there has been a lot of discussion of the impact of the Government’s
Online Safety Bill
on large providers. Ofcom’s July 2022
Implementation Roadmap
(p5) estimates that there are 30-40 of those, to be covered by Categories 1, 2a and 2b. However the roadmap mentions a further 25000 UK services that will be in scope of the Bill: “Broadly speaking, services where users may encounter content (such as messages, images, videos and comments) that has been generated, uploaded or shared by other users will be in scope of the online safety regime” (p11). There are some
exemptions in the Bill
but, for example, none of those seem to apply to the comment feature on this blog. What might the Bill require here?
Although the Bill has been subject to considerable change, two types of content have been a consistent focus: “illegal” and “harmful to children”. In each case it’s envisaged that there will be a list of specific kinds of harm: service operators will need to first assess the risk of each kind of material appearing, then apply appropriate safeguards to that risk. Whether the children list needs to be considered depends on each service’s assessment of “whether children are likely to access their service or part of their service” (p16). The categories considered “harmful to children” will be defined in a future statutory instrument; those considered “illegal” are currently in Schedules 5 (Terrorism), 6 (Child Sexual Exploitation and Abuse) and 7 (Assisting Suicide, Threats to Kill, Public Order Offences, Drugs and Psychoactive Substances, Firearms and Other Weapons, Illegal Immigration, Sexual Exploitation, Sexual Images, Proceeds of Crime, Fraud, Financial Services crimes) though this may change.
All services will need to implement processes to receive reports of content in their relevant categories, to take down (at least) illegal content, and to deal with complaints about these processes (p14). There will also be duties on “review and record keeping” (p13) including – according to
clause 29 of the current Bill
– “every risk assessment”, “any measures taken” and regular compliance reviews.
For small sites, the amount of work will depend heavily on the required risk assessments and safeguards. The Bill seems to require that these are done separately for each kind of harm (current
clause 8(5)(b)(i)
), but details of how to assess and what protection is required are left to Ofcom. For illegal content, their Roadmap suggests:
“This must assess, amongst other things, the risk of individuals encountering illegal content on a service, the risk of harm presented by illegal content and how the operations and functionalities of a service may reduce or increase these risks” (p14)
and
“All services will need to put in place proportionate measures to effectively mitigate and manage the risks of harm from illegal content.” (p14)
There are similar requirements for the “harmful to children” categories.
A lot will depend on those words “proportionate” and “effectively”. Will it be sufficient, for example, to say that all comments to this site are already checked and approved by humans before they are published? I can’t think what we could do that would further reduce any (I hope, low) risk of encountering illegal or harmful content. Ofcom do note that large services have “capabilities and resources that vastly outstrip those of most in-scope services” (p8) and “each service’s chosen approach should reflect its characteristics and the risks it faces” (p5). But the Bill applies the same risk management framework to everyone, so their flexibility may be limited.
The Bill was significantly changed in December 2022, and Ofcom’s Roadmap refers to an earlier version. I have concentrated here on areas which were not affected. However the Bill is yet to go to the House of Lords (expected Jan/Feb 2023) and both government and opposition have declared their intention to make further changes there. Other obligations may appear or disappear. But if it is to become law, the Bill needs to be agreed before the summer. Ofcom’s powers will commence two months after that happens, and the Roadmap envisages a consultation on draft guidance on illegal content shortly thereafter, with a final version a year later (p7). Categories harmful to children need to be defined in further legislation, so that guidance is likely to appear later following a similar process.
#570 - NIS 2 Directive: cybersecurity improvement for all
Originally posted: 5 January 2023 in category
Articles
The final text of the revised
European Network and Information Security Directive (NIS 2 Directive)
has now been published. This doesn’t formally apply in the UK, but does have some helpful comments on using data protection law to support network and information security. I’ve blogged about these previously but, since the final version significantly changes the draft numbering, I thought it was worth posting a revised index to those posts:
CSIRT (international) Information Sharing
: Draft Recital 69, which encouraged incident response and information sharing, is now split across Recitals 120 and 121. The former is now even more explicit that “entities should be encouraged and assisted by Member States to collectively leverage their individual knowledge and practical experience at strategic, tactical and operational levels with a view to enhancing their capabilities to adequately prevent, detect, respond to or recover from incidents or to mitigate their impact”. The societal importance of this is still in Recital 3.
CSIRT Collaboration:
Helpfully, the Directive separates “reporting obligations” (Article 23) of various kinds of regulated entities from more general “exchange on a voluntary basis” (Article 29, formerly 27), which should involve anyone with relevant information and skills to improve the security of networks, systems and data. The latter might include “information relating to cyber threats, near misses, vulnerabilities, techniques and procedures, indicators of compromise, adversarial tactics, threat-actor-specific information, cybersecurity alerts and recommendations regarding configuration of cybersecurity tools to detect cyberattacks”, so long as the aim is “to prevent, detect, respond to or recover from incidents or to mitigate their impact” with the effect of “enhanc[ing] the level of cybersecurity”, again with an extensive range of examples: “raising awareness in relation to cyber threats, limiting or impeding the ability of such threats to spread, supporting a range of defensive capabilities, vulnerability remediation and disclosure, threat detection, containment and prevention techniques, mitigation strategies, or response and recovery stages or promoting collaborative cyber threat research between public and private entities”.
The Commission identified education as a field that might contain high-risk applications. Their proposed scope has typically been summarised as “high-stakes assessment”, though the formal specification (
para 3 of Annex III
) is a bit longer:
Education and vocational training:
(a) AI systems intended to be used for the purpose of determining access or assigning natural persons to educational and vocational training institutions;
(b) AI systems intended to be used for the purpose of assessing students in educational and vocational training institutions and for assessing participants in tests commonly required for admission to educational institutions.
The Council’s text is pretty similar on point (a), but seems to be significantly different in (b):
Education and vocational training:
(a) AI systems intended to be used to determine access, admission or to assign natural persons to educational and vocational training institutions or programmes at all levels;
(b) AI systems intended to be used to evaluate learning outcomes, including when those outcomes are used to steer the learning process of natural persons in educational and vocational training institutions or programmes at all levels.
Here “assessing students” has been replaced by “evaluate learning outcomes”, with an illustrative example of “steer[ing] the learning process of natural persons”. This feels a lot more like something that would take place during a course, not just at the start or end. Many examples of personalised learning seem quite close to this definition, for example consider an online language course that identifies a student as having difficulty with the past tense and “steers” their revision exercises to focus on that.
Under the Council’s proposal, fitting the Annex III definition isn’t the sole determinant of whether an application needs to demonstrate formal compliance: they have added a final per-application test “of the significance of the output of the AI system in respect of the relevant action or a decision to be taken”. My language tutor might be ruled “purely accessory in respect of the relevant action or decision to be taken and is not therefore likely to lead to a significant risk to the health, safety or fundamental rights” (Article 6(3)). But if the Council’s broadening of scope is intended as I’m reading it, it might be interesting to consider which processes and decisions within a course might create such risks.
The European Parliament is expected to produce its version of the text in the first quarter of 2023; the three bodies then agree on a final version, which can take months or years. This won’t apply directly in the UK, but if AI products we use are also designed for the European market, we may see the results of the required design processes and documentation.
Originally posted: 12 December 2022 in category
Articles
One promising application of Machine Learning in education is marking support. Colleagues in Jisc’s
National Centre for AI
have identified several products that implement a similar process, where a program “watches” a human marking assessments, learns in real time, and suggests how the quality and consistency of marking can be maintained or even improved. This seems an attractive human/machine collaboration, with each partner doing what it does best.
The approach actually involves two stages of Machine Learning (ML):
the first is trained by the vendor to extract sufficient information from students’ input to be able to recognise similar sections in different submissions. This may involve domain-specific knowledge, for example to interpret hand-written mathematical or scientific equations, but is likely to be the same for every purchaser of the system;
the second stage of training is performed by a human marker as they work on each assessment: typically by highlighting parts of the submission, marking them as positive (a relevant step in a calculation, for example) or negative, and attaching feedback. The ML can then apply its pre-learned idea of “similarity” to point out when another submission contains a similar point and suggest attaching the same mark and comment. The human can agree or disagree with the suggestion, in either case providing more information for the ML’s learning about that particular assessment.
This combination of human and machine offers advantages for both markers and students. Once the machine is making appropriate suggestions for points that appear in most submissions, the marker can quickly approve those. This lets the human focus on less common insights or misunderstandings, with more time to provide relevant feedback on those. Students should get more consistent marks and better feedback. Furthermore, most systems record the structure of feedback as well the content, so markers can review how often each piece of feedback was referenced and, for example, expand those relating to common misunderstandings. All students benefit from this enhanced feedback, not just those marked after the need for it was noticed.
In terms of AI regulation, this two-stage collaborative process has several attractions. The marker remains very much a human-in-the-loop, with both marks and feedback individually approved. The link between the human’s actions and the machine’s interpretation of them is quick and direct: well suited for what is referred to as “human oversight” and “correction”. Those are provided by humans who are experts in the domain where the AI is operating, not in AI,
which insights from safety-critical systems
suggest is a desirable feature.
The process should also provide clear signals (through rejected suggestions) when either stage of the ML isn’t working: this might indicate either that the marker isn’t highlighting enough of the submission for the ML to be able to recognise common features, or that the ML’s original training isn’t extracting sufficient meaning from the submissions. The
draft EU AI Act
concentrates on information flow from providers of AI systems to their users, but here there seems to be value in the provider inviting reports in the other direction: that “your system isn’t performing well in these circumstances” and either supporting the users with better instructions or improving the performance of the first stage ML.
Originally posted: 30 November 2022 in category
Articles
The recent increased awareness of federated social networks has produced some discussion about their status under new “platform regulation” laws, such as the UK
Online Safety Bill
. Most of this has focussed on whether federated instances might be covered by legislation and, if so, what their operators’ responsibilities are.
But this post uses them as a way to look at content regulation in general. In particular, are these laws about controlling what we post, or what we read? On a centralised platform such as Facebook or Twitter, there’s no difference: the platform operator controls both what its users post and what they can see. But in a federated system, each instance has its own community of people who can both post and read, but members of that community can also choose to read content posted on other instances by people who have no relationship with the local instance or its policies. What light does that difference shed on how we think about regulation?
Posting is fundamental to the definitions in the Online Safety Bill: a service that doesn’t allow posting (clause 2 says “generated”, “uploaded”, “shared”) isn’t a user-to-user service, so immediately falls out of scope. Services that allow interaction, but limit this posting to “expressing a view” (via likes, votes, etc.) on provider content are also exempt (see Schedule 1 clause 4). Posting is also at the heart of the model of
different federated instances having different policies
: these may be pre-defined by an instance operator and those who find them welcoming can join, or an existing community may decide on its preferred rules and create an instance to implement them. Perhaps the strongest community link is an
instance for employees
, where contracts may already contain a policy on acceptable posting. This is very different to a centralised social network where a single policy covers all posters and readers, no matter how (un)comfortable they may be with it.
Reading isn’t as deeply embedded in the Bill, though groups of readers are likely to be a consideration in the required risk assessments. Two features of current federated systems support group-appropriate reading. As above, federated instances are expected to set up and enforce different rules for what is posted locally, and members of an instance can choose what (if any) content they see from outside that instance. Such choices are more effective in the currently normal situation where federated instances don’t use algorithms to select or promote extra content to individual users. An individual reader can start from their local timeline (which should follow the instance’s policies) and use controls to narrow or widen their personal policies by blocking, following, searching or accessing a broader timeline. Instance operators can block whole external instances, typically because of incompatible policy or practice, but readers who want to read content from a blocked instance can still do so, either by joining it, or by reading its public feed. Both of these are outside the control or even visibility of the blocking instance operator.
Federated social networks offer an alternative way to think about platform regulation. It will be interesting to see whether Parliament or OFCOM incorporate this additional perspective as they develop and implement the UK legislation.
#566 - ECJ: Legitimate Interest in accessing registries
Originally posted: 22 November 2022 in category
Articles
European Data Protection Regulators have been expressing their concerns for nearly twenty years about
public records of domain name ownership
(commonly referred to as
WHOIS data
). A
recent case (C37-20) on public records of company ownership
(required under money-laundering legislation) suggests that the European Court of Justice would have similar doubts. But its comments on how access to such records might be made lawful could provide a useful framework for Incident Response Teams or registries wishing to obtain or provide access to WHOIS data as well.
Interestingly the Court contrasts a situation where records of ownership are public with an earlier one where such records were available to “any person or organization capable of demonstrating a legitimate interest”. The latter is the
rule currently applied
by many Domain Name Registries. So how might such a legitimate interest be established? First, the Court dismisses (72) the claim that the difficulty of providing a detailed definition is a justification for dropping the requirement. Instead, those wishing access need to demonstrate:
That their need for access relates to an “objective of general interest” (46);
That the interference with individuals’ privacy and other rights is necessary for that objective (in the usual EU sense of “could not be achieved by other means less prejudicial”) (66);
That that interference is proportionate, in particular “capable of being offset by any benefits which might result” (85);
And that there are “sufficient safeguards enabling data subjects to protect their personal data effectively against risks of abuse” (86). For example company ownership data “enables a potentially unlimited number of persons to find out about the material and financial situation of a beneficial owner” (42) and “the potential consequences for the data subjects resulting from possible abuse of their personal data are exacerbated by the fact that, once those data have been made available to the general public, they can not only be freely consulted, but also retained and disseminated” (43).
Incident response teams
that analyse WHOIS data to detect and even prevent security incidents shouldn’t find it too hard to meet these requirements. Doing so, using the structure from the case, should reassure regulators and registries, as well as system and network users. Reducing incidents and their impact is identified as a general interest in both
data protection
and
network security
laws. CSIRTs have been applying “
necessary and proportionate
” tests to their activities for many years: the benefit to individuals of their data, systems and networks being secure helps to support this case. The purpose of incident response itself requires strong safeguards against information being misused or inappropriately disseminated (it would help attackers greatly if they could find out how much of their activities had been detected); though the case also highlights the need for safeguards on registers to ensure that only authorised individuals can access data.
Originally posted: 1 November 2022 in category
Articles
Discussions of student wellbeing tend to focus on providing individual support for those who are struggling to cope. That’s great, but likely to demand a lot of skilled staff time. A few years ago Bangor University investigated whether the university might be contributing to stress through excessive or spiky workloads. Addressing causes of stress would, of course, benefit many students at once. And quite possibly staff, too…
The Bangor researchers considered a department that had a single catalogue of modules and assignments. From that,
timelines of student workload
could be extracted in a consistent fashion. When I heard the work presented, they were planning to model how different student behaviours would affect the timing and intensity of workloads: the student who works steadily as soon as an assignment is set may have a different experience to the one who leaves everything to the last minute. Tutors could then be helped to adjust their assignments or schedules to avoid creating excessive peaks across the cohort.
Expanding and reproducing that idea at institution scale would require a central source of information about modules and assignments. Depending on institutional practice and technology, that might be available from a VLE or the Jisc Learning Analytics Service. Refinements could include distinguishing formative and summative assignments and types, and adding exams, but even partial data can generate ‘heat maps’ of assessments and dates across courses or faculties that suggest where pinch points may exist.
If that “demand-side” information isn’t available, then perhaps there are “supply-side” proxies that could be used instead? A colleague pointed out that the act of submitting assignments also produces records, and that that might be a more consistent source of cross-institution data. Logs from submission or checking systems should at least show how many assessments were completed each week, revealing peaks and troughs. Additional details such as number of submission attempts and proximity to submission date might reveal common strategies that may need support.
Doing this at assessment, module or programme level shouldn’t require any personal data: just counts. Determining whether particular combinations result in high workloads probably does require linking submissions by the same individual (“students doing Intellectual Property and Data Protection made three submissions that week”), but should be possible using strong pseudonyms that don’t identify who the students are. The same is, I think, true of the approach using “demand-side” data: either can be done in a privacy-protecting way. The aim here isn’t to identify “steady workers” and “last minutes”, but to adjust our demands so as to make life tolerable for both.
Originally posted: 25 October 2022 in category
Articles
I’ve read two documents this week – one
academic paper
and one
guide from the Information Commissioner
– pointing out that just because someone chooses to participate in an activity doesn’t mean that Consent is the appropriate legal basis for processing their personal data. There might be several reasons for that…
First, if the nature of the activity for which the individual volunteers requires a longer-term commitment then frequent flips in and out – which must be provided if consent is used – may well make their participation a waste of everyone’s time. For example a research study is likely to benefit from a continuous sequence of information, not one with arbitrary gaps. Participants in a Covid-tracking programme who absorb resources by joining but then withdraw their consent to processing rather than report a positive test are likely to degrade the quality of everyone else’s statistics. Joining an activity of this kind may be a free choice but that choice ought to involve more consideration and commitment than the Consent framework, with its stress on ease of changing your mind, can really support.
Second, Consent relies on individuals making good choices. If they don’t do so, either because they have insufficient information, or because the consequences of the processing are too hard to predict, then confidence in the whole system may be put at risk. It’s often better for the data controller to take responsibility and ensure that the processing is, and continues to be, safe, at least for participants within a clearly defined range of characteristics. “Necessary” legal bases, such as public task and (particularly) legitimate interests, provide more support and guidance, and
may be more appropriate for this
. Both still allow a volunteer participant to change their minds if unforeseen risks emerge: formally the data controller can refuse a “
right to object
” if the individual’s risks are not significantly different to what was anticipated, but the law also allows them to be generous in granting opt-outs where that is appropriate.
It seems to me there might even be an argument that volunteers are psychologically more at risk of making inappropriate consent choices. If an activity is something I am passionate about, then it might be particularly important that someone else continues to keep an eye on my safety while I am doing it. In GDPR terms, the freedom whether to participate then becomes an additional safeguard for processing that already has a sound legal basis.
When GDPR was first proposed, one of the stated aims was to address “the overuse of consent”. That hasn’t always worked out, but it’s good to have situations highlighted where an alternative does indeed provide a better approach. For both data subjects and data controllers.
Originally posted: 24 October 2022 in category
Articles
One of the major causes of disruption on the Internet is Distributed Denial of Service (DDoS) attacks. Unlike “hacking”, these don’t require there to be any security weakness in the target system: they simply aim to overload it with more traffic than it (or its network connection) can handle. Often such attacks are launched from multiple sources at once (hence “distributed”), with many or all of the sources being innocent machines that are being controlled, but not owned, by the attacker.
From the defender’s point of view that creates a new challenge as, in principle at least, the attack packets can be identical to legitimate ones. We could simply block all packets in an over-large flow, but that does the attacker’s work for them. Fortunately there are often patterns that can be used to (mostly) distinguish the malicious packets from the genuine ones. These are commonly identified, and sometimes implemented, using automated systems.
Levers
: DDoS protection systems typically consist of two layers. The first selects a portion of the packets on the network, based on header characteristics (source address, port/service, etc.) and re-routes these to an inspection system. Here the re-routed packets are examined more closely: those that appear harmless are routed on to their original destination, the rest are judged to be part of the attack and typically dropped. Thus the outcomes may be:
Packet follows normal route to destination
Packet is (slightly) delayed through re-routing, but identified as harmless and passed to destination following inspection
Packet is dropped after failing both stages of check.
It is worth noting that without DDoS protection an attack would likely cause significant packet loss for the target site, and possibly the network, in any case. So a DDoS protection system doesn’t have to perfectly classify every packet: a sizeable reduction in bad traffic is what we are looking for. If a few good packets get blocked, they may well be re-transmitted by their (legitimate) origins anyway: if a few bad ones get through, the target system should be able to deal with those without overload.
Data
: The first stage check is likely to use only packet header data; its re-routing algorithm may also take account of current context, e.g. any recent unusual flows to/from the same destination. Second stage check may inspect any accessible portion of the packet, including unencrypted content. It seems unlikely that either decryption or flow re-assembly will be worth the required processing cycles in a situation where the aim is to “make things less bad”, rather than “achieve perfection”.
Malice
: A malicious actor may try to persuade the automat that a DDoS attack is in progress, to cause it to block either a particular source or destination, or a particular application. These outcomes could, of course, be generated by actually creating a DDoS attack, but deceiving the automat into mis-applying its levers is likely to be cheaper than renting a “stresser” service, and may be harder to trace to its origin.
Controls
: The human operator of the DDoS service may wish to intervene at two different levels:
Correct the automat’s mis-identification of a flow as being (part of) a DDoS attack. Particularly on research networks, large unexpected flows may be the successful outcome of new systems or experiments (for example novel file-synchronisation protocols have triggered many alarms in the past). In this case the operator is likely to want to withdraw the automat’s proposed intervention entirely. Or
Refine the automat’s classification of a DDoS flow, either by amending the rules for identifying packets for re-routing or the rules for analysing and disposing of them.
Depending on context, each of these options may be required both before a new rule is introduced (human approval of proposed blocking) and/or afterwards (human review). Some operators may also wish to pro-actively list some flows as exempt (typically identified by source/destination/port) from redirection or blocking if their nature (e.g. DNS responses) means that any interruption by the “protection” system would effectively deny service to the receiving site anyway.
Signals
: The operator is likely to want to know when a new rule(set) is proposed or introduced, either to approve it before implementation, or to review it afterwards. Statistical information may also be required about the current status and activity of the protection system (e.g. how many/which destinations are under attack, what proportion of traffic is being forwarded after cleaning, etc.). Since attacks and campaigns are typically short-lived, the operator may want to know which rules are no longer matching traffic, so they can be disabled to save space, network and processing capacity.
Historic information might also be useful to assess effectiveness: how much has the addition of the rule changed the traffic being delivered compared to what it looked like before the attack? Perfection would be “no change at all”, if there is a significant difference this might be an indication that the rules need reviewing, or that the attack is having an impact on systems or networks elsewhere.
Originally posted: 30 September 2022 in category
Articles
The
Proposal for a Regulation on Cybersecurity Requirements,
recently published by the European Commission, significantly raises the profile of software vulnerabilities and processes for dealing with them after a product is delivered. The
Regulation on Digital Resilience in the Financial Sector (DORA)
, proposed in 2020 and likely to become law shortly, does require organisations to “have appropriate and comprehensive policies for patches and updates” (Art.8(4)(f)). But that’s limited to the financial sector.
The new proposal covers all manufacturers/vendors of software that is capable of being “connected” to anything else “via hardware interfaces … network sockets, pipes, files, application programming interfaces or any other types of software interface” (Recital 7), with only a very limited exemption if software is not “supplied in the course of a commercial activity” (Recital 23). Criticality of software or application doesn’t change the requirements (it does make a difference to how compliance needs to be demonstrated – see Annex III), because “even hardware and software considered as less critical can facilitate the initial compromise of a device or network, enabling malicious actors to gain privileged access to a system or move laterally across systems” (Recital 7).
The requirement that all such products be “designed, developed and produced in such a way that they ensure an appropriate level of cybersecurity” (Annex I 1(1)) is an obvious read-across from existing laws on physical product quality and safety. Annex I 1(3) provides an extensive list of cybersecurity issues that should be considered in design: secure by default, access controls, data confidentiality/integrity, logs, etc. And “Products with digital elements shall be delivered without any known exploitable vulnerabilities” (Annex I 1(2)).
What’s new is the recognition that a digital product – and its manufacturer’s responsibility – isn’t finished when it is delivered to the customer. The last bullet of Annex I 1 introduces an obligation to: “ensure that vulnerabilities can be addressed through security updates, including, where applicable, through automatic updates and the notification of available updates to users”. And there follows a
lot
more detail in Annex I 2 (my summaries):
Dissemination “free and without charge” of patches and information about mitigation
That’s a pretty state-of-the-art vulnerability handling process! And, according to Article 10(6), it must be maintained for at least five years or, if shorter, the expected product lifetime. Some software producers may already meet the requirements, but many will need to improve.
Once the law is passed – which could take a while – manufacturers will have two years to comply, so there won’t a sudden improvement in the availability of patches. But it’s a striking statement of what European legislators feel is needed to secure the digital society.
Originally posted: 26 September 2022 in category
Presentations
A few weeks ago I was invited to contribute to Team Cymru’s
Future of Cyber Risk podcast
. As I hope is apparent from the resulting recording, it was a fun conversation about working with regulators and how apparently different risks often turn out to be the same after all.
Originally posted: 16 September 2022 in category
Articles
The latest draft part of the ICOs guidance on data protection technologies covers
Privacy Enhancing Technologies (PETs)
. This is a useful return to a topic covered in a very early factsheet, informed both by technical developments and a better understanding of how technologies can (and cannot) contribute to data protection.
Perhaps the most important message is in the very first section. All the technologies can help to reduce risk – both to data subjects and data controllers – but very few will change personal data into anonymous data. Data Protection law still applies, both to the application of PETs and to their results. Thoughtfully used, PETs can contribute, in particular, to data minimisation, security and risk reduction, making existing processing safer and, sometimes, permitting processing that would otherwise involve too high a risk.
Conversely, PETs can increase risk if used inappropriately. In particular, most privacy-enhancing technologies rely on the privacy-enhancing organisational measures and processes that surround them. Weaknesses (or misplaced trust) in these organisational measures can undermine the protection provided by the technology, or even increase the privacy risk if they increase the scope or duration of access to personal data. This makes PETs hard to add retrospectively – they are best incorporated at the design stage, where tools such as
Data Protection by Design
and
Data Protection Impact Assessments
can provide the breadth of analysis required.
Unlike the earlier guidance, the discussion of specific PETs assumes that basic security and minimisation measures have already been applied. There is no discussion of encrypted storage and transmission or pseudonymisation for example: these should now be routine considerations for all data controllers. The division of PETs into three classes provides a useful framework:
Deriving or generating data which reduces or removes identifiability (the latter the only group whose product might fall outside the definition of personal data);
Hiding or shielding data;
Splitting or controlling access to certain parts of data.
Familiar technologies (e.g. statistics, encryption and key-coding, respectively) can contribute to all of these, and should be used where possible.
The remainder of the guidance considers individual technologies in each of these categories. Most are still active topics of computer science research, so likely to be suitable only for exploration by technologically advanced data controllers. Oddly the sequence in which they are presented – Homomorphic Encryption, Secure Multi-Party Computation, Private Set Intersection, Federated Learning, Trusted Execution Environments, Zero-Knowledge Proofs, Differential Privacy and Synthetic Data – doesn’t seem to match either the document’s own categories or my impression of how close to production use they are. Synthetic data and differential privacy are the ones I’d expect to be considering first.
Originally posted: 16 September 2022 in category
Articles
Display Names are often how we are represented online. Michael might choose to appear as “MusicFan”, “Mikey”, “Florence” or “Andrew”. Does that establish a good tone for discussion? Or does it risk misleading readers, perhaps making them act on the basis of a mistaken identity? Platforms that use display names can and, I think, should consider what intuitions their users may have, and choose policies and practices that help to establish a shared understanding.
If the nature of a platform is such that mistaken identity is a serious risk, then maybe the platform shouldn’t allow display names at all? Or only display them to people (such as platform operators) who ought to remember their (lack of) significance? There are many complaints, however, that the random user identities everyone else sees are unfriendly, hard to recognise and use.
Or a platform might decide only to accept users whose display names can be vouched for by a trusted third party. This will exclude all those who can’t provide a verified name and may discourage those who could. Depending on the purpose of the platform and its intended community, exclusion may be more or less of a problem: for some platforms, it could entirely defeat their purpose. Note, incidentally, that even “official names” aren’t unique guarantees of identity: there are several “Andrew Cormack” in the blogosphere.
Or a platform might try to guide users to an appropriate balance of those risks. The platform can control how display names are presented: I’ve put mine in quotes above, for example, an even less subtle approach would be to append “(not verified)”; suggested pseudonyms might encourage informality, readers might be less sure of “Andrew Cormack (Jisc)” when surrounded by the likes of “Prickly Hedgehog”; user interface experts will have many and much better suggestions.
The key point, I think, is that the appropriate answer will differ between platforms, so is something that each platform should consider. As a platform operator, what expectations do you need your users to have about display names, and what can you do to encourage that to happen?
By the way, I can be found on Twitter as …
Andrew Cormack (five vax, mask, one infection, one OK) @Janet_LegReg
… or so I self-assert. What do you believe? And does it matter?
#558 - Thinking about automation: Malware Detection
Originally posted: 15 September 2022 in category
Articles
Sophos have recently released a tool that uses Machine Learning to propose simple rules that can be used to identify malware. The output from
YaraML
has many potential uses, but here I’m considering it as an example of how automation might help end devices identify hostile files in storage (
a use-case described by Sophos
) and also in emails. As usual, I’m structuring my thoughts using my
generic model of a security automat
(Levers, Data, Malice, Controls, Signals), and hoping the results are applicable to a general class of automation applications, not just the one that happened to catch my eye…
Levers
. In Sophos’ system, the Machine Learning component doesn’t have any levers: it just creates a list of rules. The levers belong to whatever software that ruleset is fed into. If that’s a scanner that examines files in storage then presumably it will move any file that matches into a quarantine directory: fine if the match is correct, but potentially damaging or making the device unusable if there’s a false match when examining, for example, a critical operating system or software component. Typical actions when scanning emails – such as marking or filing a message – are easier to remedy when they are mistakenly applied to legitimate content. The most extreme response might be to block a particular organisation, website or IP address that is the source of content considered malicious. A false positive here will be inconvenient, though usually remediable, though I have come across examples of automats blocking critical services such as DNS resolvers…
Data
. The machine learning component of the system takes as input two directories: one containing files considered malicious and one containing a similar number considered good. Based on these, Machine Learning identifies text fragments (“substring features” according to the documentation) that seem to be more common in good or bad files; YaraML’s output is a list of these fragments with weights indicating how strong an indication of good/badness they represent. Even a low-power end device should be able to search a new file for these fragments, calculate the weighted sum, and check whether it exceeds threshold. The quality of the rules clearly depends heavily on the quality of the input datasets; finding the necessary quantity of correctly classified samples might be a challenge, as the article suggests that 10,000 of each would be ideal. Statistical models can always misclassify: smaller training data sets might increase this probability, making Signals and Controls particularly important to detect and remedy when that happens.
Malice
. The obvious way for a malicious person to affect the process is by way of the training data sets. If I can insert enough examples of my malware into the “good” collection (or even swap a significant number from your “bad” to “good”) then the resulting rules might provide false reassurance to the end devices. This stresses the need for secure and reliable sourcing of training datasets, and for security during the training and deployment processes. An interesting aspect of making the software available as open source is that different organisations might use different training sets to generate rules for the same malware. At least this limits the scope of any interference: subsequent (careful, to avoid cross-pollution!) comparison of rulesets might also help to detect this kind of interference.
Controls
. Thinking about how an organisation might respond if it discovered it had deployed a rogue ruleset – either through malice or accident – the obvious control is to be able to un-deploy it from all end devices. This depends on the facilities provided by the application: anti-virus software is typically designed to add new rulesets quickly in response to new threats, but I’d want to check it could also remove those that turned out to be significantly harmful, or at least change the levers available. Thinking specifically about the risk of quarantining an operating system component, it occurred to me that it would be good to have a list of files that should be treated with extra care. It turns out that someone involved in Yara development had an even better idea: “
YARA-CI
helps you to detect poorly designed rules by scanning a corpus of more than 1 million files extracted from the
National Reference Software Library
, a collection of well-known, traceable files maintained by the U.S. Department of Homeland Security”. So destructive false positives against those files should be detected even before the rules are deployed. Nice!
Signals
. An obvious desirable signal once a ruleset has been deployed is how many times it has been triggered. That’s relevant for both true positives (“how much badness do we have?”) and false positives (“how accurate is my rule?”). That needs some sort of feedback mechanism from the end devices to the deployers; for applications like email scanning it would also be useful to learn how often users disagree with the rule’s classification, for example by moving a quarantined message back out of the spam/malware folder. For file quarantining, an equivalent signal might come from helpdesk reports of “my machine stopped working”. But the Yara-CI idea suggests that it’s not just raw numbers that matter. A positive match in a folder belonging to the operating system is more significant than one in a user folder, whether it’s true or false. If true, then malicious code has managed to install itself into a particularly dangerous location: if false then there’s an increased risk that the mistaken quarantining action might have harmful consequences.
#557 - Thinking about automation: network debugging
Originally posted: 31 August 2022 in category
Articles
I’m hoping my
generic model of a security automat
(Levers, Data, Malice, Controls, Signals) will help me think about how tools can contribute to network security and operations. It produces the ideas I’d expect when applied to areas that I already know about, but the acid test is what happens when I use it to think about new applications. So here are some thoughts prompted by an automat that helps identify and debug wifi (and other) network problems: Juniper’s
Mist AI
. This was chosen purely because a colleague mentioned their Networkshop presentation: I wasn’t there, so the following is based on the published documentation.
Levers
. Mist AI seems to produce two distinct kinds of output (noticing that got me thinking about
different modes of automation
). In a few cases – upgrading firmware the main one highlighted in the product videos – it offers to actually perform the task for the human operator. But more often it suggests to the human what the root cause of a problem might be – “this DHCP server seems to be linked to a lot of other failures” – and relies on human expertise to diagnose and fix the problem. So humans make, or at least approve, all changes. There are interesting comments in one of the videos that more automation would be possible: “it’s not a technical issue, more one of building trust” and “we want no false positives”. The latter seems a very high bar, since most automats will be based on statistics and correlations, but the trust point is really important. There’s a challenging balance in any new source of “authority” (see the introduction of printing!) to make humans trust it enough that it does save time/improve quality, but not so much that they follow it blindly even when its recommendations – for example in a situation it wasn’t designed for – don’t make sense.
Data
. Mist AI takes data from a huge range of sources: pretty much any compatible network equipment. The one obvious gap is the computer/laptop/phone/printer/thing that is trying to connect to and use the network. Given the challenges of installing agents on such devices, that’s probably sensible. But it probably is something that needs to be flagged to the system’s operators: when it says “most likely cause is a misconfigured device, but I don’t know”, that’s a design choice, not a system failure. Otherwise that huge range of input data enables another mode of human/machine partnership: helping humans visualise and navigate. The interface provides timelines and other visual representations to help humans spot patterns, as well as the ability to “pivot” through different sources – “show me what else is going on at that time/that device/etc.” – that has been used in many of the most impressive examples of security diagnosis I’ve seen.
Malice
. The few fully-automated actions envisaged for Mist AI seem to give an attacker little opportunity, though anything with administrator access needs to be designed carefully. There’s a steady trickle of attacks that use auto-update functions to either downgrade security or install entirely new software. Perhaps more interesting is whether an automat could detect malicious activity at the network level: sending requests with odd parameters to get more than your fair share of bandwidth, or to disconnect others; or perhaps trying to confuse or overload network devices to redirect traffic or hide malicious activity in a storm of noise. This probably isn’t something you’d want to respond automatically to (that could easily provide a disruptive attacker with a useful tool) but an automat that alerts when things simply don’t make sense could be a useful function.
Controls
. The executive powers of the current Mist AI system are very limited, and human operators have to approve individual actions (e.g. a firmware upgrade). One reason that works is that the system is addressing the kind of problems that users often assume will “go away”: network slow, took longer than usual to connect to wifi, etc. Indeed one stated aim of Mist is to help operators fix problems (or contact the user) before they are reported. On that time-scale, human-in-the-loop is fine, and worth it for the confidence it adds. Given the aim to fix problems before they are noticed, I wondered whether the system could check that the fix did actually reduce the problem: if not, the operator might want to automatically revert an approved change, or go back to a “last known good” state. Perhaps undoing a change is more readily automatable than doing it? And, since there is “machine learning” going on, maybe invoking those controls could be input to the next learning cycle (“OK, that didn’t work out”)?
Signals
. One of the interesting displays I spotted on the video was strength-of-correlation: “100% of DHCP failures involve this server” suggests we have found the root cause, 30% and I might do a bit more digging. Confidence is a useful signal in pretty much any recommendation system, not least to highlight occasions when the machine, programmed to find
something
it can recommend, has searched ever more widely and ended up with a suggestion that’s little better than a random guess. Any fully-automated system should probably have a lower confidence threshold beyond which it will still seek human confirmation. And, as in Controls above, the timeline displays in Mist AI got me thinking whether we could use automated before/after comparisons to evaluate the effectiveness of changes: did the original problem reduce? Did anything else start happening? And I like the option to “list clients experiencing problems”: sometimes talking to a person will be the quickest way to work out what is going on; and to show we aren’t completely mechanical, too!
Originally posted: 23 August 2022 in category
Articles
A couple of recent discussions have mentioned “trade-offs” between risks. But I wonder whether that might sometimes be a misleading phrase: concealing dangers and perhaps even hiding opportunities? “Trade-off” makes me think of a see-saw – one end down, other up – which has a couple of implications. First, the two ends are in opposition; and second, we can always change our minds, change the weights, and things will go back to where they were.
But think about a real-world example from 2014:
care.data
. Here a risk was identified: that medical research would be limited by shortage of data from real patients. I’ve no idea if the proposed solution was thought of as a “trade-off”. But making patient data from their family doctors available to a central research service was seen by many people as increasing the risk to their personal privacy. Individuals could ask their doctors not to transfer their data. But doctors identified another risk: that patients would say less about their symptoms if they thought they might go beyond the consulting room, so treatment would be less well informed. To mitigate that risk, some doctors stated publicly that they would not be participating in the scheme. Confidence fell resulting, according to 2022’s
Goldacre Review
, in “very large numbers of patients opting out of their records ever being shared outside of their GP practice (approximately three million by the end of 2021) with opt-outs now at a scale that will compromise the usefulness of the data” (p88). To put it another way, because of linked risks, the attempt to reduce the risk of insufficient research data actually made the research data risk worse. So the see-saw image was wrong on two counts: the risks to research and patient privacy weren’t actually opposed, but linked in a way that created feedback; and that feedback actually changed the environment so the seesaw couldn’t (easily) be returned to its original position.
Thinking instead of a spiral (OK, technically a
helix
) explains better what happened: the linked risks took the system around a loop (data => individual => doctor => data) but when, some months later, it returned to the original position things had deteriorated and the original situation could not be recovered.
But spirals can go both ways… Can we use linked risks to make a situation better? Regulators suggest a couple. According to the
Information Commissioner
(specifically referring to consent, but the point is general):
“Getting this right should be seen as essential to good customer service: it will put people at the centre of the relationship, and can help build confidence and trust. This can enhance your reputation, improve levels of engagement and encourage use of new services and products.”
But:
“Handling personal data badly … can erode trust in your organisation and damage your reputation. Individuals won’t want to engage with you if they think they cannot trust you with their data; you do things with it that they don’t understand, want or expect; or you make it difficult for them to control how it is used or shared”
Here are clear statements of the link between the risks of insufficient data for business and risk of privacy invasion for customers, and the possible spirals. The first is a spiral of improvement: if a business uses personal data in ways that also mitigate customers’ risks then those customers may be willing to volunteer more information which can then be used for mutual benefit. Now we have gone around the helix, but arrived at a better place for everyone. Similarly, but at sector or societal level, the European Commission’s
Recitals to the NIS2 Directive
suggest that appropriate sharing of information to improve the security of systems and data could increase confidence and make individuals more willing to transact through digital systems, with benefits for individuals, organisations, “economy and society”.
Considering whether risks might be mutually reinforcing (in either a positive or negative direction) rather than a trade-off, might help us find positive opportunities or, at least, highlight the risk of downward spirals before they do serious damage.
Originally posted: 19 August 2022 in category
Articles
Earlier in the year, Networkshop included a presentation on Juniper’s
Mist AI
system for managing wifi networks. I was going to look at it – as an application I don’t know – as a test for my model for thinking about network/security automation. That may still happen, but first it has taken me down an interesting diversion…
The product video shows two use cases: first, identifying when an access point needs a firmware upgrade and (once approved by a human) doing it; second, tracing from an intermittent client connectivity failure through to a possible root cause in DHCP pool management. In terms of the human/automat relationship, those seem to represent different reasons for automating. The first is, perhaps, the traditional application of automation in the physical world, where humans are doing a repetitive task that could be scripted. Not necessarily a simple task – one of the benefits of automation is that a long sequence of actions can be performed consistently – but a repeated one. The second seems to challenge human capability from the opposite direction – a one-off situation with so many possible resolutions that working out which are most likely to be right involves more data, more knowledge and, perhaps, more linkages than most humans can keep track of. Here automation helps by refining down the whole solution space to a small enough number that a human can examine each one, work out its consequences and at least plan the implementation of the one they choose.
The simple tasks spend most of their time in the left-hand (“automated”) loop, but we need an automat that can detect and alert us when something about the task has changed so the original automation “script” may no longer be appropriate. Then the human can step in, perhaps redefine the boundaries and/or update the script for the new circumstances.
The complicated tasks spend most of their time in the right-hand (“human”) loop, but an automat may be able to spot patterns – either in the technological context or in how humans respond to it – that help it make occasional suggestions. This could be anywhere between a traditional expert system approach (“if connection failures, look at DHCP”) and something more like data-driven machine learning (“which kinds of logfile entry are correlated with this kind of problem report?”). Some humans can do that unassisted – I remember an amazing presentation at a FIRST conference many years ago where a human analyst pivoted through a series of data sources, including image hashes, to link together apparently isolated malware incidents. But most of us could probably use the occasional suggestion from an automat that can look at far more datapoints and possible connections than we can. Ideally we’d involve both the human “I remember one of these…” and the machine “oooh, data…” approaches. And, by providing (cross-)feedback on the results of collaboration, maybe even improve both?
For a final squeeze on the diagram, could we use it to explore moving some (sub-)problems from one side to the other? If part of a simple problem evolves in a way that we need to human-approve those solutions, can we define which part, and help the automat send the right situations for approval? Or, coming the other way, identify some parts of complex problems that we understand sufficiently well (at least, for now) that they can transition at least from human-advice to human-approval, and maybe even to fully automated?
Originally posted: 5 August 2022 in category
Articles
Throughout the time I’ve been working for Janet, the possibility of using technology to block undesirable activity on networks and computers keeps coming up. Here are four questions I use to think about whether and how technology is likely to be effective in reducing a particular kind of activity:
Where is the list?
Any technology needs a set of instructions. In the case of blocking, we need to tell it how to distinguish things that should be blocked from things that should be allowed. Typically, that’s a list of Internet locations. One day machine learning may get closer to understanding content or intention, but we’ll still need to provide it with a good/bad model.
So, can we get that list from someone else, or do we have to create and maintain it ourselves? Maintained lists of different categories of activity may be available, either free or as part of commercial services or appliances. If we have to create a new list, do we have the skills, resources and permission (in some cases including legal) to do that? How will we keep it up to date, and handle any challenges to our decisions to include or exclude particular actions or content?
Where is the technology?
Internet technologies typically give us four different ways to specify things to be blocked: network (IP) addresses, domain names (DNS), application identifiers such as URLs and email addresses, and content inspection (e.g. keywords or hash values). Each of these gives a different precision, depending on the nature of the unwanted activity, so we should choose the one that most accurately defines what it is we want to block. Errors are likely in both directions – over-blocking that prevents legitimate activity: under-blocking that allows some unwanted – but choosing the right blocking mechanism should minimise these. Modern technologies such as cloud hosting and Content Delivery Networks (CDNs) involve a lot of sharing of both domain names and IP addresses, so those rarely offer good precision. Application identifiers are usually the most precise but extracting and checking them adds delay and privacy issues. Content inspection is unreliable outside a narrow set of applications, such as detecting repeat appearances of known illegal images.
Whatever technology layer we choose for blocking, we need some equipment to implement the block, and some way to ensure that network traffic goes through that equipment. Depending on the approach chosen, existing routers (IP), resolvers (DNS) or proxies (identifiers and content) may offer relevant functions: otherwise new equipment will be needed. Note that forcing traffic through blocking equipment is likely to create a single point of failure. Blocking and resilience are very hard to reconcile.
Who are the users?
A few kinds of activity – notably, active threats to connected computers – can be blocked for every user of the network. More often institutions will want to choose which blocks to apply and to whom, so should opt-in to the blocking, rather than having it imposed. If institutions need to make local changes to make blocking effective, imposing it before they are ready will have unpredictable results, possibly undermining existing protection measures. To assess the effectiveness of blocking, or to use the blocked content in research or teaching, particular individuals or locations will need to be exempted from the block.
These issues have implications for where the blocking equipment is located, who configures it and has access to logs. Equipment should be placed where it will have access to as much of the traffic to be checked as possible and (because most technologies add delay) as little other traffic as can be arranged. Where fine-grained per-user or per-location control is needed, this must be managed by the organisation that can identify the individuals and locations that should be (temporarily) exempted: typically their institution. Note that such fine-grained control is technically complex to implement for IP and DNS blocks. Where access to logs is required – for example to provide help to those who may have tried to undertake prohibited activities – this should also be at institutional level.
How will people react?
Technical blocks can always be circumvented, so are most effective against activity that no one should want to encounter. Even if recipients welcome the block, we still need to consider how malicious actors will respond: they might simply change location so we have to update lists more frequently; but they may also move activity closer to legitimate services to make over-blocking more likely and more disruptive.
Attempting to block activity that users desire gives them an incentive to circumvent the block. They can use different connectivity (home or mobile), but there are many technical ways to evade blocks without changing network. The activity may then continue but be invisible to those operating the network. Worse, most evasion technologies circumvent
all
blocks, including those for unwanted activity such as viruses, ransomware and other threats to devices and individuals. As our
Guide to Filtering on Janet
explains, it is particularly important that technical measures against desired content are part of a wider awareness, behaviour and support process: information and warnings may help reduce deliberate circumvention.
Examples
Two examples show how the questions can help explore the use of technology against different types of unwanted activity.
Distributed Denial of Service (DDoS)
Where is the list?
DDoS attacks against Janet and its customers are usually
identified and blocked
using a combination of source IP addresses and packet characteristics. Live information is available from commercial sources as well as Jisc’s own threat analysts.
Where is the technology?
Although some attacks can be blocked using existing routers it is more efficient (and less disruptive to the routers’ intended function) to redirect suspect traffic to a dedicated cleaning service where malicious traffic can be identified and blocked and legitimate traffic from the same sources (which are usually compromised computers) forwarded to its intended direction.
Who are the users?
DDoS attacks can target any institution or service. Since blocks are typically temporary (the average attack duration in mid-2022 was one hour, the maximum six) and precise, they can be applied to protect all users of the Janet network.
How will people react?
Targets of blocked attacks should welcome the protection provided. Attackers can, and do, switch both the sources and targets of their attacks when blocked. Hence it is essential that blocks reflect live information from the network, as well as from external sources.
Terrorism
Where is the list?
Lists of content, including some regulated by Terrorism laws, are available through filtering services.
Where is the technology?
Terrorist content is frequently published through otherwise legitimate social media and hosting services. Unwanted content therefore needs to be defined at URL level, suitable for application proxies able to make these distinctions.
Who are the users?
UniversitiesUK has guidance on how to provide researchers with the access they need to
security-sensitive material
. Such access must be managed by the institution that can vet requests for access, verify the identities of authorised researchers, and provide appropriate access control facilities.
How will people react?
The
Home Office Prevent Duty Guidance
warns that some individuals may be drawn in by this kind of material. These may quickly adopt technologies to evade any blocks, so institutions’ Prevent strategies should aim to provide appropriate advice and support to anyone showing early signs of interest.
Originally posted: 12 July 2022 in category
Articles
Victoria Baines closed the FIRST conference with
a challenge to improve our image
(
video
). Try searching for “cyber security” and you’ll see why: lots of ones, zeroes, padlocks, and faceless figures in hoodies. Some of the latter look a lot like the
grim reaper
, which makes the task seem hopeless: in fact, cyber badguys can be resisted. And you don’t need to read binary or work in a datacentre to do it.
What’s especially odd is that similar images and phrases are often used for defenders, too. Mystique may make us feel good, but it doesn’t help with recruitment and retention. We need a much wider range of skills, personalities and people to defend the online world. And referring to them as superheroes doesn’t help either: everyone can, and should, contribute to their own and others’ security. Of course superheroes save the world: that’s what they do. What we need to celebrate is the ordinary people who save the world by their choices and actions: reporting odd-looking websites or double-checking when the CEO asks them to buy gift vouchers.
Victoria’s research traces this hyperbole back two thousand years. If you are trying to draw attention to a threat, overstate it, whether it is a “
Cybercrime Tsunami
” in 2003, or
flying chamberpots in the streets of 1st Century Rome
(though Mary Beard thinks Juvenal may not have been overstating much!). Sadly, Victoria’s recent book on the Rhetoric of Insecurity is priced for academic libraries, but her
Gresham College lecture series
, starting this autumn, will be free in person, online or on YouTube.
So what’s the alternative? We need a message and images that encourage everyone to do their bit. Maybe it’s worth returning to the idea of (individual) cyber-hygiene: not so much “coughs and sneezes spread diseases”, but “catch it, bin it, kill it” might have promise.
But if you are thinking “cyber-pandemic”, please don’t!
#552 - Knowledge Management for Security & Incident Response
Originally posted: 11 July 2022 in category
Articles
Knowledge Management (KM) isn’t a topic I remember being presented at a FIRST conference before, but
Rebecca Taylor
(
video
) made a good case for its relevance. Security and incident response use and produce a lot of information – a Knowledge Management approach could help us use it better. Most teams quickly recognise the benefits of having knowledge recorded, rather than just in individuals’ heads, so most will have contacts list, processes and playbooks. Many are also asked to provide statistics. But KM could also help with things like internal and external knowledge bases, from tips for effective forensic investigations to threat intelligence or customer Frequently Asked Questions.
The first step in making this information useful is to know where it is; then attach metadata, such as when it should be used, when it was last checked/updated, etc. Just establishing these single points of truth can build confidence in the information and make the team’s work more effective. But KM seems to call for a more dynamic approach – it’s “knowledge” management, not just “document” management – where those who use information participate in improving it. So the knowledge system also needs to help users and authors communicate and collaborate, both to mark “good document: still relevant” and “I had problems interpreting this bit”. Somewhere around here, we should be moving from recorded information to shared knowledge, I think.
Systems need to support this way of working – for example change control must balance ease of updating and maintaining accuracy – but we also need to promote the right culture. Staff should be encouraged to identify opportunities and problems: those who help to improve knowledge should be recognised and rewarded. One way to do this is to use a KM approach to look at known pain points or inefficiencies: for example rapid sharing Indicators of Compromise between teams working on different engagements.
KM can even help with future planning. Looking at which information is being actively used (and, conversely, sought but not found) can help us make that easier to find and/or justify effort to improve it. If those using a process are discussing changes, can we anticipate, and pre-approve, any variations of policy or mission that may be needed? There’s a link here, I think, to Vilius Benetis’
talk on CSIRT improvement
. A proactive review, ideally every few months, should check: does this still work, could it work better?
While many companies offer “knowledge management” software, that’s not the only option. Rebecca’s talk included effective examples of both a customised commercial system and one (for forensic practitioners, including a Knowledge Base, processes and templates) using Microsoft Teams. Starting small/focussed is definitely the way to go. Identify an area where there’s an obvious need – whether in a particular team or subject area or for management or funders – and use a KM approach to make their work easier. When that succeeds, you’ll have champions to support your work on the next area. Above all, treat KM as a tool to help make improvements, not a thing that should be “done”.
Originally posted: 8 July 2022 in category
Articles
Incident Response Teams are, as the name indicates, responsive. Often they will try to provide whatever services their constituency asks for, or seems to need. However over time that can result in a mismatch between what the team offers and what its resources, capabilities and authority can actually deliver. That leads frustration, both among disappointed customers and among team members who know they are not delivering the best they could. And, as Vilius Benetis asked at the FIRST conference “do their eyes shine with passion?”.
He was presenting (
video
) a report by ENISA that, although titled “
How to set up CSIRT and SOC
”, can also help existing teams move to a more consistent and satisfying state. Critically, this adds a feedback loop to the design/implement/operate sequence that many teams – more or less formally – adopt. An “improve” stage considers the results of “operate” and how “design” might be changed to deliver better outcomes for the team and its constituency. This might involve changes to the CSIRT’s mandate; the services it offers; its processes and workflows; skills and training; facilities; technologies, including automation; cooperation; information security management plan; or implementation requirements. Budgets and other resources may mean it’s only possible to deliver a subset of these ideas, but those selected should be developed into improvement initiatives and detailed design changes. If resources are limited, this might include reducing the range of services offered by the team, to improve the performance of those that are most important.
These feedback reviews should take place regularly, ideally annually: developing relevant metrics for CSIRT performance will ensure consistent reviews as well as guiding operational activities. The presentation identified several sources that can be used, including:
SIM3 model
: for assessing/benchmarking the current maturity of your CSIRT and the required future status
The objective of this process is to improve satisfaction, both within the team and among its constituents. So communicating and celebrating improvement is an important part of that. Shiny-eyed customers may be too much to hope for, but at least we should be enthusing our team members.
Denial
: in a ransomware attack, denial should be short-lived, as the nature of the problem will quickly be clear and undeniable. However there is a danger that individuals at this stage will take unplanned actions, such as changing passwords or rebuilding systems, that are at best a waste of time (while the bad actor still has access to the system) and at worst may destroy information needed for recovery. A related possibility is misplaced (mis)trust in systems, data or people whose reliability isn’t yet known.
Anger
: depending how it is directed, anger can be either destructive – if channelled into finding someone to blame – or constructive – if used to bond and inspire those involved in recovery. “We are all in this lousy situation together, let’s combine our energy to get out of it” can be positive, but needs care, because…
Depression
: individuals may naturally believe the situation is their fault, even if there was no way their actions could have changed the course of events. Leaders must provide constant reassurance, otherwise a feeling of hopelessness can easily spread through the organisation.
Bargaining
: here the risk is of being too successful in the previous stages, leading individuals to over-commit to the recovery process. Ransomware incidents take a long time to repair – anything from two weeks to four months was suggested – which is too long for anyone to work in “emergency” mode. The impact of burnout is amplified because not only the individual’s effort is lost, so is their detailed knowledge and understanding of the affected system. Here external support can help by taking on the “commodity” recovery actions, allowing local staff to focus their knowledge, skills and efforts on the locally-unique aspects.
Acceptance
: this is essential to plan and perform the recovery process. Leaders need to establish and enforce a tempo that will sustain the required level of work without risking burnout, plan a recovery process, and ensure it is trusted by the whole organisation. Earlier emotions may recur, in particular anger and depression, so everyone must ensure the shared, no-blame approach is maintained. Here external support can help emotionally as well as practically: people who are less directly engaged are better placed to manage their own emotions and can spread confidence – “we’ve done this before, with a successful outcome” – among those who are going through a thoroughly unpleasant experience for the first time.
Tony suggested a sixth stage, not in the original Kubler-Ross model:
Meaning
: sometimes referred to as “never let a good crisis go to waste”. Once an organisation has successfully recovered from an incident, it should always review what lessons can be learned and implement measures that make a repetition less likely. This still needs care to manage emotions: a successful review will identify improvements to processes, systems and guidance; one that descends into blaming is unlikely to help the organisational situation and may even make it worse.
Originally posted: 6 July 2022 in category
Articles
The theme of this year’s FIRST conference is “
Strength Together
”. Since I first attended the conference in 1999, we’ve always said the basis for working together was “trust”. However that’s a notoriously slippery word – lawyers, computer scientists and psychologists mean very different things from common language – and I wonder whether security and incident response would benefit from a different framing.
When I joined the global incident response community I tried to observe behaviour, so I could fit in without causing offence. My conclusion was that relationships were actually established by “I will spend some time on you: if that makes my life better then I will spend more time on you”. Trust may develop as part of that collaboration, but the actual basis for it is mutual benefit. The hour I take out of my primary job of protecting my customers will be more than justified if your actions save me two hours in future.
This may seem like semantics, but I think it’s more important. As
Wendy Nather’s keynote
explored, my next security catastrophe may well originate in an entity I’ve never heard of: whether an obscure software library, an organisation deep in my (security!) supply chain, or a data processor engaged by an apparently peripheral organisational function. In a world where
global service providers can be disabled by insecure webcams
, “strength together” needs to extend far beyond those we have established trust relations with. In an emergency, “are we trusted?” may be too high a bar, “are we recognised?” (by others and by the claimed constituency) may be where we need to start.
And, in tough economic times, invoking “trust” and “social responsibility” may underplay the importance of working together. It’s often said that trust is hard to gain, easy to lose. When working together is business-critical, we simply can’t afford to lose the basis for it. A panel session suggested “socially responsible” as a motivation for information sharing, but if that’s the best we can do then we shouldn’t be surprised when its budget gets cut. Again, we need to frame working together as essential, not optional.
As the
European Commission’s draft NIS2 Directive
recognised, effective cyber-security collaboration is now critical for individuals, organisations, the economy and society. The converse of “strength together” is “weakness apart”: unless we recognise the necessity of working with others to improve the whole digital environment then it may not be long before that environment becomes intolerable for all of us.
Originally posted: 5 July 2022 in category
Articles
Wendy Nather’s keynote at the FIRST conference
(
video
) considered the security poverty line, and why it should concern those above it at least as much as those below. To secure our systems and data requires resources (tools and people); expertise to apply those effectively; and capability, including sufficient influence to overcome blocking situations or logistics.
But most current guidance, tools and practice are designed for those above the poverty line, not below. That’s a problem, because insecurity now affects everyone in the digital environment. Pollution is a better metaphor than escaping hungry bears: “there’s more than enough bear for everyone”. Even organisations whose own security is excellent can be hit by breaches in software or services they didn’t know they were dependent on, or devices with which they have no relationship at all. In a digital world where global retailers can be
taken offline by insecure webcams
, helping improve others’ security may be as important as improving your own.
To do that we need to move beyond talking about “awareness” and do what we can to increase “capability”. Small organisations, or those in sectors with low profit margins, can’t afford state-of-the-art security software or people. Dashboards that give security experts visibility of everything that is going on may be less useful to a part-time system administrator who just needs to identify and fix a problem. Open-source software is great, but it’s not free when you include the costs of the skilled people to install, configure and run it. A survey of security experts asked “what is the minimum set of tools?” came up with lists from four to thirty-one. The baseline looked a lot like PCI-DSS, but even that may be beyond the capability of a small business using off-the-shelf security tools.
Legacy systems are a major risk factor: organisations that proactively refresh their technology experience much better security outcomes. It may even have wider benefits: recruitment is likely to be easier for organisations that offer a modern infrastructure experience. So what can we do to help others move at least non-core business systems (for example email and payroll) to cloud-based services where many of the security issues are looked after by the provider? When we work with our own providers, can we encourage them to make essential security functions, such as multi-factor authentication, part of the basic product rather than an add-on? Instead of bare lists of tools, could industry sectors develop their own reference architectures, fitting business and cultural constraints, to help those with less capability implement systems that are easier to operate securely, improve interoperability, and reduce vendor lock-in? And can they work together to discover services that represent a common dependency, and to help them reduce the shared risk?
The pollution metaphor suggests a shared reputational risk as well as a security one. If individuals lose confidence in digital systems and services then we all suffer, not just those directly causing the problem. Over the past decade,
Governments have started to help with “ordinary” internet security threats
not just advanced, state-level, ones. If you are fortunate enough to be above the security poverty line then consider how you can contribute: help others reduce incidents, respond to those that happen, and learn from them, to improve security and confidence for all of us.
Originally posted: 4 July 2022 in category
Articles
My first reaction to
Mehmet Surmeli’s FIRST Conference presentation on Incident Response in the Cloud
(
video
) was “here we go again”. So much seemed awfully familiar from my early days of on-premises incident investigations more than twenty years ago: incomplete logs, tools not designed for security, opaque corners of the target infrastructure, even the dreaded “didn’t we tell you that…?” call from the victim organisation.
But the response and lessons learned were different, and more positive. Maybe the next cloud incident can be different…
It turns out that, although they are often turned off by default, cloud platforms do have logging facilities, and it often requires just a couple of clicks to enable them. Bear in mind, however, that logs kept within the cloud container may be lost when the load scales up or down. Instead it’s better to use the cloud service to build your own (virtual) logging infrastructure, gathering logs from transient virtual machines into a persistent central storage location where you can use cloud facilities to process and explore them. Twenty years ago we knew we ought to have separate infrastructure for gathering, storing and processing logs: cloud systems might actually make that feasible for most organisations to implement.
Keeping incident response within the cloud fits the technical and economic models, too: avoiding limits or costs on exporting large volumes of data and, instead using cloud facilities for their intended purpose of analysing large datasets. As with local incident response, things will be much easier if you prepare tools in advance and use separate accounts and access controls to move data to secure places where intruders can’t follow. As with compromised physical machines, don’t investigate on a system that the badguy can access. Once you’ve established an incident response toolkit on each (major) platform your organisation uses, you can quickly bring new activities within its scope and add new tools as you find them useful. Once you have a working incident response infrastructure and toolkit, consider how you might use cloud tools for real-time monitoring: it should be possible to investigate what intruders are doing as they do it.
Some key principles:
Get logs out of their default locations: cloud dashboards and tools are not designed for incident response;
Default logging is not enough: use the cloud to build the logging infrastructure you need;
Tag and map your assets: don’t make the incident response team reverse engineer what your cloud deployment is supposed to look like;
Establish incident responder accounts, with sufficient privileges to monitor production systems, but no more.
Originally posted: 30 June 2022 in category
Articles
Wout Debaenst’s FIRST talk
(
video
) described the preparatory steps an adversary must take before conducting a targeted phishing campaign, and the opportunities each of these presents for defenders to detect and prevent the attack before it happens. The talk was supposed to be accompanied by live demos, but these were sufficiently realistic that the hosting provider blocked them the night before the presentation!
Create the domain name(s) to be used to create (misplaced) confidence in the phishing emails. I was familiar with the term ‘typosquatting’ for domains that transpose two letters, or use look-alike characters, but ‘combosquatting’ – adding something plausible like “shop” to a genuine domain name – and ‘doppelganger’ – where the malicious domain is created by removing punctuation from the real one – were new, useful, descriptions. Tools exist, including the free
DNStwister
, to check for domains that may be suspiciously close to your own. Another technique is to register something that looks like a genuine platform service, then add the target company as a subdomain: here certificate transparency reports can be a useful source to check for your company name appearing in unexpected places, but wildcard certificates mean that individual subdomains will not be reported.
Prepare the infrastructure that will be used to send emails, host webpages and so on. This involves considerable effort, so phishers will often reuse the same infrastructure across multiple attacks. This creates an opportunity for detection: if your company name appears in association with an IP address, WHOIS information or even website images and templates that have previously been reported in relation to phishing attacks, then it’s likely that bad things are being prepared for you. Tools such as
Virustotal
and
Brandefense
map these known associations. Intruders can evade these by setting up new infrastructure for each attack, or mingle their activities with genuine traffic by using a CDN, but this increases the cost of the attack, hopefully beyond its likely benefit.
Send phishing emails. This provides an additional source of information whose reputation can be checked by the receiving organisation. Email content is often checked, but there are opportunities also to check the originating domain, IP address, mailserver and other information. These defender checks complement those at the previous stage, because freshly-created domains may themselves look suspicious.
Execute malicious code. Although phishing can be conducted using only plaintext, executable components are more common and can often be blocked by disabling unnecessary features, such as macros or filetypes, in endpoint clients and devices.
None of these techniques can prevent phishing by a sufficiently determined attacker, but they increase the cost of a successful attack, both in terms of required preparation and risk of discovery. For many organisations, that should put off sufficient threat actors to significantly reduce the risk.
Originally posted: 29 June 2022 in category
Articles
My post about
automating incident response
prompted a fascinating chat with a long-standing friend-colleague who knows far more about Incident Response technology than I ever did. With many thanks to Aaron Kaplan (AK), here’s a summary of our discussion…
Developments in automated defence
AK: Using Machine Learning (“AI”) in cyber-defence will be a gradual journey. So, in practice in the next years, we won’t even notice that ML is there. I don’t see it as a turnkey/switch on magic. It will appear first for a few well defined sub-fields such as fighting spam – already here for many years (spam assassin, Bayes statistics, etc), never 100% eliminated the spam problem but we can’t live without ML for spam classification anymore – or
weeding out False Positive alerts
in a Security Operations Centre….
AK: Or – this is already being worked on, for example by
CIRCL
– we will see
very simple
classifiers which try to answer simple questions such as “what kind of IP address is this?” (residential CPE, server, datacentre, …). Or questions such as “What’s the probability that this is a genuine webpage on that URL? Or is it rather a simple web server’s default page (in all its variations up till landing pages of domain grabbers)?”. IMHO these tasks are well suited to ML. And all that it will give us for Incident Response is that we get another “opinion” from some system. So the “opinion”/probability for decision support is probably going to come first.
AC: So this is providing incident responders with better information for their decision-making. Indeed often automating routine searches and giving statistical evidence for gut-feel decisions that, if they had time, they’d hope to do manually?
AK: It also is a path towards fully automatic decisions based on (possibly biased) simpler ML models (such as the ones mentioned above). But it will be a gradual, very long journey. First, we will discover just how hard it is to get a good ML based system running and how hard it is to eliminate bias. And since it’s a long journey, we won’t even notice we are on this journey. We plan and learn as we go. One example I am looking into right now: do GPT-3 based systems sufficiently summarise APT threat intelligence reports? It’s *really* fun to play around with…
Developments in automated attack
AC: You mentioned that the badguy might be able to interfere with
my robot
in even simpler ways?
AC: I guess they are both about the impact of tiny non-randomnesses…
AK: Another thought which came to mind after seeing the
good guy – bad guy infinity-eight picture
: this is basically reinforcement learning from the attacker’s point of view. And if the defender also deployed ML on his side of the infinity-eight game, we would end up with essentially something like
Generative Adversarial Networks
.
ANC: Hmmm. When you use a GAN in the lab, there’s a referee to make sure the good guy wins…
Conclusions
ANC: I think you’ve reassured me that both defenders and attackers are on a long journey to use this stuff. And, actually, maybe it doesn’t hugely tilt the balance? On the defender side, we can become more efficient by using ML decision-support tools to free up analysts’ and incident responders’ time to do the sort of things that humans will always be best at. Meanwhile explore what aspects of active defences can be automated.
Attackers will get new tools, too, but for most sites those are going to be mass attacks and, I think, pretty noisy? One of the few things I’ve always taken reassurance from is that a mass attack ought to be detectable simply because it is mass. It might take us a while to work out what it is, but so long as we share information, that doesn’t seem impossible. That’s how spam detection continues to work, and I’d settle for that level of prevention for other types of attack!
Some organisations will, by their nature, be specific targets of particularly well-funded attackers who may use ML for precision. Those organisations need equivalent skills in their defenders. But for most of us our defences need to be good – say, a bit better than good practice – but probably not elite. Thanks.
Originally posted: 29 June 2022 in category
Articles
Threat hunting is perhaps the least mechanical of security activities: according to
Joe Slowik’s FIRST presentation
(
video
) the whole point is to find things that made it past our automated defences. But that doesn’t mean it should rely entirely on human intuition. Our hunting will be much more effective if we think first about which threats it will be most beneficial to find and how we are most likely to find them.
Thoughtful threat hunting requires an understanding of likely adversaries; telemetry and data sources; and the ability to search and query them. Rather than randomly searching for signs of intrusion, threat hunting provides most benefit if it concentrates on the kinds of threat that would cause most harm to the particular organisation. Thinking about how those actors are likely to operate, and what their goals might be, should guide us to the services and systems they are most likely to use. Then we can consider what traces they might leave, and what records we might need to find them. If those don’t exist, then we can fill the gaps either by increasing activity logging in specific areas (but not so far that we overload ourselves) or by considering alternative sources that already exist.
For example a frequent blind spot, mentioned in a number of different talks, is network activity
within
the organization. Perimeter systems such as firewalls should give good visibility of ingress and egress traffic, but multi-stage threats such as ransomware are more easily detected by their unusual lateral movement between organisational systems. But for organisations that identify email fraud as a significant risk, email headers are more likely to be a relevant source.
Even with a focus on specific threats and data sources, threat hunters are likely to have a “needle in the haystack” challenge: data sources are too big for humans alone to analyse. So we need tools to explore individual data sources and, particularly, patterns (or their suspicious absence) across sources. Flexible, exploratory tools are likely to be harder to use effectively than single-purpose searches, so threat hunters need more time to plan and develop their skills. Again, focusing on particular threats can guide this learning to where it will most benefit the organisation.
Finally, when a threat is discovered we should “codify the success”. Having discovered the signs of an successful intrusion, try to update the rules that it bypassed to make the same technique less likely to succeed in future. Repeated hunting for the same threat is frustrating for the hunter and a waste of precious resource for the organisation.
Following my Networkshop talk on logfiles, I was asked at what point logfiles can be treated as “anonymous” under data protection law. Since the GDPR covers all kinds of re-identification, as well as data that can “single out” an individual even without knowing their name, that’s a good CompSci/law question: the work of
Paul Ohm
and others suggests it may take a very long time. But when designing processes I wonder if we should approach from a different angle?
When we were looking at GDPR for Jisc’s (then) 130+ services, we concluded that much the best place to start was identifying the purpose of the processing and the
lawful basis applicable to that
. Once we understood those, most of the requirements – including on transparency, safeguards and user rights – could “simply” be looked up in the law.
I’m now wondering whether we can get a similarly helpful collection of guidance by treating “processing that can use anonymous data” as a sort-of seventh lawful basis? Like the
guidance we derived from the other six
, that should deliver:
Clear definition (and limitation) of
purpose
, without which we’re unlikely to get the right kind and level of anonymisation. We might even conclude that the purpose is better achieved using personal data within the GDPR;
Transparency
both about how we can produce the anonymised data we need and – since the anonymisation step involves processing of personal data – how we explain that to data subjects;
Safeguards
, in particular how we ensure that our data are, and remain, anonymised. These will depend on whether we are actually destroying the input personal data (for example aggregating log records to get usage statistics over time), or just removing sufficient information to make re-identification or singling out unlikely. As the
UK Anonymisation Network
explain, at least the latter approach requires an ongoing risk-management process not dissimilar to the legitimate interests balancing test when using personal data;
Individual
rights
, at least those applicable to whatever lawful basis we are using for the anonymisation process, and perhaps also something similar to a “right to object” if the data subject can point out a particular reason why that process doesn’t effectively anonymise them. We should at least learn from the GDPR right to object and use any data subject concerns as prompts to
review what we are doing and how we are explaining it
, to understand why that isn’t sufficiently reassuring.
The term “anonymous” is used with sufficient variety of meaning that I find it worrying more often than reassuring. Has the speaker actually implemented a process to produce “personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable” (GDPR Rec. 26), or just blanked the “Personally Identifying Information” (the dreaded US term)? Something like the above approach would give me a lot more confidence.
Two common concerns in incident response are (a) not having the data needed to investigate an incident and (b) not being able to find signs of incidents in a mass of other data. My Networkshop talk (see “
Making IT Safer… Safely
”) looked at how the GDPR principles might help us to get it, like Goldilocks’ porridge, “just right”.
First, write your incident response (IR) process(es). How am I going to detect a (possible) incident? What will I do when that happens? This helps towards the GDPR principle that processing should be Lawful and Fair: and also means that your documented IR process will be quick;
Then think what data and sources those processes will need, make sure you know where those are and that you can access them quickly when needed. For the GDPR Data Minimisation principle that tells you which data and sources you don’t need: on the IR side it means the ones you do need should be ready to hand;
Then think how long after an incident it is realistically possible and worthwhile to conduct an investigation, rather than simply wiping the affected machine and restoring it to a more secure state. You’ll often need external information to interpret your logfiles: what was the network and system configuration? What vulnerabilities existed and were being exploited? Once those data no longer exist an investigation is likely to be hard work. Also, once an intruder has had access to a system for months, they’ve had ample time to do damage and conceal their traces. How much of the logs can be trusted? Getting rid of logfiles that are too old to be worth investigating addresses the Storage Limitation principle: it should also reduce the size of the Incident Detection haystack;
Keeping logs secure should be obvious, but the same needs to apply to the tools used to access them. Both are a goldmine for any intruder. Security is both a GDPR principle and an IR obligation;
Automating at least the early stages of incident detection is another win-win. Data Protection law has long recognised that having a computer, rather than a human, look at personal data can contribute to Process Minimisation and reduce intrusiveness: from the IR side, having a machine group logfile “events” into security “alerts” reduces tedium and lets humans get on with what they are best at. Incidentally, I’ve also been finding some
guidance on automation in draft AI laws
.
One of the legal advantages of incident response is that most of the identifiers we deal with (IP and MAC addresses in particular) are what GDPR refers to as pseudonyms: they don’t directly identify an individual but require an additional step (such as looking at DHCP and authentication logs) to do so. Postponing that lookup process until we are pretty sure that an incident has happened and that there are victims in need of help, contributes to GDPR Purpose Limitation and delivers the benefits of IR to those who need it most.
Once you’ve developed your process, it may be worth checking it by conducting a more or less formal
Data Protection Impact Assessment
. We are doing these regularly for the Janet Security Operations Centre, who are finding them a really useful way to think about their work (so much so that they asked to do them more often!). We also
publish the results
, which we hope will reassure users of the network that, yes, we do process a lot of personal data, but that’s necessary to protect you and we work hard to ensure we do it as safely as we can.
#541 - Does the AI Act allow automated network defence?
Originally posted: 1 June 2022 in category
Articles
In response to my posts about the relevance of the draft EU AI Act to
automated network management
one concern was raised: would falling within scope of this law slow down our response to attacks? From the text of the Act, I was pretty sure it wouldn’t, so I’m grateful to Lilian Edwards for the light-bulb moment that not only it won’t, in practice, but it can’t, in principle.
That’s because the AI Act follows in a long tradition of European product liability/safety laws. These regulate how products are
developed
but say almost nothing about how they may be
used
after sale or supply. In the
case of the AI Act
, Articles 9 to 19 apply to the designers and providers of high-risk AI systems, but only Article 29 applies to users, and simply requires them to use the system in accordance with the instructions.
So the AI Act does suggest how to think about AI during its development. As I’ve suggested in a previous post, those are exactly the kinds of thought we should be having anyway, to
reduce the risk of our automation going rogue
(perhaps encouraged by a badguy). By insisting, in Article 14, that the system provides all the human-machine tools that the user might need to enable effective oversight and control of operations, the Act should even increase the flexibility and speed with which we can deploy and use automation. Might we want the possibility of fully-automated defence? If so, Article 14 reminds us to think, during software development, about the tools we will need to do that safely. Do we need the option to step in, audit and debug the automat’s behaviour? If so, then Article 12 reminds us to build in the controls and records those actions and processes will need.
Where a literal interpretation of law might be a problem is Article 22 of the GDPR, whose opaque wording (a source of confusion since at least 2001) now seems to be interpreted as a
ban
– rather than a right to request human review – on “decision[s] based solely on automated processing … which produce[] legal effects … or similarly significantly affect[] him or her”. For a full discussion, see chapter 6 of my
paper on incident detection
. The problem is that, unlike the corresponding text in Recital 38 of the
Law Enforcement Directive
, the GDPR omits the word “adverse”. So an over-literal reading could read this as prohibiting automated processing with significant
beneficial
effects. Say, for example, protecting an individual’s data and rights against
spam & malware
(approved by the Article 29 Working Party in 2006), distributed
denial of service attacks
or, the most recent application,
ransomware
…
Does the GDPR really compel us to wait for individual human approval for automated defensive measures that Regulators have supported for fifteen years? Fortunately, the approach to interpretating European law is “purposive”, so a legally valid response to such a suggestion would be “that’s nuts”.
Originally posted: 24 May 2022 in category
Articles
To help me think about
automated systems in network and security management
, I’ve put what seem to be the key points into a picture. In the middle is my automated network management or security robot: to the left are the systems the robot can observe and control, to the right its human partner and the things they need.
Taking those in turn, to the left:
The robot has certain
levers
it can pull. In network management, those might block traffic flows, throttle or redirect them; in spam detection they might send a message to the inbox, the spambox, or direct to the bin. First thing to think about is how those powers could go wrong, now or in future: in my examples they could delete all mail or block all traffic. If that’s not OK, we need to think about
additional measures to prevent it
, or at least make it less likely (15).
Then there’s the question of what
data
the robot can see, to inform its decisions on how to manipulate the levers. Can it see content, or just traffic data (former is probably needed for spam, latter probably sufficient for at least some network management)? Does it need more, or less, information, for example historic data or information from other components of the digital system? If it needs training, where can we obtain that data, and how often does it need updating? (10).
Finally, we can’t assume that the world the robot is operating in is friendly, or even neutral. Could a
malicious actor
compromise the robot, or just create real or fake data to make it operate its levers in destructive ways? Why generate a huge DDoS flow if I can persuade an automated network defender to disconnect the organisation for me? Can the actor test how the robot responds to changes, and thereby discover non-public information about our operations? Ultimately, an attacker could use their own automation to probe ours (15).
And, having identified how things could go wrong, on the right-hand side:
What
controls
does the human partner need to be able to act effectively when unexpected things happen? Do they need to approve the robot’s suggestions before they are implemented (known as human-in-the-loop), or have the option to correct them soon afterwards? If the robot is approaching the limits of its capabilities, does the human need to take over, or enable a simpler algorithm or more detailed logging so that the event can be debugged or reviewed later? (14).
And, what
signals
does the human need, to know when and how to operate their controls. This could include individual decisions, capacity warnings or metrics, alerts of unusual situations, etc. What logs are needed for subsequent review and debugging (12, 13)?
Having applied these questions to the case of email filtering, they seem to be a helpful guide to achieving the most effective machine/human partnership. Also, and encouragingly, answering them seems to address most of the topics required for
high-risk Artificial Intelligence in the draft EU AI Act
(the numbers in the bulleted list are the relevant Articles and my visualisation). Whether or not these systems are formally covered by the final legislation, it’s always good when two completely different approaches get to similar answers.
I’m delighted to announce that the
Journal of Learning Analytics
has published our paper on why and how we developed the
Jisc Wellbeing Analytics Code of Practice
. If you want to know the context that prompted our interest in data-supported wellbeing, or how we mined the GDPR for all possible safeguards, then have a look at
Originally posted: 12 May 2022 in category
Articles
Decisions whether or not to use Artificial Intelligence (AI) should involve considering several factors, including the institution’s objectives, purpose and culture, readiness, and issues relating to the particular application. Jisc’s
Pathway Towards Responsible, Ethical AI
is designed to help you with that detailed investigation and decision-making.
But I wondered whether there might be a check that can be done in a few minutes, to get an initial feel for whether a particular use of AI is likely to be a good institutional fit. So here’s a proposed scale of “AI Terrain Roughness”, using objective factors that should be easy to determine from the documentation of a candidate product or service. It only covers some of the relevant factors, but if a glance at this “Terrain” seems to fit your level of experience and comfort with data and AI, then it’s worth moving on to the more detailed investigation.
The scale tries to capture the complexity that’s likely to be involved in using AI for a particular purpose, at all levels from technical and legal to organisational consultation and communications. I’ve chosen a hiking metaphor: for even a simple exploration you should know the route and weather forecast; whereas a complex AI project will require good preparation, skills and equipment, take significant time and teamwork, probably involve setbacks and some (institutional) discomfort. On deeper investigation, you may conclude that the benefits of a particular application do justify that complexity, and experience may give you confidence that you can deal with any problems. But a three-mountain application probably shouldn’t be your first venture into AI.
The factors considered are
the kinds of
data
used, or generated, by the AI;
the technology used, or
purpose
for which it is deployed;
the degree of prior control over how the AI is configured for, or
learns
about, its environment; and
the need to
integrate
it with other existing systems and data.
For each factor the scale is based on either legal (
data
&
purpose
) or technical (
learning
&
integration
) distinctions that have been identified as making AI more or less challenging. If you really want to reduce this to a single number, choose the highest of the four.
Data
This factor records the most sensitive type of data that the system appears to use or generate. Definitions are taken from the
General Data Protection Regulation
.
No use or creation of personal data.
Uses or creates personal data (“data relating to an identified or [directly or indirectly] identifiable natural person … in particular by reference to an identifier such as a name, identification number, location data, online identifier or one or more factors specific to … that natural person” – GDPR Art.4(1). Note that this is much broader than the US concept of “personally identifiable information”).
Uses or creates special category personal data (racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, biometric, health and sexual – GDPR Art.9).
Purpose
This factor reflects how regulators assess the risk of using AI with a particular technology or for a particular purpose. Sources are primarily the EU
draft Regulation on AI
, UK and EU case law, and statements by national data protection regulators, particularly where these relate to education.
Technology/purpose is regarded as low-risk (i.e., typically, not mentioned) in law, regulation and cases.
Technology/purpose is regarded as high-risk in law, regulation and cases (including determining access to education or course of someone’s life, e.g.
assessing students
’ performance;
automated decision-making
).
Technology has been banned for some purposes or contexts (e.g. behavioural manipulation or
profiling
likely to cause harm or unjustified disadvantage; face recognition and other forms of
remote biometrics
; potentially
discriminatory data sources
).
Learning
This factor looks at how the AI is programmed or “learns” about its local environment. As discussed in the
AI Pathway
, this includes the degree of control over the inputs from which the AI learns, the method by which it learns, and the range of outputs it can produce. Less control lets the system behave in unexpected ways, which may be desirable in some contexts but not in others. Managing the risk of unexpected behaviour adds complexity.
Learning/programming by well-understood methods to map from a known set of input data to a defined set of outputs (risk can be managed by design and comprehensive testing).
Learning where outputs are constrained (e.g. to a pre-defined set of decisions or categories), but either the input data or method are unconstrained, e.g. supervised or goal-based learning (risk of undetected or inexplicable learning failures, including bias).
Real-time learning, feedback loops or uncontrolled outputs (risk of emergent inappropriate behaviour).
Integration
This factor considers whether the AI can be, or must be, integrated with other systems. Such integration increases the technical/effort requirement, but also creates risks that must be managed. AI that consumes data from other systems can amplify problems (such as data quality or understanding of process): AI outputs consumed by other systems may lose essential qualifiers or caveats. Either may produce unexpected or harmful results.
AI system is designed to operate standalone (e.g. the natural language processing in an informational chatbot).
AI system can operate standalone, or be integrated with other data and services (e.g. adding transactional ability to a chatbot).
AI system can only function if integrated with other data and services (e.g. a guided learning system that needs information from the virtual learning environment).
#537 - Data Protection expectations on Vulnerability Management
Originally posted: 4 May 2022 in category
Articles
Legal cases aren’t often a source for guidance on system management but, thanks to the cooperation of the victims of a ransomware attack, a recent
Monetary Penalty Notice
(MPN) from the Information Commissioner (ICO) is an exception. Vulnerability management was mentioned in previous MPNs (e.g.
Carphone Warehouse
,
Cathay Pacific
, and
DSG
), but they don’t go much beyond “do it”, and “unpatched for more than four years is not acceptable”. Now we have information on factors to include in patch prioritisation, steps that a vulnerability management process may include, and the features of data protection law that should encourage vulnerability management. The last is particularly interesting, as those features aren’t just in UK law, but are common to privacy laws across the globe.
In this case, intruders stole documents containing personal data from an archive server, before encrypting it and demanding ransom. It was suspected that access was obtained via an unpatched vulnerability in software, though this wasn’t proven. The vulnerability had been announced by the software vendor in December 2019 and mitigations provided, a patch was made available in January 2020, but the system was not patched until June (para 51). The ICO stresses that:
The original announcement “strongly urges affected customers to immediately upgrade to a fixed build OR apply the provided mitigation” (52);
The UK National Cyber Security Centre (NCSC) published an alert in late January warning “that malicious actors were exploiting” the vulnerability, with a tool to detect the vulnerability (53);
The NCSC published a further joint advisory with the US Department of Homeland Security in April (54);
The vulnerability was given a Common Vulnerability Scoring System (CVSS) Base score of 9.8, “Critical” (57).
There are clear messages here that organisations should monitor security announcements by vendors of software and operating systems, as well as the NCSC and similar (inter-)national bodies; also that CVSS scores and reports of active exploitation should be considered when prioritising remedial action.
Not actually explicit in the MPN, but strongly implied, is that we
should
be prioritising among vulnerabilities. It seems unlikely that this was the only vulnerability announced during the relevant period: the MPN’s focus on factors creating urgency implies that resources should have been allocated first to the high-severity, actively-exploited one. However, even for this urgent vulnerability, the ICO recognises that immediate patching may not be the appropriate response: there is explicit mention (59) of “test[ing] the patch prior to deployment” and reference (56) to ISO27002’s “suggestion that organisations should define a timeline to react to notifications of potentially relevant technical vulnerabilities, and once a vulnerability has been identified, associated risks should be identified and actions taken, such as patching the system to remove the vulnerability”. Application of the patch should be “prompt” (59) and the Cyber Essentials timescale of 14 days is referenced (57).
The MPN therefore appears to be a strong endorsement of risk-based vulnerability management, using tools such as vendor and
NCSC alerts
,
CVSS scores
and likelihood of exploit tools such as
Forum of Incident Response and Security Teams’ Exploit Prediction Scoring System (EPSS)
and the
CISA known exploited vulnerabilities catalogue
. The MPN also discusses multi-factor authentication and encryption, so could be a useful reference for those, too. Four features of data protection law should provide a particularly effective incentive to adopt such good practice: the law applies to behaviour, of an individual organisation (the ICO has explicitly rejected comparisons with “industry practice” in previous MPNs), expects risk to be considered (through words such as “appropriate measures”), and can apply sanctions irrespective of harm or causation. I’ve found these features in laws from six continents so, wherever you are, demonstrating how security measures relate to a law of this kind should be a good way to communicate their importance between technical, compliance and regulatory spheres.
Originally posted: 21 April 2022 in category
Articles
Reading the Machine Learning literature, you could get the impression that the aim is to develop a perfect model of the real world. That may be true when you are trying to
distinguish between dogs and muffins
, but for a lot of applications in education, I suspect that a model that achieved perfection would be a sign of failure.
That’s because our models are often part of a process designed to change the real world. We use
analytics
to understand how to teach and learn better: students should be enabled and encouraged to beat the model. Even applications like the
Graide feedback tool
should, over time, result in students needing different feedback, by helping tutors explain hard concepts better the first time around. At the simplest level, that means we should be updating our models frequently, and limiting the age of data we include in them as it will – by design – go out of date.
But the safety-critical world may provide higher-level guidance. Here change is considered inevitable, and something that systems must plan for. An intriguing example from a
paper on using safety-critical thinking to inform AI design
is that operators will always find different ways to use systems from how their designers intended. That’s not a bug, it’s a feature. The operators’ approach may well work better in the real world; the real world may itself have changed from the design. Systems – technical, organizational, and human – within which Artificial Intelligence sits must detect those changes,
ensure that they cannot produce unsafe outcomes
, and work out what can be learned from them. If a change makes the system better, we should ensure it is widely adopted: if it highlights a problem with the system (for example that use as designed is inefficient or inconvenient) then the system needs to be improved.
Above all, the reality of change must be part of the culture around AI. A human finding a different way to use it must not be considered a “problem” or “at fault”. They are using human creativity to identify either an opportunity or a risk: both should be welcomed, even encouraged. A system that doesn’t cope with change is a problem.
Originally posted: 19 April 2022 in category
Articles
I’ve been reading a fascinating paper on “
System Safety and Artificial Intelligence
”, applying ways of thinking about safety-critical software to Artificial Intelligence (AI). Following is very much my interpretation: I hope it’s accurate but do read the paper as there’s lots more to think about.
AI is a world of probabilities, statistics and data. That means that anything that could possibly happen, might. We can adjust AI to make particular behaviours unlikely, but the statistical nature of the approach means we can’t make them impossible. This contrasts with or, the paper suggests, is complementary to, the approach taken in safety-critical systems, which declares some outcomes to be prohibited and uses limits and controls to prevent them happening; or, at least, to require human confirmation before they do. The key point seems to be that you don’t rely on a single system to restrict its own behaviour, you wrap independent controls around it.
In the AI world, even in applications where safety isn’t an issue, it strikes me that this kind of approach might be preferable to trying to incorporate all the limits we want into the AI itself. If we need to restrict what impacts the AI can have on the outside world, consider whether that can be done by way of a wrapper around it. Swaddling a baby keeps it warm, but also restricts its movement and cushions its surroundings against unexpected behaviour. And, once the AI is wrapped up, its design and training can focus on achieving the best statistical interpretation of its inputs; any low-probability quirks may be more tolerable if we know there’s an external wrapper to catch those that would cause harm. And, incidentally, to draw designers’ attention to the fact that something considered unlikely did actually happen.
In my
visualisation of the draft EU AI Act
, such a wrapper would probably invoke Human Oversight, but fit mainly in the Risk Management, Quality Management and Lifecycle areas. As those headings suggest, outside contexts where the use of AI is entirely prohibited, the Act itself aims at managing risk, rather than making certain outcomes impossible. But there are a few hints at hard external limits on the AI: “
mitigation and control measures
in relation to risks that cannot be eliminated” (Art.9(4)(b)); “Training, validation and testing data sets … particular to the
specific geographical, behavioural or functional setting
” (Art.10(4)), and “shall use such systems
in accordance with the instructions
of use accompanying the systems” (Art.29(1)). Technical and procedural controls that stop the AI going beyond its intended setting or operating outside instructions might be good candidates for an external wrapper.
This approach naturally focuses attention on the links the AI has to the outside world: these are the points where the AI approach and the safety-critical one meet. What information can the AI measure? What levers can it pull? How could that could go wrong, either through accident or deliberate, including malicious, action? Are there inputs – for example a situation outside the one the AI was trained for, or data such as
signs deliberately modified to mislead
– where exceptional action is required: warnings, changing algorithm to something simpler or more explicable, ignoring the particular input, or returning control to a human? On the output side, are there actions that the AI is capable of triggering that we need to prevent from taking effect?
This reminded me of a situation, many years ago, where a “smart firewall” decided its network was under attack on UDP port 53. In accordance with its design, it blocked the “hostile” traffic. Unfortunately blocking responses to DNS requests turned out to be a very effective way to make the Internet unusable for everyone behind that firewall. This does seem like an example where we would want the AI wrapper to intervene, probably by asking a human to confirm whether this particularly significant port number should be treated according to the normal blocking rules.
And that, in turn, suggests what I think may be a common rule: that the wrapper around the AI needs to be designed by those with expertise in the particular domain where the AI will operate. A data scientist might reasonably assume that port 53 is no different to ports 52 or 54; a network manager will immediately know its significance. Having identified these unusual situations, the domain experts need to work with AI experts to identify how they might be detected and responded to. Are there relevant confidence levels that the AI can use to warn human operators, to increase logging, or change to a different algorithm? What information or signals could it generate to help operators understand what is happening? What alternative processes can we fall back to if it’s no longer safe to rely on the AI?
Considering those questions before deploying AI should significantly reduce the number of nasty surprises after it starts operating.
Originally posted: 8 April 2022 in category
Articles
I’m hoping to use the
EU’s draft AI Act
as a way to think about how we can safely use Artificial Intelligence. The Commission’s draft sets a number of obligations on both providers and users of AI; formally these only apply when AI is used in “high-risk” contexts, but they seem like a useful “have I thought about…?” checklist in any case.
The text can be found below, but I’ve been using this visualisation to explain to myself what’s going on. Article numbers are at what I think is the relevant point on the diagram. Comments and suggestions very welcome!
[11/4/22: Added arrows to show that Training and Application have links from/to the outside world]
What the draft Act says (first sentence of each of the requirement Articles):
Article 9: A risk management system shall be established, implemented, documented and maintained in relation to high-risk AI systems
Article 10: High-risk AI systems which make use of techniques involving the training of models with data shall be developed on the basis of training, validation and testing data sets that meet the quality criteria…
Article 11: The technical documentation of a high-risk AI system shall be drawn up before that system is placed on the market or put into service and shall be kept up-to date (further detail in Article 18).
Article 12: High-risk AI systems shall be designed and developed with capabilities enabling the automatic recording of events (‘logs’) while the high-risk AI systems is operating. Those logging capabilities shall conform to recognised standards or common specifications (obligations on retention in Article 20).
Article 13: High-risk AI systems shall be designed and developed in such a way to ensure that their operation is sufficiently transparent to enable users to interpret the system’s output and use it appropriately.
Article 14: High-risk AI systems shall be designed and developed in such a way, including with appropriate human-machine interface tools, that they can be effectively overseen by natural persons during the period in which the AI system is in use.
Article 15: High-risk AI systems shall be designed and developed in such a way that they achieve, in the light of their intended purpose, an appropriate level of accuracy, robustness and cybersecurity, and perform consistently in those respects throughout their lifecycle
Article 17: Providers of high-risk AI systems shall put a quality management system in place that ensures compliance with this Regulation.
Article 19: Providers of high-risk AI systems shall ensure that their systems undergo the relevant conformity assessment procedure in accordance with Article 43, prior to their placing on the market or putting into service.
Article 29: Users of high-risk AI systems shall use such systems in accordance with the instructions of use accompanying the systems.
Originally posted: 6 April 2022 in category
Articles
A really interesting series of talks on how to gather and share information about the performance of networks at today’s
GEANT Telemetry and Data Workshop
. One of the most positive things was a clear awareness that this information can be sensitive both to individuals and to connected organisations. So, as the last speaker, I decided I didn’t need to present “be careful” and talked instead about “how to reassure lawyers, partners and users”.
Key point, in my experience of being on both sides of that question, is not to ask “Can we do this?”: that immediately gets people envisaging how wrong it could go. Instead, explain “This is what we need to do, here’s how we propose to make it safe: are you comfortable with that?”. They may still be able to suggest improvements, which is great: now we’re working together, rather than in opposition.
As usual on this blog, the GDPR provides some useful pointers to how to make things safe. Remember that its subject is “the protection of natural persons … and the free movement of data”. So how might we do both of those with information about networks? Some ideas:
Active measurements, especially between devices deployed for that purpose such as
perfSONAR
, are likely to contain less extraneous, potentially-sensitive, information than monitoring real user traffic. For many of the things you want to know about a network, they are a more reliable source anyway.
In GDPR terms, data about a device such as a router or server that has a large number of indistinguishable users is much easier to work with than data about something that might be a single-user’s endpoint. Again, measuring performance between institutions and/or key network nodes is often more relevant than individual flows, too.
If you do need to get closer to the edge of the network and measure user experience, then statistics will often provide relevant information. Data protection law doesn’t have a fixed threshold, but if you can show that you are combining data from at least 10-20 individual users then both users and lawyers will usually be more relaxed.
Finally, there are situations where you do need to look at individual flows: primarily to debug them (if the individual involved has reported a problem) or to investigate a possible security problem (if someone else has). In the first case it should be natural, and uncontentious, to explain that to debug a network issue you need to look at the individual’s network traffic. Professional codes, such as our
System Administrator’s Charter
(which also works for network admins) should add reassurance. For security problems, I’ve written and presented a lot on
how the GDPR actually encourages necessary use and sharing of network and system data
.
Each of these kinds of safeguards can benefit from a bit of simple (definitely not lawyerly!) documentation: how and where active measurement works; how you select devices that are privacy-safe to monitor; how your statistical techniques irreversibly anonymise general data; and the safeguards you apply when investigating faults or security issues. And, above all, how these activities benefit all users of networks and systems. With those in hand you should be able to discuss your planned network telemetry activities with confidence.
#532 - Right to Object: Public Interest Processing
Originally posted: 1 April 2022 in category
Articles
GDPR Article 21 provides a “right to object” whenever personal data are processed based on either Legitimate Interests or Public Interests. In both cases, an individual can highlight “grounds relating to his or her personal situation” and require the data controller to consider whether there remain “compelling legitimate grounds for the processing which override the interests, rights and freedoms” of that individual. If there are no such grounds then processing must cease.
Responding to an objection therefore requires the data controller to analyse both the “grounds for processing” and the “interests, rights and freedoms” of the individual. However the different origins of “Legitimate” and “Public” interests mean the data controller’s ability to do so is likely to be very different depending on which basis is used for processing.
For Legitimate Interests there should be little difficulty. Before processing can start, Article 6(1)(f) requires the controller to define the interests served, Article 13(1)(d) requires them to inform data subject of those interests; Article 6(1)(f) requires them to consider what “interests or fundamental rights and freedoms” might be affected by the processing. On receipt of an Article 21 objection, the controller simply has to re-assess the risks to that particular individual’s interests, rights and freedoms and determine whether or not those change the balance with the interests that have already been defined and declared. If they do, the objection must be granted and the individual excluded from processing.
But for Public Interest (Article 6(1)(e)), the data controller’s initial duty is merely – according to Article 6(3) – to identify an applicable law that identifies a “task carried out in the public interest” for which the processing is necessary or else assigns them “official authority”. Responsibility for the content of the law is given to the legislator: it must “meet an objective of public interest and be proportionate to the legitimate aim pursued”. However there is no obligation on the legislator to declare either what that “objective of public interest” was, or what risks were considered when ensuring that it is “proportionate”. This leaves a challenging task for any Public Interest data controller required to “demonstrate compelling legitimate grounds … which override the interests, rights and freedoms”. How can they assess whether the objecting individual’s “particular situation” changes that balance, when they may have no idea how the balance was assessed in the first place?
A possible approach might be to focus on the risk side. Arguably the data controller should have done some sort of risk assessment when determining whether their chosen means of processing was “necessary” for the legally-defined task, or if a different approach would be less intrusive. Having done such a general assessment, it should be easier to determine whether a given individual’s “particular situation” changes that assessment significantly. If the individual is exposed to a risk that was not previously considered then there must be doubt – without additional information – whether the legislator’s original proportionality test would still be satisfied. If there are no new risks, but an apparently increased exposure, then it’s worth considering whether additional safeguards could be applied to bring the individual within the original (presumably acceptable to the legislator) range. As in my other Right to Object post,
identifying new safeguards that can make processing safer for everyone
is a highly positive outcome of the Objection process. If, however, no suitable safeguards can be found for an increased risk, it seems unlikely that the controller will be able to demonstrate the required “compelling legitimate grounds” to continue processing after an objection.
Finally, it’s worth noting that starting processing for a Legitimate Interest requires “legitimate grounds”; but continuing after an objection has the stronger requirement that those grounds be “compelling”. This makes sense for both Legitimate and Public Interests, since overruling an objection is, itself, likely to leave the individual feeling harmed. When assessing an objection, data controllers should seek reassurance that the risks are safely within the range originally contemplated, not on the borderline.
#531 - Right to Object: an Opportunity to Improve?
Originally posted: 29 March 2022 in category
Articles
I was invited to contribute to a seminar on the Right to Object (RtO). Normally this GDPR provision is seen as a way to prevent harm to a particular individual because of their special circumstances. But I wondered whether data controllers could also use the RtO process as an opportunity to review whether their processing can be made safer for everyone.
The diagram shows how this might work. Across the top we have the normal “Accountability” design process whereby a controller identifies the appropriate lawful basis for their processing; applies the relevant tests of benefits, risks and safeguards; and publishes information describing the processing and demonstrating their accountability. Ideally, this should result in processing, safeguards and documentation that makes everyone content.
For the purposes of this talk I’ve divided up the six lawful bases into three groups:
Those (contract, legal obligation, vital interests) that allow processing to be
mandatory
for everyone in a group;
Those (legitimate interest, public interest) that – subject to specific safeguards – allow processing of those who don’t object, in other words where it’s
desirable
to have broad coverage; and
Consent, which only allows processing of those who actively opt in; and, incidentally, lets them change their mind as often as they like.
The Right to Object only applies when using a lawful basis from the “desirable” group. Formally it isn’t an automatic right to opt out: the data controller can continue processing if it can demonstrate “compelling legitimate grounds for the processing which override the interests, rights and freedoms of the data subject” (Art.16(1)). Doing so is likely to further upset the individual, so this is a risky approach compared to treating an Objection as a simple opt-out.
But the important point for this analysis is that the arrival of an Objection indicates that at least one data subject was not reassured by the results of our Accountability process. GDPR requires the data controller to address the concerns of that individual, but it may be possible to get more value from the process by considering the Accountability results more generally. Looking at the stages of the diagram in turn:
It’s possible that an Objection might identify that the wrong lawful basis was chosen, for example if an individual feels they ought to be able to opt-out from processing that we previously identified as mandatory. Changing lawful basis is a significant step – probably involving deleting all data and starting again – so it’s worth quite a lot of effort to get this right first time.
More likely, an Objection may highlight new risks or safeguards that weren’t identified by the original Accountability process. This sort of change is positively encouraged by GDPR, so it’s well worth considering whether risks can be addressed, or safeguards incorporated, in our normal processing.
Or the Objection may show that some aspect of the processing – for example its benefits or safeguards – could be better communicated. Both can be explained through a Legitimate Interests Assessment (LIA) or Data Protection Impact Assessment (DPIA); publishing those documents is a good way to reassure data subjects.
Most data controllers would hope that Objections will be rare if they get their Accountability right. So it’s well worth getting the maximum benefit when they do arrive.
Originally posted: 22 March 2022 in category
Articles
When the Government first announced plans to regulate online discussion platforms I wondered whether small organisations would be able to outsource the compliance burden to a provider better equipped to deliver rapid and effective response. Clause 180(2) of the
Online Safety Bill
suggests the answer is yes:
The provider of a user-to-user service is to be treated as being the entity that has control over who can use the user-to-user part of the service (and that entity alone).
The first thing to note is that this implements the
Impact Assessment
statement (para 67) that any exemption for educational institutions “also includes platforms like intranets and cloud storage systems, but also ‘edtech’ platforms”. Whether the platform is operated in-house or by a third party, the institution is likely to “control who can use” it, so it will be the provider and the platform’s status will reflect that of the institution.
Conversely, if an organisation wants to outsource the compliance duties for a discussion platform, it must outsource “control over who can use” it. The first such platform I came across was Disqus, with three “
login options
” used here to illustrate how responsibility might work:
Universal Disqus: a single user account that works across all Disqus instances, so appears to be controlled by Disqus and make them responsible for Online Safety Bill compliance;
Social Login: including Facebook, Google and Twitter; although it doesn’t manage credentials for these users, or have any control over who they are issued to, Disqus does seem to be able to block trouble-makers, which could be an argument that they “control who can use”;
Single Sign-On (SSO): assuming the individual organisation “controls” who has accounts in its user management system, it seems likely to be the provider of the discussion service for the purpose of the Bill, responsible for any compliance obligations. Note, however, that “Internal Business Services” – an obvious application for SSO – may be covered by the exemption in
Schedule 1 para 7
.
#529 - Online Safety Bill – Educational Institutions
Originally posted: 18 March 2022 in category
Articles
[21/6: Added more examples of public engagement]
[22/3: Updated analysis of why read-only access fits within the para 8 exemption]
The Government has now published its
Online Safety Bill
: the text that will be debated, and no doubt amended, in Parliament. Compared to
last summer’s draft
, this is somewhat clearer on whether platforms operated by educational organisations are within scope. The
Impact Assessment
is clear, according to paragraph 67 the following are excluded from the Bill:
Online services managed by educational institutions, including early years, schools, and further and higher education providers. This includes platforms used by teachers, students, parents and alumni to communicate and collaborate. It also includes platforms like intranets and cloud storage systems, but also “edtech” platforms.
And the text of the draft Bill (unlike last summer) does now match this, mostly. Schedule 1 Part 2 (paras 12-24) has a list of “persons providing education and childcare”: childminding, nursery schools, schools, independent training providers, and further education for persons under 19. This is a welcome clarification over the previous “public authorities”. But Higher Education isn’t there, indeed HE institutions that also provide Further Education are explicitly removed from the exemption.
So HEIs need to look at the exemptions by service type. Here there is another welcome clarification, that Schedule 1 Paragraph 7’s “internal business services … for the purpose of any activities of the business” include “educational institution” (para 7(3) – which
does
include HE) and that authorised persons (allowed to comment without bringing the service into scope) include “in the case of an educational organisation, pupils or students”.
So, as far as I can see, the main situation where an HEI might fall within scope is if it wants to receive and publish comments from those outside the “closed group” of staff, pupils, students (para 7(2)(c)). This might include outreach activities such as festivals of ideas; inviting public comments or responses to research or community activities; supporting professional practice communities (including cross-institution) or user groups.
Here there seem to be three possible approaches, though none is entirely clear:
Create personal accounts for external individuals who wish to make comments thus, perhaps, “authorising” them within the meaning of para 7(3)(iv); this would seem to be the only way to bring in the “parents and alumni” mentioned in the Impact Assessment, so perhaps other interested individuals could be included as well. Para 8 seems to allow content and comments on exempt platforms to be visible to those who aren’t yet “authorised” (adding read-only access to the internal service doesn’t “enable” any new user-generated content, in terms of para 8(1)(b)), so they can decide if they want to request permission; or
Rely on the distinction in Schedule 1 para 4 between comments “relating to provider content”, which keep the service out of scope, and comments (other than likes, emojis & votes) on other people’s comments, which bring it in. As in my
previous post
, turning off threading is the only technical measure I can think of that might possibly support that distinction; or
Combine these two ideas, allow non-registered users to like, vote, or post emojis (definitely OK under Schedule 1 para 4); but only registered ones can add text comments (maybe OK under para 7(3)(iv)).
Comments very welcome if you spot a legal or technical possibility that I’ve missed…
[Script for a presentation at a recent Westminster Education Forum event…]
Back in February 2020 we knew what assessment looked like. Jisc had just published “
The Future of Assessment
”, setting five targets – Authentic, Accessible, Appropriately Automated, Continuous, and Secure – to aim for by 2025. Then COVID made us all look at assessment through a new, and much more urgent, lens
It seems to me there were three responses, invoking different roles for technology
First: technology as
defender
of the existing process. This saw the lockdown requirement for remote assessment as a threat, with technology as the solution. In its most extreme form, this produced e-proctoring: which makes assessment even more stressful, even less Authentic, and even less Accessible for those who don’t have their own private space or technology, or without bandwidth for a live video connection throughout the assessment. These – I hope – are temporary measures…
Then there’s technology as
facilitator
. Can it help us adopt different forms of assessment that address both the problems we knew about in 2020
and
those of the pandemic? Here I’m thinking of things like open book – probably a more Authentic preparation for the workplace – and, if we actually want to test memory, rapid-fire multiple choice. Technology should create opportunities for things like advance downloading and on-device management of resources and timings, so network connectivity is no longer critical; or assessment of multiple-choice responses; or supporting markers by highlighting or grouping desired features in long-form essays; or suggesting when they may be marking inconsistently. Incidentally this takes a very different approach to assessment security: redefining “misconduct” as a feature, rather than a bug. If someone can select appropriate quotes and examples from a whole library, rather than just their memorized notes, or look up multiple choice answers within tight time limits, then they probably know the subject pretty well.
Finally, something to bear in mind as we contemplate a “return to…”. Can technology be an
enabler
for kinds of assessment that are otherwise impractical? Could it give us a better perspective on assessing group work – or at least an early indication of things going wrong – by looking at patterns of communication among the students? Having technology inspect discussion
content
may be too intrusive; or maybe not, if the alternative is accusations of “letting the team down”, breaking personal relationships and individual confidence? Or could we use technology to move from assessment
of
learning, through assessment
for
learning, to assessment
as
learning, where the assessment activities themselves are relevant and productive learning experiences. For example students could learn by providing anonymised feedback – with tutor guidance – on one anothers’ work? These exciting ideas, which are already being tested, were presented at a
EUNIS workshop
in November 2021.
So, will technology be a defender, a facilitator, or an enabler of our post-pandemic assessment system? Could pandemic-enforced changes move us towards better assessments?
Informed by experiences of the pandemic, Jisc has now published
revised principles
. Assessment should:
Help learners understand what
good
looks like;
Support the
personalized
needs of learners;
Foster
active
learning;
Develop
autonomous
learners;
Manage staff and learner
workload
effectively;
Foster a
motivated
learning community;
Promote learner
employability
.
We will need humans and technology to work together to deliver those.
#527 - Voice Processing: opportunities and controls
Originally posted: 25 February 2022 in category
Articles
We’ve been talking to computers for a surprisingly long time. Can you even remember when a phone menu first misunderstand your accent? Obviously there have been visible (and audible) advances in technology since then: voice assistants are increasingly embedded parts of our lives. A
talk by Joseph Turow
to the Privacy and Identity Lab (a group of university researchers in the Netherlands) explored some of the less obvious developments that might be coming; some may even be present already. As well as
what
we say, might voice technology analyse
how
we say it? Could a voice assistant recognise our speech to connect us to our accounts? Could it sense our mood, and suggest appropriate comfort or celebratory food? Could it recognise signs of COVID, or other diseases? Could it recognise angry customers and pass them to an appropriately trained human? Could it detect when we are doubtful about a product, and offer a discount? Or when we are excited, and see an opportunity for upselling? Should it?
Turow’s book is about the advertising industry, but the discussion got me thinking about the tools that might exist to regulate the use of these ideas more generally. Could contraints help us explore what seem acceptable applications and technologies with more confidence that they won’t later slip into unacceptable territory? I’ve come up with four, but there may be more:
Law
: Turow suggests that some applications of voice technology in advertising should simply be banned. This sounds like a strong lever, but competition authorities discovered long ago that if a prohibited technology practice was sufficiently profitable then legal costs and fines would simply be absorbed as a cost of doing business;
Economics
(and, remember, I’m a mathematician, not an economist or marketer): Researching, developing and operating these technologies costs money. There ought to be a limit on advertising budgets: if the profit from selling one more item is less than the cost of the advanced tech required to make the sale, I can’t see the logic in using the technology;
Business
: many of the major players in this space have multiple roles, which may have different business incentives. For example, as browser providers, both Google and Apple are changing their rules on third-party cookies in ways that significantly affect existing ad.tech. solutions. Technology can be a gatekeeper as well as an enabler;
Social
: some technologies simply turn out to be socially unacceptable, for example it appears that when Google realised that Glass users were being treated as outcasts, the consumer product was withdrawn. Here the lack of visibility of what voice processing is actually taking place could cut both ways. If buyers, visitors and employers can’t tell how their voices are actually being processed by a particular device, they may become nervous about a whole class of products, even ones that don’t actually involve the offensive practice;
Following on from this last point, there was a fascinating contribution from a linguist who is researching potential uses of voice processing to help care for people living in their own homes. Sensing, triaging and responding to mood, emotion, even medical conditions might have much greater social benefit in these contexts than for advertising. Unfortunately none of my tools seem to cope well with that level of nuance.
Originally posted: 18 February 2022 in category
Articles
Using and sharing information can create benefits, but can also cause harm. Trust can be an amplifier in both directions: with potential to increase benefit and to increase harm. If your data, purposes and systems are trusted – by individuals, partners and society – then you are likely to be offered more data. By choosing and using that effectively, you build further confidence that your innovations will be safe and beneficial to others. Those who have data that adds further value are likely to see sharing with you as low risk, those who want access to your data and services may consider that sufficiently valuable to commit to enhanced standards of practice. But if you lose trust, then you’ll get less data; any innovations – even uses that aren’t particularly innovative – are likely to be closely scrutinised. Spirals lead both upward and downward.
But we do need to step onto the spiral. Doing the absolute minimum with data might be “safe”, but it also provides the absolute minimum benefit. Gradually, those who do a little bit more will be more effective, provide more benefit and become more trusted. Those who do a lot more may do even better in the short term, of course, but if they go beyond what their trust or capability will bear they will flip to the downward arm of the spiral and rapidly become the partner and service that no one wants to be involved with. Occasional mistakes may be tolerated: an effective response to them may even enhance trust in the medium and long term. But intentional deception, much less so.
Trust is an essential foundation: without it, data will only be shared when there’s a legal obligation. Those who share data must trust one another; they must also work to make sure their community is trusted by those who do not participate but may influence wider sentiment and attitudes. But, according to a study for the Open Data Institute on the
Economic Impact of Trust
, to achieve optimal levels of sharing needs more than just trust. We need to be able to find those with whom trusted sharing would increase value, and to establish permanent infrastructures – in the broad sense: all the way from technical, organisational, legal to cultural – to enable the sharing.
But this move from ad hoc to systematic, even automated, sharing is tricky. Fundamentally, it’s likely to involve moving the basis of what we do from inter-personal trust – which we can all understand, but rarely rationalise – to inter-organisational trust – based on agreed standards, as rational as you need, but always likely to be less intuitive or instinctive. That change has benefits, notably when individuals with strong personal trust networks leave. But unless we take care to show how the new system is even more trustworthy than the old, the transition can be a place where doubts arise.
Externally enforced rules and visible sanctions for breaking them can help here. In an interaction sometimes summarised as “you can drive faster if you have good brakes” strong regulation can actually increase confidence and trust in the regulated. If individuals and groups can see innovation being effectively scrutinised by an independent regulator that champions their rights, they may be more willing to trust the innovators. If they can rely on a regulator correcting – or, if necessary, closing down – an unsafe processing ecosystem, individuals are less likely to worry about, or withdraw, their personal participation. Such a regime benefits regulated organisations both by warning if they approach the downward arm of the trust spiral and by providing more stable public sentiment towards information sharing.
However the UK’s proposals for post-Brexit Data Protection law reform have been criticised as
involving both broader permissions for industry
and
weaker regulation
. The analysis above should explain the apparent paradox that this might reduce the amount of data made available for innovation, rather than increase it.
Many on-line services work with just an account name (often an email address) and don’t need strong, or any, proof of the customer’s actual identity. This is good for satisfying the GDPR’s data minimisation principle, but makes it tricky to deal with individuals who contact you outside those existing channels. If you’ve never previously needed to link the human to the account, is it possible to do so retrospectively, or is the risk of accidental or deliberate misidentification – resulting in personal information being disclosed to the wrong person – just too high?
The
EDPB guidance
(starting on page 23) strongly recommends using existing, established digital channels wherever possible (paragraphs 63&71). To access your personal data, login to your account and view or download it. Alternatively, it may be possible to link the existing account to a new communication channel (never the other way around!), for example sending a one-time access code to mobile phone known to belong to the account-holder (para 66) or requiring someone to demonstrate knowledge of a shared digital secret, such as a previously shared unique cookie, to prove that they are entitled to view the associated data (para 67).
Additional information may sometimes increase confidence that requester is the data subject, but the guidance points out (para 69) that this information must be no more than necessary or proportionate and – less often discussed – that the information requested must actually be useful. The guidance is clear about the common practice of demanding “a national identity document”: first, those are far from secret as hotels, banks and car rental companies routinely request and take copies of them; second that transmitting or storing an image of such a document involves a high risk; and, third, “that identification by means of an identity card does not necessarily help in the online context (e.g. with the use of pseudonyms) if the person concerned cannot contribute any other evidence, e.g. further characteristics matching to the user account” (para 73). A photographic ID card is excellent proof of the legal name of a person standing in front of you: it may be useless when trying to connect one digital persona (for example an email address) to another (for example a user account). Such proof might be useful for high-risk disclosures: the guidance mentions special category data or processing whose disclosure may present a risk to the individual (para 77). But strong security precautions must be implemented: further copying or storage of the image of the document is “likely to amount to an infringement” of both GDPR and national law (para 78) so only a record that “ID document was checked” should be kept.
Finally, and for the first time I’m aware of, the guidance explicitly states in paragraph 68 that in some cases it may be “impossible” – even with additional information – to identify the requester with sufficient confidence to safely release the requested data. Here the data controller may lawfully refuse the request but, if they can, must inform the requester of the “demonstrable impossibility”.
Originally posted: 2 February 2022 in category
Articles
Most of our digital infrastructures rely on automation to function smoothly. Cloud services adjust automatically to changes in demand; firewalls detect when networks are under attack and automatically try to pick out good traffic from bad. Automation adjusts faster and on a broader scale than humans. That has advantages: when Jisc’s CSIRT responded manually to denial of service attacks it took us about thirty minutes – remarkably quick by industry standards – to mitigate the damage, now we often do it before the target site even notices the attack. But automation can also amplify mistakes: years ago I remember working with one site whose anti-virus update deleted chunks of the PC operating system, and another whose firewall had decided that responses to DNS queries were hostile and to be discarded. Automation has power, in both directions!
So it’s interesting to see suggestions that
a future European law on Artificial Intelligence
might be further broadened to classify digital infrastructure operations as a “high risk” use for AI, on a par with industrial and public safety measures. [UPDATE: it’s been pointed out that page 48 of the
UK’s Cyber Security Strategy
also mentions “
Use of AI to secure systems. Many AI algorithms are complex and opaque,
with the potential to introduce new classes of vulnerability. Understanding and
mitigating these emerging threats is a priority”].
That definitely doesn’t mean AI is banned, but that its power is expected to be wrapped in a lot of human thought. Leaving an AI to just get on with it isn’t appropriate. But nor should a human be approving every decision: that throws away much of automation’s potential benefit.
Instead the model (in Articles 9-20 & 29 of the original
Commission draft
) seems to require a close and continuing partnership between human and AI capabilities. Humans must design appropriate contexts and limits within which AI can work, taking account of both the risks of too much automation and too little; inputs and training data must be appropriately chosen and updated; there must be documentation of how the system was intended to behave, and how it actually did; live information, monitoring, authority and fallback plans must enable humans to take over quickly and effectively when the AI is no longer behaving appropriately. There are repeated reminders that systems may be working in actively hostile environments. As with my old DNS example, attackers may try to deceive or confuse the AI and turn its power to their advantage. Humans will definitely be needed to identify these possibilities, design precautions against them, and respond when the AI is recruited to the dark side. Providing excellent digital infrastructures will need both excellent AI and excellent people, working together.
Originally posted: 24 January 2022 in category
Articles
I’ve been reading about
Slow Computing
and the need for ‘digital forgetting’. But, unlike the GDPR Right to Erasure, human forgetting isn’t clean: more often involving uncertainty rather than simple elimination. That leaves our database in a different state: whereas digital erasure has no effect on the records that remain, much of our human memory is still present but of uncertain quality. We don’t know which of those memories are accurate, so should be wary of placing too much reliance on them.
So what would happen if there were a Right to Data Decay? We might imagine databases inhabited by
chaos monkeys
that randomly alter a small percentage of field values each time they ran. To mimic human forgetting, the likelihood of alteration could relate to the age of the record or the length of time since it was last used. Over time, old or unused records would become increasingly unreliable, and relying on them increasingly hazardous. Provided the database holder bears the cost of that unreliability, they might well be motivated to introduce more frequent re-validation processes and/or to simply dispose of data once it approached the age of unreliability.
Those seem like incentives that benefit both the data controller and the data subjects. So do we need such a right? Probably not, once you realise that the real world already develops in ways that make data go out of date. The university still sending glossy alumni brochures to the person who sold our house a decade ago is wasting money through not recognising that; the online book-seller still recommending children’s books for relatives who are now grown up is devaluing its other recommendations to me and, presumably, “people like me” too; data science models that incorporate too-old data may well lose accuracy, especially where the purpose of the model is to change the reality that it reflects.
Recognise data decay, save money, improve services!
#522 - Entangled personal data: what if it’s not only mine?
Originally posted: 17 January 2022 in category
Articles
Feedback and performance review are routine parts of many employment relationships. So it’s surprising to find that they take us into obscure corners of data protection law. Regulators have been clear for more than a decade that
an opinion about someone is personal data
, but there has been much less exploration of the fact that it’s likely to be information about
two
people – the one who is the subject of the opinion and the opinion holder. And – arguably unlike the situation of social network “friends” – those two people have very different relationships to the same data: for one it may be no more than an impression, for the other it may have significant financial or reputational impact. Any processing of that data must deal with two sets of rights and responsibilities, which are inextricably entangled.
Entangled data present an immediate challenge to the normal triad of data protection safeguards: information, individual rights, and data controller accountability. GDPR Article 13 offers the data subject information and individual rights at the point where data are collected or observed. But the subject of an opinion isn’t involved in the collection of their personal data, so processes that assume the data subject is present won’t work. This makes the data controller’s exercise of accountability (for example ensuring compliance with the Article 5 Principles and an Article 6/9 legal basis) even more important.
Uncertain data protection requirements may matter less for traditional human feedback and review processes, which are also covered by a great deal of good practice guidance (e.g. from the
Chartered Institute for Personnel and Development
) and, ultimately, employment law. However a new trend for using data, rather than human sources, to generate “opinions” may require new thinking. For example, would it be acceptable to use student sentiment, attendance or performance data as part of staff reviews? It’s worth reviewing which GDPR sections might help us think about situations where the same personal data relates to two different people. Although the following uses review/feedback for illustration, the aim is to sketch a possible approach to entangled data in general.
The Article 5
Principles and Accountability
are always a good starting point. The Art.5(1)(b) requirement for purposes to be explicit means those who provide information must know who else it may be linked to and, because Art.5(1)(a) requires fairness to both, that knowledge must not distort the providers’ own behaviour or relationship with the processes through which data are collected. This links to Art.5(1)(c): if introducing a second purpose affects the quality or meaning of the data, then it is doubtful whether it will still be “adequate and relevant” for either purpose. The Art.5(1)(d) requirement that data be “accurate” highlights a specific challenge for entangled data: what if an opinion is accurate in the holder’s mind but not the subject’s? Do the two sides (and processes) share, or need, the same definition of “accurate”? Some of the less familiar Individual Rights may help to resolve these situations, as discussed below.
Article 5(1)(a) requires that every action to process data must be covered by one of the Article 6
lawful bases
. Where the same personal data relates to two different people those bases don’t have to be the same but, if they are not, then particular care will be needed to ensure that the right conditions and safeguards apply to all the relevant processing. For example, Jisc’s standard model for analytics uses the Legitimate Interests of the institution for finding patterns in observed behaviour. Those interests must not (by Art.6(1)(f)) be over-ridden by the “interests, fundamental rights and freedoms of the data subject”: where there are multiple data subjects, this means that every one’s interests, rights and freedoms (not just to privacy) must be considered. By contrast, using data for performance review is most likely to be justified as “necessary for the performance of [the employment] contract” (Art.6(1)(b)), which involves a different set of data protection and employment law safeguards.
If different lawful bases apply to the different data subjects, it’s likely that their processing will be for different purposes. Art.5(1)(b) permits multiple purposes, so long as they are “compatible”. Incompatible purposes can only be added with consent: a problem for entangled data because – even if their contexts permit valid consent – it must be obtained from both data subjects. Although Article 6(4) is most often used to assess compatibility when different purposes affect the
same
data subject, its factors for
Purpose Compatibility
should also be useful in assessing which data and purposes are compatible across
different
groups of data subjects. Highlighting links between processes, context of collection, nature of data, possible consequences, and safeguards suggests that compatibility is most likely when the two groups have a similar relationship with the data, and when the processing has similar levels of impact on both. Using data collected in an informal context from one group to influence formal consequences for the other is unlikely to be compatible. We should also beware of situations where the meaning and significance of the information change significantly when viewed from the two sides.
As mentioned above, the normal
Individual Rights
safeguards of information (Art.13) and subject access (Art.15) are less effective when the same personal data relates to multiple data subjects. Information cannot be provided at the point of collection if a data subject is not present; subject access rights of one data subject may need to be limited to protect the privacy and rights of the others (Art.15(4)). It may be more appropriate to use Article 14’s “Information to be provided when personal data have not been obtained from the data subject”, but Art.14(2)(f) highlights that disclosing “from which source the personal data originate” may, again, breach the privacy of the individual source. Normally these information and access rights combine to help data subjects, controllers and sources identify inaccurate data and correct it. If necessary, Article 16 gives the data subject a legal Right to Rectification. However, where entangled privacy rights and disputes about the meaning of “accurate” hinder this approach, it may be better to combine the Right of Rectification with the Article 18 Right to Restriction. Such a process would let a data subject contest the accuracy of personal data and exclude it from further processing until/unless its meaning can be agreed.
This review suggests that data protection law can guide appropriate use of multi-party entangled personal data, but that this may involve considering some less familiar sections and perspectives.
Originally posted: 12 January 2022 in category
Articles
Under the GDPR’s breach notification rules, it’s essential to be able to quickly assess the level of risk that a security breach presents to individual data subjects. Any breach that is likely to result in a risk to the rights and freedoms of natural persons must be reported to the relevant data protection authority, with at least initial notification within 72 hours. Where the risk is high, affected individuals must also be notified. Where there is unlikely to be a risk, only internal documentation is required. The Article 29 Working Party published
general guidance on breach notification
in 2017, which was subsequently adopted by the European Data Protection Board. However the EDPB has now published a supplement,
specifically on the question of assessing risk
.
This takes the very helpful approach of looking at clusters of similar breaches, and explaining the factors and differences that may lead to different risk assessments. Clusters cover ransomware, data exfiltration, internal human risk (both deliberate and accidental), lost/stolen devices/documents, postal errors; finishing with a couple of examples of social engineering. In many cases the guidance suggests appropriate mitigation measures, as well as what notifications are required.
This guidance should be helpful in reducing the amount of thinking required in the immediate stressful aftermath of detecting a security breach. Check if your incident matches one of these patterns and follow the relevant instructions for initial notification (Note that the earlier guidance explicitly allows update notifications, whether to provide more information, revise the risk assessment, or even declare a false alarm).
Even better if you can use it to
review your systems and datasets
before
any breach occurs
, when you can take time to assess the likely risk that would be created by a future confidentiality, integrity or availability breach. With that kind of specific preparation, a quick check of whether the actual breach was significantly different to the anticipated one should be all you need before initiating the relevant notification and response processes.
Originally posted: 10 January 2022 in category
Articles
More than a decade ago, European data protection regulators identified the problem of “consent fatigue”, where website users were overwhelmed with multiple requests to give consent for processing of their personal data. In theory, responding to those requests let individuals exercise control but, in practice, it seemed more likely that they were just clicking whatever was needed to get the content they wanted.
Thus the
latest enforcement action by the French regulator
against concerns the widespread practice of offering a choice between “accept” and “configure”: the latter typically leading to pages of detailed settings that the user must refuse individually. The Regulator’s conclusion that “it is not as easy to refuse cookies as to accept them” – as required by GDPR Art.7(3) – is hardly surprising. But given
earlier enforcement actions
demanding that data controllers give more detail and granularity, providers might be tempted to think “you asked for it, you got it”. As with previous enforcement, the result seems more likely to be an adjustment of practice towards the regulator’s rulings, rather than a major change of approach.
Ironically, the opportunity for that change may now come from the technical side, where browser creators (including Google) are proposing new technologies for Internet advertising that may not obviously relate to existing legal provisions and rulings. The Information Commissioner has responded with a set of
privacy expectations for such developments
: these still call for “User Choice”, but alongside “Data Protection by Design”, “Accountability”, “Purpose”, and “Reducing Harm”. Whether this will result in a new approach, or just a new front in the battle of formalities, we will have to wait and see.
Originally posted: 5 January 2022 in category
Articles
Terminology matters. OK, you’d expect me to say that, as a sometime mathematician, engineer and lawyer. But the importance to all of us is highlighted by a confusing tangle of terminology that has grown out of Ann Cavoukian’s original idea of “
Privacy by Design
”.
That phrase was introduced in 1995 – just too late to make it into the European Data Protection Directive – but was taken up by many Regulators as a requirement that “
has always been an implicit requirement of data protection
”, according to the UK Information Commissioner. While the general idea seems good the phrase itself is open to criticism, notably from engineers required to actually turn it into code: that lawyers and philosophers have been arguing about the meaning of “privacy” for at least a couple of millennia, making it tricky to understand what the design requirement actually is.
In 2016, the drafters of the General Data Protection Regulation avoided the phrase and, instead, created an obligation of “Data Protection by Design” (DPbD) in Article 25(1). According to the European Commission that requires “
implement[ing] technical and organisational measures, at the earliest stages of the design of the processing operations, in such a way that safeguards … data protection principles right from the start
”. So far, so good: the GDPR does define “data protection principles” (in Article 5) and most of them have reasonably obvious translations to technical requirements. Unfortunately, this change was made so late in the process that many privacy regulators simply retitled their existing “Privacy by Design” documentation, making it unclear whether Data Protection by Design is actually a new, clear, requirement, or just a rebrand of the old, unclear, one. For example the European Data Protection Supervisor’s
Preliminary Opinion on
Privacy
by Design
describes itself as “contributing to the successful impact of the new obligation of ‘
data protection
by design and by default’ as set forth by Article 25 of the General Data Protection Regulation”.
If that wasn’t enough, Article 25(2) added a third phrase and requirement: “data protection by default”, defined as “by default, only personal data which are necessary for each specific purpose of the processing are processed”. And, perhaps inevitably, the set was soon completed by authors referring to this as “privacy by default”.
So does it matter that we have “Privacy by Design”, “Privacy by Default”, “Data Protection by Design” and “Data Protection by Default”, all used pretty much interchangeably? I think it does:
“Privacy by Design” is a good slogan and provided valuable direction for twenty years. But it now seems to be cited – worryingly often – as “unclear, so whatever I have done must be OK”. As a privacy-sensitive individual, and engineer trying to do the right thing, that’s a distraction I’d rather not have floating around;
“
Data Protection by Design
” is, I think, much to be preferred. As in my new paper “
Thinking with GDPR
” it contains about a dozen specific obligations (the Principles, the Individual Rights, and the obligations of whichever Lawful Basis is chosen), most of which translate into clear engineering requirements;
“Data Protection by Default”, even though it’s the phrase chosen by the GDPR, I find, frankly, scary. A default is something each individual can choose to turn off. Again, there are already too many claims that user behaviour can “opt out” of data protection, for example by publishing personal data (“it’s on the web, so I can use it how I like”) or, more often implicitly, by “consent”. Our terminology shouldn’t be giving support to such ideas;
“
Privacy by Default
” – ironically, the phrase that doesn’t actually have official blessing – I find a much more helpful engineering requirement. Indeed looking at the explanation in Article 25(2) it seems a much more accurate description of what’s required: wherever we offer individuals a choice, the do-nothing option should be the one that provides the best privacy protection. That doesn’t require a philosophical debate about the global meaning of “privacy”, just that for each decision we must be able to locate the options on a linear scale. If we can’t do that, maybe the choice isn’t one that can be communicated in a “concise, transparent, intelligible and easily accessible form, using clear and plain language” (Article 12(1)), and we should do more work on our Data Protection by Design to come up with choice(s) that can.
So: four phrases, two of which positively support engineering that respects personal data, one of which obscures that goal, and one that actively undermines it. I think the choice does matter…
#518 - Thinking with GDPR: Design by Data Protection
Originally posted: 4 January 2022 in category
Publications
Last year, I was invited to give a talk “on GDPR” to
NISO
, an organisation that develops standards for managing digital information. While most of my thinking and writing has looked at applying data protection law to existing systems, this seemed like a good opportunity to think about how you might use it at an earlier stage, when designing a protocol, system or software. Flipping the usual phrase, rather than “data protection by design”, can we do “design by data protection”?
The resulting ten-minute
talk
got a good response from both the conference audience and organisers; and an offer to publish a paper if I would like to write an expanded version of the ideas. The result – “
Thinking with GDPR: A guide to better system design
” – has now been published.
It starts by pointing out three common, but false, assumptions about the law: that it’s about preventing processing of personal data, that it’s most relevant to individuals, and that it’s mainly about consent. Then moves on to how organisations can use the law – in particular the Principles, Lawful Bases and Individual Rights – to design their systems, demonstrate accountability in their approach to personal data, and build trust. Then gives three practical examples – student voter registration, federated access management, and data analytics – of how Jisc and the wider research network community are using the approach to design and develop systems that are innovative and world-leading both in the functions they provide and in their built-in respect for personal data.
#517 - Attackers, CSIRTs and Individual Rights: Clarified
Originally posted: 22 December 2021 in category
Articles
A few years ago I wrote a post on how the GDPR copes with situations when there was a conflict between the obligation to prevent, detect and investigate incidents and the obligation to inform all those whose personal data you process. Do you, for example,
need to inform someone who is attacking your systems
that their hostile activity has been detected?
GDPR Article 14(5) provides a general tool for resolving that conflict: you don’t need to inform if doing so “is likely to render impossible or seriously impair the achievement of the objectives of that processing”. Telling an attacker what attacks you can detect would clearly “seriously impair” our ability to protect systems and data.
A new
Commission Decision
provides a longer (but still not exhaustive) list of situations when such conflicts might arise: when complying with the exercise of individual data protection rights “would undermine the purpose of providing IT security operations and services, inter alia, by revealing the Commission’s investigative tools, vulnerabilities and methods, or would adversely affect the rights and freedoms and the security of other data subjects”:
communicate alerts and warnings relating to IT security events and incidents;
respond to and contain IT security events and incidents;
facilitate tools and operations through security audits, security assessments and vulnerability management;
increase the awareness … in the field of cybersecurity;
monitor, detect and prevent the occurrence of IT security events and incidents;
review privileged user accounts (Article 2(2)).
Formally, this Decision and its list only apply to the security and incident response activities of the European Commission itself. But it’s still a helpful indication to other CSIRTs – and to regulators – that the importance of these activities for protecting personal data may make it necessary to apply the more general exemptions (such as Article 14(5)) provided in the GDPR.
Originally posted: 17 December 2021 in category
Articles
Over the past decade or more, we’ve developed
federated access management
as a technical, policy and legal framework to exchange up-to-date information to help current staff and students access the resources they need. Authentication, status and membership information all need to be fresh to be useful and frequent use makes it worth organisations entering into formal federation agreements to ensure that.
But there’s another kind of educational information that’s far longer-lived. Degree certificates are still relevant forty years on; transcripts of course content at least a year or two. These are used much less often, but with a much wider range of organisations. Various technologies have been proposed to store and process these in digital form. So what might their legal and organisational framework look like? Existing processes around paper degree certificates provide an interesting angle.
Issue:
Institution creates certificate and provides it to graduate. Certificate has various mechanisms to enable validation (often a university crest) and to help detect forgeries.
Graduate stores certificate in a safe place.
Presentation (perhaps many years later):
Graduate presents certificate to potential employer as proof of qualification; employer’s grounds for requesting that personal data will usually be that it is “necessary to take steps prior to entering into a contract” (GDPR Art 6(1)(b)).
Assessment. Employer does one or more of the following, to obtain the verified information they need:
Checks that certificate is not an obvious
forgery
. This uses characteristics of the certificate plus generic information (for example whether the institution used that title at that date). There is no processing or transfer of personal data.
Checks that the qualification is
relevant
to the job applied for. Again, this uses only information on the certificate, any processing personal data should be limited to matching the qualification details against the requirements of the specific job.
(optional)
Verifies
with the issuing institution that the information in the certificate is still valid. This does involve a new processing of personal data, by both the employer and the institution: typically the graduate is asked to consent (GDPR Art.6(1)(a)) to this one-off transfer in their application (“you agree that we may check your qualifications with your university”).
(optional)
Requests
additional information – topics covered in the course, relevant skills demonstrated, etc. – from the issuing institution. Again, this is a new processing activity based on a one-off consent.
All these steps, except one, either do not involve processing of personal data or have an obvious GDPR provision. So what part of GDPR best fits the first step – the creation and issuing of the certificate?
Consent seems to work at a high level, but thinking of it as “data subject requests copy of own personal data” makes either the Article 15 Subject Access Request (SAR) or the Article 20 Right to Portability (RtP) a much more precise fit. The right to portability would be best of all – the intention here is, precisely, that the data subject will subsequently “port” the information on their certificate to another data controller – however this formally only covers information the student has provided to the institution. We therefore need to fall back on the more general Article 15 right of any data subject to “obtain … access to data” that is being processed by the controller. In practice, many regulators seem to have treated the Article 20 right as a formatted SAR anyway, and Article 15(3) already requires “provided in a commonly used electronic form”.
So a possible framework for long-lived digital credentials might look like:
Process 1 (“Issue” above): user requests a digital copy of their qualification: institution provides the data in standard electronic form (e.g. a
W3C verifiable credential
) as an Article 15(3) Subject Access Request.
Process 2 (“Presentation” above): applicant presents qualification data as part of an application, most likely requested as Article 6(1)(b) necessary for contract.
Process 3a (“Forgery” and “Relevance” above): recipient checks that the offered data is not obviously forged (e.g. that its
digital signature is valid
), and is relevant to the role applied for. This may, particularly with a formatted credential whose validity can be checked separately to its content, involve no processing of personal data; or the processing may be necessary for contract or consented.
Process 3b (“Verification” and “Request” above): recipient may ask the issuing institution to either confirm or supplement the information contained within the certificate. To authorise this one-off transaction the recipient should obtain a recent, specific, consent from the applicant. The institution has a free choice how to respond: for paper certificates, consent is routinely received as a photocopy of a tick on a form, but the digital world may offer more robust processes to check and confirm (for example verified credentials can include
expiry dates
, when either the holder or issuer must refresh the information and its signature).
This framework, which treats Issue, Presentation and Assessment as individual, free-standing, transactions, is very different to the federated access management model’s ongoing exchange of data backed by a long-term contractual relationship (the “Federation Agreement”, for example for the
UK Access Management Federation
). That provides safeguards such that we can take the individual’s requests to access content and services as implicitly directing the necessary release and processing of real-time information, it being in the
legitimate interests
of institution and service provider to facilitate access to services desired by their members. Requiring explicit consent for each transmission of information would be impossibly onerous for all parties.
However in the qualification context, information flows are much rarer and sparser, occurring between a much wider range of parties. Requiring a pre-existing contract is therefore too heavyweight, and a framework where the individual explicitly requests each transaction is both more appropriate and a much more natural fit for the actual data flows. In both frameworks, the responsibilities of each party (and their limits) are clear and appropriate to the context.
Finally, there is a natural transition between the two models. Where an institution and an employer have a particularly close relationship (for example through student placements) they may well want to enter into a contract to cover that relationship. Such a contract could naturally include moving to the “federated” model with its stronger guarantees of fresh data and safeguards agreed once, by contract, rather than on every individual transaction, by consent.
Originally posted: 19 November 2021 in category
Articles
A colleague spotted an article suggesting, among other things, that
Virtual Reality could provide a safe space for students to practice their soft skills
. This can, of course, be done by classroom roleplay but the possibility of making mistakes that fellow students will remember could well increase stress. This certainly chimes with feedback I received when suggesting that my team practised giving presentations in what seemed to me the “safe” environment of a company lunchtime chat: “no, we’d far rather have an audience of complete strangers”.
So what about an audience of avatars, whose memories can be wiped at the end of the session? The article suggests that AI can provide feedback on tone, body-language and eye-contact; even that the session could be replayed with the student taking another role and watching an avatar act out their behaviour.
But this gets ethically interesting. This sort of recording and feedback involves what would normally be considered “high-risk” uses of AI, particularly processing of faces and emotions. Conventional wisdom says that if that is to be done at all then there must be a lot of human oversight and involvement. But providing that involvement seems to break the private safe space, which was why we used VR in the first place. I was reminded of school language labs, where it was just me and the non-judgemental tape reels… Until the teacher’s voice suddenly burst in to my headset…
Giving the student the option to invite another human to view the recording seems fine: “I don’t understand the AI’s comments, please help”. But should the teacher listen in? Or intervene? What happens if the student starts to interact in ways that could harm themselves or others? There are also fascinating articles on how
our interactions with devices can quickly become uncivil
, because “it’s only a robot”. Can the VR system recognise those situations and, if so, what should it do?
Should “What happens in VR, stay in VR”? I don’t know…
Originally posted: 18 November 2021 in category
Articles
Recently I was in a video-conference where Apple’s “smart” assistant kept popping up on the presenter’s shared screen. Another delegate realised this happened whenever the word “theory” was spoken. It’s close…
These events – which I refer to as “false-wakes” – are privacy risk: maybe small, but that depends very much on the nature of the conversations that are going on around them. So it would be good if privacy law helped suppliers to reduce them.
However the recent
guidance from European privacy regulators
seems to have the opposite effect. They treat each “wake-word” as granting consent for the subsequent processing, which means that even detecting a false-wake involves unlawful processing, as it turns out (in retrospect) that the speaker had no intention of granting consent, so there was no lawful basis for the processing. And it makes it impossible to use the recorded data to tune the system to reduce future false-wakes, because the only possible response to not having a lawful basis is to delete the data immediately (and probably silently, to avoid admitting the law-breaking). So a position has been created where the Lawfulness Principle is actively discouraging compliance with the Accuracy one. Having written about
using GDPR as a design tool
, I wondered whether I could do better. Is there a way:
To avoid having to tolerate unlawful processing (even if time-limited);
To provide a mechanism whereby speakers can let their recordings be used to improve accuracy; and, incidentally
At least partially, to address the EDPB’s overall concerns about the invisibility of voice-triggered devices?
On closer reading, there’s only one lawful basis that can possibly cover a false-wake spoken by someone who hasn’t previously interacted with the device. Consent or contract might work for the person who installed the system, someone who has enrolled in its voice recognition process, or who intended to issue a command. But those require the speaker (as “data subject”) to have done, known or intended something. For accidental processing, perhaps of a visitor’s voice, the only possible lawful basis is “legitimate interest”.
That immediately triggers the notice obligation in Article 13, to provide information “at the time when personal data are obtained”. That probably shouldn’t mean reading out a complete privacy notice (unlikely to meet the requirement for intelligibility), but the device should draw attention to itself and where that information can be found. Suggestions for the latter have included
QR codes or other layered notices
.
To meet the storage limitation principle, and give some chance of satisfying the legitimate interests rights-balancing test, the legitimate interest in listening for a wake-word should terminate as soon as possible. However that might still leave enough time for the system to offer the speaker the choice of whether a short sound recording may be used for the new purpose of reducing the likelihood of future false-wakes. That is probably best offered as an opt-in consent dialogue (“Sorry, you woke me by mistake, may I process a five-second recording to work out why?”), where anything other than a clearly-spoken “yes” results in the recording being deleted. A further refinement might be to play the recording, so the speaker knows what will be shared.
So, yes, all three objectives can be achieved. Just pick the right legal basis, and the rest follows 🙂
Originally posted: 17 November 2021 in category
Publications
We can probably agree that “Ethical Artificial Intelligence” is a desirable goal. But getting there can involve daunting leaps over unfamiliar terrain. What do principles like “beneficence” and “non-maleficence” mean in practice? Indeed, what is, and is not, AI?
Working with the
British and Irish Law, Education and Technology Association (BILETA)
, Jisc’s
National Centre for AI
has mapped an alternative route, taking smaller steps through more familiar ground, towards that goal. This involves two key insights. First, that the intuitions and practice of the broad education community will usually guide us towards responsible and ethical actions and away from unethical ones. And, second, that discussing more familiar questions can help us discover those intuitions and practices.
Or, to put it another way, unethical actions are usually bad for other reasons, too.
Our “
Pathway Towards Responsible, Ethical AI
” considers four key questions for any proposal that relies on data or algorithms; suggests groups – including students, tutors, minorities, and boards – with whom they can most usefully be discussed; and links to resources that can provide a framework for those discussions:
“Does this proposal fit our institution’s objectives?” clarifies what we are trying to achieve and why; whether it is likely to work; and how it relates to the institution’s mission;
“Does using AI fit our institution’s culture?” considers how policy-makers have viewed similar uses of algorithms and data; their compatibility with our local culture; and whether they are likely to be welcomed or resisted;
“Are we ready?” looks at both institutional readiness – in terms of skills, systems, data and trust – and whether suppliers can provide services appropriate to that level of readiness;
“Does AI raise specific issues?” considers what the application and context require – in terms of control, explanation, bias and learning – from any technology that may be used.
Finally, for ideas that make it this far, the Pathway reviews how tools from law, technology and ethics can support a successful deployment. It’s only this stage that requires specialist knowledge: the four questions are much more about human and institutional experience.
Originally posted: 8 November 2021 in category
Articles
[Update (Nov’21): I’ve discovered that
Patrick Breyer MEP
has published a “
parallel text
” of the three current proposals (Commission, Parliament and Council). Not exactly easy reading, but it makes it much easier to see where they are similar, and where there remain significant differences]
One area where there does seem to be agreement is the use of data about communications (and in some cases their content) to protect the security of networks, systems and end-users. Whereas the Commission draft only covered the security of networks, the Parliament’s Amendment 15 copied the text of Recital 49 from the GDPR into Recital 16, recognising the need to protect both the security of networks and of connected devices, and the range of organisations involved. Article 6(1)(b) was amended (Amend.72) to explicitly add “availability, integrity, confidentiality” of networks to the “security” permission, and Article 8(1)(da) added (Amend.90) to permit patches to protect the “security, confidentiality, integrity availability and authenticity of … terminal equipment”. The Council add more threats to the list of examples in Recital 16 – viruses, phishing and spam (as a threat to availability) – and explicitly link security measures to the prevention of personal data breaches. Processing of metadata and content to “detect or prevent security risks or attacks on end-users’ terminal equipment” is added to Art. 6(1)(c) and use of end-device capabilities to Art. 8(1)(da). They also recognise the need for security patches in Recital 21b and Article 8(1)(e).
Much less clear is what will be agreed on processing for other purposes. The Parliament retained the Commission’s closed list of purposes: transmission and security; quality of service, billing, and fraud prevention (these three only being allowed to use traffic data, not content); and where the user has requested a specific service and granted consent to the processing it requires. Where possible, the Parliament tightened these permissions, notably by the requirement in Art 6(2a) (Amend.77) that processing likely to result in a high risk to the rights and freedoms of individuals must be subject to a Data Protection Impact Assessment. The Council, however, has extended the Commission’s list, to include “compatible purpose” processing of both network and terminal information (Rec.17aa/20aa & Art.6c/8(g)), protecting “an interest which is essential for the life” of the user (Rec.17a & Art.6b(1)(d)), and scientific research (Rec.17b & Art.6b(1)(e)&(f)) (Parliament also mention scientific use, but only in relation to analytics: Amend 89).
On cookies and other use of end-device capabilities, the permissions for those necessary to transmit a communication (e.g. load balancers) or to provide a service requested by the user (e.g. shopping carts) are largely
carried over from the existing Directive
; there is also general agreement – though variation in detail – on a point first raised by the Article 29 Working Party in 2013 (!), that at least some analytics cookies should be permitted without prior consent (Art 8(1)(d) Amend 89). Otherwise the Parliament and Council positions are very different. Parliament insist on prior consent for all other use of end-device capabilities and (Amend 92) that refusal to give such consent must not result in the user being denied access to any service or function (often referred to as “cookie walls”). Council Recital 20aaaa, however, allows cookie walls so long as the user has a choice between free and (implicitly) pay-for versions of the service. This does not apply where this would “deprive the end-user of a genuine choice”, for example websites operated by public authorities or dominant service providers. But Recital 21aa suggests that some ad-funded services (online newspapers are given as one example) may not need to offer a choice.
These are the main areas I’ve been keeping an eye on, but there are also significant divergences between the Council and Parliament elsewhere. Resolving those seems unlikely to be quick.
Originally posted: 29 October 2021 in category
Articles
Something made me uneasy when a colleague recently referred to “AI bias”. I think that’s because it doesn’t mention the actual source of such bias: humans! AI may expand and expose that bias, but it can’t do that unless we give it the seed. That’s rarely deliberate: we might treat it as a result of “how the world is”. But maybe we should be using “AI bias” less as an unconscious excuse and more as a sign that something about that world is wrong, and needs fixing?
Some alternative terms I find useful when thinking about that:
Learned bias
: even if we could provide AI with a perfect view of the human world, that world contains biases. And the way we choose what view to give the AI may introduce more. A good example of this is the “gendered pronoun” issue: AI that is given a corpus of human text to read will encounter the phrases “she is a CEO”/”he is a nurse” less often than their gender-flipped counterparts. So when translating from one of the many languages that doesn’t have gendered pronouns – such as
Turkish
, Finnish or
Persian
– an AI is likely to pick the more common version. Heroic
efforts
are being made to detect and fix this issue in translation sources and algorithms. But it would be good to try to work on the underlying issue, too.
Blind-spot bias
: AI feeds on the data we give it, but what about the data we can’t give it, because we don’t have it? Are the white spaces on our maps of city air quality because there is no pollution, or because there are fewer smartphone owners there to report it? We need to learn from
Abraham Wald’s
“returning bombers” paradox and investigate those blind-spots at least as intensely as the data-rich ones. The blind-spot may, itself, be telling us something important.
Digital confirmation bias: a stronger subset of blind-spot bias occurs when our use of the AI’s predictions creates a positive feedback loop and increases the disparity between data-rich and data-poor areas.
Sending more police into areas where there are more reports of crime
is the classic example.
Design bias
: sometimes bias doesn’t come from the data, it comes from oversights or assumptions during the design of the AI or its surrounding processes. We need to try to detect and question these. Do all students
actually have a smartphone
? Are skin-tones generally
lighter than the background
? I know it’s much easier for me to remember that about 1 in 20 people don’t have
“normal” colour vision
: those who do can try to keep us in mind, but making your design team as diverse as possible can reduce the amount of “others’ shoes” effort that’s needed.
Incentive bias
: it’s all too easy for a “goal” to slip into “bias”. Social media analysts noticed a long time ago that the goal of “increase attention” was closely linked to the bias that will “
increase outrage
”. Hence the algorithms that curate for the former are likely to promote extreme expressions and views. It’s not yet clear whether a different definition of “attention” can fix this problem, or whether the AI will always (re-)discover the human weakness for strong emotions. Perhaps in these stressful times there might be a market for a social media platform that delivered attention through calming, mindful moments? I’d certainly be willing to give it a try.
The economic and societal benefits of this digital growth are only possible through earning and maintaining people’s trust and their willing participation in how their data is used. Data-driven innovations rely on people being willing to share their data.
Others have suggested a safety analogy:
Good brakes let you drive faster
That has certainly been our experience at Jisc. We’ve been developing, using and publishing GDPR tools as part of our innovation in use of data since before the GDPR was passed! Not because it’s a legal requirement (which is often arguable) but because it’s a really good way to think through issues and explore concerns with customers and users of our services. And, because we’ve done that thinking and exploration, those stakeholders seem inclined – when we come up with a new idea – to approach it with confidence. They may want to point out issues we haven’t thought of, which is great as we can work together to improve, but we rarely get a reaction of pure suspicion.
When I first suggested using a DPIA to
explore and explain our network security services
, it felt like radical transparency. Now it seems much more like common sense. You can find the tools we’ve developed along the way at:
Originally posted: 11 October 2021 in category
Articles
I keep coming back to the idea that Data Protection law (at least as expressed in the GDPR) has
two
explicit objectives: to “protect natural persons” and to enable “free movement of data”. And those are presented as compatible, not conflicting. In the case of a couple of the Article 6 lawful bases for processing that’s fairly obvious: if I enter into a contract with you then I want you to process the data that’s necessary to deliver that contract; if a life is at risk then society wants the processing of data that’s necessary to save it.
But can we view the other lawful bases, with their associated conditions and safeguards, as guides to finding similar sweet spots? If you want to do this kind of thing, under these conditions and with these safeguards can we (either as individuals whose data are processed, or as members of society whose data might be processed in future if we experience particular situations) reach consensus that the processing benefits both?
If all the conditions of the other four bases are genuinely met – notably fully-informed free consent, laws (whether permissive or mandatory) that include appropriate safeguards, other interests that are both legitimate and not overridden by rights and freedoms – then it seems plausible.
And this is increasingly important, because these win-win situations are stable. Alternatives, where one party wins at the expense of the other, probably aren’t. There are an increasing number of options for those who want to resist, frustrate or corrupt the processing of their data. Long ago I got fed up waiting for a consensus resolution to the targeted advertising debate, so I adjusted my browsers and behaviour to exclude that ecosystem as far as I could. That does make some websites practically unusable, and every now and then a volunteer site reminds me that I am a lousy freeloader depriving them of income.
But that’s the point: the alternative to win-win is lose-lose, where both personal protection and data availability are diminished. If we can use data protection law as a guide to how to avoid those conflicts, it has to be a good thing.
Originally posted: 23 September 2021 in category
Articles
“Consent” is a word with many meanings. In data protection it’s something like “a signal that an individual agrees to data being used”. But in political theory “consent to be governed” is something very different. A panel at the
PrivSec Global conference
suggested that the latter – also referred to as the “social contract” – might be an interesting lens through which to consider the use of data, algorithms and Artificial Intelligence. The basic idea is that creating a society involves a balance: we give up some individual freedoms (for example to choose which side, and how fast, to drive on the roads; or to take whatever property we choose) in order to create a communal life that works for everyone.
So how does that help in discussing new technology? How can we create technologies that enhance humanity rather than exploiting our weaknesses? First is the idea that a valid social contract must include everyone, it can’t be imposed by those with (current) political, technological or economic power. All views, impacts and situations need to be considered and weighed. Which means we need to make that discussion accessible, particularly to children and the (digitally) vulnerable. That may actually be easier if we debate principles, rather than technological details: “it’s too complicated” and unquestioned following of algorithmic outputs are signs that we’re getting the debate wrong. Complication, algorithms/goals and data sources are choices made by humans: we need to discuss whether and when it’s acceptable to make those choices. Above all, principles (and systems) must be designed for the vulnerable and, maybe, adapted by those with greater autonomy: not the other way around. Tools such as
consequence scanning
and
ethically-inclined design
can help us explore possible futures.
To claim this kind of consent, organisations must commit to putting the principles into practice, and their doing so must be monitored and publicly reported on. As in many fields, without “trust but verify” there will be a natural tendency to creep into loopholes. Data Protection Officers may be the first layer in this verification, but their burden of maintaining independence and capability is likely to need external support and reinforcement. And we must beware of confusing adoption with acceptance. Something that is convenient but resented is not part of the social contract and should not be read as such. Popularity creates a particular risk: that widespread reluctant adoption may squeeze out the alternatives that would be a better fit for the social contract. The difficulty of buying paper street maps of major cities (“everyone uses their phone”) was mentioned. Bringing new technologies within the social contract won’t be quick or easy, but doing so should reduce the risk of individual harm or resistance, and of future “techlash” by parts or all of society.
Originally posted: 22 September 2021 in category
Articles
A fascinating panel at the
PrivSec Global conference
looked at how individual courts and regulators have responded to the
Schrems II decision on international transfers of personal data
. That decision, and the subsequent guidance from the European Data Protection Board, aimed to establish a consistent regime for transferring personal data from the EEA to external countries. However individual regulators now seem to be applying the case in ways that reflect particular local circumstances, such as the existence of functionally-equivalent alternatives or the sentiment of local populations towards transfers (in particular to the US). That may be good for avoiding a complete breakdown in personal data flows, but such divergence doesn’t help organisations trying to work out what they need to do, either as exporters or importers.
Although Schrems II stressed that exports might be possible, based on an assessment of risk, the
EDPB guidance sets a very high standard
. In effect it permits only exports for encrypted storage and technically-arcane forms of processing. Exports to most normal data handling services are essentially prohibited. Individual regulators do, however, seem to be returning to the risk-based idea: asking what is the risk to data subjects of transferring that data to that organisation for that purpose. As a per-instance assessment, this is still onerous: perhaps something that large corporate law teams can do, but unlikely to be feasible for a start-up. Even the corporates may be pointing out that this is the third export regime in a decade with, at least in the case of exports to the UK, every possibility of another one within four years. Worryingly, they may be tempted to consider
corporate
risk – will we get caught and how much will it cost – rather than the risk to data subjects.
This is made worse by the fact that the main risk that Schrems II focused on – compelled access by foreign security services – may be unknowable, certainly to foreign exporters, and quite possibly to local importers as well. Until or unless regulators start providing, at least, baseline per-country or per-sector opinions, the best option seems to be for exporters and importers to collaborate to
make a reasoned assessment
. This should include not only differences in law (exports to a bank may well have more legal protection than those to a technology company) but also in practice (a dating site may have a different level of law enforcement interest to one dedicated to professional networking). The good news is that, as far as the panel were aware, regulators’ actions have not yet gone beyond warnings and – admittedly short notice – orders to cease transfers. In a world where even regulators seem uncertain, exporters and importers who do their best to assess the risks and document their decisions may hope they will not suffer worse than these.
Originally posted: 20 September 2021 in category
Articles
The Information Commissioner’s new blog post explains how Data Protection law should be seen as a
guide to when and how to share information in emergencies
, not an obstacle to such sharing. In health emergencies three provisions are most likely to be relevant:
Explicit Consent
(GDPR Art.9(2)(a)): where an individual chooses to disclose information, such as a health condition or disability, their university or college can discuss the different ways that information could be used or shared, and let the user choose which of them should be done or allowed.
Vital Interests
(GDPR Art.9(2)(c)): where there is an imminent threat to life or serious injury and the individual (for example because they are unconscious) cannot give explicit, informed, consent.
Employment and other laws
(GDPR Art.9(2)(b)): allow states to legislate to either allow or require sharing of health and other sensitive data. Recital 52 gives “prevention or control of communicable diseases” as an example of such legislation; Recital 53 “monitoring and alerting purposes”. Such laws must provide “appropriate safeguards for the fundamental rights and interests of [individuals]”.
Schedule 1 Part 1 of the UK Data Protection Act 2018
provides a general framework; further details may be contained in emergency legislation.
The Information Commissioner’s Data Sharing Code of Practice includes a section on
Data Sharing in an Urgent Situation or in an Emergency
. This stresses that organisations should try to anticipate and plan for such emergencies, but that when an unforeseen or unplanned emergency occurs, “it might be more harmful not to share data than to [proportionately] share it”.
#505 - Ethics + Consultation + Regulation: a basis for trust
Originally posted: 15 September 2021 in category
Articles
A fascinating discussion at today’s QMUL/SCL/WorldBank event on
AI Ethics and Regulations
on how we should develop such ethics and regulations. There was general agreement that an ethical approach is essential if any new technology is to be trusted; also, probably, that researchers and developers should lead this through professionalising their practice. First steps are already being taken, with journals requiring that papers consider ethical issues: both those that can be addressed in design and implementation, and those that need to be monitored as the technology or context develops.
However for some fields, applications and contexts, society will not trust AI (and there are already plenty of people ready to lead a backlash against it) unless there are legal sanctions as well as ethical codes. The process of developing those laws must identify and address the concerns of all stakeholders, not just legal or technology experts. That needs a lot of genuine consultation (the multi-stakeholder process of Internet governance was cited with approval), with stakeholders, legislators and regulators all being enabled to make their contributions. Participation must represent all those who may be affected: lack of prior technological or legal knowledge must not be a barrier. Some technologies may be found to be socially unacceptable.
Successful regulation should be a benefit to those who want to enter these markets, by stabilising society’s attitudes to them. This was illustrated by two contrasting “new technologies” of the past: GM crops, and the Warnock Committee on Human Fertilisation and Embryology.
That framework has been widely used by incident response and security teams, however it left a couple of loose ends. First, that the framework was motivated by Recital 49 of the GDPR which, back in 2016, only said that such data processing “could” be linked to that legal provision; and second – particularly for the international sharing that is essential to protect the international internet – that GDPR Article 49 requires data exports to serve a “compelling legitimate interest” of the exporter. Information sharing more directly benefits the recipients, who can learn from others’ experience and analysis how to secure their own systems, so we need a bit of logical gymnastics to claim that improving overall security benefits the exporter, too.
This is based on Recitals in the European Commission’s
draft Network and Information Security Directive (NIS2D)
. Published in early 2021, these show how thinking has developed. First, although Recital 69 repeats the GDPR wording linking incident response to the Legitimate Interests basis, the permissive “could” in the GDPR is now a significantly stronger “should” in the NIS2D. The same Recital explicitly describes sharing “to raise awareness in relation to specific cyber threats, exchange of information in the context of vulnerability remediation and coordinated disclosure … voluntary exchange of information on those incidents, cyber threats and vulnerabilities, [Indicators of Compromise], tactics, techniques and procedures, cybersecurity alerts and configuration tools” as a component of the defender toolbox.
Second, the
individual
harms that motivated incident response in 2016 (“unauthorized access … malicious code distribution and … denial of service attacks”) have been replaced in NIS2D Recital 3 by
societal
harms (“impede the pursuit of economic activities …, generate financial losses, undermine user confidence and cause major damage to … economy and society”). This seems to invoke a different GDPR export provision, that sharing is “necessary for important reasons of public interest” (Article 49(1)(d)). Not only is this a more natural description of what information sharing actually does, it also removes the possible duty – if relying on a “compelling legitimate interest” – to inform regulators of all transfers.
So now I have a more complete framework, with NIS2D thinking joining up GDPR law:
When
: network defenders should share information when this will serve an “important public interest” (GDPR Art.49(1)(d)) …
Including those of preventing “financial losses, undermin[ing] user confidence, … caus[ing] major damage to … economy or damage to society” (NIS2D Rec.3) …
What
: the information shared should be “necessary for [that] interest” and “not over-ridden by the rights and freedoms of individuals” (GDPR Art.6(1)(f) in fact, as discussed in my original paper, sharing among defenders normally benefits those rights and freedoms) …
We’ve been focusing more on text-interface chatbots than voice interfaces, so I did a quick compare and contrast. My conclusion is that voice interfaces do raise novel data protection challenges: text interfaces probably only familiar ones. Parts of the EDPB guidance would become relevant if a chatbot were used to continually monitor what you typed into other applications, to combine its text input with other data such as location or device type, or to provide access to emergency services.
Using the EDPB’s headlines and paragraph numbers…
Transparency
. Both kinds of bot must provide accurate notices of processing (62); where the bot is part of a wider set of functions, the bot’s operations should be made clear and not buried in that notice (61); both types must support rights of information, subject access, etc. in accordance with the GDPR (65). In what becomes one common theme of the guidance, these rights are likely to be easier to provide through a (layered) text interface than audio: the gabbled style used to speak the rules on lottery adverts almost certainly wouldn’t pass Article 12’s intelligibility requirement!
Accountability
returns to this idea, requiring that any transparency messages communicated through voice interfaces should also be provided (to users and regulators) in written form on websites (143).
The other theme is the loose connection between a voice-bot and the humans around it: unlike a screen/keyboard interface you don’t need to physically touch, or even look at, a voice-bot to use it. Reminding humans of the bot’s presence and state is a new challenge (63), as is the likelihood that more than one human will interact through the same interface while needing to be provided with personalised transparency information and rights (64). There are useful reminders (66) that both kinds may have access to incidental information about the surroundings – sounds for an audio interface; location, device type, etc. for text – and the need to design technical, process and legal controls to handle this data (or exclude it) in accordance with the GDPR (
Data Minimisation
: 139).
Purpose limitation
. Both kinds must meet the usual GDPR requirement to only provide functions that users expect and only perform processing that is necessary for those functions (89). The EDPB also recall (90) the need to provide separate opt-ins for each purpose that is based on consent. Their heavy emphasis on consent may make this more challenging than it needs to be.
Data Retention
. Both kinds must minimise their storage of personal data, both in quantity and duration (108, 106). The GDPR normally offers anonymisation as an alternative to deletion, but effectively anonymising a voice recording may be impossible (107). The EDPB’s framing makes misidentified wake-words a particular problem (109). This is unlikely to arise for text-based bots unless they are continually monitoring typing and popping up when they think help is required.
Security
. Both kinds of bot need to meet the usual GDPR requirements on security of data (123); if either is used as a way to access emergency services then availability should be a major design focus (124). Bots that provide transactional facilities, or that implement rights such as subject access, must ensure they appropriately authenticate the user before making changes or providing personal information (122). Text chat-bots can do this using a wide range of existing keyboard/screen mechanisms. For voice-bots many of these are unavailable (reading out a password is not secure!) and …
Processing Special Category Data
. … voiceprint identification – which is a unique feature of the voice interface – are in the GDPR’s most sensitive category of data (“biometric authentication”). Nonetheless the EDPB do seem attracted to them as a way to address the “multiple-users” issue as well as individual authentication. They point out legal and technical challenges: that voiceprints should be stored and processed on the device, not a central server (133); that additional standards on protecting data must be followed (134); and that individual identification must be sufficiently accurate for all individuals and demographic groups (135). If either type of bot is used to access special category data then GDPR’s Article 9 provisions will, of course, apply.
Originally posted: 27 August 2021 in category
Articles
It’s interesting to see the (UK) ICO’s
response to the (EU) consultation on an AI Act
. The EU proposal won’t directly affect us, post-Brexit, but it seems reasonable to assume that where the ICO “supports the proposal”, we’ll see pretty similar policies here. Three of those seem directly relevant to education:
That remote biometric identification for non-law-enforcement purposes is high risk (para 26). This is unsurprising, given the ICO’s past comments that live face recognition (LFR) represents a
step-change in invasiveness
. But the EU proposal isn’t limited to LFR in public spaces: any processing of live (or near-live) video to try to identify or classify faces is likely to be covered.
That managing high-risk deployments needs a “continuous iterative process” (para 19). The EU proposal stated (again not binding on the UK, but may be a strong hint) that
high-stakes assessments in education
(e.g. course entry/selection) are high-risk places to use AI.
And (para 21) that there should be a public registry for high-risk AI systems “in particular for systems deployed in the public sector”. I don’t know whether they count education as “public sector” for this purpose – neither of the commonly-cited registers in
Amsterdam
or
Helsinki
seem to include educational deployments at the moment – but Helsinki does include a couple of library management applications and three chatbots.
Incidentally, Helsinki’s register may actually go further than the EU proposal. Two of the chatbots are deployed in health contexts, so do have an obvious reason for high-risk categorisation. But I can’t see why other three applications (parking information, book recommendations and shelf management) would meet that threshold. The draft EU Act actually suggests that
chatbots would normally qualify as low
(but not no)-risk: any register that lists every use of natural language processing is going to need some good navigation tools to find the few high-risk applications in amongst all the mostly-harmless ones.
Originally posted: 17 August 2021 in category
Articles
The ICO’s
proposals for international transfers
seem closer to the actual findings of the Schrems II case than the EDPB’s
effective demand
that processing of non-pseudonymised data be kept within Europe. However, as a risk-based scheme, it will require more work from both exporters and importers to demonstrate that transferring doesn’t create significantly greater risk to individuals.
The ICO’s scheme has two components:
an
International Data Transfer Agreement
(IDTA), which is a contract between an exporter and an importer (playing the same role as the current Standard Contractual Clauses), and
an
International Transfer Risk Assessment
(ITRA), which exporters should use to determine whether the IDTA is an appropriate mechanism for a particular transfer.
The ITRA is the new feature, responding to the
Schrems II requirement
that exporters consider whether any contract can provide sufficient protection for individuals whose data are exported. Whereas the EDPB focused on the powers and actions of law enforcement and security services and whether those “
go beyond what is necessary and proportionate in a democratic society
”, the ICO takes a broader view.
Its first stage is to consider whether the contract itself is likely to be enforceable: does the receiving jurisdiction recognise international agreements, including those that confer benefits on persons other than the contracting parties (here, data subjects)? If not, are there factors about the specific transfer – for example the behaviour of the importer or the nature of the data being transferred – that make it unlikely that lack of enforceability will actually create a significant risk to data subjects? If not, and judicial enforcement against the importer is likely to be needed to protect data subjects, are there ways to change the nature of the transfer (for example making data pseudonymous) to reduce the risk to an acceptable level?
The second stage is to look at third-party access (including under surveillance laws) using a similar series of tests: is the regulation of such access sufficiently similar to the UK that the transfer does not create significant additional risks? If not, how likely is it that third-party access to the transferred data will occur? If more than minimal, what risk to data subjects does such access present? If more than low, are there additional steps and protections the exporter can apply?
So long as both stages conclude that the additional risk created by transferring from the UK to the overseas jurisdiction is low, the transfer can take place under an IDTA.
For each question, the proposed guidance provides tables of factors that would create, increase or decrease risk. These seem to have been chosen with specific applications in mind: for example employee data is separated into basic low-risk data such as name, job title and contact details; medium-risk non-sensitive records such as CV and payroll history; and high-risk banking details and special category data. This is much more helpful (and realistic) than the EDPB’s bald statement that there are
no circumstances in which “transfer to cloud service providers … which require access to data in the clear” or “remote access to data for business purposes” can be adequately protected
. However it does still leave a potentially complex assessment for general-purpose cloud services. It’s possible that these will be addressed in the Example blocks (which are blank in the current draft); if not, then at least using an ITRA to explore and document the risks will show that the exporter has done its best to identify these and mitigate any increase caused by the transfer.
Originally posted: 11 August 2021 in category
Articles
The Government’s Online Safety Bill proposes to impose duties on “user-to-user services” to deal with harmful (including both lawful and unlawful) content and to protect free speech while doing so. Unlike most operators of on-line discussion platforms, educational institutions already have legal duties in both areas: through legislation on
safeguarding
,
preventing radicalisation
, and
free speech
. These have been extensively discussed – in Parliament and courts, in committees and among practitioners – to find and implement an appropriate balance. It’s therefore important to work out what impact, if any, the new legislation might have.
Unfortunately this isn’t clear, at least in the
most recent text
published for pre-legislative scrutiny. The Government’s
preparatory report
in December 2020 proposed (on p.18) excluding
services managed by educational institutions that are already subject to regulatory or inspection frameworks (or similar processes) that address online harm.
“Educational Platforms” are still mentioned in the current
impact assessment
(para 111) but not in the draft Bill itself. That does contain an exemption for “public bodies” (Schedule 1 para 6): some activities of educational institutions fall within that term for freedom of information and data protection purposes, but the reference here is to human rights law, whose application to education is less clear.
The impact may also depend on technology. Education rarely involves providing the unstructured public discussion spaces that are the Government’s main concern. More often, discussion starts from content provided by the institution: perhaps a lecture, research idea or discussion question. Participation may be limited to members of the institution, in which case it may be exempt as an “Internal Business Service” (Schedule 1 para 4), but what about discussions shared between multiple institutions? Or public discussion of research, which is something that Governments have been keen to encourage and institutions to facilitate?
The draft Bill also makes a distinction (in Schedule 1 para 5) between comments on the original material (exempt) versus comments on other comments (not exempt). But this seems hard to implement in practice and impossible in technology. If A comments “I found this helpful” and B comments “I agree with A”, is B commenting on the original material or on A’s comment? In technology terms, the platform operator might disable threaded comments. But, as is familiar to anyone who has tried to follow the unthreaded chat alongside a video-conference, the main effect of that is merely to make discussion more confusing to readers and contributers.
There are likely to be more opportunities for clarification as the proposal develops. The current text is a draft, which a
Parliamentary committee
will read and comment on, probably in the autumn. The Government is then expected to publish a Bill, which will go through the usual Parliamentary process, potentially including amendments. Then, to a greater extent than many legislative proposals, the requirements will be interpreted by a regulator – expected to be Ofcom – in the light of changing circumstances. If educational institutions are brought into scope, this will need to be done carefully and clearly, to avoid creating mismatches with existing practice and law that could benefit harmful content and/or suppress legitimate and necessary free speech.
Originally posted: 9 August 2021 in category
Articles
The ICO’s
Age Appropriate Design Code
(more familiarly the “Children’s Code”) may have been written before lockdown, but it could provide useful guidance to everyone designing or implementing systems for the post-COVID world. We’re all trying to work out what a “hybrid” world should look like, whether in schools, colleges, universities, workplaces or social spaces. A Code that helps us provide respectful digital systems should be relevant to all these and more.
It’s also worth remembering that, as a statutory Code, the guidance fits within the legal requirements of the GDPR. It doesn’t create new law. It may highlight features that are particularly important when working with children, but only to suggest how to comply with what is the law for users of all ages. And which of us adults wouldn’t welcome digital services that offered clear explanations of what they were doing, had respectful default settings, and didn’t try to push the boundaries of the law?
Best interests of the [individual]: which should already be our focus in education;
Data Protection Impact Assessments (DPIAs): to help understand the risks and how we might mitigate them; we’ve also found them a really useful way to show individuals that we are taking care of them and their data;
Age-appropriate application: provide services and systems that meet the needs and safeguards of your users (the ICO specifically notes that you can “apply th[is] standard to all your users” if you aren’t sure of their ages or needs);
Transparency: using clear language – accessible to the likely audience(s) – to explain what we are doing with data (a GDPR requirement in any case);
Detrimental use of data: the ICO provides an
indicative list of these
, with industry sector standards to be aware of;
Policies and community standards: acting in accordance with our statements, and our community’s expectations;
Default settings: it’s not just children who “will just accept whatever default settings you provide”, that’s why “privacy by default” is a GDPR requirement;
Data minimisation: collecting and using only the minimum data you need, and for the time you need it; again, a GDPR requirement for everyone;
Data sharing: arguably a principle that is stricter for adults than for children – there may be lawful reasons to share children’s data with parents & guardians, or in emergencies, but make sure you know what they are and have well-defined processes for them;
Geolocation: location data has always been regarded as particularly sensitive (for everyone) under ePrivacy laws, but has never made it explicitly into GDPR. This is a reminder of that sensitivity;
Parental controls: adults might want to control these for themselves, but most people still have things they would prefer not to encounter accidentally;
Profiling: again, the GDPR warnings about profiling apply to users of all ages. The Code suggests that it should be off by default;
Nudge techniques, or “exploitation of human psychological bias”: should not be deployed to encourage users to make bad (for them) choices;
Connected toys and devices: remember that users may forget that it’s not just a toy/smart speaker/fitness device/etc. but also a powerful data collection device;
Online tools: that make it easy for individuals to exercise their data protection rights.
Which of these would you want to reserve only to children, and not want in services designed for adults too?
An example in the ICO’s
Frequently Asked Questions
highlights that the principles aren’t bans, but areas to think carefully about. Using geo-location to provide information relevant to an international student’s country is fine, but let them choose whether to give you access to location data, and stop using that access as soon as you have the information you need.
In a few cases it may be reasonable to expect adults to (slightly) better understand the consequences of their choices. But distracted post-lockdown adults will still be grateful for clear explanations and services that just do the right thing.
Originally posted: 4 August 2021 in category
Articles
Jisc’s 2020
Future of Assessment
report identifies five desirable features that assessors should design their assessments to deliver: authentic, accessible, appropriately automated, continuous and secure. Those can sometimes seem to conflict, for example if you decide that “secure” assessment requires the student to be online through their exam, then you have an “accessibility” problem for students who may not have the required broadband provision in their best location for taking the test. But that example highlights some differences between the features, which may help us avoid those clashes and
produce assessments that are better for everyone
.
First is how much control we, as assessors, have over the definition of the terms. “Accessible” is almost entirely defined externally: either by law, for some groups of students, or by circumstance such as broadband disparity. If we want our assignments to be “accessible” then we don’t have much choice what that means. But, at the opposite extreme, if you define “secure” as meaning “conducted within the assessment rules”, then it’s clear that we have a lot of freedom to change those rules and make nearly any kind of assessment “secure”. This needn’t create a free-for-all: security rules should still offer an appropriate combination of (pre-assessment) prevention, (during assessment) enforcement, and (post-assessment) verification.
For example if you think that collusion among students is a “security” problem, you can re-define the assessment as group, rather than individual, work; if you think using external resources is a “security” problem, then make it an open-book research question, rather than a memory one. In each case, what used to be a “security” problem is now an authentic assessment of a valuable transferrable skill. It may well be that the only non-negotiable aspect of “secure” is “assessment was completed by the student”: but even here there are several possibilities, including checking that the assessment product is consistent with previous work, in quality, style, etc. Sometimes a student will “get it” on the eve of the exam, and their mark jump beyond the expected range: sometimes they may have a bad day and do significantly worse. In both cases we should be investigating gently, rather than jumping to conclusions about what happened.
Which raises another difference between the features: when they have to be present. Accessibility generally needs to be delivered at the time(s) of assessment, though even here there may be some potential for prior or subsequent adjustment. For security the moment of assessment is just one among a host of stages where measures – both preventive and corrective – can be applied. These can and should be designed to work together. Traditional invigilators will generally give warnings and make notes of anything that looks like a breach of the rules: only if a student’s behaviour is disrupting others will they be asked to leave. Combining the notes, output and other relevant information to produce an assessment score is done, later, by markers.
To avoid conflicts between the features, it may be helpful to start by looking at the ones where we have fewest options. Those are probably “accessible” and “authentic”: the latter offers some choices around which skill(s) or scenario(s) we want to be authentic to, but once that decision has been made, the only question is how close to reality we need to get. “Appropriately automated” and “continuous” are likely to be somewhat constrained by external environmental factors: including assessment facilities, technologies and staff workload. But, as well as being a little more flexible than accessible and authentic, these two are actually quite hard to even define until you’ve done those first two. And, as discussed above, “secure” has the widest suite of options, so it ought to be possible to apply it to nearly anything the first four have produced. There may still be some negotiation and adjustment between the five, but getting the right sequence should avoid the sort of painting-into-a-corner situation created by starting with the feature that is actually most flexible.
Originally posted: 14 July 2021 in category
Articles
This morning’s “multiplier event” from the
Onward from Learning Analytics (OfLA) project
highlighted the importance of human and institutional aspects in a productive LA deployment. They begin at the end – what is the desired outcome of your LA deployment? The answer probably isn’t “a business intelligence report”, and almost certainly not “a dashboard”. Starting from “a one-to-one conversation between a student and their personal tutor” gives a much richer perspective.
That approach makes clear the importance of tutor and student preparedness: are tutors confident of having those conversations, do they know when and how to hand over to others, and what kind of conversations do students find most helpful? The project has developed online tools for the first two of those: to help tutors explore the most appropriate timing, messenger, medium, content and follow-up for their interventions, and to help them do “warm referrals” where recommending the student talks to other experts is seen as supportive, rather than a brush-off.
Striking the right note for an individual student is hard, since it will depend on many factors, some of which are (at least initially) unknown to the tutor. For this reason, however tempting it may be, it’s probably not a good idea to try to shock students into working harder: there are just too many possible reasons why they may not appear to be making the expected progress. Sharing data with the student also needs to be handled with care: among other negative responses, too many graphs may be seen as obfuscating the message, comparison with benchmarks may be demotivating. One productive approach is to present “the system” as an antagonist, and invite the student to collaborate with the tutor in changing behaviour so as to confound its expectations. More generally: data can be part of conversations, but it must not be at their core.
This greater understanding of what comes
after
the application of learning analytics technology should then inform what comes
before
. LA purpose(s) that align with the institution’s mission are much more likely to be supported. The answers to “Why do we need an LA platform? Who are we trying to help?” lead naturally to answers to “who needs to access it?”, “what data presentations will be helpful?” and “what data literacy will users need?”. These, in turn, help derive requirements for both systems and data.
In this light, identifying a small set of effective data sources becomes an operational requirement as much as a legal one: too many sources make it hard to explain how students’ difficulties can be addressed. Human understanding is essential: one algorithm identified “enrolment status” as a (statistically) strong indicator of outcome. Well, yes! An interesting idea was to use transparency as an operational requirement/test: if students can’t explain the system to each other then it’s too complex. Reducing the number of sources also reduces the work needed to maintain data quality and ensure that changes in collection or systems don’t disrupt the student support purpose. The project has an excellent info-graphic on these policy issues, which should be available on their website soon.
Finally, any application of learning analytics involves many trade-offs. Early interventions will be less accurate than waiting for more data, but intervening the day before a student obtains a poor grade isn’t helpful. Ease of use tends to increase automation, which reduces both student and staff autonomy. And there is no guaranteed right way to communicate bad news. But a multi-layered approach that covers everything from data to process, presentation and literacy, seems to provide the best opportunity to adapt to circumstances and bring each alert to a satisfactory conclusion.
Originally posted: 7 July 2021 in category
Articles
This morning’s
Westminster Forum event on the Future of Artificial Intelligence
provided an interesting angle on “Trust in AI”. All speakers agreed that such trust is essential if AI is to achieve acceptance, and that (self-)regulatory frameworks can help to support it. However AI doesn’t stand alone: it depends on technical and organisational foundations. And if those aren’t already trusted it will be much harder – perhaps impossible – to create trust in any AI that is built on them. At the very least, a realistic assessment of how much trust we already have can inform how much of a “trust leap” the introduction of AI might involve.
The first layer is the context within which we work, or propose to act. Are organisations in that field generally trusted to behave responsibly, or are there concerns about hidden agendas and motivations? If you need to establish yourself as the only ethical actor in an unethical field, then do that first before you introduce further technological complexity, which may well be perceived and portrayed as suspicious opaqueness.
Next, since most AI systems will consume data, are our existing practices when handling and using data trusted? If we are seen as behaving responsibly in the ways we have humans collect, process and use data, then carefully introducing AI for the bulk data handling (thereby reducing the amount of access by human eyeballs) could even increase trust.
Research by the Open University
found that educational institutions generally are trusted by students to use data appropriately and ethically, but there are also stories of students
creating their own data segregation
, because they were not sufficiently confident of the university’s. We must be careful that introducing AI contributes to the former, rather than the latter.
If this analysis has identified a “trust gap”, that needn’t mean avoiding AI entirely. But while working to strengthen the trust foundations, it will probably be best to stick to low-risk applications of AI, rather than over-loading what trust we have. Interestingly, risk involves the same three factors – technology, data and context. Here, again, the context or purpose and the data we use may well be at least as important than the technology. Natural language processing involves some of the most complex AI algorithms, but many of its useful applications – for example chatbots and subtitling – involve little risk. But an algorithm as simple as a linear regression may be high-risk if used in a context where it influences life-changing decisions, or to process sensitive data.
Originally posted: 24 June 2021 in category
Articles
For the past twenty-five years I’ve tried to avoid saying “no”. Whether in website management, security or law, “have you thought of…?” seems much more fruitful. In the short term it lets us discuss alternatives, in the long term it encourages – or at least doesn’t discourage – the questioner to come back.
So it was depressing this week to see European data protection regulators apparently
saying “no”
to a wide range of trans-national
cloud services and business arrangements
. The context of the Schrems II case seems to have led them to focus solely on the risk to data protection from the US Government. Sadly, that’s far from the only threat to our privacy and ability to control what happens to our personal data.
Taking care of personal data is complicated, and needs discussion, rather than over-simple solutions. I’m hoping the UK regulator’s response to Schrems II will let me carry on having those discussions, rather than cut them short.
Originally posted: 22 June 2021 in category
Articles
Heard in a recent AI conversation: “I’m worried about black boxes”. But observation suggests that’s not a hard and fast rule: we’re often entirely happy to stake our lives, and those of others, on systems we don’t understand; and we may worry even about those whose workings are fully public. So what’s going on?
Outside our
houses
, motor cars are probably the most dangerous thing that most of us interact with on a regular basis. But, unless you’re a specialist engineer, how a modern car works is almost certainly completely opaque. Indeed, the tone of articles when
security vulnerabilities are discovered
suggests we’d like it to stay that way: too much visibility inside the box may be more alarming than too little.
We may be reassured by the presence of expert examiners, with legal powers. Any car more than three years old shouldn’t be on the UK’s public roads if it hasn’t had an
annual inspection
. Systemic interference with that process – even on an issue not directly related to safely – did cause
major public concern
. But even those inspectors don’t routinely carry out “white box” inspections on our behalf: much of what they do is still limited to examining inputs and outputs, not how those are linked inside the system.
And full “white box” transparency probably isn’t satisfactory, either. It may even create what Edwards and Veale refer to as the “
transparency fallacy
”, overloading individuals with information without giving them any meaningful ability to act on it. The notorious
trolley problem
suggests that even if we could be told, in advance, exactly how a self-driving car would respond in every possible scenario, even non-engineers would want to know why those particular trade-offs and choices were made. Questions like “what’s your business model?”, “what training data, limitations and monitoring have you designed for?” (a recent ACM article pointed out that
training on European and American roads may be poor preparation for those in the rest of the world
), even “why replace humans at all?”.
So it seems that the transparency, or otherwise, of the box may be less important than the transparency of the decision-making. Neither “black box” nor “white box” should be a way to escape accountability. Those who choose either model to develop or deploy should expect to have to explain and justify their choices.
Originally posted: 11 June 2021 in category
Articles
I’d been musing on a post on how “Artificial Intelligence” can be an unhelpful metaphor. But the European Parliament’s ThinkTank has written
a far better one
, so read theirs…
Originally posted: 4 June 2021 in category
Articles
“Algorithms” haven’t had the best press recently. So it’s been fascinating to hear from the
ReEnTrust
project, which actually started back in 2018, on Rebuilding and Enabling Trust in Algorithms. Their
recent presentations
have looked at explanations, but not (mostly) the mathematical ones that are often the focus. Rather than trying to reverse engineer a neural network, they have been exploring the benefits of clear and coherent messaging about why a task was chosen for automation, what the business models and data flows are.
That chimes with an idea I’ve had for a while about “shared interests”. If the organisation using the algorithm shares my discomfort (or worse) when something goes wrong, then I’m much happier to rely on its judgement. If the relationship is adversarial, where the organisation benefits from things that make me uncomfortable, then I’m much more likely to demand detailed explanations, or simply use opt-outs and technology to obstruct data collection or reduce data quality. Sometimes that undoubtedly makes me a free-rider – receiving benefits of data processing without contributing to it – but that’s the fault of the organisation that failed to explain how its limits of acceptability aligned with mine. If you want me to be altruistic, you have to continually earn it.
And that idea of alignment leads on to another idea about how we relate to our own algorithms. If we want others to behave as if we have made a good choice, then we must behave that way ourselves. And that applies even when things go wrong. If our algorithm responds badly to unforeseen circumstances or exposes unpalatable facts then we, who chose it, must own its behaviour and accept the blame.
Or maybe we can do better? Many years ago when I started working in what’s now called “cyber-security” it was really hard to get organisations to talk about their incidents. It was assumed that security should be perfect and that any breach was evidence of failure. The first breach notification laws were explicitly intended to “
name-and-shame
“. Now, we’re are a bit more mature: recognising that occasional breaches will happen, and what really matters is rapid detection and effective response. Claims that an organisation or product is unbreachable now cause me to lose trust: even if they have been lucky so far, it suggests that they will be unprepared when something does go wrong. What really builds trust in an organisation’s cyber-security is clear public explanations of what went wrong, what has been done to stop it happening again, and recognition that they aren’t the only (or even main) victim. That might be an interesting model for those working with algorithms, too.
Originally posted: 25 May 2021 in category
Articles
So many “AI ethics frameworks” are crossing my browser nowadays that I’m only really keeping an eye out for things that I’ve not seen before. The Government’s new “
Ethics, Transparency and Accountability Framework for Automated Decision-Making
” has one of those: actively seeking out ways that an AI decision-making system can go wrong.
The terminology makes pretty clear that this is based on how we have been finding
security vulnerabilities
in software systems for many years: using “red teams” and “bounty schemes”. But here the aim isn’t to find bugs in software that give access to what should be private data or systems, it’s to find situations where an AI decision-maker or support-system will make wrong, biased, discriminatory or harmful choices.
“Red-teaming” – in the sense of an internal activity to test the limits of systems – isn’t really new for AI. Practices such as ensuring test data sets are comprehensive and include examples that have caused problems in the past should be routine, especially given the availability of tools such as Facebook’s
Casual Conversations
. And there’s an active field of research exploring how
adversarial modifications
can make AI vision processors, in particular, mis-classify or mis-read what they see.
But the idea of a bounty scheme does seem relatively new (it turns out it was proposed in a
paper
in 2020). For software bugs, payments for making helpful reports were introduced into what was already a thriving security researcher scene. Since many security bugs could be exploited to make money, either by the researcher or by someone who paid them for their knowledge, the idea was to create a counter-incentive. If you discover a new bug, report it to the software vendor and help them fix it then you may receive a financial reward without the risk of being involved in criminality. That model has grown to the point where a software producer can subscribe to a bounty-as-a-service platform such as
HackerOne
; a few researchers make enough for bounties to be their main source of income, but for most they seem to be a token of appreciation, a way to fund the next round of research, or simply to justify the time taken to make a quality report.
The context for a bias and safety bounty is a bit different. It’s less obvious how a criminal would make money from secret knowledge of an AI bias risk and – as far as I know – there isn’t the same community of hobbyists searching for such problems as in the heyday of
bugtraq
in the late 1990s. So perhaps the main focus of a bounty scheme is to create that community, with the signal it sends being as important as the payment: we want to know about bias problems, help us find them and we’ll show our gratitude in an appropriate way (which, the history of bug bounties suggests, could include T-shirts or public thanks, as well as money).
One thing that is common to both types of bounty is that the benefits depend heavily on how organisations respond to the reports they receive. It would be nice to think that – twenty years on – we won’t see a return to vendors threatening to sue researchers, and researchers threatening to “go public” with their findings. At the very least, work together to fix the problem that has been identified: ideally, take a step back, work out how the problem got into the system and fix the development process as well.
Originally posted: 23 April 2021 in category
Articles
The European Commission has just published its
draft Regulation on Artificial Intelligence
(AI). While there’s no obligation for UK law to follow suit, the Regulation provides a helpful guide to risk from different applications of AI, and the sort of controls that might be required.
What “AI” is covered?
According to Article 3(1) [with sub-clauses split out and interpolating Annex I], it’s…
software…
developed with one or more of:
machine learning approaches, including supervised, unsupervised and reinforcement learning, using a wide variety of methods including deep learning;
logic-and knowledge-based approaches, including knowledge representation, inductive (logic) programming, knowledge bases, inference and deductive engines, (symbolic) reasoning and expert systems;
statistical approaches, Bayesian estimation, search and optimization methods…
that can, for a given set of human objectives…
generate outputs such as content, predictions, recommendations, or decisions influencing the environments they interact with.
That’s a huge improvement in precision over ‘definitions’ such as “a standard industry term for a range of technologies”. This one does seem like a reasonable basis for regulation: in particular you can imagine different people reaching the same conclusion on whether a given system was, or was not, “AI”. But it’s pretty broad.
So is it all alike?
No. The draft identifies four kinds of purpose that AI technology might be used for. Some purposes have minimal risk, and are not mentioned further. Some have low risk: here the main requirement is to make humans aware when they are being used. Some have high risk, and carry significant obligations for both suppliers and users. Some are unacceptable, and prohibited.
Low risk AI
According to Article 52, there is some risk whenever AI interacts with a human (e.g. chatbots); is used to recognise emotion or assign categories such as age, hair colour, sex, or ethnic origin; or to produce images, audio, video that might appear authentic or truthful (“deep fakes”). Humans must be informed when any of these are used. The introductory text says this lets people “make meaningful choices or step back”: although there’s no right to “step back” in
this
regulation, that may well arise from the rules for processing personal or special category data under the GDPR.
High-risk AI
These purposes are listed in Annex III, together with any use of AI as part of a safety mechanism in regulated products. Specific to education, paragraph 3 lists:
AI systems intended to be used for the purpose of determining access or assigning natural persons to educational and vocational training institutions; [and]
AI systems intended to be used for the purpose of assessing students in educational and vocational training institutions and for assessing participants in tests commonly required for admission to educational institutions.
These uses are considered high-risk even if AI supports a human decision-maker, thus representing a considerable extension of the GDPR Article 22 provisions on Automated Decision Making.
Other high-risk uses that may be relevant include remote biometric identification and categorisation of natural persons (para 1); recruitment or selection of employment candidates, promotion, termination, task allocation and monitoring of employees (para 4).
Using AI for these purposes may be permitted – subject to prior registration (Art.16) and conformity checks (Art.19) – but there are significant and continuing obligations on both suppliers and users. Suppliers must, for example: continually manage risk from both normal operation and foreseeable misuse (Art.9); comply with requirements on training data (Art.10), technical documentation (Art.11), and provision of logging facilities (Art.12); ensure accuracy, robustness and security, including against feedback loops, data poisoning and adversarial examples (Art.15). They must inform users (i.e. organisations): how to interpret the system’s output and use it appropriately; of situations that may lead to risks to health, safety or fundamental rights; of groups of people who the system is, and is not, designed to be used on; the expected lifetime of the system and ongoing maintenance measures (Art.13). Suppliers and users must work together to: ensure effective human oversight; understand the system’s capacities and limitations; monitor for anomalies, disfunction and unexpected performance (Art.14). Users must keep logs, monitor performance; they must stop using the system and inform the supplier if there is any serious incident or malfunction or if operation presents an unexpected risk (Art.29).
Prohibited AI
Some uses of AI are considered unacceptable (Art.5) because they contravene EU values, such as fundamental rights. These include subliminal manipulation and exploiting individual vulnerabilities so as to distort behaviour and cause harm to them or others; AI-based “social scoring” by public authorities. Real-time remote biometric identification in spaces accessible to the public (which is high-risk in any case) is unacceptable for law enforcement purposes except in certain defined circumstances.
A third way?
Some commentators have seen the draft Regulation as a “third way?” to regulate AI: between free market and complete control. Others have focussed on the bureaucracy required for high-risk applications, or the exemptions for law enforcement. To me, the most interesting thing is how it works together with the GDPR, in particular the Accountability principle. Both require organisations to think carefully about risks to individuals before implementing new uses of data and technology. This AI Regulation actually provides more detailed guidance on those risks. Having heard, just last week, that “most ‘AI ethics’ questions turn out to be ‘data ethics’ ones”, drawing those two strands of closer can only be helpful.
Originally posted: 19 April 2021 in category
Articles
Over the past twenty years, I’ve seen a lot of attempts to start information sharing schemes. And a lot of those have failed, some very slowly, despite huge amounts of effort. I wondered if there pointers that could be used, early on, to try to spot those.
Story
First, what is the story? If you want to receive information you should already have a story about how it will help. But what’s the story for those who will provide the information? What do they get out of it, and why is that something worth doing? The best stories are where sharing will address a common problem, but there are other kinds. Sharing may address a different problem for the two sides, or save money, or just improve their reputation. But there must be a significant overlap between the donor and recipient stories, where sharing looks like a win-win. And reputation matters. A long time ago I was asked if schools could provide the data source for an age verification scheme. Could, maybe: would, no. There was no story in which helping pupils to buy alcohol and tobacco, even if lawfully, looked good.
Scale
Second, scale. It’s rare for an information sharing scheme to be beneficial for the first few participants: bilateral agreements would be simpler if that was all they wanted. But what really matters how many participants you need before you start seeing benefits from choosing to do more than that. If it’s a handful on each side, you can go and make your case individually; if it’s half the community, you need a compelling case so they can decide for themselves to do it, plus excellent instructions so they can join without individual help. If the majority need to be sharing before anyone benefits, be prepared to provide long term support and encouragement. Network effects – when each new participant brings value to everyone – are critical for a scheme to become self-motivating, so you need to know when those can be expected.
Safeguards
Putting together stories and scale. At some point in a growing sharing scheme, some participants will use or provide information in ways that weren’t anticipated. What does that do the stories – both for donors and recipients? Sometimes it will make them better, by decreasing risk and/or increasing value; sometimes it will only affect that participant; but sometimes it will undermine the story for everyone else. How will you assess that, and how will you respond to an undermining action? If necessary, can you exclude – either temporarily or permanently – the misbehaving party? Or will their exclusion (and their likely response to it) do more damage than the misbehaviour? Ironically, successful sharing schemes may run the greatest risks: if participation becomes essential then both misbehaviour and exclusion – if there is no other option – may be highly damaging for everyone.
Thinking about these shouldn’t take long. Indeed that’s much of the point. If you, as the proponent of the scheme, can’t quickly see and explain how it will work for everyone, then you should expect to be spending a long time doing so, perhaps unsuccessfully.
#488 - An (organisational) framework for ethical AI
Originally posted: 31 March 2021 in category
Articles
One striking aspect of the new
Ethical Framework for AI in Education
is how little of it is actually about AI technology. The Framework has nine objectives and 33 criteria: 18 of these apply to the ‘pre-procurement’ stage, and another five to ‘monitoring and evaluation’.
That’s a refreshing change from the usual technology-led discussions in this space: here it’s almost all about the organisation within which the AI will work. Do we understand our goal in choosing to use AI, is there a sound educational basis for that, what changes will this involve for processes and skills, do we understand the risks, how can we detect and change course if it doesn’t work out? And, equally important, does our supplier understand what we are trying to achieve and commit to supporting our choice of goals and assessment of risks?
Even the seven ‘implementation’ criteria are about process: how can AI be used in assessment to demonstrate skills and support well-being; how can we create safe spaces outside continuous assessment; how can AI help us avoid unfavourable outcomes for individuals; how will we help all stakeholders (students and staff) work effectively and ethically with AI; how will we manage the changes that introducing it should bring?
With this comprehensive understanding of the context we want AI to support and enhance, the actual technology choice should be much simpler. Some technologies (maybe even some applications) will be clearly unsuitable: others will be a good, or perfect, fit. Best of all, we’ll be able to provide the most important explanation for trustworthy AI: why we chose to use it.
Originally posted: 23 March 2021 in category
Articles
To improve websites and other online services, measuring how they are used is a key tool. However the law on measuring visitors to websites is a mess. Nine years ago, when
reviewing the types of cookies that do not need consent
, the Article 29 Working Party of data protection regulators concluded that requiring consent when sites measure their own audiences was a major source of “consent fatigue”. A law to fix this was proposed in 2017 but has been stuck in debate in the European Council of Ministers ever since. While there has recently been
some progress
, Brexit means there is no guarantee that the UK will follow the result. Meanwhile the entry into force of the GDPR – in both the EU and UK – made that consent requirement even more onerous for both websites and their visitors. Last year the UK’s Information Commissioner said that enforcing this aspect of law was “
unlikely to be prioritised
”, but that could change at any time. If it does, regulators already have automated “
cookie sweep
” tools that would make widespread enforcement straightforward.
The law currently distinguishes between two (in future maybe three) different groups of technologies:
Multi-site measurement cookies, tracking pixels, fingerprinting, etc
. All technologies that store or access data from user devices require prior opt-in consent (unless they are solely for an
exempt purpose
) under the ePrivacy Directive. Using such data also requires a justification under the GDPR, and doubts have been cast whether this is possible given the close link between multi-site measurement, user profiling and targeted advertising.
Single-site measurement cookies, etc
. These technologies currently require opt-in consent under the ePrivacy Directive, however the proposed ePrivacy Regulation would make at least some of them exempt from this requirement.
Logfiles
. It is possible to measure website traffic using the logfiles routinely collected by the server. This is outside the scope of the ePrivacy Directive, and may be considered a Legitimate Interest under the GDPR. However, using general logfiles for this purpose may well be more intrusive than a tool that is specifically designed to produce audience statistics, so this approach is likely to require more in the way of safeguards.
It’s worth noting that all audience measurements are inaccurate for both technical and social reasons. Many people use cookie and script blockers that reduce the numbers recorded by those technologies. Changes to the default behaviour of popular browsers can also have a significant impact. On the other hand logfiles contain records of visits by search engines and other web mapping tools, so are likely to over-report. Adding or changing consent banners is also likely to change user behaviour, either reducing the number granting consent, or increasing the number willing to trust that the technology is beneficial.
There’s no obvious “right answer” to how to do audience measurement, either in law or technology. Changing involves a trade-off. Moving to a different technology on your own schedule should allow you to determine the effect of the change in measurement, and how to compare figures from before and after. Waiting until a regulator, legislator, technology firm or public sentiment forces the change may give more consistency in the short term, but a greater risk of an irreconcilable break when the change has to be made.
My Digifest talk yesterday developed a couple of ideas on how we might move Towards Ethical AI, at least as that is defined by the
EU High-Level Experts Group
.
First is that three of the HLEG’s four Principles, and at least five of their seven Requirements, look strikingly similar to the requirements when processing personal data under the GDPR. That shouldn’t be a surprise: GDPR has long been recognised as more than just a “privacy law”. But it does suggest that applying GDPR concepts and guidance – Accountability/Transparency, Purpose, Fairness/Accuracy/Impact, Minimisation/Security – even when we
aren’t
processing personal data may help us to be perceived as behaving ethically.
That leaves three areas:
Respect for Autonomy: which the HLEG explain as making sure that AI augments, complements, and empowers humans. In Q&A I borrowed from
Priya Lakhani’s keynote
to explain that as recognising that “Artificial Intelligence” and “Human Intelligence” aren’t, and shouldn’t try to be, the same. Autonomy, then, is about finding the proper roles for AI and HI, such that they can complement each other;
Diversity/non-Discrimination: in its impact on groups and society (GDPR should already have taken care of the impact on individuals) and
Societal/Environmental Wellbeing. As I
realised earlier in the week
, a significant amount of these two is actually “ethics”, it’s not specific to AI. Discriminating against groups (or individuals) is likely to be unethical, whether it’s done by a human, an AI or, come to that, Mechanical Turk.
So before getting into questions of “AI ethics” we should probably start by working out whether the actions are considering should be done at all. Here I suggested another quick tool:
four questions
to help explore new ideas for both feasibility and stakeholder reaction.
Since I make no claim to be an ethicist, I think this is about as far as I can take my journey “towards” Ethical AI. There remain two important questions:
If we have concluded that a thing should be done, is there an ethical reason to distinguish between it being done by humans or being done by AI? Here there does seem to be a general feeling that high-stakes decisions should be taken by humans: perhaps with AI assistance, but not by machines alone. I was also reminded of an instance where students wanted gentle “you need to do more work” reminders to come from computers and
not
their tutors, concerned that if tutors knew how much prompting they had needed, they might consciously or sub-consciously reflect this in their marks; and
What do we do if two ethical principles conflict? It’s easy to imagine (see many of Isaac Asimov’s
Laws of Robotics
stories!) scenarios where Respect for Autonomy might conflict with Prevention of Harm. And I suspect the same applies to most, or all, of the other pairs.
For those I think you do need an ethicist. Or, at the very least, a representative and thoughtful group of stakeholders.
The good news is that I think we can wait for that. Treating the appearance of either of those questions as a “no”, at least for now, doesn’t seem to limit the potential for using AI in education very much. There are still lots of applications waiting to be discovered, developed or delivered.
Originally posted: 10 March 2021 in category
Articles
One of the trickiest questions I’m being asked at the moment is about “the ethics of Artificial Intelligence”. Not, I think, because it is necessarily a hard question, but because it’s so ill-defined. Indeed a couple of discussions at Digifest yesterday made me wonder whether it’s the simply the wrong question to start with.
First, on “chatbots”. These use AI – in the form of natural language processing – to provide an additional interface between students and digital data sources. Those may be static Frequently Asked Questions (“when is the library open?”), transactions (“renew my library book”) or complex queries across linked data sources (“where is my next lecture?”). Here the role of the AI is to work out what the student wants to do, translate that to the relevant back-end function and translate the result of that function back into natural language. In these sessions, ethics hardly featured: an interesting point was made that a chatbot should not replace skills – such as navigating and selecting from academic literature – that the student should be learning for themselves; and there was a question whether the right answer to a student trying to work at 3am should actually be “get some sleep”.
Second on the use of student data to provide support and guidance. Here the conversation was almost entirely about ethics: are our recommendations biased? when do predictions become pre-judgements? when do personalised nudges become unethical? if a student has chosen the wrong institution, it is ethical to try to keep them on our register, or should we help them find a better option?
What struck me is that none of these ethical questions change significantly if the actions are done by humans rather than AI. Discrimination is unethical, no matter who/what does it. So maybe they aren’t about “ethical AI” at all, but “ethical behaviour”? It may be that some of the behaviours aren’t actually possible without the use of computers to crunch statistics, so here we’re looking at “AI-enabled ethical questions”. Conversely if we make our AI explainable – which will almost always be a practical necessity in education, where we need to understand predictions if we are going to help students beat them – then AI may actually give us a better understanding of human bias: “AI-illuminated ethical questions”, perhaps.
My talk (“Towards Ethical AI”) on Thursday will sketch a map containing three different kinds of purpose: those that are ethical no matter who/what does them; those that are unethical no matter who/what does them; and those where the human/computer choice actually makes an ethical difference. True “ethics of AI” may only arise in that last group, and it’s much the smallest.
Originally posted: 9 March 2021 in category
Articles
Priya Lakhani’s Digifest keynote was titled “How COVID-19 has catalysed edtech adoption” but actually ranged much more widely. What has the pandemic shown us about the role of technology in education and, indeed, how does that relate to education’s role in future society.
One obvious result of the pandemic is that we have (nearly) all got a lot more familiar with using technology. In some cases it has become second nature: we no longer qualify “chat” with the prefix “video-”, for example. Although we are all missing physical human contact, that deep engagement with technology presents an opportunity. In future we should always remember we have a choice of how to conduct meetings, and many other aspects of our lives. We should look out for opportunities for humans and machines to work together, each enhancing the other by adding its unique capabilities. In particular, we should remember that “artificial intelligence” and “human intelligence” are complementary, not competing. Human Intelligence will always be required of teachers, tutors and lecturers: Artificial Intelligence (AI) should help increase the amount of time they have to practise it.
For example AI can personalise and inform students: including taking a cross-curriculum view. It can analyse – not just identify – gaps in student knowledge and skills: is this student struggling in physics because they didn’t grasp a concept in maths? AI may be able to triage and suggest appropriate remedies: is this an individual issue, or a common one that we need to address in teaching materials as well as interventions? But it cannot analyse long-form essays, develop inter-personal skills, comfort a distressed student or celebrate with one who has “got” a tricky concept.
Getting this right isn’t just important for the school/college/university setting: it’s what we need to prepare students for in the workplace, too. Future employers should be looking for adaptive humans, who can continue to make productive use of whatever new technologies may develop. It’s common to talk about “life-long learning”, but maybe our concept starts too late? If you think of key habits and skills as “making things that work and making things work better”, then very young children already do that instinctively: might traditional education even be suppressing those ways of thinking – adapting, visualising, problem finding, problem solving, systems thinking – that we will need?
But – and hence my “nearly” above – we must ensure this opportunity is available to everyone. At the moment, something like 1 in 10 families does not have a laptop, desktop or tablet at all; in many more, learners have to share their devices. Software and connectivity also need to be sufficient for effective learning. And, though we often talk about post-pandemic “blended learning”, we must remember “blended teaching” as well. Tutors need new skills, too. In particular, if they are to work effectively with technology, they need to understand why it makes the suggestions it does, neither blindly accepting, nor blindly rejecting them. Technologists, deployers and managers all need to work together on this.
Ultimately, though, we must recognise that the pandemic has forced many of us to adopt a radically new way of making progress: trying something, failing or succeeding, and learning from both failure and success. Will we continue to do that, or will we revert to the safer ground of inertia, learning little or nothing?
#483 - Draft NIS2 Directive: security teams “should” be collaborating
Originally posted: 23 February 2021 in category
Articles
Anyone who works with flows, logs and other sources of information to protect network and information security should already be familiar with Recital 49 of the GDPR, where European legislators explained why that was (subject to a risk-based design) a good thing. Now the European Commission has published its
draft of the replacement Network and Information Security Directive
(NIS2D), it’s interesting to see how that thinking has been refined. Comparing Recital 69 of NIS2D with Recital 49 of GDPR gives us an update of what, how and why the Commission think we should be doing to defend networks, systems, users and data.
Both start with exactly the same premise:
processing … for the purposes of ensuring network and information security … constitutes a legitimate interest of the data controller concerned
But, while GDPR moves straight to examples of what defenders “could” try to achieve:
preventing unauthorised access … and malicious code distribution and stopping ‘denial of service’ attacks and damage to computer and electronic communication systems
NIS2D starts with a much more complete description of the classical process for protecting systems that we “should” be following:
measures related to the prevention, detection, analysis and response to incidents
and recognises that this cannot be done by individuals or teams working alone:
to raise awareness in relation to specific cyber threats, exchange of information in the context of vulnerability remediation and coordinated disclosure … voluntary exchange of information on those incidents, cyber threats and vulnerabilities, IoCs, tactics, techniques and procedures, cybersecurity alerts and configuration tools
The change from “could” to “should” reflects the move by Data Protection regulators (in their
Opinion on Breach Notification
, and
subsequent fines
) from viewing incident detection and response as something that is permitted to something that is required.
And the explicit recognition of the need for defenders to share information is very welcome, as this was one area where there remained some nervousness about whether GDPR might require European teams to reduce their sharing activities. Here we have a very clear statement to the contrary: information sharing “should” be happening, and the legal framework for it is the
same legitimate interests basis
as for our internal system defence activities.
Finally, there’s an interesting shift between the two laws in why network and information security matters. GDPR’s examples – unauthorised access, malware and DoS – are incidents that harm individuals. But NIS2D Recital 3 adds a much broader perspective:
cyber incidents can impede the pursuit of economic activities …, generate financial losses, undermine user confidence and cause major damage to … economy and society
I think that may also signpost a clearer legal framework for international sharing than the current patchwork of relevant GDPR measures, but I’m still working on that idea.
Finally note that, although the main focus of the NIS2 Directive is National CSIRTs and Critical Infrastructures, Article 27 is explicit that “entities falling outside the scope” must be included in information sharing. Together with the exact repetition of Recital 49’s motivating sentence, that seems a clear justification for reading Recital 69 back to the full GDPR scope: i.e. – according to the
Article 29 Working Party Opinion
– all data controllers.
Originally posted: 15 February 2021 in category
Presentations
Early in 2021 I was invited to give a one-hour presentation on Data Protection and Incident Response, looking at how the demands of the two fields align and support each other, and how law and guidance have come to recognise that over the past decade or so.
Originally posted: 15 February 2021 in category
Articles
To celebrate my 500th blog post, here’s another sea shanty:
What shall we do with the stolen data?
What shall we do with the stolen data?
What shall we do with the stolen data?
Early in the morning.
Way-hey the fines are rising
Way-hey the fines are rising
Way-hey the fines are rising
Early in the morning.
Got to tell the DPA unless there’s no risk
Got to tell the DPA unless there’s no risk
Got to tell the DPA unless there’s no risk
Seventy-two hours!
Way-hey the fines are rising…
Thoroughly protected using strong encryption
Thoroughly protected using strong encryption
Thoroughly protected using strong encryption
And we have the keys safe!
Way-hey the fines are rising…
Quickly we detected it and mitigated
Quickly we detected it and mitigated
Quickly we detected it and mitigated
Hooray for the C-SIRT!
Way-hey the fines are rising…
Yes we trained the personnel in all departments
Yes we trained the personnel in all departments
Yes we trained the personnel in all departments
And we have the records!
Way-hey the fines are rising…
Technical and org’nisational our measures
Technical and org’nisational our measures
Technical and org’nisational our measures
Starting to feel better!
Way-hey the fines are rising…
May not be required to inform the users
May not be required to inform the users
May not be required to inform the users
Think if it’s good practice?
Way-hey the fines are rising…
Thoroughly investigated, found the root cause
Thoroughly investigated, found the root cause
Thoroughly investigated, found the root cause
No more early mornings!
Way-hey the fines are rising
Way-hey the fines are rising
Way-hey the fines are rising
Learn from this and prosper!!
Originally posted: 12 February 2021 in category
Articles
A fascinating discussion session with colleagues who worked on Jisc’s “
Future of Assessment
” report. When that was written, in the first months of 2020, its intention was to look at how things might change over the next five years. Little did we know…
When the pandemic hit, suddenly many of things we had expected to happen by 2025 needed to be done by June. It was very quickly apparent that traditional exam halls were not going to be possible for the 2020 cycle, so there was a very rapid pivot to other ways of assessing students’ abilities. And that was amazingly successful. As I commented: the Future came 57 months early!
So now we know that it is possible to do assessments under lockdown conditions, can we use that experience as an opportunity to think what the future of assessment might actually look like? Maybe getting back to normal in terms of travel, meetings and gatherings shouldn’t just mean reverting to the traditional forms of assessment?
We gradually coalesced around five questions:
What are we actually assessing, and is that what we want to assess?
Knowledge, skill, ability to work under pressure, ability to write/type intensively for an extended period, short-term memory, long-term memory, digital wealth?
Who/which groups does that put at a disadvantage?
And is the disadvantage something – like lack of computers, bandwidth or a quiet place for undisturbed assessment – which can be fixed by providing appropriate resources; or something inherently incompatible between the student and the assessment style?
Can we reduce the stress of being assessed?
We should at least be wary of approaches that increase stress.
Can we make our exams more realistic?
How many jobs actually require us to sit at a desk for three hours, with no access to external information resources?
What is malpractice?
Can we adapt our style of assessment to make that ineffective or meaningless? Maybe a student who can use reference materials quickly to produce a well-argued response within the time-limit is actually demonstrating their knowledge of the subject? Having done both open-book and exam hall assessments during my law degrees, I felt the former tested my subject knowledge, the latter my exam technique. And have the words “digital” and “remote” triggered an excessive concern with on-the-spot “security”, overriding other important concerns? If we take a broader view of the context in which assessment takes place, there may be ways to detect cheating that don’t require us to discard the other priorities for effective assessment.
Originally posted: 8 February 2021 in category
Peacasts
“Big Data” has – often rightly – had a bad press. Is there a better way to think about it? Starting from potential benefits and discussing how they might be achieved should help us choose the right outcomes to aim for when using data, make it more likely that those aims will be delivered, and build trust and confidence in our approach.
Originally posted: 6 February 2021 in category
Articles
Inspired by Gavin Freeguard’s
National Data Strategy Sea-Shanty
, and in homage to the shanty-makers (I’ve worked the North Atlantic on small ships), here’s my “Adequacy Shanty”…
Farewell and adieu to you, fair Spanish data,
Farewell and adieu to you data of Spain,
For our UK law may be judg-ed inadequate,
And we may never see your fine data again.
The first of our
problems
is data retention
Ruled non-compliant in twenty sixteen;
Then a new issue with immigration processing
Oh how can we fathom just what that might mean?
Farewell and adieu…
We’ll rant and we’ll roar about
model clauses
Or, where it’s appropriate, write BCRs.
For contracts essential and users consenting
We have to be grateful to our lucky stars
Farewell and adieu…
Perhaps the Commission will
rule in our favour
,
And judge our position with some sympathy?
A problem postponed, or a permanent solution?
We wait for the outcome of Schrems number three!
Originally posted: 3 February 2021 in category
Articles
It seems easy to come up with new ways we might re-use data we already have. But harder to work out, in advance, whether an idea is likely to be perceived as unethical, intrusive, or just creepy. In a recent paper – “
Between the Devil and the Deep Blue Sea (of Data)
” – I explored how simple questions might help us look at ideas from different perspectives and identify the ones most likely to be accepted.
Before starting to implement anything – while the idea is at back-of-an-envelope stage – we can discuss it with stakeholders, to test how they are likely to respond. This should include at least those whose data will go into the proposed process, those who will do the processing, and those who will use the results. Some questions to frame that discussion:
Will it help?
Do we have a process/resources to act on any signals the data may contain?
Will it work?
Now we know what the process is, do the data contain the signals that process needs?
Will it comfort?
Or might it make people nervous, whether about the data we are collecting, how/why we are processing it, and who can see the data or results.
Will it fly?
Are the assumptions we are making valid, and will they stay that way? This may be particularly tricky when the aim of the process is to modify the environment within which the data are collected. Will the process have different effects, either in terms of traditional discrimination, or for groups with different digital footprints, because of different learning styles, different equipment, or different experiences?
If we still have a “warm feeling” about the idea, Data Protection law can provide further sanity checks, even if we don’t think we are processing personal data. For now, we are mostly looking at points to discuss – though the information gathered will be a great help if we do come back later to look formally at legal requirements. But if it’s hard to explain the answers to these high-level questions (based on the Information Commissioner’s
Twelve Steps to Prepare for GDPR
), that’s probably a warning sign that the idea itself needs more work:
Data Protection by Design/Impact assessments
. What are the benefits and risks for individuals (not – at least not directly – the organization)? Are there ways we could reduce the risks?
Information Lifecycle
. How do we collect data, use it, do we need to involve others, when and how will we destroy it?
Breach Notification
. How will we know when something has gone wrong and limit the harm? How might our handling and reporting of breaches – to users, regulators or management – increase or decrease trust?
Legal Basis
. This may sound dry, but having a clear legal basis will make your proposal much easier, and more reassuring, to explain. It’s also the gateway to lots of useful guidance. Is it needed
to deliver an agreement you’ve made with the individual (e.g. processing bank details to pay salary),
to meet a legal requirement (informing the tax office about the salary),
to protect life (from an imminent threat),
to serve a public interest (something that’s within our lawful remit),
to serve a legitimate interest (whether ours, individuals’, third parties’). And are we sure that that benefit doesn’t come at too high a cost to the rights and freedoms of individuals?
Or, if you can’t fit it into any of the above, can you meet the high bar for giving students or staff a genuinely free and easily withdrawn choice?
Privacy Notice
. The content of the notice flows fairly automatically from the questions above, but how will you communicate a new use of data that you already have?
Individual Rights Processes
(information, subject access, objection, etc.). As with Privacy Notices, if these look hard to provide, then the proposal may need rethinking to reduce the risk of it being seen as unethical.
Discussing these questions early in the design stage doesn’t just test out whether the idea is a good one. It can also reveal opportunities to make it better. For example if there’s a spread of opinion as to whether it seems creepy, can we make it optional, or add in additional controls for those (users and stakeholders, as well as data subjects) who are uncomfortable with it? If not, maybe that’s another warning sign. If we can, then it’s much easier to do it early than late in the development process.
One thing it seems everyone knows about Europe is that we have a strong privacy law: the General Data Protection Regulation, or GDPR. In this talk I’d like to get you viewing that not just as a law, but as a really useful way to think about designing systems and processes. And maybe challenge a few myths along the way.
Here’s what the GDPR itself says it’s about:
This Regulation lays down rules relating to the protection of natural persons with regard to the processing of personal data and rules relating to the free movement of personal data.
You’ll hear a lot about the “rules relating to the protection of natural persons”, so I’m not going to talk much about that. What I’d like to focus on is the much less referenced “rules relating to the free movement of personal data”. GDPR is explicitly – in its very first Article – about helping the movement and use of data, so long as that’s done in a way that’s safe for individuals.
First Myth
So – my first myth – GDPR isn’t (primarily) about individuals, it’s about the organisations that handle their data. All the GDPR Principles are aimed at them. And those Principles are a really useful guide to designing safe products, services, and other activities. For example:
Accountability
requires not only that organisations are compliant, but that they can show they are compliant. So we must think – before we start to use personal data – about the design of our systems and processes, safeguards against error and misuse, how we will operate them safely, and how we will ensure those plans actually happen. A key point is that the focus must be on the individuals and groups whose data we process, not on the organisation. And the GDPR provides a tool – the Data Protection Impact Assessment or DPIA – to guide that thinking. DPIAs are mandatory for large-scale and otherwise high-risk processing, but they are a really useful tool for thinking about smaller activities, too. And once you’ve done a DPIA, why not publish it to show your users and other stakeholders that you are taking care of their interests?
Another principle (both of law and design) is
Purpose Limitation
. This requires us to think clearly and precisely about why we are collecting and using personal data. Multiple purposes may be OK, but we have to be clear – in our own minds and in our documentation – what those are. “In case it comes in useful” isn’t a convincing purpose either for Regulators or for stakeholders. And, having set our purposes, we must avoid “creep” beyond them.
And once you have identified one or more purposes, you need to ensure that your organisation has a
lawful basis
for that purpose. Is it something you need to do in order to fulfil an agreement with the individual (for example to pay a salary, or deliver a service they have requested)? Or something you are required to do by law (telling the tax office about the salary)? Or (and we hope not to be in this situation) something that’s needed to save a life or prevent serious injury? Or something that is in the public interest – and where our organisation is best placed to do it – or something that is in the interests of the organisation itself, individuals or third parties it may work with? Each of these has its own conditions that our design must satisfy: in particular for public interest and legitimate interest we must balance our interests with those of the individuals whose data we propose to process. If it’s hard to meet those conditions, then you probably need to rethink either your design, or whether you should be doing this at all.
Second myth
GDPR isn’t about preventing processing, it’s about allowing processing that’s necessary. And “necessary” has a very specific meaning – that there’s no less intrusive way to achieve the purpose. So it forces us to think – again good design practice – about
minimisation
. How little data does the purpose need, how little processing, how little disclosure (both internally and externally), and how soon can we get rid of it?
GDPR and its guidance recognise lots of technologies as contributing to this: attributes (what someone is – student, staff, guest – is often more useful than who anyway); pseudonyms, which let us recognise a returning user, but not identify them; statistics, where we can achieve our purpose with counts, averages, and so on; roles that allow us to define and enforce policies; and federations, which we’ll come back to later.
Third myth
GDPR isn’t (mostly) about choice, it’s about notice.
With very few exceptions, people must be told the “natural consequences” of the situation they are in, or about to enter. Most of what you must tell them is the product of the thinking in the first two stages: who is processing their data, what processing you are doing (including the legal basis), why (including the purpose(s)), how long this will continue (and what happens to the data when it stops), who else (and where) may be involved, and how to exercise their rights over their data.
Sometimes – but far less often than is claimed – individuals will actually have a free choice whether or not to give you their data. But remember the five legal bases: if you are offering them a service, or required by law to process the data, or saving life, or serving a public or other interest, then their choice probably isn’t free. In those cases, this quote from Guy Singh-Watson is relevant:
Customers expected us to do the right thing on their behalf, not just give them the info to choose for themselves (arguably an abdication of corporate responsibility).
And Guy isn’t a data protection guru – he’s a farmer, who runs an environmentally responsible veg.box scheme. If he knows what corporate responsibility looks like, shouldn’t we try a bit harder?
Most often, I’d suggest, true consent will be appropriate when you’d like an individual to volunteer additional information, to get into a deeper relationship with you. Not to discover whether they want a relationship at all. If you can’t find a basis for that initial relationship among the first five bases, maybe re-think your plans.
So, thinking with GDPR helps us to meet the expectations of our users, customers and wider stakeholders.
We reduce the flow of information;
We increase the benefits we deliver from what we have;
and, by doing that publicly, we can provide a basis for increasing confidence and trust.
How does that work in practice?
Federated Access Management
Let’s look first at how students get access to the content they need for their courses.
Historically, that was a two-party relationship, where the student had to set up a personal account with the content provider, containing lots of personal data. Most of which didn’t actually help the provider either to decide whether the student should have access (because it was self-declared) or to deal with problems if they misbehaved.
Thinking with the GDPR principles – and some smart technologists – we realised that inserting the student’s institution as a trusted third party produced a very different data flow. Now, the student requests access, the provider checks with the designated institution whether they are covered by the licence. The institution uses its existing relationship and data to strongly authenticate the student, associate them with the licence and undertake to deal with any misbehaviour. Everyone benefits under this
Federated Access Management
model.
Analytics
Or, thinking about
Analytics
. Institutions do stuff: whether teaching, providing support, or providing facilities. Data trails generated by students and staff in using those facilities can be analysed (as a compatible purpose) to work out how to improve them (an obvious legitimate interest, with the balancing test ensuring it’s done safely).
If additional information from the student would help, we can ask them to provide it, always being aware that they may refuse or lie. And, if there’s an opportunity for individual improvement, as well as system-wide, we can suggest that. Again, the student can refuse to follow the suggestion. Limiting consent to these last two stages means our analytics and improvements can be based on whole-cohort data, not self-selected. Students can be reassured that the institution has weighed the risks and benefits to them, and that their actions in donating data or acting on personalised suggestions are free and fully-informed. Again, everyone benefits.
Originally posted: 28 January 2021 in category
Articles
In a chat at the
DataMatters
conference I was asked about the ethics of universities and colleges using social media providers to contact students. In breaking down that question, I think it illustrates a continuum: the more we interfere with individuals’ own choices of what and how to use, the more thinking we need to do beforehand to ensure they are protected from the consequences of our actions. So, for example:
Putting adverts on the social media platforms where we expect to find future students has little effect on their autonomy. Though we do still need to look carefully at the data flows and processes that may result from them reading or responding to our adverts;
Staff contacting students on social media, or even asking them for their contact details, need to be aware that students may consider those platforms to be personal social spaces, where intrusions from teachers (or parents) are not welcome;
If we expect, or require, students or staff to sign up to particular social media platforms (or anything else) as part of their learning, teaching, assessment or research, then we bear the greatest responsibility for ensuring our choice of platforms, applications, etc. is appropriate and safe. And, where possible, provide alternatives: some may have deliberately chosen not to use a particular platform for very good reasons.
This feels like an extension/generalisation of the Data Protection rule that as you process more, or more sensitive, data, the level of prior thought (there called “accountability”) must get deeper. Indeed many of the data protection tools – in particular Data Protection Impact Assessments – may well apply to choice of social media platforms as well. So it’s well worth involving your Data Protection team, who can help you use those tools and may be able to suggest alternative approaches and settings.
And, particularly at the upper end of the continuum, we need to review our choices and requirements periodically in the light of changing circumstances. Changes in platforms’ policies and practices may make them less or more appropriate for our, and our students’, purposes.
Originally posted: 5 January 2021 in category
Articles
The European Commission’s
proposed update of the Network and Information Security Directive
may revive discussions about access to WHOIS data. When a domain name is registered, contact details are typically requested for various purposes, including billing, administrative and technical questions. For most of the history of the DNS this ‘WHOIS’ data – including names, postal and email addresses – was published openly by domain name registries or registrars.
Although its quality is patchy, WHOIS became a frequent source for a much wider range of parties than had originally been envisaged, including law enforcement, incident responders, rightsholders and spammers. European privacy regulators expressed concern about this for most of the 21
st
century, but it was only when the GDPR introduced the possibility of massive fines that many European registrars and registries changed their behaviour, often by stopping publishing, or even collecting, WHOIS data at all.
Recital 60 of the
Commission’s proposal
now notes that (I’ve added one set of parentheses for easier reading):
The availability and timely accessibility of these data to public authorities, including competent authorities under Union or national law for the prevention, investigation or prosecution of criminal offences, CERTs, CSIRTs, and (as regards the data of their clients) to providers of electronic communications networks and services and providers of cybersecurity technologies and services acting on behalf of those clients, is essential to prevent and combat Domain Name System abuse, in particular to prevent, detect and respond to cybersecurity incidents.
Recital 62, and Article 23, therefore call on registries and registrars
to publish WHOIS data that is not subject to GDPR, and
to make data that is subject to GDPR available to “legitimate access seekers”.
That raises a number of questions:
Which WHOIS data are “not personal data” and required to be published by Art.23(4)? Although it is recommended practice to enter role-based contact details, which will survive the departure of an individual member of staff, that’s very hard for registrars to check or enforce.
And, for data that are personal:
Which groups are “legitimate access seekers” who must be given access according to Art.23(5)?
What is the “lawful, and duly justified” basis for that access? The NIS Directive repeatedly stresses that this must be in accordance with GDPR, and does not appear to be creating any new basis for the processing.
How (technically, since Rec.62 suggests “the use of an interface, portal or other technical tool”) can those “access seekers” be authenticated, authorised and provided with access?
Back in 2018, I
sketched out
how, if registries and registrars wished to give access to CSIRTs/CERTs, they could use GDPR Recital 49 and Legitimate Interest as a GDPR lawful basis, and how membership organisations such as FIRST and TF-CSIRT might be able to provide the necessary authentication, authorisation and policy infrastructures to ensure this delivers data protection benefits, rather than risks, to domain registrants. Now that such access is being recognised as “essential … to prevent, detect and respond to cybersecurity incidents” (Rec.60) that approach may be worth revisiting.
The draft Directive – partly because it
is
a Directive – leaves open the question of who might do that. Member States have considerable flexibility whether to add their own detail, or simply pass on the Commission’s wording to registrars and registries within their jurisdiction. But there’s an interesting hint of a more coordinated approach right at the end of Recital 62: “With a view to promoting harmonised practices across the internal market, the Commission may adopt guidelines on such procedures without prejudice to the competences of the European Data Protection Board”.
Originally posted: 24 December 2020 in category
Articles
We’ve all been trained how to spot phishing emails: check the sender address, hover over links to see where they go, etc. But that’s a lot of work and mental effort. And, given that most emails
aren’t
phish, almost all wasted. So can we do it better?
A
fascinating paper by Rick Wash
looked at how experts (in this case, university IT staff) do it. Yes, they use all those techniques, but only
after
something has flipped them into “look carefully” mode for a particular email. Most messages they classify instinctively, and correctly, as not-phish. So what is that something else: the pre-filter that leaves them relaxed about most emails?
It turns out that one academic definition of an expert is someone who is sensitive to the unusual. If that sensitivity is linked to a willingness to change your view of the world – from “this email is fine” to “this email is suspicious” – then that may be exactly the pre-filter we need. What we more often think of as “expertise” – deep understanding of a knowledge domain – may then be useful to assess which anomalies are probably harmless accidents, versus the ones that are likely to be created by a phisher. But it’s that initial sensitivity and willingness to abandon pre-conceptions that are key to optimising our mental workload.
If we can get better at paying attention when our instinct says “that colleague normally uses Slack, not email”, or “my bank tells me when I have a message, it doesn’t send it to me”, or “why did my friend write so formally?”, or “why didn’t the supplier give the order number”, or “why didn’t I hear about this by another route?” then we may be able to save ourselves a lot of conscious effort, without increasing the number of phish we fall victim to. Subsequent conscious inspection may reveal that the unusual feature in fact had a legitimate explanation: if we don’t get a few “false positive” triggers then we should try to increase our sensitivity. But we’ll still need to get into that mindset less often than every time “you have mail”.
One particularly interesting aspect of this is that it suggests that expert phish detectors don’t need any technical knowledge. If you have that then, of course, it means you can do the stage two conscious inspection yourself. But if you can become an expert in what your own email environment feels like, and develop expert-level sensitivity to when something doesn’t fit (maybe practice reviewing consciously why you felt uneasy about a particular mail), then dealing with your inbox should become a lot less stressful for you and for others. That’s something we should all be able to manage.
#472 - Thinking (using COVID-19) about location data
Originally posted: 22 December 2020 in category
Peacasts
During the pandemic, a lot of ideas have come up – not just contact tracing! – where useful information
might
be derived from location data. It struck me that a selection of those might be an interesting illustration of how intrusiveness isn’t just about the data we use, but what we use it for. Here’s a video…
#471 - Sandbox Tales: Public Interest and Privacy Notices
Originally posted: 21 December 2020 in category
Articles
The
latest report on ICO sandbox participation
contains a rapid pivot, and some useful discussion of the “public interest” justification for processing. Back in mid-2019, NHS Digital was awarded a sandbox place for a system for recruiting volunteers into clinical trials (the actual conduct of trials is out of scope). A few months into 2020 that, like many of us, pivoted to respond specifically to the COVID-19 pandemic.
A particularly interesting feature of the resulting report is the discussion of lawful basis in paragraph 4.3. Even after NHS Digital had been required by law to set up the system – which might have been expected to trigger an Article 6(1)(c) Legal Obligation – the preferred basis for processing any particular volunteer’s data remains Art.6(1)(e) Public Interest. This provides a useful middle ground between mandatory participation and the hard-to-explain morass created by the different meanings of “consent” in research and data protection law. There’s a hint here of an old, pre-GDPR, framing, that “public interest” was what you used when you chose to help someone who had a legal obligation.
Another suggested benefit of using Public Interest is that, unlike Legal Obligation, it preserves the individual’s right to object to processing. This is certainly what Article 21 of the GDPR says, though the report doesn’t make clear what the effect of such an objection should be. Under Article 6(1)(f) Legitimate Interest, an objection requires the data controller to repeat the rights-balancing exercise, but applying the individual’s specific circumstances, rather than those of data subjects in general. But Article 6(1)(e) doesn’t have an initial rights-balancing test: it presumes that whatever legislator created the law will have taken relevant rights into account. Rather than trying to work out what those were, it might be simpler for a data controller to consider whether they have “compelling legitimate grounds” for continuing (some) processing, and/or need to keep the data in case of legal claims. Or simply treat any objection as a direct opt-out.
Finally, paragraph 4.8 makes an interesting point on describing benefits in privacy notices. Where someone is volunteering to help “the public interest”, it’s useful to break that interest down to different stakeholder groups. This feels right: if I’m being invited to be altruistic then the benefits to identifiable groups such as “frontline NHS staff” or “high-risk patients” may well be more persuasive than broad appeals to “health” or the “NHS”.
Originally posted: 16 December 2020 in category
Articles
Tertiary educational institutions have a very specific role in promoting free speech, whether verbal, in writing or on-line. This is set out in general in the
Education (No.2) Act 1986
, with specific limitations – monitored by the sector regulators – to manage the risk of radicalisation in the
Counter-Terrorism and Security Act 2015
and, for Further Education, to safeguard students. Where researchers need to access material that would otherwise be unlawful, well-established
sector-wide guidance
explains how to work with law enforcement authorities to ensure this can be done safely.
The Government’s ongoing
review of Online Harms
appears to have concluded that this existing, sector-specific, regime should not be disrupted by imposing an overlapping regime designed primarily for social media platforms. According to paragraph 1.6 of the new
White Paper
, the future Online Harms legislation will have an exemption for:
Online services managed by educational institutions, where those institutions are already subject to sufficient safeguarding duties or expectations
. This includes platforms used by teachers, students, parents and alumni to communicate and collaborate. This is to avoid unnecessarily adding to any online safeguarding regulatory or inspection frameworks (or similar processes) already in place.
That legislation is due next year but, to judge from this White Paper, it shouldn’t affect the careful processes by which institutions, sector bodies, regulators and legislators have thought about speech over many years.
David Clark of MIT
is one of the best people to take a long view of the Internet: he has been working on it since the 1970s. So his suggestion – in a
Weizenbaum Institute Symposium
yesterday – that the 2020s may see as dramatic a change in Internet regulation as the 1990s is significant.
Before the 1990s, most Internet development had taken place in the public sector, in research and military organisations. Once the technology had been shown to work, and become usable (to some extent) by private individuals and organisations, government reduced its involvement and commercial organisations were allowed, indeed encouraged, to take more of a role. To facilitate this, regulation of the new medium was deliberately light touch: in both the USA and Europe, existing models of publisher liability were rejected as being too onerous for a developing commercial market.
There’s no question that that created an explosion of new ideas, services and possibilities: for Jisc’s recent 25
th
anniversary a number of us “silverlocks” reflected on what we were doing with networks in 1994 (I was setting up Cardiff University’s first web server) and our younger interviewers were amazed how primitive it all sounded. But David’s sense is that Governments are now looking, increasingly unhappily, at the consequences of that decision.
Much of that is down to simple economics. The original vision of the Internet was a mesh of cooperating entities, providing distributed services. That’s OK, perhaps, for large research universities who are used to collaborating. But it’s a really hard model to sustain: it’s much easier to build a centralised encyclopedia or discussion group than a distributed one. There’s no need for entities to agree to define (and then, which may be even harder, implement) complex standards and protocols; nor to persuade users that it might be better not to head to the service where all their friends are; nor to explain to regulators why discussing future plans is positive for competition and not the early stages of a cartel. Centralised services are much easier to monetise: the Internet has lots of protocols for moving bytes, very few for moving pennies. Dominant players emerge naturally, it doesn’t need any evil intent.
But once you have dominant players, offering frictionless and essentially free exchange of information, they naturally become a focus for societal problems that are normally constrained by either friction or economics. The list of issues that Governments are being told to “do something” about is increasing: privacy, trust, use of platforms by malicious and adverse interests, societal and economic dependency on large platforms, anonymity, national security, concentration of power, erosion of democracy, taxation… And there are signs that policy-makers in many countries and regions are looking to respond to at least some of those demands.
But in the 1990s the Government stakeholders were relatively few and shared a common approach, and the commercial ones were small and fragmented. Now, by contrast, Governments have very diverse views on Internet regulatory policy: many even hold competing policies (for example on encryption) in different departments. The consistent view is now on the commercial side – at least among the large platforms. It now at least as common for platform choices to change Government policies (notably on
COVID contact-tracing apps
and
link taxes
) as the other way around. As David concluded, we may well be at the start of a change in Internet regulation that is as significant as twenty-five years ago, but significantly slower and messier.
#468 - Schrems II: EDPB draft Guidance on exporting personal data
Originally posted: 8 December 2020 in category
Articles
The European Data Protection Board (the gathering of all EU Data Protection Regulators) has now published
its initial guidance on transfers out of the EEA
following the Schrems II case. This recommends that exporting organisations follow a similar roadmap to the
earlier one from the European Data Protection Supervisor
(who regulates the EU institutions). In particular, it only applies where personal data physically leave the EEA. But the EDPB takes a significantly harder line than the EDPS where the receiving organisation is subject to the US FISA Section 702, or similar, rules. According to footnote 49 that’s: telecoms carriers, providers of electronic communications service, providers of remote computing service, any other communication service provider with access during transmission or storage. Whereas the EDPS suggested a risk-based approach to those – prioritising large-scale, complex processing chains and sensitive data – the EDPB make no such distinction. If “the power granted to public authorities of the recipient country to access the transferred data goes beyond what is necessary and proportionate in a democratic society”, then the exporter is responsible for ensuring adequate supplementary measures that protect against that power.
Annex 2 contains example scenarios where the EDPB consider that adequate supplementary measures might be possible, as well as those where they can see no such possibility. The former include (with paragraph numbers in parentheses):
(79) storage of encrypted backups, where encryption and decryption keys remain within the EU;
(80-83) transfer of effectively pseudonymised data, where keys are kept in the EU and the transferred data (along with any other information available to the receiving state authorities) cannot be used to identify or single out individuals (a high threshold!);
(84) transit of encrypted data over the internet to a safe third country (though the requirements for “flawless implementation” and “backdoors … ruled out” will be challenging);
(85) encrypted transfer to an organisation that is protected by law from disclosure powers. In the main text there is a reference to “children’s data”, which seems likely to be a reference to the US FERPA, so also includes at least some US universities;
(86) split processing by multiple parties in different jurisdictions, such that neither party nor jurisdiction can access actual content.
However the two scenarios where the EDPB cannot envisage any measures giving adequate protection include the most common uses of Standard Contractual Clauses and Binding Corporate Rules, respectively:
(88-89) “Transfer to cloud services providers or other processors which require access to data in the clear”; and
(90-91) “Remote access to data for [shared] business purposes”, for example within a corporate group or joint economic activity.
The EDPB does concede that, although the requirement for data exporters to check foreign law and practice applies to all transfers that are protected by contractual safeguards (including Article 46 Model Clauses and Article 47 Binding Corporate Rules), it does not apply to transfers under Article 45 Adequacy Decisions or Article 49 Specific Derogations. The latter include “necessary for the performance of a contract” (often known as the hotel booking derogation), “compelling legitimate interests” (only for non-repetitive and small-scale transfers) and “explicit consent”, each with specific requirements that must be satisfied. For example “explicit consent” (Article 49(a)) can only be used after the data subject has “been informed of the possible risks” of the transfer, and agreed to them. This might work, for example, where a user requests out-of-hours support from a cloud provider (the EDPB explicitly states that non-EEA support access to data in an EEA-hosted cloud is an “export”), if consent took the form of offering the user a choice between immediate support from a jurisdiction without adequate protection or office hours support from within the EEA.
These Article 49 derogations were designed to be used only for occasional, ad hoc, transfers, with Articles 46 and 47 covering regular and larger scale ones. There seems to be a significant risk that the EDPB’s hard line on the routine provisions may have the counter-productive effect of forcing organisations to push the boundaries of the ad hoc ones, as has previously happened with necessary, consent and legitimate interests.
These are draft guidelines, so it’s possible there may be some relaxation in the final version. We also don’t know how
individual national regulators will respond
. But with the test for non-EEA legal systems being set so high (
higher than several EU member states could attain
, according to the European Law Blog) the tendency does seem to be strongly towards “data localisation” where European personal data must remain within Europe.
This raises a particular problem for the UK, post-Brexit. Onward transfers are a particular focus of both the Schrems II judgment and the EDPB guidance. If the UK does not follow EDPB guidance on limiting transfers
from
the UK out of the EEA, then it increases the likelihood that that guidance will be applied to limit transfers
to
the UK from the EEA.
Originally posted: 27 November 2020 in category
Articles
Dataguidance is reporting that the German presidency has
produced its progress report
on the last six months of discussions on the ePrivacy Regulation. Recall that this was supposed to come into force on the same day as the GDPR… And it seems that Member States
still
haven’t reached agreement on what purposes might justify a service provider processing communications metadata, or using the processing and storage capabilities of end-user devices (including storing and reading cookies).
There is a hint, at least, that the range of options may have narrowed slightly – with “broad support” for the idea that it should be less than simply adopting the Legitimate Interests basis provided for processing under the GDPR. But also a general feeling that the current detailed list of permitted options was “too restrictive towards innovation”. So far, so good…
But then there’s a suggestion from “a number of Member States” that discussions under the Portugese presidency in the first half of 2021 should start, not from the current German proposal, but from the one handed over by the Finns at the end of 2019. So I’m not sure whether we are going forwards or backwards…
You might think that the more training data you give to a Machine Learning algorithm, the better it will get. Humans get better with more practice, after all. But that’s not typically how ML works. For a while, more training datapoints will indeed improve the algorithm’s ability to derive general patterns. But if you give it too much training data, then it will tend to simply memorise datapoints. This is called “
over-fitting
”, where the algorithm gets so good at explaining the points it has already seen that it actually becomes worse at explaining any new ones.
So it turns out that the GDPR’s data minimisation principle – that data shall be adequate, relevant and limited to what is necessary – is the right way to train a Machine Learning algorithm, too!
Originally posted: 24 November 2020 in category
Articles
Two talks at last week’s FIRST conference looked at how Artificial Intelligence might be used in incident response. In both cases, the use of AI improves user privacy directly – by reducing or eliminating the need for human responders to look at user data – and also indirectly, by producing faster detection and mitigation of security/privacy threats.
Both talks stretched my knowledge in fascinating ways, so apologies if anything in the following isn’t correct. I’ll add links to the recordings when they are publicly available…
CK Chen looked at more traditional approaches, giving an excellent walk-through of how to construct a Machine Learning pipeline with the characteristics needed to support human threat hunters. Human threat hunting approaches involve looking at lots of user activity data, and generate lots of false positives. Can Machine Learning do better? As source data, the demonstration pipeline uses Windows process creation and command line events, gathered during (a) normal operation and (b) simulated attacks using APT3 and Metasploit.
Stage 0: training an algorithm using these two – good and bad – datasets still produces lots of errors. A few processes/commands only appear in a single dataset, but things such as ‘netstat’ and ‘whoami’ are in both. Whether these are good or bad depends on the context. So…
Stage 1: noting that a human threat hunter will look for significant sequences of events, try grouping parent and child processes into clusters, then get a human to label those clusters as good or bad, and train the algorithm using the clusters. This gives much fewer false positives, but still needs significant effort and data inspection. So…
Stage 2: noting that attacks are less common than normal behaviour, add an anomaly detection stage to the pipeline. Processes common in the ‘bad’ dataset that appear in anomalous clusters give a strong signal. But that same pattern applies to novel legitimate activity, so this algorithm tends to generate false positives that are hard to explain. So…
Stage 3: noting that attackers probably have to start from one of a small number of vulnerable processes, look for abnormally densely connected clusters around those processes. Interestingly, this algorithm performs slightly less well, in terms of number of false positives, but it provides a storyline that is much easier for a human to interpret: here’s where they gained initial access, escalated privilege, exploited the vulnerability.
For an AI that is designed to work
with
a human – protecting the privacy of (most) legitimate activity from human eyeballs, and passing the rest on to a human investigator – easy comprehension is more relevant (to both privacy and security) than highest numerical performance.
Holly Stewart, Anna Bertinger and Sharada Acharaya from Microsoft looked at approaches that go further, and take the human out of the loop (except when invited in) entirely. When millions of new spam and phishing attacks appear every day, and last no more than an hour, full automation is essential from a security, as well as a privacy, point of view. In each case, the aim is to build AI that can classify previously unseen threats, based on self-reported data. The first approach they described was data obfuscation: eliminating personal data that you don’t need. For example if someone reports malware hiding files in their Favourites directory, that information is sufficiently well structured that you can remove the username from the path, benefitting privacy without affecting either training or detection. Next is “eyes-off training” where human data scientists see the “shape” of submitted data (flows, volumes, etc) but only the AI sees content for both training and detection. This can work well, but raises a problem when investigating false positives and negatives, and understanding what the model is doing, since the investigator can’t look at live content to understand its behaviour. Finally, one of the first practical uses of homomorphic encryption I’ve seen. This is a class of encryption algorithms that preserve arithmetic operations, so adding or multiplying two encrypted values produces the encrypted version of the true sum or product. It turns out that it is (just) possible to write machine learning classifiers within these constraints. So, when inviting users to submit screenshots of phishing pages, features of the pages are extracted and encrypted on the local machine, the encrypted values are submitted to a classifier in the cloud, and the user gets back a “don’t go there” message, fast enough that it should prevent them being tempted. Seriously impressive, both from a privacy
and
security point of view!
#464 - Threat Intelligence: for machines and humans
Originally posted: 20 November 2020 in category
Articles
Threat Intelligence is something of a perennial topic at FIRST conferences. Three presentations this year discussed how we can generate and consume information about cyber-threats more effectively.
First Martin Eian from Mnemonic described using (topological) graphs to represent threat information. Objects, such as domain names, IP addresses and malware samples are vertices in the graph. Facts about them are edges. So an edge of type “resolves to” would connect a domain name and an IP address. Databases that use this kind of structure are widely available and make it easy to explore threats by visualisation and pivoting. Access controls can be applied to edges, thus allowing different people and partners to access parts of the graph that are relevant to them. While individual threat reports tend to create islands in the graph, databases can suggest links between those islands, where what may be the same object appears in more than one island. To be most effective this requires those populating the graph to use strict vocabularies: if two things
are
the same we should endeavour to make them the same in the graph. But where things
may
be the same (for example multiple names for malware or threat actors) it’s better to keep the different names as different objects, linked by “alias” facts. Choosing a single canonical name turned out to be a bad idea as it makes it impossible to disentangle the graph if you later change your mind. These – in fact all facts – should be labelled with a measure of “confidence”, so we know how much reliance we can place on the conclusions we draw. Changes of mind should also be explicitly recorded: facts should be timestamped and never changed. Instead, new, later, perhaps different confidence, facts should be added to the graph. As well as recording how our thinking developed, the sequence of timestamped facts should itself reveal threats such as fast-flux DNS (a rapidly changing “resolves to” link) and the development of malware families. Such labelling may be more work for the creator of threat intelligence than simply copying machine-generated alerts into a file. But good threat intelligence should aim to be write-once, read-many. As Trey Darley (CERT.be) and Andras Iklody (CIRCL) pointed out, adding context is like putting comments in source code: it’s worth taking the time to help others, not to mention your future self.
Trey and Andras developed these ideas further. Ideally, our threat intelligence should be valuable to many different types of consumer, including Security Operations Centres, Internet Service Providers, incident responders, threat analysts, risk analysts, and decision-makers. The technical information for each group may be similar, but how they use it will be very different and highly dependent on the contextual information that surrounds it. SOCs want to know which alerts they already have, or can deploy, protection against and which novel ones need deeper investigation; ISPs, who control Internet access for thousands of users, cannot afford false positives, so need to know which data points are sufficiently robust to use in blocking rules; Incident Responders want to see how an incident developed, so they can look out for similar signs; Threat Analysts want to understand motivation, modus operandi, attacker infrastructure, and unknown attack vectors; Risk Analysts want to see patterns in attacks, sectors and geography; Decision-Makers want evidence to inform decisions on resource allocation, including which threat information feeds to continue paying for! Use existing protocols to indicate how information may be used (for example the Permissible Action Protocol) and whether it may be shared (Traffic Light Protocol), but be clear whether these apply to the whole report or only parts of it. The aim of sharing should be to help others protect themselves: if you have reports, scripts or configurations that helped you, consider whether you can pass these on, too. Although a lot of the discussion around information sharing has focused on machine-readable information, this highlights the need to connect this to human-readable information, too.
A tool for doing just that was presented in a wonderful – costumed! – talk by the Fujitsu team of Ryusuke Masuoka, Toshitaka Satomi and Koji Yamada. Their S-TIP platform creates a bridge between human and machine worlds, on both the input and output sides. Human sources – blogs, incident reports, social media posts and emails – are scanned for data such as IP addresses and domain names, bitcoin addresses, CVEs, malware hashes and threat group names. These are tagged so they can be linked to machine-readable alerts and Indicators of Compromise. Chatbots within the system can then add richer information and links. Using this combined information, human analysts can quickly determine what (if any) action may need to be taken. This, too, is automated: the system has one-click links to Jira (to create block requests), Slack (to share internally), MISP (for external sharing) etc. In each case the original human-readable context accompanies the machine-readable instructions.
#463 - Human Factors: Don’t make a CRISIS! out of a Crisis
Originally posted: 19 November 2020 in category
Articles
Some security incidents need more than a technical solution. Two talks at this week’s FIRST conference looked at the importance of human factors, in crisis management and vulnerability handling.
Jaco Cloete looked at situations where a cyber-incident can become a business incident, causing reputational damage, social media fallout, loss of market share, regulatory fines, even a liquidity crisis. These need a Cyber Crisis Management Team (CCMT) to coordinate between stakeholder groups and internal teams, the latter including the CSIRT doing the technical investigation. The core of the CCMT should be the CISO, CIO, executive responsible for risk, and executive responsible for the affected business unit. Others who may be brought in – as required by the nature and progress of the incident – include legal counsel, insurance, social media, CSIRT, crisis management experts, contact centre, investor relations and forensics. Where the organisation does not have these functions in-house, it may need to engage external help. The CCMT needs to meet regularly, at least daily, in an appropriately secured and resourced “war room”, not dependent on any infrastructure that may have been compromised. Even organisations whose size does not justify maintaining such a facility permanently should have plans, policies and protocols in place to create and operate one on demand. The decision to invoke these steps (something else to document in the crisis plan) may be based on publicity; sensitive client data; market, industry, regulatory or operational impact. One major job of the CCMT is to facilitate all communications – both external and internal, though in a crisis the difference should not be relied upon. Key points for the communications strategy: regulators and clients/victims first; honesty/trust; show competence; regular updates; social media/microsite; facts, not speculation; right tone (clients are victims, not you – apologise to them); respect confidentiality.
Mark Stanislav looked at another situation where communications are critical: receiving reports of vulnerabilities in products or services. He suggested treating this as a customer support function, rather than a technical one, and using personas to help staff maintain appropriate communications with those reporting vulnerabilities. At a minimum, a persona should suggest the likely motivations, pain points, technical expertise and community visibility of the individual you are talking to. This may be more natural if those are set within an appropriate back-story, name and (stock) image. It occurs to me that a pre-defined persona might also provide a flag when someone is behaving “out of character” and may need particular care. The personas need to be realistic. Specifically for bug reporters, HackerOne have some very useful statistics on
why people find bugs
– is it a hobby, an educational project, a job, or did they find it accidentally in the course of their work (even I have done this!). This may well give clues about how they may react to both successful and unsuccessful engagements: will the story be told at a major conference, on a popular social media feed, in an essay, or forgotten in mutual embarrassment. But there are also more subtle signals to bear in mind: a professional researcher will expect (and be worth) individual treatment, but for a hobbyist with a fuzzing tool it’s actually more dangerous to leave the standard script and risk being seen as not delivering on what you promise. It may be tempting to respond to all calls with “that’s a really interesting bug”, but don’t do that unless you are in a position to follow through on the implied promise. People who choose to report bugs to those who can fix them, rather than sell them on the black market, are demonstrating good intent. But don’t be complacent. Failing to understand and respond to their reasons for doing so can quickly turn a friend into an enemy.
[Typing that reminded me of another possible source for real researcher personas, and an excellent read: Chris van’t Hof’s
Helpful Hackers (e)Book
]
#462 - Vulnerability Disclosure: Why are we still talking about it?
Originally posted: 18 November 2020 in category
Articles
Ben Hawkes, from Google’s
Project Zero
, gave a fascinating keynote presentation on vulnerability disclosure policies at this week’s FIRST Conference. There is little disagreement about the aim of such policies: to ensure that discovering a vulnerability in software or hardware reduces/minimises the harm the vulnerability subsequently causes. And, to achieve that, there are only really three things a vulnerability discoverer can control: Who to tell, What to tell them, and When. So why have we been debating the answers since the Security Digest and Bugtraq lists of the late 1980s and early 1990s, still without reaching a conclusion?
Mostly it comes down to that word “harm”: how do we measure it, and how do we predict it.
First, different people and different organisations will have different measures of “harm”. Is a vulnerability that allows a million PCs to be used for cryptocurrency mining more or less harmful than one that allows a trade negotiator’s communications to be read by an adversary? Are we concerned about short- or long-term harms? Harms to individuals, organisations or societies? There probably is no single right answer to these questions, in which case the best that organisations processing vulnerabilities can do is to think what their answer is, and document it so others can understand their behaviour.
Where there does seem to be scope for improvement is in our collective ability to assess the likelihood of a particular vulnerability causing harm. This needs an assessment of how attackers who know about the security weakness are likely to use that knowledge: before, during and after our discovery and disclosure process. How many of our vulnerabilities were already known and being silently exploited? If we discover it, how long before an attacker does? How much skill do they need to exploit it? How are they motivated to use it? Will our disclosure significantly change the situation?
Here we are dealing with incomplete information. Attackers have strong incentives to conceal their actions and reasons from us, maybe even to actively mislead. The ones we do find out about are the “failures”: the attackers who got caught. We may be able to learn a little from these, but it’s the successful ones we really need to be able to predict. I was reminded of the “
bullet-hole misconception
”, though here we are observing only the attackers that failed to escape, rather than only the planes that succeeded in doing so.
Statistical efforts to fill in this information gap include FIRST’s
Exploit Prediction Scoring System SIG
. But Ben suggested another angle on this might be to look at ourselves: ask experts to predict which recent vulnerabilities will cause significant harm, record their predictions, later test those predictions against what actually happens, and then try to understand how the more successful experts do it?
Originally posted: 17 November 2020 in category
Articles
The ICO’s
latest notice of a Monetary Penalty Notice
, on Ticketmaster, contains unusually detailed guidance on the good practice they expect transactional websites to adopt. Although the particular breach concerned credit card data, this seems likely to apply to any site that takes customer data or that uses third party components. The
whole notice
is worth reading but, since it’s 73 pages long, here are the key points I spotted.
Simplify payment pages
, or any others where you collect customer data. The breach occurred due to the insertion of malicious code via a chatbot. The ICO considers (6.13 – 6.17) that the risk of including third party JavaScript code was well known at the time of the breach in February 2018 and (6.18 – 6.20) that pages that accepted credit card details were particularly likely to be targeted. Removing the code from that page would have reduced the attack surface.
Use a layered approach
to security, so you are not reliant on any single factor. In particular:
Don’t rely solely on third party certifications
(6.22). Ensure contracts for third party code are clear where such products should and should not be used, and make sure security checks occur at a frequency appropriate to the speed of development of the threat (6.22.2).
When using third party written or hosted code,
consider the technical measures you might deploy yourself
, both in design and operation, in case any security issues arise in that code (6.24). These might include isolating the code from the rest of the page and applying security protections to the communications between the code and the rest of the site. And…
Relevant to both third-party and in-house code.
Do your own checks
, such as monitoring for unexpected changes (6.12), performing test transactions (6.22.5) and examining network traffic (7.13).
When these checks, or external reports (see 3.3 – 3.26), identify a problem,
involve an incident response team promptly
, and give them full information. It appears (7.12) that Ticketmaster’s response was delayed by focussing on a particular event and PC operating system when the problem was actually on the website and could have affected all bookings made through it.
#460 - Sandbox Tales – Information Sharing Platforms
Originally posted: 11 November 2020 in category
Articles
The latest reports from the ICO sandbox provide important clarification of how data protection law applies to, and can guide, the application of novel technologies. This post looks at information sharing…
FutureFlow’s Transaction Monitoring and Forensic Analysis Platform
lets financial institutions such as banks upload pseudonymised transaction data to a common platform where they, regulators and other agencies can look for patterns across the combined data set to detect and investigate “unusual behaviours and transaction patterns” that may indicate financial crime. This looks a lot like the information sharing platforms used by computer security incident response teams (CSIRTs) so it’s good to see that the sandbox report largely supports the legal model (
explained in detail by the MISP project
) that those have been using.
First, although uploaded data are typically pseudonyms – in FutureFlow’s case through standardised hashing of identifying data, in CSIRTs because most data are associated with pseudonyms such as IP addresses – they should not be treated as anonymous. Pseudonymisation reduces the identifiability of data but these datasets are sufficiently rich that a “motivated intruder” might still be able to identify individuals if they were to gain access. Data Protection law applies.
The first question is therefore which parties are Data Controllers and which Data Processors. Institutions that upload data into the platform (and presumably those that access and download it, if different) are data controllers, since they decide which data to upload and what purposes (within the platform’s technical and policy limits) to use it for. Where, as in in FutureFlow’s case, the platform operator does neither, it is likely to be a Data Processor. This suggests that in federated sharing platforms, where contributors can run their own instance of the platform and link it to others, the contributor function would dominate and those organisations would be Data Controllers. But a platform operator – like FutureFlow – that merely develops algorithms and runs them on others’ data may be a Data Processor.
Interestingly, although GDPR Article 35 only makes Data Protection Impact Assessments (DPIAs) a requirement for Data Controllers, the sandbox report suggests that a DPIA might be a good way for a Data Processor to document the risks it has considered and the security measures it has adopted to manage them (this is the approach that Jisc has taken with its
Learning Analytics platform DPIA
).
Using a platform to share personal data requires a legal basis, chosen from GDPR Article 6. Although financial institutions may have a legal obligation to prevent fraud, the FutureFlow report suggests that “necessary for legal obligation” (Article 6(1)(c)) is probably not the best choice. This is because the sharing platform “demonstrates maximum effectiveness when applied to a broad account base, prior to any firm indication that any accounts have been involved in suspicious activity”. Or, as we tend to express it in incident response, to identify malicious anomalies you need to know what normal looks like. At this “pre-suspicion” state, “necessary for a legitimate interest” (Article 6(1)(f)) is more appropriate, and brings the additional reassurance that each Data Controller must ensure its use of data is not just legitimate (for computer and network security this is likely to invoke GDPR Recital 49), but is not over-ridden by the impact on the rights and freedoms of the individuals involved. The platform’s DPIA should be useful in performing this balancing test.
Finally, one difference between FutureFlow and CSIRTs sharing platforms is that FutureFlow only appears to let institutions see their own data, with automated flags added by the platform. Incident response – at least at present – typically relies on more manual investigation, with participants likely to have some access to data uploaded by others. To reassure contributors that this increased risk is mitigated, platforms and the communities that use them may need to supplement technical and operational security measures with policies and/or legal agreements that ensure uploaded data will only be used in ways and for purposes intended. Where the platform offers a DPIA, such measures should be included there.
Originally posted: 10 November 2020 in category
Articles
The latest reports from the ICO sandbox provide important clarification of how data protection law applies to, and can guide, the application of novel technologies. This post looks at machine learning…
Onfido’s engagement
looked at how to train and review the performance of machine learning models. In thinking about that I’d concluded that the GDPR provided more useful guidance if you
thought of Training and Review as separate processes
from actually Operating the model. In Onfido’s case that’s a legal necessity, because its model operates as software-as-a-service, with the customer as data controller and Onfido as data processor. Customers aren’t involved in Training and Review – though obviously they want those to happen – so Onfido must be the data controller for those steps.
When thinking about a single organisation doing Training, Operation and Review, I’d suggested that there should be a primary legal basis for Operation, with the GDPR “research” provisions used as compatible extensions of that to Training and Review. That provides strong safeguards, notably that any impact on individuals must be minimised, justified by the benefits, and that there must be no possibility of using the resulting data to make decisions about individuals. Since Onfido is a data processor for Operation, it needs a primary legal basis for Training and Review: the sandbox report suggests Article 6(1)(f) Legitimate Interests. That provides safeguards that – you guessed – any impact on individuals must be minimised, justified by the benefits, and that (now as part of impact minimisation) there must be no possibility of using the resulting data to make decisions about individuals.
The details of the Onfido service raise a couple of other interesting issues. It supports banks – particularly in COVID times when it may not be possible to go into a branch to open an account – by verifying that a photograph of a face (typically from an ID document presented by the applicant) matches a current selfie – “are these the same person?” – and has not been tampered with. Training and Review are done with pairs of historic images and, perhaps, information about the origin of the ID document, but no information that would identify the individual. It might be argued that this is not personal data at all. But if the same individual were later to apply for another account, then Onfido’s data processor function might handle identifying information about them, bringing the training and review processes within scope of GDPR as well.
If the face pairs might be personal data, then it’s likely that they count as “biometrics”, and so will be classed as Special Category Data under GDPR. But since it has been widely reported that many
Machine Learning algorithms perform very differently
with faces of different racial types, there is an Article 9 basis that fits snugly and, again, provides strong safeguards: the “substantial public interest” in reducing discrimination.
In summary: a textbook example of how, if you are trying to do the right thing, a detailed study of data protection law will usually be a strong and helpful guide, rather than a barrier.
Perform an inventory of all flows of personal data to entities outside the EU;
Priority for change will be existing transfers with either no legal basis, those based on a derogation, and those to organisations “clearly subject” to the US FISA s702 or EO12333 laws and that involve large-scale or complex or sensitive data/processing;
A strong precautionary principle should be applied to new contracts, with institutions strongly encouraged not to enter into any agreements that involve transferring data to the US;
More detailed “Transfer Impact Assessment” questions will follow.
Since the EDPS works closely with national regulators within the European Data Protection Board (confusingly, the EDPB), we may well see those national regulators adopting a similar approach.
#457 - Health Data Partnerships: using trust to build trust
Originally posted: 29 October 2020 in category
Articles
This morning’s discussion – jointly hosted by the All-Party Parliamentary Groups on
Data Analytics
and
Health
– suggested that if we want uses of health data to be trusted, we need to trust citizens and patients to think more deeply about benefits and risks than media headlines might suggest. The session was inspired by a recent
Understanding Patient Data
study and report which used citizen juries and a survey to discover public attitudes to data partnerships between the NHS and researchers, charities and businesses.
The results indicate that both citizens and patients are keen to engage, and can quickly develop sophisticated understandings of benefits and risks in data partnerships. If we give them the chance…
The framing of the study must have helped, by asking what would a fair partnership look like? This encouraged contributors to range widely in their interpretations: fair to individual patients whose data may be used; but also fair between the health service and its current and future partners (benefits should not be locked away to commercial advantage), fair to the population (benefits should not be localised, either geographically or by community), fair to past patients (who almost always want their experiences to benefit others), and fair to future patients (who should be able to benefit from the experiences of those who have been treated before).
But opportunities to benefit from partnerships are not limited to patient data: providing health services also generates large amounts of administrative and operational data, and a growing amount from sensors. For example data has already been used to route supplies of blood products, which have a very short shelf-life, to places where they are most likely to be needed.
Since the study was completed just before the onset of the COVID-19 pandemic, panellists considered what had changed. Public awareness of the role of data has definitely been raised, with both good and bad experiences being explored by the media in more detail than might have previously been the case. COVID-focussed research has revealed surprising, and important, gaps in data: 26% of Electronic Health Records (EHRs) omit ethnicity, making them hard to use to determine whether this is a factor in the severity of the disease; long COVID is poorly detected by any quantitative statistics, and EHRs are not a good vehicle for capturing the qualitative data where this form shows up. Responding rapidly to the onset of the pandemic meant that a number of partnerships were set up quickly: as has been
suggested for education
we should be reviewing the policies, infrastructures and norms that those emergency measures encoded to ensure they are appropriate to maintain public trust in the longer term.
All of which seems to make the study’s recommendations even more relevant. Health is such a sensitive issue that trust will always be fragile and need to be continually re-earned. This requires good governance, accountability and meaningful transparency (see below). There is an expectation that citizens will be involved in decision-making, both about uses of personal data and anonymised, and an appetite to understand how data can be used for public benefit. Since it should also provide a wider perspective to reveal unexpected consequences, early citizen engagement should be a win-win. Even if full public consultation is not possible in a rapidly-changing situation, having citizens/patients as regular members of boards, panels and juries provides many benefits.
Communications are likely to be critical to trust in any partnership, and need to be developed alongside technology and health, perhaps even before. This is a specialist task, particularly given the need to address many audiences, who may want a simple reassurance or a deep dive. We need to be ready to invest in expert support, especially when circumstances demand communication needs be done quickly. We must be open about benefits and risks: citizens have now seen sufficient unsuccessful data projects to presume the worst if the latter are not mentioned, or if information is not available. But we should also celebrate the successful partnerships that have been going on for many years, perhaps not wishing to draw attention to themselves for fear of adverse publicity.
Communication and support is also likely to be needed within the health and research communities: if expectations, safeguards and red lines are not explained and understood then cautious interpretation is likely to be much more of a limit than law, policy or governance actually require. We need to get better at explaining what rules such as the GDPR already allow, why and under what safeguards, rather than letting them be cited as barriers. Here the virus response may provide a model, with simple Information Governance guidance being issued quickly, and cross-skilled teams assembled to work together on technical, legal, governance and communications requirements.
It seems to me that much of this is applicable far beyond the health sector. Especially the closing line: “regulation and governance are not barriers to responsible innovation, they allow it to go faster: like brakes on cars”.
Originally posted: 28 October 2020 in category
Peacasts
Jisc performs a number of different activities to keep Janet and customer sites secure. Here’s a very short video on how we used a Data Protection Impact Assessment and a Legitimate Interests Assessment to check that those activities do not themselves create disproportionate risks.
Originally posted: 20 October 2020 in category
Peacasts
Since it has provided the foundation for most of the work I’ve been doing on data for the past couple of years, I’ve recorded a video explaining our standard model for “analytics”, in both practical and legal terms
If you’d like to know more, a couple of papers set out the theory
Originally posted: 19 October 2020 in category
Articles
After a couple of years when the question of data location had dropped a little down the priority list, two things have pushed it back up again. First, the
Schrems II decision
of the European Court, which cancelled the US-EU Privacy Shield and added some – but it’s not yet clear how onerous – new duties to those relying on Standard Contractual Clauses (SCCs). And second, the 31
st
December deadline when the UK will
leave the post-Brexit transition arrangements
.
Furthermore, whatever the law or regulators say may be pre-empted by partners or individuals who are reluctant to have their data transferred to what they perceive to be less safe locations.
With so much uncertainty, it’s impossible to pick a single location and be sure it will be the “best” choice. But it may help to look at the things that, for each choice, could cause us to have to invoke “Plan B”:
UK hosting
: if data includes personal data about Europeans, could become problematic if UK and EU laws diverge significantly, since EU individuals, partners and regulators will expect their data to be held according to what might be non-local standards. As many large US companies have found, that can be an uncomfortable situation. If there is no adequacy decision, or if such a decision were to be successfully challenged in court, then transfers of personal data from EU organisations will need to be covered by Standard Contractual Clauses, and it’s not clear whether exporting organisations will be willing (or importing organisations able) to implement the additional checks required by Schrems II; it’s also worth checking how reliable a single-country cloud service is, as these are more likely to be subject to single points of failure, congestion, etc.
EU/EEA hosting
: could be disrupted if the hosting state’s regulator decided to consider the “fetching” of data to the UK as an export, but there has been no sign of this happening in the 25 years since it (arguably) became a theoretical legal possibility under the 1995 DP Directive; no Schrems II issue and, unless the UK Government changes its view that
the EU will continue to provide equivalent protection to the UK
, unlikely to be any Brexit one either;
US hosting under SCCs
: likely to be disrupted, for an unknown amount of high-risk data, when the ICO publishes guidance on Schrems II checks. Some transfers may be acceptable under an appropriate combination of technical controls (such as encrypted transfer) and type of receiving organisation (which will affect the protection available under US law): others may be judged too high risk to continue. Acceptability to individuals may not be the same as acceptability to regulators.
US hosting under Privacy Shield
: already illegal. Move to one of the above.
Originally posted: 16 October 2020 in category
Articles
To ensure a lively discussion at a recent round-table on AI Ethics participants were asked, provocatively, “was the A Level algorithm fair?”. OK, I can be provoked…
It depends on what you mean by “fair”…
As has been
widely discussed
, the main objective set for those who designed the algorithm seems to have been to reproduce the pattern of results that each school obtained in past years. In other words to be “fair” to
previous
years’ students, who can’t now be compared to a 2020 cohort whose different form of assessment might have resulted in a different pattern of marks.
What does not seem to have been a priority is “fairness” to
this
year’s students. They were mathematically unable to score better than their predecessors, even if their work might have indicated that they should. The range and distribution of marks within each school had to be the same as before, even if the level of achievement was different.
So, clearly, the definition of “fair” is something we need to discuss and decide on, long before we choose an algorithm, training data, etc.
A related question is whether technology is the “best” way to achieve a purpose. Here, again, thinking about what we mean by “best” can be very informative.
For example, are we trying to do something humans could do, but not at that scale? Or something that humans could do, but at greater cost? Or something that humans can’t do? Or something that humans could do, but not as consistently? As with “fair”, all may be valid choices, but they are likely to have different outcomes. Being clear about that from the start of a development should greatly reduce the risk of misunderstandings, mistakes and miscommunications later on: during development, deployment, operation, and review.
You may have spotted that I said “not as consistently”, rather than “not as fairly”. Creating, and sustaining, an AI that is more “fair” than the context within which it operates is
really hard
. There are just too many ways that existing unfairness can creep in: even the way we pose the question to be answered may contain implicit assumptions, training sets that do not contain a balanced representation of the population are a well-known issue, but what about unfairness in people’s ability to access the system or to act on its recommendations? That definitely doesn’t mean we should give up on trying to make our systems “fair”: doing so may actually be one of the best ways to highlight those real-world unfairnesses that society needs to address.
Originally posted: 15 October 2020 in category
Peacasts
On and off, I’ve been researching the legal aspects of incident detection and response for fifteen years, and published more than 25000 words in law journals. So, can that be summarised in less than five minutes? You judge…
And if you’d like to read more, here are the original papers:
Originally posted: 1 October 2020 in category
Articles
Alan Shark’s
SOCITM ShareNational
keynote looked at why regulation is not sufficient to deal with emerging technologies, and the complementary role that needs to be played by ethics.
Although privacy is not the only threat posed by such technologies, it does seem to be the one that has got people interested in the debate, whether over face recognition, tracking by apps, surveillance cameras, biometrics, smart “speakers” (actually, microphones) and deep fakes. It’s no longer just privacy activists who are worried about how much we give away to these and other applications, asking how long this is kept, where it is stored, who has access, who it might be shared with: who does, and who should, decide? The GDPR was called out as a leader in both its regulatory and ethical aspects.
Most technologies have the potential for both socially beneficial and socially harmful uses, so simple technology bans will have unintended effects: an Illinois ban on automated face-recognition makes it illegal to sell a robot dog that can recognise its owner. Whether this is an acceptable loss, or whether the law needs to be more nuanced, is an ethical question. Should we ban uses, rather than technologies? But then, how to define the uses: can regulation deal with the viral spread of conspiracy theories on social media and, if so, what levers should it apply? Again, a difficult, ethical question.
Although “AI” may be seen as the most urgent area to address, we need to break that term down. At least three categories can be identified:
Systems that analyse large datasets to derive (relatively) static general-purpose insights or capabilities: much of “big data” falls into this category along with things like speech and image recognition;
Systems that use individual data to inform human decision-makers. Perhaps “Augmented Intelligence” is a better term for these, since humans can – at least in principle – interrogate the system’s suggestion and ignore or override it;
Systems that make autonomous decisions, learn from what happens, and modify themselves. Here there may be no way to either predict or understand the system’s decisions or – depending on the effects of the decisions that were assigned to it – to override or reverse those consequences.
In the first of those the main focus of ethics is probably on the choice of application and data (the answers may then lead to graduated regulation, as in the GDPR/ePrivacy Directive) and how systems are trained and tested; in the second on ensuring that humans are actually able to make appropriate decisions; in the third ethics may identify domains and kinds of decision where we simply do not want to develop or deploy such tools.
And, though privacy is a good starting point, our ethical thinking needs to range wider, on both the technological and consequence sides. What happens if inaccurate data are fed into new technologies? Are assumptions reliable (e.g. that blockchain is immutable, even in the presence of market dominance)? Uses have been proposed – some already implemented – that could lead to bad decision making; loss of life or destruction of property; loss of justice (even if “perfect” judges were possible, could society cope?); irreversible decisions; distrust of Government and technology. We need to consider those risks as well as the benefits that the technologies might deliver.
For these discussions to take place, ethics needs to be recognised as a complementary tool to regulation. At the moment technology ethics is increasingly being included in HE science curricula; making it part of policy and public administration ones as well might help increase its visibility. Ethical review boards – by government, region or discipline – might examine emerging technologies and suggest an appropriate balance of ethical and regulatory tools for each. Standards, testing processes and certification of ethical engagement (in the whole development process, not just the operation of technology) might inform markets and, where appropriate, legislators.
Originally posted: 1 October 2020 in category
Articles
Allison Gardner’s keynote to the
SOCTIM ShareNational conference
last week highlighted how using AI responsibly is at least as much about how decisions are made as about the technology itself. Questions of “transparency” often focus on whether the AI is explainable, but how decisions were made – even how a particular problem was identified and chosen as appropriate for an AI solution – need at least as much transparency.
Humans are involved in many decisions: before, during and after the technology is put to work. How the question is framed, which data are made available to answer it, how those data are processed and cleaned, which features are selected, what weightings are given, which algorithms are chosen, what metrics are used to set objectives, how systems are deployed and how their results are evaluated are all human choices that will affect the results. So we need to understand what those decisions were, and why they were made.
Although AI supply chains may be complex – though hardly unique in this – the organisation that decides to deploy AI in a particular situation is responsible for what happens. They should be very wary of “black boxes”, which may conceal too much complexity or too little. A striking example of the latter is an “image analysis” tool that recommended treatment for hip fractures: on investigation it turned out that the patient’s age and whether the image was taken on a portable scanner carried much more weight than any feature of the X-ray. If data analysis finds that those
are
the key factors, fine, just tell humans that and avoid the expensive tech. Beware of explanations that simply assert “fair” or “accurate”: both have many different mathematical definitions, which are mutually exclusive: a system that is “fair” by one of them is very likely to be “unfair” by another measure. “Accuracy” figures can easily be improved by choosing the most common outcome. Make sure your system implements the one you actually need.
Interfaces are critical: they need to be clear, but avoid encouraging operators to over-rely on them. Finding a way to support operators and supervisors in exercising their professional judgement involves a very narrow line between causing them to doubt that judgement and, on the other hand, dismissing the machine as useless. Interestingly, this is an issue that goes back at least 500 years: the first printed books were quoted as “truth”, even though they were obviously internally inconsistent (for example using the same woodcut illustration for two different medicinal herbs to save money). Interfaces that seem to offer certainty can easily result in a “human in the loophole” situation, where decisions appear to be made by humans, but in practice they always follow the computer. Black boxes that don’t reveal the limits of their own skills are particularly dangerous.
Be realistic about bias. Automated systems will be biased, because they learn from a world that is biased. So make sure you have good processes to detect and correct it when (not if) it does emerge. More broadly, and excitingly: humans, and human-created systems, are biased; machines should be able to explain why they made particular decisions. So if we hold machines to higher standards of fairness, might we be able to use their explanations to learn about our own human biases?
Finally we need to think, and explain, what effects our introduction of AI may have on individuals and across the workforce. If decision-makers come to regard AI as the “expert”, does that limit the incentive, or possibility, to develop their own expertise? Or, perhaps even worse, could encoding current knowledge into an AI even limit the discovery of new knowledge across our domain? We need to find ways to get humans and machines working together – complementing each other – both at the level of individual decisions and in advancing our combined abilities.
#449 - “Digital Ethics”, or Ethical Digitalisation?
Originally posted: 29 September 2020 in category
Articles
Perhaps surprisingly – given that its title was “
Digital ethics
” – last week’s SOCITM panel session spent a lot of time exploring things that aren’t “digital”. Although the discussion focussed on local government, a lot of the ideas seemed relevant to education, too.
Don’t be solutionist: technology might not be the right option.
When identifying issues, might a survey be more effective than using “big data”? It’s probably is less privacy invasive and – unlike using existing data – you can work to make sure the results represent all of the affected community. Even in universities and colleges, disparate access to – and confidence with – digital devices means that data from digital services will not be representative. Working out
how
unrepresentative
after
data are collected may well be more effort than gathering a representative sample in the first place. And engaging with affected people opens up discussion about the actual reasons for behaviour, rather than assuming those can be inferred from observations.
When proposing solutions, again, actively seek out and work with those who will be affected. Start grounded and simple, both in the aims and how they are communicated. Take as much time as is needed to explain and understand: time spent at this stage should be more than recouped later in the development. And don’t be simplistic. Be open about risks, and invite dissenting views. Reduce the number of unanticipated (by you) problems at this stage, not after you have implemented the system. Late-2020 is a good opportunity to escape the idea that technology is, or can be, perfect! Be honest about the objectives – cost reduction or staff redeployment may be OK, but don’t dress them up as something else. Know how progress against those goals will be tested, and what will be done if things don’t work out as hoped.
When implementing solutions (whether digital or not) ensure this is done by a multi-disciplinary team, not just statisticians and technologists. And make sure this is genuine engagement, not just a tickbox. Even if you don’t formally adopt Agile methods, try to test and learn during development, not just after. And capture and share the lessons of failures, not just successes: the former are at least as valuable. Be willing to learn from, and build on, other communities, tools, and resources: starting from scratch shouldn’t be necessary. Every process will need to include some facility for human contact, if only to detect, remedy and fix when “computer says no”. And be open about when it
is
a computer – Amsterdam’s new “
Algorithm Register
” is an interesting approach, though as it grows I suspect it will need to become more granular to avoid enforcement support systems getting lost in a swarm of chatbots.
Don’t (just) think “digital ethics”: think “ethical process change”.
Originally posted: 27 September 2020 in category
Presentations
Thinking through an idea that occurred to me during our
SOCITM ShareNational
panel on ethical use of data and technology.
What happens if we explicitly think about “our spaces, which people use”, rather than “people that use our spaces”? That may seem like a semantic quibble, but I think it leads in three interesting directions:
First, space sensors are much simpler than people sensors. Even before lockdown, Jisc colleagues were looking at
CO
2
monitors
and low-resolution infrared cameras. Now: might that be enough to work out when a room needs a period of ventilating to reduce the virus load or, longer term, which rooms we need to reduce effective capacity to prevent dangerous (or, in normal times, sleep-inducing) levels of human exhaust building up; might those fuzzy pictures be analysed to work out the gaps between warm bodies (and whether they are stationary or moving) and let us identify places where we need to improve traffic flow (a
Microsoft video
suggests how this might work)? Simple messages and low data rates might mean we can dispense with power and network cables, and just use battery and (low-power) wireless for sensors that can be quickly deployed to any location where there is a concern;
Second, space sensors are much less of a privacy threat than people sensors. If we explain them – maybe even show examples of their output – then we should be able to calm fears of surveillance. Similarly with data, if we look for data about spaces, rather than people, we should be able to discard a lot of the identifiers that raise dataveillance concerns;
And third, building on these two. Thinking about spaces seems to lead naturally to measures that involve improved design: thinking about people may be more likely to tempt us towards measures that involve enforcement.
Spaces are something we all use. Using sensors and data to improve them should benefit everyone. Maybe thinking about spaces can help build a sense of shared community, rather than a divide between campus managers and campus occupants?
Originally posted: 25 September 2020 in category
Presentations
When I was invited to join a panel at the
SOCITM ShareNational event
for local government I presumed my role was to provide a different, external, perspective on “Ethical Use of Emerging Technologies and Data”. So I offered to contribute a five-minute “sparkler” introduction: a bit of illumination, some striking of ideas, maybe a smile. In fact, the conference programme was already buzzing with new thinking (there will be lots more blog posts next week), so I didn’t need to add to that. Here’s what I would have said…
Over the past decade or so my job has been to work with Jisc colleagues to ensure the networking and analytics services they want to provide are “lawful”. More recently, they’ve been asking about “ethical”. But maybe what we actually need is “comforting”. That’s different, because it’s about how
others perceive
those services, not how
we think
about them.
We need to talk…
A couple of phrases I don’t find comforting. “For the Greater Good”. So why are you throwing me under a bus? Aren’t there sufficient ways to use technology and data that benefit everyone?
Perhaps more surprisingly. “Individual Control”. Why would that be important if the proposal is a no-brainer? Too often “individual control” is a sign of laziness – we can’t work it out, you do it. We should be working together to find those no-brainers; then use individual control to find and address situations that couldn’t have been foreseen, not as a belated acceptance test to discover we built the wrong thing.
So be careful about digital volunteering. It might help, but it might also amplify digital divides into visibility divides. I was shocked to discover that when I assume “students have smartphones” I’m actually
missing 1 in 6
.
An example: I love the idea of an app that uses phone accelerometers to
detect and report potholes
. So cool! But… What about drivers who don’t have phones? What about cyclists, pedestrians and residents, who may welcome potholes as informal traffic-calming measures? Does that app actually identify desire lines and divert scarce resources to building smooth rat-runs?
I’ve been using four questions to explore new ideas for data and technology.
Will it help? Do we have a process that would be improved by any signal the data might produce?
Will it work? Will there be a sufficiently accurate signal, or am I relying on false assumptions about technology or behaviour?
Will it comfort? Or will I be perceived as Big Brother?
Will it fly? What are the broader effects on the community and society?
As a colleague observed, after exam results and virus testing, probably more people than ever before now have
personal experience
of the discomfort caused by inappropriate use of data. If we can use that engagement opportunity to move the discourse from “mutant algorithms” to pride in how our community uses technology then we’ll have salvaged something really valuable from 2020.
[UPDATE 8/1/21: the “four questions”, and how they might be used in practice to assess ideas for data (re)use, became the subject of a peer-reviewed paper – “
Between the Devil and the Deep Blue Sea (of Data)
” – published by the Journal of Law, Technology and Trust]
Originally posted: 22 September 2020 in category
Articles
A
panel on Algorithms
at the
UK IGF
asked whether the summer of 2020 was a catastrophe – “mutant algorithm” having entered political discourse – or an opportunity to work with a population that is now
much more aware of the personal significance of the debate
? “Transparency” is often cited as a remedy, but we now know that knowing how an algorithm works is far from sufficient: we need to know much more about how and why it came to be doing that job.
Viewing the “algorithm” space as multi-disciplinary, and building on existing work on (open) data, data (science) ethics, and governance/procurement can take us a long way. Indeed, a lot of what is perceived as an “AI Governance/Ethics” is actually data Governance and, as I’ve previously written, is
already addressed in tools such as Data Protection Impact Assessments
.
On
Data
, responsible use is the backbone: without trust there will be suspicion, with it there will come licence to innovate. But even perfect data wouldn’t guarantee a perfect outcome: we also need to look at behaviours, understandings, rules. Are we competent users of data, in the sense that we ask the right questions, apply emotional/social/political intelligence and domain knowledge? Are we working within trusted systems – institutions as well as algorithms, trusted as well as trustworthy – does the organisational culture encourage critical opinions, diverse viewpoints? Our processes and tools must be sustainable, in the sense that they respond appropriately to unforeseen situations. It was suggested that the A-level issue was so significant because those exams are so critical to social mobility: a societal issue, not a technological or legal one.
On
Ethics
, version 3 of the
Government’s Data Ethics framework
has just been released. This has three Principles – transparency, accountability and fairness – and five detailed Specific Actions – define and understand public benefit and user need, involve diverse expertise, comply with the law, review data quality and limitations, consider wider policy implications. The framework is likely to be used initially as a gateway for individual projects, but is designed to promote organisational change by developing skills, providing feedback and user stories. But, as with data, we need to prepare for imperfection. Algorithms will inevitably reflect existing societal biases: we need to be humble, to accept that, plan to mitigate harms and fix flaws. And be trusted to do so. Part of that is to ask whether data/apps are the right solution for a particular problem: might it be better to just talk?
On
Governance
inviting help from the public and experts is essential to picking the right problems and solutions, and to building trust in what we do. Here Open Government approaches – deliberation, participation, citizen assemblies, dialogues, citizen participation and feedback – are worth considering. We must achieve shared goals and understanding: applying data or technology to a problem that isn’t agreed or understood is likely to just amplify those disagreements. Definitions are critical: OFQUAL’s algorithm may have been “fair” across cohorts, but amplified social unfairness to individuals. Two practical tools were mentioned: AI Now’s
Algorithmic Impact Assessment
and AI Global’s
AI Design Assistant
. Governance must provide effective oversight of the whole life-cycle of a system: information gathering, monitoring/response, review/improvement. When procuring a system or service, ensure that your requirements for values and transparency match what the supplier is offering. Check that their Governance frameworks are compatible with yours. And be clear about the respective responsibilities of supplier and procurer/user.
Finally, a couple of thoughts on
Explanation
. There’s a useful distinction between “interpretable” systems, where a domain expert can understand what it is doing, versus “explainable” ones, where an individual can ask why it reached that conclusion for them [it occurs to me that I was
trying to get at this distinction
, without having the terminology, a couple of years ago]. Counter-factuals may be useful for the latter: what would need to change for the result to change? But such a “contrastive” explanation must also be “selective” (a limited number of things) and allow for a “social” dialogue asking what-if questions. And explanation can have a much deeper role: by holding algorithms to a higher standard than human decision-makers, we may learn about our own biases, too.
Intelligent Campuses use existing data and new sensors to deliver better places to study, work, live and socialise. But there’s a risk with any use of data or sensors that even the best-intentioned ideas will be misused or misunderstood: as inappropriate, intrusive or even surveillance. Data Protection law suggests – may even require – conducting a Data Protection Impact Assessment (DPIA) as a way to understand risks to individuals, to explore less intrusive ways of achieving the objective (or conclude that it cannot be achieved with acceptable risk), and to implement appropriate safeguards. There are plenty of guides to how to conduct a DPIA, but it may be hard to work out how to apply these to a specific domain, especially when that is as novel as the intelligent campus.
Our toolkit aims to fill that gap, by providing domain-specific help on how to assess intrusiveness, the risks to consider, and the controls and mitigations that might help to reduce those to, and keep them at, an acceptable level. It was inspired by a DPIA template for RFID applications that was approved by European Regulators back in 2011, and informed by
lots of presentations and conversations with many people
. Thanks for all your inputs!
If you’d like to know more about the background, there’s a peer-reviewed paper – “
See no… Hear no… Track no… Ethics and the Intelligent Campus
”. But the toolkit should contain all you need to use it. I’d very much like to add a collection of experiences, case studies and similar supporting material, so please let me know how you are using it.
Originally posted: 17 September 2020 in category
Articles
A
panel on “Building Trust in a Digital Identity”
at the
UK IGF
may have raised more questions than answers, but at least highlighted why doing so is taking so long. Since terminology can be confusing, what was being discussed was how to prove facts about your real-world self to an online service: for example to claim a furlough payment, or to gain access to an age-restricted site.
Why do we want to?
Those two examples immediately throw up the first challenge: why would we want to do this anyway? Digital identities are already used effectively to pay TV licences or tax a car; somewhat less so to pay income tax. But these Government services are things we have to do, not things we choose to. It’s hard to get excited about them, and a successful digital identity (eco)system needs customers to want to use it. Takeup of digital identity in services of choice – mostly in the private sector – has been much slower.
That may be partly a question of what “identity” is actually needed. Government services typically do need to know (at least indirectly) the name and address of “who” they are dealing with. Commercial services may be more interested in “what”: how old or – perhaps an unconscious reference to a
Jisc service
– whether it has a degree. It’s possible to combine the two functions, but not clear to me how much incentive there has been to do this. And, of course, the more data and functions a service offers, the harder it has to work to maintain trust that those will be protected against misuse. And, although the painful experience of high-quality account linking may be acceptable for a handful of Government services, would someone volunteer to go through that for a dozen or more commercial ones that they may only use occasionally? It would be nice to make the process easier, but that runs the risk of increased fraud.
Who (else) could do it?
Outside Government, the kinds of organisations that know enough about us to make a secure link between real world and online identities may not be the ones we (either as consumers or as service providers) want to rely on. Data brokers and others whose business model relies on data reuse probably aren’t the best foundation for a trusted identity service. Is there a risk that a socially-important function will be cross-subsidised by activities whose lawfulness is questionable; or, that those activities would be legitimised by the parallel use? We need to look very closely at business models and, at least, be prepared to pay enough (either directly, or via increased costs of services) for the identity functions to discourage providers from reusing data in the short term, and to remain in the market (since many service providers are going to rely on them) for the long term. The adtech industry was cited as a warning where both customers and services may be harmed by dependency on a “free” offering.
An opposite problem arises if we rely on device manufacturers to provide identity services. With control over everything from applications down to hardware, these can provide state-of-the-art privacy protection. Indeed one of the complaints about device support for contact tracing apps is that its privacy protection is better than public interests might wish. Here the problem – for both individuals, software developers, and nation states – is control. Who chooses what privacy-protecting identity services exist, and to whom they are made available?
Do we need a market, or a regulated infrastructure?
It’s possible to imagine a world where interoperable, standards-based, identity services compete for business (on functionality, privacy and cost, among other things). But such a market definitely isn’t where we are at present, and it’s not clear that it would ever be stable anyway. Identity services are intermediaries in multi-sided markets, and those gatekeeper functions have a strong economic tendency to tip to a dominant provider (video-conferencing, through which the conference took place, is a rare counter-example!). Should a government be comfortable with a market-dominant Identity service – which, if all goes well, will be a keystone of online society – that may decide to change or withdraw its offering for commercial or geopolitical reasons?
Or should nation states recognise that identity provision is a (inter-)national infrastructure and regulate it as such, for example to mandate access for SMEs? Although this might appear attractive, the history of regulating global tech companies suggests that only the largest states or groupings (e.g. the US or EU) have much chance of enforcing their will. And, while enforcement against economic monopolies has had some success, information monopolies seem much harder to control. Not least because the desired outcomes are much harder to identify and agree.
We must beware of mission creep and perverse incentives. COVID “passports” are a timely example. If employers insist that only proven-healthy workers can return to the office, does this create an incentive to intentionally catch the disease (currently the most likely way to demonstrate immunity)? When I was a child it was normal for parents to try to expose children to mumps, measles and chickenpox, because the likely consequences of infection later in life were much more serious! Or, if a disease turns out to be more prevalent in some communities, does such a requirement create indirect discrimination or reinforce deprivation?
And finally, remember the “three Ds”: devices, documents and disadvantage. If we rely on a portable device to carry our identity, what happens to the 16% of students who do not have a smartphone? Where we need documents to establish even our real-world identity, what happens to people who do not have either a driving licence or a passport (24%, and higher among young people); what alternative proofs might they offer? And how to include those who may be disabled from using these systems, either because of medical or social disadvantage, or for lack of the first two Ds?
Originally posted: 15 September 2020 in category
Articles
Lilian Edwards gave a fascinating keynote at the
UK IGF
this morning, on
Protecting Digital Rights During a Pandemic
. Though privacy is the most often discussed right in the context of pandemic response, rights of free speech and free assembly also need to be borne in mind.
Although the impact of national schemes (contact tracing apps, etc.) has been widely discussed, how we respond to the virus in re-opening workplaces may be at least as significant for individual rights: not least because employers can invoke a wider range of permissions from data protection law. Will our response to COVID-19 accelerate an existing trend towards workplace surveillance, through the re-purposing of existing sensors and controls such as CCTV, swipecards and smartphones? Might employers feel justified in compelling employees to run, and provide access to, a location-recording app to gain entry to the office? Or, might some even refuse access to those who have chosen to run a social distancing app? What are the effects on our rights – and those of family and visitors – if employers insist on extending these into our off-work time, or our homeworking space? Or can we use the pandemic as an opportunity to demonstrate good practice in how we choose our purposes and technologies?
Considering university campuses as a possible testbed for developing good practice, it’s clear that there are many options to choose from (all these examples have appeared in the press in recent weeks). Even slight modifications to how we think about purpose could make new technological available, and have significant benefits for rights. For example, rather than individual testing to pick up early signs of an outbreak – which affects privacy and uses testing resources inefficiently – could samples be pooled before analysis? If students are expected to live and learn together, it doesn’t matter which member of a “study bubble” tests positive: all need to isolate anyway. Or could we test wastewater and avoid bodily intrusion entirely? If we think of social distancing as an issue about spaces, rather than about people, then many more sensors become available: blurred CCTV images can be effectively anonymous, but still let us measure the distance between bodies; even atmospheric CO2 level might be used to detect when there are more people in a space than is safe. Now we can avoid discriminating against the 1-in-6 students who does not have a smartphone, leave those who do have one with a free choice how to use and when to carry it, but still inform campus users of spaces and behaviours to avoid.
Adjusting how we think about the problem could be a win-win. If we aim low – in the sense of rights infringement – then we are likely to get greater participation (or less resistance) and end up with more accurate, relevant information on how to stay safe.
Originally posted: 11 September 2020 in category
Peacasts
Colleagues set me the challenge of saying something about my work in one minute. So here (on YouTube) is a “peacast” – my wife says it’s too small to be a “podcast” – on Brexit and GDPR:
Comments very welcome on the format and, if you like it, suggestions for any other topics I could cover in a similar way. I am also working on a five-minute format, which allows more in-depth exploration!
As part of Jisc’s exploration of Artificial Intelligence, we’ve created a free “mini-MOOC” (mini, because you should be able to complete it in 30 minutes, or longer if you do the additional reading). We’re planning to run it monthly, but you can
sign up
any time for the next run.
The course, and the format are both new, so we’d really welcome your feedback. There’s a comment form at the end of the course, or you can comment on this blog post.
If you’re interested in Artificial Intelligence, and have half an hour to spare, Jisc’s new “mini-MOOC” is designed for you. We hear a lot about how we should be worried about “AI”, usually illustrated with an image from Terminator. But most of us frequently use AI, without even noticing, to do things that would have seemed impossible just a few years ago. Through videos, articles and exercises, the course explores why that might be. We hope it’ll help you think about your own uses of AI and how you can make them more likely to be perceived as useful rather than creepy. And if you haven’t got a whole half-hour, you can even split the course into four shorter chunks!
This mini-MOOC is open to all learners from Jisc member institutions. The MOOC includes commenting on other students’ posts, so we are granting access in “waves”, so that there is a group passing through together each month. We hope this will encourage you to discuss your ideas. This may mean that there is a short wait between applying to do the course and being granted access. We’ll advertise the next starting date (usually the start of the month), in case you need to plan.
We currently have an enrolment limit for each “wave”. If you’re from an eligible Jisc member institution you will be accepted as soon as we have space; we appreciate your patience in awaiting the confirmation email.
#440 - BEREC Net Neutrality Guidelines: good news for security
Originally posted: 18 August 2020 in category
Articles
BEREC, the board of European Telecoms Regulators, has just published its updated
guidance on enforcing the Network Neutrality Regulation
. Jisc has been working with the Forum of Incident Response and Security Teams (FIRST) for nearly five years to ensure that this legislation and guidance didn’t discourage legitimate practices to secure the operation of networks: this new version suggests our advice has been heard and taken.
Article 3(3) of the Regulation permits “blocking, slowing down, altering, restricting, interfering with, degrading or discriminating” only in three specific circumstances, one of which (covered in Article 3(3)(b) is where this is necessary to “preserve the integrity and security of the network, of services provided by that network, and of the terminal equipment of end-users”.
The new guidance (para 83) identifies “typical attacks and threats that will trigger integrity and security measures”:
flooding network components or terminal equipment with traffic to destabilise them (e.g. Denial of Service attack);
spoofing IP addresses in order to mimic network devices or allow for unauthorised communication;
hacking attacks against network components or terminal equipment;
distribution of malicious software, viruses etc.
Paragraph 84 lists “typical examples of … traffic management measures”:
blocking of IP addresses, or ranges of them, because they are well-known sources of attacks;
blocking of IP addresses from which an actual attack is originating;
blocking of IP addresses/IAS showing suspicious behaviour (e.g. unauthorised communication with network components, address spoofing);
blocking of IP addresses where there are clear indications that they are part of a bot network;
blocking of specific port numbers which constitute a threat to security and integrity.
Paragraphs 85 and 86 note that the need to enable for such measures might be identified by the network’s own monitoring, or by reports/complaints from end-users or blocking lists from recognised security organisations.
And, as discussed in the earlier
post on the consultation paper
, paragraph 85 also explains why permanently configured blocks, such as for BCP-38 spoofing, do not contravene the Regulation’s “only when needed” requirement, as the block only takes effect when an offending packet is seen.
Although the Regulation doesn’t apply to Janet and private networks within our customers, it’s good to have such explicit confirmation of our security practices. If other networks follow them, then there should be less hostile traffic for us all to deal with.
Originally posted: 12 August 2020 in category
Articles
Might some of the problems in applying data protection law to machine learning arise because we’re using too simple a model? Sometimes an over-simplified model can be hard to apply in practice. So here’s a model that’s a bit more complex but, I hope, a lot easier to apply. It’s also a lot more informative, especially about what data we should be using, about what people, and for how long.
This views a machine learning model as having four stages:
Development, where we decide which features are of interest, which algorithms to use, etc.;
Learning, where algorithms decide what weights to give to each feature;
Use, where we apply the model to real data and situations;
Review, where we consider how well the model worked.
These form a cycle: review may trigger a new round of development, learning, etc. There may also be shorter cycles within the loop – iterating between development and learning when we discover that we chose the wrong features or algorithms, for example – but I haven’t shown those in the diagram.
GDPR model for Machine Learning
Each stage has different requirements for the data it uses, so they should be considered separately under data protection law (that law definitely applies if machine is learning about people, though the same model seems to work well even if it isn’t). In particular, this approach suggests there may be a nice balance between the quantity of data required at each stage and the safeguards that can be applied: stages that need more data may also be able to apply more safeguards.
Note that, at a higher level, the ICO has new
Guidance on AI and Data Protection
, covering Governance, Accountability, Lawfulness, Fairness, Transparency, Security, Data Minimisation and Individual Rights.
Development/Feature Selection
This stage needs a broader selection of data than any of the others, precisely because one of its roles is to identify and eliminate fields and sources that don’t provide sufficient useful information for the model’s purpose. Here, we need a representative set of data, but it may be acceptable for those data to be less than comprehensive, so long as they include the features likely to be relevant, and a representative range of subjects. It should be possible to use pseudonymised data for feature selection, and there should be no need to keep the data after the model has been constructed.
A wide range of GDPR lawful bases could be used for this stage: in education the most likely are probably
Necessary for Contract
(if the model is part of the contracted service),
Necessary for Public Task
,
Necessary for Legitimate Interests
, and
Consent
(provided we ensure the resulting data are still representative). If the institution already has the required data for some other “necessary for…” purpose then the “statistical” provisions may be worth considering since these provide helpful guidance on how to maintain separation between the purposes and avoid creating risks to individuals.
Learning
This stage uses the reduced set of fields identified in the Development stage, but it is essential that the data in those fields be comprehensive and unbiased. To reduce the risk of learning discovering proxies for protected characteristics (typically, those covered by discrimination law), we may need to include data about those protected characteristics at the learning stage. Again, it should be possible to use pseudonymised data for Learning, and it should not be necessary to keep the data after the model has been constructed.
Here, Consent is less likely to be an appropriate basis, because opt-in data is likely to result in models that recognise those who opt-in. Again, the statistical provisions are informative.
Use
Here we apply the model to real people and situations, usually with the aim of providing them with some kind of personalised response. We probably need all the fields that were identified in the Development stage, though Learning may have identified some that are less important (or are correlated with others) so can be eliminated. The model should, at least, recognise data records that are too sparse to be reliably usable. Here the data does need to allow identification of, or personalisation to, an individual, so pseudonyms are unlikely to work. But allowing individuals to self-select whether, or when, the model is applied to them is much less of a problem. And tight time-limits on how long we keep data should be possible.
Finally the Review stage will need to include historical data – what actually happened – and may need additional information about outcomes that was not relevant to the Use stage. It should be possible, however, to protect this wider range and duration of data by either pseudonymisation or anonymisation.
The review stage is likely to process some data on the basis of
Consent
(from individuals who are either particularly happy or unhappy with their treatment). However this must be balanced with a representative selection of data from those who do not respond. Sampling should be possible, even desirable, as a safeguard. It may be necessary to use
Consent
for this as well (for example if the only way to discover outcomes is through self-reporting), but if the institution already has the data needed for Review then
Necessary for Public Task
or
Legitimate Interests
may be more appropriate ways to achieve the required representativeness.
Summary
The following table shows how this might work…
Stage
Who
What
How long
Safeguards
Main legal bases
Develop
Representative of the population
Potentially relevant to the model’s purpose (largest set)
Till model built
Pseudonym/
Anonymous
Contract,
Statistics,
Public task, Legitimate interest, Consent
Learn
Comprehensive coverage of affected population
Relevant (as identified by Develop). May also need to check discrimination
Till model built
Pseudonym/
anonymous
Contract,
Statistics,
Public task, Legitimate interest
Use
Voluntary, either as part of a contracted service or by specific consent
Informative (may be less than Learn if model can cope with null entries)
Originally posted: 11 August 2020 in category
Articles
We’re delighted to have launched our Wellbeing Analytics Code of Practice, something we’ve been working on in the
ICO’s Regulatory Sandbox
for almost exactly a year. The resulting Code builds on Jisc’s widely-used
Learning Analytics Code of Practice
and includes tools for Data Protection Impact Assessment and Purpose Compatibility assessment. We hope it will give students, staff and institutions confidence that data-informed wellbeing support can be provided safely. You can download:
Originally posted: 7 August 2020 in category
Articles
A couple of new documents provide ideas on how to think about ethics when we deploy Artificial Intelligence.
First is an article by Linda Thornton for EDUCAUSE, on
Artificial Intelligence and Ethical Accountability
. This looks at who should be thinking ethically, finding responsibilities for programmers, managers, marketers, salespeople and organisations that implement AI. Since this is an EDUCAUSE article, it focuses on Higher Education Institutions in their role as purchasers of AI, and proposes a five-step approach – with lots of references – to selecting and using AI ethically.
Second is the latest document from the European Commission’s High-Level Expert Group on Trustworthy AI (HLEG): the
Assessment List for Trustworthy Artificial Intelligence
. This has specific questions relating to each of the seven requirements set out in the HLEG’s
Ethics Guidelines for Trustworthy AI
: Human Agency and Oversight; Technical Robustness and Safety; Privacy and Data Governance; Transparency; Diversity, Non-discrimination and Fairness; Societal and Environmental Well-being; and Accountability.
The authors note that answering these questions should involve discussions among a multi-disciplinary team: given that the questions range from whether the AI is likely to become addictive and its effect on the environment and “other sentient beings” to technical questions about the security of data and the stability of algorithms in the face of data attacks, those would be fascinating meetings to be involved with.
One oddity is that, whereas I’ve previously noted that GDPR compliance seemed a good (and, if using personal data, essential)
starting point for the HLEG requirements
, this Assessment list seems to take things the other way around, suggesting that the GDPR is a useful source when completing the assessment. “Protect[ing] personal data relating to individuals in line with GDPR” is mentioned, but only as one of the things that “might” be included in a prior Fundamental Rights Impact Assessment.
That seems to run the risk of missing both useful guidance and legally-required measures. For example there’s no mention under Transparency of the information requirements in GDPR Articles 13 & 14; nor in Accountability of the overlapping GDPR Principle of the same name. Even more fundamentally, there’s no mention of the need to define a legal basis (GDPR Articles 6 & 9) for processing personal data, nor to check purpose compatibility when reusing data. Those may be challenging for some AI systems – though perhaps not as challenging as is sometimes claimed – but that can’t be a reason to ignore them.
Originally posted: 29 July 2020 in category
Articles
The recent
Schrems II
decision on Standard Contractual Clauses
found that, in some situations, data exporters and importers might need to agree additional measures beyond just relying on SCCs. While we’re waiting for the
Information Commissioner
and
EDPB
to give more detailed advice on which situations and which measures, here are some themes I’ve spotted in articles and webinars:
Those additional measures can’t be contractual in nature, because the problem identified in
Schrems II
was that the US Government was not bound by any contract that a US organisation might enter into;
The concern still seems to be with personal data that is physically moved to the US, not merely put within the technical reach of US companies. The
laws quoted in paragraphs 60-63 of the judgment
as giving the US Government power to access data despite contractual protection appear to be limited to particular physical locations;
Additional measures could be in the form of laws of the foreign state, since these
could
bind that state’s Governmental authorities. Interestingly the judgment mentions GDPR Article 45(2)(a), which covers “both general and sectoral” laws as something that should be taken into account in an adequacy decision or, now, what I’m thinking of as an SCCplus discussion. Since the US does have a sectoral privacy law covering educational institutions – the
Family Education Rights & Privacy Act (FERPA)
– this might be something to discuss with the recipient if you are exporting to a US university or college;
Additional measures could be technological, if they protect against the foreign Government’s legal powers.
Encryption
has been mentioned as an option. This clearly works best if the exporting organisation controls the encryption throughout, for example if storing encrypted backups on an IaaS cloud server;
But, as far as I can see, there’s no requirement for a single measure to cover the whole transfer of data. So, for example, you might argue sufficient protection was provided by a hybrid solution that used encryption to technically protect data as it flowed over public networks into (and back from) an enclave that was protected by law.
I’ll update this post as and when there’s any more detailed guidance from regulators.
On July 16
th
2020, the European Court of Justice made its long-awaited decision in the case of
Data Protection Commissioner [Ireland] v Facebook Ireland Ltd and Maximillian Schrems
, generally known as “Schrems II”. This concerned two of the GDPR’s mechanisms for transferring personal data from the EU to other countries: Standard Contractual Clauses (SCCs) and the US Privacy Shield. This is relevant to organisations in the UK for two reasons:
SCCs and Privacy Shield were options available – both now and after we leave the EU – for transferring personal data
to
third countries;
After we leave the EU, SCCs are one of the options that may be used to receive data
from
EU countries.
Taking the Court’s summary of findings (see the very last section of the judgment – p61 of the PDF) in reverse order, for clarity:
Point 5:
Privacy Shield
is invalid because it does not protect against US surveillance laws which do not provide safeguards equivalent to the EU requirements for proportionality and judicial redress.
Point 4:
SCCs
are still valid (para 149) and sufficient to ensure the recipient organisation provides adequate protection (para 124), but…
Point 3: …since a contract cannot bind the authorities of the receiving state (para 125), National Regulatory Authorities (and data exporters)
must
also examine the legal environment into which transfers under SCCs are made, and
must
stop/order suspension of individual transfers where that environment does not offer sufficient protection;
Point 2 – In particular (para 129), where data transferred under SCCs may be accessed by the receiving country’s public authorities, the legal framework covering that access must be assessed on the same basis as when the Commission makes (or doesn’t) an adequacy decision (including rule of law, relevant legislation, independent supervisory authorities, international commitments, etc. Para 45(2)) is full list).
I think that means
Watch ICO for indications of which transfers
from
UK to US are likely to raise concerns under SCCs; review yourself any transfers that might need additional safeguards.
Post-Brexit, unless the UK receives an adequacy decision, SCC transfers
to
the UK may be investigated/stopped by any EU regulator if they feel UK law does not provide adequate protection in case of access by authorities. Such decisions must be taken by individual regulators, but may be discussed by the EDPB.
SCCs are still valid and worth including (both when exporting and importing personal data) as they continue to ensure the recipient organisation provides adequate protection.
But exporters and importers also need to consider whether additional protective measures are needed in case of access by authorities (note, for example, that transfers of student data to US institutions – unlike the transfers within Facebook that were the subject of the case – are likely to be covered by FERPA when they get there). Document these decisions, in case they are challenged. It’s also worth reminding (and expecting to be reminded) of SCC Clause 5(b)’s obligation on importers to inform the exporter if national law has a substantial adverse effect on their ability to comply with the contract. And have a process ready for receiving/sending such notifications.
If an exporter or a Regulator decides a data flow isn’t safe, the only option seems to be to change the flow. Para 132 makes clear that a contract can’t fix the problem, because it doesn’t bind the national authorities. But Para 112 considers “all the circumstances of the transfer of personal data in question”: Bird & Bird suggest that
encryption, tokenisation and other technical measures may be relevant circumstances
.
Finally, my attention has been drawn (thanks!) to the excellent “
EU-US Privacy Shield, Brexit and the Future of Transatlantic Data Flows
”, published by UCL’s European Institute in May – after the Advocate-General’s advice to the ECJ has been published but before the Court ruling. Highly recommended if you want to know more about the legal and practical background, the options available to the Court, and the implications for post-Brexit EU-UK data flows.
When I submitted my proposal for a
talk at the EUNIS 2020 conference
, I was planning to talk about the need to work with staff and students to agree
why and how to use intelligent campus sensors and data
. That was intended to be looking into the future, but in the past three months it has become much more imminent. As campuses re-open after COVID-19 lockdown, data and sensors seem likely to play a significant part.
Most universities seem to be planning to use a hybrid model
, where most students and staff are present on campus but use on-line tools for large-scale activities such as lectures that may be unfeasible under social distancing requirements. That combination is likely to give institutions an unprecedented amount of data: they may well have access to data from
both
the connectivity layer (wifi, logins, etc.) and the application layer (VLEs, video-conferences, etc.). Under normal circumstances they would have application data about remote students and connectivity data from on-campus ones. During the return to campus stage of the virus there may well be additional purposes for which institutions might consider using that information: from planning and managing social distancing to supporting those who may need to self-isolate on campus.
However it is important to remember that both staff and students are likely to be highly stressed during this period. Wikipedia defines “
technostress
” as the “result of altered habits of work and collaboration that are being brought about due to the use of modern information technologies at office and home situations”. That’s exactly what most of us have been experiencing for three months or more. Additional uses of data could easily be perceived as surveillance, rather than support. Even before the virus outbreak, student and staff wellbeing was a concern in many countries. We must be particularly careful that anything we do (or might be perceived as doing) does not make that worse.
In such an environment, it seems particularly important to achieve consensus among all those involved before taking action that, if misinterpreted, might do more harm than good. In particular, we must agree which uses are temporary measures that will be regularly reviewed and terminated when they are no longer required by a medical emergency.
Originally posted: 8 July 2020 in category
Articles
It seems a long time since I wrote about the
ePrivacy Regulation
. This was
supposed
to come into force alongside the GDPR, back in May 2018, and provide specific guidance on its application to the communications sector. You may remember it as “Cookie law”, though it was never just that. Unfortunately its scope grew and, for at least the past eighteen months, discussion among Member State Governments has been going around in (sometimes increasing) circles.
Germany took over the EU Presidency last week, and on Monday published what looks (mostly) like a
decisive approach to the outstanding issues
. They have summarised (nearly all) the issues in three questions to be discussed at a meeting in a couple of weeks’ time (my summary, though theirs aren’t much longer, once you discount the strawman sections of legislation):
Particularly in the light of COVID-19, should there be sector specific rules on processing communications metadata for health purposes, or can we just rely on the GDPR “vital interests” justification and safeguards?
Should there be sector-specific rules on processing communications data for purposes others than security, service delivery, etc., or can we just rely on the GDPR “legitimate interests” justification and safeguards?
Should there be sector-specific rules on accessing terminal devices (e.g. to install security patches), or can we just rely on the GDPR “legitimate interests” justification and safeguards?
So far, so good. But, several presidencies ago, it was noticed that any law on how networks could process communications data and content was likely to have an impact on how networks detect and block illegal content, in particular child abuse imagery. Alarmingly, although the Presidency thinks it can assume that all Member States think those activities should continue, it seems that “elementary questions” on the correct legislative approach to achieving that “remain highly controversial”. So that discussion is postponed to “a later date”.
Finally, note that we are still in the process of European
Governments
coming to a shared agreement on what the legislation should look like. Once they’ve done that, they still need to negotiate with the European
Parliament
(which
reached its opinion two and a half years, and an election, ago
) to find a mutually agreeable text. Not quite so long ago, the UK Government indicated that, despite Brexit, it was minded to follow the European lead. But when there might be such a lead to consider is still a very open question.
Originally posted: 1 July 2020 in category
Articles
An interesting virtual water-cooler discussion with colleagues who are exploring the potential of AI as a Service. They tested a selection of easily available cloud face-processing systems on a recording of one of our internal Zoom meetings, and were startled by the results.
Face identification wasn’t a surprise: everyone who has changed the background on a conference call has used software to pick out a face from a background. Identifying other objects in the picture, estimating age and gender we were expecting. But the ability to attribute names (by comparing with publicly available photographs) and emotions is much more striking when you see it done to you, rather than just described.
It’s not always accurate, of course. My age varied by 10 years depending on lighting level, and was reduced by 50 when I tried on my COVID mask! The exec who was speaking was mostly “angry” (we think he’d prefer “passionate”) and he might have hoped fewer of us would be “neutral” or “sad” while listening. He did manage to change the emotion assigned to a colleague’s background picture of
Mount Rushmore
, though!
Face recognition and emotion detection could, of course, be valuable assistive technologies for those who have difficulty doing those things themselves. But they have also been banned by law in some states and contexts. Faces are especially sensitive, and specially protected, parts of our humanity.
So, some questions to consider before using any of these technologies:
What are we trying to achieve? Can it be done another way? Why aren’t we doing that instead?
Can we ensure everyone supports this? How will they respond if they don’t?
What’s the risk, and how will we handle it, when (not if) the results come out wrong or discriminatory?
Are we setting an example we’d be happy for others to follow? All the technology we used is available for students, staff, friends, colleagues and strangers to apply and share to pictures and videos of us, too.
Originally posted: 24 June 2020 in category
Articles
In the week that would have been their annual conference, EEMA have been hosting
a series of fascinating online discussions among experts in the identity world
. Today’s featured Steve Purser, Dave Birch and Kim Cameron in a deep discussion about whether we might have been looking at the wrong kind of “identity” all along…
The words “identity” and “identification” seem so close that it’s easy to think that the thing we really need to know is who someone is. And Governments, in particular, have spent a lot of effort in building systems to do that. But adoption of them has been, at best, slow and confined to relatively narrow niches. For many, perhaps most, applications, “who” is actually among the least useful things to know: often it’s not enough, sometimes it’s too much. In financial transactions we actually want to know whether someone is financially reliable; when granting access to data we want to know whether their role and other qualities entitle them to see it; in a bar we want to know whether someone is old enough to buy a drink.
The emergence of the Internet of Things makes this particularly obvious. We may well want to “authenticate” and “authorise” a car, a lightbulb or a fitness app, but this has nothing to do with its passport. On social media we might simply want to know “is the account I’m interacting with a human?”; if we’re taking a report from a whistleblower we want to know “do they work there?” but we must be able to guarantee that we cannot identify them. Technologies exist that can do this, but they’ve not been the focus of mainstream development.
Kim Cameron suggested going back, way back, to the definition of “identity”. According to the Oxford English Dictionary this has three strands: “selfness”/ sameness/individuality (a sense dating back to 1611); “whatness” (also 1611) and “whoness” (which appears in 1922). So far, identity technologies have been focussed on whoness: the thing we need when dealing with Government and colleagues. IoT and most other applications actually want whatness (interestingly this – is someone a student or staff member, are they entitled to a car parking permit – has been of interest in Research and Education). We need to do a lot more development of that and of the selfness that allows us to bring together the multiple strands of our “who” and “what” and control which we use in each context. A bar may get to see confirmation of drinking entitlement and perhaps a photo, as certified by the driving agency, but it does not need to see the rest of the information on our licence.
So, although identity technologies have already contributed a great deal to digital transformation of enterprises and government, there is still a lot to do. Virus lockdown has shown that organisations are at very different stages of that digital transformation. And, whereas previous digital identity transformations have focussed on organisations, this time we really need to consider personal digital transformation, too, and help individuals through it. Many of the problems in our current “identity” space actually derive from the two sides of the transaction being far out of step. Organisations may have transformed to demand digital identity, but the uncoordinated nature of this transformation has overwhelmed the individual, who has to deal with tens, hundreds or thousands of “transformed” entities. If every one presents different identity demands, it is little wonder that individuals cannot cope and either give up on digital services entirely, or use them in the most convenient/least secure way possible.
Originally posted: 23 June 2020 in category
Articles
This morning’s Westminster e-Forum event on regulating Online Harms contained a particularly rich discussion of both the challenges and opportunities of using regulation to reduce the amount of harmful content we see on the Internet. The Government published a
white paper
in April 2019 and an
initial response to comments
in February 2020. A full response is expected later this year with legislation to follow in this Parliament.
One of the biggest challenges is the ambition to address both content that is illegal – typically well-defined in laws such as the Protection of Children Act – and content that is lawful but harmful. In the latter category the current pandemic has drawn particular attention to misinformation (accidental) and disinformation (deliberate): apparently a single item of “junk news” can achieve greater reach through social media than individual articles in the mainstream media. The Government’s initial response has recognised that these do need to be treated separately and suggests the approach to lawful but harmful will focus on processes rather than individual items of content.
Among the challenges identified:
The scope of the regulation is still unclear. Although the Government has stated that “less than 5% of UK businesses” will be covered, it have not provided any suggestion of how the current broad definition – any website allowing user-generated content, comments, or interaction – will be reduced. TechUK noted the very wide range of size and capability of organisations in the UK’s digital sector: regulation must not require measures that only large organisations can deliver. It may help to consider different ways of reducing the visibility of harmful content: preventing, disrupting, de-ranking and de-monetising as well as removing. Appropriate measures of “success” will be needed, which may well vary between types of harm, approaches to reduction and types/scales of regulated entity.
The range of lawful content to be addressed is not clear, likely to be dynamic and, by its nature, hard to deal with at scale. Targets of hate-speech have changed dramatically over the past three months: could systems and processes (which may need to review millions of items a day) keep up with changes in vocabulary? There may also be a high level of dependency on context: whether a statement is teasing or bullying may well depend on the relationship between the individuals. Victoria Nash from the Oxford Internet Institute suggested we may well need specific legislation on statements by political leaders: should these be judged by the same standards as those applied to citizens? This should definitely not be left to platforms and regulators to decide.
Although the White Paper mentioned the importance of protecting free (lawful) speech, this has not been supported by the same level of detail as commitments on rapid removal. Internet regulation has a long, and largely undistinguished, history of
creating one-sided incentives
that make it safer for platforms to remove material rather than justify their decision to continue to publish it. The White Paper set ambitious targets for removal of material within 24 hours, but accurate decisions need to be given as much credit as fast ones. Asgar Koene raised an interesting point that clarity is particularly important for UK legislation since, unlike Germany, we share a language with countries whose approach to this free speech balance may be significantly different. Global platforms cannot simply apply our national law to content in “our” national language.
The sessions also included presentations on some models of regulation that could be more widely adopted.
The
Internet Watch Foundation’s
work in using public reports and their own proactive investigations to generate takedown notices, URL lists and hashlists for child abuse images is well-known. The depth of their collaboration with industry perhaps less so. The charity has been industry-funded from its origins twenty years ago. It now works with technical experts from members to understand the complex ways in which material is distributed and how this might best be disrupted; and it holds hackathons where members can explore new ways of using IWF data in their systems.
The
Internet Commission
is a newer non-profit organisation that aims to identify and promote best practices in content moderation. These look broadly at the moderation process: reporting, moderation, promotion, notice, appeal, resources, governance. Companies from diverse sectors have volunteered for an independent assessment, involving confidential bilateral review, private benchmarking and information exchange. Some common issues that are already emerging are the relationship between automated and human moderation, and how to provide rights of appeal. The first annual report, due before Christmas, will be interesting both for content and model.
Finally, since many of the problems are social in origin, we should not ignore the contribution of social solutions. Though attempts at “awareness raising” and “digital literacy” have been common for many years, panellists suggested it might be more fruitful to focus on “digital civility”. Rather than trying to teach readers how to assess the source of material we receive, this might usefully focus on responsible habits in how we should use it. Ofcom’s digital literacy surveys suggest that while a lot of people are concerned about material they encounter, many don’t do anything about it.
But as well as standards and regulation the collection is steadily expanding to cover things like privacy for consumers, architectures, access control, digital identity, project management and knowledge sharing. If you’re interested in any of those, it’s well worth a look.
#427 - Maintaining trust in University data handling
Originally posted: 16 June 2020 in category
Publications
WONKHE has published my article on the need to be careful in introducing, and withdrawing, with any post-virus data processing (the absolute sub-head isn’t mine!)
Originally posted: 15 June 2020 in category
Articles
As data protection
regulators keep reminding us
, the research and data protection communities mean different things when they talk about “consent”. A couple of recent conversations have made me wonder whether that terminology clash may have another effect: are those putting research into practice missing out on existing guidance that could help with that transition?
In the research world it seems that once you’ve obtained consent, or decided it is not applicable, the only other guidance available is from the field of “ethics” as it applies to the particular research domain. Hence it may also seem natural when reading data protection law to look at the section marked “consent” and then try to resolve all remaining questions using “ethics”. In fact, the rest of the General Data Protection Regulation (GDPR) provides much more concrete guidance on how to do the research-to-practice transition.
First is the way that research is explicitly allowed (subject to appropriate safeguards) to take a broader focus than services: for example contrast “consent to
certain areas
of scientific research” in Recital 33 with “consent … for one or more
specific purposes
” in Article 6(1)(a); or the recognition of research as a broad “compatible purpose” in Article 5(1)(b). This indicates that we should expect to narrow our focus, and set more specific requirements, as we move from research to implementation. Indeed one of the outcomes of research should be precisely to discover which practical activities are likely to be beneficial.
Similarly with data, there should be a narrowing of focus from data that
might
be needed for research down to the data that the research concludes are
actually required
to achieve a specific result. If that result is the delivery of a service, then the GDPR’s principles of
data
and
storage
minimisation are particularly relevant. These appear in many ethics codes but the GDPR provides better guidance. In particular, the GDPR concept of processing “
necessary for …
” provides a clear test to distinguish information that is essential to service delivery from optional information that we could use if the user chooses to provide it.
Finally, the principle of “
accountability
” requires that we not only do this thinking, but that we be able to demonstrate that we have done it.
As
I’ve written elsewhere
, this takes us a long way into what has traditionally been solely a matter for “ethics”. Once we have
actually
exhausted the guidance that is available through the GDPR, the remaining questions that really do need to be dealt with by ethics may seem less daunting.
Originally posted: 12 June 2020 in category
Articles
Tony Sheehan, of Gartner, observed in this morning’s
EUNIS 2020 keynote
that Higher Education has changed more in the past three months than in the whole of his previous career. Universities have delivered an “extraordinary achievement” in delivering learning continuity through various intensities of COVID-19 lockdown. Now we’re approaching a recovery stage when we can review – “learning optimisation” – and consider what to do next – “learning transformation”.
This needs to recognise that our current (June 2020) practices almost certainly aren’t sustainable in the long term. Most institutions currently have an imperfect implementation of online learning, which depends on the goodwill of both students and staff. But we’ve also learned a lot about what might be possible in future: again picking up an unofficial conference theme that the virus may well have brought the future of education a lot closer.
So now it’s worth reflecting on which aspects of that change we want to keep; which we want to continue but do differently; and which we want to treat as short-term emergency measures. It’s pretty clear that things won’t go back to the way they were: staff and students who have experienced new possibilities won’t want those to be lost. Equally, trying to sustain everything about our current operations is likely to be too stressful for both staff and students: we need to choose the right things to “return to normal”. The resulting plans need to be flexible. We don’t know either when, or under what constraints, that future can be delivered; we may even have to return to stricter measures during any second wave, though there will be less tolerance of improvisation second time around.
In the time between future vision and past experience we should review:
Our systems: which worked well in the new environment, and which only coped thanks to staff and student commitment;
Our skills: what did we already have, how can we make improvisations sustainable, and which might we need to train or recruit;
Our students and staff: how did they feel, what is sustainable beyond crisis mode, how do we prepare for the new world.
Originally posted: 11 June 2020 in category
Articles
A pair of interesting sessions at today’s EUNIS conference looked at how universities responded to the impact of COVID-19 lockdown on end of year assessment. An audience survey indicated that 60% have changed the form of their assessment, 15% cancelled exams, and 15% adopted some kind of remote proctoring system to allow for traditional-format exams to be taken in uncontrolled locations, such as the home. In countries where travel was possible, but limited, existing arrangements for taking exams in other institutions had become highly relevant.
For remote proctoring (only one option could be chosen), 33% of the audience were concerned about privacy, 31% about equality: mostly because students with less appropriate devices or poorer internet connectivity might be disadvantaged, either in fact, or by increased stress from worrying about it. Cost and other factors worried the remainder. Case studies from the Norwegian and Finnish university systems suggested that the only use of remote video was to verify the identity of the person sitting the exam against their official documents. Technical tools mentioned included kiosk applications that limited what other applications could run during the exam period; blacklists on collaboration tools; plagiarism detection; and noting significant pauses or sudden bursts of typing for later investigation.
The much more popular option was, however, to change the style of assessment, with many people commenting that lockdown had brought forward
changes they had hoped to make anyway
. These included moving to open book exams and eliminating multiple-choice questions, which were felt to have the greatest risk of cheating. The limitations of digital exam platforms may even have advantages: if the discipline involves notation that is not easily supported by keyboard and mouse, then get the student to write that part of their answer and submit the picture. This gives not only a check of knowledge, but also of the person doing the handwriting!
Finally, there was a reminder not to aim for perfection. Paper exams have risks, too. And, as one audience member commented, if someone can use reference materials fast enough to pass a time-limited multiple-choice paper, then perhaps they do know the subject quite well anyway!
Originally posted: 11 June 2020 in category
Articles
Alberto Cairo
, Knight Chair in Visual Journalism at the School of Communication of the University of Miami, gave a wonderful EUNIS 2020 keynote on
Making Good Visualisation Decisions
. His argument – Visualisation is like writing: there are basic (grammatical) rules, but also choices, and those should be reasoned. Bad decisions can cause real-world harm. Just three of my highlights from his presentation.
How, even whether, to use visualisation must be appropriate for the context. A cartoon bubble map of Google searches beginning “Why does my dog/cat…?” is
great for the cover of a report
. A
representation of COVID-19 statistics
by anyone who does not understand epidemics is very different.
The choice of visualisation style must be led by the message you want to convey, not by incidental features of the data. Just because numbers sum to 100% doesn’t mean they should be displayed as a pie chart; just because a table contains geographic data doesn’t mean they should be shown as a map. Don’t be afraid to
explain your visualisation and to highlight key points
. This will make it accessible to many people who find visual presentation hard to read and
may help increase visual literacy
. The Financial Times has an
excellent visualisation vocabulary
.
And use visualisation yourself to identify, understand and, if necessary, correct outliers. On any statistics of internet use, the state of Kansas is likely to be one of these. Not because of anything to do with the population, but because it’s the geometric centre of the country, and that’s where many geo-location tools show VPN accesses as coming from!
Originally posted: 5 June 2020 in category
Articles
There seems to be a widespread perception that “AI is creepy”. But at the same time as reacting strongly against an app that would
check social media posts for signs that we were struggling to cope
, we don’t think twice about the grammar checker that continually reads everything we type. I wondered why and if there were any rules of thumb we could use when proposing AI as a helpful assistant, rather than a creepy intruder.
Using AI to process faces provides an informative range of examples.
Automated face recognition to find criminals
has had a
strong negative reaction
in the UK and
is being banned in an increasing number of other states
. But I accepted the same technology letting me board a plane in the US last year; was happy to join the shorter queue for an automated face/passport verification to get airside; and I hadn’t even thought about the face detection involved every time we insert an alternative background into a video call.
This suggests there are two significant factors: whether the AI operates continuously or only at times I choose; and how limited its function seems to be. Ideally that should be a technological limit, though more general technology may be acceptable if there are strong policies and sanctions for misuse. In a video conference I choose whether or not to use face detection, and separating a picture from the background has few other uses. A boarding corridor that identifies passing faces and checks they are on the correct flight is time-limited, and I could opt for a human document check instead. So:
Time-limited
Always-on
Single-function
Face detection (to blur background)
Face verification (matches passport)
AI translation
Grammar checker
Multi-function (potential)
Boarding gate
Voice-bot
Automated face recognition
Smart speaker
Checking this model with AI that processes words, rather than faces, suggests that it fits there too. Smart “speakers” (actually, it’s the smart microphone function that’s spooky) are always on and potentially unlimited in purpose – the common concern is “what
else
is it doing?”; grammar checkers are always on, but limited to a single function; voice bots that try to help us through phone menus are limited in time (though frustrating if they don’t offer a human fallback option); asking a translator to work on a text gives us control over both what and when we disclose.
Other factors that seem to increase the sensation of creepiness include:
Tasks that get too close to our identity as humans: e.g. identifying faces or emotions;
Decisions we feel should only be made by humans: e.g.
on early release from prison
, in education course entry or continuation may be one of these;
Using information the individual might not have realised that we have, or not expected to be used in that way. Here a clear notice
may satisfy the law
, but may not remove the unease.
Any of these is likely to push our application down and to the right in the matrix, increasing the risk that it will be perceived as creepy. Conversely, the further up and left we can place our application, the more likely it will just be accepted for the contribution it makes to our daily lives.
For an excellent introduction to AI, with no mention of creepiness, see
DSTL’s “Biscuit Book”
.
An article, on “The value of e-proctoring as Exams move on-line”/”Technology can reduce exam stress”, was published in
University Business
(6/5/20) and the
Jisc website
(13/5/20).
Originally posted: 12 May 2020 in category
Articles
[with thanks to a former university Head of Examinations for input and discussion]
Recent years, and weeks, have seen a move away from the traditional examination context, where candidates gather in large halls to write on paper, to candidates being assessed using computers, in small groups or individual work spaces. In this change, the role of the invigilator (also known as “proctor”) remains important; there may be new opportunities to use technology to assist in the invigilation process. However some of the technological systems being proposed appear to significantly expand, or even to contradict, the role of the invigilator. Such changes require particularly careful scrutiny, as they are likely to change both the purpose and the effect of examinations.
Invigilator’s Role
The role of the invigilator is to help all candidates complete their exams to the best of their abilities, in as supportive an environment as possible. Significant departures from appropriate conduct, either of examinations in general or of the specific paper being assessed, must be recorded and should be corrected where possible. These records will then be used by academic staff to determine how, and in some cases whether, the candidate’s assessment should be marked. An invigilator must only prevent a candidate completing their assessment if this is the only way to prevent disruption to others.
Management of the Examination
The invigilator has three main roles in managing the conduct of the examination:
Time-keeping
: the invigilator will generally provide interval warnings, for example when there is one hour, or ten minutes to go. Each candidate should be able to choose how much more precisely to keep track of time, to minimise their own stress level;
Faults in papers
: if candidates have questions about the examination paper – for example because it appears to have an error or be unclear – the invigilator(s) should be able to refer these promptly to a member of academic staff and then to disseminate their ruling to all candidates in all locations;
Managing/recording unexpected situations
: in a physical exam hall the invigilator is responsible for recording incidents such as fire alarms or water spills and maintaining, so far as is safely possible, compliance with the exam rubric. The impact of such disturbances on individual candidates’ performance is assessed later, by academic staff. In an online context incidents could include, for example, loss of internet connectivity.
Improper conduct that should be detected
The invigilator is expected to detect three main types of improper conduct (note that details of these may vary depending on the exam, for example whether specified external resources are allowed, and whether annotations are permitted):
Wrong candidate taking exam
: the identity of candidates should be checked to confirm that the individual who sits the exam is who they claim to be. If a candidate cannot show a matching identity document they should normally be permitted to sit the exam (in case they have good reason for lack of ID) but the circumstances must be recorded. Similarly, if a candidate who is not on the list wishes to sit a paper, they should normally be allowed to do so, as this may be the result of simple mistakes by student or institution. Both situations can be resolved later.
Candidate using unauthorised materials
: the exam rubric should state what additional resources (if any) the candidate is allowed to consult; use of resources not on the list should be prevented or detected.
Candidates colluding
(either within or outside room): unless the exam rubric permits collaboration, candidates’ attempts to communicate with others should be prevented or detected.
Improper conduct that is not expected to be detected
It is important to remember that there are some types of improper conduct that invigilators are not expected to detect. These include those that would require extreme preparation by candidates, or where detection would require unacceptable levels of intrusion and stress for them. In particular, invigilators are not expected to detect:
Anything that cannot be detected during the exam session (e.g. that requires a recording of the whole examination process);
Anything that requires long-term preparation (e.g. candidate substitution after obtaining false ID documents);
Anything that requires intimate inspection/monitoring/restriction of candidates.
Methods (face-to-face)
During a traditional examination, invigilators use a number of techniques to detect improper conduct:
At the start of the exam, or at least early in the period, identity documents are checked against the candidate’s appearance (see above for if the candidate does not present an ID); invigilators are not expected to be experts in detecting forgeries;
Where candidates are allowed to bring materials into the examination, these are checked to ensure they meet requirements (for example on annotations);
If there is a grace period for latecomers to enter the exam, candidates are prohibited from leaving their desks until after that period;
If candidates are permitted to leave their desks and return they are supervised, but not intimately, while away;
Invigilators continually survey the examination hall from a distance; if they see something that, based on their experience, raises concerns then this may trigger…
Invigilators periodically inspect the desk area: the candidate has warning of their approach.
Thus invigilation consists of a combination of continuous, coarse-grained observation from a distance and occasional close-focus inspection. To reduce stress, the candidate is aware when the latter is taking place: a candidate who believes they may be under continuous close-focus human surveillance or recording is likely to experience considerable stress and will not perform their best.
Methods (remote/digital)
Technology should be used to contribute to the invigilation process, not merely to allow it to be conducted remotely. Simply providing a continuous video-conferencing link that effectively seats the invigilator on the candidate’s desk fails the invigilator, the candidate and the technology: the invigilator has to do at least as much work, the candidate is placed in a more stressful environment, and the technology is badly under-utilised.
Rather than merely a communications medium that removes any distance (even the length of the exam hall) between the invigilator and the candidate, technology should aim to be part of the invigilator’s alerting and record-keeping process: detecting abnormal situations, recording these for later consideration, and drawing the attention of a human invigilator in cases where either correction or further investigation is required. Where possible, technological innovation should support the invigilator’s full role: allowing it to be performed with less stress (for both candidate and invigilator) and more effectively than a physical human presence. For example:
An e-proctoring system might take a snapshot of the candidate’s work at the point of any alert, break, or interruption. This extension of the face-to-face practice of ruling a line on the script after any fire alarm allows the work to be checked for sudden bursts of “creativity” or correction that might suggest a candidate had been consulting unauthorised materials during the break;
An e-proctoring system might detect unexpected sounds, such as the turning of pages in a book, record and alert the human invigilator to these;
An e-proctoring system might detect, record and alert on changes in typing cadence, suggesting that the individual entering the assessment is no longer the intended candidate;
An e-proctoring system might detect, record and alert on unusual patterns of system or network activity that may suggest the candidate is engaged in unauthorised activity;
An e-proctoring system might detect, record and alert on environmental changes, such as loss of network connectivity;
Etc. etc….
[UPDATE:
colleagues in Norway
have pointed out that many of these ‘in-machine’ mechanisms already exist in systems designed for sitting computerised exams in traditional exam hall environments]
Since digital systems cannot understand the full human context of what may take place during the examination, their most likely role is in the continuous, “distance” monitoring aspects of invigilation. If an e-proctoring system detects behaviour that it does not understand, or believes may be suspicious, it should raise an alert. The circumstances around the alert can then be checked, either by a human invigilator during the exam or, if this is not possible, by a member of academic staff, using the system’s records and their knowledge of the individual candidate, afterwards.
“E-proctoring” systems that do no more than reproduce, badly, the face-to-face invigilation process should be regarded with suspicion.
Other Factors
Finally, remember that the invigilation process is not the only thing that prevents candidates cheating in examinations. Invigilation/proctoring, whether in person or remote, must be part of an assessment system that is designed to be resistant to cheating. Other means to this end include:
Before assessment: considering alternative ways of assessing or verifying performance; designing assessment so that it is hard for candidates to benefit from collusion.
During assessment: considering open book exams (so the risk of “unauthorised sources” is designed out) or, conversely, conducting on-line exams using kiosk systems that only allow candidates to view permitted resources.
After assessment: using a moderation process to identify candidates whose examination performance differs markedly from what was expected from their work in class; also to review invigilators’ records for anything that might significantly affect the performance (either negatively or positively) of an individual or group.
Originally posted: 1 May 2020 in category
Articles
In looking at the many
ethical concerns
that have been expressed about the use of Artificial Intelligence in education, it struck me that most fall at the two ends of a scale. On the one hand questions of human autonomy lead to concerns about cookie-cutter approaches, where AI treats every student according to a rigid formula; on the other hand questions about the social function of education raise concerns about hyper-personalisation where students cannot learn together as each one is doing different things at different times. As we move toward either of those extremes we seem to need a human to step in and say “no further”.
But we don’t worry – indeed we don’t usually notice – when we use AI for things like spelling or grammar checks. So perhaps the best place to start using AI is in that middle ground, using AI as an assistant, and not as a decision-maker?
This can still be very powerful, making best use of AI’s capacity to sift through immense quantities of unstructured input and suggest which parts of it may be relevant to an individual human’s current needs. So, for example:
An AI might act as
study-buddy
, spotting when a student seems to have got stuck on a topic and suggesting “have you thought about it this way?” (or, particularly in current circumstances,
when we should take a break
from screen-staring or video-conferencing);
An AI might help with research, by suggesting a
short-list of legal case reports
or published papers that seem to be relevant to a particular area of study;
AI is already used to
analyse student essays
and highlight to tutors any passages that they should check for plagiarism;
The spelling/grammar example may provide further guidance, that an AI assistant should always know, and signal, its own limitations. Where there is a “right” answer (spelling) it may be acceptable for it to act silently: where the rules are less clear, or where a human may reasonably choose to break them (grammar) it may be better for it to mark “this doesn’t look right to me” and offer alternatives for the human to consider (including, of course, “it’s OK, I really did mean to start a paragraph with ‘But'”).
The human may be deliberately breaking the rules to make a point; or they may know about rules that the AI doesn’t (“will this combination make a better conference programme?”); or they may be making a decision where they are expected to apply their discretion and instinct. Perfect consistency may not be the desired outcome of some processes: sometimes the same set of inputs
should
lead to different outputs, in ways that are very hard, or impossible, for an AI to understand.
This approach seems naturally to meet the
All-Party Parliamentary Group on Data Analytics
desire for AI to be used to promote the purpose of education, but leaving humans to decide – in any particular circumstance – what that purpose requires.
Originally posted: 30 April 2020 in category
Articles
I’ve been reading a fascinating paper by Julia Slupska – “
War, Health and Ecosystem: Generative Metaphors in Cybersecurity Governance
” – that looks at how the metaphors we choose for Internet (in)security limit the kinds of solutions we are likely to come up with. I was reminded of a talk I prepared maybe fifteen years ago where I worried that none of the then-current metaphors for the Internet seemed to lead to desirable outcomes: “Information Superhighway” (seven deaths a day acceptable), “Wild West” (get a bigger gun), and so on. But Slupska – who, unlike me, knows the theoretical background – has her eye on things of greater significance: whose role it is to address the problem and what a “successful” outcome looks like.
The most common metaphor seems to be “cyber-war”, either explicitly or implicitly through terms like “battlefield”, “enemy” or even “Geneva Convention”. These constrain us to thinking of “solutions” that take place between nation states, and involve the “defeat” of some enemy. Any de-escalation must be mutual. At the opposite extreme “cyber-hygiene” places the burden almost entirely on individual behaviour, which seems to be taking things too far in the opposite direction. Intermediate metaphors seem more fruitful: “cyber-ecosystem (environment)” and “cyber-public health”. Both assign roles to nation states, the private sector and individuals, and seek to mitigate, though perhaps not to eliminate, a global threat. Both seek to create mutually-reinforcing incentives though without being entirely dependent on concerted action.
Both seem useful, but I detect a slight preference for the environmental metaphor, partly because global discussions have been going on longer so the framework may be more developed. In particular there’s a fascinating observation that environmental discussions can cope with disagreement, or some parties stepping outside the system entirely. Within an environmental metaphor unilateral action can make sense, even be beneficial: adopting stricter standards for your own industries may give them an economic advantage when others are finally forced to catch up. Here the parallel is explicit with vulnerability disclosure: a “warfare” metaphor makes you much more likely to hoard vulnerabilities in the “enemy’s” systems, an “environmental” one lets you consider whether the (direct or indirect) benefit in fixing your own systems might actually be greater. Maybe we should be talking about a “digital Paris Agreement”, rather than a “Geneva Convention”.
Originally posted: 28 April 2020 in category
Articles
[Notes:
This isn’t legal advice, but I hope it will reassure anyone considering supporting the
COVID-19 Cyber Threat Coalition
that the data protection risks should be very low;
This only covers the use of data for defending systems, networks, data and users; use for offense, including attribution and evidence, is
covered by separate legislation
, which varies much more between countries.
I’ve recently been introduced to the work of the COVID-19
Cyber Threat Coalition
(CTC). This is a global group of volunteers who have got together in response to
criminals’ increasing use
of fear of the virus as a way to propagate scams, ransomware and other malicious content. At a time when we are all worried about our own health and that of our friends, families and colleagues, it’s easy to see how an apparently authoritative email or website might tempt us to click on the wrong attachment or link.
The good news is that collecting data about such scams, analysing that data securely within a group of experts, and disseminating information to help protect all of us against them seems to be comfortably within the bounds of
Europe’s General Data Protection Regulation (GDPR)
. A few years ago I wrote a peer-reviewed paper on
how incident response fits into the GDPR’s provisions
on protecting networks, systems, data and users. The framework described in that paper can be applied to CTC’s work.
When we are processing personal data (which may include some IP and email addresses) for the purpose of ensuring network and information security, Recital 49 of the GDPR directs us to look at the “legitimate interests” provisions in Article 6(1)(f). Those require a three-step test: is the purpose legitimate? Is the processing necessary to achieve that purpose? Does the risk that the processing will cause outweigh the benefit it might produce? In section 4.2 of the paper I set out key questions for assessing incident response activities against these requirements: here’s how COVID-19 CTC responds.
When addressing the legitimate interest:
The potential or actual severity of the incident being prevented, detected or investigated:
a
joint advisory from the UK and US Governments on 8th April
reports that COVID-19 is now the most common “hook” for scams masquerading as trusted government sources. These range from financially-motivated ransomware and phishing against individuals to espionage.
How widely the [] activities will benefit others:
results from CTC are made public, in formats that can be directly incorporated into existing software and network defences. With appropriate take-up of these resources, this can help to protect the majority of Internet users around the world.
Whether the objectives and activities fall within the reasonable expectations of those whose data will be processed, for example whether they are recognised as legitimate by the law or community norms:
processing of data about cyber-attacks in order to improve defences against them has been recognised as legitimate in European law since at least the
2009 revision of the ePrivacy Directive
(see Recital 53), and as a
positive requirement in Regulatory guidance
(see first paragraph on p.6) since the 2016 GDPR.
When assessing the impact on individual rights:
Whether the activity involves processing identifiers that might be linked to individuals, and how likely such linkage is:
reports submitted to CTC may include identifiers that might be linked to recipients and victims of scams, such as their IP and email addresses. However the coalition has no interest (and, in most cases, no ability) to perform that linking or use that recipient data in any way. Support for victims of scams should be provided by their home networks and organisations, not by CTC. The identities of recipients in one organisation are irrelevant to protecting recipients in others, so such information should not be included in feeds published by CTC. IP, and possibly email, addresses used by attackers are likely to be included in the published feeds, but attackers design these to be hard to link to their origins, and even law enforcement agencies may be unable to do this. The likelihood of linkage is therefore near-zero for victims and, sadly, very low for attackers.
Whether information was collected in a way that included privacy safeguards:
CTC receives information from voluntary donors, it does not collect its own. Donors are encouraged to use OTX feeds, which structure data to focus on fields whose defensive value is high and whose privacy impact is known.
How widely information will be disclosed, and the interests of all recipients:
information that can be used to defend against attacks is made public, other information is not disclosed at all. Recipients of information are expected to use it for defending against attacks, and it would have few other uses in any case.
What safeguards – including pseudonymisation, encryption and computer, rather than human, inspection – can be used:
CTC holds and analyses donated data within industry-standard secure cloud services; the scale and speed of processing required means that computer inspection, at least of raw data, is always preferred; data is published in formats suitable for automated ingestion into defensive systems so that no human inspection is required by recipients.
Applying the balancing test, it is clear that COVID-19 CTC’s activities can help mitigate a serious threat to a significant proportion of global Internet users. And both the CTC’s purpose, and how it carries it out, result in a very low risk to those users. Thus there should be little difficulty in justifying those activities as lawful under GDPR Article 6(1)(f).
Originally posted: 22 April 2020 in category
Articles
The EU High-Level Expert Group’s (HLEG)
Ethics Guidelines for Trustworthy AI
contain four principles and, derived from them, seven requirements for AI systems. The Guidelines do not discuss the need for AI to be lawful, but the
expansion of Data Protection law beyond just privacy into areas formerly considered part of Ethics
means that much useful guidance can, in fact, already be obtained from legal and regulatory sources. In particular the General Data Protection Regulation (GDPR) principles of
Accountability
and
Fairness
require steps to be taken to identify and address potential harms
before
any system is developed or deployed, rather than relying on remedies after the event. Such an approach is helpful even for systems that do not process personal data.
Indeed it appears that any AI that addresses the requirements of the EU GDPR will already have made significant progress towards achieving the HLEG’s principles and requirements. This analysis considers each of those principles and requirements, identifies relevant GDPR provisions and guidance and,
in italics
, areas where ethics requires going significantly beyond the GDPR. For each section we also note any issues, or guidance, specific to the use of AI in education. These paragraphs, in particular, will be updated as I discover new, or better, sources.
The major outstanding questions appear to be in the areas of Respect for Human Autonomy and Societal and Environmental Wellbeing, where questions such as “should we do this at all?” and “should we use machines to do this?” are largely outside the scope of Data Protection law. In the areas of Human Agency and Transparency, an ethical approach may provide a better indicator of social and individual risk than the GDPR’s “automated decisions with legal consequences”, which can be criticised as being both too wide and too narrow.
[UPDATE 8/1/21: I’ve been using four questions – Will it help? Will it work? Will it comfort? Will it fly? – to explore some of these “should we do this?” issues. Another post has a
brief introduction to how this might work
: for more detail, with practical examples, the Journal of Law, Technology and Trust published a short paper “
Between the Devil and the Deep Blue Sea (of Data)
“]
HLEG Principles
The HLEG derives its four principles for trustworthy AI from fundamental rights set out in human rights law, the EU Treaties and the EU Charter. For the education context, we should therefore add the right to education set out in those documents and, in particular, the broad purpose of education set out in the
UN Declaration of Human Rights
: “the full development of the human personality”. UK law also expects educational institutions to support the rights to free speech and free assembly, both of which could be impacted by inappropriate uses of AI.
As was suggested at a recent Westminster e-Forum event, organisations that can show that their activities are governed according to such principles are likely to be granted more trust, and greater permission to innovate.
Respect for Human Autonomy
HLEG
: “Humans interacting with AI systems must be able to keep full and effective self-determination over themselves, and be able to partake in the democratic process. AI systems should not unjustifiably subordinate, coerce, deceive, manipulate, condition or herd humans. Instead, they should be designed to augment, complement and empower human cognitive, social and cultural skills”.
This is largely a question of the uses to which AI may be put: the prohibitions appear to define unethical behaviour whether it is implemented using artificial or human intelligence. The use of AI may, however, have an amplifying effect, either by making these unethical effects on individuals more intense, or by affecting more individuals
. One specific type of “deception” (also considered by the HLEG as a transparency issue) is addressed by the GDPR: that individuals should always be aware that they are dealing with an AI rather than a human and, in most cases, should have the option of reverting to a human decision-maker.
For education, the UN goal of developing the human personality appears a useful test that both supports the HLEG’s desired effects of AI and warns against the prohibited effects, whether intended or consequential. The
All-Party Parliamentary Group on Data Analytics
recommends that “data should be used thoughtfully to improve higher education”, and cites the Slade/Prinsloo principle “Students as agents: institutions should ‘engage students as collaborators and not as mere recipients of interventions and services'”.
Prevention of Harm
HLEG
: “AI systems should neither cause nor exacerbate harm or otherwise adversely affect human beings”.
Assessment and management of harms to
individuals
is a key part of the GDPR’s
balancing test
and
accountability principle
.
The ethical viewpoint requires this to be broadened to collective and intangible harms, such as those to “social, cultural and political environments”.
The Information Commissioner’s
Guidance on AI and Data Protection
suggests that consultation with external stakeholders as part of the Data Protection Impact Assessment (DPIA) may provide some check against these harms.
Fairness
HLEG
: “fairness has both a substantive and a procedural dimension. The substantive dimension implies a commitment to: ensuring equal and just distribution of both benefits and costs, and ensuring that individuals and groups are free from unfair bias, discrimination and stigmatisation … The procedural dimension of fairness entails the ability to contest and seek effective redress against decisions made by AI systems and by the humans operating them”.
Bias and discrimination against individuals
is also a concern of the GDPR, in particular through its invocation of other laws on discrimination, etc. The ICO finds a requirement to
consider impact on groups
as part of the GDPR fairness principle.
Fairness
between
groups is likely to be an issue requiring a wider ethical perspective
. The ability to challenge and obtain redress for significant automated decisions based on personal data is a requirement of Article 22 of the GDPR.
From an education perspective, it is notable that the HLEG specifically mentions that “Equal opportunity in terms of access to education, goods, services and technology should also be fostered”. However the
All-Party Group on Data Analytics
warns against a “one-size-fits-all” approach: different institutions and different contexts are likely to benefit from AI in different ways. The
European Parliament
warns that “the deployment of new AI systems in schools should not lead to a wider digital gap being created in society”.
Explicability
HLEG
: “processes need to be transparent, the capabilities and purpose of AI systems openly communicated, and decisions – to the extent possible – explainable to those directly and indirectly affected”.
Although there is still debate as to the extent of the “right to an explanation” that is contained within GDPR Article 13(2)(f) etc., the
ICO’s guidance on Explaining AI Decisions
appears to provide a comprehensive exploration of all the issues involved in both legal and ethical terms.
HLEG Requirements
To support its four principles, the HLEG identifies a non-exhaustive list of requirements for trustworthy AI. Any system that does not meet these requirements is unlikely to be trustworthy; however even meeting all the requirements may not be sufficient to be trusted.
Human Agency and Oversight
HLEG
: “Including fundamental rights, human agency and human oversight”.
Where legitimate interests (Article 6(1)(f)) are used as a lawful basis for processing personal data, there is already a legal requirement to consider the effect on fundamental rights, which appears to meet the HLEG’s objectives. On human (subject) agency, the HLEG cites, as key, the GDPR’s provisions on fully-automated decisions in Article 22. On human (operator) oversight of AI it recognises that different levels of involvement are appropriate for different circumstances. As a general rule: as humans become more distant from individual decisions, “more extensive testing and stricter governance are required”.
Given the uncertainty over the scope of the GDPR automated decision provisions – which appear not to cover some circumstances (such as nudges) that concern the HLEG, but also to include decisions on contracts (such as bicycle rental) that fall well below the threshold of ethical concern – an ethical approach may provide a more appropriate perspective on the circumstances and tools through which human agency may need to be supported.
In education and the wider public sector, where public interest may be chosen to replace legitimate interest, the fundamental rights check may not be a legal requirement, but should be considered good practice and may contribute to institutions meeting their duties under the
Human Rights Act 1998
. The
All-Party Group on Data Analytics
note that AI in education is likely to be used to assist human decision-makers, thus providing the deepest (“human-in-the-loop”) level of human involvement in individual decisions. The
European Parliament
notes that “notes that AI personalised learning systems should not replace educational relationships involving teachers” and that this will require training and support for teachers, as well as pupils.
Technical Robustness and Safety
HLEG
: “Including resilience to attack and security, fall back plan and general safety, accuracy, reliability and reproducibility”.
As well as incidents and attacks affecting AI systems and software, which should already be covered by GDPR’s “integrity and confidentiality” principle, the HLEG notes that attacks against training data may be effective. Security measures must both make this type of attack less likely to succeed, and be able to detect and respond to those that do.
For some systems the appropriate response to an attack may be to revert to a rule-based, rather than statistical, approach to decision-making.
Accuracy and reliability of predictions should be delivered by the testing and monitoring processes required by the second half of GDPR Recital 71 and by the
ICO’s auditing framework
(under “
What do we need to do about Statistical Accuracy?
“);
reproducibility of behaviour is not an explicit GDPR requirement, and may prove challenging for systems using undirected learning.
However the ICO’s
risk-based approach to explainability
and the HLEG’s comment that the requirement for explicability “is highly context-dependent” suggests that this may only be necessary for high-risk applications and contexts.
Accuracy of data and predictions may be a particular challenge for education systems where there is significant exchange of data across educational transitions and between institutions. When accepting information from another organisation, a school, college or university should be aware of the context in which it was collected: what individuals were told and the purposes for which the original collection and data validation processes were designed. When using such information for a different purpose, particular care is needed that this does not go beyond the limits of those processes: see
Annex B
of
Jisc’s Wellbeing Analytics Code of Practice
for further discussion of data re-purposing.
Privacy and Data Governance
HLEG
: “Including respect for privacy, quality and integrity of data, and access to data”.
HLEG
: “Including traceability, explainability and communication”.
With the
broad scope of GDPR explainability adopted by the ICO
(see the explainability principle above), the first two points should already be covered.
As with Human Agency above, the ethical requirement to inform users of the presence of an AI may apply to a different scope to the GDPR’s “automated decision-making”. The GDPR’s focus on information for
data subjects
may omit the ethical requirement to communicate information about the system’s capabilities and limitations to its
operators
.
Specific to education, Jisc’s
Learning Analytics Code of Practice
discusses making relevant data labels available to individuals. The HLEG requirement that “AI systems should not represent themselves as humans to users” may require care when AI uses particularly human modes of communication, such as speech.
Diversity, Non-discrimination and Fairness
HLEG
: “Including the avoidance of unfair bias, accessibility and universal design, and stakeholder participation”.
GDPR Recital 71 requires algorithm developers to avoid discrimination and detect signs of it emerging. The ICO’s
Guidance on AI
adds
risks of bias in training data, and the risk of algorithms learning to (accurately) reproduce existing biases
, whether deliberate or accidental, in the systems or processes being observed
. Diversity of hiring is beyond the GDPR’s scope.
GDPR requires accessibility of communications, but not
wider accessibility of digital systems
. Stakeholder participation should be considered (and for AI, normal practice) as part of the organisation’s Data Protection Impact Assessment (DPIA).
Most educational organisations will already be subject to additional accessibility obligations, both for
websites and apps
and, more widely, to make reasonable adjustments under the
Equality Act 2010
.
Societal and Environmental Well-Being
HLEG
: “Including sustainability and environmental friendliness, social impact, society and democracy”.
This is much the broadest of the HLEG requirements, addressing impacts on society, the environment and democracy as well as the physical and mental wellbeing of individuals.
These issues – which may be summarised as “should we do this at all?” and “should we use computers to do it?” – are almost entirely outside the remit of the GDPR.
It is notable that education is specifically mentioned as a field in which “ubiquitous exposure to social AI systems … has the potential to change our socio-cultural practices and the fabric of our social life”. As well as the
UN Sustainable Development Goals
(Goal 4 covers education, including tertiary), which the HLEG mention as a reference point, guidance may be found in the UN Human Rights Convention definition of the purpose of education, and the Convention’s requirements to protect both free speech and free assembly. Along similar lines the
All-Party Parliamentary Group
recommends that AI should be used to enhance the learning experience, not just as an administrative tool. A helpful starting point may be that there is likely to be
more shared interest between the learner and the provider
than in most other public and private sector relationships.
Accountability
HLEG
: “Including auditability, minimisation and reporting of negative impact, trade-offs and redress”.
There appears to be a significant overlap between the HLEG’s concept of Accountability and the principle of the same name in the GDPR. Whereas the GDPR’s primary focus is on Accountability (including redress) for how the system is designed and operated,
the HLEG adds some new requirements for accountability for errors, such as protection for whistle-blowers, trade unions and others wishing to report problems
. The Information Commissioner’s
Guidance on AI
requires organisations to
consider impact and to document trade-offs
(under Auditing and Governance); in particular all AI applications processing personal data are likely to require a Data Protection Impact Assessment (DPIA). The ICO
guidance on explaining AI
considers how to choose algorithms that provide an appropriate level of auditability for each particular context.
#414 - Wellbeing Analytics Code of Practice: Consultation
Originally posted: 7 April 2020 in category
Closed
[UPDATE 2nd June 2020: thanks for your feedback. Final text has now gone into the Jisc production process :)]
Jisc has been providing expert, trusted advice on digital technology in the education sector for more than 30 years. We know that technology and data have the ability to transform the student experience. But, as a membership organisation owned by research and educational institutions, we must ensure our advice and guidance are responsible and safe for students, staff and institutions. With universities and colleges concerned about wellbeing and mental health problems among students and staff, and suggestions that increased use of data might help them provide better support, we were delighted to
have the opportunity of participating in the ICO sandbox
to test our ideas of how this might be done without increasing the risks to students and staff.
In the event, our discussions with ICO colleagues have been even more productive than we had hoped. We have explored possible legal bases for processing personal data to support wellbeing and mental health services and expanded our draft Code of Practice to include all relevant safeguards. In addition, with the ICO’s encouragement and support, we have developed new tools for educational institutions to conduct Data Protection Impact Assessments (DPIAs) for their planned activities and to assess purpose compatibility when considering new data sources. These tools should help institutions meet their accountability duty in the General Data Protection Regulation (GDPR).
Having completed our sandbox engagement we are now conducting a public consultation on the Code of Practice, including its Data Protection Impact Assessment and Purpose Compatibility Assessment Annexes.
Here we have some creepy applications of immersive technologies.
Body-cameras
and
mobile phone apps
that scan every passing face and search for anything they can find out about their identities and contacts… Incidentally, I’ve no idea what the smiley faces on the body-cam mean, but can you think of a less appropriate marker for someone “Wanted for felony…”?
So what’s the difference, and how do you ensure you build the latter, not the former?
Legal compliance should go without saying: safety, discrimination and data protection law in particular. And the General Data Protection Regulation’s guidance on designing Fair, Transparent and Accountable systems is good, whether you are using personal data or not.
But legality isn’t enough. Some lawful applications, like (at least at present) face recognition, are nonetheless very creepy; as are some applications that don’t seem to involve personal data at all. Racist hand-dryers, for example. So what more do we need?
I’d suggest it’s about “respect”, in three different ways:
First, respect for
equality
. Not just in the sense of non-discrimination, but equality of arms. By all means use immersive technologies to assist expert surgeons; but not to create inequalities or broaden digital divides. Instead they should be used to increase opportunity for all. Why can’t I have the best scientist on the planet as my buddy in VR-space?
I think this is why the face-scanning body-cam offends. An officer on foot is claiming equality: someone I can have a conversation with. A camera recording that interaction is for both our safety. But face recognition goes back to the dominant and controlling position of an officer on a horse or in a car.
Second, respect for
context
. This is Helen Nissenbaum’s idea that spaces and situations have implicit expectations as to data purposes and flows. In a conference room we wear name badges; here, perhaps, it might be acceptable to augment the Chair’s memory with a University Challenge-style voiceover when someone raises a hand. Incidentally, this illustrates that AR doesn’t have to be limited to augmenting vision. Outside, AR should not be making each of us expose our LinkedIn contacts on a virtual sandwich board. Incidentally, context is probably more of a challenge for AR, which intrudes into existing contexts, whereas VR defines its own.
Third, respect for
humanity
. I was going to say respect for rights, but it’s more than that. Don’t create superpowers, addicts, or release Pokemon Go characters into crowded streets. And think carefully before interfering with practical obscurity – what we don’t know is as at least as important for our sociability as what we do. Panopticons are for punishment.
In summary, if you respect us, then we are more likely to respect you as making a positive contribution to society, not shun you and your users. Comics and movies have known for nearly a century that superheroes are likely to be social misfits: let’s not make that our technological reality.
Originally posted: 25 March 2020 in category
Articles
If
Education 4.0
is about preparing students for the workplace of the future, that’s going to be a dynamically changing workplace. Even in my working life I’ve gone from
VT100s
to laptops and video-conferences. The mobile phone in my pocket is much more powerful than the first university mainframe I encountered. To send a single email abroad I had to determine and specify which transit points it should use to get there: now I can tweet to the entire planet without thinking (or, sometimes, intending!). The rate of change is still growing. And this applies to every workplace: even delivery drivers and police officers now have to be comfortable with a wide range of technology.
So this isn’t just about “multiple jobs over a career”: we’ve been planning for that for decades. Even if you stay in the same job, you’ll have to cope with multiple generations of different technologies doing completely different things. What those are is going to be much harder to predict. I remember being told in the late 1980s that I’d soon be working with robots and telepresence and have much more leisure time. None of that has happened; but no one told me I’d be comfortably working from home, trains, cafes, anywhere I can pitch my laptop.
So we need to be preparing students, not to work with a particular future technology and working style – we’ll almost certainly guess wrong – but with anything the next 40 years may come up with. A speaker at Digifest mentioned Adaptability Quotient (AQ) as the thing employers should really be looking for. But it does seem reasonable to assume that future work will be digital and involve communications, so everyone will need a level of familiarity and comfort with those. A recently-arrived colleague commented that Jisc was the most video-friendly place he had ever worked. None of us had noticed: it’s just the way we hold meetings.
So maybe it’s that kind of unconscious adaptation/adoption that we should be preparing students for. Two attributes in particular seem key: openness and curiosity. Openness leads us to say “I’ll give that a try”, curiosity says “how (else) could I use that (better)?”. And the good news for any human teachers still worried about being replaced by computers is that those skills are hard to develop using technology alone. Learning modules can teach us facts and techniques, but to develop the exploratory instinct we need to discuss their implications and consequences. Even the best AI is a long way from being able to join in the collaborative bouncing around of ideas that’s the most fulfilling, and important, part of learning, teaching and research.
Again, this doesn’t seem to be a new idea. Recently I’ve been looking at how we might think about Jisc’s services from an explicitly ethical viewpoint. One source stands out: according to the 1948
UN Declaration of Human Rights
, the purpose of education is “the full development of the human personality”. If we can do that then we’ll be well on the way to producing graduates who can flourish whatever the future requires of them.
Originally posted: 12 March 2020 in category
Articles
A fascinating Digifest talk by Westminster City Council suggested that students may have a key role in ensuring that smart city and intelligent campus projects deliver real benefits. Westminster have a partnership with two of their local universities – KCL and UCL – that gives Masters students access to the council’s extensive datasets about use of the city. Students, who are familiar with city life, can choose the problems they would like to investigate using these datasets: their choices and conclusions can both inform the council about what policies matter to residents and provide a strong evidence base for how they might be addressed.
Three projects were highlighted: examining the distribution of AirBnB properties in both space and time and, in particular, those in multiple ownership; looking at how use of leisure centres is distributed across council districts; and identifying different patterns in the use of electric vehicle charging points. In each case, having students make choices about their projects mitigated against the problems – of smart city activities being driven by vendors, funders or deadlines – that have been widely identified in both
research literature
and
news
. The council also commented that the students’ work was at least as good as that of professional consultants.
Westminster’s experience suggests that intelligent campuses may be able to follow a different, and more successful, path than most smart cities. Let students lead…
The question mark in the title of
my Digifest talk
is the key point, because I wonder whether data is the wrong place to start. In our current digital landscape, we’re all too used to hearing ourselves described as “silkworms”, donating “new oil” to “surveillance capitalists”; even the term “data subject” has a dehumanising feel.
All of these reflect a model where our activities are analysed, the results of that analysis go to benefit a corporate entity, and that corporate entity may share some benefit back to us. That may take the form of personalisation, “better service”, or simply access to the service without payment. Here the very best we can hope for is to get back as much benefit as we give away. But in education, I think, the flow of benefit is significantly different: here the activities of students and staff are analysed, and the benefits fed directly back to the individuals concerned. This may be hints to help them study or research better, pointers to relevant campus services, etc. The universities and colleges that perform the analysis benefit
indirectly
, from happier students, better learning and research outcomes, etc. The benefits to students should be greater than those to the institution.
So, rather than thinking about data, we should probably be thinking about benefits. How can we help students and staff,
then
which of our data can assist in that. There’s a useful categorisation of benefits in a
paper by Aion et al
: Learning, Health, Social, Management, Environment and Governance. This was written for intelligent campus data, but seems to cover most of our activities. And a
HEPI study
suggests that the majority of students would agree to their data being used to provide these kinds of secondary benefits so we are starting from a position of some trust.
So how to think about benefits? The first step is to identify them, and a good place to start that seems to be asking students and staff themselves. What might we do using data to make their lives better. It should definitely be an early warning sign if they don’t like our pet project at this stage. Consulting leads naturally on to transparency: being open about what we are proposing, open to comment and willing to change. Such engagement is radically different from what we are used to from commercial data users and should, itself, build trust.
Then we need to ensure the benefits are actually delivered by the systems, processes and data as we develop them. That means thinking about risks to individuals in the design stage, doing frequent temperature checks as systems operate, and responding quickly to any discomfort. Particular warning signs to look out for include individuals changing behaviour to avoid or obfuscate data collection, any reduction in the voluntary disclosure of information and any increase in the use of external, rather than internal services. Then review, whether the system itself delivered the benefits we expected, and also what we can learn from each design-operate-review cycle.
Three Jisc tools aim to help in different areas of benefit:
Learning
,
Wellbeing
and
Intelligent Campus
. These highlight key areas to consider: Governance and Transparency; Purpose Compatibility, Accountability and Impacts; Choice of Purpose, Choice of Data, and Ethics.
In all cases our thinking should be guided by three key points:
“Should we do this?”, not “Can we do it?”
“How does it feel?” (Big Brother isn’t a good look)
Individuals as part of the team, not part of the product
#409 - Consultation: Assessing the impact of (re-)using campus data
Originally posted: 11 March 2020 in category
Closed
Our university and college buildings already contain a surprising number of sensors that could collect information about those who occupy them. At a recent event I spotted at least half a dozen different systems in a normal lecture room, including motion detectors, swipe card readers, wireless access points, the camera and microphone being used to stream the event, and Bluetooth and other transmissions from the many laptops and devices we were all carrying.
There is increasing interest in using data from these sensors – and new ones installed for specific purposes – to make our campuses “better” in many different ways. A
paper by Aion et al
groups these possibilities into six categories: those that directly affect students’ learning; those involved in managing campus infrastructure; those that facilitate collaboration; those that provide institutional accountability; those that protect the environment, for example by improving energy efficiency; and those that create a healthy environment for learning and living.
With such a wide range of sensors and data to process and combine, and such a wide range of purposes, we need some way to assess the risks and benefits our plans will create for those who use the campus. Some possible uses of data will provide high benefit at very low risk: others will involve such high risks that, even with all possible mitigations used, they cannot be justified for the likely benefit.
To guide universities and colleges through this complex area, we’ve written a draft Data Protection Impact Assessment Toolkit, inspired by a Toolkit approved by European Regulators for RFID applications back in 2011. It is designed to help you work out how intrusive a particular application might be, what risks might arise, and what mitigations might be available to reduce these to an acceptable level. We’d very much welcome feedback on the toolkit: please send your comments to <
Andrew.Cormack@jisc.ac.uk
> by the end of June.
Article 6(1)(b) allows network providers to process electronic communications data (a term that includes both metadata and content) where this is necessary “necessary to maintain or restore the security of electronic communications networks and services”. Note that this is
not
limited to protecting the provider’s
own
network. Where information sharing (which is a type of processing) is necessary to protect the security of another network, this Article permits it.
Article 6(1)(c) uses the same phrasing for processing that is “necessary to detect or prevent security risks or attacks on end-users’ terminal equipment”. Again, this is not limited to the network’s own customers so, again, information sharing that is necessary for this purpose is permitted. Note that “end-users” includes both individuals and organisations (see Art.2(14) of the
Directive Establishing the Electronic Communications Code
).
In each case, “necessary” should be read in the GDPR sense of “objective cannot be achieved in a less intrusive way”, in particular, as is made explicit by Article 6(2), “if the specified purpose or purposes cannot be fulfilled by processing information that is made anonymous”.
This permission to share is even clearer by contrast with Article 6b(1)(e), which, according to Recital 17b, covers the processing of communications metadata for “detecting or stopping fraudulent or abusive use of, or subscription to, electronic communications services”. Here, Article 6b(2) imposes an explicit restriction that information can only be shared once it has been anonymised. Network operators that wish to offer fraud and abuse protection services to their users should probably do so by way of a service offering, where Article 6a(1)(a) appears to permit “necessary” processing of content, potentially including sharing of threat information.
Article 6b(1)(e) and Recital 17b, in particular, seem likely to be further modified before they become law, as they are part of the reintroduction into ePrivacy law of “Legitimate Interests” as a basis for processing, which has been controversial among the Council of Ministers and is likely to be strongly resisted by the European Parliament. The Article 6(1)(b) and 6(1)(c) security provisions should, however, be widely welcomed.
Originally posted: 30 January 2020 in category
Articles
In a world where data storage is almost unlimited and algorithms promise to interrogate data to answer any question, it’s tempting for security teams to simply follow a “log everything, for ever” approach. At this week’s CSIRT Task Force in Malaga, Xavier Mertens suggested that
traditional approaches are still preferable
.
With the speed of modern networks and systems, logging everything is almost guaranteed to produce files far too big for humans to interpret, so incident responders become entirely dependent on algorithms. And, since those algorithms don’t know which events or incidents really matter to the organisation, they may well highlight or explain the wrong things. Xavier suggested that having too many logs may well give organisations a false sense of security.
Another problem with this approach is that no one knows which logs are actually important, so it’s hard to work out which are worth spending time on when, for example, their format changes (if we even notice), or they are challenged by accountants or regulators.
So it seems it’s still better to start from a purposive approach: think through the kinds of incident that it’s most important for you to be able to deal with, work out which logs you need to investigate those, and ensure those are available for as long as there is any point in investigating.
If, as still seems to be too common, a breach
remains undiscovered for months or years
, investigation is likely to be more trouble than it is worth, since it’s likely that some essential knowledge will have been lost, and the attacker will have had ample time to do all the damage they want. Belated discovery of breaches is a sign that we need to improve our detection processes, not that we need to retain even more logs for even longer.
Originally posted: 24 January 2020 in category
Articles
[A second post arising out of excellent discussions at the
DALTAí project seminar
in Dublin this week]
We’re all familiar, perhaps too familiar, with how data flows typically work online. We give commercial companies access to data about ourselves; they extract some benefit from it, for example by selling profiled advertising space; they share some of that benefit back to us, for example in the form of services we don’t have to pay money for.
But that’s probably not how it works in education and research. Here, students and staff benefit directly from the use institutions make of data, and it’s the institutions that get the benefit at second-hand. That’s most obvious in one of the early uses of learning analytics: to help students at risk of dropping out. Institutions use data to identify and help those students, as a consequence the students who succeed in passing pay the institution another year’s fees. There may be a few cases where institutions benefit directly from data use – for example where they can make more efficient use of energy or space – but most situations seem to involve exactly the reverse flows of benefit from those in the commercial model. Successful students, successful teachers and successful researchers all channel
indirect
benefits from data and analytics to the institutions that do those analytics.
That’s a fundamental difference, which should lead us to think about data use in a very different way. Whereas, in the commercial model, the best we can hope for is that the benefits are shared equitably between the individual and the provider, in education, institutions are only likely to benefit if they can be confident that individuals will benefit more. And, to ensure that happens, we need to involve students and staff at the earliest stages of our plans to use data. If they can’t see a benefit, then it’s highly unlikely that any benefit will reflect onto the organisation. Students and staff may be able to suggest ways to increase the mutual benefit, or they may give us a strong signal that an idea won’t provide benefit to either individuals or institution.
Thinking about data and benefits in education and research suggests that early collaboration with staff and students may not just be a good thing from an ethical and legal perspective, but from an economic one too.
#404 - Learning Analytics: helping tutors help students
Originally posted: 24 January 2020 in category
Presentations
Talking to new audiences, who may not share your preconceptions, is a great way to learn new things. So I was delighted to be invited to Dublin to talk about learning analytics as part of their
DALTAí project
(an English backronym creating the Irish for student: bilingualism creates opportunities!). The audience – and my fellow panellists – came from a particularly wide range: students, tutors, ethics, regulatory, administrative, etc. all around one table.
In thinking about learning analytics, this blog has tended to focus on students. Their data is the source for most of what we do, and the law places clear obligations on institutions to protect their interests. And the response from them in Dublin was very positive: if institutions have data that they can use safely to improve the student experience, then please do it.
But learning analytics also involves tutors. They need to understand how the signals from dashboards can support and complement the ways they have supported students in the past; and, where necessary, they need to be helped to communicate that understanding to students. Messages based on data may actually be harder to discuss than those based on empathy. So, although the tutors’ attitude to learning analytics was positive, they were concerned that their ability to use it effectively would be limited without training in both interpreting and explaining its outputs.
Another area given qualified support was the idea of using analytics to improve learning processes overall, rather than to help individual students. The dilemma was well expressed: “I’m very happy to use data to improve my teaching practice: I’m not happy if it’s used to spy on my performance”. Organisational (and departmental) culture is key to this, as the tools involved are pretty much identical: if tutors fear the technology will be used to monitor them they are likely to resist it, a tool they are encouraged to use for personal development (with the option of asking for help when they choose) is much more likely to be adopted.
Finally, although data protection law clearly does apply to information about tutors’ performance, what its specific requirements are is much less clear. Most of the personal data about tutors will be inferred from the behaviour of their students, whereas most data protection guidance and discussion assumes that the person observed and the person affected are the same: the “data subject”. We should at least ensure that when assessing the risks and benefits of learning analytics activities we consider how those apply to tutors as well as to students. That’s particularly important because the two may well be counter-linked: the more we try to anonymise data about individual students by generating statistics for tutorial groups, the more likely we are to create data that is very much about the tutors who teach those groups.
#403 - EDPS preliminary opinion on Data Protection and Scientific Research
Originally posted: 9 January 2020 in category
Articles
The European Data Protection Supervisor has just published an interesting
paper on the research provisions in the GDPR
. The whole thing is worth reading, but some things particularly caught my eye:
Stresses (again) that research-consent is not the same as GDPR-consent, though the former may still be an “appropriate safeguard” when using a legal basis other than consent (pp18-20).
Tries (pp9-10) to distinguish GDPR provisions on “academic expression” from those on “scientific research”. The breadth of the former should not be a way to avoid the safeguards required by the latter.
Scratches head (pp20-21) on how to reconcile the right to information with research that requires subjects not to know what is actually being researched.
“Requires controllers to assess honestly and manage responsibly the risks inherent in their research projects” (p2)
Sees ethics review boards as key to that: in particular to distinguishing between public interest research (which should qualify for the various GDPR exemptions/presumptions) and “research which serves primarily private or commercial ends” (which should not). There’s a three-step test on p12, and a recommendation on p25 that Data Protection Officers should work with research ethics boards to refine both the rules and the applicable safeguards.
Suggests (p25) EU-level Code(s) of Practice to govern research practices in different fields.
Muses (p26) on a future right of access to large commercial datasets for research in the public interest.
Although the report concludes that “there is no evidence that the GDPR itself hampers genuine scientific reearch”, there is a recognition that “more time is needed to see how the special regime for data protection in the field of scientific research plays out on the ground”. As the list above indicates, several areas are identified as requiring further discussion, either within the research and data protection communities, or wider public debate.
#402 - Jisc response to ICO consultation on Explaining AI
Originally posted: 6 January 2020 in category
Closed
Jisc responded to the Information Commissioner’s consultation on draft guidance on explaining AI. The
final guidance
was published in May 2020.
We welcome the
ICO/Turing Institute’s draft guidance on Explaining AI Decisions
, and believe that it could be useful well beyond the narrow question of when and how decisions need to be explained. However, as a regulatory tool we suggest that it needs a clearer, and objective, definition of which systems are, and are not, covered by the term “AI”. We also have some suggestions to improve the usability of the guidance.
We consider the most significant contribution of the document to be its identification and analysis of six different types of explanation: rationale, responsibility, data, fairness, safety and performance, and impact. The guidance also provides helpful clarification that some of these occur before processing takes place and apply to the whole system, while others occur after processing and apply to individual decisions. We believe that this analysis could usefully be applied to most systems involving complex flows or large amounts of data, whether or not they involve “Artificial Intelligence”. Considering rationale, responsibility, data, fairness, safety and performance, and impact throughout the design, development, implementation and operation of large-scale data processing systems should be good practice to improve their safety for operators and individuals alike.
To deliver its full benefit, we therefore consider that the guidance should both make this broader scope explicit and, within it, provide a clear, objective, definition of “AI”. The draft contains only a statement (on Part 1, page 4) that “AI is an umbrella term for a range of technologies and approaches that often attempt to mimic human thought to solve complex tasks. Things that humans have traditionally done by thinking and reasoning are increasingly being done by, or with the help of, AI”. This appears to accept that “AI” is often used purely as a marketing term, and to leave it to individual marketing departments to decide whether their product or service falls within the guidance. Those that do not wish to follow the guidance may simply reduce the prominence of the term “AI” in their marketing materials, or replace it by some other term. Conversely, unrealistic expectations may be raised among data subjects that anything labelled “AI” will provide the explanations described in the guidance, even when these may not be relevant or necessary.
Our principal recommendation is therefore that the ICO/Turing Institute adopt an objective definition that can be applied consistently and objectively to determine which systems are, and are not, “Artificial Intelligence”. We have found the
definitions used by DSTL
helpful: in particular that AI consists of “Theories and techniques developed to allow computer systems to perform tasks normally requiring human or biological intelligence.”
Alongside that objective definition, we consider that the broad applicability of the guidance would be made clearer by changing the order of the Legal Framework section in Part 1. At present it begins with the narrow set of legally-significant decisions covered by Article 22. The much wider group of data controllers who may be required to provide explanations under Article 5 Fairness might easily conclude that the guidance does not apply to them. To avoid this, we would suggest presenting the Article 5 requirement, then Article 22, then the situations where explanations are good practice.
Part 2 is currently a very long block of text and, as a result, hard to navigate. Some sort of graphical representation would help readers find the sections most relevant to their application. It would also be helpful to provide a graphical indication when discussing types of algorithm that are inherently non-explainable.
Part 2 also contains an important point, which we consider should also be raised in the introductory or management Parts, on the need to train the humans who will be working with AI as an assistant. This involves striking a tricky balance between unquestioning over-reliance on the AI’s recommendations and encouraging humans to substitute their own biased judgments. Both training on when to over-ride the algorithm, and support systems to ensure this facility is not (consciously or unconsciously) misused are likely to be needed.
Part 3, page 17 mentions the Article 21/Article 17 right to object, but without explaining its scope and nature. In our experience the application of this right to AI has been widely misunderstood by both data subjects and data controllers. In the most extreme form of this misunderstanding we have heard model builders assert that it requires them to keep all the personal data used to build a model, in case one person exercises their “right to object” and they are required to rebuild the whole model from scratch omitting that individual’s data. This guidance would be a good place to counter such high-risk practices by providing an authoritative statement of what the right does, and does not, require.
Finally, we welcome the recognition that for some applications of AI, “gaming the algorithm” is a positively desirable feature. Jisc has done considerable work on applying analytics to various fields in education and research. By examining data generated by teaching and research processes we hope not merely to predict likely outcomes, but to identify changes that can result in actual outcomes being better than those predicted. This presents new challenges throughout the lifecycle of such systems: algorithm developers must not just explain why a certain prediction was made, but also what needs to be done to improve it; users and regulators must understand that predictions that turn out to be inaccurate may actually be a sign that that the system is achieving its objective.
This week I’ve been presenting at an event on Artificial Intelligence in Education, organised by the Finnish Government in their current role as EU Presidency. Specifically I was asked to look at where we might find building blocks for the ethical use of AI in education.
Looking at the
EU High Level Experts Group list of Principles and Requirements for Trustworthy AI
, it seems that the General Data Protection Regulation can be a significant building block. At least seven of their eleven “ethical” issues are already covered by the GDPR, which means both that ethics is a legal requirement, and that we have a lot of guidance both from the law itself and from regulators’ guidance on how to implement it.
That seems to leave three areas: whether we should do things at all (the HLEG call this Societal and Environmental Wellbeing); whether we should let machines do it (though the GDPR does suggest some guidance on “automated decision making”); and, if so, how much and what kind of explanation of those decisions we should require. To make those a little more concrete we looked at three specific questions: should students be allowed to use AI to tell them which passages to study in order to pass their exams; should we let AI decide which students are accepted onto an over-subscribed course; and whether teachers need to have a complete understanding of how an AI predicts grades, or just the factors that affected each student’s prediction. Answers to all of these turned out to be highly dependent on detail, confirming that we do, indeed, need some ethical principles on which to base our answers.
As to where we might find those, there are plenty of ethics codes available (one speaker thought around a hundred!); there may also be GDPR-based guidance (the UK Information Commissioner has just published a 150 page
draft on explainability
); and I suggested we might need to keep in mind the UN Human Rights Convention’s statement of the purpose of education: “the full development of human personality”.
In summing up, Ari Korhonen from Aalto University reminded us of the essential need to maintain trust, and suggested that it might be useful to review how we retain that when delegating tasks to other humans, for example using teaching assistants or external examiners.
Originally posted: 6 December 2019 in category
Presentations
A few weeks ago I gave a presentation to an audience of university accommodation managers (thanks to Kinetic for the invitation), where I suggested that we should view Data Protection as an opportunity, rather than a challenge.
That may seem strange, given that universities probably have the most complex data flows of any organisation. And there definitely are challenges, resulting from both sides of our hybrid nature as part-business, part public service. From the one we may inherit a feeling that consent is the answer to everything, from the other a tendency to think that data sharing agreements are some kind of magic wand; both sides take us into areas where the legislation is unclear, for example the extent of our public function; research has its own special issues; and there’s always a temptation to assume that if “they” are doing something then it must be OK.
But it seems to me that the new General Data Protection Regulation actually creates an opportunity to distinguish ourselves from bad practice in both commercial and government sectors. The GDPR introduces a principle of Accountability, which I summarise as data controllers demonstrating that they have thought about their data processing activities themselves, rather than simply relying on either data subjects’ “consent” or “common practice” when it gets to tricky areas. For an organisation practising accountability, the law becomes a guide to how to do things right, rather than a barrier to be worked around in the hope that it will be someone else that gets found out.
A tool we’ve used to do that is the Data Protection Impact Assessment (DPIA), which has helped us to a better understanding of the complex balance of interests around
running a Security Operations Centre
,
providing a Learning Analytics Service to universities and colleges
, and using data to
improve support for student Wellbeing and Mental Health
. And DPIAs shouldn’t just be internal activities: by publishing the resulting reports (with redactions if needed, but so far it hasn’t been) we can both demonstrate that we have thought carefully about what we are doing, and reassure users and funders of our services that what we are doing is necessary, proportionate, beneficial and appropriately protected.
The positive response we’ve had from law-makers and regulators, as well as users and funders, suggests that this is indeed a distinctive and welcome approach.
#399 - Laws to help security and incident response
Originally posted: 4 December 2019 in category
Presentations
Last week I was invited to be a member of a panel at the UN Internet Governance Forum on how law can help security and incident response and, in particular, information sharing. It seems there are still concerns in some places that privacy law is getting in the way of these essential functions.
I started from how bad things would be if it were actually against the law to share information for security and incident response. Patches and anti-malware systems would be slower to arrive, since those often require sharing personal data. So our systems – PCs, phones, security cameras, baby alarms – would be vulnerable to attack for (much) longer than they are now. Reporting of attacks would be nearly impossible, since that almost always requires sharing of details of attacking computers, accounts or websites. And, of course, it would be illegal to inform victims, so once their systems had fallen under the control of malicious outsiders, they’d stay that way. Eastern Berlin seemed a particularly apt place to be discussing such a nightmare scenario for privacy.
From that counter-example I derived four characteristics that Internet defenders need in a law on information sharing:
It has to be part of a privacy law, which recognises that insecurity is among the biggest threats to privacy, and contains internal checks and balances to protect both defenders and victims;
It has to be clear, so defenders can get on with defending and not spend scarce resource worrying about legality, or (apparently still a concern in some quarters) whether they need attackers’ consent to send out warnings;
It has to be limited to what is necessary, and require defenders to demonstrate that their activities have a net benefit for internet security and individual users’ privacy;
It has to have a broad scope – covering at least the operators of networks and connected systems, vendors, researchers and users – so that changes in legal regime don’t create unnecessary barriers to sharing between those groups.
It seems to me that Recital 49 of the
General Data Protection Regulation
gets pretty close to those requirements. We were also asked about regimes elsewhere, such as those based on the Council of Europe’s
Convention 108
. Interestingly the European Court managed to infer something quite close to Recital 49 when examining the earlier Data Protection Directive in the case of
Breyer v Germany
, so even if your local law doesn’t contain an explicit Recital 49 equivalent, similar information sharing practices may still be OK.
I had also prepared some notes on how those drafting laws in this area might do even better than Recital 49:
Although Recital 49 talks about “processing necessary for security” it doesn’t explicitly mention information sharing. You need to follow the trail through “legitimate interests” in Article 6(1)(f) to discover the
safeguards under which that is permitted
;
The GDPR as a whole still creates some puzzles, even impossibilities, by combining a very wide definition of “personal data” (including IP and MAC addresses) with binary obligations on anyone processing “personal data”. No matter how much the law may demand that you proactively contact someone whose IP or MAC address you have, that may be technically impossible;
These, and other issues, still raise the temptation to argue that “an IP address is a machine not a person”, so that privacy law shouldn’t apply. Security and incident response teams shouldn’t need to rely on legal quibbles to make their actions lawful: they should be able to embrace privacy law wholeheartedly and show how their actions are essential to comply with it (here the encouragement from the Article 29 Working Party to “
put in place processes to be able to detect and promptly contain a breach
” is particularly helpful).
Done right, privacy and security should be very much on the same side. Both need to keep information secure from malicious actors to achieve their purpose. And both are damaged every time a computer falls under the control of such actors.
#398 - BEREC clarifies that permanent network security measures may be OK
Originally posted: 25 October 2019 in category
Articles
Four years ago, Jisc responded to the Board of European Regulators of Electronic Communications (BEREC) consultation on network neutrality to point out that
some security measures
cannot just be temporary responses by the victims of attacks, but need to be permanently configured in all networks to prevent them being used for distributed denial of service and other attacks. This applies, in particular, to blocking of spoofed addresses, as recommended by
BCP-38
. The final 2015 version of the BEREC guidelines contained a four word change to the consultation draft, suggesting that
such measures should not be considered as breaking network neutrality
.
BEREC is now consulting on
new draft guidelines
, published in October 2019, which contain a much more explicit statement that permanently configured blocks do not automatically breach neutrality:
NRAs should consider that, in order to identify attacks and activate security measures, the use of security monitoring systems by ISPs is often justified. Such traffic management systems consist of two separate components: one component that executes the traffic management itself and one component that monitors traffic on an ongoing basis and triggers the traffic management. Monitoring of traffic to detect security threats may be implemented in the background on a continuous basis. Traffic management measures (such as those listed in paragraph 84) preserving integrity and security are only triggered when concrete security threats are detected. Therefore, the precondition “
only for as long as necessary”
does not preclude implementation of such monitoring of the integrity and security of the network.
[Paragraph 85]
This should be welcomed by network operators and users alike.
Originally posted: 23 October 2019 in category
Tools
One of the key steps in preparing for the
General Data Protection Regulation
is to know why you are processing each set of personal data, and which of the six legal justifications applies: consent, contract, legal obligation, vital interest, public interest or legitimate interest. The Regulation significantly tightens the rules on when consent can be used, so data controllers may well have to look more closely at the other five. Each justification has different implications for when processing is allowed, the information you provide to data subjects, and the rights they can exercise, so the choice of the most appropriate one for each processing activity is likely to drive much of your subsequent compliance activity.
[Note that, as the Article 29 Working Party noted on page 8 of their
Opinion on Consent
, a single activity may involve a combination of justifications. For example on an interactive website such as this, the processing of user accounts required to post comments is “necessary for contract”; the processing of logs to detect misuse and security incidents is “necessary for a legitimate interest”; adding your name or a photo to the comment is by “consent”]
The Recitals to the Regulation contain quite a lot of information, and examples, of when each of the justifications is likely to be appropriate. This post attempts to gather that into a summary of the kinds of processing likely to be suited to each justification. In each case I’ve suggested a question as an initial check whether the justification is likely to fit your processing – these are just hints and carry no legal significance, nor are they the only questions you need to consider before making your choice.
Contract
: covers processing that is necessary (i.e. there is no less intrusive way to perform the agreement) either for an existing contract to which the data subject is a party, or in preparation to enter into a contract at the data subject’s request. This includes exporting personal data where that is a necessary part of the contract. The EDPB has provided
more detailed guidance on this basis
. Note that in English law “contracts” are not limited to those on paper, so this justification is also likely to cover less formal agreements between a data subject and a data controller.
Q: “is this required to deliver an agreement with the individual?”
Legal Obligation
: covers processing that is necessary to fulfil a legal obligation to which the data controller is subject. The obligation must be set out in EU or national law, must meet an objective of public interest and be proportionate. Examples include obligations in the fields of employment and social security, including those that require processing sensitive (now known as “special category”) personal data.
Q: “am I required to do this by law?”
Vital Interest
: covers processing that is necessary to protect a vital interest (something essential to life) of the data subject or a third party. This can include necessary exports of personal data. If the data subject is capable (both in law and in practice) of giving consent to the processing, that justification should be preferred.
Q: “is this processing needed to protect someone’s life?”
Public Interest
: covers processing (by both public and private bodies) that is necessary for some public interest. That interest must be set out in EU or national law, and any processing must be proportionate to it. The law may designate a particular data controller to carry out the function (“exercise of official authority”); this justification also covers other organisations that wish to share relevant information with those authorities. Examples include taxation; reporting crimes; humanitarian purposes; preventive or occupational medicine; public health; social care; quality and safety of products, devices and services; election campaigns.
Q: “is this processing needed for some legally-defined public purpose?”
Legitimate Interest
: covers processing that is necessary for a legitimate interest of the data controller or a third party, provided that interest is not overridden by the interests and rights of the individual. The Article 29 Working Party provided
detailed guidance on how to ensure this balance of interests is met
. Processing is more likely to satisfy the balance if it is expected given the nature of the relationship between the individual and the data controller. This justification cannot be used when exercising official authority (use “necessary for public interest” instead). Examples include processing necessary to detect fraud or report criminal activity, to protect network and information security, for internal administration in a corporate group or not-for-profit organisation.
Q: “would this processing surprise or upset the individual, given our relationship?”
Consent
: the only justification that does not include the word “necessary”. May therefore be used for data and processing that are not necessary, but should not be used for processing that is (use one of the “necessary” justifications instead). According to the
Information Commissioner’s guidance
consent is appropriate when the individual, not the organisation, is in control of processing. Individuals must have a genuine choice what (if any) personal data to provide and must be able to change their mind at any time. In particular consent should not be used where there is a clear imbalance in negotiating strength (employers and those exercising official authority are likely to have difficulty obtaining genuine consent), or when “consent” is made a condition of providing some other service (use “necessary for contract” instead).
Q: “is this processing truly optional for both the organisation and the individual?”
Originally posted: 23 October 2019 in category
Tools
The European Data Protection Board’s (EDPB) latest Guidelines further develop the idea that we should not always expect relationships involving personal data to have a single legal basis. Although the subject of the
Guidelines is the legal basis “Necessary for Contract”
, much of the text is dedicated to pointing out the other legal bases that will often be involved in a contractual relationship. Trying to squeeze all of the processing into a single legal basis is unlikely to help either the individual (“data subject”) or organisation (“data controller”).
The Necessary for Contract basis is, itself, much narrower than is often claimed. First because it is limited to processing that is necessary for the performance of the specific contract with that particular data subject (para 26), or for preparatory steps such as responding to an enquiry (para 46); and second because – according to the definition of “necessary” common to all legal bases – the processing must be the least intrusive that will permit the contract to be performed (para 25). In particular, the EDPB point out that “necessary for contract” does not mean “required by contract” (para 27). Conversely, by entering into a contract, an individual does not Consent to the processing that is necessary to deliver it (para 20), otherwise they could withdraw consent at any time, which probably isn’t what the supplier wants! An interesting test is suggested in paragraph 33’s checklist – would the data subject view this data/processing as necessary in order to deliver what they have asked for? An important test for the data controller is that processing that is claimed to be “necessary for contract” should usually cease when the contract terminates (para 44); the EDPB mention a few exceptions, such as providing product warranties, but these are very limited (para 39). If you expect the processing to continue after the contract is performed, then it probably isn’t necessary for the performance of the contract!
Instead, many of the processing activities that often surround a contract should be done under different bases and, importantly, subject to the legal conditions that apply to those bases. For example fraud prevention might be Necessary for a Legal Duty, or Necessary in the Legitimate Interests of the supplier, but it is not necessary for contract (para 51). If the legitimate interests basis is used then, as usual, there must be a balancing test of those interests against the rights and freedoms of the individual. Service improvement is not necessary for contract (para 49): it might be done by consent (for example through optional feedback forms), or perhaps as a legitimate interest, subject to the balancing test. If consent is used then it must be free, informed and opt-in, and definitely not tied to the delivery of the product or service.
#395 - Reducing your vulnerability to insider threat
Originally posted: 12 July 2019 in category
Articles
Monica Whitty’s keynote at the FIRST Conference (
recording
available on YouTube) used interviews at organisations that had been victims of insider attacks to try to understand these attackers – and possible defences – from a psychological perspective.
It turns out that thinking about stereotypical “insider threats” probably doesn’t help. Notably, disgruntled employees were responsible for a surprisingly small proportion of such incidents. Far more were identified by their colleagues as having a strong company loyalty. In demographic terms, attackers (at least those that were detected) show very similar patterns to typical workforces. Personality traits appear more promising, until you realise that the traits most likely be involved in insider incidents are also those in demand among successful organisations, particularly in ICT.
One thing that does seem to distinguish insider threats from other workers is motivation. By far the most common is addiction (including to something as innocent as bingo), followed by challenging circumstances in their personal life. And, strikingly, these were often known to the organisation before the incident took place. The trigger for them acting was often a sudden increase in anxiety. So it seems that a significant reduction in insider threat may be possible simply by providing better support for employees who seek help in dealing with personal problems. Organisational culture can also reduce the opportunity for insider threat – if someone is behaving strangely, it should be acceptable to ask if they are OK. Refusing to share passwords, let someone in to an area where they are not authorised, etc. should not be seen as lack of trust, but as helping them avoid a self-destructive path.
My attention has been drawn to
research by the Software Engineering Institute
that highlights the importance of (perceived) organisational support in general, not just when employees are experiencing difficulties.
Originally posted: 11 July 2019 in category
Articles
Leonie Tanczer’s FIRST 2019 keynote
(
recording
now available on YouTube) looked at more than a decade of European discussions of whether/how to regulate the Internet of Things (no, I didn’t realise, either) and how we might do better in future. This is particularly relevant to an incident response conference as – as Mirai and other incidents have revealed – CSIRTs are, and will continue to be, strongly impacted by whatever incentives regulators may (or may not) create.
There’s little question that the IoT involves many complex issues – in particular lack of knowledge, lack of incentives, and lack of monitoring of the results of the previous two – however it seems odd that consumers can (if they choose) rely on regulators to deliver a safe bottle of milk, but are left to themselves to assess the safety of the internet-connected fridge they store it in. In a global supply chain liability – either of vendors or distributors – may not be an effective way to internalise the external costs of insecure devices. And such discussions as have taken place in the past have tended to concentrate on only the first half of the IoT lifecycle – design, purchase and setup – and omitted the much longer, and more hazardous, questions of maintenance and disposal.
However in recent years there have been more promising signs.
ENISA’s Baseline Security Recommendations for IoT
come highly recommended. Also, whereas older studies suggested that consumers seem not to have understood that it might be worth paying extra for a more secure device or service, in recent years there has been both much stronger interest in security labels, and a (probably demographic) shift to devices being bought in physical shops than online. This suggests that even a
simple labelling scheme such as that recently consulted on by the UK Government
(no default passwords, a reporting channel for vulnerabilities and a date until which patches are guaranteed) may have some beneficial effect. If the fridge, like the bottle of milk, has a “best before” date then that might provide a helpful signal in purchasing choices.
Finally, although discussions on IoT Governance may not seem to be moving forward, they are definitely moving upward, with the WTO, OECD and World Economic Forum all expressing an interest. Security and Incident Response teams – not just those directly associated with product security – should take any opportunities to provide input and experiences.
#393 - Rebuilding trust in the Internet’s building blocks
Originally posted: 11 July 2019 in category
Articles
Merike Kaeo’s
keynote “Waking Up the Guards”
at the FIRST 2019 conference (
recording
now available on YouTube) highlighted how attacks on the internet core no longer target a single service (naming, routing, signing) but move between these to achieve their hostile result. Defenders, too, need to consider the consequences of their implementation choices as a whole, to reduce to opportunities for bad things to happen “in the seams” of the Internet. Thus, for example, an attack on DNS that started by exploiting weaknesses in BGP routing needs to be mitigated through a combination of prefix filtering, Resource Public Key Infrastructure (
RPKI
) and DNS Security (DNSSec). Those may well be managed by different parts of the organisation, or even different organisations, which need to work together to ensure the individual tools are effective in combination. Default settings – which are often selected for ease of debate, rather than overall security – may not be the best choice.
Key building blocks to all these systems are hard-to-impersonate identity, integrity, confidentiality and audit but, again, their interactions need to be understood. Ensure they do actually complement one another, rather than introducing single points of failure. Encryption, in particular, needs to be deployed with care: over-use may add little to confidentiality, but severely limit auditability. If an operator cannot detect when their infrastructure has been compromised then there’s little benefit in passing on confidential communications to an unknown and probably hostile destination. Identity typically depends on some kind of credentials, but the security aspects of their whole lifecycle – generation, distribution, storage, recovery, delegation/transfer, revocation and destruction – need to be understood to avoid introducing weakness.
Finally, although Merike limited this point to communications with managers, it seems to me that it may be more widely valuable. Don’t talk in acronyms, as I have here (!), say what a protocol or service actually does. Even for technical people, once in a while talking about “ensuring authoritative answers come from the expected place” might highlight mismatched assumptions that would be hidden by simply repeating “DNSSec”.
Originally posted: 11 July 2019 in category
Articles
Apparently Miranda Mowbray had been wanting to do a talk on “
Things that Go Bump in the Night
” for some time, and it made an excellent
closing keynote
for the 2019 FIRST conference in Edinburgh (
recording
now available on YouTube). Although “things” may increasingly need an Internet connection to operate, there are significant differences between them and end-user devices such as PCs, laptops and phones that defenders can use to their advantage.
First, the range of communications required by a “thing” should be much narrower than a general-purpose computing device. Both the protocols and destinations involved in its traffic should be easier to enumerate. Whereas networks of end-user devices may be too troublesome to do more than alert on unexpected traffic, for networks connecting things the precautionary principle of “block unknown traffic until we understand it” probably can, and should, still apply.
Where traffic is allowed, similar things (unlike similar PCs) ought to behave similarly. An unusual pattern of behaviour by a single thing – especially if that behaviour then spreads to nearby things – is probably a sign of trouble. Bumps in the night are, indeed, worth listening for: configuration changes and administrative access should happen during working hours.
But the most extreme oddities may well be mis-configurations, rather than hostile action. Two atmospheric dust sensors showed very similar peaks suggesting, perhaps, a passing dustcart. Except that their reported positions were continents apart: Boston, Massachusetts and Antarctica. After some thought it was realised that an owner swapping Latitude and Longitude was the most likely cause of this particular long-leggity beastie!
Originally posted: 17 June 2019 in category
Articles
An interesting talk from Rockwell at
this year’s FIRST conference
looked at how to organise incident response in environments containing network-connected hardware devices. Though Rockwell’s focus is on industrial machinery, the same ideas should apply to smart buildings and other places where a security incident can cause physical, not just digital, harm. This is not the only difference: connected hardware devices tend to be much more diverse than PCs, and they are expected to have much longer lifetimes. Those deploying Operational Technology (OT) are also more likely to focus on availability and integrity, whereas their colleagues in Information Technology (IT) worry mostly about confidentiality.
The traditional advice for OT devices has been to place them on a separate, segmented network, and rely on a strong perimeter defence. However this becomes harder as connected hardware systems increasingly depend on controllers implemented as cloud services. This turns out to be an area of convergence with IT: nether can now function as isolated islands cut off from the Internet.
Instead we need to use “home field advantage”: ensuring that defenders know more about their networks and what is connected to them than attackers do. For OT, in particular, this requires processes and protocols that help defenders work together. Network monitors may well spot what seems to be an unusual flow, but without input from the OT side they will find it hard to determine its meaning or importance. Is this proprietary flow a relatively harmless device receiving a software update, or a safety critical device being compromised? Rockwell are developing a single incident response platform where people from IT and OT sides can collaboratively analyse events, but also, at a more basic level, establishing communications channels and mutual understanding so incident responders can contact equipment operators in real-time to say “we’ve just spotted X: were you expecting that?”. That way we can not only respond effectively to current alerts, but learn together to handle future ones better.
We’d like a framework that could include services that cover all students, not just those who
consent
to their personal data being processed for this purpose;
We want to act (or alert the students) early, well before doing so is
necessary to protect their vital interests
; and
At least at present, such a service is considerably more than
necessary for universities’ legal
duty
of care
under common law.
In trying to find a legal basis that fits the space between these three, the fact that such a service may well be inferring health data – i.e. special category data – from non-special-category activity data is helpful. Rather than just six broad legal bases for processing personal data in Article 6, for special category data, GDPR Article 9 has ten and Schedule 1 of the Data Protection Act 2018 (DPA) more than twenty-five. These are, of course, much more narrowly defined. But if our processing fits one of these narrow definitions, then we can work back to the appropriate Article 6 basis, and identify at least a minimum set of safeguards for the processing.
Going through the DPA Schedule – a process memorably described by one legal scholar as “like wading through treacle-coated spaghetti” – the best fit appears to be
paragraph 17 in Part 2
– that the processing is “necessary for the provision of confidential counselling, advice or support or of another similar service provided confidentially”. A further promising sign is the restriction in 17(2)(c) that that paragraph can only be used where “obtaining the consent of the data subject would prejudice the provision of the service”. As above, that does indeed describe our situation. So,
as discussed in an earlier post
, we’ve chosen this particular area of spaghetti as the likely basis for a Code of Practice. Comparing with our
legal framework for Learning Analytics
, paragraph 17 and its associated Article 6 justification (which appears to be Public Interest) would cover the orange Collection and Analysis (of Wellbeing) stages.
Since this is a new area for holding data-informed conversations, it’s particularly important to test and validate the results – are we using the right data sources? are we extracting the right signals from them? are we informing students (and others) of those signals in constructive ways? But it’s debatable, in strict legal terms, whether that testing is actually “necessary” to deliver the counselling service. Since validation, in particular, may well require processing additional data – for example about historic outcomes for those who both were and were not flagged by the system – it may in any case be preferable to do that under a different legal basis, with a strong Chinese wall between the two activities. This should reduce the risk of leakages in both directions: that testers become aware of individual identities, and that validation data might be incorporated into the live early warning system, for example. Rather than stretching Schedule 1 Paragraph 17, these requirements are a much better match for the rules on handling data for “scientific or historical research or statistical purposes” in GDPR Article 89 and
DPA section 19
, so we are likely to use those as the basis for this part of the Code of Practice.
If there are any other explorers of this area of law out there, I’d love to compare maps. And many thanks to the Jiscmail subscriber who pointed me at paragraph 17 when I was stuck in a GDPR dead-end.
Originally posted: 18 April 2019 in category
Articles
In data protection circles, the phrase “Safe Harbour” doesn’t have a great reputation.
Wikipedia describes those
as setting hard boundaries around an area where “a vaguer, overall standard” applies. Famously, in 2015, the European Court of Justice struck down the data protection Safe Harbor arrangement negotiated between the European Commission and the US Government. So I was surprised recently to hear someone describing
GDPR Recital 49
as a “safe harbour” for actions to protect network and information security. Looking at the other ways that the drafters could have recognised the importance of protecting security reassured me that Recital 49 is, indeed, significantly more than that.
One option would have been to use the approach used in GDPR Article 5(1)(b) for archiving, research and historical purposes: to declare that processing for network and information security is “not incompatible” with the purpose for which the data were originally collected. This would limit the processing to the designated purpose – network and information security – but, at least according to the GDPR, there are few other limits. This feels like a “safe harbour” in the Wikipedia sense. The
UK Data Protection Act 2018
does add a requirement that, to qualify for the research purpose, processing must be done in ways that are not likely to “cause substantial damage or substantial distress to individuals”, and the results must not be used for “measures or decisions with respect to a particular data subject”.
Alternatively, maintaining the security of networks and systems could have been treated as just part of the provision of those services. This, arguably, is how network security is treated under
Article 6 of the draft ePrivacy Regulation
. This links the security activities tightly to service provision, but provides little restriction or guidance on they should be conducted.
Instead Recital 49 declares maintaining network and information security (NIS) to be a separate purpose, subject to the requirements of the Legitimate Interests basis in Article 6(1)(f). This makes it subject to both types of restrictions, in each case more tightly defined than by the research or Privacy approaches. The NIS purpose is much more narrowly defined than “research” and, rather than simply avoiding risks of “
substantial
damage”, organisations must consider whether
any
“rights and freedoms of the individual” might override the benefits of the security processing. Fortunately, those data protection requirements are very closely aligned to the requirements of security and incident response: taking care of logfiles and other data is essential to avoid helping those who wish to attack our systems, as well as to protect the privacy and other rights of our users.
So, not so much a safe harbour as a snugly fitting dock.
Originally posted: 16 April 2019 in category
Articles
The Government’s new
White Paper on Online Harms
is strikingly wide in both the range of harms identified, and the range of entities asked to play a part in reducing them. The White Paper envisages that harmful content could be spread through any online facility that allows individual users to share content, to find content shared by others, or interact with each other. The White Paper – recognising that this includes not just entities usually classed as social media platforms but also “retailers that allow users to review products online, along with non-profit organisations” – encourages a proportionate, risk-based approach to regulation. This will be essential, as many of the technical tools used by major social networks to block the uploading of unlawful or harmful material to their sites are unlikely to be available to the thousands of retailers whose review pages might, in theory, be used as a venue for abuse.
Although universities and colleges may offer comment and public feedback pages, they are likely to have already assessed the risk of them being used for the main types of harm identified in the White Paper. Colleges’ existing safeguarding duties should already cover the risk of their online services being abused in ways harmful to young people; both universities and colleges should have considered the terrorism risk as part of their Prevent duties.
The White Paper envisages that the measures expected of organisations at different risk levels will be set out in Codes of Practice produced by the (yet to be appointed) Regulator. Given the relatively low attractiveness of university or college pages for disseminating harmful material, it would be surprising if these required more than is likely to be in place already: an effective route to flag inappropriate content, with post- or pre-moderation as a fallback option if a site were actually to become a target for misuse.
The Intelligent Campus is a microcosm of the Smart City. Smart cities, according to
Finch and Tene
, may be “more livable, more efficient, more sustainable and more democratic” or “turn into electronic panopticons in which everybody is constantly watched”. Intelligent Campuses amplify both of these possibilities since – unlike cities where space and data are owned by many different organisations – a university may well control and monitor the whole physical and digital infrastructure of its students’ lives, from bed to workplace to social spaces. Students and staff might well consider such monitoring “creepy”, or worse. But that single control, and the strong shared interest between campus managers and occupants, may make the goal of smart citizenship easier to achieve on campus than in cities, where political and commercial interests have largely limited the relationship to a paternalistic one, at best.
Our responses to monitoring depend not only on fact, but on sentiment. Attitudes to electronic monitoring, in particular, are often set by the behaviour of social networks and other commercial service providers. Campus occupants used to hearing that they are
“the new oil”
or “digital silkworms” (Brown & Marsden, 2013) need to be reassured about the purposes, intentions and incentives of those who monitor, as well as how monitoring is currently performed. Campus managers therefore need to ensure their plans and actions are acceptable to both their organisation and the campus occupants. If not, occupants may well respond by changing behaviour – for example swapping identities or providing deliberately incorrect data – in ways that undermine both the intelligent campus and, more importantly, its primary purposes of research and education.
As well as smart city literature, tools borrowed from other fields can guide us towards intelligent campuses that are accepted by their occupants. Many implementation issues are shared with Radio Frequency Identification (RFID) technologies, for which
a toolkit
was endorsed by European Data Protection Regulators in 2011. When selecting appropriate purposes for intelligent campus technologies, ethics codes on using digital data for research and policy formation are relevant.
Intelligent campuses can be viewed as having three ‘senses’: sight, sound and location. Sight includes PIR sensors that indicate whether or not a desk is occupied, and face recognition analysis of live video images; sound can record conversations, or detect whether a room is empty; location and movement of devices and individuals can be gathered from wireless access points, door access or payment cards. As these examples indicate, all three senses cover a similar, wide, range of intrusiveness. Rather than ranking the senses, it is better to generalise and extend the four-level impact scale from the RFID guidance: presence, counting, identifying, recording and (new) analysing. This gives an immediate indication of the likely level of intrusiveness, and the depth of analysis and mitigation likely to be required.
The context from which information is gathered can significantly affect both intrusiveness and perception. A standalone Passive Infra-Red (PIR) desk-occupancy monitor is much less intrusive in a hotdesk area than a personal, locked office, or if its data are linked to login or other information that can identify individuals. Some spaces, such as bedrooms, offices and toilets, are always considered more sensitive, but universities may also have spaces such as counselling services and some laboratories where monitoring, and its results, require particular protection. Sight sensors naturally respect opaque boundaries, such as walls, but sound and location may leak through them.
While
an extended version of the RFID toolkit
provides guidance on controls – such as organisation and policy, system architecture, sensor choice, and other risk reduction measures familiar when protecting personal data – these may be insufficient to ensure acceptability. For this we need to consider not just legal questions (‘what
can
we do?’) but also ethical ones (‘what
should
we do?’).
Kitchin
identifies six ethical concerns for smart cities: datafication, dataveillance and geosurveillance; inferencing and predictive privacy harms; anonymisation and re-identification; obfuscation and reduced control; notice & consent empty or absent; data use, sharing and repurposing. The
Menlo Principles
for digital research ethics and the
UK Government’s 2016 Data Science Ethical Framework
for policy formation reinforce the need for organisational controls, but add choice of purpose; robust models (in both theoretical and data science senses); and awareness of – possibly changing – public perception.
One of the greatest challenges in either a smart city or intelligent campus is to ensure that occupants are informed about data collection and use. Much data collection takes place through passive observance, unlinked to any specific action by the individual (entry and payment cards are a rare exception); many internet of things sensors are designed to be unobtrusive. Individual occupants may well be, or become, unaware of data collection, reducing the effectiveness of traditional protections such as notice, consent and objection. In any case, it is often unreasonable to rely on individual actions to control risk: individuals cannot realistically avoid using campus infrastructures, and should not be burdened with daily, or even more disruptive, consent decisions.
The concept of “smart citizenship” may well help with this transparency challenge, as well as identifying acceptable uses of intelligent campus technologies and holding institutions accountable for their activities. Rather than viewing citizens as “consumers or testers”, authors such as
Cardullo and Kitchin
propose involving them from the start in the selection, design and monitoring of smart city or intelligent campus. Policies or proposals that feel unfair, creepy, or worse, to citizens will be discovered – and improved or rejected – at an early stage, before money or infrastructure has been deployed. Such an approach also reflects the ethical need to be aware of public sentiment, and the legal requirement for Data Protection Impact Assessments to consider consultation with individuals. Smart citizens guide the development of their city, rather than merely occupying it. The complexity of cities has, so far, prevented the achievement of this concept. The simpler organisation of an intelligent campus might be an opportunity to show how it can be done.
Reference (book)
Brown, I & Marsden, C. (2013)
Regulating Code: Good Governance and Better Regulation in the Information Age
. Cambridge: MIT Press.
Originally posted: 22 March 2019 in category
Articles
To my ex-programmer ears, phrases like “web 2.0” and “industry 4.0” always sound a bit odd. Sectors don’t have release dates, unlike Windows 10, iOS 12 or Android Oreo. Oddly, one field that does have major version releases is the law: it would be quite reasonable to view 25th May 2018 as the launch of Data Protection 3.0 in the UK. Looking at past release cycles, it seems likely to be fifteen to twenty years before we see version 4.0. During that time, the web, industry, education, technology and all other uses of personal data will develop in ways that those drafting the law could not have foreseen. The gap between what the law says and what technology makes possible is bound to increase.
You might hope that a brand-new law would at least answer current questions: “what can we (lawfully) do?”. But, with a ‘developer release’ fixed in 2016 and initial drafts dating back to 2012, even that may be optimistic. From now on it’s inevitable that we’ll be asking questions that the drafters could not have envisaged. Principles may remain valid – indeed the 2016 General Data Protection Regulation (GDPR) declares that the principles of its 1995 predecessor remain sound. But details will steadily diverge from reality.
To bridge that gap, we need to ask a different question: “what
should
we do?”. Not just because the law’s answers are unlikely to be clear (e.g. the long-standing legal distinction between controller and processor is very hard to apply to many cloud service models) but because such answers as it does give may no longer reflect individuals’ expectations (e.g. both regulators and web users seem increasingly uncomfortable with the law’s current rules on cookies). Even if the law does appear to give a clear answer to a question, we should probably double-check that with other sources.
We are already starting to see that, with universities and colleges asking “is this ethical?” rather than just “is it lawful?”. Reference points for that question include the
Data Protection Principles
, but also documents such as the
Menlo Report: Ethical Principles Guiding Information and Communication Technology Research
. Academic analysis of related areas such as smart cities can also provide useful sources to compare and contrast: if we are different, what risks and opportunities might that difference create? An ethical approach asks us to think hard about what we are doing, to document our draft conclusions and try to achieve consensus on an acceptable approach.
This may well be more time-consuming than simply looking up an answer in “the law”, but it should produce a more robust plan that can respond to legal, ethical and practical challenges. Some organisations seem to stagger from one legal, ethical or PR incident to the next. Doing ethics first, and being transparent about the process and outcome, should help us avoid that. Once we’ve decided what we should be doing, it’s easier to go back to the law, identify the relevant sections, and work out what it says about how we should be doing it.
Such a process is more likely to accord with another trend in both data protection law and public attitudes: away from simply dumping decisions on the individual (often labelled as “consent”, though it rarely satisfies either the ethical or legal definitions) and towards organisations taking responsibility and demonstrating that they are doing so. The GDPR calls this
“accountability”
, though it covers more than just holding organisations to account for errors. Individual rights and controls are still important when things go wrong – though we’d hope that that only happens where an unknown fact or unforeseen event affects the ethical assessment – but we shouldn’t be relying on them to correct the faults we leave in our designs.
Data Protection 3.0 should, perhaps, be less about “pushing the boundaries” and more about developing responsible practice. That might be confirmed by regulators and, one day, incorporated into the next release. “Compliance”, even if we could define it, should be the very least we aspire to.
Student support is simplest when an individual themselves asks for help: a support service can immediately begin to discuss – using
toolkits such as that developed by UHI and AMOSSHE
– what the problem is and how the university or college can help. Sometimes a friend will report concerns: in this case the support service needs first to work out how to contact the individual and find out if they do, indeed, need help. This must be done in ways that minimise risks to privacy, wellbeing and trust (in both the organisation and the friend).
It has been
suggested
that algorithms like those used for learning analytics might be able to act as “friends” for everyone in the university: raising alerts when data suggest there may be a wellbeing issue. This amplifies the challenges of human friend reporting – not least because we can’t discuss concerns with an algorithm – and expands the risks, as well as the potential benefits, to everyone, not just students with concerned friends.
The Jisc
Learning Analytics Code of Practice
and
legal model
seem to provide a good basis for this kind of Wellbeing Analytics, but both need to be adapted to deal with health (in legal terms “Special Category”) data. The rules derived from Legitimate Interests for “Analysis of Learning” need to be supplemented for “Analysis of Wellbeing” with those for Preventive Medicine in EU law, and for Public Interest/Confidential Counselling under the UK Data Protection Act 2018.
Probably the most important point is that policies, data, systems, algorithms and processes need to be overseen by health professionals, though they can be operated by tutors and others. As a recent Guardian article observes,
these processes look a lot like medical diagnosis
, which is a regulated activity.
Data Protection law, too, is likely to consider wellbeing analytics a high-risk activity, requiring a formal
Data Protection Impact Assessment
to identify the risks to individuals and ensure they can be managed. Prior consultation with the Information Commissioner may also be needed. Wellbeing Analytics will require even greater care than Learning Analytics in describing, protecting and reviewing the data, processing and results.
Finally, thinking of algorithms as a “friend” highlights some particular concerns:
Beware of anything that could feel like “surveillance”: no one asks Big Brother for help;
Keep testing and refining the data and algorithms, just as you test and refine your guidance to human friends: remember that the algorithm will never be “right”;
Start from a robust process for human friends: strengthen it to cope with algorithmic “friends” who know everything about data, little about context and nothing about empathy.
Originally posted: 7 February 2019 in category
Presentations
Earlier this week I did a presentation to a group from Dutch Universities on the ethics work that Jisc has done alongside its studies, pilots and services on the use of data. This covered the development of our
Learning Analytics Code of Practice
, as well as our plans to apply that Code to wellbeing applications, and work to develop an
Impact Assessment toolkit for Intelligent Campus applications
.
In section (a) the nature of processing should mention any new technologies or novel processing and retention periods for data. There’s also specific information about the context: how many data subjects there are, where they are located, what our relationship is with them and what expectations they are likely to have of us and our processing.
In section (c) the harms considered should include discrimination, fraud, financial loss, reputational damage, physical harm, loss of confidentiality, reidentification, other significant economic or social disadvantage
In section (d) measures and safeguards include training, documentation, pseudonymisation, and reduced retention.
We’ll be using this revised cribsheet for future DPIAs, including when we revisit the existing ones.
Originally posted: 28 January 2019 in category
Articles
Incident response teams often share information when investigating incidents. Some patterns may only become apparent when data from different networks are compared; other teams may have skills – such as analysing malware – to understand data in ways we cannot. Since much of this information includes IP or email addresses – information classed as Personal under data protection law – concerns have arisen that attackers might be able to use the law to frustrate this sharing.
Article 14 of the General Data Protection Regulation (GDPR) normally means that as soon as an organisation receives personal information, it must ensure that the individual knows about this. If attackers had to be informed every time their information was shared, this would tell them when they needed to modify their tactics or to wipe compromised systems to conceal their traces. Fortunately, Article 14(5) suspends the duty to inform if doing so “is likely to render impossible or seriously impair the achievement of the objectives of that processing”. Investigating an attack seems exactly the kind of processing this clause is designed for.
There have also been concerns that an attacker might use their “Right to Be Forgotten” to erase evidence. However the Article 17 Right to Erasure only arises once there is no lawful reason to continue processing. That’s unlikely to be the case while an investigation is in progress. Since the Right also requires the intruder to identify themselves and to help the data controller find the information relating to them, incident responders might actually welcome such requests…
Of course, victims of attacks also have a right to be notified under Article 14. Providing such notifications is one of the main aims of Incident Response. There will normally be a natural point – once an incident has been confirmed and its likely consequences and victims are understood – when that is most beneficial. Until then, it is likely to be better to rely on Article 14(5) again, on the basis that premature, uncertain notices to people who may not be victims are likely to cause more distress than benefit and would therefore be disproportionate, as well as “impairing the achievement of the objectives” by causing unncessary alarm.
While applying the Article 14(5) postponement, there is a special duty to “protect the data subject’s rights and freedoms and legitimate interests”. Again, this is absolutely compatible with what Incident Response requires: failure to keep shared information secure, or using it for anything other than network and information security, is likely to undermine those purposes, or even make the situation worse.
Originally posted: 14 January 2019 in category
Articles
Under current plans the UK will become – for data protection purposes – a “third country” when it leaves the EU. Although the UK Government has stated that
the rules for transferring personal data from the UK to the EU will remain the same
, any transfers from the EU to the UK will need to satisfy the “export” clauses in Articles 44 to 49 of the
General Data Protection Regulation
. These rules could be enforced – as in my
blog post on GDPR for universities in North America
– by EU regulators prohibiting particular data exports (though I’m not aware of this happening for current third countries), by exporting organisations deciding that transferring data is too risky, or by individuals objecting, either to the exporting organisation or to their national courts.
Where organisations receive information direct from individuals, they may need to provide additional information and assurances about how the data and individuals’ rights will be protected, as there may be uncertainties whether these can still be enforced under EU law.
UK-hosted cloud services are likely to join other non-EU providers in offering SCCs to their international customers. UK organisations are likely to be able to continue to use EU-based clouds as at present: although retrieving personal data from such a cloud might possibly constitute an “export” this does not seem to have concerned Regulators so far [UPDATE: there is no mention of it in the
Irish DPC guidance on no-deal Brexit
]
Note that the UK’s
Data Protection Act 2018
incorporates the export clauses along with the rest of the GDPR, so any UK organisation exporting personal data to the rest of the world will continue to be responsible for ensuring that those provisions are satisfied. This could involve the same UK organisation having to accept SCCs as an importer from the EU, and to insist that other (non-EU) organisations accept SCCs when it exports personal data to them.
Originally posted: 12 December 2018 in category
Presentations
With the GDPR having now been in force for more than six months, my talk at this week’s
EUNIS workshop
looked at some of the less familiar corners of the GDPR map. In particular, since EUNIS provided an international audience, I was looking for opportunities to find common, or at least compatible, approaches across the international endeavours of education and research.
Originally posted: 7 December 2018 in category
Articles
The Government’s powers make orders relating to information about communications have now moved from the
Regulation of Investigatory Powers Act 2000
to the
Investigatory Powers Act 2016
. The associated
Code of Practice
provides useful information on the process for issuing three types of notice in particular: Communications Data Requests, Technical Capabilities Orders and Data Retention Notices.
Under the new Act,
all three of these powers can be applied to private networks
like Janet and its customer networks – under RIPA Technical Capabilities and Data Retention were limited to public networks – so it’s worth checking that your own processes would do the right thing if one of these were to arrive.
Communications data requests
(as under RIPA s22, which had pretty much the same process) can just arrive without warning. Normally (s6.21) they are in writing, but they may be oral in urgent cases. You’re not required (6.25) to do anything which it is not reasonably practical to do: in particular there’s a useful warning to those making requests that just IP+time is often not enough to identify a connection, something they must take into account both when deciding how to specify the order and when considering how much collateral intrusion the order may involve. Normally (6.27) a response is expected within ten working days.
Technical capabilities orders
to adapt networks and systems to make communications data orders easier to fulfil will (12.2) “only be given to operators required to give effect to authorisations on a recurrent basis”. Under RIPA these were limited by law to public networks: this volume test seems likely to limit any expansion to private networks. Operators are consulted in advance (12.10) on technical and economic feasibility, at this stage they can also agree who any notice should be sent to. If there is no agreement then (12.18) it must be served on a “senior executive”, which addresses the concern that the Act appeared to allow notices to be sent to junior network technicians. Orders must be reviewed at least every two years (12.31) and this must include consultation with the operator.
Data retention notices
. Importantly, the Code
confirms
(16.1) that “the default position is that no operator is required to retain any data under the Act until given a notice”. The Code seems to say (17.3) that notices will only be issued if you are receiving more Communications Data Requests than you can handle; but there is also mention of the possibility (17.8-17.10) of placing a requirement on all wifi providers in a particular geographic area. The latter presumably links to the use case suggested by the Home Office during the debate on the Act, if a particular cyber-café became popular with terrorists, in which case only public wifi would be relevant. The Home Office must consult before issuing a notice (17.2) and “in practice, informal consultation is likely to take place long before a notice is given in order that the operator(s) understands the requirements that may be imposed and can consider the impact” (17.12), so there should be plenty of warning.
For both retention and technical capabilities, cost recovery must be agreed before any implementation begins (22.10) so there’s a lot to agree before any notice is put into effect.
Finally, if an you receive any of these orders, your organisation should keep a record for two years in case of any investigation by the Regulator. The Code sets out (24.10-24.16) what needs to be recorded: for communications data requests the identity of the authority making the request, the unique reference number, and the dates when the required information was specified and delivered.
Originally posted: 19 November 2018 in category
Presentations
I’ve been asked a number of times whether GDPR affects the sharing of information between incident response teams. This slideset from a recent RUGIT Security meeting discusses how GDPR encourages sharing to improve security, and provides a rule of thumb for deciding when the benefit of sharing justifies the data protection risk.
#377 - Assessing the DP Impact of Jisc Security Services
Originally posted: 12 November 2018 in category
Presentations
At last week’s
Jisc Security Conference
I presented a talk on how we’ve assessed a couple of Jisc services (our Security Operations Centre and Penetration Testing Service) from a data protection perspective. The results have reassured us that these services create benefits rather than risks for Jisc, its customers and members, and users of the Janet network.
It is also important that end-users, including legal entities, have the possibility to take the necessary measures to secure their services, networks, employees and customers from security threats or incidents. Information security services may play an important role in ensuring the security of end-users’ digital environment. For example, an end-user as an information society service provider may process its electronic communications data, or may request a third party, such as a provider of security technologies and services, to process that end-user’s electronic communications data on its behalf, for purposes such as ensuring network and information security, including the prevention, monitoring and termination of fraud, unauthorised access and Distributed Denial of Service attacks, or facilitating efficient delivery of website content. Such processing of their electronic communications data by the end-users concerned, or by a third party requested by the end-users concerned to process their electronic communications data on their behalf, should not be covered by this Regulation.
That’s not a complete solution, because it still leaves security logs collected by network providers (explicitly permitted by Article 6(1)(b)) on a different basis from security logs collected by connected organisations (ruled out of scope by Recital 8). That could cause problems when sharing information about security incidents among different types of organisations – notably Article 6 may remove processing by network operators from the requirements of a GDPR “legitimate interest”, whereas Recital 8 leaves processing by websites and others within that regime. It also relies on a statement in a Recital over-riding the statement in Article 2(1)(a) that
all
processing of communications metadata “in connection with the provision and the use of electronic communications services” is within scope. Also, this is only a draft text, which still has to be agreed both within the Council and with the European Parliament.
But it should, at least, act as a sign to Regulators to take care when applying a Regulation whose purpose is, after all, to improve the security of online information.
Between Collection and Analysis there’s a necessity/relevance filter so that not all the available data debris are uploaded to the analysis algorithms; between Analysis and Improvement there’s a strong filter that removes all personal data and transfers only information on how to improve the learning environment for all; between Donation and Analysis students themselves choose whether to provide data at all; the filter between Analysis and Intervention only passes information about students who could benefit from a particular intervention.
Tutors should always have policy guidance on how to use learning analytics safely; rather than giving them free rein to study and (mis-)interpret the raw learning data as in a
recent Dutch example
(machine translation works OK!), our model implements technical controls that support that safe use.
Originally posted: 12 September 2018 in category
Articles
In developing our
Data Protection Impact Assessment for the Janet Security Operations Centre
we noted that our Penetration Testing service could involve high risks, but didn’t really fit the DPIA framework.
Penetration tests
are much smaller scale than the SOC; they are commissioned by individual Jisc customers, usually on only parts of their operations; and it’s the customer that has the ability to address any security issues found, and thereby ensure that the net effect on data protection is positive.
Unlike the SOC activity, penetration testing does involve actively searching for weaknesses in the technical and human security of systems likely to contain personal and special category data. So we thought it was important to assure ourselves and customers of the service that we were managing the privacy risks appropriately. The Information Commissioner has recently introduced a lightweight process for
Legitimate Interests Analysis (LIA)
, which seemed a good way to meet that need.
As described in the
report
, the LIA process involves identifying:
The interest(s) served by the processing – in this case, improving the security of customers’ key data processing systems;
What personal data are processed, and that this is necessary to achieve that purpose;
Whether the benefits of the processing justify the risks; and
What safeguards can be applied.
Jisc can – and, we believe, does – ensure that we only process personal data to the extent necessary for the testing we have been asked to perform, and that that processing is subject to appropriate safeguards. However the security benefits that justify those risks depend on the customer acting on the report we provide. The main conclusion of the LIA activity is therefore to emphasise the importance of customers addressing the problems that our tests identify.
Originally posted: 17 August 2018 in category
Articles
Recently I’ve been presenting our
suggested legal framework for learning analytics
to audiences involved in teaching, rather than legal people. For that I’ve been trying out a different visualisation, which considers the teaching process as involving three layers:
Teaching itself (red): during which we process the personal data that’s needed to help students learn. The legal model considers that to be a contracted (whether formally or informally) service that should deliver benefits to each learner.
Improving the teaching process (orange): during which we process data (including personal data) about how students learn. This should be done in ways that minimise the impact on individual students – the aim is to improve teaching for everyone. Legally, this is a legitimate interest of the institution, which must be balanced against the risk to the rights and freedoms of students and teachers.
Students voluntarily improving their own learning (gold). This may involve students donating additional data (how much I studied last week, etc.); and/or students following personalised guidance derived from the teaching improvement stage about (e.g. trying different learning styles, classes, etc.). In both cases it’s up to the student whether or not to participate: the institution should try to ensure the minimum detriment to those who don’t. Legally, each donation of data or adoption of a personalised suggestion is done on the basis of free, informed, consent, so students not only get to choose whether or not to participate, they get to choose which activities to participate in.
Originally posted: 16 August 2018 in category
Articles
Alongside the
1995 Data Protection Directive
(DPD) sat the
2002 ePrivacy Directive
(ePD), explaining how the DPD should be applied in the specific context of electronic communications. In fact, particularly after it
was amended in 2009
, the ePD did a bit more than that, as it turned out to be a convenient place to insert new ideas such as breach notification and incident response during the lengthy process of developing the General Data Protection Regulation (GDPR).
In 2016 the
GDPR text
was finally agreed, incorporating most of the ideas from the ePrivacy Directive. Nonetheless,
following consultation
, the European Commission proposed that the GDPR, too, should have an accompanying ePrivacy Regulation (ePR) for the electronic communications sector.
According to the Commission
this was needed to deal with:
New Players: Over-the-Top services that look like phone/messaging but are currently regulated differently;
Stronger Rules: Regulation rather than Directive;
Regulating both content and metadata;
New Business Opportunities: all based on user consent;
Cookie simplification: to address the problem of “cookie fatigue”;
Spam protection: opt-in for marketing by all electronic media (not just email), possible mandatory marking;
Enforcement: by Data Protection Authorities rather than Telecoms Regulators.
The
Commission’s draft
was published in January 2017, with the intention that it would come into force alongside the GDPR on 25th May 2018. That didn’t happen. In December 2017 the
European Parliament agreed that 168 amendments
were needed. These are generally more privacy-protecting than the Commission’s draft, for example on tracking/cookie walls and privacy by design. As of July 2018, the European Council is still discussing its proposed amendments to the Commission draft, in many cases heading in the opposite direction from the Parliament. In the meantime, the combination of new GDPR and ten-year-old ePD – which was never supposed to exist – is becoming increasingly awkward to work with.
Since there’s still quite a way to go before the bodies even start to discuss how to reconcile their differences, it’s worth identifying the areas where there is general agreement, so a reasonably clear legislative future to design for, versus those where there is still disagreement, so likely to be continuing uncertainty. Of the areas most relevant to educational institutions, the following seem pretty clear:
Opt-in location-based services. All parties seem happy that an app that tells me where the nearest free terminal is, or guides me to my next lecture, should be fine. The actual design of those apps can make a significant difference to the risk they represent;
Counting mobile devices in a location. All parties seem to agree that some types of “statistical counting” are acceptable; identifying popular hotspots seems to be the least intrusive of these. As discussed below, though, applications that involve tracking devices over time are more contentious;
Cookie classes. All the kinds of cookies that were
exempt from the consent under the ePD
are likely to retain that status (though many will require notice under the GDPR). As proposed by Regulators in their 2012 Opinion, “audience measuring” has been added to the exemption, though it is not clear how far this can be combined with other uses such as advertising. The
ICO’s notice on its own website analytics
is worth keeping an eye on.
Security. There is general agreement on the principle that using communications data to improve the security of systems is a good thing. The actual text that is supposed to enable this is, however, a self-contradictory mess!
By contrast there are still significant differences between the positions of Commission, Parliament and Council on the following, so planning in these areas should include the possibility that the law may change significantly:
Location tracking. Applications that record a sequence of locations of a mobile device cover a wide range of privacy intrusion, and it’s not clear where the boundary of legal acceptability will be drawn. Legislators all seem to like queue-measuring applications – recording how long devices are stationary before moving to the other side of an airport security check, for example – but academics have also discovered that just four or five location points may be sufficient to uniquely identify an individual. Any plans in this area should ensure that they include strong privacy safeguards: data minimisation, short retention times, technical and organisational controls, etc. And be aware that they may become unlawful as the result of either a legislative decision (in which case there will probably be a (de-)implementation period) or court ruling (in which case there will not);
Cookie walls. The ePR is clear that some cookies require consent; the GDPR is clear that consent cannot be linked to the provision of a service. Yet there is still a considerable range of views on whether it is lawful for a website to refuse service to those who do not accept additional cookies. Websites should at least ensure that they know which cookies are, and are not, necessary for the technical operation of the service. And probably have a Plan B for the latter (if any) in case separate, opt-in, consent does become a legal requirement.
Browser requirements. Since the original 2002 Directive, it has been envisaged that websites would be able to rely on browser settings to obtain consent. In other words “if you accepted my cookie, it must be because you’ve positively consented (via browser settings) to that”. Unfortunately for that idea, pretty much all browsers accept cookies by default. The Commission and Parliament proposals would finally have opened up this possibility by requiring browser defaults to reject (most) cookies but, after many months of discussion,
the Council now seems to have decided the whole thing is too hard
and is proposing deleting that Article. That means websites probably do still need to obtain opt-in consent for any cookies that aren’t covered by the exemptions (see ‘Cookie classes’ above) and users will still suffer from “consent fatigue”.
Marketing. I wasn’t sure whether to include this in ‘clear’ or ‘unclear’ since it seems highly unlikely that the current situation will change. Post-Regulation there will still be endless discussions over what constitutes marketing, whether sending to business addresses counts, what constitutes a valid ‘opt-in’, etc. There may even be a new definition to debate, if the final text differentiates between advertising that is “sent” versus “presented”…
Originally posted: 3 August 2018 in category
Articles
Over recent months the GDPR has given extra weight to concerns –
originally expressed by regulators fifteen years ago
– about public access to information about individual registrants of DNS domains. This article considers the use of this WHOIS data by those handling information security incidents, and why this represents a benefit, rather than a risk, to the objectives of data protection law.
Dealing with Information Security Incidents
As has been repeatedly recognised by legislators and regulators, the prompt detection and remediation of information security incidents is an essential part of keeping personal data secure. The processing of personal data necessary to do this is declared a legitimate interest in Recital 49 of the
General Data Protection Regulation
(GDPR); on page 6 of their
Guidelines on Breach Notification
the Article 29 Working Party recommended that all data controllers and processors should conduct such activities. The compatibility of the GDPR’s requirements with current incident response practice is discussed in
Cormack (2016)
.
Examples of WHOIS use
Incident responders use WHOIS contact details in a number of different ways to respond to, and prevent, information security incidents. For example:
When a website is reported as being involved in phishing, or installing malicious code on its visitors’ computers, WHOIS data may be the only trustworthy way to contact the site’s owners and alert them of the need to protect their visitors. WHOIS contact data may also provide an indication whether this is a legitimate site that has been taken over by criminals, or one that was created with malicious intent. Without WHOIS information it is likely to take longer, and may be impossible, to report the malicious activity, particularly in generic Top Level Domains where it may not even be possible to determine which country’s incident responders to contact. WHOIS is the only way of directly reaching out to the web site owner. Engaging through intermediaries such as upstream providers adds significant delay and uncertainty and removes agency from the web site owner to take action on a web site compromise.
When domains are registered for the purpose of cyber-attacks, WHOIS data may allow incident responders to prevent incidents, as well as mitigate them. This is because criminals often register large numbers of domains using the same contact details. When the first of a group of such domains is reported, incident responders can check for other domains with the same contact details and proactively filter or block traffic to or from those before they are used. Without WHOIS data, each malicious domain must be dealt with individually, after it has already caused harm. This technique can be used to mitigate attacks from botnets, malware, phishing and spam, among others.
1. The legitimate purposes of the processing of registrant data and of the disclosure in the public directory need to be defined. These legitimate purposes need to be limited to the narrow remit of ICANN, which is to manage the assignment of names and numbers in a manner that assures the security and stability of the Internet.
Responding to on-line information security incidents is clearly within both the remit of ICANN and of Data Protection law.
2. The personal data collected from and about registrants must be limited to that which is necessary for the purposes as described in recommendation No. 1 of this Working Paper. This includes the processing of data necessary for the registration of the domain name. Also, the personal data disclosed in the public directory must be limited to that which is necessary for assuring contactability of registrants in the event that there are technical issues related to the name registered.
As example 1 above highlights, incident response is precisely dealing with a “technical issue[] related to the name registered”. No additional information is required for the use case in example 2, though it does require the ability to search actual contact details, rather than the ability to contact via a pseudonymising service.
3. (relating to Law Enforcement access) Access to personal data must be as provided for by law. Such law needs to be transparent, foreseeable and proportionate to the legitimate aim pursued in a democratic society.
Although this relates only to law enforcement, it should be noted that, as discussed above, incident response is both provided for by law and recommended by Regulators. Indeed for network operators, it is a legal requirement under Article 4 of the
ePrivacy Directive (2002/58/EC)
.
4. There are two data retention requirements in the 2013 RAA19 which are problematic in terms of data protection law. ICANN should reexamine them and ensure compliance with applicable law.
The incident response examples given above do not require data to be retained after the domain is de-registered. If historic data continues to be available then patterns can be used to identify and prioritise incidents likely to cause significant harm: for example if a domain was previously held by a legitimate entity but is now registered to an unknown person this suggests a takeover with hostile intent; or if a domain referring to a bank in one country is held by an individual in another part of the world this is likely to indicate preparations for a phishing attack. Here the small risk to legitimate registrants of retaining historic information is likely to provide a much greater benefit to them and their customers when malicious activity can be detected and stopped.
5. Any new Registration Data Service should investigate means of restricting searches to those related to the purpose of the processing of the data.
Such policy restrictions already exist in the membership rules of several incident response associations (See below)
6. ICANN should explicitly address the issue of transborder dataflow in its policies, and ensure that data transfers ensure adequate data protection is maintained.
Cross-border flows of WHOIS data may occur whenever an incident responder identifies a domain as being involved in an information security incident. Whether a responder within Europe is notifying a non-European registrant of an incident, or a non-European team is notifying a European registrant, the responder, the registrant and any data subjects of the registrant’s systems all have a strong legitimate interest in that flow being permitted by law.
7. Commercial data which may be disclosed must not include personal data.
This appears to refer to situations where commercial data are assumed to be non-personal, and therefore not subject to data protection law. This distinction is not necessary for incident response purposes, since these can be achieved while processing all disclosed data in accordance with personal data law.
8. The IWGDPT recommends that ICANN develop a data processing policy that is in line with the requirements of existing privacy legislation and internationally recognized data protection and privacy principles and standards.
This paper demonstrates how the use of WHOIS data is, indeed, in line with those requirements.
Incident Response Associations
Various associations of incident responders bind their members to policies that support the beneficial use of WHOIS data, as described above. The following also have existing authentication systems that could be used as a basis for enhanced access to WHOIS data by their members who are bound by those policies:
Originally posted: 25 June 2018 in category
Articles
It’s only lunchtime on the first day of the
FIRST Conference 2018
, and already two talks have stressed the importance and value of reviewing incidents over both the short and long terms. In the very different contexts of an open science research lab (LBNL) and an online IPR-based business on IPR (Netflix), a common message applies: “don’t have the same incident twice”.
After you have detected, mitigated and recovered from an incident, make the time to understand the sequence of events and how they were (finally) discovered. If an attack was quickly detected and blocked then that won’t take long. But where an attack moves undetected through several phases it may well be useful to adopt what Netflix described as a “purple-team” approach, looking at each stage from both the attacker (red) and defender (blue) perspectives. What options did the attacker have to make progress, and what options might the defenders have used to stop those.
Sometimes this will highlight the need for new defensive tools and techniques. But if you have a long-term record of how past incidents were detected, that may contain existing approaches that could be reused against new types of attack. Such a record can also inform when to retire tools and techniques that aren’t proving useful in detecting or preventing attacks.
And the first talk after lunch added another point. DON’T do this while the incident is in progress. The right time to ask “how could we have stopped this?” is afterwards. So maybe the question should be “how could we have stopped this sooner?”.
Since there was a lot of interest in my keynote presentation at the EUNIS 2018 conference last week, this post collects together the slides and the blog posts that provide further analysis and discussion of the ideas:
On the question of which legal bases are available to universities and colleges – in particular whether they are included within the GDPR’s disapproval of consent and legitimate interests being used by “public authorities” – the previous advice remains, that “[public task] is likely to give [public authorities] a lawful basis for many if not all of [their] activities”. However this is now qualified by the requirement that such activities must be “to perform your official functions as set down in UK law” (p.22) confirming
our earlier analysis
that where universities and colleges are performing functions that are
not
“set down in UK law”, the other five legal bases remain available, in the same way (and for the same functions) as for any other organisation.
In the light of the GDPR’s
stricter conditions on consent
, the guidance repeatedly mentions legitimate interests as an alternative, that will “help ensure you assess the impact of your processing … and consider whether it is fair and proportionate” (p.32). This might apply in particular where an activity will benefit an individual so much that they do not really have a free choice, and it is more appropriate to expect the data controller to assess and minimise any harmful side effects. However the guidance does confirm that a decision does not have to be completely neutral for the individual’s consent to be valid – “it may be possible to incentivise consent to some extent” (p.26).
As discussed at
Jisc’s GDPR conference last year
, there has been confusion between the ethical requirement for consent when doing research on human subjects and the legal basis for the data processing. The ICO confirms that these are “entirely separate” (p.33) and that a requirement to gain ethical consent does not mean that legal consent is either appropriate or even possible. As above, legitimate interests – with its extra requirement on researchers to manage risks – may be an alternative.
Finally, where consent is used, page 40 suggests how to think about renewing it. The guidance recognises that situations vary greatly, but suggests as a starting point that consent should be “refreshed” every two years. The requirement to consider “how disruptive repeated consent requests would be to the individual” sounds like an encouragement to refresh consent through normal communications, rather than a repeat of the re-consenting frenzy that has occurred over the past month.
Originally posted: 31 May 2018 in category
Articles
Learning analytics dashboards, like the class mark books that long preceded them, show tutors a lot of information about their students. That could be pretty intrusive, so should universities and colleges be asking students to consent before tutors look at their data? I don’t think so, both because the students most likely to benefit are probably the least likely to provide the positive response that the GDPR requires, but mainly because this seems an ideal opportunity for institutions to “
take responsibility for what [they] do with personal data
“, in the Information Commissioner’s phrase, rather than passing the whole of that burden on to students.
According to the dictionary definition, looking at a dashboard is not an intervention, because it is not an attempt “to affect the outcome of a situation” [Chambers 2003]. That sort of intervention – such as suggesting that a student attend a more advanced class – may follow after consulting a dashboard, but is best treated as a separate data processing activity. In terms of the
Jisc learning analytics model
: the dashboard is part of the institution’s legitimate interest in providing a good educational experience; the suggestion of an additional class is the intervention, to which the student can freely consent or not.
This means that dashboards and their use must be designed to minimise the risk of impacting the students, in particular to avoid infringing their rights and freedoms. In most cases this is likely to be achieved through a combination of technology and policy. Layered dashboards could provide summary information for all students and allow tutors to look more closely at particular individuals who appear likely to benefit from interventions. Appropriate use of such dashboard tools must be a rule of academic policy. Limiting tutors’ access to only the students they teach could be done either through technology or, if there are frequent changes, through policy.
Using legitimate interests as a basis also means the benefits of processing must be assessed. Dashboards and the interventions that result from them must have a clear, demonstrable benefit to learning. The balance between that benefit and the risk of processing must be explained to students, and individuals whose circumstances place them at increased risk have the right to have that balance re-assessed in their particular case.
Jisc’s Learning Analytics Code of Practice
provides a framework for these and similar issues.
Adopting and documenting such an approach would contribute to
demonstrating accountability
, as required by the GDPR. More importantly it should reassure both students and tutors that these powerful tools can, and will, be used to everyone’s benefit.
Instead, look at your processes for detecting and responding to breaches. If you don’t have such processes, write them. Those processes will tell you which logs you need: for attacks from outside, logs from externally visible servers and network flows are likely to be the foundation; for internal attacks, and to deal with complaints, you need to be able to translate the local IP and email addresses in those logs and reports into the identity of the individuals responsible for the problematic activity.
Jisc’s technical guide to logfiles
has more detail. Exercises are a good way to test processes and logging: start from a (theoretical) report or alert (
NIST Appendix A
is a good source of example scenarios), and apply your response process to confirm that it works. That may highlight that you are missing some logs, tools or processes; or that you are unnecessarily keeping logs that no process will ever use.
As to how long to keep logs: clearly you need to keep them long enough that you’ll be able to investigate the incidents that are discovered. Getting better at discovering your own incidents should mean that happens more quickly. Monitoring how long it takes you to detect incidents and then to fix them can be a useful indicator of the effectiveness of your incident response, as well as a guide to appropriate retention times. However surveys still show that
incident detection can take several months
, particularly in sectors or organisations where the majority of incidents are detected by third parties. If you are one of those, improving your own detection is a better approach than keeping logs longer in the hope that someone else will eventually find your incidents for you.
Under the General Data Protection Regulation, the justification for retaining logs is that
the benefits to users of detection are greater than the risks caused to them by retention
. But the longer an intruder stays in your systems undetected, the less benefit there will from a detailed investigation. Once the intruder has taken all the data accessible from a system, backdoored it to give them a full and persistent control, and modified applications and logs to conceal these activities, the benefit of all those logfiles is pretty small.
Many years ago, the UK Data Protection Commissioner suggested keeping routine logs for three to six months. Logs for incidents being investigated can obviously be kept for longer if required. At the time, we hoped that improved detection and investigation techniques would gradually let us reduce that period but, sadly, it still seems about right for most organisations.
Where we might have been inadvertently captured was in the provisions for DNS Services. These cover both authoritative domain servers and DNS resolvers, and the thresholds originally proposed by the UK Government would have included large universities at least. Jisc helped DCMS to develop revised thresholds that more accurately reflect the Government’s desired coverage. It seems highly unlikely that any university is authoritative for more than a quarter of a million subdomains or provides resolution for more than two million client IP addresses.
The Regulations permit DCMS to bring individual organisations into scope, even though their services fall below the numeric thresholds. It is possible that they may wish to do this for Jisc’s operation of the .gov.uk domain. If so we are confident that measures already taken to bring that activity within the scope of our ISO27001 certification will satisfy the law’s requirements.
Thanks to the Jisc DNS team and the universities that provided us with statistics to inform the discussions with DCMS.
Originally posted: 26 April 2018 in category
Articles
Like the current
Data Protection Act 1998
, the
General Data Protection Regulation (GDPR)
will apply to any research involving data about identifiable living individuals. Also like the Act, the Regulation provides for adaptation in a couple of areas where this is needed to make such research possible.
All processing of personal data needs a legal basis. Six are listed in the GDPR Article 6: three seem most likely to be suitable for research:
Under the GDPR
consent
needs to be freely-given, informed, opt-in and capable of being withdrawn at any time. For research the requirement to inform is relaxed so the researcher only needs to describe the “areas of research” (Recital 33), rather than giving specific detail. But consent must still be free, withdrawable and indicated by a specific positive action by the data subject;
For research where GDPR-compliant consent is not feasible, either
legitimate interests
or
public interest
may be a better fit. The boundary between the two is still unclear – the Information Commissioner has recently confirmed that
public interest is unlikely to apply to all of a university’s activities
– but both require the benefits of research to be balanced against the risks caused to individuals. This needs to be done by the researcher for legitimate interest or the legislator for public interest. It may be safer for researchers to incorporate the balancing test in any case, as if it is later ruled that public interest does not apply then the research may become unlawful if this has not been done. With both bases, individuals have the right to object to processing;
GDPR Article 9(2)(i) requires research using special category data (health, race, religion, etc.) to be authorised by EU or national laws that set appropriate conditions and safeguards. For the UK, this will be done by the
Data Protection Bill
currently being debated in Parliament (see Schedule 1).
It’s worth noting that whereas the law does not normally allow a
change of basis for ongoing processing
, the Information Commissioner has recognised that the introduction of the GDPR is an occasion when such a change may be permitted. That offer is likely to be open for only a limited period of time, so it is worth double-checking that your current legal basis will still be the appropriate one under the GDPR’s new conditions or if a different one would be preferable.
Whereas the research adaptation for legal basis is set across Europe by the GDPR itself, the adaptations in the area of data subject rights are left (by Article 89) for individual member states to decide. The Regulation permits research activities to be exempted from some rights, but only if those rights would “render impossible or seriously impair” the research process. Member states must specify which rights (at most Subject Access, Rectification, Objection and Restriction, i.e. suspending processing while performing a rectification or objection) may be refused, as well as specifying safeguards that must be applied to research before it can qualify for any exemption. Under
section 33 of the 1998 Data Protection Act
, those safeguards include that the processing of data must not lead to decisions or measures with respect to individuals and there must be no substantial risk of damage or distress arising out of the research. The Data Protection Bill, currently being debated in Parliament, has similar requirements in Schedule 2, but also includes a proposal to allow results of approved medical research to be used to treat the individual research subjects.
Finally, GDPR Article 85 for the first time gives research publications a similar status to journalism so, while it should still be unusual to identify individuals in a publication, it may be possible to claim that the public interest justifies doing this in some cases. Further legal guidance will be needed on this permission – newspapers frequently have to defend their publication choices in court – but it may, for example, help those studying the history of recent events where it is impossible to avoid identifying the (still-living) individuals involved.
Originally posted: 24 April 2018 in category
Articles
As the GDPR approaches, several customer organisations have asked us if the Janet network will be offering a data processor contract. Presumably the idea is that the organisation that creates an IP packet is the data controller for the source IP address and that all the other networks that handle the packet on its journey are (sub-)processors.
The law isn’t clear on whether networks process personal data when they forward packets. But if you assume it does and that the relationship between originator and networks is a data controller-data processor one, then the law would also require the existence of a chain of sub-processor contracts, first with every network to whom we pass your packets on, then on all the way to the destination organisation. Similarly, we’d need a data sub-sub-(…)-processor contract with every customer organisation that receives packets from us, to make sure that the responding organisation also satisifed its data controller obligations. I hope it’s obvious why – at least unless and until there’s a clear statemement from data protection authorities – we favour interpretations that don’t require that immense mesh of contracts to be in place before we can send and receive packets for you!
When processing packets for security – to protect our networks and those of connected customers – we are clearly data controllers, because we decide the purpose and means of that processing. As Recital 49 of the Regulation requires, we do that in ways that minimise the risk to users of the network and ensure that those risks are far outweighed by network and information security benefits that we all rely on.
Originally posted: 4 April 2018 in category
Articles
It’s well-known that the General Data Protection Regulation says that IP addresses should be treated as personal data because they can be used to single out individuals for different treatment, even if not to actually identify them. In fact – as most organisations and network providers implement proxies, Network Address Translation (NAT) and other technologies to squeeze more networked devices into the finite and largely exhausted pool of IPv4 addresses – education institutions that benefitted from the generous address space allocations in the 1980s and 1990s may be one of the few places where that’s still true. Certainly, advertisers long ago stopped believing that a single IP address was associated with a single individual. For their targeting, they use cookies, browser fingerprinting and other much more effective techniques to track unique individuals.
Fortunately, having declared IP addresses to be personal data, the European ePrivacy Directive and draft ePrivacy Regulation both state that processing these addresses is an acceptable activity for those operating networks. Without this, the mere act of transmitting an IP packet containing source and destination addresses would be legally problematic! And those identifiers are very unlikely to be the biggest privacy risk that Internet users face. However it’s still worth considering whether there are services we can offer our users, or ways we can design our networks, that can provide improved privacy safeguards for those who want them.
For example reducing the period for which a workstation keeps the same IP address may reduce the possibilities for long-term tracking (non-sticky DHCP and IPv6 privacy extensions may be things to consider here; RFCs
4864
,
7721
and
8065
have a more detailed discussion for IPv6). Routing traffic through a proxy or NAT device will mean that different users’ activities can no longer be singled out by source IP address alone. Tracking using application-layer techniques such as cookies will be unaffected by such measures, though, so privacy-sensitive users or activities need to be helped at those levels as well as, and probably before, relying on network configurations.
All of these options are likely to involve trade-offs. Changing IP address may break some old-fashioned authentication systems; middleboxes such as proxies and NATs break the end-to-end principle and thereby put some limits on your ability to send any packet to any destination. Vendors do a pretty good job of keeping up with complex innovative protocols (see VoIP, gaming, etc.) but these options may not be enabled automatically.
And few of them can eliminate the possibility of tracking: most just move that capability around. As I discovered 20 years ago when introducing the first web cache in Wales (anyone who can beat 1996 is welcome to get in touch), routing your traffic through any kind of proxy, NAT or VPN may make it a little harder for websites to track your activities but it makes it much easier for the proxy operator to do so. Ultimately, if you want to receive responses to the communications you send to the Internet, then there has to be someone out there who knows where to find you. The best you can do is make sure that is someone you trust.
#360 - Federated Authentication and the GDPR Principles
Originally posted: 23 March 2018 in category
Articles
The General Data Protection Regulation’s Article 4(1) establishes six principles for any processing of personal data. It’s interesting to compare how
federated authentication
– where a student authenticates to their university/college, which then provides relevant assurances to the website they want to access – performs against those principles when compared with traditional direct logins to websites.
Lawfulness, fairness and transparency
(processed lawfully, fairly and in a transparent manner)
Personal data required to maintain an account on a website will normally be processed on the grounds that it is necessary for a contract between the site and the user. For federated authentication, where there is rarely a direct contract between the site and the user, it is generally considered that a more appropriate legal basis is the
legitimate interests of home organisation and service provider in providing the service requested
. Both situations therefore permit only “necessary” data to be exchanged, but federated authentication additionally requires both home organisation and service provider to consider the fundamental rights and freedoms of the individual.
Purpose limitation
(collected for specific, explicit and legitimate purposes and not processed incompatibly)
With direct login, the purpose(s) of processing are set in the contract the website offers to the user. Federated authentication agreements between home organisations and service providers typically require that the information provided may only be used for access and service personalisation decisions. Federated authentication technology also provides a practical limit on incompatible processing, since the pseudonymised information provided will often be of little use for other purposes in any case. For example federated authentication requires much less information for the website to protect itself against misuse, since federation agreements normally require the home organisation to enforce any breaches of policy by its users.
Data minimisation
(adequate, relevant and limited)
Where a user registers themselves for access to a website, that website is likely to obtain significant amounts of (self-declared) information about who the user is. For websites attempting to implement particular authorisation policies (for example, that the user is a member of an organisation holding a licence) this may well be both excessive and inadequate. By contrast, federated authentication can provide exactly the membership information the website needs, without any unnecessary personal information. Federated thus achieves better adequacy, relevance and limitation.
Accuracy
(accurate and kept up to date)
As noted under minimisation, traditional login relies on information provided by the individual user. The website has no way to determine whether it is accurate, either at the time it is provided, or later. Each time a user logs in using federated authentication, the site is provided with current information from the home organisation’s own records.
Storage limitation
(kept in a form that permits identification no longer than necessary)
Direct login requires the website to maintain all its account details, essentially indefinitely, since it has no way to determine when the user is no longer interested in the service. Federated authentication can be done without the website retaining any personal data, since the necessary assurances are provided by the home organisation each time the user accesses the site. Where a site wishes to let users retain information between sessions (saved searches, progress, etc.) this can be done using a pseudonymous identifier, unique to that site, provided by the home organisation. Again, there is no need for the website to retain any other information about the user.
Integrity and confidentiality
(appropriate security, using technical or organisational measures)
With direct login, integrity and confidentiality are a matter for the service provider. With federated authentication, personal data are held by the home organisation, which has a strong incentive to keep it secure to protect its own systems and the individuals (students and staff) with whom it needs a strong, long-term trust relationship. Furthermore the authentication process only reveals to the home organisation which websites the individual has authenticated to, not which content on those sites they accessed.
Federated login therefore appears clearly better for five of the six GDPR principles, and at least equal to direct login on the other.
#359 - Why should non-EU organisations care about GDPR?
Originally posted: 22 March 2018 in category
Publications
I was recently invited by EDUCAUSE to present a webinar on GDPR to their community of mostly North American universities and colleges. The number of participants indicates that European data protection law is a topic of interest. But the most common question was why, as non-EU organisations, they should care about GDPR. So I wrote a
blog post, which EDUCAUSE has now published
…
Originally posted: 2 March 2018 in category
Articles
I’ve had a number of questions recently about how long help desks should keep personal data about the queries they receive. The correct answer is “as long as you need, and no longer”. But I hope the following examples of why you might need to keep helpdesk tickets are more helpful than that bare statement:
To resolve the question
. Obviously, until both the requester and the helpdesk are satisfied that the question has been satisfactorily resolved, the helpdesk needs to keep personal data such as email address and phone number that’s needed to contact them. Once the problem has been resolved, this purpose doesn’t require you to keep information. So we should be looking at days or weeks before personal data is deleted or anonymised.
To identify users with persistent problems
. Some helpdesks look for patterns of requests that might indicate a user with long-term problems. This might be resolved by training, new equipment/software, etc. This requires that requesters remain identifiable for longer, but we should still be aiming to resolve the problem as soon as possible. So perhaps a few months’ retention. The same approach, though with an even more urgent need to address problems, applies to monitoring of helpdesk staff.
Statistical reporting
. This is normally done by department, type of software, or some other categorisation. There’s no need to keep personal data about which individual reported the problem for this purpose, just the categories into which the report fell.
To collate frequently-asked questions and answers
. Again, there’s no need for personal data: just a description of the problem and a model answer.
To monitor system performance over the long-term
. A history of reports about a particular piece of equipment may provide an early indication of a fault or imminent failure. For this purpose reports should be grouped by piece of equipment, not by the person reporting the problem. If remedial action is needed, the current responsible person can be identified from an asset register or similar – there’s no need to contact everyone who has reported the problem in the past.
These and other reasons for keeping information only apply if you actually have those processes, of course. But I hope they give examples of how to think about the “how long should we keep…?” questions.
In any database, it should be possible to delete/anonymise a single field if the rest of the data are still required for another purpose. For example – a common combination of the bullets above – if you are resolving questions but also want to keep a resource to identify frequently asked questions, it should be possible to remove the requester’s details from the database once their query has been resolved but keep the question and answers for later use in a FAQ.
Originally posted: 2 March 2018 in category
Articles
Collections of free text – whether in database fields, documents or email archives – present a challenge both for operations and under data protection law. They may contain personal data but it’s hard to find: whether you’re trying to use it, to ensure compliance with the data protection principles, or to allow data subjects to exercise their legal rights. Some level of risk is unavoidable in these collections, but there are ways to reduce it.
Provide structured fields wherever possible. If you know that a helpdesk ticket will contain the requester’s name and e-mail address, ensure those fields exist in the database. This makes the information much easier to find for operational purposes, as well as to apply appropriate deletion/anonymisation policies.
Set policies for using those structured fields, for when and how personal data may be entered into unstructured fields, and which personal data (e.g. sensitive) should never be entered there. Some of the data may be entered by people not under your control (e.g. if someone describes their health problems in a website comment field), but at least those who are under your control should know how to do the right thing. Knowing the source of unstructured data and the ways in which it is collected should also help in the subsequent assessment of how great a risk it represents.
Set appropriate retention periods for both structured and unstructured fields. With structured fields it should be relatively easy to define when personal data are no longer needed for the purpose and the content of a single field can be deleted or over-written. For unstructured fields this is harder, since both the utility and risk of long retention are unknown. Deciding on an appropriate period to retain unstructured information is likely to involve balancing the benefit and the risk, taking account of the uncertainty of both.
For high-risk situations or activities, it may be worth considering using either humans or computers to scan unstructured data for personal content. The choice involves a trade-off: humans are likely to be more accurate but also more expensive. Conversely a computer may spot a name and redact it without realising that it was critical to the meaning and purpose of the record (though in that case it should, perhaps, have been in a structured field anyway).
Databases and other collections should also be secured using technical means, of course. Where appropriate to the purpose, access controls can ensure that only authorised users can see the content, encrypting that content when it is at rest and in transmission can protect against those with physical access.
Finally, the organisation should assess the remaining risk – it is very unlikely to be possible to eliminate it – and ensure that this is justified by the benefits of storing and processing the data. The General Data Protection Regulation’s requirement to demonstrate accountability for processing of personal data probably means this assessment (and particularly the reasons why possible risk-reduction options were
not
taken) should be documented, at least for large collections of information.
Originally posted: 28 February 2018 in category
Articles
Although the Article 29 Working Party seem to have had applications such as
incident response
in mind when drafting their
guidance on exports
, that guidance could also be helpful in the field of federated authentication. This technology allows an “identity provider” such as a university or college to assure a “service provider” such as a research discussion group, online journal or wireless network:
That an individual requesting access to the service is one of its students or staff, and
That the identity provider organisation will deal with any reports of misuse by that individual.
This can be achieved with far less release of personal data than if the service provider tried to obtain those assurances itself. Often no more than “yes, it’s one of my students” needs to be released. Under the current Data Protection Directive, the most appropriate legal justification for the processing – and the one that best protects the individual’s interest – is considered to be the legitimate interests of both identity provider and service provider in providing the service the individual has requested. If the service provider was outside the EEA then the minimal amount of personal data involved has suggested that exporting it may represent an acceptable risk, especially to
services of high value to research and education
.
Under the GDPR, however, the ability of a data controller to self-assess the risk of exporting has been removed: instead, legitimate interest has been added as a reason that may permit exports. Testing common federated access management against the Working Party’s analysis of this provision:
Exports are “occasional” or “not repetitive” (p4)
: i.e. “such transfers may happen more than once, but not regularly, and would occur outside the regular course of actions, for example, under random, unknown circumstances and within arbitrary time intervals”. Although some instances of federated authentication may take place within long-term relationships – for example where a university has a subscription to an academic publisher (here the subscription contract can contain provisions to protect the exported data) – many authentication requests will be ad hoc, to services chosen by the individual user, with which the identity provider has no existing relationship.
All other legal grounds must be inapplicable (p15)
: where an individual needs to access a service for their research or education, it is unlikely that they will be able to give free consent. As above, for some cases a long-term contract between identity provider and service provider will be appropriate, but for many others this would involve far more complexity than the nature of the request justifies.
Export must involve only a limited number of data subjects (p16)
: each export will involve only the minimised personal data of the individual requesting access to the service.
Export must be subject to safeguards (p17)
: the information released will be minimised, in many cases only a pseudonymous identifier, unique to that service provider, will be needed. Federated authentication is conducted within national and international agreements that ensure information can only be used for the purpose of supplying the service to the individual user.
Export must balance the interests, rights and freedoms of the individual (p16)
: Export will only take place at the request of the individual, and involves significantly less personal data, and less risk, than any other way they could obtain access to the service.
Individual must be informed of the export (p17)
: individuals should be informed by services when an access request will be handled outside the European Economic Area.
The final requirement is that the export must serve a “compelling” legitimate interest of the data exporter (the identity provider in this case). Since the alternative will generally be that the user has to create an account directly with an overseas service provider, with no data minimisation or contractual restrictions, regulators should recognise the provision of privacy-protecting authentication services as a compelling interest of organisations that can offer them.
As with incident response, requiring individual notification of individual exports would be highly burdensome; in the federated authentication context it is likely to represent an increased privacy risk, since such a notification may well need to contain more personal data than the authentication transaction itself!
Originally posted: 23 February 2018 in category
Articles
When incident response teams (CSIRTs) detect an attack on their systems, they normally report details back to the network or organisation from which the attack comes. This can have two benefits for the reporter: in the short term, making the attack stop; in the longer term helping that organisation to improve the security of its systems so they are less likely to be used in future attacks. The vast majority of attacks will not, in fact, be initiated by individuals within those organisations, but by third parties who have managed to compromise accounts or systems belonging to the organisation.
To be useful to the recipient (and therefore effective to the sender), such reports need to include details of the source, time and nature of the attack. e.g. “between 1400-1500 UTC on Friday 23rd Feb, your IP address 192.168.10.10 participated in an NTP DDoS attack against me”. It’s not usually necessary to give specific details of the systems or accounts attacked. However such a report is likely to constitute personal data, since it mentions a specific IP address, so be subject to data protection law. In some cases the addresses in the report will not in fact be connected to an individual, but the reporting organisation cannot be sure of that. Within Europe such reporting has been justified for some time as a legitimate interest of the reporting organisation (
paper from 2011
); however it has been less clear which legal provision applied when sending reports outside the EEA, thereby exporting personal data. The UK Information Commissioner has helpfully noted that
when sending personal data back to where it came from
the privacy expectations of that country, rather than of Europe, are relevant.
The Article 29 Working Party’s new
draft guidance on exporting personal data
is clearly aware of this issue, though perhaps not of how often it arises. The General Data Protection Regulation, for the first time, adds legitimate interests as a justification for exporting personal data. According to the guidance this can only be done where:
Exports are “occasional” or “not repetitive” (p4)
: i.e. “such transfers may happen more than once, but not regularly, and would occur outside the regular course of actions, for example, under random, unknown circumstances and within arbitrary time intervals”. Since reports are only sent when an attack occurs, and the aim is to prevent future attacks, CSIRTs definitely do not intend them to occur “regularly within a stable relationship between the data exporter and a certain data importer”. Ideally, we’d like each reporting relationship to be used only once!
Export is necessary for a compelling legitimate interest (p15):
protecting network and information security is recognised as a legitimate interest by Recital 49 of the GDPR. Indeed the Working Party’s guidance gives as an example “to protect its organisation or systems from serious immediate harm” – a description that clearly fits a hacking or denial of service attack.
All other legal grounds must be inapplicable (p15)
: it is highly unlikely that an attacker would consent to his attack being reported and investigated or that there will be time to establish a model clauses contract between the CSIRT and the organisation to which it needs to report the attack.
Export must involve only a limited number of data subjects (p16)
: most reports will only involve one, or a small number of, IP or email addresses used in the attack.
Export must be subject to safeguards (p17)
: the information in reports will almost always be pseudonyms, since the reporting CSIRT will have no way to link IP or e-mail addresses to individual users in the organisation to which it reports. Where possible the report will be sent to either a known CSIRT or the advertised security contact for the organisation: both can be expected to only use the information for the purpose of stopping the attack and fixing the security problem that permitted it.
Export must balance the interests, rights and freedoms of the individual (p16)
: as noted above, in most cases any individual whose IP or e-mail address is contained in a report will also be a victim whose system has been compromised. Reporting should therefore result in that individual’s rights being enhanced (because the attacker’s access to their account, systems and data will be removed), rather than damaged. The safeguards listed above should further protect their rights.
Individual must be informed of the export (p17)
: the effect of the report should be precisely to inform any affected individuals both that their data have been (re-)exported from the EEA and, more importantly, that they have a security problem that they need to address.
It therefore appears that European CSIRTs now have an explicitly recognised legal basis for sending incident reports overseas. Furthermore this is the same legal basis as used within Europe, so they can apply the same processes and policies to both groups of destinations.
The one requirement that may cause problems, though mostly for national regulators rather than CSIRTs, is that “[t]he controller shall inform the supervisory authority of the transfer” (Article 49). Neither the GDPR nor the new guidance indicate whether this should be done every time an overseas incident report is made, or whether a single general notification of the practice will be sufficient. Since a busy team may send tens or hundreds of incident reports per day, the latter would be better to protect regulators’ inboxes.
Originally posted: 20 February 2018 in category
Articles
The
Article 29 Working Party’s guidance on Breach Notification
suggests some things we should do before a security breach occurs. The GDPR expects data controllers, within 72 hours of becoming aware of any security breach, to determine whether there is a risk to individuals and, if so, to report to the national Data Protection Authority. It seems unlikely that an organisation that hasn’t prepared is going to be able to manage that.
Although the guidance states, correctly, that the impact of a particular breach can only be assessed after it has happened, it should be possible to identify at least the range of possible impacts beforehand. Indeed some of the Working Party’s suggested factors seem very unlikely to be spotted in the busy time immediately following an incident: if you hadn’t thought about it previously, would you notice that a list of addresses for which deliveries are temporarily suspended (indicating occupants away on holiday) could have a much higher impact (value to burglars) than the list of addresses to which regular deliveries are made?
Page 24 of the guidance suggests several things we could think about in advance, perhaps during the
assessment of information lifecycles
. For each collection of personal data it should be possible to identify:
What types of breach (confidentiality, integrity or availability) could have significant impact on individuals’ rights and freedoms?
What is the nature and sensitivity of personal data?
How easily can individuals be identified (perhaps in combination with other information)?
What kinds of consequence might result from a breach?
Are there individuals who might be particularly vulnerable (e.g. children) or a context that increases the sensitivity of otherwise low-risk data (e.g. names held by a medical clinic)?
How many individuals would be affected by a breach?
Knowing this information should allow the data controller to assess, for each collection, whether a future breach is likely to involve a risk to individuals (so be reportable to the DPA), a high risk (so reportable to data subjects) or only risks that are mitigated (so recordable, but not reportable). When a breach occurs, the controller just needs to consider whether there were mitigating or aggregating factors to change that assessment. The Working Party give the example that if a spreadsheet of personal data is accidentally emailed to a partner who can be trusted to delete it, this will reduce the initial assessment of the severity of that kind of breach.
The answers to the questions will also provide most of the information needed for the initial report.
One point that isn’t specifically highlighted in the guidance is that this kind of preparation is particularly important when processing is conducted by a data processor. Whereas for in-house processing the data controller may be permitted a short period of investigation between the discovery of a breach and the “awareness” that it has affected personal data, for outsourced processing awareness begins as soon as the controller is notified of the breach. That means even more needs to be fitted in to the 72 hours, so it’s even more important to be prepared.
#353 - Automated Processing for Network and Information Security
Originally posted: 16 February 2018 in category
Articles
Article 22 of the GDPR contains a new, and oddly-worded, “right not to be subject to a decision based solely on automated processing”. This only applies to decisions that “produce[] legal effects … or similarly significantly affect[]” the individual. Last year, the Article 29 Working Party’s draft guidance on interpreting this Article noted that an automated refusal to hire a bicycle – because of insufficient credit – might reach this threshold.
This raised the concern, discussed in
our consultation response
, that automated processes that the Working Party has previously approved of – such as automatically filtering e-mails for viruses and spam – might now require human intervention. They do, after all, aim to cause disadvantage to the person who hopes to hold your files to ransom.
Fortunately the
Working Party’s final guidance
, published this week, clarifies that the threshold is, in fact, much higher than this. Their examples of “serious impactful” effects are now at the level of automated refusal of citizenship, social benefits or job opportunities. So automation to defend our systems, networks and data against attack should be well within the boundaries where normal data protection law, not Article 22’s special provisions, apply.
Interestingly there’s also a suggestion that some flexibility may be allowed where the volume of data makes human inspection impractical. Although GDPR Recital 71 mentions ‘e-recruiting practices without any human intervention’, the example on page 23 of the guidance approves of automated short-listing where the volume of job applications makes it “not practically possible to identify fitting candidates without first using fully automated means to sift out irrelevant applications”.
#352 - Sensitive/Special Category Data and Learning Analytics
Originally posted: 2 February 2018 in category
Articles
In thinking about the legal arrangements for Jisc’s learning analytics services we consciously postponed incorporating medical and other information that Article 9(1) of the General Data Protection Regulation (GDPR) classifies as Special Category Data (SCD): “personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation” (most of this is Sensitive Personal Data under current law). However there is now interest in including such data so we’re looking at how this might be done: in particular because
the legitimate interests legal basis we recommend for other learning analytics data
isn’t sufficient for SCD.
GDPR Article 6(1) sets out the familiar six legal bases for processing personal data: contract, legal duty, vital interests, legitimate interests, public interest and consent. However processing SCD is prohibited unless the data controller can also meet one of the narrower conditions in Article 9(2): for example consent must be “explicit”, public interest must be substantial, and vital interests can only be used when the data subject is incapable of giving consent. These Article 9(2) conditions will apply in two circumstances: if SCD is used as an
input
to a learning analytics process (for example because it has been found to have predictive value or to detect when algorithms are generating discriminatory patterns); and if learning analytics techniques are applied to try to derive SCD (for example health) as an
output
from other types of data.
SCD as a learning analytics input
It has been noted that SCD might be a useful factor to take into account for some learning analytics purposes: for example knowing that I am red-green colourblind might let a personalised learning system realise I need more time for exercises involving chemical indicators or geological maps. An
Open University paper identifies similar opportunities
.
For most learning analytics processing of SCD, it appears the only available Article 9(2) condition will be the explicit consent of the individual. However this legal requirement may, in any case, be a practical necessity since the usual source of such information is the individual voluntarily disclosing it. This information gathering is dependent on the individual telling the truth (one of my colleagues ticks a minority religion just to ensure he gets his in-flight meal first!), so it needs to be done in a way that reassures them that truth-telling is both safe and advantageous. This is likely to involve something that looks very like an explicit consent process: providing full information about both positive and negative consequences, avoiding any pressure to grant or refuse consent, and getting active agreement to the proposed processing. If information may be used for more than one purpose, individuals should be allowed to consent to each of these separately.
Valid consent can only be obtained if the consequences of granting or refusing consent are made clear to the individual in advance. This means that algorithms including SCD can only be used for decisions or interventions that were foreseen and explained at the time the data were obtained. Unlike legitimate interests, the data controller can’t specify a broader purpose and then seek later consent for a specific intervention. However current proposals for using SCD do seek to answer specific questions, known in advance, so this is unlikely to be a significant restriction in practice. Indeed, if computer algorithms are being used to replace human inspection, individuals may well see this as a privacy-enhancing step and be more willing to provide their data.
The consent process provides a useful additional check of data subject sentiment: if individuals are comfortable with the proposed uses of information and safeguards to protect it, then we should see at least a constant rate of consent being given and ideally an increasing one. Certainly if the rate of consents drops, or is lower than the current rate of return when the same information is collected for HESA statistics, we should immediately check why our activities are being perceived as “creepy”.
Under
the standard Jisc model
, organisations are recommended to seek consent to the interventions that result from learning analytics processing. Typically a student should be offered a choice between generic and personalised treatments or have a free choice whether or not to take up a proposed intervention. Even though consent to gather and process SCD will have been obtained at data collection stage, it still seems advisable to offer a second consent option when a specific intervention is suggested, both because more detail can be provided at this stage and because individual students are likely to want to choose which interventions they accept.
SCD as a learning analytics output
It has been suggested that learning analytics-type approaches might be used to derive early warnings of health problems from other types of data. Using explicit consent for this is likely to be tricky, as much of the (non-SCD) input data will be observed, rather than collected directly from the individual. With research at an early stage, it is also likely to be hard to inform the individual in advance of the specific consequences of granting or refusing consent. A more appropriate option is likely to be “the purposes of preventive or occupational medicine” (Art 9(2)(h)). This requires that “data be processed by or under the responsibility of a professional subject to the obligation of professional secrecy” (Art 9(3)), so medical professionals would need to be involved in any such activity.
Processing designed to generate SCD as an output seems certain to meet the Article 29 Working Party’s threshold for requiring a Data Protection Impact Assessment (DPIA), since it involves at least “evaluation or scoring”, “sensitive data” and “innovative use” (see pp 9-11 of the
Working Party’s guidance
). Where the purpose of processing is to discover previously unknown SCD – perhaps not even known to the individual – this may well constitute a “high residual risk”, requiring the prior approval of the national Data Protection Authority (for the UK, the Information Commissioner).
Originally posted: 23 January 2018 in category
Articles
Reflecting on the scope chosen by Blackboard for our working group – “
Ethical use of AI in Education
” – it’s worth considering what, if anything, makes education different as a venue for artificial intelligence. Education is, I think, different from commercial businesses because our measure of success should be what pupils/students achieve. Educational institutions should have the same goal as those they teach, unlike commercial settings where success is often a zero-sum game. We should be using AI to achieve value for those who use our services, not from them. Similarly, we should be looking to AI as a way to help tutors do their jobs to the best of their ability. AI is good at large-scale and repetitive tasks – it doesn’t get tired, bored, or grumpy. Well-used AI should help both learners and teachers to concentrate on the things that humans do best.
Clearly there are also risks in using AI in education – there would be little for an ethics working group to discuss if there weren’t! The technology could be deployed for inappropriate purposes or in ways that are unfair to students, tutors, or both. The current stress on using AI only to “prevent failure” feels a bit close to these lines: if we can use AI to help all students and tutors improve then they won’t presume that any notification from the system is bad news. Getting this right is mostly about
purposes and processes
. However there’s also a risk of AI too closely mimicking human behaviour: poorly-chosen training sets can result in algorithms that reproduce existing human and systemic pre-conceptions; too great a reliance on student feedback could result in algorithms delivering what gives students an easy life, rather than what will help them achieve their potential. An AI that never produces unexpected results is probably worth close examination to see if it has fallen into these traps.
Computers work best when presented with clear binary rules: this course of action is acceptable, that one isn’t. However the rules provided by the legal system rarely provide that. Laws are often vague about where lines are drawn, with legislators happy to leave to courts the question of how to apply them to particular situations. As Kroll et al point out,
when laws are implemented in AI systems, those decisions on interpretation will instead be made by programmers
– something that we should probably be less comfortable about (p61). Conversely, laws may demand rules that are incomprehensible to an AI system: for example European discrimination law prohibits an AI from
setting different insurance premiums for men and women
even if those are what the input data demand. Finally, and particularly in education, we may well be asking AI systems to make decisions where society has not yet decided what actions are acceptable: how should we handle data from a student that tells us about their tutor or parent? when is it OK to for charities to
target donors based on their likely size of donations
? when should a college to recommend an easier course to a borderline student?
Originally posted: 17 January 2018 in category
Articles
Last week I was invited to a fascinating discussion on
ethical use of artificial intelligence in higher education
, hosted by Blackboard. Obviously that’s a huge topic, so I’ve been trying to come up with a way to divide it into smaller ones without too many overlaps. So far, it seems a division into three may be possible:
Ethical purposes. Here there seems the best chance of saying that some purposes are ethical and some are not. The much cited example of a
college using data to discourage students
who were likely to reduce its position in ranking tables would seem unethical no matter how the decisions were reached. But there are also some purposes where we seem to accept humans doing them but be uneasy about them being conducted solely by algorithms, for example when
drones are used for targeted killing
, or algorithms used to
recommend whether not to send a criminal to jail
. So “Why are we doing this?” may divide into three categories: OK, not OK, and decision-by-human.
Ethical implementations. It’s straightforward to think of ways of using the results of AI in unethical ways: an automated email saying “YOU’RE GOING TO FAIL!!!” is not going to pass many ethics assessments. However in this case there are situations where a pure-technology solution might actually tick more ethical boxes than a human-mediated one: a student group in the Netherlands concluded that they would prefer gentle reminders – “do a bit more work” – to come solely from a computer and not, provided they took notice, to come to the attention of their tutors at all. We seem to have varying instincts about computers processing our data: in some instances it’s less privacy-invasive than a human doing the same, but where computerisation allows processing that would have been impossible for humans there is a risk that that will be perceived as increasing privacy invasion. “How are we doing this?” is definitely worth reviewing from an ethical perspective.
Ethical use of data. Ethical questions arise both out of which data we use to reach decisions, and the characteristics of the algorithms used to make them. However both questions depend a lot on the purpose and the situation. Using location data to help a student find the right lecture theatre or library shelf seems to raise few ethical questions: using the same data to judge whether they are in an appropriate place for Friday-evening study would be much more troubling. The way the data were obtained also need to be considered: a student volunteering the information that they are in the library may be ethically different to the same information being extracted from CCTV or wifi logs.
I’ll cover algorithms in the next post
, but the situation will also affect the desired characteristics of the algorithm: do we expect to know how it works in advance, or be able to explain it retrospectively, or not care so long as it gives the right result? So “What are we using for this?” seems to raise its own group of ethical issues.
Reviewing those three categories, it strikes me that they are somewhat similar to European law’s requirements that processing of personal data be “legitimate”, “fair” and “necessary”. That may be a good thing or, given the difficulty that legislators and regulators have in keeping those separate, maybe not!
Originally posted: 17 January 2018 in category
Articles
One of the concerns commonly raised for Artificial Intelligence is that it may not be clear how a system reached its conclusion from the input data. The same could well be said of human decision makers: AI at least lets us choose an approach based on the kind of explainability we want. Discussions at last week’s Ethical AI in HE meeting revealed several different options:
When we are making decisions such as awarding bursaries to students, regulators may well want to know in advance that those decisions will always be made fairly, based on the data available to them. This kind of
ex ante
explainability seems likely to be the most demanding, probably restricting the choice of algorithm to those using known (and meaningful to humans) parameters to convert inputs to outputs;
Conversely for decisions such as which course to recommend to a student, the focus is likely to be explaining to the individual affected which characteristics led to that decision being reached. Here it may be possible to use more complex models, so long as it’s possible to perform some sort of retrospective sensitivity analysis (for example using the
LIME approach
) to discover which characteristics of the particular individual had most weight in the recommendation that was provided for them;
A variant of the previous type occurs where a student’s future performance has been predicted and they, and their teachers, want to know how to improve it. This is likely to require a combination of information from the algorithm with human knowledge about the individual and their progress;
Finally there are algorithms – for example deciding which applicants are shown social medial adverts – where the only test of the algorithm is whether it delivers the planned results and we don’t care how it achieved that.
Explainability won’t be the only factor in our choice of algorithms: speed and accuracy are obvious other factors. But it may well carry some weight in deciding the most appropriate techniques to use in particular applications.
Finally it’s interesting to compare these requirements of the educational context with the “right to explanation” contained in the General Data Protection Regulation and discussed on page 14 of in the
Article 29 Working Party’s draft Guidance
. It seems that the education’s requirements for explainability may be significantly wider and more complex.
One of my guidelines for when consent may be an appropriate basis for processing personal data is whether the individual is able to lie or walk away. If they can, then that practical possibility may indicate a legal possibility too.
When we’re using learning analytics, as a production service, to identify when students could benefit from some sort of personalisation of their learning experience, that’s not what we want. Those opportunities should be offered to all students who might benefit from them, with the option to refuse when they know exactly what alteration or intervention is being proposed. Hence
Jisc’s recommended model
uses consent only at the point of intervention (and, by the same “can lie” test, if we are inviting students to provide self-declared input data into our models).
Legally, and morally too, if we are imposing processing on individuals then we need to ensure that it doesn’t create unjustified risks for them. Doing that shouldn’t be a problem when we know what objective we are aiming at and what information is likely to be relevant to that objective. However this creates a chicken/egg problem: how do we find out what objectives are possible and what data might help with them?
For this sort of exploratory investigation, consent may be a more appropriate option. At this preliminary stage inclusiveness may be less important (though we need to beware of self-selecting inputs producing biased models) and we may indeed be able to offer the option to walk away at any time. Participants who do so must not suffer any detriment: one way to ensure this, and to satisfy the requirement that individuals must know the detailed consequences of participation, is to state that the outputs from pilot systems will not be used for any decisions, or to offer any interventions. So no consequences and no detriment. Learning which types of data can inform which types of outputs should be sufficient for the pilot stage: we can then use that knowledge to assess and implement our production algorithms and processes.
Originally posted: 18 December 2017 in category
Articles
The Article 29 Working Party has published its
draft guidelines on transparency
. For those of us who have already been working on GDPR privacy notices, there don’t seem to be any surprises: this is largely a compilation of the relevant sections of the Regulation and other guidance. In particular, it seems to have been strongly influenced by the
UK Information Commissioner’s guidance on Privacy Notices
.
Transparency is required in three areas: providing information to data subjects to ensure processing is fair; informing data subjects about their rights; and facilitating the exercise of those rights. Most of the guidelines deal with the first of these, commonly known as privacy notices or fair processing notices. Although the guidelines don’t explicitly admit the tension between the GDPR requirements to be “concise” and also “specific”, they do suggest how to prioritise information. Data subjects must always be informed of the processing that will have most impact on them, and especially any processing or consequences that may surprise them. This matches the Information Commissioner’s view that telling people the blindingly obvious is not a priority! However data controllers should avoid the temptation to rely on vague wording; a number of words and phrases are singled out as undesirable, including “to develop new services”, “for research purposes” and “for personalisation”. In the on-line context, layered notices are repeatedly mentioned as a possible solution, though with a possibly new twist that such notices should allow individuals not just to choose the level of detail, but also the specific areas they want information about.
Finally, there’s a reminder that existing notices should be reviewed before May 25th, and pages 31-35 have a table (less pretty, but containing more detail, than the Information Commissioner’s version) of the information required in different circumstances.
#346 - GDPR: Processing notification and protecting security
Originally posted: 18 December 2017 in category
Articles
Concern has sometimes been expressed whether the General Data Protection Regulation’s (GDPR) requirement to notify individuals of all processing of their personal data would cause difficulties for security and incident response teams. These activities involve a lot of processing of IP addresses, which the GDPR and case law seem to indicate will normally count as personal data. But a law that required us to tell attackers how much we knew about their activities would help them far more than us.
Fortunately the law, and now the Article 29 Working Party of European Data Protection Regulators, recognise this and similar problems. As the
Working Party’s draft transparency guidance
explains, the situation is covered by at least two exemptions:
Paragraph 58 discusses Article 14.5(b), which says that informing the individual is not a requirement if doing so “is likely to make impossible or seriously impair the purpose of the processing”. Analysing attackers’ techniques so we can defend against them (and tell others how to do so) is an important aspect of keeping computers and data secure. Telling attackers when they need to change their approach would obviously “seriously impair” this purpose;
Paragraph 57 also notes that informing individuals may, in any case, be impossible where the processing does not require them to be identified. Analysing network traffic is one of these situations since it is generally done “with pseudonymised data”. GDPR Article 11.1 states that such circumstances do not require the data controller to acquire additional personal data (for example an attacker’s contact details) solely to comply with GDPR requirements.
Security and incident response teams still have to ensure their processing is fair and has a legal basis. Recital 49 provides “legitimate interests” as the appropriate legal basis for securing networks, computers and data.
Fairness should be ensured
by the tests that processing is “necessary” for that purpose and is not overridden by the rights and freedoms of individuals. A public notice informing users of websites, networks and computers of an incident response team’s activities should meet the GDPR’s legal requirement as well as, perhaps, persuading at least some attackers to leave that organisation alone.
Originally posted: 15 December 2017 in category
Presentations
For those who couldn’t make it to the
Jisc GDPR conference
last week (and those who did, but want a refresher) the slides are now available.
Presenters were told to ensure they gave lots of practical advice, so whether you want ideas on GDPR in Further Education or Research; need to work on an asset register or supplier contracts; to learn why (and how) you need to talk to ICT, or how to simplify the myriad of processing activities your organisation conducts, scroll down the
conference webpage
. It was an excellent day 🙂
Originally posted: 15 December 2017 in category
Articles
The Article 29 Working Party of European Data Protection Supervisors has published
draft guidance on consent under the General Data Protection Regulation
. Since the Working Party has already published extensive guidance on the existing Data Protection Directive rules on consent, this new paper concentrates on what has changed under the GDPR.
The first message is that consent is only one of six legal bases for processing personal data: “consent can only be an appropriate lawful basis if a data subject is offered control and is offered a genuine choice with regard to accepting or declining the terms offered or declining them without detriment” (Page 4). Where any part of that requirement cannot be met, data controllers must look at
the other five possibilities
.
In particular, consent will rarely be appropriate where there is an imbalance of power between the data subject and the data controller. For example public authorities will often have difficulty satisfying the requirements for consent, as individuals have little choice whether or not to use their services. Employers, too, will generally have too much power for employees to give free consent. Neither case is an absolute ban, however: the guidance mentions examples of subscribing to e-mail updates about roadworks or having photographs included in a school magazine, where the organisation may be able to establish that refusal of consent does, indeed, involve no significant adverse consequences.
Commercial organisations also need to take care when using consent: “the two lawful bases for the lawful processing of personal data, i.e. consent and contract cannot be merged and blurred”. If the personal information is necessary to perform the contract then that, not consent, is the correct basis. Where organisations request additional data that are not directly linked to the contract then free consent is required: this may be demonstrated, for example, by providing two versions of the service, one with additional data and one without, provided these are “genuinely equivalent, including no further costs” (page 10).
The Working Party consider that the greatest changes, most likely to require a change in process, are the need for consent to be indicated by a positive action (no pre-ticked boxes or “consent by silence”) and the requirement for organisations to be able to demonstrate that this was done. The latter is likely to involve keeping records of what information was shown to the individual, and what workflow resulted in their consent being obtained. In terms of systems, the biggest change are the need to make withdrawing consent as easy as obtaining it (if you gave consent with a mouse click, you can’t be required to withdraw it by a phone call) and, where consented data are used for several different purposes, providing individual consent to each one.
As with the
Information Commissioner’s draft guidance
from last February there’s a strong hint here that data controllers should be moving from consent to other bases where these are more appropriate. The Working Party adds an interesting twist: that continuing processing while changing its legal basis may be lawful as part of the change from Directive to Regulation, but not thereafter.
#342 - Article 29 WP draft on Automated Processing
Originally posted: 8 December 2017 in category
Closed
The Article 29 Working Party have conducted a brief consultation on
draft guidance on Automated Processing
that, surprisingly, reverses all previous legal interpretations I’ve found. GDPR Article 22 is one of several that begin “The data subject shall have the right”, in this case:
The data subject shall have the right not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her.
This had been widely understood (including by the Working Party when they proposed this wording in 2014!) as meaning that individuals could request that any such decisions be reviewed by a human, in line with all the other Articles creating rights. The Information Commissioner says that “
You must ensure that individuals are able to obtain human intervention
“. However the Working Party is now stating, without explanation, that the Article actually bans such decisions being made in the first place.
Our response (PDF)
points out how this will make many decision-making processes – including in network security, personalisation and prioritisation – both slower and more privacy-invasive. We hope this persuades them to revert to their earlier interpretation.
Clause 6(1) of the Bill states that (subject to modification by the Secretary of State) organisations that are classed as public authorities under the Freedom of Information or Freedom of Information (Scotland) Acts will also be “public authorities” for the purposes of the GDPR;
Under Article 6(1) of the GDPR, those public authorities are not permitted to use the legitimate interests basis “in the performance of their tasks”;
Instead, by Recital 47, those tasks and their legal basis should be “provide[d] by law”;
And, by Clause 7(c) of the Bill, where a task is “conferred on a person by an enactment”, the legal basis is that it is necessary in the public interest.
Where an educational institution is performing a task that
is
specified by law, therefore, the correct legal basis is that it is “necessary in the public interest” (Article 6(1)(e)). Where it is performing a task that is
not
specified by law (for example protecting the security of networks and systems, as in GDPR Recital 49), then all the other legal bases, including “necessary in the legitimate interests [of the organisation]” are available, subject to their usual GDPR conditions.
The previous day, I did a more detailed presentation on one of those tools – information lifecycles – at Jisc’s own security event.
Slides
from that presentation are now available.
For more information about the tools discussed in both presentations, see my earlier posts on
Originally posted: 3 November 2017 in category
Articles
The Article 29 Working Party’s
draft guidance on Breach Notification
under the General Data Protection Regulation (GDPR) provides welcome recognition of the need to do incident response and mitigation in parallel with any breach notification rather than,
as I’ve been warning since 2012
, giving priority to notification. Now the Working Party is explicit that “immediately upon becoming aware of a breach, it is vitally important that the controller should not only seek to contain the incident but it should also assess the risk that could result from it”. And in reporting “the focus should be directed towards addressing the adverse effects of the breach rather than providing precise figures.”
The guidance confirms the GDPR’s wide definition of security breach: “this can include loss of control over [individuals’] personal data, limitation of their rights, discrimination, identity theft or fraud, financial loss, unauthorised reversal of pseudonymisation, damage to reputation, and loss of confidentiality of personal data protected by professional secrecy. It can also include any other significant economic or social disadvantage to those individuals”. It also clarifies that events affecting the availability of personal data – e.g. ransomware, loss of decryption key and denial of service attacks – qualify as breaches, and may need to be reported if they affect individuals’ rights, for example by causing the cancellation of a hospital operation.
The GDPR expects breaches that create a risk to individual rights to be reported to the relevant national data protection authority within 72 hours of the data controller becoming aware of the breach. According to the Working Party, that is “when that [data] controller has a reasonable degree of certainty that a security incident has occurred that has led to personal data being compromised”. If a breach is suspected, but the controller does not yet have clear evidence that personal data have been affected, the “controller may undertake a short period of investigation in order to establish whether or not a breach has in fact occurred”, but this must be done “as soon as possible”. Remedial action and reporting should be started as soon as there is “a reasonable degree of certainty”: controllers should not wait until complete details have been obtained.
The GDPR also requires that where a breach represents a high risk to individuals (for example “discrimination, identity theft or fraud, financial loss [or] damage to reputation”), they must be notified, either individually or through a public notice. The Working Party gives examples of the kinds of notification expected: “direct messaging (e.g. email, SMS, direct message), prominent website banners or notification, postal communications and prominent advertisements in print media. A notification solely confined within a press release or corporate blog would not be an effective means of communicating a breach to an individual”. The GDPR does not set specific time limits for notifying individuals, and the Working Party recognises that this will depend on the “nature of the breach and the severity of the risk”: “if there is an immediate threat of identity theft, or if special categories of personal data are disclosed online, the controller should act without undue delay to contain the breach and to communicate it to the individuals concerned … In exceptional circumstances, this might even take place before notifying the supervisory authority”. In less urgent cases data controllers can seek advice, as part of their notification to the data protection authority, on whether they need to notify individuals.
The Working Party is clear that this will require organisations to have and follow documented incident response plans: “Controllers and processors are therefore encouraged to plan in advance and put in place processes to be able to detect and promptly contain a breach, to assess the risk to individuals, and then to determine whether it is necessary to notify the competent supervisory authority, and to communicate the breach to the individuals concerned when necessary”.
Originally posted: 26 October 2017 in category
Publications
Education Technology have just published an article I wrote (though I didn’t choose the headline!) on
how security and incident response fit into the General Data Protection Regulation
. It aims to be an easy read: if you want something more challenging follow the “incident response protects privacy” link to get the full legal analysis.
Originally posted: 23 October 2017 in category
Articles
Although privacy notices are an important aspect of the General Data Protection Regulation, it seems unlikely that we will have final guidance from regulators for several months. Since we need to start rolling out GDPR-friendly privacy notices for Jisc services sooner than that, we’re using what information we have – the
GDPR
itself, the Information Commissioner’s
GDPR summary
and their
existing guidance under the Directive
– and implementing something that we hope won’t be too hard to modify if required in future.
The key to this is the ICO’s recommendation for “layered notices”. We’ve put most of the legally-required information in a single central page, with individual data collection forms linking to that and providing additional information – either on the form itself or hyperlinked – where they need to. The style tries to combine user-friendliness with legal rigour, but favouring the former. We expect lawyers to be able to work out that when we say “you asked us to process data” we’re talking about what they know as “consent”.
The
central notice
is structured around the four legal bases that we expect to rely on when handling customer data:
necessary for contract (“to provide a service you’ve requested”);
necessary for legitimate interests (“to identify faults or ways to make the service better”);
consent (“you asked us”); and
data processor for an educational organisation (“we’re operating a service provided to you by a third party”).
In each case, it turns out that the GDPR’s information requirements can be covered in a paragraph or two.
For data collection pages, we’ve identified three types of service:
transaction, where the processing has a natural end-point (e.g. a helpdesk query);
relationship, which is likely to be indefinite (e.g. subscribing to a Jisc service); and
free consent (e.g. providing input to a survey).
The minimum information in each case is to state which of the four legal bases apply, point to the central notice and, for relationship and consent, tell the individual how to end the processing. We’re also proposing to add optional information, either on the collection page itself or through a link, where appropriate to the particular service:
If it’s covered by Jisc’s ISO27001 certification; if it involves placing information in a public directory; if any third parties are involved in processing; if data may be transferred outside the EEA; and if there has been a Data Protection Impact Assessment;
Any option to convert a “transaction” to a “relationship” (e.g. keep my data for the next conference);
If the service involves a user providing personal data about others (e.g. when managing an organisation’s subscription to a Jisc resource);
We’ve started to roll this approach out for a small number of our services. So far it seems to be working well for those, so expect to see more information in this style over the next few months.
Originally posted: 14 October 2017 in category
Articles
The Article 29 Working Party of European data protection supervisors has published the final version of its
Guidelines on Data Protection Impact Assessments (DPIAs)
. These build on the long-standing concept of Privacy Impact Assessments, being similar to normal risk assessments but looking at risks to the individuals whose data are being processed, rather than to the organisation doing the processing. Having identified the risks, the DPIA process should then consider how they may be mitigated, and ensure that this reduces them to an acceptably low level.
Under Article 35 of the GDPR, performing a DPIA is mandatory for any processing activity that represents a high risk to individuals. The Guidelines provide a list of nine characteristics of processing – evaluation or scoring, automated decision-making with significant effect, systematic monitoring, sensitive data, large-scale processing, combining datasets, vulnerable data subjects (including employees), innovative technological or organisational solutions, processing that prevents individuals exercising their rights – and suggest that any activity including two or more of these is likely to require a DPIA. A table of worked examples provides useful comparisons for organisations assessing their own activities. In addition, supervisory authorities are encouraged to make lists both of activities that do require a DPIA and those that do not.
Once a DPIA has been decided on, the next question is which risks need to be assessed. Here the guidelines provide little help. Although “privacy” and “data protection” are different rights in European law, here “Privacy Impact Assessment” and “Data Protection Impact Assessment” appear to be treated as synonymous. Annex 1, which suggests existing processes likely to be satisfactory, includes both types (including the Information Commissioner’s PIA Code). It’s therefore unclear whether a DPIA should look only at risks to non-public data, or include issues such as potential misuse of public directories (a DP issue, but not a privacy one) or, as suggested on page 6 of the guidelines, risks to
all
rights and freedoms, including free speech and freedom from discrimination.
The guidelines aren’t sufficiently detailed, in themselves, to be used to conduct a DPIA. Instead organisations could look at the various Codes referenced in Annex 1, or else use the list in Annex 2 of features of a DPIA to perform a gap analysis against their existing risk assessment and development processes to determine how these could be developed into an acceptable DPIA.
Formally the legal requirement to perform a DPIA only applies to new activities and those where risks have changed. The draft guidelines contained a specific deadline by which existing high-risk processing should be subject to a DPIA; this has now been replaced by an expectation that this will happen as risks to personal data are periodically reviewed. The guidelines also note that performing a DPIA and publishing a summary can help to build confidence in an organisation and its processing, so there may be benefits from applying the approach more widely.
Originally posted: 20 September 2017 in category
Articles
It’s pretty clear from the context and implications that when European legislators wrote “public authority” into the
General Data Protection Regulation
they didn’t mean the same as the drafters of the UK’s Freedom of Information Acts. “Public authority” isn’t defined in the Regulation and I’ve not been able to find it in any other European law, so I’m grateful to David Erdos for pointing out the case where the concept and reason for it, if not the actual phrase, were discussed.
has been made responsible, pursuant to a measure adopted by the State, for providing a public service under the control of the State and has for that purpose special powers beyond those which result from the normal rules applicable in relations between individuals. (para 22)
That makes a lot of sense in the data protection context too. Where a law has given an organisation special powers to process personal data for a particular task, it may well be appropriate to restrict its use of other processing powers that it should not need. There is a clear echo of the
British Gas
case in Recital 47:
Given that it is for the legislator to provide by law for the legal basis for public authorities to process personal data, that legal basis should not apply to the processing by public authorities in the performance of their tasks.
Recital 43 also casts doubt on whether valid consent can be obtained.
However where the organisation is acting in areas
other
than the special “tasks” assigned to it by law (for example to protect the security of its networks and information, as in Recital 49), it has no special powers, should not be given special treatment and “the normal rules applicable in relations between individuals” should apply. Extending the restriction beyond the legally-defined tasks is likely to force the organisation either to extend its special powers to processing for which they were not authorised, or to use other inappropriate bases for processing.
Pleasingly, this is
pretty much the intention I’d worked out
based on how the term “public authority” is used in the legislation. Where an organisation has been given special legal authority to carry out a particular task it should be using that authority, not legitimate interests, to justify the processing. For other tasks, it should be free to use legitimate interests, consent and the other legal bases, whichever is the most appropriate. An instance of successful reverse engineering of law, I think 🙂
#334 - GDPR: Backups, Archives and the Right to Erasure
Originally posted: 11 September 2017 in category
Articles
I was recently asked how the GDPR’s Right to Erasure would affect backups and archives. However that right, created by
Article 17 of the GDPR
, only arises when a data controller no longer has a legal basis for processing personal data. Provided an organisation is implementing an appropriate backup and archiving strategy, that shouldn’t happen.
The key point is that
backups and archives are different
. Backups exist in case information is accidentally destroyed. Backups should cover all information, but each one only needs to be kept for a short time: essentially however long it will take the organisation to discover the destruction. Since they are only needed when something goes wrong, access to them can be tightly limited by both process and technology. The legal basis for processing is likely to be the organisation’s (and its data subjects’) legitimate interest in recovering from accidents.
Archives, by contrast, involve long-term storage of the organisation’s history. So they should only contain the selected subset of information that constitutes that history. Organisations intend that their archives will be used, so should store them with indexes and structures that make that easy. The legal basis for archives may well be that they are a legal obligation (see
Jisc’s record retention schedules
) or else the legitimate interest in retaining an organisational memory.
Thus provided we don’t try to keep backups for ever, or to archive everything, both types of processing should always have a legal basis and the right to erasure shouldn’t arise.
Where personal data are being processed based on legitimate interests, the individual is entitled to raise an objection, under Article 21, requiring the organisation to check that its interest in the processing is not overridden by the resulting risk to that individual’s rights and freedoms. For backups – with strong security, limited access and a short retention period – the risk should be very low and the balancing test straightforward to satisfy. Placing personal data in an archive may create greater risks, since the intention is that these will form a long-term record that can be accessed by others, so organisations need to ensure that data selected for archiving is clearly necessary for that purpose.
Originally posted: 29 August 2017 in category
Articles
Most of us are familiar with the recorded messages at the start of phone calls that warn “this call may be recorded for compliance and training purposes”. Some may recognise it as meeting the requirement to notify callers under the snappily titled
Telecommunications (Lawful Business Practice) (Interception of Communications) Regulations 2000
. But the data protection implications of call recording are perhaps more interesting.
Any conversation involves two people, so organisations need to think of two groups of data subjects before recording calls: staff and callers. For staff, the requirements are set out in Part 3 of the
Information Commissioner’s Employment Practices Code
:
There must be a clear purpose to the recording (page 60 mentions examples “to listen to as part of workers training, or simply to have a record to refer to in the event of a customer complaint about a worker”);
An impact assessment should be carried out, including identifying any possible alternatives;
Unless an exception applies, staff must be informed of the recording and the reason(s) for it.
From the caller’s side, the organisation needs to think about the legal justification for processing, the rights that callers will have over their personal data, and how long the recording will be kept. A few industries may have a legal obligation to record calls but normally – as the ICO’s examples indicate –this will be done to support a legitimate interest of the organisation. This justification involves three tests: is the purpose of processing legitimate, is the processing necessary to achieve that purpose, and can the risk to the data subject be reduced to a level where it does not override the organisation’s interest in the processing.
For example, identifying areas where helpdesk staff could benefit from training seems to be recognised by the ICO as legitimate, and listening to recordings is likely to identify needs that might not be discovered by other approaches. Reducing risk to callers will require controlling access to recordings, ensuring that those with access only use recordings for the specified purpose, and deleting recordings as soon as they have been checked. To improve service to its customers the organisation should want to do that as soon as possible after the call, even if it weren’t also a requirement under data protection law.
However, using a recording as an example in a training course seems much harder to justify under these criteria. If the caller’s or recipient’s voice is played back there is a risk – which the organisation cannot control – that trainer or trainees will identify them, either during the course or next time the individual calls. The same purpose can be as well, or better, achieved by using an anonymised transcript as an illustration, role-play, or script voiced by someone else. And an anonymised script doesn’t need to be deleted under a retention requirement or disclosed under a subject access request. However the balancing test still needs to be applied to the anonymisation process to protect the individuals’ interests – if they use distinctive phrases or styles of speech then the risk of identification from a transcript may still remain too high for the use to be acceptable.
Originally posted: 1 August 2017 in category
Articles
Many, perhaps most, wifi access services want to perform some sort of authentication of people who use them (for those providing connectivity via Janet, it’s a requirement of the
Network Connection Policy
). Since authentication involves some processing of personal data, it’s worth reviewing how different ways of doing that might be affected (or not) by the
General Data Protection Regulation
(GDPR) when it comes into force next year.
The eduroam/govroam approach provides both the best guarantees of good behaviour (since the user’s home organisation is required to deal with any breaches of visited site policy)
and
involves the least exchange of personal data. The visited site only knows where a roaming user comes from, not who they are, and sees no username, e-mail address or other information that would allow them to contact the user directly. The only thing provided by the home site is confirmation that the user has authenticated successfully and will be held to account for their behaviour, and a temporary session ID indicating which connection that applies to. That’s clearly the minimum needed to provide authenticated access, so “necessary for the purpose of the [user agreement] contract” under Article 6(1)(b) of the GDPR. Since
UK practice
is that home sites do not disclose the identities of roaming users, it could be argued that, under the
European Court’s judgment in Breyer
, the session ID isn’t even personal data; however visited sites should probably treat it as a pseudonym (recognised by Article 25(1) of the GDPR as a helpful risk-reduction measure) and continue to keep it and any accompanying logs in accordance with their own security policies.
One definite pseudonym, provided by some home organisations, is the
Chargeable User ID (CUID)
. Like the session ID, only the home organisation can link this to an individual or use it to contact them. Home organisations should provide different CUID values to each visited organisation, preventing its use to track visitors between organisations. However CUID does enable a visited organisation to recognise when, for example, an individual is repeatedly logging in and causing problems for the service. Such problems should be resolved by the home organisation, but CUID can let the visited network implement temporary measures until that is done. Since CUID is not necessary to provide the service, the appropriate GDPR basis is likely to be that processing is in the legitimate interest of the visited site, for example to protect the availability of the service. This basis requires the organisation to balance its interests against those of the individual, so visited organisations requesting CUID should review the purpose(s) for which they plan to use it, implement appropriate retention periods and other controls, and then confirm that these do not involve an excessive intrusion into users’ privacy and other rights.
Where wifi providers can’t rely on eduroam’s strong guarantee that users are known to their home organisations and have passwords acceptable to those organisations, some use two-factor approaches instead. These typically ask the user to provide a mobile phone number or e-mail address to which a temporary authentication token can be sent. For a service concerned that usernames may be shared (either knowingly or not) it again seems reasonable to claim that this is a requirement of providing the service the user has requested. An e-mail address or mobile number is, however, likely to be considered as a direct identifier so there’s little doubt that these must be handled in accordance with the GDPR.
Some services request an e-mail address not in order to send a second authentication factor, but to allow the provider to identify patterns of suspicious use. In effect this is a less privacy-protecting (and less effective, since the same user can give more than one e-mail address) equivalent of eduroam’s CUID. Again it’s hard to claim that this is necessary for a contract but, given that Recital 49 of the GDPR recognises that processing personal data for network and information security may be a legitimate interest, that justification (Article 6(1)(f)) might apply instead. This requires, however, that the provider ensures (and, under the GDPR, documents) that their interest is not overridden by the rights and interests of the user. Since identifying patterns of use will require a directly-identifying email address to be kept over multiple login sessions, retention periods and the security of stored data will need careful consideration and implementation.
Finally, if personal data collected during registration or authentication are used for other purposes, then those activities must be justified separately under the GDPR. Some changes likely are likely to be needed to practices common under the previous Data Protection Directive (EU) and Act (UK). In particular, any use of addresses to send marketing e-mails must be opt-in; making such consent a condition of providing service is likely to be unlawful under Article 7(4).
Originally posted: 25 July 2017 in category
Articles
Jisc provides a lot of different services: too many for us to look at each one from scratch before the General Data Protection Regulation comes into force next May. Instead, we’ve identified four different patterns that seem to cover the majority of services. We hope that having a common set of expectations for each pattern will simplify discussions with service managers, customers and users.
The first group is the simplest: services where an individual makes a request to Jisc, we respond to what they’ve asked, and the activity is complete. These transactional services include things like websites, helpdesks, and events. In each case we need to process sufficient information to understand the request and respond to it: for example for a helpdesk question that’s likely to be your name and an email address or phone number so we can return the answer to you. When you visit a website, we need to record your Internet Protocol (IP) address to send the requested page to your browser. To process an event booking we need a bit more information, but there’s still an obvious point when the transaction is finished and we no longer need to process its associated personal data.
The second group of services involve an individual having a longer term relationship with Jisc that doesn’t have a natural end-point. For example you might subscribe to updates from our website, or be nominated as one of our site contacts. Some of the transactional services in the first group may offer you the option to convert to one of these longer-term relationships: for example you can ask us to save your details for next time you book an event, express an interest in hearing about related training courses and so on. For these services we need to think about things like when to send you reminders, which other uses of your information you’ll consider “related” and so on. In legal terms, Jisc is likely to be the data controller for both these groups of service.
The third group of services involve an indirect relationship between Jisc and individual users. For a wide range of services we have a direct relationship with one or more individuals at each customer organisation whose role is to authorise others – for example by creating accounts or approving requests – as users of the Jisc service. Since Jisc doesn’t have a direct relationship with these services’ users we need to think about how to route information and communications via their authorisers. The nature of each service may introduce additional issues: for example services such as repositories may let users store information that the law expects us to take care of, for services such as personal certificates we can control what information may be stored, but for eduroam there’s no storage at all. In legal terms, Jisc will be a data controller for personal data about authorisers but may be a data processor, on behalf of the customer organisation, for user and stored information. We expect these variations to involve more detailed discussion with service managers but the basic pattern seems likely to remain the same.
Finally there’s a small group of services that have no relationship with individual users. These include keeping networks, systems and data secure, and other expected activities of either Jisc or the organisations that use our services. Here we need to pay particular attention to the new GDPR requirement of “accountability”: we must ensure that all processing of personal data is justified, that none of it would surprise the individuals whose data may be processed, and that there’s a clear overall benefit to the data protection and other rights of those individuals. We’re considering whether formal Data Protection Impact Assessments of these services will help us both ensure and demonstrate that. With all these services, we need to be as open as possible about what we are doing and how it benefits individuals. With that in mind, it’s helpful that legislators, regulators and others have been stressing that keeping systems and networks secure protects the privacy of those using them.
Over the next few months we’ll be working with service managers to establish which group is most appropriate, and how that can guide them towards GDPR compliance.
Originally posted: 11 July 2017 in category
Articles
Looking at yet another of those web registration forms that seems to collect more data than required, it occurred to me that there might be quite a neat way to meet the General Data Protection Regulation’s requirements for positive, recorded consent.
First step, as with anything under the GDPR, it to think about which information is really necessary to provide the service, rather than optional. Will the service actually break if I tell it I’m a seventeen-year-old wizard called Harry Potter? If not, that information isn’t necessary and consent is the right basis for processing it. The remaining fields should be documented, and processed, under one of the Regulation’s
“necessary for…” clauses
: most likely “necessary for the performance of a contract”.
For the other, optional, fields, where
consent is the appropriate basis
, the Regulation requires that this be a positive choice by the user, that providing the information not be a condition of providing the service, that the user’s choice be recorded, and that it be as easy for the user to withdraw consent as to provide it in the first place. Where a field is populated using a drop-down list, that could be as simple as providing a “prefer not to say” option and making that the default. If something else appears in the user’s submission, you know that’s a result of them having made a positive choice to change the default. Similarly for free-text entry, the form field should be empty by default, with the user allowed to leave it that way.
This means consent to processing data from any of those fields is both positive and not a condition of providing the service. For the documentation requirement you need to record when the information was provided. To ensure you know what each user consented to, you need to keep a record of all changes to information provided on the input form and your published privacy policy. And you need a “manage my account” form that allows users to change their information and set any optional fields (and the database behind them) back to “prefer not to say”.
Originally posted: 5 July 2017 in category
Articles
The Article 29 Working Party has produced
new guidance on data processing in the workplace
, to account for the very significant changes that have occurred since their previous guidance in 2001. Although the focus is on “employee monitoring”, it is likely to be relevant to other situations where an organisation has significant power over those who use its premises and equipment. The guidance considers the requirements under both the Data Protection Directive and, from next year, the GDPR.
The Working Party confirm that the same basic principles continue to apply, indeed they are now even more important because modern workplace systems are both more capable of intruding into privacy and much less obvious when they do so (compare a 2017 wifi monitoring system with a 2002 CCTV camera). Also, for many people, the boundary between workplace and home has blurred, so employers must take additional care not to intrude into private contexts. So, especially:
Proportionality: the benefits of monitoring must clearly justify the privacy intrusion;
Transparency: monitoring must be clearly explained and justified to those being monitored.
Legally, the guidance suggests that most activities will need to be done on the basis that they are necessary for a contract, necessary for a legal duty (e.g. to pay tax and national insurance), or necessary in the employer’s legitimate interests. Consent is considered “highly unlikely to be a legal basis for processing at work, unless employees can refuse without adverse consequence”. Page 6 has a helpful summary of the circumstances when each of these may apply, and the associated obligations on the employer.
The guidance stresses that technologies do not know why they are being used, so may well collect more data than is actually required. It is the employer’s responsibility to ensure that they have a clear, transparent and legitimate purpose for any collection of data, that collection and processing are the minimum necessary to achieve that purpose, and that appropriate measures are taken to prevent the reuse of data for other purposes. Whatever legal basis is being used, an analysis should confirm that processing is necessary and proportionate and that any interference with rights is minimised: this might well be formalised under the GDPR as a Data Protection Impact Analysis (DPIA).
A basic checklist: Is it necessary? Is it fair? Is it proportionate? Is it transparent?
Finally, chapter 5 provides helpful discussions of a number of specific scenarios that frequently arise: social media profiles of recruitment candidates; social media profiles of employees; ICT monitoring (both via security tools and general usage); monitoring of home/remote/BYOD working; physical access control; video monitoring; vehicle monitoring; third-party disclosure; international transfers.
Originally posted: 23 June 2017 in category
Articles
An interesting query arrived about when to advertise role-based, rather than individual, e-mail addresses. Do role-based ones feel too impersonal, for example, because senders don’t know who they are dealing with?
I’ve been recommending the benefits of role-based e-mail addresses, such as
service@jisc.ac.uk
for a long time. From a legal point of view they avoid the question “can we get access to X’s mailbox while she’s away?”, which may well raise tricky questions under interception and human rights laws. If messages are sent to a role-based address then, even if they are stored in an individual’s mailbox, it’s easy to get a computer to extract those particular messages if someone else needs to deal with the request. It seems to me pretty clear that for those messages, this isn’t interception as the mail is still going to the “intended recipient” (the people performing the role). And I’d expect that to be what the sender expects to happen, too.
[I’ve also heard reports that there’s a psychological benefit: that team members are less upset by spam received via a role-based address than sent direct to an individual one]
So when might you advertise an individual address, such as
my.name@example.ac.uk
? Presumably when the arguments in favour of role-based ones don’t apply. So that’s for messages that shouldn’t be accessed by anyone else, even when the addressee is on leave or has left the organisation. Here we’re looking at situations where it’s more important that the message be dealt with by a specific individual than that it be dealt with on a particular timescale, or at all. Indeed I’d argue that the original concern – that senders don’t know who will they are dealing with – actually applies more strongly to this case. If you’ve advertised an individual’s address, knowing that there are circumstances in which the message will actually be read by someone else, then it seems to me that the sender really could say that they have been misled.
Which leads me to a possible rule-of-thumb: what should happen to e-mails when the individual leaves? If the answer is “handled by another member of the team”, then use a role-based address. If, however, the answer is “bounced, with a ‘no such user’ message” (or perhaps forwarded to the user’s new location) then use an individual one.
Originally posted: 14 June 2017 in category
Articles
A question recently arose about monitoring students’ attendance at lectures and tutorials, and how this fitted into data protection law. Since the main purpose of such monitoring seems to be to identify and assist students who
don’t
attend, and whose presence is therefore
not
recorded or processed, there seem to be a number of both practical and legal issues to think about.
Firstly, is there any processing of absentees’ personal data going on at all? It seems to me that there is, because at some point the absence record will lead to an “expression of opinion about the individual and…indication of the intentions of the data controller or any other person in respect of that individual” (Data Protection Act s1(1)). That means some legal basis for the processing is required: since these individuals won’t, by definition, have had recent contact with the organisation, consent seems an unlikely option (these individuals may, in any case, be the least likely to provide opt-in consent). So it seems better to consider the data collection and offer of support as legitimate interests of the university or college. As in our
approach to Learning Analytics
, the benefits of such processing need to be balanced against the risk to the individuals. When the student responds to the offer they will either grant or refuse informed consent for the help being offered.
So what about processing the personal data of those who do attend? In many cases the main purpose of this seems to be to understand what patterns constitute normal attendance, so as to be able to identify those whose behaviour diverges from what is typical for their cohort or class. Since these students are making their personal data available, consent might be a possible basis, but this has practical disadvantages because of the need for that consent to be informed and opt-in. Since attending students obtain little or no personal benefit, a low participation rate seems likely, so the patterns derived from the data may well be unreliable. A useful rule of thumb is that for any processing that depends on maximising participation, consent is likely to be a poor choice. Again, legitimate interests appears a better option, though the balancing test may impose stronger requirements on the processing. Unlike non-attendees, where the benefit of intervention can be included in the calculation, attendees are unlikely to receive any benefit themselves. So stronger risk-reduction measures are likely to be required: for example it would be worth considering whether attendance patterns can be derived from pseudonymised data, kept separate from the students’ actual identities. Information about the processing, and the option to object if a student’s particular circumstances mean processing creates a greater risk for them, needs to be provided, but could be included in course or enrolment details.
In some situations, a couple of other legal bases may be available. Where attendance monitoring forms part of a university or college’s access agreement with a regulator, it might be argued to be necessary for that public interest. Or, for some students (e.g. international) and some courses (e.g. those leading to professional recognition) attendance monitoring may be necessary to comply with a legal obligation. Whether this could be interpreted under non-discrimination law as a duty to record attendance for
all
students is a question for lawyers – the argument that you need to increase someone’s data protection risk in order to not discriminate in their favour is a tricky one!
#326 - GDPR: Public Authorities and Legitimate Interests
Originally posted: 12 June 2017 in category
Articles
I was interested to spot that the Article 29 Working Party visited
the question of “public authorities”
back in 2014, on page 23 of their
Opinion on Legitimate Interests
. There they note that there are two possible interpretations of the (then draft) General Data Protection Regulation’s (GDPR) rule that public authorities may not use legitimate interests in the performance of their tasks: a narrow interpretation of both “public authority” and “task”, which leaves legitimate interests available for most of the body’s activities; and a wide view that means that all activities of those bodies should be performed under the alternative “public interest” justification. The working party’s discussion of “authorities” and “tasks” on page 21 suggests they favoured the narrow approach.
However so long as those are indeed the two alternatives that regulators will consider now the GDPR is law, it seems to mean that universities and other organisations that might be classed – under the wide definition – as public authorities can continue to design their processes to use legitimate interests where that provides the best protection for their data subjects. If regulators subsequently decide that public interest should be used instead, the same processes should satisfy that justification, too. Though considering the rights and freedoms of data subjects would then become optional. In either case there should be no need for the radical re-design of process (and torture of statutory wording) that would be required to replace a legitimate interests process with one based on consent.
[UPDATE:
a blog post from CASE Europe
suggests that the ICO and DCMS are indeed inclined to allow universities and colleges to use both legitimate interests and public interest as justifications for non-core and core functions respectively. So there should be no need to squeeze “consent” onto activities for which it’s clearly unsuitable.]
Originally posted: 23 May 2017 in category
Articles
Some of the
General Data Protection Regulation’s
requirements on data controllers apply no matter which legal basis for processing is being used. For example there are
common requirements on information given
to data subjects;
breach notification
and rights of
access
and
rectification
will normally apply to all personal data. However other requirements are specific to particular justifications. A previous post aimed to help organisations
determine the most appropriate justification(s)
for particular data processing activity. This one summarises the main differences – in particular to the information organisations must provide and the processes they must support – that arise from the choice of legal basis.
For further information I’ve linked to relevant guidance – either under the previous Directive or proposed for the Regulation – where I can find it.
Contract
: Data subjects must be informed that providing the information is necessary for the contract, and of the consequences of refusal. The Data Controller must handle requests for
data portability
.
Legal Obligation
: Data subjects must be informed that providing the information is a legal requirement, and of the consequences of refusal.
Vital Interest
: The Data Controller must handle requests for human review of any automated decision making.
Public Interest
: Data subjects must be informed of their right to object, based on their particular circumstances, to processing. The Data Controller must handle requests for human review of any automated decision making; they must have a process for reviewing objections to processing; they must also handle requests for restriction of processing while this review is taking place, and for erasure if the review concludes that there are no legitimate grounds to continue processing.
Legitimate Interest
: Data subjects must be informed of the legitimate interest(s) that justify processing and of their right to object, based on their particular circumstances. The Data Controller must have processes to
balance the interest(s) of the data controller against those of data subjects
; they must handle requests for human review of any automated decision making; they must have a process for reviewing objections to processing; they must also handle requests for restriction of processing while this review is taking place, and for erasure if the review concludes that there are no legitimate grounds to continue processing.
Consent
: Data subjects must be informed how to withdraw consent, and the right to erasure if they do so. The Data Controller must ensure that processes for giving and withdrawing consent
satisfy the Regulation’s requirements
(in particular that adult consent is obtained when relying on this basis to process a child’s personal data); they must keep records of when, how and to what consent was given; they must also handle requests for erasure when consent is withdrawn, and for
portability
.
Originally posted: 23 May 2017 in category
Articles
The Article 29 Working Party’s final
guidance on implementing the right to portability
is a significant improvement on the
previous draft
. The Working Party appear to have recognised the significant risk involved in making large collections of personal data available through on-line interfaces, and that other approaches will be more suitable for most data controllers.
The suggestion of providing an API as a portability interface is now restricted to “information society services that specialise in automated processing of personal data”. This might, for example, include banks and social networks that are already familiar with how to design and implement secure interfaces. The Working Party now stress the need for these to be secure, noting that a portability request, which gives access to all of an individual’s personal data, may require additional authentication such as a one-time token, in case the user’s normal login details have been compromised. Protocols that will encrypt the exported data as it passes over networks are recommended.
For other data controllers – likely to be the vast majority – less high-tech implementations now seem to be envisaged. Although the Regulation requires that data be provided in industry-standard formats, the guidance recognises that in many cases the best available option will be comma-separated values (CSV) accompanied by the metadata required to interpret them. The thought that portability requests from these organisations will be handled through a manual process, involving spreadsheet exports and human checks, is very reassuring to this particular data subject.
Originally posted: 15 May 2017 in category
Articles
The
Digital Economy Act 2017
contains sections relating to content filtering by “Internet Service Providers” (ISPs) and “Internet Access Providers” (IAPs). However both terms are derived from (and subsets of) the European definition of Public Electronic Communications Services, so will not apply to Janet or customer networks that are not available to members of the public. This means we can continue to choose filtering policies and technologies that are appropriate to the needs of research and education organisations, rather than having imposed solutions designed for domestic connections.
For any readers who do offer public connectivity, or are otherwise interested, the parts to look at are as follows:
Part 3
(Sections 14 to 30) of the Act allow the Age Verification Regulator (expected to be the British Board for Film Classification) to maintain a list of material that any ISP served with a notice is required to block (
s.23
); the Regulator may further prescribe how such blocking is implemented.
Section 104
ensures that content filtering and site blocking, for these or other reasons, is lawful so long as it complies with the terms and conditions for access to the network. This clarifies that provisions for IAPs in the
European Network Neutrality Regulation
do not make voluntary blocking unlawful.
The exemptions from certain obligations and data subject rights contained in
section 33
of the
Data Protection Act 1998
have been vital in enabling long-term research studies, including in health and social sciences, while ensuring the protection of individuals whose data may be used in those studies. We consider it important for the continuation of those studies and datasets that the same conditions continue to apply under the
General Data Protection Regulation
(GDPR). Any requirement on researchers to change their existing practice, or any new right of data subjects to prevent or place conditions on processing, could damage ongoing research and make future work unviable. We therefore encourage the Government to use the derogations in Article 89 to reproduce, so far as possible, the current
Data Protection Act
s.33 regime.
In particular we welcome the European Data Protection Supervisor’s recent suggestion (
Opinion 6/2017
, p.16) that Member States should use Article 89 to provide “additional, limited and specific exceptions in the ePrivacy Regulation, for example … to allow processing for the purposes of scientific research”. As provider of Janet, the UK’s National Research and Education Network, Jisc both benefits from and supports advanced network research in the UK. We therefore encourage the Government to use the Article 89 derogations to provide a legal regime that supports such research while providing appropriate safeguards for users of electronic communications systems.
We also note that Article 85 requires the Government to provide exemptions or derogations to several sections of the GDPR in order to protect the right to freedom of expression and information for the purposes of academic expression. The dissemination and publication of research represent speech of very high importance to society, which should be awarded an appropriately high level of legal protection. Subject to conditions to protect individuals (again, section 33(1) of the
Data Protection Act 1998
provides an appropriate model) we consider that academic expression requires and deserves the same level of protection as currently provided for journalistic expression by
section 32
of the
Data Protection Act 1998
. We therefore encourage the Government to use its obligation under Article 85 to provide that protection.
Additional Question – cost impact
Probably the greatest cost impact on UK organisations will be if, after leaving the European Union, they are required to include Model Clauses in, or obtain permission from EU regulators for, every contract with an EU counter-party. We therefore consider it essential that the UK seeks and obtains a declaration of adequacy under Article 45(3) of the
General Data Protection Regulation
, and would be concerned if derogations or other measures in the UK’s implementation risked reducing the likelihood of obtaining such a declaration.
The Department for Culture, Media and Sport has called for
views on how the UK should use the “derogations”
(i.e. opportunities and requirements for national legislation) contained within the General Data Protection Regulation. The main area where derogations, or the lack of them, could affect the Jisc community is in the application of the GDPR to research data. We have therefore recommended that the UK Government should:
use the Article 89 (Research and Archives) derogation to reproduce the current regime under
s.33 of the
Data Protection Act 1998
(DPA), which has enabled long-term research studies and data sets, including in health and social sciences;
in particular, and as suggested by the European Data Protection Supervisor, apply that derogation to the forthcoming ePrivacy Regulation to permit suitably protected research on electronic communications data;
use the Article 85 (Free Speech) derogation, as required by the GDPR, to give academic expression and information the same free speech protection as journalistic expression has under
section 32 of the DPA
.
Originally posted: 8 May 2017 in category
Articles
[I’ve updated this 2015 post to refer to the section numbers in the
Investigatory Powers Act 2016
. As far as I can see, the powers contained in the Act are the same as those proposed in the draft Bill]
Over past months there has been various speculation that the
Investigatory Powers Bill
[now the
Investigatory Powers Act 2016
] would try to ban the use of strong encryption. Now the proposed text has been published [and still under the Act as passed], it doesn’t seem to go quite that far. It won’t be illegal either to use strong encryption or to provide it.
However clause 189 of the draft Bill [
section 253
of the Act] does create a power for the Secretary of State to order any provider of telecommunications services or public postal services (including those outside the UK – clause 190(5) [section 253(8)]) to implement “technical capabilities”. The limits on such orders are contained in clause 189(3), which requires that it must be practicable for the operator to comply with the requirement [section 253(4)] and that by doing so they will “provide assistance” [section 253(1)(a)] to those authorised to conduct interceptions (Parts 2 and 6), obtain communications data (Parts 3 and 6) or interfere with equipment (Part 5). Clause 189(7) [section 253(1)(a)] seems to imply that a “technical capability order” could be made before any specific requirement to intercept etc. had been identified or authorised.
Clause 189(4) [section 253(5)] gives some examples of areas where a technical capability might be ordered, including c189(4)(c):
obligations relating to the removal of electronic protection applied by a relevant operator to any communications or data
[In the Act, the example in s.253(5)(c) is slightly modified:
obligations relating to the removal by a relevant operator of electronic protection applied by or on behalf of that operator to any communications or data.]
So it seems that the possibility of ordering a telecommunications provider to remove encryption is in the Government’s mind. It’s easy to imagine circumstances where a decryption capability would assist with interception or data collection, so the only restriction seems to be whether it is practicable for the communications provider to do it. That may not be possible, even where the provider has itself applied the encryption. Many modern algorithms are “one-way”: I encrypt, you decrypt. Most people who regularly use encrypted e-mail will have had the experience of forgetting to “encrypt-to-self” and having to ask the recipient to send a copy back again!
The process for issuing a technical capability notice gives the provider opportunities to raise these issues, both before and after issue. Clause 191 [
section 257
of the Act] allows an issued notice to be referred back for review, at which point the Secretary of State must consult with both the Investigatory Powers Commissioner [now replaced by a Judicial Commissioner] and the Technical Advisory Board. Things to be taken into account include the technical feasibility, cost and other impacts on the provider (clause 190(3) [
section 255(3) & (4)]
). So it seems unlikely that a notice that was actually impossible to comply with would be imposed. However if you are using, providing or recommending any encryption system where a layperson might imagine you could decrypt messages (and I suspect that means pretty much anything involving asymmetric keys) then it would be a good idea to document who actually can and cannot do so.
Originally posted: 5 May 2017 in category
Articles
Most universities maintain databases of alumni, for purposes including keeping them informed about the organisation, offering services and seeking donations. These activities have a lot in common with other charities, so the
Information Commissioner’s guidance
is relevant. Indeed the Information Commissioner’s recent description of using consent-based relationships “to improve [supporters’] level of engagement with your organisation and encourage them to trust you with more useful data” is likely to be very much what universities are aiming for. However the way in which individuals join alumni databases is likely to be different from other charities, so it’s worth reviewing these processes and communications in the light of planned changes to data protection law in May 2018.
Whereas most charities recruit supporters directly, in universities this will often take place as part of the individual’s transition from being a student in a contractual relationship with the organisation to an alumnus with a long-term relationship based on freely-given consent. For both legal and practical reasons this transition needs to include an exchange of information: the university needs to inform the alumnus about future storage and processing of data, and obtain their consent to this (since it is no longer necessary for the purpose of education); the alumnus may well need to provide updated contact details, since those used while a student are likely to go quickly out of date.
In May 2018 the
General Data Protection Regulation
(GDPR) will change the requirements for consent to be valid; the European Commission’s recently proposed draft e-Privacy Regulation may also change the law on how this may be communicated:
Article 13 of the GDPR sets
specific requirements on the information that must be provided along with a request for consent
: the organisation’s identity and contact details; the purpose(s) of processing; how long data will be kept; how to exercise rights, including to withdraw consent and complain to a statutory authority; any third-party recipients of the data; any international transfers; any automated decision-making. Consent must now be indicated through a positive action (silence, or leaving a pre-ticked box are no longer sufficient) and must be easy to withdraw. And a record must be kept of how consent was obtained, when, and on what terms.
The European Commission has recently proposed a
new e-Privacy Regulation
, which would extend the requirement to obtain consent before sending marketing messages (which may well cover supporter recruitment). At present prior consent is only required for e-mail, but the draft text would extend this to all electronic communications, including phone and SMS.
The combination of these two changes may make it harder to re-establish communications with alumni after they leave. In particular, if prior consent to electronic messages has not been obtained then universities may only be permitted to use postal mail, and that a time when ex-students are particularly likely to have changed address. Starting the alumnus relationship before students leave should help to achieve a smooth transition.
Under the GDPR it may be possible to continue to use existing data about alumni, but only if the information and process used to collect it met the new GDPR standard. If this is not the case then new consents will need to be obtained. However recent cases of misuse of personal data by high-profile charities may lead alumni to expect this level of engagement anyway; the GDPR then provides universities with an opportunity to demonstrate that they are implementing best practice. Again, the possibility of changes to the law on communications means this may be easier if done before May 2018.
Anyone who has looked at an information security standard is likely to be familiar with the idea of an Information Asset Register. These cover the What and Where of information that an organisation relies on: what information do we hold, and where is it kept.
Many of the requirements of the
General Data Protection Regulation
(GDPR) point to an extension of this idea: something more like an Information Lifecycle Register. This would add
Why – are we processing this personal information?
How – do we process it to minimise risks?
When – do we need it, and when can we delete it?
Who – do we need to disclose it to?
From this lifecycle information the
legal basis for processing
– for example that it is necessary for a contract, for a legal duty, for a legitimate interest, or processed by consent – should be obvious. Under the Regulation, notification requirements and data subject rights flow from that legal basis. The answers to How, When and Who should identify opportunities to minimise data (for example by using pseudonyms) and processing. Documenting this lifecycle information before a new processing activity begins should help the organisation demonstrate that it is practising data protection by design.
In fact, many organisations will already have much of this information about their key assets, arising out of risk assessment and records management processes. For example the National Archives suggest including risks to and opportunities from, as well as retention periods, in their
guidance on Information Asset Registers
. So understanding information lifecycles, which is likely to be a
critical step in preparing for the GDPR
, may be easier than you think.
Documented and explained life cycles will go a long way to achieving the
accountability requirements
of the GDPR. But understanding the flows of information through an organisation, rather than just its existence, is much more than just a compliance benefit. It should let the organisation make better use of that information too.
#315 - Article 29 Working Party support security and incident response
Originally posted: 11 April 2017 in category
Articles
Having had my own concerns that the European Commission’s draft e-Privacy Regulation
might prevent some activities that are needed by security and incident response teams
, it’s very reassuring to see the Article 29 Working Party recommending an explicit broadening of the scope of permitted Network and Information Security (NIS) activities. Strikingly, this comes in an
Opinion
that otherwise expresses “grave concern” that too much processing of communications content and metadata is being allowed. It’s clear that the European Data Protection Regulators have understood that NIS and the data processing it involves are an essential part of protecting communications privacy.
Paragraph 18 of the Working Party’s Opinion supports the Commission’s proposal to permit processing of electronic communications data that is “necessary to maintain or restore the security of electronic communications networks and services” (Article 6(1)(b)). However the Opinion adds that “certain spam detection/filtering and botnet mitigation techniques” should explicitly be permitted. The Working Party thus recognises that users and their devices, not only networks, need protection and help.
Paragraph 26 (page 20) also recommends that installing security updates should be an explicit exception to the normal rule that “interference with equipment” requires the user’s prior consent. Instead the Working Party favour automatic installation of patches without consent – to “ensur[e] that the security of these devices remains up-to-date” – so long as users are informed in advance and have the possibility to turn off automatic installation. Paragraph 41b suggests that an employer could even override an employee’s choice when updating or re-configuring company-issued equipment.
Finally, in paragraph 35 the Working Party “welcomes” the requirement on service providers to inform users about security risks: “if a service provider detects that a user’s device is infected with malware and has become part of a bot-net, this provision seems to put a direct obligation on the provider to inform the user about the resulting risks”. In the past I’ve been told of other countries’ regulators prohibiting ISPs from informing their customers when we passed on botnet warnings, so this positive encouragement of this practice is good news for all of us.
Whether or not these proposals are reflected in the final legislation, security and incident response teams now have a clear endorsement of their activities from privacy and data protection regulators.
Originally posted: 31 March 2017 in category
Articles
While some have viewed the
General Data Protection Regulation
‘s approach to consent as merely adjusting the existing regime, the
Information Commissioner’s draft guidance
suggests a more fundamental change: “a more dynamic idea of consent: consent as an organic, ongoing and actively managed choice, and not simply a one-off compliance box to tick and file away”. In this it continues a long-standing view from the UK Commissioner that consent should probably be the last of the six available justifications to be considered, unlike other European countries where law or practice appear to consider it first. Indeed there’s even a hint that consent should be reserved for an entirely different kind of data processing: that which isn’t “necessary” but is done as a voluntary collaboration between data subject and data controller. As Chris Pounder has pointed out, where consent is used
the data subject, not the data controller, must be in control
.
Where processing is necessary, one of the other five justifications (contract, legal duty, vital interests, public function, legitimate interests) should be used. The guidance notes that one of the others
must
be used if “you would still process the data without consent”. If an attempt to withdraw consent results in “we need to carry on processing” then the original consent was almost certainly invalid, and the misinformation when it was obtained is likely to make any other basis doubtful as well. Any situation where the data controller is “in a position of power” over the data subject is likely to render consent unreliable – employers and those exercising public authority need to look particularly carefully at the guidance on ensuring that consent is genuinely free.
That leaves consent to be used “when no other lawful basis applies”, though it’s clear that consent cannot cover all such circumstances. If no other basis applies
and
you can’t meet the requirements of consent, then it is likely that your processing has no legal basis and is therefore unlawful. Instead, consent should reflect a positive relationship between data controller and data subject, building trust to “encourage [data subjects] to trust you with more useful data”. In that kind of relationship, meeting the requirements for valid consent should not be hard: if it is, then you should check whether this is really the right approach.
The guidance notes that the Regulation “sets high standards for consent” though it appears that when used properly, those standards should be a relatively natural result of the relationship. The guidance hints strongly that many current uses of “consent” are unlikely to meet those standards. Data controllers should review how they actually use personal data and fix any forms, notices, documents and processes to reflect the true legal basis. Where existing lists are found to have been gathered using a lower standard of consent, these are likely to need refreshing. Given the widespread use of consent under current data protection law, and the high fines for misusing it under the Regulation, this should probably be a high priority for action before May 2018.
#313 - What’s the data protection difference between public and private sectors?
Originally posted: 31 March 2017 in category
Closed
[UPDATE] a slightly revised version of this post formed our response to the ICO consultation.
The
Information Commissioner’s draft guidance on consent
makes a surprisingly broad distinction between public and private sector organisations, even when they process the same data for the same purposes. This risks removing important protections when personal data are processed by the public sector, and does not appear to be required by the
General Data Protection Regulation
that the guidance aims to implement.
In discussing the alternatives to consent, page 16 treats “necessary for a public task” (Article 6(1)(e) of the Regulation) and “necessary for legitimate interests” (Article 6(1)(f)) as an equivalent pair – the former “likely to give [] a lawful basis for many if not all of [a public body’s] activities”, the latter available only “if you are a private-sector organisation”. However the two are not equivalent for the person whose data are being processed: the legitimate interests of an organisation must be balanced against “the interests or fundamental rights and freedoms” of the individual, whereas this is not a requirement when processing for a public task. For a number of different activities performed by both public and private sector education organisations – from
protecting the security of computers, data and networks
to
federated access management
and
learning analytics
– we have found that this balancing test provides valuable guidance to organisations and protection to individuals.
Furthermore many, if not most, of the data processing activities performed by public sector organisations are done by private sector organisations as well. Both act as employers, provide education, raise funds, protect their premises using CCTV, and so on. Applying different rules to this processing, depending solely on whether or not public funds are involved, can only create uncertainty and opportunities for accidental or deliberate breaches of data protection.
Article 6(1)(f) of the General Data Protection Regulation in fact only prohibits the use of legitimate interests “by public authorities in the performance of their tasks”. Article 6(3) requires that those tasks be prescribed by law, which may adapt the normal rules of the Regulation. Where a task requires the state to authorise a particular body to work outside normal data protection rules, prohibiting the use of legitimate interests to expand that authority does indeed protect data subjects. However Recital 49 demonstrates that this does not apply to all activities performed by public bodies: “ensuring network and information security” is declared to be a legitimate interest of public authorities equally with a wide range of both public and private organisations. Where public and private sector bodies perform the same function under the same data protection rules there seems no reason to treat them differently.
In the interests of both consistency and protection of data subjects, it seems preferable to limit the use of the “public task” basis to processing activities, such as tax collection, that involve the state assigning specific powers to particular bodies. For activities that are performed on an equal basis by both public and private sector organisations, the greater protection provided by “legitimate interests” and the other legal justifications should be used.
Originally posted: 23 March 2017 in category
Articles
A couple of organisations have asked me recently whether the General Data Protection Regulation (GDPR) requires them to get some sort of external recognition of their incident response team. Here’s why I don’t think it does.
Recital 49 of the Regulation says:
The processing of personal data to the extent strictly necessary and proportionate for the purposes of ensuring network and information security, i.e. the ability of a network or an information system to resist, at a given level of confidence, accidental events or unlawful or malicious actions that compromise the availability, authenticity, integrity and confidentiality of stored or transmitted personal data, and the security of the related services offered by, or accessible via, those networks and systems,
by public authorities, by computer emergency response teams (CERTs), computer security incident response teams (CSIRTs), by providers of electronic communications networks and services and by providers of security technologies and services
, constitutes a legitimate interest of the data controller concerned…
If your work involves using logs or other usage data to protect network or information (system) security, then clearly it would be reassuring to be on that list. However it’s already apparent that the list isn’t exhaustive – the recent European Court case of
Breyer v Deutschland
added website operators to it. And, anyway, universities, colleges and most other organisations are already there as “providers of electronic communications networks and services”: the GDPR wording (taken from the telecoms framework directive 2002/21/EC) covers both public and private networks. So those organisations are already covered by Recital 49, irrespective of whether they have a team called CERT/CSIRT.
As to which group(s) within the organisation are authorised to “process[] personal data … for the purposes of ensuring network and information security”, the person responsible for deciding that is the data controller for that personal data, i.e. the university or college itself. An external body such as Jisc may be able to suggest how to do incident response in accordance with the Regulation (my
paper on Incident Response and the GDPR
tries to provide both a comprehensive framework and a lot of specific examples), but we can’t decide how those tasks should be assigned within your organisation. So if your organisation operates a network or servers, and has authorised you to protect them against digital attacks, I’d be comfortable that Recital 49 applies to you.
Finally, and confusingly, unlike the GDPR the European Network and Information Security Directive
does
have a concept of an official CSIRT. However that’s a team designated by the Government as having responsibility for part of the critical national infrastructure: not a status that Jisc or any university or college is likely to seek.
Originally posted: 16 February 2017 in category
Articles
Organisations connecting to Janet are required to implement three policies: the
Eligibility Policy
determines who may be given access to the network; the
Security Policy
sets out responsibilities for protecting the security of the network and its users; the
Acceptable Use Policy
identifies a small number of activities that are not permitted on the network. For years we’ve been applying those policies to connecting people to Janet: more recently questions have arisen about connecting devices, often referred to as the Internet of Things (IoT).
Whether connecting people or things, the responsibilities of organisations remain the same, broadly:
ensure that only members and guests can gain access to Janet (Eligibility Policy 15-19);
ensure that insecure devices and users don’t pose a threat to other users of Janet (Security Policy 9);
ensure that any complaints can be investigated and dealt with effectively (Security Policy 8; Acceptable Use Policy 19).
How to do that depends very much on what the device in question is and does: all things are not alike. Many will use the Internet as clients, connecting to servers but not running any services of their own. For example we’ve been asked about connecting exercise machines that store their users’ fitness plans on a remote, cloud-based, server. Here traditional firewalls can be used to block inbound access to the machine, and possibly also to limit the protocols and servers it can use outbound. Patching is known to be a challenge for IoT devices – many will pass their entire life without a software update – so network-based measures may well be their main, or only, defence against attacks. Protecting IoT networks with tools such as virtual networks, firewalls, proxies and intrusion protection systems should be seen as essential deployment practice, not just policy compliance.
Where devices connect to wireless, rather than wired networks, organisations will need to ensure that they can only connect to the intended, local, network. If using a common SSID such as
eduroam
the device must be configured to present authentication credentials that will only work on the owning site’s wireless network, not on any neighbour’s network that may not provide the protection it needs. The local network should be configured to recognise the account as belonging to a potentially vulnerable “thing” and connect it to an appropriately configured and protected network segment; well-separated from those used for visiting laptops etc.
A device without users may be less likely to breach the Acceptable Use Policy, but it’s not impossible. There have been a number of reports of compromised “things” being recruited into botnets. Recently the
largest ever denial of service attack
has been reported, apparently generated using insecure webcams with unrestricted internet connections. It seems likely that pictures from all those cameras were openly viewable too. Organisations need to be able to detect incidents and respond to complaints relating to connected devices, so it’s important to know where they are and who is responsible for them.
Devices that do (or may) have human users will also need controls to ensure that only authorised individuals can access them. If a user of the device will thereby gain access to Janet then some measure will be needed to ensure that only members or guests of the organisation can do so. If this isn’t possible then the device will need to be treated as
providing public access
and separate internet connectivity arranged. If the device itself doesn’t support authentication the necessary control could instead be achieved by limiting physical access, signing out individual devices, using an authenticating gateway to gain network access, etc. Humans are likely to make wider use of the network than an automated device, so are more likely to give rise to complaints. Some way of dealing with misbehaviour will be needed, either by warning individual users to stop, or by removing or restricting the problematic access from the device as a whole.
Connecting things isn’t so different to connecting people, though it may involve a shift in the kinds of precautions that are used. Preventive, rather than responsive, controls may well be more appropriate, especially where devices such as cameras or building controls interact with the physical world.
Jisc is the UK’s expert body for digital technology and digital resources in higher education, further education and research. Since its foundation in the early 1990s, Jisc has played a pivotal role in the adoption of information technology by UK universities and colleges, supporting them to improve learning, teaching, the student experience and institutional efficiency, as well as enabling more powerful research.
Our incident response team, Janet CSIRT, frequently helps universities and colleges to deal with the consequences of security breaches of third-party internet services, recently including TalkTalk, LinkedIn and Yahoo!. These databases often contain personal details of students and staff who happen to be customers of such services: once these have been accessed or disclosed by hackers there is little that can be done to remedy the damage to those individuals’ privacy and data protection rights. We are therefore concerned that, by suggesting (contrary to data protection regulators’ existing security recommendations) that all data controllers should make personal data stores, including their customer and employee databases, accessible on-line, the Working Party’s guidance on the GDPR Portability Right will greatly increase the number of such security breaches and the harm they cause.
Since the primary aim of the portability right is now stated (pp4&5) as “to facilitate switching from one service provider to another, … enhancing competition” and “preventing lock-in”, we believe that a technological implementation of the right should only be required of the small minority of data controllers that raise competition concerns. The Working Party’s guidance should explicitly recognise that for many data controllers on-line access to personal data will be an unjustified security risk, and other ways of providing the right will be more appropriate.
Risks of Internet-connected customer/employee databases
Good security practice holds that personal data should not be placed on computers accessible from the Internet unless this is essential. Systems holding such data should normally only be accessible to a limited number of trusted staff. The UK Information Commissioner’s
Protecting personal data in online services: learning from others
notes the importance of segregating internal and externally-accessible systems using firewalls and de-militarised zones (para 108) and reducing the number of people granted external access to personal data as far as possible (para 47).
Providing “download tools and APIs”, as the Working Party’s guidance recommends for all data controllers (p3), breaks this security model. Such tools will require systems holding relevant personal data to be accessible over the Internet. This will include every customer and employee database since these, being “necessary for a contract”, are subject to the portability right (p7). Furthermore such access must be available to all data subjects, in case they wish to exercise that right: it can no longer be limited to authorised, trusted, staff.
The number of reports of compromises of existing on-line customer databases indicate how hard it is to provide such access in a secure fashion. The businesses suffering these breaches are those – communications providers, social networks, etc. – where providing customers with access to their data is a core business function. These already have a business incentive to spend money, effort and skill on designing and maintaining secure systems and providing customers with appropriate authentication systems, including two-factor authentication. However the majority of data controllers affected by the Working Party’s guidance will have only a regulatory incentive to create their new remote access systems – in business terms these will be a pure cost. It seems very unlikely that these data controllers will achieve or maintain the same level of security. This means the rate of compromise of systems created solely to support the portability right is likely to be much higher. The impact of such breaches may also be greater as, by design, they will give attackers access to all the personal data the organisation holds by consent or contract.
Risk of idle accounts
A common way for online systems to be compromised is through unused accounts. If these are left with default passwords then, as the Information Commissioner notes (para 129-133), they provide easy access to unauthorised attackers. Even if individual passwords are set, accounts that are not used provide attackers with an opportunity to guess passwords with little risk of detection. The current rate of subject access requests suggests that the majority of data subjects will never exercise their portability right, so tools and APIs are likely to provide a rich source of opportunities for such attacks. According to the Information Commissioner (para 44): “If you have services which are publicly accessible and are not being actively used, you are exposing a range of potential attack vectors unnecessarily.”
Risk of user deception
Even if the data controllers’ systems for exercising the right to portability can be kept secure, there is a global criminal industry dedicated to persuading users to disclose their passwords. Successfully phishing a data subject’s portability password may only give access to that individual’s data but, again, the portability right ensures significant harm as all the relevant data held by the data controller will be disclosed.
Even the cost of a phishing campaign may not be necessary, as many passwords chosen by users will be
trivial for attackers to guess
. Even for the minority of data controllers that are capable of providing a technically secure portability interface, the benefits to attackers seem likely to be far greater than to data subjects.
Recommendation
Creating and maintaining a secure download tool or API will be a challenging software development task that only a small proportion of data controllers will have the skills to achieve.
To avoid creating many opportunities for large-scale breaches of data protection and privacy rights we recommend that:
Data controllers should inform data subjects of their portability right;
Data controllers should only enable processes or systems to support that right for individual data subjects when an individual, having been securely authenticated, requests it;
Only data controllers who already provide secure on-line access to customer data as a business function (e.g. banks, social network providers) should consider providing tools or APIs to exercise the right. All other data controllers should handle portability requests in the same way as their current subject access processes. In most cases this will involve manual processes by trusted staff, not direct access to databases by data subjects.
The Working Party’s guidance should highlight the importance of data security, not leave it till the very last page, and emphasise that for most data controllers a manual implementation of the portability right will be the best way to achieve this.
Finally, we note that only a tiny minority of data controllers will raise the competition and lock-in issues that the portability right is intended to address. The
European Data Protection Supervisor’s 2014 paper
identified concerns only with “free services paid for by personal information. Many of these will already be in the group that could provide technical portability tools as a natural extension of their existing business access to customer data. For all other data controllers, a technical implementation of the portability right will create great risks to the security of personal data with little or no benefit to competition.
#308 - ePrivacy Regulation: a risk for website security?
Originally posted: 18 January 2017 in category
Articles
Last October the European Court of Justice confirmed that
websites do have a legitimate interest in security that may justify the processing of personal data
. That case (
Breyer
) overruled a German law that said websites could only process personal data for the purpose of delivering the pages requested by users. As far as I know, everywhere else in Europe the use of logs to secure websites is accepted as lawful. However the European Commission’s
proposed e-Privacy Regulation
seems to risk reversing that: I hope by an accident of drafting.
The presumption of the draft Regulation, stated in Article 5, is that communications content and metadata “shall be confidential”. Any interference with such data, other than as permitted by the Regulation, shall be prohibited.
The draft Regulation does permit “providers of electronic communications networks and services” to process both content and metadata where this is “necessary to maintain or restore the security of electronic communications networks and services” (Art.6(1)(b)). However the definitions of “electronic communications networks and services” (themselves dependent on
another draft Regulation
) won’t cover all websites, etc. So, if those are covered by the draft Regulation, then collecting and using logs for security may become legally questionable, this time across the whole EU, not just Germany.
That, in turn, depends on interpreting the scope of the draft Regulation. According to Article 2(1) it applies to “processing of electronic communications data carried out in connection with the provision and the use of electronic communications services”. So if web logs (which undoubtedly involve “processing of electronic communications data”) were found to be “in connection with the provision and use of electronic communications services”, even though the website operator is not itself a provider of such services, then website security would fall back into the gap between those two definitions: prohibited by Article 2(1) but not then permitted by Article 6(1).
As a continuing sequence of security breaches demonstrates, website security is one of the most important ways to protect online privacy. A draft “e-Privacy Regulation” that could make it harder for websites to prevent, detect and deal with those breaches, needs to be sorted out before it becomes law.
#307 - Investigatory Powers Act – new orders to prepare for
Originally posted: 12 January 2017 in category
Articles
[UPDATE: I’ve added links to the
Codes of Practice
that authorities will use when preparing each of the orders]
Under the current
Regulation of Investigatory Powers Act 2000
(RIPA), organisations that operate their own private computer networks may receive three different orders relating to those systems. Any organisation that receives an order is, subject to feasibility, required by law to do what it says. The new
Investigatory Powers Act 2016
(IPA) adds some new orders to this list and provides a new basis for two of the existing ones.
Although it’s impossible to predict which of these orders may actually be directed to which (if any) organisations, or what requirements those orders may contain, it’s worth checking that you have the right processes in place, if you do receive one, to ensure it is handled promptly and effectively. Note that altering your systems to prepare, “in case” you receive one of these orders, is likely to breach data protection and possibly also interception law. It is also likely to forgo the opportunity in
s.249
to claim a contribution from the Government towards the costs of responding to any order that is subsequently received.
The orders are as follows:
To
disclose specified communications data
held by the organisation [currently
RIPA s.22
]: The existing power for the police and other authorities to order disclosure of information about the use of computers and networks is moved to
s.61
of the IPA. The current limitation that this can only cover information about the use of the systems the organisation itself provides has been removed. If the organisation holds information about the use of other, third-party, communications systems then that may also be subject to a disclosure order (s.61(5)(c)). [
Communications Data code of practice
]
To
intercept specified communications
on networks [currently
RIPA s.5
]: The existing power of the Home Secretary to authorise targeted interceptions is moved to
s.19
of the IPA. For investigations relating to Scotland, the relevant Scottish Minister can also exercise this power. [
Interception of Communications code of practice
]
To
retain or collect communications data
[NEW]:
s.87
of the IPA allows relevant Ministers to order any telecommunications operator to retain specific communications data for up to 12 months. This power previously only covered public network operators under, most recently, the
Data Retention and Investigatory Powers Act 2014
. The IPA extends them to anyone who controls networking or communications equipment (
s.261(10)(b)&(13)
). Nowadays that probably covers all organisations and most homes. Unlike the communications disclosure orders above, it appears (by s.87(4)) that data retention orders cannot cover third-party data. [there doesn’t appear to be a new
Data Retention code of practice
; this is the one used under the Data Retention and Investigatory Powers Act 2014]
To “
interfere with equipment
” [NEW]: under
s.99
of the Act, relevant Ministers may order any person (including organisations) to “interfere with equipment” in order to obtain either communications or information about the equipment. The Act gives examples of “monitoring, observing or listening to a person’s communications or other activities” and making recordings. [
Equipment Interference code of practice
]
To implement
specified technical facilities
to support future disclosure, interception or interference orders [NEW]:
s.253
of the Act allows relevant Ministers to order any telecommunications operator to “ha[ve] the capability to provide any assistance which the operator may be required to provide in relation to any [communications data, interception or equipment interference order]”. Under RIPA such orders could only be made against operators of public networks, and were apparently used to require them to maintain permanent interception capabilities. The IPA extends them to anyone who controls networking or communications equipment (
s.261(10)(b) &(13)
) and appears to cover a wider range of technical facilities. [technical capabilities are covered in section 10 of the
Communications Data code of practice
]
Most organisations will already handle RIPA s.22 communications data orders (most often to identify the person who was allocated a particular IP or e-mail address at a specified time) as a matter of routine. The other orders seem likely to be much rarer. Since they involve legal, technical, financial and operational considerations, and will often be subject to secrecy obligations, organisations’ processes should ensure that they receive appropriate consideration across all those fields.
#306 - UK e-Infrastructure Security & Access Management WG
Originally posted: 31 December 2016 in category
Publications
At the request of the Research Councils UK e-Infrastructure group, Janet established a working group from 2013-2016 to support those providing and using e-infrastructure services in achieving an approach that both protects services from threats and is usable by practitioners. More detail about the group can be found in the
Terms of Reference
.
Originally posted: 20 December 2016 in category
Publications
While some e-infrastructures included accounting in their design and operations from the start, others are now being asked or required to add accounting support to their existing systems. Typically accounting forms part of a relationship between the infrastructure and some other organisation – perhaps a funder, host or customer – rather than the infrastructure’s relationship with its individual users. These organisations may be interested in usage statistics across particular categories: for example by subject, by time, by project or by origin. It might be assumed that infrastructures already have enough data to generate these statistics retrospectively, as a result of their authentication, authorisation and security activities. However a closer examination indicates that these may not, in fact, be sufficient and that specific data, processes and agreements may be needed to support reliable accounting.
This paper uses accounting infrastructures’ experience to examine some of the situations where accounting may be required and the extent to which existing data may, or may not, support it. It then identifies some of the new issues that accounting requirements are likely to raise, and suggests questions for infrastructures that do not currently provide accounting to consider either when, or before, they are asked about it.
The
General Data Protection Regulation
contains one new right for individuals – data portability (Article 20). Some commentators have suggested that this is just a digital form of the existing subject access right, but the
Article 29 Working Party’s new guidance
describes something much more radical. Indeed, rather than data protection, the main purpose of the right is described as to “facilitate switching from one service to another, thus enhancing competition between services” (p.4) and “prevent[ing] lock-in” (p.5). This competition law issue is likely to concern only a small minority of vary large data controllers, but the Working Party appear to give it priority over a number of traditional data protection principles: data minimisation, control of personal data, and even security.
The new right entitles data subjects to request that digital personal data they have provided by consent or contract (note, not all the data that would be available under a subject access request) be provided to them or transferred to another data controller of their choice. Any receiving controller must apparently accept all the data, even if it has no use for it (p.10): reversing the usual minimisation rule that controllers should only process data they need. While data protection authorities have, in the past, required data controllers to spend hours redacting information about others before responding to subject access requests, now they “must not take an overly restrictive interpretation of the sentence ‘personal data concerning the data subject'” (p.7) and should include information about other individuals involved in transactions or relationships while (somehow) “implement[ing] consent mechanisms for the other data subjects involved” (p.10). Finally, the question “how can portable data be secured?” is only raised on the very last page of the document (p.15).
The Working Party encourage all data controllers to provide “download tools and Application Programming Interfaces” (APIs) to their computer systems, through which individuals can download or transfer their data online. While a very small number of data controllers (for example banks) may already allow users to view their account and transaction details on demand, for most organisations this information will be held on internal databases, securely firewalled off from the internet. Providing internet access into these databases will require a new and significantly more complex security model for these organisations. Each data subject will need their own account on this API; since the vast majority are unlikely to ever use it this will create a large number of idle accounts, likely to have simple or default passwords. Good security practice for many years has been to remove such accounts, not create thousands of new ones. Securely distributing passwords or stronger authentication credentials to all those remote users is another area known in security circles to be hard and error-prone for both organisations and individuals.
Many organisations – from Ashley Madison to TalkTalk – have recently and publicly demonstrated how difficult it is to set up and maintain access to user accounts. And those are large organisations whose core business is providing secure on-line services. Even if a data controller can manage that, there is a global criminal business sector dedicated to persuading users to give up their passwords. At present that is largely funded by stealing credit card and bank account numbers: how much more valuable (and damaging to the individual) would complete transaction histories be?
The competition problem identified by the Working Party seems to concern a very small number of data controllers. Evidence on the exercise of existing data subject rights suggests this one will be used by only a small proportion of data subjects. Data Protection Regulators should think very carefully before encouraging or requiring all the other organisations and individuals to expose themselves to those threats.
Originally posted: 19 December 2016 in category
Publications
After (too) many years, I’ve turned the ideas from my original
TF-CSIRT documents
into a formal academic paper, which has just been published in the open access law journal, SCRIPTed:
The new General Data Protection Regulation provides explicit support for the idea that protecting the security of computers, networks and data is a legitimate interest of organisations. That has recently been confirmed by the European Court of Justice in the
Breyer
case.
After discussing the need for incident response, the very diverse legal approaches that have been taken to it in the past, and the problems those have created for collaboration, the paper looks at the rules that data protection law applies when processing for a “legitimate interest”. This produces a framework for assessing the impact and benefit of security and incident response activities. Finally there are a series of practical case studies, suggested by various CSIRT teams, analysed against that framework. Reassuringly, the conclusion is that most current CSIRT practice – which is already designed to protect the security of sensitive information – also satisfies the requirements for privacy and data protection.
Thanks to everyone who has, knowingly or not, contributed to the final result.
#302 - EU proposes to reduce intermediary protection – but how much?
Originally posted: 7 December 2016 in category
Consultations
The European Commission recently published wide
proposals to reform copyright law
. One particular concern is that the proposals appear to reduce the existing legal protections for sites that host third party content. Under the current
e-Commerce Directive
, such sites are generally protected from liability until they are informed of allegedly infringing content (Article 14), and cannot be required to inspect content before it is published (Article 15).
Recital 38 to the
proposed Copyright Directive
suggests that some hosting sites will lose one or both of those protections. And it’s very unclear, from the draft wording, which sites will be affected. Those that “play an active role … irrespective of the means used therefor” seem to lose their liability protection, those that “store and provide access to the public … thereby going beyond the mere provision of physical facilities” or “stor[e] and provid[e] access to the public to large amounts … of subject-matter uploaded by their users” will be required to take proactive measures.
In our
submission
to the
Intellectual Property Office
, we’ve pointed out that whatever the intended scope of the restrictions is, such uncertain terms are likely to give a much wider range of hosting providers concerns about their legal position. Since organisations typically avoid legal uncertainty, it’s likely that unclear wording will result in the withdrawal or restriction of services that the law was supposed to continue to protect.
Originally posted: 1 December 2016 in category
Articles
At Jisc’s
Learning Analytics Network meeting
last month I presented an updated version of my
suggested legal model for Learning Analytics
. The new version adds the data collection stage(s) and seems to me – both as a sometime system developer and privacy-sensitive student – to provide the kinds of guidance, choices and protections that I’d expect universities and colleges to apply to student data.
Whereas learning analytics has sometimes been documented as a monolithic process, it seems to fit much better into data protection law if split into (up to) five separate stages:
Data Collection: using information the institution has already gathered about students as part of existing educational processes. Here rules and guidance on necessity and purpose limitation can help determine what data may be used for learning analytics purposes and how far those purposes may extend;
Data Donation (optional): in some cases students may be asked to provide additional information – for example reporting on their own study patterns. Rules and guidance on consent indicate what information students must be given and the rights they have to refuse or stop providing information without detriment;
Analysis: the stage where data are interrogated to discover relevant patterns, highlighting factors that may improve or hinder educational achievement. During this stage the aim should be to minimise impact on individuals and ensure that any remaining risk is justified, in accordance with rules and guidance on processing for legitimate interests;
Improvement (optional): where patterns can be used to improve educational provision in general, for example by adapting teaching materials or practices. Here there is no need to process personal data at all;
Intervention (optional): where patterns are used to identify and propose relevant actions for individual students. Here personal data must be used, and the aim is to maximise the (positive) impact on individuals. Thus consent for interventions is needed (unless they are, for example, a legal obligation) and this can be sought at the time when the organisation can give the most detailed information about the proposed intervention and its likely consequences.
It was good to receive feedback that this model was “reassuring” and, indeed, matched what many organisations already do in practice, even though their policies may describe the simpler, monolithic, model. The legal detail and resulting guidance can be found in a paper:
“Downstream Consent: A Better Legal Framework for Big Data”
, published in the Journal of Information Rights, Policy and Practice.
Although the final text won’t be published till that happens, the Parliamentary stages don’t seem to have made any significant changes to the powers in the
original draft Bill
. Most changes appear to be clarifications and modifications for the process of approving orders.
For Janet and its customers the most significant change is that the Government’s current powers to order public networks to retain communications data and provide technical measures to facilitate investigations have been extended to all “telecommunications operators”. This term is defined sufficiently widely to capture any network, including private networks between and within universities, colleges, businesses and homes.
The only example the Government has given of where this power might be used is if a cybercafe were to become a meeting-place for terrorists. That puzzled many telecoms lawyers who had understood from Ofcom’s rule of thumb that cybercafes were public networks already. It’s therefore impossible to predict whether the Government might decide to make an order against any of the much wider range of networks that are now within the scope of its powers.
Unless a network operator does receive such an order, any retention of data or inspection of content can only be done under existing legal permissions – typically limited to the operator’s own requirements such as protecting the network and its services. Increasing your logging or interception facilities just because of the new Act is likely to breach data protection and interception law.
Originally posted: 15 November 2016 in category
Articles
Although the Information Commissioner’s
“Twelve Steps to Prepare”
is an excellent guide to what organisations need to do in the eighteen months before the
General Data Protection Regulation
becomes
UK law
in May 2018, following them in order from 1 to 12 may not be the best approach. Some of the steps depend on the results of others, some are likely to take longer to achieve (in particular those that are new requirements, rather than adaptions of existing ones), and some may be easier once guidance is published by either the
Information Commissioner
or the
Article 29 Working Party
. This post attempts to use those factors to put the steps into a logical sequence for implementation.
Craig Clark of the University of East London has written an article on
setting up a GDPR project
. To lead this, organisations should identify their Data Protection Officer (ICO step 11) as soon as possible, even though the promised guidance from the Article 29 Working Party has not yet appeared. Identifying the relevant national regulator (ICO step 12) is another area where formal guidance is still awaited, though almost all Jisc customers seem likely to be subject to the UK Information Commissioner.
The first group of activities, on which work should probably have started already, contains the ICO’s steps 1 (Awareness), 2 (Information You Hold), and 10 (Data Protection by Design and Data Protection Impact Assessments). Awareness among senior managers will be essential to obtain support and resources. Knowledge of information flows is the starting point for most other steps. The process used to map flows will form a significant part of implementing data protection by design, so steps 2 and 10 are likely to benefit from being developed together. The Regulation’s stress on accountability means that documented processes to identify, analyse and protect new and existing activities will be a key part of demonstrating compliance. These processes should be well advanced by May 2018. Since they need to cover both internal development activities and external procurements, development and implementation are likely to require most of the remaining 18 months, so work should start now. Specific ICO guidance on Contracts and Data Controller/Data Processor relationships, and the Article 29 guidance on Data Protection Impact Assessments, can be incorporated when those are published.
As data flows and processing activities are identified, the ICO’s step 6 (Legal Basis for Processing Personal Data) can be applied. Changes to the definition of valid Consent (in
Recitals 42&43 and Article 7
) seem likely to lead to a reduction in the use of that justification, so other justifications in Article 6(1) may need to be considered.
Once the legal basis for a flow is determined, it will be possible to identify and implement the appropriate rules for steps 3 (Communicating Privacy Information), 7 (Consent), 8 (Children), 4 (Individuals’ Rights) and 5 (Subject Access Requests). The ICO’s
guide to Privacy Notices
is already available; further guidance on Individuals’ Rights and Consent is expected soon, with Profiling and Children to be covered later. The Article 29 Working Party are expected to provide guidance on the Right to Portability, which appears to be considered an aspect of the Subject Access Right, by the end of this year.
As a new requirement under the Regulation, step 9 (Data Breaches) should be borne in mind when mapping information flows. Wherever information is stored, organisations should ensure that they have processes and systems to quickly obtain the information that would be needed if a breach were to occur. Under the Regulation, all breaches will need to be recorded. However determining which breaches need to be reported to the regulator and which to affected data subjects will depend on regulators’ interpretation of “(high) risk to the rights and freedoms of individuals” (
Articles 33&34
). Although the ICO mentions “risk and significant/legal effects” as a topic where thinking will be developed, it appears that formal guidance may not be provided till later next year.
#298 - ECJ rules in favour of security and incident response
Originally posted: 26 October 2016 in category
Articles
The recent European Court case of
Breyer v Germany
provides welcome support for those who wish to protect the security of on-line services. The case concerned two questions – whether a website’s logfiles (typically containing time, client IP address, URL requested and result) constituted personal data and, if so, whether data protection law allowed the site operator to retain that personal data after the request had been completed.
The Court’s first conclusion – that logfiles indexed by IP address do constitute personal data – agrees with the view long expressed by the Article 29 Working Party, that service providers should treat IP addresses as personal data unless they know they are not. However the Court rejected two of the widest theories: that IP addresses are personal data merely because they allow an (unknown) individual’s activity to be collated, and that they are personal data merely because some third party can link them to the responsible individual. Instead the Court’s argument relied on the website operator’s ability to use a legal process (some equivalent of the UK’s
Norwich Pharmacal
order) to obtain the name of the user from their Internet Access Provider if required.
Having decided that logfiles were personal data the Court then concluded, nonetheless, that the website operator “may also have a legitimate interest in ensuring, in addition to the specific use of their publicly accessible websites, the continued functioning of those websites”, which could justify the continued retention of the files. Although the new
General Data Protection Regulation
(GDPR), to come into effect in May 2018, does recognise that “the processing of personal data to the extent strictly necessary and proportionate for the purposes of ensuring network and information security” (Rec.49) is a legitimate interest of a wide range of parties, current EU law is silent on whether anyone other than a network operator may process personal data to protect the security of their systems and services, while current German law explicitly prohibits it.
Declaring that protecting services is a legitimate interest does not give unconditional permission to process personal data – organisations still need to ensure that their actions are necessary, proportionate and not overridden by the rights of individuals – but these conditions are
very similar
to the precautions that incident response teams already take to ensure their activities protect, rather than harming, security. The
Breyer
judgment therefore provides a welcome “back-dating” of the GDPR’s re-assurance to security and incident response teams.
#297 - Downstream Consent: A better legal framework for big data
Originally posted: 18 October 2016 in category
Publications
Abstract
: Reconciling big data techniques with a legal approach relying on prior consent has proved difficult. By definition, when organisations collection personal information for data-led investigations they do not know what the results and impact of their processing will be. This paper suggests how other parts of the current European data protection framework can provide more effective protection for individuals, better guidance for big data users, and more effective tools for regulators. Splitting big data into collection, analysis and intervention stages, and applying appropriate legal provisions to each, could guide the development of privacy-respecting big data techniques that support the needs of individuals, businesses and society.
Published by the Journal of Information Rights, Policy and Practice
Neither question is straightforward. Blocking websites may not be the most effective way to deliver the
Counter-Terrorism and Security Act’s
objective of preventing people being drawn into terrorism. The Act itself recognises that that objective needs to be
balanced against HE providers’ duties to ensure free speech and academic freedom
. Even within the goal of helping students avoid or escape radicalisation,
other ways of using technology
– for example monitoring for and responding to patterns of risky behaviour rather than forcing such behaviour to take place out-of-sight – may be more effective. Or the risk may be better addressed by spending effort and money on human, rather than technological, approaches to the problem.
I suspect what HEFCE are actually looking for is evidence that providers have, indeed,
considered
these various balances in deciding on the approach they will take. HEFCE’s first note on Action Plans (page 3 of the
Advice Note
) asks whether “actions are appropriate to the provider’s own context” and warns that “providers should ensure that they have considered carefully what will work for their organisation”. This seems much more concerned with the process that has been used to determine each individual provider’s “overall strategy” than with whether any particular tools have or have not been adopted.
Originally posted: 31 August 2016 in category
Articles
The Board of European Regulators of Electronic Communications (BEREC) have now released the final version of their
net neutrality guidelines
, following a public consultation that received nearly half a million responses. These seem to have resulted in clarifications of the draft version, rather than any significant change of policy.
Jisc’s response
raised a concern that the guidelines appeared to prohibit permanent filtering of spoofed IP addresses. Such filtering is recommended internet good practice (see
BCP-38
) to address a security threat identified by BEREC themselves, that spoofed addresses greatly enhance the ability to perform denial of service attacks. The revised guidelines include a small change, apparently in response to this comment. Paragraph 85 now says [new text in capitals]:
85. [National Regulatory Authorities] should consider that, in order to identify attacks and activate security measures, the use of security monitoring systems by ISPs is often justified. In such cases, the monitoring of traffic to detect security threats … may be implemented in the background ON A CONTINUOUS BASIS, while the actual traffic management measure preserving integrity and security is triggered only when concrete security threats are detected. Therefore, the precondition
“only for as long as necessary”
does not preclude implementation of such monitoring of the integrity and security of the network.
This suggests viewing a router’s actions in blocking spoofed packets as continually monitoring for invalid addresses and only turning on the traffic management measure (to drop the packet) at the moments when such an address is detected. At a very deep technical level that is how it works, but it’s probably not how most people configuring firewalls or routers think about it! Nonetheless it’s good to have some response indicating, however indirectly, BEREC’s support for measures to protect networks against denial of service attacks. In preparing our response I also learned of a number of national regulators who are actively promoting BCP-38 compliance in their countries, which is excellent news.
Originally posted: 29 July 2016 in category
Articles
The latest
announcement from the Article 29 Working Party on the US-EU Privacy Shield
also suggests that there shouldn’t be any short-term surprises for those using the other justifications for exporting personal data to the USA. The European Court judgment that invalidated the Safe Harbor agreement in 2015 was concerned, among other things, with the level of US state access to EU citizens’ personal data. The Working Party noted that those concerns applied equally to other forms of transfer to the US, including Binding Corporate Rules (BCRs) and Standard Contractual Clauses (SCCs), and planned to comment on those in January 2016.
That commentary
never appeared
. Instead, as part of the Privacy Shield agreement, the US government has undertaken to limit its access and provide more opportunities for Europeans to obtain remedies. The Working Party has now said that it will review those undertakings in a year’s time, and report on their effect on all export mechanisms, not just the Privacy Shield.
The European Council has published the
text of the Network and Information Security Directive
recently agreed by its representatives and those of the European Parliament. This still needs to be “technically finalised” (in particular Recital and Article numbers will change, so I’ve not included them here) and formally approved by the Parliament; then Member States will have 21 months to bring it into force.
The Directive falls into two parts – national arrangements for improving the security of network and information systems, and duties on operators of socially important services that rely on secure network and information services. The definition of the latter has been shifting through the development of the Directive. This latest version splits them into two groups: “operators of essential services” and “digital service providers”. Interestingly different types of internet service appear in both groups.
The list of “essential services” is similar to the UK’s
definition of “critical infrastructure”
, though food seems to have been left out. Unlike the
original proposal
, there’s no mention of any public sector services. And whereas the UK’s definition says “communications”, the Directive specifies Internet Exchange Points, DNS Service Providers, and Top Level Domain Registries. Telecommunications providers are already covered by their own Directive so aren’t included here. Each Member State is expected to come up with a list of the operators of these services – a good thing as, as far as I can see, the definition of “DNS Service Providers” would actually extend all the way down the hierarchy and cover anyone running a resolver. I presume Governments will in practice impose a cut-off when developing their (finite) lists.
“Digital service providers” are of three types: “online marketplaces”, “online search engines” that aim to index all websites or all sites in a particular language, and “cloud services” defined in a way that appears to cover everything from Infrastructure as a Service to Software as a Service. The definition of clouds doesn’t appear to be limited to fully public clouds and Member States are specifically warned against developing lists of Digital Service Providers. However the duties imposed on DSPs are required to be proportionate to the risk that their services represent, which should reduce the impact on clouds with limited user communities.
The duties imposed on both groups are familiar ones: to “take appropriate and proportionate technical and organisational measures” to manage risks to the security of service and to report significant breaches to national regulators. However this Directive appears more explicitly focussed than others on the “continuity of service” aspect of security. The requirement to notify only applies where incident have “a significant impact” on continuity of service, taking into account factors like duration, number of users and geographical spread of the impact. Also, there’s no fixed timescale for reporting – it should be “without undue delay”.
The provisions on incident response teams seem to recognise that quite a lot of development has taken place while this Directive has been under discussion. There’s explicit recognition of existing national and international cooperation and that different sectors may well be covered by different incident response teams. The list of CERT functions is now much less prescriptive – the member states to whom this is addressed should all know what a CERT does by now!
Now that the General Data Protection Regulation has been completed, the European Commission is
reviewing the ePrivacy Directive
. This law was introduced in 2002 as part of the telecommunications framework, and it was recognised at the time that it was likely to be largely replaced by a future general privacy law.
That has taken longer than expected, and in the meantime technology has developed in ways that highlight the main problem of sector-specific law: defining the sector. The ePrivacy directive only covers telecommunications services so, for example, telephony providers are covered by it but internet telephony providers aren’t, while apps on your mobile phone can lawfully use location data in ways that the mobile network provider can’t (
Bird & Bird’s analysis
points out these and other inconsistencies ).
Our response therefore recommends two principles: that general privacy law (such as the GDPR) should be preferred, with sector-specific regulation only where there is a sector-specific problem; and that regulation should focus on privacy-harming behaviour, not on the specific technology that may currently be used to enable it. Otherwise inconsistent regulation, and inconsistent privacy protection, will continue to emerge as technologies and our use of them develop.
A new EU law, created earlier this year, requires public network providers to ensure “network neutrality” – roughly, that every packet be treated alike unless there are legitimate reasons not to. The Body of European Regulators of Electronic Communications (BEREC) has now published
draft guidelines on how this will be implemented
, in particular the circumstances in which network traffic may be filtered to protect the security of networks and services. Janet is a private network, so not subject to the law; we already operate as neutral a policy as possible in order to facilitate the use of the network for innovative teaching and research. However BEREC’s proposals affect us because security measures taken (or not taken) by public networks will affect the level of malicious traffic directed to Janet and its customers.
Overall the proposal shows a good appreciation of the sorts of hostile traffic that networks may need to deal with, and authorises most of the actions we would like networks to take. These are declared to be necessary and acceptable reductions in strict neutrality. However the guidance requires that filtering only be used temporarily, in response to a particular threat. That may be possible when dealing with threats
to
a network or its users, but some filtering is used to protect others
from
the consequences of local incidents. In particular, the Internet Engineering Task Force identified
filtering spoofed outbound packets
as best practice for all networks more than a decade ago. BEREC, too, regard spoofed addresses as something that should be filtered. However to provide effective protection, that filtering needs to be in place permanently.
Our
response to BEREC
, developed with the assistance of other members of GEANT’s CSIRT Task Force, explains why spoofed addresses are a security problem, and why filtering them permanently has no effect on network neutrality.
A few hours after the result of Thursday’s referendum on membership of the European Union, I gave a presentation on the significance of the EU’s
General Data Protection Regulation
, due to come into force in May 2018. That might seem a waste of time, but my suggestion was that the referendum result might in fact make the GDPR more important to us.
If the UK remains part of the European Economic Area, then we still have to comply with all EU laws: situation unchanged. But if we leave the EEA as well as the EU, then two particular aspects of the GDPR become significant. First is that, according to Article 3(2), the Regulation applies to organisations outside the EU whenever they process personal data of “data subjects who are in the Union” in relation to “the offering of goods or services … to such data subjects in the Union”. That clearly covers distance learning and other services we might offer remotely; it seems possible that it might also cover on-line recruitment of students into face-to-face courses delivered in the UK. In respect of those personal data, at least, the GDPR will still apply directly.
And so long as UK organisations wish to receive personal data from organisations located within the EU, there will also be a strong indirect incentive to comply. That’s because, under Article 44, the sending organisations must ensure that what would then count as “exports from the EEA” will not undermine the level of protection that the Regulation guarantees for individuals. When transferring to another member state, it is presumed that such “adequate protection” is automatically provided by that member state’s national law, but when transferring to a non-member state the presumption is that it does not.
Under the current Data Protection Directive a small number of non-EEA countries have obtained a declaration that their laws do provide adequate protection. In most cases this has required them to essentially implement the Directive in their own laws. The one country to try an alternative approach is the USA, whose Safe Harbor agreement was supposed to ensure adequate protection but was last year found by the European Court not to do so. A replacement Privacy Shield agreement is now being negotiated. If the UK did not obtain an adequacy declaration then organisations receiving personal data from Europe would need to provide both the protections that are the responsibility of the data controller/processor under current law, and those that are the responsibility of the state. The Regulation allows that to be done, as under the current Directive, through a contract incorporating model contract clauses. However following the Safe Harbor case it has been suggested that those clauses, too, need to be strengthened.
Far from going away, the GDPR could in future increase the requirements on us to protect personal data.
Originally posted: 22 June 2016 in category
Articles
With the number of data breaches still increasing, all organisations should be making plans for their response when, not if, it happens to them. At the FIRST conference,
Jeff Kouns of Risk Based Security
suggested learning from examples where the organisation’s response, or lack of it, had made the consequences of a breach much worse, both for the organisation and its customers.
The first lesson is to detect breaches quickly. This seems obvious, but the average length of time to discover a breach is still many months: one US financial institution took three and a half years to detect unauthorised access to its customer files. Not only does this delay give attackers ample opportunity to do lasting harm, but by the time the breach is discovered the organisation is unlikely to still have the information needed to work out what happened and how far the impact extended.
And when a breach is discovered, you do need to find out how it happened and fix the root cause. Failure to do so results in, at best, a steady trickle of increasingly bad news as new consequences are discovered. At worst you could miss the opportunity to fix a vulnerability when it exposed eighty-eight usernames and passwords, only to have it later exploited to access the personal data of more than two million people. Repeated data breaches look particularly bad.
Communication around an incident makes a big difference to how well or badly it turns out. Although we seem to be slowly understanding that it’s not a good idea to respond to vulnerability reports with legal threats, that seems still to be a depressingly common response to reports of security breaches. If you shoot the first messenger, the next person to find the vulnerability might be more willing to exploit it to cause real harm. When a breach happens, those affected will want to know what they can do, so don’t announce that you are turning off your telephone system because it can’t handle the load. And if you’re a regulated organisation (and under the General Data Protection Regulation we all will be from May 2018) talk to your regulator: they’re likely to be less sympathetic if they learn of your breach from someone else.
Shortly after the recent attacks on TalkTalk the Culture, Media and Sport Committee decided
to hold an inquiry into the circumstances surrounding the data breach
, but also the wider implications for telecoms and internet service providers. This raised a number of issues around the premature speculation around the causes of the incident, cybersecurity within the telecoms industry, and the role of encryption as a tool to protect personal data.
These are clearly issues of importance to Jisc, the Janet network, and our customers, and are topics that we have discussed in some length in blogs and other forums.
Our response to the inquiry is now available
. In total 28 submissions have been made to the inquiry from a wide variety of organisations.
#287 - Incident Response and Insurance: Opportunities to Collaborate?
Originally posted: 16 June 2016 in category
Articles
At the FIRST conference,
Eireann Leverett and Marie Moe
discussed a number of areas where incident response teams and insurers could usefully collaborate.
At present some cyber-insurance policies can seem expensive. One component of the cost is the contingency fund that insurers have to maintain in case their assessment of the likelihood and size of claims is wrong. In a new area such as insuring against digital incidents, a shortage of data means there may be considerable uncertainty involved in those assessments. That means large contingency funds, which contribute to high premiums. Many incident response teams have a lot of information about past incidents, which might help insurers reduce that uncertainty. For that to work, however, we need to be able to provide information about the cost of incidents, something that not all incident response teams collect. If you do have, or can obtain, that sort of data, Eireann and Marie would be happy to put you in touch with insurers who can use it.
That’s mostly about incident response teams helping insurers, but there may also be opportunities for insurers to help incident responders. Although there’s a tendency to think of insurance for rare, high-cost events, insurance companies also deal with relatively common problems – burst pipes, burglaries and similar. And – particularly when helping individuals, householders or small businesses – they often provide practical, as well as financial, help. When you make an insurance claim you’ll be put in touch with plumbers, carpenters, glaziers, or other local businesses that can resolve the immediate damage. It turns out that some insurance companies are already extending this to digital assistance: Eireann reported one instance of a small business insurance policy helping to remove ransomware from a customer’s computer. If that sort of help fits into insurers’ business models then it might be an alternative way to deal with things like virus infections as well.
Finally, it’s worth noting that just because your insurance policy doesn’t say “cyber” doesn’t mean it won’t cover accidents involving your computer. Policies for professional, business or household activities may not distinguish between those events taking place in the physical world or on line. Whether you’re buying a new policy or using an existing one, check the exclusions. If the worst does happen, your insurer may be worth a call.
Originally posted: 16 June 2016 in category
Articles
At the FIRST conference,
James Pleger and William MacArthur from RiskIQ
described a relatively new technique being used to create DNS domain names for use in phishing, spam, malware and other types of harmful Internet activity. Rather than registering their own domains, perpetrators obtain the usernames and passwords used by legitimate registrants to manage their own domains on registrars’ web portals. They can then create their own subdomains (for example badhost.realbusiness.com) and point them at the malicious hosts they control.
Subdomains registered in this way, known as “domain shadowing”, have a number advantages for the perpetrator. They may gain some credibility with potential victims from appearing to be part of a legitimate business. For incident response teams they may be harder to spot as the (original) registrant’s details are valid and the registered domain appears normal in terms of its lifecycle. RiskIO estimate that at least 27,000 registrant accounts have been compromised and used in this way. That’s a small percentage of the total number of registrants, but it seems that as much as 40% of malicious internet activity may involve shadowed domains at some stage.
Depressing to report, domain management passwords seem to be discovered in much the same ways as any others. They may be simple enough to guess, or obtained through phishing, or reused by the same person on some less secure site than a domain name registry. The password that gives control of your domain ought to be important enough to be long and complex, not reused on other sites, and only entered into websites with great care. Better yet, if your domain registry offers two-factor authentication, or other ways of validating that you are indeed the registrant when you request changes, consider taking up that offer.
#285 - Information Sharing: Learning from Social Networks
Originally posted: 14 June 2016 in category
Articles
Information sharing is something of a holy grail in computer security. The idea is simple enough: if we could only find out the sort of attacks our peers are experiencing, then we could use that information to protect ourselves. But, as
Alexandre Sieira
pointed out at the FIRST conference, this creates a trust paradox. Before I share my experiences of being attacked, I need to trust that those I share with won’t misuse or mishandle that information in ways that damage my security or reputation. One solution to that is to share anonymously, so the information can’t be associated with a particular victim. But if you are going to act on information that you receive, you need to trust the source that provided it, which is much harder if you don’t know who they are!
One way around this is to pass information through a third party, who can provide assurances about the source and quality without disclosing the identity of the source. That model is often followed by Information Sharing and Analysis Centres (ISACs), but it requires a well-resourced central point: one of the reasons why ISAC membership tends to have a significant price tag.
Alexandre proposed another model: that used by social networks. These manage to provide the reputation information that recipients need for trust, while at the same time giving contributors the level of anonymity they need. This relies on a couple of tools. First public feedback, so recipients can indicate the value they obtained from what was shared. This helps other recipients trust the shared information; it also helps the contributor (and others) work out what information their peers would find it useful for them to share. Second, because contributions can be identified as coming from the same source, over time the reputation of the source builds up, based on their previous contributions. This way people and organisations can come to trust one another (both as contributors and recipients) without needing to know their real world identities.
But social networks also suggest that even in a fully-trusting group, we shouldn’t expect universal sharing to break out. In any community of humans it turns out that some people share a lot more than others, and that there’s always likely to be significantly more information shared bilaterally than in an open (even though restricted entry) group. Observations across different communities seem to suggest that private/bilateral sharing naturally settles at about 80% of the total information exchanged.
And even a successful sharing community won’t provide all the information an organisation needs to protect itself. Comparison of different security sharing communities, together with commercial and open source feeds, suggests that there are far more threats out there than ever make it on to any of these lists. Even if you subscribe to all of these, there will still be occasions when you are the first to encounter a particular threat. Every organisation needs the skills to recognise when that happens, to protect themselves based on experiences obtained in sharing groups, and to help others by sharing in return.
In our evidence to these committees, Jisc is focussing on the new powers the draft Bill would give the Government to order “telecommunications operators” to prepare for future criminal investigations. In particular
The definition of “telecommunications operator” is much wider than the public electronic communications networks, “ISPs” or “CSPs” that have been covered by previous data retention legislation. It appears to include any organisation that operates a network, including businesses, universities, colleges and the Janet network itself;
Any such organisation could, in future, be ordered to implement “filtering arrangements” or “technical measures” to facilitate future warrants to obtain communications data or content respectively. These terms are neither defined nor limited by the text of the draft Bill, only examples are given. It appears that any technically feasible change could be ordered, affecting all communications through the systems, not just those that turn out to be the subject of warrants. If enhanced access to data or content is available it seems inevitable that it will be discovered and used by criminals, as has happened in the past. Orders that harm the intended function of the network or service (for example by making it less flexible or reliable) are permitted;
Organisations will be prohibited from revealing that they have received any type of order. This appears likely to prevent Jisc helping customers and law enforcement authorities, as we do at present, to develop efficient processes and safeguards for criminal investigations. More widely, it is likely to damage trust in all UK organisations falling within the definition of “telecommunications operator”, whether or not they have actually received an order.
When the Committees publish the evidence they receive, we’ll add links here:
Originally posted: 3 June 2016 in category
Articles
It’s relatively common for incident response teams, in scanning the web for information about threats to their constituencies, to come across dumps of usernames and passwords. Even if the team can work out which service these refer to [*], it’s seldom clear whether they are the result of current phishing campaigns, information left over from years ago, or even fake details published by intruders who want to inflate their claims. There’s little benefit in warning people of compromises of accounts or credentials that are no longer live, so how can teams work out which passwords are real and current?
The obvious approach would be to try to log in to the account, but under most legal systems that’s likely to constitute (attempted) unauthorised access. In some countries such access may still be lawful if the person’s intention is not malicious, but UK law doesn’t contain that defence.
Section 17(5) of the
Computer Misuse Act 1990
says:
Access of any kind by any person to any program or data held in a computer is unauthorised if—
(a) he is not himself entitled to control access of the kind in question to the program or data; and
(b) he does not have consent to access by him of the kind in question to the program or data from any person who is so entitled
That leaves two options. If (under clause (a)) the incident responder is “entitled to control access” – for example because the account in question is on one of their own organisation’s systems – then the attempted access should be authorised. Alternatively (under clause (b)) the team could ask the operator of the system for permission to test some accounts. Note that it doesn’t seem to be necessary to get the permission of the account holder to make such a test lawful.
Asking for permission to test every account would involve as much work as simply passing on all the account details, but fortunately that probably isn’t necessary. Since the initial purpose is simply to determine whether the collection of account information is accurate and up-to-date, testing just a handful of accounts or services should be enough. If most of those don’t work, then the information is probably old or inaccurate and can be treated as a lower priority. If most of the tests do work then it’s likely that the password information is fresh, and it’s worth passing on all the details to relevant service providers – often using the team’s automated systems for distributing warnings to affected parties – with the assurance that the information appears to be current.
In this way incident response teams can identify the most urgent threats and pass them on to those best placed to act to remedy them.
The European Commission has now published its
conclusions
from the
consultation on platforms
it carried our earlier this year. This included notice-and-takedown: an issue we’ve been working on for many years. When universities and colleges receive an allegation that information on their website breaks the law, they’re forced to choose between supporting free speech (a legal duty) or running the risk that the allegation will turn out to be true and a court will find them liable for continued publication. UK defamation law
removed this dilemma
in 2013 by allowing website hosts to seek a response from the author of the information and, if the dispute can’t be resolved, wait for a court to confirm whether the material should be removed or left.
Unfortunately wider EU law doesn’t allow that approach, and the current consultation seems to have produced no more than the possibility of further “consideration” in future of whether change might be needed. There are a couple of helpful points in the response, though. First, strong support for maintaining the current liability shield for information that websites aren’t aware of (a
recent Estonian case
had cast doubt on that). And – again something that the UK Defamation Act addressed – a recognition that websites’ attempts to remove inappropriate content shouldn’t automatically lose that protection.
On the main subject of the consultation there now seems to be a feeling that better enforcement of existing laws – including data protection, competition and consumer protection – may be sufficient to deal with most problems relating to on-line platforms. Where there are genuinely new problems, sector-specific legislation should be used, rather than an all-encompassing “platform law”. Since it’s still not clear which on-line services would have fallen within such a law, that sounds like a much better way to avoid legal confusion.
Originally posted: 4 May 2016 in category
Articles
More than a decade ago the
e-Privacy Directive
mentioned “location data” in the context of telecommunications services. At the time that was almost entirely about mobile phone locations – data processed by just a handful of network providers – but nowadays many more organisations are able to gather location data about wifi-enabled devices in range of their access points. The law (and our own instincts) treats location as a relatively intrusive form of personal data – though it’s not included within the formal category of “sensitive personal data” – so organisations are rightly concerned to handle it correctly.
Although the e-Privacy Directive’s location provisions formally only apply to users of publicly available telecommunications services (Art.2(c)), the Directive is derived from general data protection law so provides at least good practice guidance for private networks as well. The Information Commissioner has recently published advice on wifi location data, though three different types of use are covered in three different documents:
First a category that’s only mentioned in the Directive: location data that is traffic data (
Article 9’s
special rules only apply to “Location Data Other Than Traffic Data”). Where the location of the device is processed “for the purpose of the conveyance of a communication on an electronic communications network” (Art.2(b)) it can be treated in the same way as IP addresses and other traffic data. This would seem to cover things like knowing which access points a device is near in order to transmit its traffic from the best location. These are covered by the ICO’s general guidance on
Traffic Data
.
Then there’s a range of location-aware services that can be offered to the user. These could range from “where is my (lost) device?” to “where is the nearest helpdesk/printer/bus?”. Legally, these are still relatively straightforward as location data only needs to be processed for the devices whose users have signed up to the service. Information about the data and processing involved can be provided to users as part of the signing up process: the ICO’s guidance on
Location Data
suggests how organisations can ensure they have valid consent for this processing. In particular location data shouldn’t be processed for anyone who hasn’t signed up to the service.
Finally, some organisations are using the radio signals emitted by wifi devices to identify popular locations, how people move around an area, and so on. This is considerably more challenging from a legal perspective as it’s likely to capture and process locations of all live devices, including those that haven’t signed up to a service or connected to a network. Unless the system is only deployed in a physically secure area, it can’t even be assumed that all devices are carried by members of the organisation. As the ICO’s guidance on
Wi-fi Location Analytics
points out, the only way to inform individuals of this processing is likely to be through physical signs. With the only ways to opt-out of processing being to avoid the area or turn off your device – neither of which will be possible for some visitors – the ICO strongly recommends conducting a privacy impact assessment to ensure the activity can be justified, and using strong technical and organisational measures to protect all those affected by it.
I was a law student when I first came across learning analytics; the idea of being asked “do you consent to learning analytics?” worried me. From the student point of view it didn’t seem to offer me either useful information or meaningful control of what (unknown) consequences might arise if I answered “yes” or “no”. From the perspective of a responsible service provider it doesn’t seem to help much either: it doesn’t give me any clues what I
ought
to be doing with students’ data, beyond a temptation to “whatever they’ll let me get away with”, which almost certainly isn’t how an ethical provider should be thinking. Since learning analytics done well ought to benefit both students and providers, there ought to be a better way.
Looking at data protection law as a whole, a lot more guidance becomes available if we think of learning analytics as a two-stage process. First finding patterns in data, and then using those patterns either to improve our educational provision as a whole, or to personalise the education offered to individual students.
Considering the “pattern-finding” stage as a legitimate interest of the organisation immediately provides the sort of ethical and practical guidance we should be looking for. The interest must be defined, stated and legitimate (“improving educational provision” should satisfy that), our processing of personal data must be necessary for that purpose, and the impact on individuals must be minimised. Furthermore the interest must be sufficiently strong to justify any remaining risk of impact – if that balancing test isn’t met then that line of enquiry must stop. Practices that reduce the risk to individuals – such as anonymisation/pseudonymisation and rules against de-identification and misuse – make it more likely that the test will be passed.
Many of the patterns that emerge from this stage can be used without any further data processing: if correlations suggest that 9am Saturday lectures don’t lead to good results, or that one section of a course is particularly hard for students to follow, then we can simply make the necessary changes to course materials or schedules.
Other patterns may suggest that some types of student will benefit from more challenging materials, or from greater support, or from a particular choice of textbook or study path. For these the aim is to maximise the (positive) impact on each student, so a different approach is needed. Now we are “pattern-matching”: querying the data to discover which individuals should be offered a particular personalised treatment. And once a pattern has been identified and the appropriate response identified, then the organisation is much better able to describe to the student what is involved and what the risks and benefits might be. Now consent can give the student meaningful information and, if the offer is presented as a choice between personalised and standard provision, control as well. Seeking consent at this stage also feels ethically meaningful because it signifies an agreement between the student and the organisation to the switch from impact-minimising to impact-maximising behaviour.
A paper discussing the legal background to the model, and exploring some of the practical guidance that emerges from it, will be published in the Journal of Learning Analytics next month.
That began last October when the European Court of Justice declared that the US-EU Safe Harbor agreement could not be relied upon to protect the rights of data subjects to EU standards. Anyone using Safe Harbor (which only covered transfers to US commercial organisations) needed to move to an alternative. However it was quickly noticed that the Court’s arguments against Safe Harbor would also apply to the other export arrangements recognised by EU law – model contracts, binding corporate rules, etc. The Working Party, consisting of national data protection regulators, announced that they would review all these arrangements in February, giving the European Commission and US authorities three months to negotiate a better solution. Most Regulators (including the
UK’s Information Commissioner
) also indicated that they would not begin enforcement action against data exporters while that review was continuing.
Exporters might therefore have hoped that the review would clarify which export arrangements were still regarded as being compliant with EU law, and provide a clear deadline by which exporters need to adopt them. Instead the Opinion published yesterday provides a detailed analysis of the draft
Privacy Shield arrangement
that has been proposed by EU and US as a replacement for Safe Harbor. The Working Party conclude that the new proposal has “major improvements” over Safe Harbor, but that the Commission needs to provide greater clarity and solve outstanding problems before they will be able to determine whether it does indeed provide “essentially equivalent protection”.
There seems to be no comment on any of the other export mechanisms, nor any process or timetable for their status to be clarified. Exporters are left knowing that they should move away from Safe Harbor, but with uncertainty surrounding all the possible alternatives. They would no doubt agree with the Working Party’s statement that “legal clarity is needed sooner rather than later”, but this Opinion seems to extend, rather than reduce, the time we will need to wait.
The slides from our Networkshop session on
Learning from Software Vulnerabilities
are now available. All three talks showed how managing the process of finding, reporting and fixing vulnerabilities can improve the quality of software and the security of our systems.
Graham Rymer and Jon Warbrick presented a case study of discovering and fixing a bug in the university’s authentication system. Although the system is robust in areas that normally cause problems, examination of the source code identified two assumptions that might not always be true. In combination these could have been used to persuade a server to accept authentication messages with forged signatures. A detailed description of the problem allowed it to be fixed and deployed on university services in less than a week; assistance was also provided to other software developers known to use derived code. This quick response was possible both thanks to the quality of the investigation and report and because the reporter knew who to contact.
Giles Howard examined how an organisation’s policies and practices might help the discovery and fixing of vulnerabilities. How, for example, would reporting a vulnerability be handled under a university’s disciplinary or whistleblowing policies? Commercial software and systems providers increasingly provide guidance and incentives to research and report vulnerabilities in constructive ways: for example making test systems and accounts available or publishing the process that will be used when bugs are reported through the official channels. These could address reasonable management concerns about unmanaged testing of critical systems or the need to report some bugs to software vendors and depend on their response. This suggests an opportunity for universities to create a third layer of testing, between commissioned professional tests of critical systems and the random external “testing” to which any Internet-connected device is exposed. By recruiting interested students and guiding them to systems and times where managed testing is an acceptable risk the organisation could both improve the security of these systems – for which professional penetration testing may be unacceptably expensive – and give those students valuable practical and ethical experience.
Finally Richard Fuller described a project to review more than 17000 scripts that were present on the university’s web servers. No automated testing was available, but it turns out to be relatively simple to train students and staff to spot the main types of vulnerability (as identified by OWASP) in Cold Fusion code. Students and staff were recruited, trained, and one day a week declared “Code Review Day” to develop a feeling of teamwork. Around 80% of applications had at least one vulnerability but, thanks to other security measures, the vast majority were protected against exploitation. Those responsible were contacted and offered support, including an internal training course featuring both theory and practical exercises. As awareness spread within the university, other developers started asking for help and training as well. But deadlines were needed to ensure the necessary changes were actually made. “Fix code within two weeks or it’ll be disabled” turned out to be an effective way to identify scripts that were no longer used. It also produced many fewer complaints or consequences than the team had feared. As well as developer awareness and training, the university identified code review as a useful measure to reduce problems in future. This has the incidental benefit of ensuring that there are at least two people who know what code does and why, so should result in fewer “orphan” scripts in future.
The Dutch National CyberSecurity Centre has published
guidelines
and a
best practice guide
for managed vulnerability disclosure. These contain many ideas for policies and incentives to develop vulnerability discovery as a tool for improving security. I’d be interested to hear from anyone using these, or any other approaches to vulnerability management, in an educational institution.
When individuals register to access a website or other on-line service, it’s common to have to provide a significant amount of personal data. Some of this is to assure the service provider that you are entitled to access, some may be needed to deal with problems in future. Typically you are then issued with a unique password to access your account on that site in future.
Federated Access Management (FAM) (
introductory animation
) also provides service providers with assurances on entitlement and problem resolution, but with much less need to disclose personal data. Instead FAM introduces a third party, trusted by both the user and the site operator, to provide the assurances. This “identity provider” will often also handle user authentication – assuring the service provider that a valid username and password have been provided. For example a college may well act as identity provider for its students: having them login using their existing credentials and then confirming to the service provider both that their user has been authenticated and that they are a student, subject to the college’s disciplinary policies. This lets services significantly reduce the amount of personal data they collect and hold. If they need a unique account number for a user then this can be obtained from the identity provider: other information such as names or e-mail addresses need only be provided if the service actually requires them.
FAM under current law
Federated Access Management is recognised by regulators as a privacy enhancing tool. However the three-sided relationship between user, identity provider and service provider doesn’t obviously fit the models provided by European data protection law. Neither the identity provider nor the service provider satisfies the legal definition of a data processor. Where the user chooses which identity provider to use for a given service there may be no contract between the identity provider and service provider. Instead the arrangement is better viewed as an individual instructing two parties – each an independent data controller – to transfer personal data. This would normally fall within legal provisions for Consent (
Data Protection Directive
Article 7(a)), but if a student needs to access a particular service as part of their study then it is not clear that the consent can be freely-given, as the law requires. Conversely, although some authentication requests may be Necessary for the Performance of a Contract (Article 7(b)) this will not apply where an individual accesses resources that are not necessary for their course. One of the design goals of federated access was to prevent identity providers knowing which specific articles were being accessed and service providers knowing the identity of individual users. This means the only way identity and service providers could determine whether a particular request is “necessary” or “consensual” would be an additional exchange of information that both privacy technology and law were designed to prevent.
Instead, to avoid the complexities of applying different legal regimes to different requests, Research and Education federations in Europe have generally considered that both identity providers and service providers process personal data in their Legitimate Interest (Article 7(f)) of providing the service that an individual has requested of them. This allows each to focus on the relationship with their user, rather than having to collude to try to establish the appropriate legal regime for each individual request.
An additional benefit of this approach is that the Legitimate Interests justification requires additional safeguards for users, which are a natural match for the goals and practice of research and education federations. Federation rules generally require both purpose limitation and data minimisation: service providers may only request information they need to provide the service, and may not use it for any other purpose. Article 7(f) requires that personal data may only be processed if the legitimate interest is not overridden by the rights and interests of the individual. As
explained by the Article 29 Working Party
of national data protection supervisors, this requires a comparison of the benefits and risks of the processing. By configuring which user attributes are released to which service providers, identity providers can implement the necessary balancing test. In addition federations are developing
guidance on service provider categories
to help identity providers determine which services represent a high benefit and low risk to their users.
With many research collaborations being global in scope it is unfortunate that legitimate interests cannot, at present, be used as a justification for exporting personal data from the European Economic Area. Instead those identity providers that wish to provide federated authentication for their users to overseas services need to argue that these users have given consent. This is unsatisfactory both because the freedom of users to give such consent may be questioned and because the consent justification provides less guidance to responsible identity and service providers on the ways in which personal data may subsequently be used. Even with these legal issues, federated access management still provides significantly better privacy protection and policy enforcement than the alternative of individual users registering directly with overseas service or identity providers. For data protection regimes that encourage exporters to assess the risks and benefits of transferring personal data overseas, there is a strong argument in favour of federated access management as involving less risk to individuals’ rights than any of the alternatives.
The Regulation further strengthens the requirements for valid consent, making it appear an even less appropriate justification for activities that affect an individual’s study or employment. For example “consent should not provide a valid legal ground for the processing of personal data in a specific case, where there is a clear imbalance between the data subject and the controller” (Recital 34) and “consent should not be regarded as freely-given if the data subject has no genuine and free choice and is unable to refuse or withdraw consent without detriment” (Recital 32).
However the legal requirements for the Legitimate Interests justification still appear a good match for the objectives and practices of federated access management in research and education. In particular the idea of a legitimate interest in “doing what users request” gains additional support from Recital 38 that the balancing test should “tak[e] into consideration the reasonable expectations of data subjects based on the relationship with the controller”: where an individual has asked their home organisation to authenticate them to a website, they will indeed expect the organisation to do so! The use of pseudonyms separated from the user’s personal identity – something that is greatly facilitated and widely used by federated systems – is recognised as both “reduc[ing] the risks for the data subjects concerned and help[ing] controllers and processors meet their data protection obligations” (Recital 23a). Recital 23c explicitly seeks to “create incentives for applying pseudonymisation”: something federation policies, recommendations and technologies have done for many years.
Using federated access management across borders should become legally simpler under the Regulation. Under the current Data Protection Directive different European countries have significantly different treatment of the Legitimate Interests justification: some have created additional restrictions, others appear not to recognise the justification at all. Such variations should be reduced by the new law being a directly-applicable Regulation, as well as by a recent European Court ruling (
Case C-468/10
) that consistent implementation is essential if the law is to achieve its purpose of removing unnecessary barriers to the single market across EU member states.
The Regulation also offers the possibility of using the same legal framework for all national and international federated access, since Legitimate Interests appears for the first time (in Article 44(1)(h)) as a justification for transferring personal data outside Europe. As with other uses of Legitimate Interests the exporter needs to have assessed the risks and ensured that adequate safeguards are provided. According to the Article, the justification may be used for non-repetitive transfers involving a limited number of data subjects and where there are “compelling interests” in the transfer taking place: conditions that appear to be met at least for FAM services, such as platforms supporting research collaborations, that are used by a small number of staff or students at each university or college. Where an educational organisation procures a service, such as access to online journals, for the majority of its users then access management arrangements are probably better addressed as part of that larger contract.
The Regulation adds one extra requirement when using Legitimate Interests to export data: that the “controller shall inform the supervisory authority of the transfer” (Article 41(1)(h)). This should be feasible provided an identity provider (or perhaps even its national federation) can inform the supervisory authority of the general conditions under which such transfers will take place. If, on the other hand, the text were to be interpreted as meaning that every login attempt must be notified then this impractical requirement (for both identity providers and regulators!) would force international access management to fall back on options with fewer safeguards: either consent or direct use of overseas services.
Using the Legitimate Interests justification entitles individuals to raise concerns if their particular circumstances mean the processing represents a higher risk than was considered in the balancing test (Article 19(1)). Educational organisations acting as data controllers should already have processes to deal with such concerns. However since federated services should, in any case, only be receiving the minimum personal data they require to provide the service, a successful objection further reducing the information released is likely to mean the individual will no longer be able to use that service and will need to find an alternative.
Whether using Legitimate Interests for national or international transfers, the Regulation requires users to be informed of the release of information and the interests that it serves (Article 14). Federated services and identity providers already use a number of different mechanisms to provide information to their users so any additional information requirement should not be onerous. Federation operators have developed
recommendations for some aspects of user interfaces
– as requirements under the new Regulation become clear there may be an opportunity for further work to develop standards in this area.
Finally, under the Regulation the current requirement for data controllers to register with their national regulator will be removed. Instead controllers will be expected to maintain documentation of all their processing that can be provided to regulators or individuals on request (e.g. Article 28). Guidance and information from national federations on the privacy-protecting features of federated access management may well be useful in developing and supporting such documentation.
Roles & Implications
The technology used by most Research and Education federations transfers authentication data and other personal information about users directly between the identity provider and service provider. The principal role of the federation operator is to maintain the list of member organisations and the common legal and technical agreements to which they subscribe: something that does not require the operator to handle any personal data other than contact details for those responsible for each organisation’s membership. The main impact of the new Regulation will therefore fall on the organisations that act as identity and service providers or manage the databases of users that are the basis for those services.
Since the Regulation generally confirms the approach that has been taken by Research and Education federations, its entry into force (expected in 2018) is unlikely to require major changes. Once requirements on process documentation are clear, identity and service providers will need to check that they can provide what is needed. The possibility of using a single legal approach to national, European and international federated access should make this simpler. Using entity categories, whose risks and benefits can be documented by the federation operators that develop them, should reduce the need for identity providers to make assessments of individual services.
Where education organisations enter into contracts, either to provide content services or to operate technical facilities such as identity providers, the terms of these agreements should be checked to ensure they meet the requirements under the Regulation. This will also affect those federation operators who provide central identity provider services – commonly known as “hub-and-spoke” federations – since these do involve processing users’ personal data.
Otherwise the main task for federation operators will continue to be to develop tools and guidance that help their member organisations provide services that respect privacy and the law. Documented entity categories have already been mentioned; other opportunities may include advice on how to provide users with information about federated access management and identifying national regulators’ requirements for notification of exports.
Originally posted: 10 March 2016 in category
Articles
The Commission’s original draft Regulation included explicit support for the work of computer security and incident response teams, recognising that such activities were a legitimate interest that involved processing of personal data. Furthermore the legal requirements implied by using the legitimate interests justification (notably ensuring that those interests not be overridden by the rights and interests of the individuals whose data are processed) are a good match for existing and developing computer security practice (see my
FIRST talk
from last year). The
latest text of the Regulation
maintains that support (explicitly in Recital 39) and adds some helpful new features, though it still leaves some uncertainties.
The text recognises that using “pseudonyms” can “reduce the risks for the data subjects concerned and help controllers and processors meet their data protection obligations” (Rec 23a). Pseudonyms are defined as
processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information, as long as such additional information is kept separately and subject to technical and organisational measures to ensure non-attribution to an identified or identifiable person (Art 4(3b))
In security and incident response work, most of the identifiers used are pseudonyms, since an organisation looking at external IP addresses communicating with its own systems is highly unlikely to be able to attribute those to individuals.
When investigating attacks on their own systems, teams often discover the IP addresses of computers outside the EEA that are likely to be compromised. Since European law may consider such IP addresses to be personal data (as discussed below this is still uncertain) it is not clear whether informing their owners of the problem constitutes an unlawful export of personal data! To date, teams in the UK have at least had the Information Commissioner’s reassurance that it is acceptable to return personal data to where it came from. The Regulation now permits incident notification to be done on the same basis – legitimate interests – whether or not the affected organisation is in the EEA. However the latest text requires that supervisory authorities be informed when exports take place on this basis (Article 44(1)(h)). Regulators should be careful not to interpret this requirement in a way that makes impractical an activity that benefits everyone.
Unfortunately the latest draft fails to clarify two problems that were
highlighted in the original Commission version
. There is still no clear explanation of when information associated with IP addresses will constitute personal data and fall within the Regulation. Recital 24 merely warns of the possibility that “Individuals may be associated with online identifiers provided by their devices, applications, tools and protocols, such as Internet Protocol addresses, cookie identifiers or other identifiers such as Radio Frequency Identification tags”. With contradictory court rulings from several European countries on the status of IP addresses in log files it is likely that opportunities to prevent and mitigate privacy breaches will be missed because of uncertainty whether information sharing (particularly across borders) may breach data protection law. With ENISA finding privacy and data protection law the
most cited reason for not exchanging data between CERTs
, greater clarity and consistency would have been welcome.
Finally, the text is still contradictory on the status of national and Government CERTs. Recital 39 explicitly includes “public authorities” in its list of those for whom computer security is a legitimate interest, but recital 38 states that public authorities may not use the legitimate interests justification in the performance of their tasks. Using different justifications for different types of CERTs would
create barriers to information sharing between them
, so it important that regulators resolve this contradiction in a way that allows national and Government CERTs to maintain their position as trusted peers in national and international CERT networks.
Roughly what I said in my
Digifest
presentation yesterday
Since the
Prevent duty
, to help those at risk of radicalisation, was applied to universities and colleges there has been a lot of discussion of what role technology can play. The first thing to note is that, although there is a section on “IT Policies” in the
Home Office Guidance
, it’s only two paragraphs out of four pages. The rest covers the policies and processes that organisations should use to identify and help those at risk of being drawn into committing criminal acts, in particular planning or committing terrorist acts themselves or inciting others to do so.
Even those two “IT” paragraphs mostly cover policy and process: defining acceptable use and providing support for legitimate research. That leaves just a single sentence:
Many educational institutions already use filtering as a means of restricting access to harmful content, and should consider the use of filters as part of their overall strategy to prevent people being drawn into terrorism
On closer inspection, that seems odd. It’s talking about institutions that already use content filtering for other purposes, so have already bought the technology and implemented the policies and processes. But it still only says they should “consider” adding radicalisation to the list of harms to which the technology is applied. Why isn’t that obviously the right thing to do?
Here it’s important to remember the state of mind that Prevent is meant to address. The early stages of radicalisation usually involve a person feeling that an injustice has been done to some group they care about – “us” – and that “they” aren’t doing enough to resolve it. By the time this grievance has progressed to the stage of unlawful violent action it’s too late for Prevent: dealing with crimes is the job of the police and security services.
So how will someone with a grievance react if, when they try to find out more about their cause, they instead get a “prohibited content” banner? Some may go back to their studies, but others may conclude that the university or college has joined the conspiracy of “them”, and either do their researches on another network or use simple technical tools to conceal their activities both from the blocking system and from the organisation’s other logs. Now we have someone on campus who is one step closer to radicalised but whose activities no longer leave traces in our systems. HEFCE’s
Prevent Monitoring Framework
expects organisations to assess risks and take steps to mitigate them: the risk that inappropriate use of technical tools might make the problem worse should be something we consider.
Indeed HEFCE’s
Advice note
encourages educational organisations to consider “whether and how” to use filtering technologies. Questions that might feature in that consideration include:
Is technology more effective as a way to prevent radicalisation, or a source of signs when it might be occurring?
What information do we have on how to use technology for either of those purposes? As with signs of radicalisation in the physical world, patterns of behaviour seem more likely indicators than any single act.
Where might our digital systems already have relevant information? Might significant changes of behaviour show up in e-mail or DNS logs, or even just times of logins?
How are our users likely to react? Does the existing organisational culture view technical systems as protecting or threatening individuals’ interests?
Perhaps most important, how do we keep those at risk within the systems we have created to help and guide them, rather than driving them away? All our attempts to support individuals could be badly undermined if our technical actions mean they view the organisation and its systems as a threat rather than a trusted helper.
Ultimately, Prevent is about changing minds: helping individuals understand the difference between constructive and destructive ways of raising and addressing concerns. Technology alone is very unlikely to be able to do that, indeed it probably won’t even accurately identify everyone who needs that help. Only people can achieve the changes that Prevent tries to deliver: processes and systems must support them. Technology may have a small part to play in that but, as the guidance says, it must be part of a consistent overall strategy.
Originally posted: 3 March 2016 in category
Articles
The European Council of Ministers have now published a
proposed text for the General Data Protection Regulation
. This still needs to be edited by the Commission’s “lawyer-linguists” to check for inconsistencies, sort out the numbering of recitals and articles etc. But the working parties of both the Parliament and the Council have recommended that the resulting text should be adopted by the respective full bodies at meetings in the next couple of months.
Over the next few weeks I’ll be revisiting the four topics I considered when the European Commission first published its proposal back in 2012, looking specifically at the Regulation’s implications for some of the networked services provided by NRENs and their customers:
Links to those posts will be added here when they are published. Once the Regulation is passed, there will be a period of two years before it comes into force. During that time I hope regulators will be providing guidance to fill in some of the practical details. It seems likely that there will also be more activity on international transfers, following the
Safe Harbor case
, and on the e-Privacy Directive, which will be revised once the Regulation’s text is agreed. But there seems to be plenty in the current text to suggest how we may need to adapt our activities, and where we may already be ahead of the developments.
Originally posted: 29 February 2016 in category
Articles
The European Commission has now published draft texts that could be used to implement an
EU/US Privacy Shield
to replace the previous
Safe Harbor agreement
. It appears that the new scheme would only cover “commercial exchanges” of personal data between the EU and US so it is unlikely to be appropriate for export of personal data to US universities or non-profit organisations. As with Safe Harbor, those need to be covered by other approved export mechanisms such as model contracts or individual consent.
For the Privacy Shield to be acceptable as a means of transfer to US companies, it will first need to be approved by the Article 29 Working Party of European Data Protection regulators. They are expecting to report in mid-April. But, like Safe Harbor, their decision could still be challenged in the European Court of Justice, so legal uncertainty is likely to persist around any new mechanism for some time.
Any organisation exporting personal data, whether to the US or elsewhere, should aim to provide a
range of data protection measures
, rather than relying on any single one.
All three reports find problems, though the pattern has changed from four years ago when the predecessor Communications Data Bill was considered. In 2012 the most severe criticism came from the
Joint Bill Committee
: this time that Committee considers the Government is “
on the right track but significant changes are needed
“. The Commons Science and Technology Committee’s headline is that the “
cost of the Bill could undermine UK tech sector
“. But the most critical report comes from the
Intelligence and Security Committee
which, working at a high level of security clearance, should have the most information about the activities of the security services. They find aspects of the Bill “inconsistent and confusing” and comment “even those working on the legislation have not always been clear as to what the provisions are intended to achieve”.
The reports share many common features. All are concerned about the unclear definitions, picking out “internet connection records” as a particular problem. The unclear extent of powers “relating to the removal of electronic protection” and “equipment interference” is criticised: the Science and Technology Committee in particular note that this lack of clarity combined with the very wide range of organisations that might be subject to these powers could damage trust in the UK high tech sector as a whole. All Committees are concerned at the potential breadth of “bulk” powers and “class” warrants, doubting whether the case for such intrusive measures has been made. For the debate in Parliament to be meaningful they consider that the Codes of Practice, which the Government will use to implement the Bill’s powers, must be published alongside the Bill. Finally all are critical of the timescales, both for their reviews and also for the preparation of the draft Bill: the Intelligence and Security Committee say “it appears that the draft Bill has perhaps
suffer
ed from a lack of sufficient time and preparation”.
The Government does now have a fixed deadline, since the High Court ruled last July that
current UK data retention law was incompatible with human rights
and would be suspended from 31st March 2016. There are now suggestions that, to allow sufficient time to address the issues raised by the Committees, the Government might propose legislation extending that deadline separately from the full Investigatory Powers Bill.
Originally posted: 12 February 2016 in category
Articles
The Article 29 Working Party of European data protection supervisors
had hoped to make a full statement on the EU/US Safe Harbor agreement
at the end of January. However this has now been postponed, probably until mid-April. The European Court of Justice declared last October that the original Safe Harbor did not guarantee adequate protection when personal data were transferred from Europe to the USA. On 2nd February the European Commission
announced a Privacy Shield agreement
to replace Safe Harbor. The Article 29 Working Party will now
review the Privacy Shield
alongside other arrangements for exporting personal data from the EU.
Although this extends the period of legal uncertainty, the UK
Information Commissioner’s interim guidance
notes that “there is no new and immediate threat to individuals’ personal data that has suddenly arisen” and that organisations and individuals should not panic.
The first thing for businesses to do is take stock. Ask yourself what personal data are you transferring outside the EU, where is it going to, and what arrangements have you made to ensure that it is adequately protected. Then look at whether these arrangements are the most appropriate ones, taking into account the ICO’s guidance on international transfers.
Specifically on cloud computing, the ICO
expect that many cloud service providers wishing to provide services in Europe will be carrying out reviews of their contractual arrangements and the mechanisms underpinning any transfers of personal data from Europe in order to guarantee EU data protection standards for data in the cloud.
The final version of the Data Protection Regulation’s breach notification proposals has addressed many of my
concerns with the original draft
. Rather than applying the same rules to all breaches, notification is now concentrated on those where it will have most benefit: breaches likely to have a serious impact and those where prompt action by individuals can reduce the likely harm. The timescales for notification are more realistic, though they will still demand a swift and well-organised response by organisations that suffer incidents. Finally Article 79 gives a hint that reporting breaches and cooperating with the regulator should be recognised in any sanctions that may be applied – a useful incentive.
The Regulation takes a broad view of the harm that may be caused by a breach of information security, recognising the possibility that individuals may suffer “physical, material or moral” damage (recital 67) if their personal data are not taken proper care of. According to Article 4(9) breaches include “accidental or unlawful destruction, loss, alteration”, not just unauthorised disclosure of, or access to, personal data. Breaches that create a “risk for the rights and freedoms of individuals” need to be reported to the regulator “without undue delay” and an explanation must be provided if this takes more than 72 hours from the time the breach was discovered (Article 31). However there is a recognition in Article 31(3a) that it may take longer than this to determine the extent of a breach, so information such as the categories and numbers of affected data subjects and records may be provided in stages. The nature of the breach, likely consequences and steps taken and proposed by the data controller also need to be reported. There is also an explicit requirement on data processors to notify data controllers of any breach they experience (Article 31(2)). Whether or not they are reported, organisations need to keep a record of all breaches affecting personal data and how they responded (Article 31(4)).
Where a breach is likely to create a high risk to individuals – Recital 67a suggests this should be determined in cooperation with the regulator – then the affected individuals should also be notified (Article 32). No fixed timescale for this notification is given, though the Recital appears to recognise that notification is more urgent when it will enable individuals to do something to protect themselves. Information about such actions should be included in the notification. For situations where the data controller is unable to contact individuals or this would require disproportionate effort Article 32(3)(c) allows a public notice to be used instead.
The new Regulation, like sector-specific provisions in other European laws, is a welcome recognition that, in an environment where all organisations are under attack, notification is best used as a tool to help reduce the number and impact of privacy breaches, rather than to “name-and-shame” organisations that try to help their customers and peers. If punishment is required, that should be done using other powers in the Regulation.
Originally posted: 20 January 2016 in category
Publications
This document provides an introduction to the work of the UK e-Infrastructure Security and Access Management Working Group and the papers it has published.
Originally posted: 14 January 2016 in category
Publications
The various organisations participating in an e-infrastructure are likely to have their own policies on its use; harmonising those policies offers an opportunity to implement them more accurately, efficiently and effectively. This paper discusses how policies are likely to interact and how those developing policies can benefit from the coordination provided by using a common infrastructure.
Under the EU e-Commerce Directive once a host receives an allegation that third-party content is unlawful, the host may itself be liable if it does not remove or modify the content and the allegation is later found by a court to be true. The legally obvious course – to take down any material that is the subject of a complaint – causes particular problems for universities and colleges as they also have a legal duty to protect free speech by their members and guests. The UK’s
Defamation Act 2013
created a new process whereby hosting providers could have a court make a ruling on the legality of content before the host acquired any liability, however this only applies in the UK and only to claims of defamation.
Since the previous EU consultation didn’t result in an equivalent change to wider intermediary liability law,
our response
again suggests that this be done for types of material where the host cannot know whether the allegation of illegality is correct. The consultation also raises the idea of “notice-and-staydown” rules, where an intermediary would be required to prevent future re-publication. Various national courts have imposed such duties in the past, but they have been declared invalid by the European Court of Justice as having a disproportionate effect on the rights of both hosting providers and their users. We’ve also pointed out the very limited benefit of such a legal duty if it only covered re-posting of identical material, and the huge uncertainty that would be created if it were required to also apply to “similar” re-postings.
Originally posted: 17 December 2015 in category
Articles
The Higher Education Funding Council for England (HEFCE), as the body given responsibility by the Home Office for monitoring compliance with the Prevent duty in the higher education sector in England, has now announced how it will perform this responsibility. Full details can be found at the links to the HEFCE website below: the following is a summary.
The
monitoring framework
consists of two stages – an initial assessment in 2016 to ensure that Higher Education Institutions have policies that are fit for purpose, followed by ongoing monitoring thereafter.
The initial assessment begins with a self-assessment form that HEIs must submit by 22nd January 2016. The sample form in Annex C suggests this is an assessment of the organisation’s preparedness to perform the various duties contained in the
Home Office Guidance
, from D (no arrangements prepared yet) to A (arrangements in place, reviewed, approved and operating). Where responses are B, C or D an estimate of when A will be reached is required. Where a paragraph is considered not to apply (response E) a justification is required.
During the spring and summer of 2016 (deadlines vary depending on the HEI’s status) further evidence must be provided, consisting of copies of the organisation’s risk assessment, action plan and policies for external speakers and events. If not already covered by those documents, an additional report is required summarising arrangements for senior management oversight, student engagement, staff training, information sharing (about vulnerable individuals and external speakers), pastoral and chaplaincy support, use of computer facilities, engagement with student unions. Organisations may also provide statistics as evidence that these processes are in operation.
In the ongoing monitoring stage, from 1st December 2016, Governing Bodies will need to provide an annual report, including statistics, as evidence of continuing activity. HEIs will also be reviewed on a five-year cycle to check that their arrangements are up to date.
A
non-statutory advice note
contains a list of questions to help HEIs develop their risk assessment, action plan, policies and processes. Most of these refer to policies and processes, but there are five questions specific to IT systems:
Do IT policies set out what is and is not acceptable use of the provider’s systems for both research and non-research purposes?
Do IT policies include arrangements for managing the provider’s ‘branded’ websites or social media to ensure they are not used to promote extremist material or activities?
What factors were taken into account when considering whether and how to use filtering to limit access to harmful content?
Is there a process for identifying and dealing with breaches of IT usage policies?
What arrangements does the provider have in respect of websites and social media operated by students’ unions or societies
UCISA’s
Model Regulations
for the use of institutional IT facilities and systems may well be relevant to these discussions.
I’ve been a full or part-time student for more than thirty years. It’s interesting to reflect on how my student record has changed over that time.
In 1981 university administrators no doubt put my typed application in a paper file. Each year they’ll have added some exam results and, in due course, a copy of a graduation certificate. Since then the file has been consulted occasionally when I’ve applied for a job, or when the university sent an appeal to alumni. Much the same will have happened to any student record created in the previous fifty years.
The record that was created for me in 2011 is very different. Obviously it’s now digital, rather than paper, but the changes in its uses are even more striking. Nowadays the student record drives what I see every day on the virtual learning environment. And that changes at least every term, if not more often. We students now want new information, new applications, new support. And universities can provide them, indeed must, to match expectations set by the data-driven services we meet in our daily lives. If my music system can recommend things I’d enjoy, why can’t the college library? If my fitness targets can be monitored daily and compared with my friends’ then why can’t my progress through education use similar incentives?
Universities and colleges already have all the raw data needed to provide these services and many more. We all leave trails of “digital exhaust”: the many physical and on-line interactions between students and their institutions create a particularly rich source. Virtual Learning Environments and eBooks can record not just what I read, but how long I spend on each page. While students are on campus, systems already record which doors they unlock, which wifi access points they use, what traffic they send over networks. With
93% of students wanting immediate feedback
to confirm that they are still on the path to success, shouldn’t we use all these data?
Well, maybe…
How would you react if told “people who got good marks spent more time reading this article”? It may be technically possible, but is it helpful? Creepy? Nannying? Or outrageous? The answer probably doesn’t depend on what data are used: network usage information can identify both which wireless hotspots need more capacity in the evenings and who watched the football rather than studying. Sometimes indirect measurements can protect privacy – number of wifi connections is a much less intrusive measure of teaching space occupancy than CCTV – but reusing data can sometimes trip over a social taboo. When that happens, users may complain, provide false information, or withdraw from the system entirely. As too many organisations have discovered, perceived misuse of data is bad for your reputation and operations. Trust is really hard to rebuild.
So how can universities and colleges avoid falling into the same trap? Data Protection law provides basic guidance. We should inform people what their data are used for; stick to our own business (if data were collected for education, don’t reuse them for commerce); protect individuals’ rights (not just privacy, but non-discrimination, freedom of action, etc.; and not just students’ rights, either); and offer choices of whether or not to accept personalised interventions. But being lawful isn’t enough: lawful things can still be nannyish or creepy. Or irrelevant!
Using digital student records requires new processes, not least because by the time a student graduates their data will be used for things unimaginable when they started. Organisations need to collaborate with their students and staff to discover which applications of student data will be acceptable, and which will be useful. That may involve informal brainstorming sessions, as Jisc has used in deveolping a
student app
or stakeholder working groups like Jisc’s
Learning Analytics Code of Practice
. More formal Privacy Impact Assessments may indicate that an idea is suitable for general use, or that individuals should be offered a choice between personalised or standard treatment, or that the benefits simply do not justify the risks.
Keeping people informed how their data are being used and involving them in new developments, should demonstrate the benefits (and let us learn early if there aren’t any) and give confidence that risks are being minimised. It allows inaccuracies to be identified and corrected: particularly important when so much of the educational experience now depends on data. Digital student data can provide a better and more responsive educational experience, for today’s students and those who follow them. Working together should ensure those benefits are achieved.
Originally posted: 13 November 2015 in category
Articles
Some very interesting and positive messages came out of this week’s
Future of Data Protection Forum
. Interestingly the forum didn’t just focus on the draft European Regulation: partly because the final state of that is still unclear, but also because there was general agreement that reputable organisations shouldn’t aim merely to comply with data protection law. A reputation for using personal data responsibly is going to be a key business asset, which means that privacy and data protection people need to be involved in senior level discussions. Chief Privacy Officers/Data Protection Officers need to be able to propose business solutions, which will require knowledge of legal, ethical and engineering issues. In future the role isn’t going to be limited to handling Subject Access Requests!
The Regulation seems likely to favour self-regulatory schemes such as industry Codes of Conduct. However the recent case of
Schrems
has highlighted the risks of those – Safe Harbor is a self-regulatory scheme too. Organisations need to develop and support strong schemes, allowing regulators to recognise good practice rather than resort to compliance box-ticking. Schemes must include international transfers as these are essential for most EU organisations: if providing appropriate safeguards requires action at the political and diplomatic level then perhaps businesses should be making that case more strongly.
If organisations want to use personal data appropriately then Privacy Impact Assessments (PIAs) will play an increasing role. Again, these will not just be a compliance requirement, so they need to be built into project lifecycles like other risk management and security plans. PIAs should take place early, as soon as there is sufficient detail of a project to allow its privacy issues to be assessed and while it is still possible to adapt the project to include appropriate privacy-protecting measures. Scoping questions can be automated, and linked to data protection education – one organisation uses drop-down menus to let project planners identify likely risks and controls. More detailed discussions can be used to resolve competing issues.
The link between incident response and privacy was made very strongly. High-profile data breaches mean that customers and journalists, not just regulators, now expect organisations to detect and respond quickly and effectively. Senior managers now need to be able to explain their organisation’s security measures in public. A number of organisations have arranged ethical hacking demonstrations and incident response war games for their senior management teams: it’s no longer hard to develop plausible, scary scenarios. These should be used to explore hard decisions – do we need to off the website yet? Post-breach reviews can be extremely valuable if they are open and honest: “what can we do to stop that happening again?”, not “who was to blame?”. Mandatory breach notification should mean regulators can help industry sectors improve their security (see for example
ENISA’s work with telecommunications regulators
), but there was concern that some may not have the resources or skills to make effective use of the increased scope of reports under the new Regulation.
Finally, Big Data was identified as another area where an ethical approach might be more helpful than a compliance one. The Regulation has a particularly complex and unclear mesh of requirements on purpose limitation, data retention, rights of deletion/objection and profiling. Regulated sectors may add further overlapping duties from their own compliance responsibilities. Fortunately the Regulation also supports high-level approaches such as PIAs and Privacy by Design, which may help in navigating this essential area. The law makes clear that “because marketing” will no longer be an adequate justification; customers and society will increasingly be applying their own “creepiness test” to all our activities.
Originally posted: 11 November 2015 in category
Closed
The European Commission have recently announced a consultation into online platforms. Last month the
House of Lords EU Internal Market Sub-committee
invited submissions of evidence to inform the UK’s response.
Although the main focus of both consultations is competition issues, they do revisit the question of intermediary liability for third-party postings. At the moment EU law says that an intermediary – such as a website or social network – that makes available postings from third parties cannot be liable for any illegality that they are not aware of. Unfortunately the law is not clear whether simply alleging that a posting breaks the law is sufficient to remove that shield. As a result many hosts simply remove material as a matter of course when any complaint is received. That approach is less comfortable for universities and colleges, as it may conflict with their legal duty to promote free speech.
A couple of years ago, working with UCISA, we were able to get
a new form of intermediary protection
into UK defamation law. That allows an intermediary, if it wishes, to obtain a court ruling on the balance between the legal requirements, rather than having to make the choice itself. Our
evidence to the Lords Committee
cites that example and suggests that it would be helpful to include something similar, covering all forms of alleged illegality, in European law.
We also plan to make a similar response direct to the European Commission before the end of the year.
#262 - Draft Investigatory Powers Bill (first look)
Originally posted: 4 November 2015 in category
Articles
The Government has today published its
draft Investigatory Powers Bill
. There are 299 pages in the legislation alone, so for now I’ve been looking at the parts most likely to affect Janet and its customers. So far I’ve looked at a bit less than half of the Bill: further implications, if any, will be the subject of future posts.
For normal operations, there doesn’t appear to be much change. The rules that make it lawful for us to intercept our own networks (for example to debug problems) have been clarified/extended in a couple of areas:
Clause 33(3) covers “identifying, combating or preventing anything which could affect the telecommunication system” or anything attached to it. So things like intrusion detection, incident response and virus scanning are now clearly OK, even where the target of an attack isn’t the network itself;
Clause 33(2)(c) mentions “services or facilities aimed at preventing or restricting the viewing or publication of the content of communications transmitted”, so content or malware filtering doesn’t constitute an illegal interception.
Under the wording of the Regulation of Investigatory Powers Act 2000 (RIPA), the conditions applying to these depended on which types of filtering were for the benefit of the network and which for connected devices and people. If the Bill becomes law these will all be covered by the same provisions.
As with current law the Home Secretary (or the equivalent Scottish Minister) can issue warrants (clause 12) ordering the interception of particular communications on any telecommunications system.
The orders most familiar to network operators are those requiring the disclosure of communications data, under section 22 of RIPA. These will still exist, under clause 46 of the draft Bill. Clause 60 brings into law the existing practice (currently just Home Office guidance) whereby authorities must check their proposed orders with a trained Single Point of Contact, who can advise on practicality, proportionality, etc. In emergencies (for example where there is a threat to life) orders can be issued without this prior check.
Unfortunately the problem of definitions, which has plagued this area of law for more than a decade, hasn’t been resolved. Clause 47(6) defines an “Internet Connection Record”, which appears from the context to be a particular type of communications data whose disclosure can only be made in certain limited circumstances. My impression was that the wording was trying to say “full URL”, but others have read it as referring to DHCP/NAT logs! I very much hope this can be clarified. The other telecommunications-related definitions are in clause 193: my immediate impression is that the definition of “Communications Data” is just as opaque as the current RIPA definition, but does seem to have fixed the “anything else” problem that extends the existing definitions far beyond anything relating to the use of computers or networks.
Potentially the most significant change is an extension of the Home Secretary’s powers to order network operators to retain communications data. Under the current Data Retention and Investigatory Powers Act (and the earlier European Data Retention Regulations that were declared invalid by the European Court last year) those orders can only be made against *public* electronic communications services. The draft Bill replaces that by “telecommunications operators”, defined in a way that is likely to include any organisational or inter-organisational network, even those not available to the public. Although the types of data that can be covered by an order are reasonably clear (see clause 71(9)), it isn’t clear from anything I’ve spotted so far whether orders are limited to information that the operator already holds. The use of “retain”, as opposed to “collect” might suggest that it is, but previous laws have been more explicit. Whether this has practical significance for universities or for Janet clearly depends on whether a Home Secretary ever choses to issue a retention notice against us (Janet, in particular, has almost none of the communications data mentioned in clause 71). And it’s not something that needs action until such a notice is issued: keeping additional data in case you one day you receive a notice would be a breach of the Data Protection Act. But I’ll be keeping an eye on this provision in particular as the draft Bill is discussed.
Originally posted: 29 October 2015 in category
Articles
The Information Commissioner’s Office has published a new article on
how they are responding to the European Court’s Safe Harbor judgment
. The overall message is that data controllers should take stock and not panic. While noting that the judgment does remove some of the former legal certainty, the ICO is “certainly not rushing to use our enforcement powers”.
There’s an important reminder that the actual protection given to personal data isn’t changed by the judgment – “there’s no new and immediate threat”. Companies that gave undertakings under the Safe Harbor principles are still required by their US regulators to stick to those undertakings. That’s particularly relevant in the UK where the Information Commissioner encourages data controllers to make their own assessment of the risk of exports, rather than relying on others’ decisions. Although the ICO is working on updated
guidance
on how to do that, “for the most part it’s still valid” and the Safe Harbor undertakings can be taken into account.
While the legal position is likely to remain unclear till at least the end of January, when European regulators plan to review progress, it’s good to see our regulator recognising that both data controllers and data subjects are much better served by stability than any sudden changes of direction.
Originally posted: 19 October 2015 in category
Articles
The Article 29 Working Party of European Data Protection supervisors has now published its
response
to the European Court’s
ruling
that the US-EU Safe Harbor agreement can no longer be relied upon when exporting personal data from the European Economic Area.
Like the
UK Information Commissioner’s earlier statement
, they recognise that data exporters and US service providers will need some time to make alternative arrangements. The Working Party note that discussions between the EU and US authorities on a revised Safe Harbor are already taking place but say that if a satisfactory conclusion is not reached by the end of January 2016 then enforcement measures may be required. In the meantime, national Data Protection Regulators are expected to provide guidance on alternative measures that organisations exporting personal data may consider, if they are not already using them.
Originally posted: 14 October 2015 in category
Articles
[Updated to include UCISA Model Regulations]
After short debates in the Houses of
Commons
and
Lords
the legal duties on universities and colleges to address risks of radicalisation came into force on 18th September.
The
Government’s guidance
is unchanged from the
drafts published in July
. In last week’s debates the Government again stressed that measures should be proportionate and appropriate to the risks faced by individual institutions. The Minister confirmed that “many, if not most, universities are doing most of this already”; similar comments on further education have been made previously. This supports the view in the Guidance that “We do not envisage the new duty creating large new burdens on institutions”.
The debates highlighted three measures needed to deal with radicalisation:
Partnership among public sector bodies (through the regional Prevent coordinators);
Appropriate procedures and policies within organisations to handle concerns;
Individual awareness to identify signs of radicalisation.
Originally posted: 14 October 2015 in category
Articles
The European Court’s declaration today that the European Commission’s fifteen year old decision on the US Safe Harbor scheme is no longer reliable is another recognition that Data Protection requires continuing assessment, rather than one-off decisions. European regulators have been recommending for years that neither data controllers nor companies to which they export data should rely on Safe Harbor certification alone. The U.K. Information Commissioner has published a
guide to data controllers
on how to assess whether exporting personal data involves unacceptable risks. He considers such assessments an
acceptable way to satisfy the export requirements
(Principle 8) of the
Data Protection Act 1998
.
Janet and Jisc have always followed this approach in discussions with cloud providers – not relying on Safe Harbor, but seeking additional contractual and operational measures to protect personal data. We therefore believe that these agreements should continue to be a good basis for customers’ risk assessments in whatever regime may follow from today’s judgment.
Safe Harbor is already being reviewed by the European Commission and US authorities, with a new legal provision currently awaiting approval from the US Congress. The new Data Protection Regulation, expected to be agreed within the next year, will also alter the legal situation that the Court was considering. With these changes already under way it seems unlikely that the Information Commissioner will expect data controllers to change existing arrangements in the short term – certainly not before his office has had time to
review the judgment and its own guidance
.
[UPDATE] As information becomes available for each of Jisc’s agreements with cloud providers, we’ll publish it on the relevant group for each agreement:
#257 - Information Security and the Data Protection Regulation
Originally posted: 12 October 2015 in category
Articles
The new European Data Protection Regulation is relevant to many areas of our work. Yesterday I had the opportunity to look at its likely effect on information security at a Jisc
Special Interest Group meeting
. For now, we’re still working from the
three draft texts
published by the European Commission in 2012, the Parliament in 2014 and the Council of Ministers in 2015. There are many differences between them but some common themes can be spotted, which seem likely to appear in the final version. Some provisional conclusions can also be drawn from the areas where there are significant differences.
With regard to information security, the Regulation seems likely to promote known good practices. All three drafts require privacy impact assessments (already the subject of
guidance from the Information Commissioner
) and early consultation with data subjects, though they vary in which projects, systems and data these will cover. Data Protection by Design and by Default are less concrete requirements in the Commission and Parliament drafts: the intention appears to be to ensure that protection is considered at an early stage of design, and that approaches such as data minimisation and appropriate access controls are included. These measures should further discourage the idea of “adding on security” after systems have been built. All three drafts promote
incident response
and
breach notification
. Although the timescales proposed for useful notification seem optimistic, it’s good to see a general European law recognising the role of effective detection and response in protecting privacy.
On the other hand, some opportunities have been missed. The Regulation was supposed to provide a
consistent law across Europe
, but the Council text in particular offers at least as much scope for national variations as the current Directive. There is little recognition that the Internet creates both new privacy challenges and new privacy opportunities: the geographic location of the disks still carries much more weight in this 21st century law than the location of the system administrator. A bald statement that IP addresses are personal data will subject them to the same treatment and obligations as postal addresses, even though their characteristics are in fact very different. The legal status of low-level cloud services is not addressed – an absence even more regrettable following the recent
European Court judgment
that it does not matter whether an organisation knows that the bytes it is processing consist of personal names rather than recipes.
With the current trilogue process likely to produce a hybrid of what are already inconsistent texts, certainty that any particular on-line activity is “compliant” seems unlikely to be possible. A more realistic aim seems to be to assess and manage risks at an acceptable level, taking note of guidance and priorities set by the local regulator. Of course a risk management approach is something information security people should already be familiar and comfortable with.
#256 - Vulnerability Coordination – a maturity model
Originally posted: 28 September 2015 in category
Articles
Vulnerability handling – how organisations deal with reports of security weaknesses in their software and systems – is a field that has developed a lot in my time working for Janet. When I started most organisations received reports and fixed vulnerabilities on an ad hoc basis, if at all. Now we have
guidelines on policies
, ideas on
motivating researchers to report bugs
, even presentations on the
psychology of vulnerability reporting
.
The latest development is a
Vulnerability Coordination Capability Maturity Model
(CMM) from hackerone, setting out five areas where organisations need to prepare if they want to be confident of receiving and handling vulnerability reports: organisational, engineering, communications, analytics and incentives. Like most CMMs, each of these has a number of different levels – here basic, advanced and expert. Definitions of each can be found in the slides linked from the hackerone post, or there’s an on-line self-assessment. For full details of the required processes, the CMM references various ISO standards in the area.
Expert level – when an organisation will be able to extract information from trends in reporting, identify issues in development processes, etc. – seems mainly aimed at software vendors, since it presumes a steady stream of vulnerability reports. However basic level seems well worth considering even for organisations that only use, rather than produce, software. If someone finds a vulnerability in one of your on-line services, you want the problem to be reported and fixed. Even if you only pass the report on to the software vendor, a basic level of vulnerability coordination maturity will help you to assess the risks to your organisation, consider appropriate mitigation measures, and highlight the importance of a fix to your supplier.
We reiterate our view that there must be realistic alternatives to consent – for example ‘legitimate interests’ where the data processing is necessary to provide the goods or services that an individual has requested.
That supports the
approach we’ve adopted in federated access management
– that ‘legitimate interests’ provides both the most appropriate justification [for identity and service providers and the best protection for users. Indeed the ICO’s “necessary to provide the … services that an individual has requested” almost exactly matches my wording from last year!
The ICO’s comment about “alternatives to consent” also supports something that has been worrying me for a while. If you give consent a higher status than other justifications – as some data protection laws and proposals do – then you encourage data controllers to use consent when it’s not appropriate: for example when the processing is necessary for something the individual needs so they can’t give free consent anyway. Paradoxically, that actually weakens the protection provided by consent, because those less-than-free consents become legitimised. The common practice of having a single “consent” cover both necessary and optional processing is a good/bad example (“by registering you agree that we can send you advertising…”). Much better for individuals to have
necessary processing
dealt with under its own, appropriate, justifications, keeping consent for processing that really can be refused.
#254 - Disclosing personal data for criminal investigations
Originally posted: 27 August 2015 in category
Articles
The Information Commissioner has published updated and extended
guidance on the use of the Data Protection Act’s “section 29” exemption
, based on cases and wider experience. This exemption is often used to release personal information (such as computer or network logs) to the police or other authorities investigating crimes, so sections 33-52 in particular are worth reading as a refresher.
The points I’m most often asked about are:
The exemption only applies to crimes, not to civil legal proceedings (para 9);
It creates a permission to disclose personal data, not a requirement to do so (para 36);
It only applies if applying the normal DPA rules (e.g. not disclosing) would be likely to prejudice the prevention, detection or investigation of crime (para 37); “prejudice” must be “real, actual and of substance” (para 11) and there must be a “significant and weighty chance” of it occurring (para 13);
The exemption only applies to the extent necessary to avoid such prejudice (i.e. you can only disclose as much information is necessary) (para 37);
This needs to be assessed on a case-by-case basis, not as a blanket policy (para 10);
Disclosure doesn’t need to be requested by the authorities – a data controller can initiate the process if they consider the requirements are met (para 40);
Keeping records of disclosure and reasoning is a good idea (para 38).
Originally posted: 21 August 2015 in category
Articles
A question that comes up from time to time when discussing federated access management is “how can I rely on another organisation to manage accounts for me?”. Federation saves services the trouble of managing user accounts by instead delegating the job to an external identity provider, but it’s entirely reasonable to think carefully about that. Why should any service trust someone else to manage the keys to its valuable content?
In research and education federations, we have perhaps the best possible answer – that the universities, colleges and schools who act as identity providers use those same accounts, information and processes to protect their own systems. If the identity provider makes a mistake then its own data and systems are likely to be harmed at least as much as those of the service providers that rely on it. For most research and education service providers, that shared interest is likely to be sufficient. For the few providers whose service involves more risk than the identity providers’ own, that may need to be supplemented with something else (whether that’s additional checks on users, different means of authentication, or whatever your particular application requires).
But if, rather than “borrowing” a function that the identity provider is already doing in its own interest, you are asking them to do something specifically for you, then you have to fall back on one of the models used in the commercial world. Those seem to leave more doubt about whether you can rely on the provider to actually do as you wish:
The service provider could simply pay the identity provider for what it does. That’s a straightforward commercial transaction, but how do you (as service provider) know how much of the fee the identify provider is actually using to run the service you rely on? If the identity provider is commercially motivated, the answer is likely to be “as little as possible”, to maximise its own profit. How much of an incentive do they have to keep your business? Commercial confidentiality means you’re unlikely to know.
So maybe you try to increase that incentive by agreeing that the identity provider will be liable for any damage caused by their failure. You hope that will encourage them to do their job more diligently but, again, you don’t know how they will actually respond. Many organisations deal with liability by taking out insurance. Whether that requires the identity provider to work better will depend their insurer’s assessment of the risks, not yours. Or they may decide to “self-insure”, balancing the income from the contract, the cost of delivery, and the risk of getting caught. Liability may give you a better feeling for what losses you may be able to recover, but it still doesn’t give you much idea of the identity provider’s actual intentions or practice.
Or you can offer the identity provider its own interest in your success. That’s typically the bargain that supports “free” identity provision – the service provider gets accounts managed for it, the identity provider gets information about how those accounts are used. So long as the identity provider cares about the accuracy of the usage information that it receives, it should have an incentive to manage accounts properly. But individual users, who in this model are “
the product
“, may not be so happy about it. It may even encourage them to subvert the identity provider’s systems – the same ones the service provider relies on – if they don’t feel their interests are being protected.
So in the commercial world federation probably does come down to “trust”, but in R&E federations we can do better than that.
Originally posted: 12 August 2015 in category
Articles
Recently I had a thought-provoking discussion on Twitter (thanks to my guides) on the practice of setting your users phishing tests: sending them e-mails that tempt them to do unsafe things with their passwords, then providing feedback. I’ve always been deeply ambivalent about this. Identifying phishing messages is hard (see how you do on
OpenDNS’s quiz
), and creating “teachable moments” may well be a good way to help us all learn. But if what we learn is “can’t trust IT, they’re out to trick us” or “this looks like a phishing mail, but it’s probably only IT running another test” then it will have gone horribly wrong.
It seems to me that the difference between success and failure is going to be less about technology and much more about how the organisation treats the exercise. Whether you want to host a programme in house or use a commercial service, there are plenty of technology options available. So here are some very tentative thoughts on how we might make success more likely. I’d love to hear if anyone has tried these and whether or not they worked.
Fundamentally, the word “test” worries me. We all get plenty of phishing tests in our inboxes already. And some of us who are caught out by those will then report ourselves to the helpdesk. If we’re running an internal exercise, we ought to be doing something different: first motivating users to look out for phish, and second improving our ability to accurately distinguish phish from genuine e-mails. Shaming (either privately or publicly) those who fall for frauds doesn’t seem a great way to do either of those. Clearly they need to have training materials brought to their attention, but that can be done within the computerised part of the system (“you clicked on a phishing link, here’s how not to fall for it next time…”). So I wonder whether the organisation actually needs to know the identities of those who clicked at all? Statistics might well be useful, not least to see whether the organisation overall is reducing its risks, but might users view the exercise less negatively if we promise that that’s all we’ll collect? That does mean we can’t use the exercise results to target those who just can’t help clicking, but we can probably find them already in our helpdesk or system logs.
On the other hand we do want to recognise are the individuals who can quickly and accurately spot and report phishing e-mails, helping to keep both themselves and others safer on line. That behaviour is well worth rewarding, whether the phish they report are real ones or part of the exercise. Rewards – whether traditional chocolate or twenty-first century “
gamification
” – feel like a promising area to investigate. And if those rewards are public, then we need to support their recipients too. If we get the exercise right, then colleagues will be asking them “so how
do
you tell the difference?”. If that happens, then the exercises really have been a success, and maybe we won’t need to run them any more!
UPDATE: 2020. A news story about a
phishing test gone wrong
has added another thought. To be effective your test has to be accepted by all its recipients. If your “hook” is so outrageous that recipients tweet about it – either in admiration or disgust – then you’ll never know whether the late-comers actually detected it, or were forewarned on social media!
#251 - Prevent Duty for FE/HE: Current position (July 2015)
Originally posted: 28 July 2015 in category
Articles
With Parliament now on its summer break, the legal position under the
Counter-Terrorism and Security Act 2015
is unlikely to change till September. That makes this a good time for HE and FE providers in England, Wales and Scotland (the duty doesn’t cover Northern Ireland – see
s51(1)
) to review the guidance that has been published and plan what they will need to do to implement the duty when it comes into force for them (expected to be later in the year). It’s probably also a good opportunity to get in touch with relevant authorities in your area:
local Prevent coordinators
are working with HE & FE groups in some areas, police forces have Counter-Terrorism Local Profiles (CTLPs) that can be used to inform individual organisations’ risk assessments.
The Home Office have just re-organised their guidance published in March into
sector-specific documents
, covering FE, HE and rest of public sector (for whom the duty came into force on 1st July). Each exists in separate versions for England/Wales and Scotland, making six July documents in total, though most education providers will only need to concentrate on one of them. The July documents, which formally need to be approved by Parliament, add guidance on visiting speakers (
analysed in the Times Higher
), but otherwise just reproduce the already approved texts from March (with a couple of terminology changes) so work already done based on the March documents should still be valid.
For FE, though the legal duty under the new Act doesn’t yet apply, OFSTED have incorporated it into their inspection regime in England.
Detailed guidance
is available from them, and there’s also an extensive range of material available from the
Education and Training Foundation
. It seems likely that Wales and Scotland will require similar measures.
For HE, the legal duty won’t come into force until Parliament votes on this, probably in the autumn. The monitoring bodies for England and Wales haven’t yet been appointed, though in Scotland it appears that role will be taken by existing Contest Multi-Agency Partnerships. However the Home Office guidance refers to existing guidance from Universities UK on the
conduct of sensitive research
,
safe campuses
, and
visiting speakers
, as well as from the
Charity
and
Equality
Commssions. These should be reviewed as part of
organisations’ preparation
– in particular assigning high-level responsibilities, establishing contact with relevant authorities and starting on risk assessment.
We’ve been asked a couple of questions about the duty’s implications for ICT, which forms a small part of the Home Office guidance. The guidance emphasises that the duty builds on existing good practice and doesn’t seem to call for significant changes: if organisations already use filtering to protect users from other types of harmful material it suggests they “consider” whether this can also contribute to their Prevent duty, but there seems to be no expectation that organisations will start to use filters just for this purpose. There is a recommendation that the statutory duty be mentioned in IT Policies. Although I’ve not found any further guidance on this, it seems most likely that the duty would be one of the factors motivating organisations’ Acceptable Use Policies (AUPs), rather than a specific requirement on individual users. Many AUPs state their purpose as ensuring that ICT services are used to further the organisation’s education and research purposes, and in accordance with the law. In this context it might be advisable to refer specifically to the organisation’s new legal duty to “have due regard to prevent people being drawn into terrorism”.
Originally posted: 20 July 2015 in category
Articles
There’s a tension between network neutrality – essentially the principle that a network should be a dumb pipe that treats every packet alike – and network security, which may require some packets to be dropped to protect either the network or its users. Some current attacks simply can’t be dealt with by devices at the edge of the network: if a denial of service attack is filling your access link with junk then nothing you do at the far end of that link can help. Other security threats, such as phishing websites, could in theory be dealt with separately at every endpoint but it’s much more efficient, and less error-prone, to do it in a smaller number of more central locations.
Attacks involving address forgery
can only be detected at points within the network where it’s apparent that the traffic is coming from somewhere it shouldn’t be.
Fortunately the
draft Open Internet Regulation
that has just been agreed by the European Parliament, Commission and Council seems to recognise the need for a balance. The Regulation’s aim is “to safeguard equal and non-discriminatory treatment of traffic in the provision of internet access services” (Article 1(1)), but recital 9aa recognises that exceptions may be required “to protect the integrity and security of the network, for instance in preventing cyber-attacks through the spread of malicious software or end-users’ identity theft through spyware”. Article 3(3)(b) therefore permits a network provider to “block, slow down, alter, restrict, interfere with, degrade or discriminate between specific content, applications or services, or specific categories thereof” where this is necessary to “preserve the integrity and security of the network, services provided via this network, and the end-users’ terminal equipment”.
The Regulation raises one interesting issue, by saying that such restrictions are only permitted “for as long as necessary”. That might suggest that security controls should only be turned on after an attack has been detected. For attacks that vary, including many denial of service attacks, that’s probably right: until the attack starts you don’t know which traffic needs to be blocked. However for things that are always bad, like address forgery and phishing pages, it may be more effective to use a permanent, relatively dumb, filter that can stop the first bad packets too. A permanent filter may also involve less processing of process personal data (as required by Article 3(4)) as it doesn’t need to inspect traffic to determine when it needs to turn itself on.
Janet and other private networks aren’t formally covered by the draft Regulation but, as the
Janet Security Policy
makes clear, neutrality is even more important for us as it’s essential for the research and innovative uses that are the reason for having the network. Even so, sometimes we do need to install limited restrictions (e.g. last year on
NTP packets used for denial of service attacks
) to protect the network or its customers. So it’ll be interesting to see how national regulators strike the required balance between network openness and network security.
#249 - A Data Protection Framework for Learning Analytics
Originally posted: 15 July 2015 in category
Publications
Since becoming involved in
Jisc’s work on learning analytics
, I’ve been trying to work out the best place to fit the use of students’ digital data to improve education into data protection law. I’ve now written up those thoughts as a paper, and submitted it to the
Journal of Learning Analytics
. As the abstract says:
Most studies on the use of digital student data adopt an ethical framework derived from human-studies research, based on the informed consent of the experimental subject. However consent gives universities little guidance on the use of learning analytics as a routine part of educational provision: which purposes are legitimate and which analyses involve an unacceptable risk of harm. Obtaining consent when students join a course will not give them meaningful control over their personal data three or more years later. Relying on consent may exclude those most likely to benefit from early interventions.
This paper proposes an alternative framework based on European Data Protection law. Separating the processes of analysis (pattern-finding) and intervention (pattern-matching) gives students and staff continuing protection from inadvertent harm during data analysis; students have a fully informed choice whether or not to accept individual interventions; organisations obtain clear guidance: how to conduct analysis, which analyses should not proceed, and when and how interventions should be offered. The framework provides formal support for practices that are already being adopted and helps with several open questions in learning analytics, including its application to small groups and alumni, automated processing and privacy-sensitive data.
As a current student and (twice) alumnus, I prefer to think that my own data will be handled according to these ideas, rather than on the basis that I gave informed consent mumble years ago.
The paper was published as Cormack, A. N. (2016). A Data Protection Framework for Learning Analytics.
Journal of Learning Analytics
,
3
(1), 91–106.
https://doi.org/10.18608/jla.2016.31.6
#248 - Data Protection Regulation – now there are three
Originally posted: 25 June 2015 in category
Articles
After more than three years of discussion, all three components of the European law making process have now produced their proposed texts for a General Data Protection Regulation should look like. The
Council of Ministers’ version
published last week adds to the
Commission’s 2012 original
and the Parliament text (
unofficial consolidated version
) agreed last March. EDRI have a helpful side-by-side
comparison of the three versions
. Data Guidance note
significant differences between them
, particularly on how prescriptive European law should be and how much its obligations may vary between organisations and countries. Representatives of the three bodies have just started a ‘trilogue’ process to develop a single agreed text. Although participants seem
confident that this can be achieved before the end of 2015
, commentators are less optimistic. Once a text is agreed, it’s likely to be around two years before it comes into force.
This seems a good time to revisit the
comments I made
in 2012 on how the original Commission proposal might affect three services of particular interest to the Jisc community: incident response, federated access management, and cloud computing.
On
incident response
, the news is mostly good. All three versions retain Recital 39 stating that protecting computers and networks is a legitimate reason for processing personal data, subject to appropriate safeguards (as I explained in my
presentation last week at the FIRST conference
). The Parliament adds limiting abusive access and use as a legitimate purpose, the Council adds fraud prevention and, probably more controversially, direct marketing. Under the Commission and Parliament texts, most incident response teams will also be able to use the same justification for including data such as IP addresses in reports sent to teams outside Europe (Art.44(1)(h)); the Parliament text would require some other justification to be found. And none of the three allows “legitimate interests” to be used by “public authorities in the performance of their tasks/exercise of their duties” which may
create a problem for Government teams
(Art 6(1)(f)) and those who wish to exchange data with them.
Access management federations
in Research and Education have tried to encourage service providers to use privacy-protecting identifiers, rather than names or e-mail addresses. However under the current Data Protection Directive there is
little legal incentive
to do this. Both the Parliament and Council texts try, in Article 10, to create an incentive to use pseudonyms where possible: the Council version is clearest, stating that duties including subject access and the right to be forgotten will not apply in these cases, unless a data subject can provide proof of their identity. As for incident response above, the Council and Commission texts would allow federations to use the same legal basis when accessing services both inside and outside Europe, the Parliament text would not. However one of the major benefits for access management – that the use of a Regulation would lead to more similar laws in different member states – seems to have been put at risk by the Council text which
allows national variation in as much as a third of the Regulation
. Indeed the former Commissioner who originally proposed the Regulation commented that the
Council risked turning it into a Directive
.
For
cloud computing
the main benefit of the Regulation would have been more consistency of national laws: something that now seems in doubt. All drafts follow the Commission in extending the Regulation’s scope to services outside Europe that offer services to individual European consumers (Art.3(2)(a)), thus making all consumer cloud services subject to European law. However there appears no resolution of the difficulties of fitting lower level cloud services, such as Platform as a Service and Infrastructure as a Service, into the legal regime (comments from Council members indicate that they were aware of these problems but did not find a solution – see footnotes in the
EDRI comparison
). For example if such clouds are considered to be “processing” personal data at all it seems that they will need to know what kinds of data are being processed, in order to fulfil a duty to provide appropriate security measures, even though an IaaS provider trying to determine the meaning of bytes processed on its equipment would itself be a significant privacy breach.
#247 - Data Protection: picking the right justification
Originally posted: 25 June 2015 in category
Articles
There’s no doubt that some parts of the UK Data Protection Act and the EU Data Protection Directive are badly out of date and need revising. The world they were drafted for in the early 1990s has changed. One area that has worn much better is the six
justifications for processing personal data
: those still look like a comprehensive set of permissions, each containing the necessary protection for individuals whose personal data whose personal information is processed under them. The justifications still appear to me to cover any legitimate data processing activity, with little overlap between them. The fact that the protections are tailored to match the justifications is significant, because it means that if you use the wrong justification then you may well be applying the wrong protection too.
I doubt that the justifications occurred to the drafters in the order in which they appear in the Act and Directive, and I think their operation is clearer if they are presented in a different sequence, as three pairs:
First are the two situations that the drafters already knew about and where the required protections were already clear: “necessary in the vital interests of the data subject” and “necessary for the purposes of a contract”. Here the data subject is protected by the narrow definitions of vital interests and contract, and the fact that any processing must be necessary for those ends. Anything that isn’t necessary can’t be done under these justifications;
Then there’s a pair of justifications where the original drafters left space for later legislators and regulators to adapt to new situations: “necessary to fulfil a legal duty” and “necessary in the public interest”. These are sometimes seen as applying respectively to the private and public sectors. Creating legal duties and declaring public interests is what parliaments and governments do, so the activities permitted under these justifications will change in time. But data subjects are still protected by the “necessary”, and parliaments and governments may (and do) add additional protections at the time they create the new duties or public interests;
Finally there’s a pair of justifications that allow data subjects and data processing organisations to declare new purposes: “consent” and “necessary in the legitimate interests”.
Consent appears particularly wide, because it’s the only justification that isn’t limited to “necessary” processing. However even where data subjects consent, they are protected by the requirement that their consent must be “free and informed”. The Information Commissioner has noted that is “not particularly easy to achieve”. In particular, the requirement that consent be freely given means, I think, that it can’t be used if any of the other five justifications apply, because if processing is “necessary” then it’s unlikely that I’m really free to give or withhold my consent to it;
“Legitimate interests” also appears wide but again is constrained by “necessary”. In addition it is the only justification that is explicitly limited by the fundamental rights of the individual. So, as the
Article 29 Working Party
have recently explained, every use of “legitimate interests” involves a balancing test, which will often mean that processing that is both necessary and for a legitimate purpose is still prohibited because it involves too great an interference with the individual’s rights.
As the Article 29 Working Party’s
Opinion on Consent
notes (on page 8), some processes will involve different activities to which different justifications apply. It may well be that core parts of a process are subject to one of the “necessity” justifications while optional extras are covered by “consent”. So when you are considering processing personal data look at all six of the justifications, pick the right ones, and ensure that you apply the matching privacy protection measures. If you find you have to stretch the definition of a justification to fit your application then you’ve probably chosen the wrong one (or your processing may not be legitimate!). Stretching the definition is also likely to involve stretching the protective measures, quite possibly weakening the protection they are supposed to offer to individuals.
#246 - Crisis Communications for Incident Response
Originally posted: 25 June 2015 in category
Articles
Scott Roberts of Github gave an excellent talk on Crisis Communications for Incident Response. If you only follow up one talk from the FIRST conference, make it this one: the
slides
and
blog post
are both well worth the time. So this post is just the personal five point plan that I hope I’ll remember to re-read whenever I’m involved in communicating around an incident:
Be Clear
: You’re explaining to semi-technical and non-technical people. Style should be “Fifth-grade level” or, for the international audience, early Harry Potter. Stay consistent across all messages and media. Don’t try to name the attacker – it doesn’t help.
Be Timely
: Which doesn’t mean sooner is better: if you have to send a continuous stream of corrections/amendments, then you look confused. Revising upward the scale of an incident isn’t good. Nor is being so slow that
Brian Krebs
reports the incident before you do.
Be Actionable
: You need to tell people clearly what you are doing to remediate the problem and to protect users, how they can determine if they are affected and what they need to do if so.
Be Responsible
: Admit what went wrong, show you understand, say sorry. It’s worse to pretend you are in complete control and things still went wrong, than to admit you made a mistake. But don’t over-apologise, so you need to work with security, PR, legal and customer support to get this right.
Be Human
: You want recipients of your message to empathise with your plight. That won’t happen if your communications are written in legalese or jargon, or by a committee. Getting feedback to correct errors and clumsy wording is fine, but try to stick to a single author as far as possible. And before you send it, read it again, and again out loud.
Originally posted: 24 June 2015 in category
Articles
Thanks to recent work, particularly by the
Dutch National Cyber Security Centre
, the processes that result in successful discovery and reporting of software vulnerabilities are reasonably well understood. For those processes to work, though, potentially tricky human interactions need to be negotiated: discoverers don’t know whether they will be regarded as helpers, criminals or sources of offensive weapons; organisations distributing or using vulnerable software need to resist the urge to shout at the researcher who has just found a crack in their prized possession. Eireann Leverett and Marie Moe
discussed their own experiences
as, respectively, security researcher and vulnerability coordinator at last week’s FIRST conference.
As in any interaction between humans, the first few exchanges are critical to establishing a successful relationship. Both sides need to make their professionalism and expertise clear, as well as determining that both have something to gain from continuing the conversations. In the security community, responding promptly and making proper use of encryption are important signals. If I send you an encrypted message and you reply in clear text, you’re putting your reputation and, perhaps, my safety at risk, not just the message content. But it’s also important to get the human issues right – a reporter who just says “these systems are vulnerable” without giving the recipient sufficient information to discuss the severity of the vulnerability with system owners, or a recipient who doesn’t provide regular positive (or negative, if appropriate) feedback can easily, and probably unintentionally, create the impression that the conversation is a waste of time. The aim should always be to provide information that can, and will, be acted on. Reporters expect to talk to someone with both technical security expertise and authority – if the initial contact comes to the wrong person in an organisation, it needs to be passed on quickly or else the opportunity to fix insecure systems may be lost. Offering a face-to-face or telephone meeting shows that you are taking the issue, and the other party, seriously.
Once trusted communications have been established and the initial information exchanged, a professional reporter may be able to provide more help. The appropriate process was characterised as “assisted discovery”: the affected organisation needs to establish the severity and appropriate response for itself, but the reporter can help them to avoid jumping to conclusions (either over-optimistic or over-pessimistic) and to identify the appropriate remedy. A researcher who has discovered a vulnerability will often have a good idea where traces of others exploiting that vulnerability might be found or what temporary measures might mitigate it until a permanent fix is deployed. These discussions may well follow different paths (and take place at different emotional levels) depending on whether the report is of a vulnerability that might cause problems for the organisation, a compromise that already is causing it problems, or a security issue (for example a website serving malware) that the organisation is causing for others. But when a reporter wants to “make us a success story”, organisations should do their best to oblige.
At the FIRST conference this week I presented ideas on
how effective incident response protects privacy
. Indeed, since most common malware infects end user devices and hides itself, an external response team may be the
only
way the owner can learn that their private information is being read and copied by others. The information sources used by incident responders – logfiles, network flows, etc. – could also be used to invade privacy, but I suggested three common incident response practices that should ensure our work will protect, rather than harm, privacy:
Concentrate on constituency: each incident response team has a constituency, those within the constituency obtain the most direct privacy and security benefit from the team’s work. Incident responders will also obtain information from outside their constituency (the vast majority of attacking systems have themselves had their security and privacy compromised) but, except for the most serious threats to the Internet community, incident response should be limited to reporting external problems to those external parties best able to fix them;
Minimise data and processing: whether using information to protect its own constituency, or to warn others of their problems, teams should only process or share information that is necessary for the task in hand. Processing unnecessary information both makes incident response harder and creates an unnecessary risk to privacy;
Think about information flows: When sharing information, as well as only sharing information that is needed, teams should only share information with those who can use it. For example before sending details of compromised accounts to an affected service, check that the recipient is able and willing to use the information. Otherwise the sharing creates only a privacy risk, with no compensating benefit. Typically, incident response work involves notifying victims of security (and privacy) breaches, so any personal data is sent towards the person it relates to. This contrasts with (and should always be clearly distinguished from) law enforcement investigations, where personal data about an attacker is sent away from them, to support investigation or prosecution.
Those three practices also correspond to the balancing test that’s required under European privacy law. The
draft General Data Protection Regulation
states in recital 39 that protecting the security of computers, data and networks is a legitimate interest of organisations (similar wording is already contained in recital 53 of the
privacy Directive for network operators
). When processing personal data for a legitimate interest, organisations are required to ensure
that the interest is legitimate;
that the processing is necessary – i.e. that there is no less intrusive way to achieve the interest; and
that the strength of the interest justifies the risk of harm to individuals.
The Directive and Regulation both say that incident detection and response are legitimate, minimisation should ensure that processing is necessary, information flows should ensure that the risk of harm is reduced. The
balancing test described by the Article 29 Working Party of European Data Protection supervisors
provides a final check for incident response: having minimised the risk to individuals, is the (potential) incident sufficiently severe to justify the risk that remains? If not then incident responders should not act until either the risk can be reduced or the likely severity of the incident has increased.
After the talk we discussed how incident response could be conducted in stages, gradually narrowing down on the serious problems. As the investigation gets deeper (and potentially more privacy invasive) the number of systems or accounts being investigated should reduce, and the confidence that they have a security problem increases. Such an approach can maintain the required balance between threat severity and privacy intrusion. The stage involving the greatest risk to privacy – identifying the people, rather than machines, involved in an incident – will normally occur last, when the threat is most certain and the number of people affected has been reduced as far as possible.
For example the initial processing of raw logs is almost always done by machine, so logs of normal activity need never be seen by a human. A subset of the log records will generate alerts, indicating a possible security problem, which are checked by a human to eliminate those that appear to be false positives. Deeper investigation of the likely real incidents can then be much more focussed on the data that relates to serious problems. Where it involves a significant risk to privacy, this investigation stage may require higher level management approval or the support of human resources staff. This requires tools that avoid displaying privacy-sensitive data that is not required at the current stage of response. Fields can either be omitted or masked using techniques such as one-way hashing. Masking should only be removed once there is sufficient confidence that a serious incident is involved, and should generate an audit log so that unnecessary privacy intrusions can be identified and dealt with.
Recent incidents involving the US Office of Personnel Management and the Lastpass password vault have shown the important of effective incident detection and response in protecting privacy.
Originally posted: 18 June 2015 in category
Articles
In Ancient Greece the oracle at Delphi was notorious for speaking in riddles. The European Human Rights Court’s
judgement in
Delfi v Estonia
is similarly puzzling.
Back in 2006 an anonymous reader
made a comment on a newspaper website
; six weeks later the comment was removed following a claim that it was defamatory. In 2008 an Estonian court nonetheless found the newspaper liable for the defamation and awarded around €320 in damages. This seems to conflict with the European
eCommerce Directive
, which protects hosting services from liability for material they are not aware of. But for some reason the Estonian law was challenged on the grounds that it infringed the human right to communicate, not because of the apparent conflict with EU law.
Thus it was the European Court of Human Rights that ruled this week that the Estonian law does not conflict with Human Rights, and that national laws that create liability for hosting providers may be permitted under the Convention in some circumstances (
“The Court emphasises that the present case relates to a large professionally managed Internet news portal run on a commercial basis which published news articles of its own and invited its readers to comment on them” [para 115])
. Whether such a law would be compatible with the
eCommerce Directive
remains an unanswered question. As
various commentators have observed
, this leaves hosting liability in an uncertain state.
The decision shouldn’t be an immediate problem in the UK – our
Defamation Act 2013
actually provides stronger protection than the
eCommerce Directive
and for other types of unlawful content our
Electronic Commerce (EC Directive) Regulations 2002
appear to match its provisions. Websites in the UK should continue to be protected from liability for third-party material at least until they have knowledge of it. However if a future UK law were to modify that liability regime then
Delfi
might mean that any challenge would need to be made under European law, rather than the Human Rights Convention.
Originally posted: 17 June 2015 in category
Articles
An interesting theme developing at this week’s FIRST conference is how we can make incident detection and response more efficient, making the best use of scarce human analysts. With lots of technologies able to generate alerts it’s tempting to turn on all the options, thereby drowning analysts in false positives and alerts of minor incidents: “drinking from your own firehose”. It was suggested that many analysts actually spend 80% of their time collecting contextual information just to determine which of the alerts are worth further investigation. If you are receiving more alerts than you can deal with in real-time, something’s wrong.
Jeff Boerio
explained how much simpler checks can provide an initial yes/no triage. For many logfiles it’s enough to know “Have we seen X?” “when did it start?” “when did it stop?”. That’s interesting whether X is a domain in a proxy log, a user-agent string, a malware family, an e-mail source address, the location from which a user initiated a VPN connection, etc. Not only do those quick queries speed things up for analysts, they can also speed up databases: extracting a simple table with just the two columns (time, indicator) makes queries faster and takes load off the main logging database.
If speeding up the triage process still doesn’t give your analysts time to breathe,
Josh Goldfarb
had a more radical suggestion: maybe you should reduce the number of alerts? And rather than starting from the list of things that your IDS and other systems can detect, maybe start from the list of things that your organisation depends on. So find out what is the biggest security risk/threat for your organisation and set up the alerts needed to detect that. Then add the next biggest risk/threat, and so on, so long as your analysts retain a workload that allows them to do proper investigations of what may be the most harmful incidents for the organisation. Focussing on particular risk/threat narratives also allows you to automatically attach relevant information to each alert: adding the context the analyst will need for that particular type of event. For an alert of a compromised user account that could be things like what access privileges does it have, where has it logged in from, at what times of day, and so on. For a compromised machine, the analyst will want to know whether it’s a server or a workstation, what sensitive information it may store or have access to, etc.
This doesn’t necessarily mean reducing your logging – you still need logs for detailed investigation of those alerts that do appear to indicate significant incidents, and you should periodically do a wider review of logs to determine whether your risk prioritisation is still appropriate. The important thing is to decide quickly and efficiently when those deeper investigations are required.
Originally posted: 16 June 2015 in category
Articles
Domain Name Service resolvers are an important source of information about incidents, but using their logs is challenging. A
talk at the FIRST conference
discussed how one large organisation is trying to achieve this.
DNS resolvers are used legitimately every time a computer needs to convert from human-friendly names (such as
www.google.com
) to machine friendly IP addresses (such as 173.194.67.106). That’s a huge number of queries – for HP’s internal network, eighteen billion log records every day. That rate of logging is a technical challenge for storage and for database software: querying the resulting database may be even harder. But hidden within that lot may be evidence of various malicious uses of DNS, including:
Attacks on DNS itself. If you want to harm an organisation then slowing down or crashing its DNS servers is nearly as effective as cutting it off the Internet entirely. Some vulnerabilities also allow false data to be inserted into DNS servers, so that anyone within the organisation requesting a particular domain name will instead be directed to a harmful server, controlled by the attacker, which may masquerade as a genuine login or payment page, infect visiting computers with malware, etc.
Attacks using DNS. In many cases the response to a DNS query is much bigger than the query itself, making the service an ideal amplifier for denial of service attacks. Here the organisation is not the primary target of the attack, though it may suffer collateral damage.
DNS as an infrastructure. As an essential protocol, DNS traffic is very rarely blocked by firewalls. The volume and variety of legitimate queries also makes it hard to spot unusual traffic. Various techniques have been developed to use DNS queries to carry data of other kinds – in the most extreme examples it’s possible to transmit complete TCP sessions using only DNS queries and responses. These techniques can be used for everything from obtaining free connectivity from wifi networks, to transmitting trade secrets out of organisations.
Unfortunately the fact that there are vastly more harmless queries than harmful ones means that any automatic classifier – determining whether an individual query is harmful or harmless – has to be implausibly accurate. Even if the classifier only makes mistakes 1% of the time, the harmless records that are misclassified as harmful will still be far more numerous than the genuinely bad ones. We need some other techniques to improve the ratio before passing the result to a human analyst.
Some of the ways of doing this are pretty obvious, others are still research topics. On an internal network there will be a lot of internal queries for internal domains: if one of those has gone bad then the organisation has big problems that it should be detecting it in other ways, so it’s probably OK to discard them from the DNS log analysis (effectively ‘white-listing’ those domains). Equally, if an internal machine requests the IP address of a known botnet command and control server, that should almost certainly be on a blacklist and raise an alarm. However alerting on malformed DNS packets isn’t a good idea: it turns out that many legitimate uses generate packets that don’t conform to the standard. A lot of DNS traffic is generated by processes such as auto-configuration and auto-discovery: that can probably be dropped as non-malicious. The volume of data may now be low enough for statistical or machine learning techniques to be effective – identifying the domain names used by botnet Domain Generation Algorithms (DGAs) has been the topic of many research papers. Only generating alerts to humans when a computer has made tens of suspicious queries rather than on each individual one may bring the number down towards manageable levels. Visualisations such as graphs of DNS queries and clusters of requests suggest there are more patterns in there: the challenge is to work out which of those are significant and how to bring algorithms up to the performance of the human eye in detecting them.
Policy and privacy issues were also highlighted in the talk. DNS queries, much more so than DNS responses, can reveal sensitive information about individuals’ browsing habits, so there need to be clear policies both for organisations and individual researchers and analysts on when to stop (or seek additional approval) before an investigation becomes a threat to privacy. Keeping DNS analysis separate from the DHCP logs that identify individuals as the source of queries is a good step, but policies are still needed to protect against accidental identification or inappropriate use of the data. DNS logs are an important source of information about insecure systems but (as I’ll be presenting later in the conference) we need to be sure those benefits aren’t achieved at the cost of our users’ privacy.
The good news is that most of the measures proposed to deal with radicalisation appear to build on existing activities in educational institutions. Most of the requirements refer to existing arrangements for supporting both staff and students: policies on safety and welfare, staff training, visitor arrangements and whistle-blowing are mentioned. Where a risk assessment identifies that any of these are insufficient, an action plan should be developed to improve them. Existing work such as the
Safe Campus Communities
website and Jisc’s safeguarding work are cited. The need to conduct appropriate research into terrorism and counter-terrorism is recognised, with a pointer to
UUK’s existing guidance
on how that may be conducted safely.
IT policies are mentioned, but again in terms of existing policies on (un)acceptable use and arrangements (if any) to use filtering to reduce access to unacceptable content. In both cases the wording of the guidance appears to suggest that these existing measures should be extended to cover radicalisation, not that organisations should adopt a completely different approach. That seems sensible – whether an organisation’s existing risk assessment of relatively well-defined content types such as malware and copyright has concluded either that filtering is appropriate, or that other methods will be more effective, it seems unlikely that adding the much looser category of “content likely to radicalise” will change that assessment.
In addition, implementation of the guidance appears likely to be overseen by bodies already familiar with the education sector, so the “regulators” should be aware of the likely impact on education and research processes of any measures they require.
Originally posted: 11 June 2015 in category
Articles
While we’re still awaiting the announcement of the date when universities and colleges will have a legal duty to “have due regard to the need to prevent people from being drawn into terrorism”, there’s probably enough information available in the
published guidance
for organisations to start reviewing whether their current practice is likely to be sufficient to satisfy that duty.
The
Home Office guidance
says that “compliance with this duty will reflect existing best practice and should not add significant new burdens on institutions”. And it identifies areas of policy and process likely to be relevant to the duty:
partnership,
risk assessment and action plan,
staff training,
welfare and pastoral care/chaplaincy support,
IT policies,
student unions and societies.
(there are slight variations between sectors and countries).
So it seems well worth universities and colleges reviewing what they already have in those areas and comparing it to the relevant on-line resources, two of which are recommended in the guidance, and one has been developed to support it. This should identify both the existing practices that are likely to satisfy the duty, and those that may need work when more detailed guidance becomes available.
Originally posted: 18 May 2015 in category
Articles
A recent
conference on student data
included perspectives on learning analytics from the OECD and the European Commission.
Stephan Vincent-Lancrin (OECD) looked at how improving our use of student data could improve the quality of education provided. He noted that a considerable volume and variety of data about education is already generated within universities, and suggested that much of this is under-used at present. He described educational data processing systems moving from basic administration (who is on what course and how well they did), to cohort studies (learning how groups of students progress over time), to ‘next-generation’ systems that include visualisation and analysis and can be used to generate recommendations for both organisations and individuals. Potential uses of these data include longitudinal studies for research and policy making (for example identifying that US community college students are rarely simply ‘part-time’ or ‘full-time’ but may study different courses in different modes); individual analyses to identify particular skills that students may need to work on; and real-time feedback and customisation for teachers, administrators and students. Key to achieving these benefits is increasing the speed of processing: a recent survey suggested that only 45% of administrators and 25% of students obtain real-time feedback, while research and policy processes were often delayed by six months or more. While that may be sufficient to improve the education provided to future students, it’s too slow to help those currently involved in the process.
Giuseppe Abamonte, from the European Commission, agreed that there were considerable opportunities in learning analytics, citing improvements of 30% in educational achievement in US universities adopting these techniques. Indeed the Commission has recently established a public-private “
Big Data Value
” programme to try to encourage the development of big data industries in Europe. While learning analytics may not benefit directly from this programme (the fields mentioned include health, agriculture, manufacturing and transport), developments in technology, expertise and legal approaches that flow from it may well help us as well.
Originally posted: 18 May 2015 in category
Articles
I’ve been at several conferences recently on how Data Protection law is developing, and they’ve left me less than optimistic. By the end of 2015 Europe will have been working for four years on a Regulation “on the protection of individuals with regard to the processing of personal data
and
on the free movement of such data”, but I’m now doubting whether the result will actually achieve either of those.
The draft law was originally promoted as modernised, cloud-friendly and providing a single law across the whole European Union. However it seems to be failing on all three counts:
The draft texts only acknowledge the internet by declaring that “internet identifiers” constitute personal data, but show no recognition of the consequences of that; all still regard the physical location of data as paramount;
They still assume that a data processor has the same access to information as the data controller (a model based on ‘computer bureaux’ of the 1970s), indeed some versions would place additional responsibility on data processors (even, apparently Infrastructure as a Service providers) to ensure appropriate security or allow direct law enforcement access to data without notifying the processor;
They retain the same options that have allowed divergent national approaches under the current Directive, for example on export formalities; in many areas where Member States have been unable to reach agreement on the Regulation text the preferred solution appears to be to allow each to implement their own preference.
Alongside these developments the courts have been adopting literal interpretations of the current Directive – giving the law the widest possible scope and making exemptions as narrow as possible – apparently relying on legislators to fix the resulting impracticalities. For example: following
Lindqvist
, anyone who posts information about another person to a public website is classed as a data controller, with all the duties the law imposes (in the UK any data controller who does not register with the Information Commissioner is committing a criminal offence!); following
Ryneš
any CCTV that covers any public space must display a notice, which will be tricky for dashboard and cycle helmet cams. We’re all data controllers now!
This hasn’t been widely noticed (at least not till the recent
Google Spain
case) because regulators have been highly selective in which parts of the law they are actually enforcing. Probably the last thing the UK Information Commissioner wants is for every social network user in the UK to turn up with a Data Controller registration form and a cheque! David Erdos gathered
startling survey results
showing just how widely regulators’ interpretation of what the law said about various online activities (tweeting, blogging, etc.) differed from the enforcement measures they were actually taking. Cookie law is far from the only example. Estimates of the resources available to regulators across Europe (typically a few pence per data subject per year) help to explain why.
But at the same time expectations have been raised unrealistically high by slogans such as the “right to be forgotten” (in two different contexts) and suggestions that data protection law can prevent spying: actually it can’t, it doesn’t even try, and the new legislation that might bring law enforcement activities roughly into line with the 1995 Directive seems to be taking even longer than the Regulation.
None of this helps organisations that want to provide services that protect users’ rights. At one time we could use the law itself as guidance, and aiming for compliance was a reasonable course. However, with judgments such as
Google Spain
not even attempting to base their arguments in statute and more than a thousand differences between proposed texts of the Data Protection Regulation, it’s really hard to work out what the law now is. Guidance from regulators such as our own
Information Commissioner
may be a better option, though this may not answer specific questions and is liable to change more often than the twenty-year cycle of formal law. The eight
data protection principles
remain a sound basis that is unlikely to change, but at the level of detail that the EU Regulation is attempting organisations may need to balance the benefits of a particular course of action against the risk that it may not be perfectly compliant.
For a privacy-conscious person that’s scary, because it means the organisations most likely to be processing my personal data are the ones that are willing to take risks. If uncertainty about data protection law means that the organisations that would protect my privacy aren’t even willing to offer me services, that would be the worst possible result.
#236 - ENISA – working out cloud security requirements
Originally posted: 22 April 2015 in category
Articles
ENISA’s new report proposing a “
Security Framework for Governmental Clouds
” may be more widely useful than its title and explicit scope suggest. Chapter 3 of the report suggests something pretty close to a project plan that any organisation could use to assess which applications and data are appropriate to move to a cloud service, what security measures they require, and which cloud models and services can provide them.
Being based on the Deming “Plan-Do-Check-Act” cycle, the report also identifies the need for monitoring and corrective measures (Check and Act stages). Here the most detailed information is in the Chapter 4 case studies, which indicate the types of monitoring, auditing and certification that four countries (including the UK) apply to their Government clouds. The report suggests some categories for these activities, but the variety of approaches actually taken suggests that the right level of monitoring/audit/certification may actually depend on the types and levels of risk identified for particular applications.
#235 - Internet regulation after the Google Spain case
Originally posted: 8 April 2015 in category
Articles
Yesterday’s excellent University of Cambridge conference on
Internet Regulation After
Google Spain
suggested that data protection law will continue to affect a growing range of our activities, but that interpreting its requirements in novel circumstances will continue to be challenging. It was suggested that if the current (1995)
European Directive
was for the age of the mainframe then the (2012)
proposed General Data Protection Regulation
is for the age of Web 2.0. So in many areas of networked services it will already be out of date when it finally comes into force. That means it’s unlikely to be possible to
guarantee
compliance when processing information that may relate to individuals: whether or not the Regulation adopts the proposed risk-based approach it seems clear that organisations will have to do so.
Although most of the headlines arising out of the
Google Spain
case
(C-131/12) concerned the “right not to be found so easily” (as one data protection regulator described it), the conference ranged much more widely over the issues arising out of the case. In particular Orla Lynskey saw the case as confirming a trend – on the rare occasions when the European Court considers data protection law – for very broad definitions of both “personal data” and “processing”. Thus, as Eduardo Ustaran observed, even if Google processes all bytes in the same way, the fact that some of those bytes are the names of individuals makes it a data controller in the eyes of the law, with all the obligations imposed on such organisations. Exemptions – such as those for journalism and domestic purposes – will be narrowly interpreted. The cases of
Lindqvist
(C-101/01) and
Rynes
(C-212/13) indicate that individuals, too, may easily become data controllers in the eyes of the law, something that neither they nor data protection regulators seem prepared for. In all three cases it seems that the Court focussed on the specific facts before it, giving little weight to the broader impact of its decision either in practice (despite clear
warnings from its own Advocate General
in
Google Spain
) or in political terms.
David Erdos, who also organised the event, presented
practical research
that confirmed these trends, but also explained why their potential impact may not have been noticed. He invited Data Protection Authorities to comment on a number of Internet publishing scenarios, as well as asking about their actual practice in regulating these areas. The responses indicated that most regulators did take a similarly broad interpretation of the law, but that actual enforcement is both rare and sporadic. Hence Google Spain has only been perceived as affecting search engines when in fact everything from bloggers to social networks, and even smart TVs, could find its conclusions being applied to them if regulators choose to do so.
David Smith, Deputy Information Commissioner for the UK, confirmed the general feeling that pretty much any on-line activity needs to take account of data protection law. Anyone concerned that regulators “don’t understand technology” would have been pleasantly surprised by his awareness – correct, in my opinion – that an IPv6 address is more likely to be personal data than an IPv4 one. But the response to this by on-line service providers and users should be responsibility, not panic. For example we (all) need to get away from the idea that “consent is the answer to everything” – something I’ve been
suggesting
, and trying to build into Janet services, for a long time (e.g.
access management
and
learning analytics
). The law provides
five other justifications
for processing personal data, each with its own requirements which may well provide better protection for on-line service providers and users than straining the definition of “free, informed consent” to the point where it, and the protection it is supposed to provide, become meaningless. David was also realistic about what legislation and regulation can achieve: only international political agreements, not national laws, can stop spies from spying.
Given all these challenges, the conference was perhaps surprisingly positive. Certainly there seems to be plenty in the field to keep academic lawyers busy for years. But there was a positive attitude to future internet developments, too. Service providers and developers who want to respect data protection are unlikely to ever find a simple instruction manual; but there do seem to be sufficient legal tools, and a willingness to find pragmatic ways to use them, to support responsible service provision and use.
Originally posted: 8 April 2015 in category
Articles
In discussions of the “Right to be Forgotten” it is often observed that Google manages each month to deal with tens of millions of
delisting requests for breach of copyright
, as opposed to tens of thousands for
inaccurate personal data
. Often the implication seems to be that those numbers should be more similar. However it seems to me that the two types of request need to be handled in significantly different ways and that they probably require, on average, significantly different amounts of manual effort per request received. If the processes ought to be different, then we need to be careful when comparing them, lest we (or search engines implementing them) come to the wrong conclusion.
The main differences concern the source of requests and the content to which they apply.
It seems likely that most requests to “forget” will come from individuals and that, unless they are particularly unfortunate, most individuals will only have one or a few pages to complain about. That means Google may well have to check the requester’s identity and entitlement to make a request for nearly every “forget” request they receive. That contrasts with copyright delisting requests that generally come in large numbers from a small number of rights holders and their representatives. That can allow a much more efficient identification process, for example by exchanging digital signatures so the sender’s identity can be verified automatically in future.
Automation is also a possibility for copyright delisting as most requests will apply to the second, tenth or hundredth identical copy of the same digital file. Once one copy of the file has been assessed as probably infringing, requests relating to further identical copies can be recognised immediately using hash values. It seems likely that anyone trying to implement an efficient takedown process would conclude that all identical copies should be treated in the same way. With “forget” requests, by contrast, it seems unlikely that identical pages will reappear so, again, every request will need to be assessed manually.
There are also significant differences in the laws that apply to the two types of request, which ought to make a difference to a search engine that tries to implement them accurately.
The European Court’s definition of the “
right to be forgotten
” under Data Protection law explicitly requires judgments and balancing tests in every case: is the material inaccurate, irrelevant, irrelevant or excessive? does the public interest in finding the material outweigh the individual’s right to object to processing? For material written in human language, it’s hard to conceive of a computer being able to apply those rules. Copyright law involves different tests: is the material subject to copyright in a relevant country? is the publication covered by fair use or other exemptions (again, with national variations)? Here there may be some possibility for computers to help, particularly when multiple requests are received for the same material.
If there’s any value in comparing and contrasting the two kinds of request, I think it needs to be done at this kind of detailed level. Raw numbers of requests don’t say much about what is (or ought to be) going on.
Originally posted: 8 April 2015 in category
Articles
A couple of discussions at Networkshop this week have raised the question of cyber-insurance, and whether this might be useful to universities and colleges. To think about that I split the question into three:
What sort of risks does insurance cover, and are they things that are high on your risk register?
If an incident of that kind does happen, is a money payment (which is what insurance policies generally provide) going to be useful in making your position better?
Are there other ways you could deal with those risks, and how to their costs/benefits compare?
For example a couple of recent reports have looked at cyber-insurance from the perspective of
businesses
and
law firms
. Those suggest that insurance is most commonly used to cover the costs incurred under data breach notification laws, where organisations are required to notify individuals if their personal data have been exposed as a result of an incident. In those cases there are obvious money costs – for example postage and perhaps paying for credit reports – so an insurance payout might well be helpful. And it is possible that universities might suffer that kind of breach, though preventive approaches such as PCI-DSS might be a more effective way to reduce the risk.
However the articles also suggest that insurance can be used to cover liability to third parties when paid hosting services suffer incidents such as website defacement. That’s an area where I suspect damage to universities is more likely to be reputational than financial, so an insurance payment might be less help in solving the problem. And, as the articles note, some of these may already be covered by existing liability and professional indemnity insurances anyway. Having an effective incident response plan to minimise the damage from such incidents may be an effective alternative approach.
The other issue with cyber-insurance seems to be that, although products have existed for a decade, there haven’t been many policies taken out or claims made under them. That probably means that neither purchasers nor insurers have much data on what the actual risks are, so policy prices are less likely to reflect the true risk/benefit balance than for other, better understood, areas of insurance [Sarah Clarke has an
excellent discussion of this
]. That situation may be even worse for universities, as insurers’ data are likely to reflect commercial businesses where IT operations and risk calculations may be very different to ours. If you are considering such insurance, you may get a better deal by limiting it to areas of operation that are most similar to businesses, where the pricing is more likely to be accurate.
#232 - Federated Authentication for E-infrastructures
Originally posted: 25 March 2015 in category
Publications
A growing challenge for on-line e-infrastructures is to manage an increasing number of user accounts, ensuring that accounts are only used by their intended users, that users can be held accountable for any misuse, and that accounts are disabled when users are no longer entitled to use them. Users face a similar challenge in managing multiple authentication credentials for different on-line services. One option, which may provide more efficient authentication for e-infrastructures and a better experience for users, is to build on the account management systems and processes already provided by users’ home universities or colleges. Federating authentication in this way is already commonly used to gain access to networks (eduroam) and electronic publications (UK Access Management Federation). E-infrastructures based on X.509 proxy certificates can implement federated login to certificate stores or issuers, for example, using the Short Lived X.509 Credential Services (SLCS) or Identifier-Only Trust Assurance (IOTA) profiles. Jisc is currently piloting technologies and processes that make federated authentication suitable for a wider range of e-infrastructure services. This paper therefore identifies the authentication services likely to become available to e-infrastructures through federation and considers the benefits they may bring.
Originally posted: 25 March 2015 in category
Publications
E-infrastructures are large computer systems with considerable processing and storage capacity and in some cases, holding valuable or sensitive data. They are therefore likely to be attractive targets for attackers with a wide range of motivations. However, to support international research, e-infrastructures must be accessible to users located anywhere on the Internet. In many cases users will upload and run their own software or virtual machines and exchange large volumes of data over high-speed networks. Operators of e-infrastructures are therefore challenged both to provide the open and flexible computing platform that is inherent to the e-infrastructure concept and to protect against the consequences of attacks on that platform over the Internet. To help them, the e-infrastructure model offers many different ways to implement security controls. This paper reviews the security measures used by e-infrastructures against a widely-used model – the Cyber-Security Council’s Top 20 Controls – to assess what is being done and where improvements may be possible.
Originally posted: 26 February 2015 in category
Articles
Next month I’ll be going to an academic conference on
Google Spain
and the “Right to be Forgotten” (actually, “right to be delinked”) so I thought I’d better organise my thoughts on why, as a provider and user of communications and information services, the decision worries me. And I am much more worried by the decision itself and the train of proposed law it seems to have created than by how Google has responded. Their response may indeed have been driven by PR and commercial interests – it certainly doesn’t follow the legal incentive the ECJ created – but Google’s actions and the proposals of their
Advisory Council
are far less harmful to fundamental rights than I feared when I read
the Court’s original decision
. Nor are my concerns about where the balance between the rights to privacy and to receive information actually lie.
So why am I worried?
The Wrong People are Deciding
. The “right to be delinked” is, essentially, a conflict between two fundamental rights – the right to privacy (Article 8 of the European Convention) and the right to communicate and receive information (Article 10). Both rights are qualified – the Convention recognises that there are occasions where one or other will take priority. And the Convention expects that the appropriate place for that balance to be decided is a court. However when the European Court of Justice (ECJ) had the chance to consider the balance in
Google Spain
it didn’t actually make a decision. Instead it said that a search engine was covered by data protection law, and that in some circumstances the Article 8 right to privacy would override the Article 10 right to receive information. The issue of deciding
which
circumstances, in other words of setting the balance between two fundamental rights, was handed back to the search engine. And, as far as I can see, there’s no way, at least in UK law, to ever get the decision-making back into the ECJ where it belongs. If I ask for a link to be removed from search results and the search engine doesn’t (in other words it gives too much weight to Article 10) then I can appeal to the Information Commissioner and, eventually, it’s possible for the dispute to end up back in the ECJ. But if the search engine removes a link that it shouldn’t (for example if another Andrew Cormack asks for one of my search results to be removed and the search engine – giving undue weight to Article 8 – mistakenly does), then I can’t see any way for me to bring my complaint to any court. I don’t have a contract with the search engine that they will link to my articles (no adwords here!) and, as a private company, it doesn’t seem possible to make a direct claim against them for breach of Article 10.
They’re Encouraged to Decide One Way
. Not only does that situation give me no way to defend my Article 10 right to be heard, it also gives the search engine a strong incentive to override that right in favour of any claim for privacy. Even if the ECJ hadn’t made the (questionable, given previous cases) statement that “[privacy] rights override, as a rule, not only the economic interest of the operator of the search engine but also the interest of the general public in having access to that information upon a search relating to the data subject’s name”, if you are faced with a decision where one choice can land you with the costs of defending a court case and the other can’t, which would you choose? This problem of one-sided incentives has been known for a long time. More than a decade ago Bits of Freedom’s
Multatuli project
found that a false claim of copyright infringement (Multatuli placed the work in question in the public domain) was sufficient to have a document removed from the majority of web hosting sites. This shouldn’t have been a surprise: if the host left the document and turned out to be wrong then they risked finding themselves in court, if they removed it then there was no legal risk thanks to clauses in their contracts with customers.
One-sided incentives on Internet intermediaries
are a well known problem. The European Commission have been
investigating the incentives
created by notice and takedown schemes for years; the
Defamation Act 2013
finally provided an
alternative course of action
that protects UK hosting services from one-sided liability risk. But now the ECJ has created a new one, applying to no less than the “gatekeepers to the internet”.
Proposed Solutions Make Other Problems Worse
. Google seems, at least for now, to have resisted the temptation to follow that incentive and simply remove any search result that was the subject of a complaint. However the risk of a search engine adopting that approach does seem to have been noticed, to judge from a recently proposed
amendment
to the “Right to Be Forgotten” section of the draft General Data Protection Regulation, discovered by Statewatch. This would require all internet search engines to create independent dispute resolution bodies to ensure that fundamental rights were balanced. Quite apart from the effective side-lining of the public court system, that would impose a substantial cost burden on anyone running a search engine. For the existing dominant players that might create a dent in the bottom line, but for would-be entrants into the market it could well make their finances unviable. In 2000 the
e-Commerce Directive
considered it important that there be special immunities for internet intermediaries, in order to promote a competitive market in these vital services. Has the market now changed so much that we can, instead, consider placing special burdens on intermediaries and exclude new competitors?
Originally posted: 16 February 2015 in category
Articles
The
Counter-Terrorism and Security Act 2015
, which received Royal Assent last week, has some network-related provisions among its various powers relating to terrorism.
Section 21
adds further “relevant internet data” to the list of information that public telecommunications operators may be required to retain about the use of their networks and systems. Although in Parliament Ministers explained that this extra information was concerned with the allocation and translation of IP addresses – trying to remove gaps in logging that prevent internet activity being linked to a network subscriber – the drafting of the Act itself is very hard to follow. Fortunately, from a Janet perspective, the new requirement is an amendment to last year’s
Data Retention and Investigatory Powers Act 2014
(DRIPA), so applies:
only to “public telecommunications operators” (DRIPA s1(1)) (so not to the majority of Janet-connected organisations), and
only to data already “generated or processed” by those operators in the course of supplying the telecommunications services (DRIPA s2(1)) (so not requiring collection of new data), and
only when the operator receives a notice from the Home Office (DRIPA s1(1)).
Any Janet customers who do offer
public network access
should discuss with their partner Internet Access Provider the arrangements that may be required if such a notice is issued.
Section 26
of the Act creates a general duty on specified authorities to “have due regard to the need to prevent people being drawn into terrorism” (s26(1)).
Schedule 6
of the Act lists schools, colleges and universities as “specified authorities”. The Secretary of State may (s29(1)) issue guidance to authorities on how they should comply with this duty; any such guidance must be approved by vote in Parliament (s29(5)). This guidance appears most likely to concentrate on organisational and policy issues, however
draft guidance
published for consultation before Christmas did include a requirement on schools, colleges and universities to “consider Internet filtering”. However the Government has said that the guidance will be amended following the consultation and comments in Parliament; more recently the
Minister has mentioned
“a policy on misuse of computer equipment” as an example of a measure that might be required. Since education is devolved matter, the authorities in Scotland, Wales and Northern Ireland may either follow the Westminster approach or provide their own guidance. Jisc will continue to work with bodies representing our customers to ensure that guidance is practical and effective (like, for example, the existing UUK guidance on
Safe Campus Communities
).
#228 - Incorporating security into development processes
Originally posted: 29 January 2015 in category
Articles
Tilmann Haak’s presentation at this week’s
TF-CSIRT/FIRST meeting
was on incorporating security requirements into software development processes using agile methods, but his key points seem relevant to any style of software or system development:
Make sure security features are treated as first-class user requirement, of equal status with the functional requirements provided by others. We’ve all experienced products where security was clearly added afterwards; in agile if it doesn’t offer value to the customer then it won’t get added at all. So be prepared to explain the value that security brings to the customer.
Do that in terms the developers are used to working with. In agile that often means user stories, so alongside Tilmann’s “As a user I would like to buy candy from the machine” you need to place my “As a thief I would like to take the money that others have put in the machine”.
Provide developers with the tools they need to implement your requirements in their systems. Don’t just say “encrypt passwords in transmission and storage” – show them the libraries and implementation guidance that will enable them to do it right. Badly implemented security really is a waste of time, delivering no value to the customer.
Originally posted: 21 January 2015 in category
Presentations
I’ve done a couple of presentations this week, comparing the risks and benefits of Bring Your Own Device (BYOD) with those that research and education organisations already accept in the ways we use organisation-managed mobile devices. As the title of my talk in Dundee asked, “
BYOD: What’s the Difference”
Nowadays, most of the significant risks to information when it’s used outside the office seem to be created or prevented by user behaviour, rather than the technology they happen to be using. We’ve all been on trains when someone reads out their credit card details, very clearly, on a mobile phone. Whether that phone is their own or their employer’s, or who owns the laptop on which you work on a confidential presentation in a public place, is irrelevant. If you are worried about information being backed-up to an insecure Internet site, or stored on a device that is lost or stolen, then those risks too exist for both personal and corporate devices. In some cases an organisation-managed device may have quicker patching or anti-virus updates, but there are also examples of corporate systems or contracts making security updates significantly slower than an individual can get them direct from the vendor.
Most of the technical security controls that we use on mobile devices in research and education are also readily available, indeed should be basic good practice, for all our personal devices. PINs, passphrases and SSL communications are at least as important to protect personal data and phone bills as they are for business information; encrypted storage and remote wipe (if they are supported) protect our precious information from casual thieves; keeping work and personal files and e-mails in separate folders (or even accounts) makes for much easier filing and less risk of sending a message to the wrong person. Awareness of surroundings is essential for anyone using a mobile device, especially if it’s you that pays for its insurance.
There are a few technologies that aren’t appropriate for personally-owned equipment: the
Information Commissioner
specifically warns against location tracking and usage monitoring on devices that may be shared with family members. It’s also unlikely to be possible to technically restrict what software is installed or what administrative rights a user has over their own device. But how many users in education have those restrictions on their “work” mobile devices anyway? We may have a policy of withholding administrator rights, but the difficulty of using a laptop without those rights (I’ve tried!) makes me suspect that the exceptions to that are invoked more often than we’d care to admit.
In fact I wonder whether the difference between BYOD and Corporate Mobile might even be the other way around? A
BT survey
found that 81% of employees (and an even higher proportion of senior executives) “didn’t care” about mobile security. That may be true of devices that are “just for work”, but do we really care so little for personal devices that may contain the only copies of photographs of family occasions or whose misuse by a thief could create a very large dent in our personal bank accounts? Perhaps we should be designing systems that encourage BYOD, helping owners to use their devices safely in their own interests, and incidentally improving the way they handle our data as well? Certainly when I talk to people about security or privacy, it’s the stories of personal impact that seem much more likely to change behaviour.
On balance I don’t see BYOD as creating significant new risks for most research and education uses, unless organisations deny its existence and leave their users without the support and guidance they’ll need when working outside the office on any device. However, there do seem to be potential benefits to be had, both for organisations and their users, if we design BYOD into our human and technical systems. Indeed the human side is probably more important – BYOD is mostly about Owners, not Devices.
Originally posted: 19 January 2015 in category
Articles
During a recent conversation about learning analytics it occurred to me that it might be helpful to analyse how universities use student data in terms of the different justifications provided by UK and European Data Protection Law. Although the ‘big data’ techniques used in learning analytics are sometimes said to be challenging for both law and ethics (though the
Open University
have what looks like a pretty good attempt), it seems to me that the different legal justifications, and the rules and principles associated with each of them, could form a helpful basis for legal and ethical guidelines on handing student data.
Here’s an initial sketch of how that might work… Corrections, comments and suggestions would be very welcome.
The first group of reasons for processing information about students is those that follow inevitably from the individual’s decision to become a student. Simply being a student means the university has to hold application and contact details, record the student’s progress, lend them library books, provide them with computer access, manage fees, etc., etc. There are also external requirements on universities, for example to report on student achievement (a condition of receiving public funds) and attendance (where students have been granted study visas). Data protection law recognises this type of ‘necessary’ processing, whether required by a contract, a legal obligation or a public function. Since neither the university nor the student can choose whether this processing takes place the main data protection requirements are transparency, minimisation and security – applicants must normally be informed of what processing will occur as a result of their application (especially any non-obvious processing), data collection and processing should not go beyond what is necessary, and information must be protected by appropriate security measures.
Next there is a group of additional functions that the university might like to perform using the student data it has or may collect in the course of its operations. This could be as simple as working out which library books are popular to guide future purchasing decisions, or as complex as noting that students with a particular group of A-levels struggle on a particular module. Results are more likely to be accurate if data can be gathered across the whole student population: struggling students are particularly unlikely to have time to fill in yet another questionnaire. In the past this kind of processing could be used to improve educational provision to future cohorts of students, but collection and analysis were unlikely to be quick enough to affect current students. Data protection law provides three different approaches to this type of processing: the simplest is to anonymise the information so that data protection law does not apply, however this is very hard to ensure so long as records exist at individual level. Alternatively a specific exemption covers research that can be designed to ensure there is no impact on individuals: this may be possible when investigating specific questions (‘hypothesis-driven research’) where all possible impacts can be predicted, and excluded, in advance. However this is unlikely to be suitable for wider data-driven investigations where it is not possible to predict what correlations may be found. These need to be done within the terms of the ‘legitimate interest’ justification, which allows processing in the interests of the organisation (e.g. to improve its educational practice) but only if those interests are not overridden by the fundamental rights of the individuals whose information is being processed. The
Article 29 Working Party
of Data Protection regulators have stated that this involves a balancing test: the better the protection for individuals’ interests, the wider the range of organisational interests that can be supported. Such interests must be legitimate for an educational organisation and the transparency, minimisation and security duties still apply. This suggests that when processing data beyond that needed for student administration, universities’ first priority must be to ensure that the interests of the students are protected – whether by full anonymisation, by designing research to avoid any impact on individuals, or minimising the risk of impact and ensuring it is justified by the benefits of the results. If there is any risk of impact then transparency about the processing is required, and account must be taken of any concerns that individual students’ circumstances may increase their risk.
Last there are functions designed to help individual students. These may include applying the patterns discovered through research, for example by offering tailored support to individuals based on their past experience and current performance. One of the benefits claimed for the rapid analysis of ‘big data’ is that such support can be immediately responsive to current students’ needs, rather than just assisting the next cohort. Here the intention is to maximise the effect on the individual, so the approaches suggested above for research clearly cannot be applied. Some of these might be considered part of normal education – so covered by the ‘necessity’ justification discussed above – but this is probably limited to interventions that were envisaged at the time the student’s data were first collected. Novel or specifically targeted options should instead be offered to individual students, who may give or withhold their individual consent to them and the additional processing of personal data they entail. Under this model, students must have a free, fully-informed, choice whether or not to accept additional support; they must also be able to withdraw their consent and return to being treated in the standard way for their cohort.
It’s also worth noting that the law requires additional controls if decisions are taken automatically that will affect individuals. Big data analysis will typically find correlations rather than causation and it may well be advisable to have a human make the final decision on whether the machine’s proposed course of action is appropriate. “Data-supported decision making”, rather than full automation, should probably be the aim.
Originally posted: 15 January 2015 in category
Articles
“Is scanning lawful?” sounds as if it ought to be a straightforward question with a simple answer. However investigating it turns out to be a good illustration of how tricky it is to apply real-world analogies to the Internet, and the very different results that different countries’ legislators (and courts) can come up with when they try.
The legal starting point is indeed simple: nearly all countries have a criminal offence that prohibits “unauthorised access” to computers. And nearly all of them, explicitly or not, seem to have had ideas of real-world “trespass” in mind when drawing up their laws. But that should immediately ring warning bells, because merely being on someone else’s property isn’t normally a criminal offence. In English law you need more than just trespass to commit a crime: for example entering someone else’s property with intent to steal is a crime (burglary), entering someone’s property by force used to be a separate crime (housebreaking).
Nonetheless the UK
Computer Misuse Act
is very clear that what is prohibited in the case of a computer is mere “access” and defines that in very wide terms: “causes a program to be executed” (s.17(3)). So in the UK scanning will almost always constitute “access” (since the whole point is to get the scanned computer to respond in some way) and the question of whether it is lawful depends almost entirely on the meaning of “authorised”. And, since life in both the Internet and the real world would be impossible if we always had to seek permission in advance, on the circumstances in which you may presume that your “access” is authorised implicitly by the behaviour, rather than the explicit words, of the person entitled to give or deny authorisation. That question turns out to be sufficiently complex that I could write
more than 3000 words
on it, and an academic law journal was happy to publish it. And even that discussion still only reaches a provisional conclusion, as none of the few relevant cases actually defines the boundary between authorised and unauthorised and none creates a precedent that would bind future court cases!
So what about
other countries
? It turns out their criminal laws don’t just come to different answers: they ask completely different questions in order to get there. Germany asks whether the action involved circumventing a protective measure – roughly analogous to our housebreaking offence – so if scanning can be done “outside” a barrier (whatever that means), or if the system owner didn’t install a barrier (access control lists, passwords, etc.) in the first place, then it appears to be lawful. Austria considers the intent of the person seeking “access” – akin to our intention-based form of “burglary” – there, if there’s no criminal intention then it seems there can’t be a crime. And the
Netherlands
defines “access” more narrowly – more like “breaking in” – so there the question would be what technical activity counts as “getting in”. All of those variations appear to be permitted by the
Council of Europe Cybercrime Convention
and the EU
Directive on Attacks on Information Systems
, the best attempts we have harmonising the law in this area.
So the answer to the question – “is scanning lawful?” – is definitely “it depends”. But what it depends on may be completely different depending on where you (and possibly the computers you are scanning) are!
Originally posted: 15 January 2015 in category
Articles
Recently we had one of our regular reviews of security incidents that have affected the company in the past few months. All three – one social engineering attack, one technical one, and one equipment loss – were minor, in that only limited information or systems were put at risk; all were detected and fixed, to the best of our knowledge, before anything was accessed that shouldn’t have been. If we had only been looking at data breaches they probably wouldn’t even have made it to the agenda.
But our definition of incidents includes events that might put information security at risk, so we were able to have a useful discussion of our processes for detecting incidents, for dealing with reports, for prevention and for mitigation. We learned, or had reinforced, something at each stage:
Incidents can be detected by a wide variety of people (the owner, an external CERT and an alert signing officer) so awareness and processes need to ensure that everyone knows how and when to identify and report the signs of one;
Holidays and periods of organisational change are challenging for receiving and handling incident reports so information needs to be kept up to date and information flows resilient;
Layered precautions are good – people supported by policies supported by technologies – so that even if an incident manages to evade one layer there’s a reasonable chance it will be detected by another.
So even non-breaches generated plenty of ideas that we can use to make our systems more robust, increasing the likelihood that the next incident will be no more than a near-miss too.
The great thing about near-misses is that there is much less blame hanging around. In each of our incidents, enough did work that the consequences of the things that didn’t were minimal. That encourages discussions that are positive and focussed on processes and systems: it’s much easier to have an open discussion of why things went wrong if this time it didn’t matter but next time it might. And, as a former incident responder myself, it was a very pleasant change to be able to thank a colleague for being one reason that a breach
didn’t
happen.
Originally posted: 6 January 2015 in category
Articles
Reading yet another paper on privacy and big data that concluded that processing should be based on the individual’s consent, it occurred to me how much that approach limits the scope and powers of privacy regulators. When using consent to justify processing, pretty much the only question for regulators is whether the consent was fairly obtained – effectively they are reduced to just commenting and ruling on privacy notices. And, indeed, a surprising number of recent opinions and cases do seem to be about physical and digital signage.
But in an area as complicated as big data, where both the potential risks and benefits to individuals and society are huge, I’d like privacy regulators to be doing more than that. It seems pretty clear that there will be some possible uses of big data that should be prohibited – no matter how persuasive the privacy notice – as harmful to individuals and society. Conversely there are other uses where the benefits to both should legitimise them without everyone having to agree individually. Privacy regulators ought, I think, to be playing a key role in those decisions, something that invoking “consent” prevents them from doing.
There is an existing legal provision that would let regulators discuss much meatier questions: whether processing is “necessary for a legitimate interest” and whether that interest is “overridden by the fundamental rights of the individual”; however until recently it hasn’t been much used. The Article 29 Working Party’s
Opinion on Legitimate Interests
is a promising start, but it would be good to see regulators routinely discussing new types of processing in those terms. Looking at big data, and other technologies with complex privacy effects, explicitly in terms of the benefits they might provide and the harms they might cause – maximising the former and minimising the latter – seems a much better way to protect privacy than simply handing the question to individuals and then considering, after it is too late, whether or not their consent was fairly obtained.
Analysing applications in terms of legitimate interests and personal rights could even benefit those organisations that want to do the right thing. A business that can demonstrate, in terms approved by a privacy regulator, how its activities provide a significant benefit without threatening the fundamental rights of its customers would seem to have a strong ethical and legal position: at least as good as one claiming “those consequences were clear from our privacy policy that you consented to”. An interesting survey of
trust in different public sector organisations
suggests this may be a calculation we are already making instinctively. And if this approach were to become the norm then it might even provide a signal of its own – that a proposition that doesn’t make the legitimate interest/fundamental rights case, but relies instead on user consent, should be examined very closely by those users.
Originally posted: 22 December 2014 in category
Articles
The steady growth in the use of encrypted communications seems likely to increase next year given recent announcements on both
web browsers
and
servers
. That’s good news for security people worried that their users may be sending sensitive information such as passwords and credit card numbers over the Internet. However it may also require an adjustment in where we concentrate our efforts to protect those users and their equipment.
For many years it’s been common to use content filtering technologies within organisational networks to detect and block both malware and undesirable content. However these are ineffective on encrypted communications as the same encryption that protects users’ privacy also protects these threats from being inspected and detected. Like any tunnelling technology, encrypting communications to a web server means that protection relies on the equipment at the end of the tunnel: normally the end user PC, laptop, tablet, etc. As the use of encrypted communications becomes more common, technical measures on those devices – such as patches, anti-virus and local firewalls – and safe behaviour by their users will be increasingly important. Fortunately devices are also becoming more powerful, capable of supporting more security features, and safe surfing is increasingly recognised as a critical life skill. We need to support and promote those trends.
Network-based measures are still available and useful. Infected or malicious websites can be blocked at DNS or IP level, whether their communications are encrypted or not. Whitelists of trusted websites will still work, too.
Safe search
can also be implemented using DNS and IP, as explained in Google’s post (see Option 3). Any unencrypted communications will still be available for inspection, of course.
If this is insufficient, it’s technically possible for an organisation to inspect content within its users’ encrypted tunnels, but there are significant technical, privacy and security disadvantages, as well as legal issues (interception, data protection and privacy) that need to be considered. Encryption relies on a matching pair of certificates – one at the server end, one in the user’s web browser. If the certificates do not match, most browsers will warn the user very loudly that they are under attack. Some systems may effectively refuse to proceed. Inspecting content inside the tunnel involves forging the server-side certificate, so the organisation must be able to reconfigure all its clients with the matching client-side certificate. This may be possible if all devices on the network are centrally managed but it is likely to make the network effectively unusable, and reported as extremely hostile, to any visiting or unmanaged devices.
Once the forged certificate is installed on a client machine, the organisation is likely to be able to decrypt
all
SSL/TLS-encrypted tunnels, including those used to transmit sensitive personal, financial or health data. The organisation must ensure their processes and technology (e.g. to prevent unauthorised or inappropriate access to the filtering device) are sufficient that that doesn’t become a serious privacy and security threat. Furthermore a client connected to an intercepting filter will no longer detect or report certificate errors, even if it accesses a malicious external site with its own forged certificate. The filtering device must recognise and block any certificate errors itself, otherwise it will expose its users to even greater risk.
While a few organisations may have the justification and ability to deploy intercepting filters, all should be taking steps to improve the security of their end devices and users. Unlike network-based measures, which only protect users when they are connected to that network, secure devices and users stay secure wherever they are and however they connect.
#221 - Can CSIRTs Lawfully Scan for Vulnerabilities?
Originally posted: 18 December 2014 in category
Publications
This
paper
looks at the UK’s Computer Misuse Act 1990 and how it might apply to the practice of vulnerability scanning. Where a scan has been authorised – either specifically or via a network security policy – there should be no problem. But there are some situations where we’d like to scan hosts for which neither of those options is possible. This turns out to be a legal grey area, depending on how much implicit authorisation is granted by the act of connecting a computer to the Internet. Using the only two reported cases, I tried to work out which kinds of scan a future court might accept as lawful, and which they would probably not. Note that this is not legal advice!
Originally posted: 18 December 2014 in category
Articles
Although it’s now almost three years since the European Commission published their proposed General Data Protection Regulation, it seems
unlikely that a final text will be agreed even in 2015
. That means we’ll be stuck for at least another year with the 1995 Directive, whose inability to deal with the world of 2015 is becoming increasingly apparent. In 1994 my job was to create Cardiff University’s first official web server: it’s little wonder that what legislators drafted then struggles to cope with the global Internet and multi-layered cloud services of today.
Although the principles of data protection set out in the Directive and our UK Data Protection Act still seem sound, applying the literal wording of old law to modern technology is producing increasingly
odd and impractical results
. Aiming for perfect “compliance” is no longer a particularly good guide to what will actually protect our, and our users’, information. Instead we should be talking a broader view of what the real risks to privacy are and how we can best defend against them.
A lot of the headlines in the past year have concerned invasions of privacy by Governments, including our own. However it’s important to remember that there have also been very large breaches of privacy committed by criminals and activists. An article I read recently pointed out that if you think the biggest threat to you is a government then the only chance of defending yourself is to adopt government-style defences to protect against electronic, physical and human intrusions. So no connecting your information to the Internet, or allowing unvetted visitors to your building! While it might be possible for universities to approximate those measures for small, specialised research areas, applying them more generally would bring the normal business of research and education to a halt.
Against criminals and activists, however, it seems that the best of common security practices do still provide reasonably good protection. That requires care from everyone with access to information and systems: identifying and adopting the appropriate behaviour, technology and systems for handling information in order to protect it against the most likely threats. However those measures aren’t incompatible with research and education. Indeed one of the security techniques that seems to have been “discovered” by the commercial world in the past couple of years is incident response: something we’ve been doing pretty well for even longer than the Data Protection Directive has existed.
So even if I expect to continue to struggle to find clear answers to “what does the law require of X?”, I do think we have good, and practical, answers to “how do I do X sufficiently securely?”.
Originally posted: 24 November 2014 in category
Articles
A long time ago, testing software was part of my job. To help with that I had an initial checklist of questions to pose to any new program: situations where I should check that it behaved as expected. Once it passed those basic checks I could get on to the more detailed testing specific to that particular program.
With the Government apparently about to “fast-track”
another piece of internet law
, it seemed worth trying to draw up a similar checklist for legislation. Here’s a second draft:
Are definitions (both in the Bill and imported) precise, and do they match common meanings?
What (if anything) does this require of:
Fixed access provides?
Mobile access providers?
Wifi providers?
Venues offering wifi (cafes, conferences, etc.)?
Backbone providers?
Information Society Services (webmail, search, hosting, etc.)?
Home users?
Internet-connected businesses?
Universities, colleges, libraries?
What does that mean for their other obligations (e.g. under Data Protection, Freedom of Information, court orders…)?
Does it create [proportionate, effective, balanced
incentives
and disincentives]?
What are the technical implications?
Do those affect the design of networks and services (e.g. by requiring choke-points/Single Points of Failure)?
Originally posted: 16 October 2014 in category
Articles
Herewith first impressions of the Government’s proposal to criminalise “
Revenge Pornography
” since, if it is passed, this will be another type of material that those offering web or other publishing services for user generated content will need to include in their notice and takedown processes. Comments welcome, especially if you think there’s something I’ve missed.
The proposed
amendment to the Criminal Justice and Courts Bill
would ensure it is a crime (
in some cases it already is
) to “disclose a private sexual photograph or film” without the consent of the subject of the photograph and “with the intention of causing that individual distress”. There have been a number of recent instances of people maliciously placing such images on social media, web and other hosting services, so it’s not surprising that the Government want to ensure that when that happens, the hosting service removes it promptly when they are notified.
However unlike other notice and takedown processes (copyright, defamation, etc.) that is slightly complicated by the fact that
intent
to cause distress is an essential component of the proposed crime. A hosting service that didn’t remove material on notification might be able to claim that it had no intention to cause distress, so was innocent of any crime. I suspect that’s why the amendment includes a second version of the crime, which can only be committed by service providers (potentially including those based outside England and Wales). It’s not at all clear to me from the drafting whether the intent to cause distress still applies to that one, but I can’t think of any other reason for including it.
The offence would, however, still be covered by the normal immunities under the E-Commerce Directive. Until a hosting provider has actual knowledge that specific information is a private sexual photograph or film, disclosed without consent and with intent to cause distress, they cannot be guilty of the offence. Once they are informed of those facts, the hosting provider must “expeditiously” remove the information (or disable access to it) if they want to avoid the possibility of committing a crime.
The amendment may need fixing in one other area, though, since although there is a defence if a film or image is disclosed for purposes related to crime there doesn’t seem to be an equivalent defence for other disclosures required by law, for example in the context of civil cases or even under the Freedom of Information Act. I hope that will be addressed in the Parliamentary debates.
And note that the use of “private” in this Bill involves yet another new definition of that term: “A photograph or film is ‘private’ if it shows something that is not of a kind ordinarily seen in public”. So the fact that an image may have already been widely disseminated to the public doesn’t legitimise its malicious use.
[Apologies for the lack of direct references to the text, but there are no section or line numbers in the current draft I can refer to. The main offence appears below the text “After Clause 29” and the Annex for service providers can be found by searching the text for “service providers”]
Originally posted: 15 October 2014 in category
Articles
One aspect of the
Google Spain judgment
I’ve not seen discussed is the incentives it creates for search engines. The European Court of Justice found that under some circumstances Data Protection law entitles an individual to demand that out of date and inaccurate results be removed from the results of a search for their name (the unusual circumstances of the case meant it wasn’t possible to remove the out of date information from the original website). If a search engine fails to remove the link then an appeal can be made to the appropriate national data protection regulator or court. If the search engine does remove the link, even if the relevant circumstances do not apply, then as far as I can see there’s no risk of any legal case being brought. Under UK law, at least, there’s no right to be linked nor does anyone have a contract with a search engine that might be breached by the removal of links. So when a search engine receives a request to de-link, it has the choice between an action that might result in a further legal case and one that definitely won’t. Which would you choose?
As the
Court’s own adviser noted
(at para 133), we’ve been here before. The eCommerce Directive’s rules on intermediary liability create the same one-way bet. When a hosting service receives an allegation that third party material is defamatory or infringes copyright or other law, the host risks liability if it continues to serve the material but none if it removes it. For hosting services there may be a contract with the provider of the information but most of those contain an exclusion from liability when a complaint is made. A research project by Bits of Freedom indicated that most hosts did indeed remove material without full investigation of copyright complaints; the
Electronic Frontier Foundation
suggest that both copyright investigators and hosting companies have automated processes that follow the incentives the law (in that case US law) has created.
I had expected that Google, having lost their ECJ case, would do the same and simply remove any link for which a request was received. The business case for doing so looks clear. That would be particularly damaging for anyone whose business depends on them being found by search – suppose a competitor made an unsubstantiated request to de-link? Such claims have been made in the past against other intermediaries under copyright and defamation law. Not only do search engines have no way to verify that the person making the request has the authority of the subject of the link, the incentives the law has created give them no reason to even try.
In fact, Google don’t seem to have taken that easy way out, but have been publicly raising the issues around the judgment. No doubt they have commercial reasons for doing so: perhaps they consider that deleting links without question would damage users’ confidence in search results. But I’d much rather have public discussion of what society actually needs of Internet intermediaries (for example in articles by
Julia Powles
and
Luciano Floridi
on the
balance of rights
and
jurisdiction issues
) than have intermediaries silently decide that themselves.
UPDATE:
Andres Guadamuz
(technollama) has pointed out that examples in Google’s transparency report suggest that they are indeed taking more care over requests than the legal incentives would indicate. And a
Dutch court
hasn’t blindly followed the ECJ’s simplistic suggestion that the right merely depends on whether or not the person asking to be de-linked is “famous”. Both good news, and I hope examples that others will follow.
Originally posted: 10 October 2014 in category
Articles
I had been planning to write up a summary of my thoughts on
Bring Your Own Device
, but I’m pleased to discover that the UK Government has pretty much done it for me. Their
draft guidance
, just published for comment, suggests an approach along the following lines:
Start by reviewing which information should
not
be accessed from BYOD, and configure networks and servers to prevent access;
Work out with users how the remaining information can safely and lawfully be used on BYOD;
Consider technical solutions to support that user agreement;
Plan to support a wider range of devices than just “corporate issue”;
Add BYOD to your incident monitoring and response plans.
In our research and education sector I expect to find only slight tweaks in stages three and four. I suspect we’ll find mobile device management less appropriate for us than Government (the
ICO
also has his doubts about this software): however high-speed networks mean we are already familiar with virtual terminal systems that avoid the need to store information on mobile devices. And our users already expect our networks and systems to support pretty much anything they bring along!
Interestingly the
Device Security Considerations
also confirm a suspicion I’ve been developing: “If sensible precautions are taken, the impact of compromise of an
unmanaged
device will be similar to the impact that the same compromise would have on a
managed
device”. Once you’ve allowed information to be accessed from a mobile device, the most significant factor affecting its security is how the user behaves (e.g. reading documents on trains!), not how the device is managed.
So let’s “maximise the business benefits of BYOD whilst minimising the risks”!
Originally posted: 2 October 2014 in category
Articles
A couple of sessions at the
VAMP2013 workshop
in Helsinki related to complexity and how best to express it to users. Bob Cowles pointed out that current access management systems can involve a lot of complexity even to reach the binary decision whether or not to allow a user to access a resource. This might, for example, involve the user authenticating themselves to their college, the college checking with a department or project that the requested access was within policy and with the resource provider that it was within budget, and finally releasing to the resource sufficient assured information about the user to identify the right account information. Most users probably don’t want to know that all that is going on, but instead to just express their wish to access content and trust the various organisations involved to do the right thing.
In a later open space session we discussed how far that trust should extend, and when organisations should check with the user before going further. There has been a tendency in software, perhaps encouraged by European Data Protection law, to seek the user’s confirmation for every step in complex processes. That’s generally regarded as training users to automatically click “OK” or “proceed” in answer to every question. Finding the right level of granularity is tricky. I wondered whether there might be something to learn from the medical field where decisions fall into three groups:
those where the patient consents to a complete procedure and its consequences,
those where individual choices are offered, and
those (such as selling a spare kidney) that all doctors must refuse to do, even if the patient orders demands it.
In access management terms that might translate to
doing silently the minimum information transfer and processing that is needed to provide the access the user has requested,
offering optional services individually to the user, and
refusing processing – such as unauthorised uses of National Insurance numbers – that is restricted by law.
The middle, optional, group seems to be where the most detailed information and control needs to be offered to the user. Depending on local laws, preferences and technology the user could be invited to enter their own information (for example an e-mail address to subscribe to notifications of updates), to consent to their Identity Provider releasing the required information, or to select additional services knowing that these will require additional transfer and processing.
Originally posted: 10 September 2014 in category
Presentations
I was invited to give a presentation on
legal and ethical issues around information sharing
at TERENA’s recent
security services workshop
. The talk highlighted the paradox that sharing information is essential to protect the privacy of our users when their accounts or computers have been compromised, but that sharing can also harm privacy if it’s not done correctly. Since there’s increasing interest in automated information sharing, we need to work out rules that we should encode into those systems to ensure that their actions on our behalf do have the effect of improving privacy rather than harming it.
A set of principles seems a good place to start, but the principles written into privacy laws generally assume that individuals can be told in advance what will be done with their information. That may not be possible in network incident response, where an incident response team will often discover indications of problems in a different organisation, network or continent. When you detect an attack, scan or spam coming in to your network, that’s usually a sign that the attacking computer has itself been compromised and that its users have a serious privacy problem. Surveys still suggest that
many incidents are first spotted by teams outside the affected organisation
. To let incident response teams try to help those external users, my suggested principles are a shorter list, designed to protect privacy even when a team has no way to identify or directly contact the individual victim:
Necessity: only share information when doing so is likely to help
Minimisation: only share the information that is needed to provide help
Accuracy: explain clearly how reliable you believe the information to be
Security: keep all information appropriately secure, both in storage and in transmission
The first two principles will be easier to satisfy if, when working to protect privacy, we concentrate on sharing information back towards its source where the privacy problem exists. If the source is within our own constituency, we should fix the problem ourselves rather than sharing it! That’s the opposite direction of information flow from the police/court process, where the focus is on finding out who a remote source is and holding them account. Interestingly, “upstream” sharing has significantly more support in data protection law: if you consider an IP address to be personal data and you receive it without prior contact with the owner then the Data Protection Directive requires you to notify them of any further processing. If the source is outside the EEA, the UK Information Commissioner’s observation that
processing should address the privacy expectations of those countries
, rather than Europe’s, suggests it should at least be no harder to share information back to a non-European source than a European one.
Both the e-Privacy Directive and the
draft Data Protection Regulation
(Recital 39) recognise preventing and responding to security incidents as legitimate interests: processing that is necessary for these purposes is allowed provided it is not overridden by the fundamental rights of the individual. The Article 29 Working Party has recently documented the balancing process that’s required when using the
legitimate interests justification
: my paper for TF-CSIRT suggests how to apply that process to the specific situation of
sharing information about incidents
. Upstream sharing should normally benefit, rather than harm, the individual’s fundamental right to privacy so it should be possible to design sharing processes that satisfy the balancing test. For sharing in other directions the balance may be less clear and sharing may only be appropriate where there is a serious and widespread threat to the security and privacy of others.
The law in this area isn’t as clear as it might be, but using that as a reason not to gather and share incident-related information is no solution. The law is clear that we must to take appropriate measures to protect the security of personal information; the international standard on information security (ISO27002) identifies incident response as one of the key controls needed to do that. Done correctly, incident response shouldn’t be seen as a threat to privacy but a vital tool in protecting it.
Originally posted: 29 August 2014 in category
Articles
A recent discussion got me thinking about what might be the right number of passwords. There are plenty of references that still say you should have a different password for every service, and
breaches such as Adobe’s
last year show why. If you use the same password on two different websites and one of those gets compromised, either by phishing or loss and cracking of a password file, then both accounts are put at risk. So when you hear of one such compromise you have to try to remember which other websites you’ve used that password on, visit each of them and try to work out how to change to a new password.
But, honestly, there’s no way I could remember a different password for every service and website I use every day, let alone all the occasional ones that I need once in a blue moon (and usually have to reset when I want to revisit the site anyway). I’d be surprised if any of our users can, either. So what’s the solution? I hope a couple of relatively new technologies can help…
Single-Sign-On (SSO) is sometimes criticised for having the same “shared fate” issue as reusing the same password on multiple sites. Yes, if your SSO password is compromised then the person who now knows it has the ability to access your accounts on all the SSO services. But there are a couple of key differences. First, the SSO password only needs to be stored (salted and hashed, please) in one place – the SSO authenticator. So there are many fewer opportunities for someone to steal the password file, and the SSO authenticator is a sufficiently critical system that it should be being well managed. Second, if the password is compromised then it can be immediately disabled and changed in a single location: I don’t have to go around all the services individually to do it. And, because the SSO authenticator is a well-managed central point, I’d expect it to have a better chance of spotting any unusual login patterns that follow a compromise too. So for my work accounts SSO, preferably federated so I can also authenticate to other organisations’ systems, looks like a good bet.
That leaves me with all the other external sites I use for information, to book conference places, tickets, etc. etc. Many of them now offer logins using social networks, but I’m not comfortable with the amount of information sharing that that involves. Instead I’m sticking with a unique password for each service, but using a password vault to manage and in many cases generate them for me. That does make the password for the vault a critical part of my security, but that one is much longer than any feasible rainbow table so should be crack-proof. Also (like my federated SSO password) I only ever have to type it into a single, familiar interface so the risk of phishing should be reduced too. If I ever lose access to the vault then I’m back at requesting password resets, which was my fallback position for most of those accounts anyway.
Sadly, although the number of passwords I have to remember is greatly reduced by this approach, it’s not down to just two. Some sensitive services use two-factor authentication, but I can cope (so far) with the small pile of dongles, tokens and phones. But there are some other “password-protected” sites that are neither federated nor usable via a vault. Interestingly, whether they realise it or not, they’ll never know whether I have re-used their password on someone else’s service. At least not until that service gets compromised…
Originally posted: 4 July 2014 in category
Articles
The recent invention of the phrase “Bring Your Own Device” seems to have got educational organisations agonising about something
we’ve been doing routinely, indeed relying on, for at least 15 years
. Whenever you send a member of staff home with some work to do but no laptop to do it on, or provide a webmail service for students, or invite a visiting academic connect their device to your network, you’re inviting BYOD. Most of the time that’s a benefit (imagine how inefficient we’d be if we could only work 9 to 5 in the office, or on corporate laptops the size of small suitcases), sometimes it creates a new risk to information.
Indeed, since people in education are generally smart and innovative, even if you don’t invite them to use their own devices for work, they’ll probably work out a way to do it anyway. Network sockets are fairly easy to connect personal devices to, wireless networks even easier. BYOD is happening, our choice is whether we ignore it or embrace it. So I’d like to propose another meaning for the acronym – Bring Your Own by Design.
Most universities and colleges already design their wireless networks on the assumption that foreign devices (whether owned by students, staff or visitors) will need to connect to them. The
eduroam
service provides a global authentication system for those in education so your wifi network can choose whether to offer no connection (or only local information) to a non-member, a connection to Janet and the Internet to authenticated visitors from other education organisations, or a connection to the internal network for your own users.
So maybe we should also be consciously designing our information services on the same assumption: that our users will be connecting and logging in from their own devices? There are still controls that can be implemented on the server side to manage whether such a device will automatically download a complete mailbox and calendar, only the messages that the user manually selects, or only ‘moving pictures’ of a remote desktop. And since users are already taking information out of the buildings, on paper even if not in digital form, we already need to raise their awareness of the risks of carrying and using information and help them do it safely. In most organisations there will be a few places where personal devices aren’t appropriate because of the sensitivity of the information and systems held there but, again, we should already be pointing out those areas to those who can enter them and requiring special policies and ways of working.
If we’ve designed our systems and processes to remain secure on the assumption that BYO will happen then it shouldn’t be an unpleasant surprise when, just after Christmas or a birthday, it does.
Originally posted: 30 June 2014 in category
Articles
At the FIRST conference this week I’ve heard depressingly many incident responders saying “our lawyers won’t let us…”. Since incident response, done right, should actually support the law’s objectives, it seems we need to be smarter, and maybe a bit more assertive, about explaining how incident response and law interact.
The laws most relevant to incident response activities are those regulating unauthorised access to computers, unauthorised access to communications, and privacy. However hacking, information “theft” and privacy breach are the most frequent incidents that we are called on to defend against. It seems that the same laws that say it’s important to defend against incidents are also the ones that are alleged to be stopping us doing just that!
For longer-standing members of the incident response community, this may sound familiar. When computer misuse laws first appeared, many struggled with the fact that the same tools that system and network managers use to find vulnerabilities in their own systems were also used by “hackers” to break into them. Most laws did eventually get the hang of these dual-use tools and recognise that the same actions might be legitimate or unlawful, depending on how and why they were done. It seems we may need to help lawyers and legislators do the same for incident response activities.
The first step is to investigate the basic requirements of your own laws on privacy, computer access and interception. What do they require for an action to be lawful, rather than illegal? In many cases that will involve having a good reason for what you are doing, doing the minimum necessary to achieve that, and informing users of the system what may happen and why. Some laws also consider your motivation and what authorisation you have. Then design your security and incident handling processes to get as close to that as you can (you are probably already doing a lot of it, as good security practice, anyway), and write down how you address each of the law’s requirements.
Next look at the threats that the law intends to protect individuals and computers from: for example unauthorised access to their data or communications, unauthorised modification of information, or invasion of their privacy. Work out how your security and incident response plan contributes to protecting against those threats. As was pointed out by
Malcolm Harkins
earlier in the week, security and privacy should reinforce each other, it’s only when either is taken to extremes that they become mutually destructive.
Once you have documented how you are protecting your users from the threats the law is concerned with, and what measures you are taking to avoid becoming a threat yourself, then you’re ready to talk to your lawyers. But don’t say “can we..?”: a much more productive approach is “this is what we need to do, this is why we think it’s lawful, can we do better?”. If they point out areas where you might improve, then see if you can implement those. If you can’t then compare the risks that your activities are creating for your users and your organisation with those they will be exposed to if you don’t do security and incident response. A user whose malware-infected computer is being remotely controlled by an attacker who can see every file and keystroke, listen to the microphone and turn on the camera is in a pretty awful privacy situation. Privacy-respecting security and incident response that can reduce the risk of such breaches, and detect and respond to those that do occur, has to be a good thing.
In fact European law already recognises that organisations have legitimate interests that may justify the processing of individuals’ personal data. The amended
Telecommunications Privacy Directive
recognises that those include “include preventing unauthorised access to electronic communications networks and malicious code distribution and stopping ‘denial of service’ attacks and damage to computer and electronic communication systems” (Recital 53). The Article 29 Working Party has recently published a
guide to performing that balance of interests
; some time ago I wrote a paper for TERENA suggesting
how incident response teams could ensure their activities created more benefit than harm
. In my discussions with Data Protection Regulators I’ve been pleasantly surprised how aware they were of the role of security monitoring and incident response in protecting the privacy of internet users. Make that case clearly and you may find there is less resistance than you expect.
Originally posted: 28 June 2014 in category
Articles
Following a couple of talks earlier in the FIRST conference that described how economic forces drive security downwards, it was good to hear a final keynote from Bruce Schneier that suggested that economics may actually encourage the development of high-quality incident response services. Incident response is commonly divided into three phases: prevent, detect, respond. Prevent and detect are increasingly in the hands of others: with a cloud provider you can’t specify specific security measures or monitor detailed activity logs; if your chosen monitoring or prevention solution isn’t in the app store then you can’t install it on your endpoints. Response is increasingly where organisations do have control and where they should be focussing their efforts.
The good news about response is that it doesn’t seem to share the same economics as much of the rest of IT. There high, entry costs, low marginal costs, high switching costs, and information asymmetries between buyers and sellers tend to lead to natural monopolies where competition is less effective at maintaining the quality of products and services. Responding to incidents requires much more human involvement – automated tools can support incident handlers but seem unlikely to replace them – so the marginal costs are higher. Furthermore, a good analyst should be able to work with a wide variety of tools – they’ll often have to – so switching costs are lower. And unlike the prevent and, particularly, detect stages, the quality of a response tool or process is likely to become apparent pretty quickly. This feels much more like a traditional economic market where different ways of doing incident response can be compared, the economic advantages of providing or switching to a better one are clear, and the advantage of being first to market is significantly reduced.
How humans and tools might work together is suggested by a model originally developed for aerial dogfights – the OODA loop. OODA stands for observe, orient, decide, act: the sequence followed by individuals in direct competition with others. And because each competing party (the attacker and the defender in the incident response process) is applying their own OODA loops, the side that gets around the loop quickest and most accurately is likely to prevail. Automated tools can be particularly helpful in gathering and presenting real-time evidence in an intuitive way: the Observe and Orient phases, in incident response often referred to as situational awareness. Decide is the stage that can only be done effectively by a human, though tools can again help automate the Act that they decide on. The effect of (and response to) that Act is the Observe and Orient stages of the next loop.
So a positive message to end the conference: incident response is increasingly important for security, humans are vital to it, and economics should promote the development and adoption of tools that help us do it better.
Originally posted: 26 June 2014 in category
Articles
Many of the talks at the FIRST conference consider activities within and between incident response teams, but two talks today considered how CSIRTs and boards can work better together. Pete O’Dell suggested that many company boards either delegate or ignore information security, perhaps considering that it is “just another risk”. He suggested that information security isn’t a normal risk but requires boards’ special attention because, unlike weather or lawsuits, it is almost impossible to quantify or predict (there are few actuarial tables), is not limited to any geographic neighbourhood and can put the survival of the entire organisation at risk.
Malcolm Harkins suggested that security teams need to understand the risks to their business and ensure that their activities are focussed on addressing them. Security must contribute to the business achieving its goals, not obstructs them. As organisations become ever more dependent on accurate and reliable information, the commercial and ethical imperative to operate securely grows. If security is perceived as getting in the way, users will work around it and leave the organisation blind to the risks that they are incurring. Malcolm’s Intel security team has made this business focus explicit by changing its mission from a general “protecting the organisation’s information assets” to the specific “protect to enable”. Finally, security teams must explain risks and benefits using terms and analogies that board members can understand, not a stream of acronyms.
Board members and executives must, in turn, take a lead in setting the priorities and tone for security in the organisation. So long as a CEO has ‘123456’ as a password, it’s unlikely that the organisation’s information and operations will be secure. Few organisations will have the same security requirements throughout – senior managers must be involved in identifying the crown jewels where the greatest security spend and effort are required, and the internal perimeters (technical, organisational and human) that separate these from less sensitive areas. IT professionals need to learn to express issues in terms of organisational risk: communicating clearly and concisely, and probably in writing; they should suggest proactive measures especially those, such as identifying appropriate replacements for legacy systems, that can significantly reduce risk at low cost.
And since all security measures will sometimes fail, both boards and security teams need to ensure that cross-organisational incident response plans exist and are tested, and that everyone with access to the organisation’s information and systems is trained and prepared to defend them.
#208 - An anthropologist learns about incident response
Originally posted: 25 June 2014 in category
Articles
If you’ve been watching movies and TV series, it may come as a surprise that most computer security incident response actually involves a lot of command line interfaces and perl scripts, and rather few graphical interfaces. That was the first disappointment that greeted a team of computer scientists from Honeywell and Kansas State University who tried to help their local security team with some new tools. The second was that those analysing incidents seemed to rely much more on experience and intuition than on rules or algorithms that might be encoded into software or training manuals. Attempts to interview analysts weren’t a great success either as they objected to the addition into their busy schedules and were reluctant to share what might be sensitive information about their work with those perceived as outsiders.
The researchers then consulted their local anthropologist (apparently most US campuses have some) and learned about participant observation. The security team were offered the services of some interns, to help with programming and other tasks. This worked much better: analysts were willing to talk to the interns about their unresolved problems and when the interns produced tools to address them, these were quickly adopted. Discussions soon widened and the interns were able to learn a lot about incident response from their new colleagues.
What they discovered and reported at the FIRST conference matches my own experience of joining the incident response community and, I hope, helping others to join it through the TRANSITS training courses. Incident responders deal with a lot of sensitive information, so very naturally adopt a ‘need to know’ attitude. To get involved in conversations, whether at a personal or organisational level, you must first demonstrate that you can bring benefits to the team and community: “talking with me is worth the time”. And those conversations are critical, because beyond the basics incident response is something you learn by doing. Much of the knowledge is tacit, rather than explicit, so incident responders couldn’t “write down what you know” even if there were sufficient time. Instead it’s a skill learned through sharing knowledge with colleagues and, eventually, experience. Managers and organisations that want to improve their incident response teams need to find ways to facilitate, encourage and reward knowledge sharing both among the team and with others – without that, shiny new technical tools are unlikely to deliver significant benefits.
Originally posted: 24 June 2014 in category
Articles
There are quite a few talks at the FIRST conference this week about getting computers to automatically receive, process and distribute information about security events. However I was particularly interested in a session on the human issues that need to accompany any such information exchange.
Organisations, which ultimately means individuals, need to trust one another before information exchange can be effective. Providers of what may well be sensitive information need to trust that the recipients won’t misuse it; and recipients need to trust that providers have gathered and analysed the information accurately so they don’t feel the need to redo all the analysis and duplicate the providers’ efforts. Although anonymity is sometimes suggested as a way to start building trust, it was suggested that this actually produces a slower build-up of trust than if individuals know who is providing the information and who is using it. Instead, a trusted exchange may be easier to establish if it is (initially, at least) narrowly focussed on a common problem that all participants want to solve.
Even a collaboration towards a specific goal is likely to need support to establish and build trust. Using (and abiding by) a clear set of rules on how information may be shared is probably the best known tool. Non-Disclosure Agreements are one possibility, and may be needed if there are legal concerns about sharing, but can be too rigid. The ability to attach distribution rules to individual items using the
Information Sharing Traffic Light Protocol
may be sufficient to give providers confidence. A good complement to this is to let the provider of information see who has accessed it, both so that breaches of the rules are visible and, I would imagine, to encourage providers that others found their input useful. Having too many passive consumers (“lurkers” or “sinks”) in any information sharing partnership is unhelpful – if hosts can actively seek these out to find out what is preventing them contributing then this can increase both information flow and trust.
On the information consumer side it was suggested that one of the most useful, but also scarce, resources for any information sharing partnership is someone who can ask the right questions, prompting others to look at, and share, their own information in a new light. Having frequently said myself that sharing needs everyone to contribute, it strikes me that insightful questions might themselves be a significant contribution justifying an individual’s and an organisation’s participation. Recipients of information also need to trust the providers, especially if they are going to make technical or business decisions on the basis of the information they receive. That needs a high level of confidence in others’ human and technical abilities, which may well only be possible if organisations share not only their information, but knowledge of how it is gathered and used.
The goal of an effective information sharing partnership was nicely summarised: computers share data, humans share insights and questions.
Originally posted: 24 June 2014 in category
Articles
A panel session at the FIRST conference on comparable security metrics made me wonder why this seems to be so hard. My first visit to another CSIRT, fifteen years ago, was to work out how to compare our Janet CSIRT statistics with those from SURFnet. And yet the tricky question still seems to be working out what it is you are actually measuring. Most incident statistics actually give you a reasonable idea of how busy the CSIRT is: as with most metrics the absolute values don’t mean much but the trend – whether more or less busy – probably does.
However what most people are looking for is some measure of “network health”, as a better guide for policy making than anecdotes, headlines and fear. That turns out to be a lot harder. One reason may be that most CSIRTs have two sources of incident reports (the ratio between them depends on how close the CSIRT is to a network). Where the CSIRT can monitor traffic on a network or to honeypots it should be able to derive reasonably consistent measures of security events, or at least attacks. An increase in either metric probably means that the network has become a less safe place.
But most CSIRTs also receive incident reports from their customers. While it would be nice to think that those too measure the level of badness on networks, with this year’s
Verizon Data Breach Investigation Report
finding that only 20% of incidents are discovered by the organisation that is the victim, it seems more likely that they actually measure the organisation’s ability to detect incidents. If that’s right then an increase in that metric actually means the network has got safer, as we get better at detecting (and presumably responding to) the incidents that are occurring. So the single figure for “number of incidents” handled by a CSIRT may well combine one trend where increase is bad with another where increase is good. No wonder it’s hard to work out whether an increase in that sum is a good or bad thing!
So it seems that one way to improve the value of statistics would be to keep those derived from direct measurements of networks and traffic separate from those that may actually be measuring the effectiveness of one or more human and organisational detection and reporting steps. In both cases the CSIRT needs to be aware of, and compensate for, any changes it has made that could affect the figures (for example changing measurement technology or rules, or running an awareness campaign to encourage detection and reporting). Then comparing trends between different networks, countries or regions might become a bit more meaningful.
#205 - Dutch national responsible disclosure guidelines
Originally posted: 23 June 2014 in category
Articles
From personal experience many years ago I know the frustration of discovering a security vulnerability in a website, wanting to warn the site owners, but being unable to find a responsive contact to accept the information. However I also know, from even longer ago, what it’s like to be a sysadmin told by a stranger that my precious computer has a bug in it that I urgently need to fix. They no doubt thought they were helping me, but it was awfully tempting to shoot the messenger! I was therefore particularly interested in a presentation of the Netherlands’
national Responsible Disclosure Guidelines
, which try to help both sides in this discussion by establishing some basic ground rules likely to lead to an outcome that benefits both parties.
Having spoken to a wide range of vulnerability researchers, organisations, lawyers, journalists and law enforcement agencies, the Guidelines’ authors identified the key points as establishing and maintaining effective communications, and ensuring that the expectations of both parties are aligned. Thus by adopting the Guidelines, organisations agree that they will act on reports of security issues in a timely fashion (letting the reporter know if normal timescales need to be extended), reporters agree that they will do no more than is needed to identify and accurately describe the problem. Reporters shouldn’t feel they need to actually exploit a system in order to provide “proof” before they will be believed. Organisations need to provide and advertise points of contact – helpdesks and telephone switchboards probably aren’t good places to have these discussions – and neither side should use threats, whether of arrest or blackmail, as part of their negotiating strategy. Organisations are, after all, being offered a very cost-effective penetration test; many reporters will be satisfied to know that they have improved security and delighted to be offered a T-shirt, trophy or site visit (all have been used as rewards by organisations participating in the Dutch scheme) as a thank you.
The proof of any such scheme is in take-up – I was reminded over Twitter of a long-expired attempt to develop a
responsible disclosure RFC
. The Dutch scheme seems to be doing well on this measure, with a much wider range of organisations than expected participating – some developing new internal structures and systems to implement the Guidelines – and even examples of journalists following the process rather than immediately publishing when they receive tip-offs from vulnerability finders who wish to remain anonymous.
Originally posted: 20 June 2014 in category
Articles
It’s often said that technical people are bad at designing user interfaces.
Ken Klingenstein’s presentation
at the TERENA Networking Conference reported (and demonstrated) the results when user interface experts looked at the problem of explaining federated login to users. A striking early finding was that even the interfaces users regularly use to login to services such as Google and Facebook leave them uncomfortable and uninformed about what information is actually disclosed and shared: “consent dialogs do not affect users’ understanding or actions”.
A better starting point may instead be to think about who users are and what their concerns are. Academic studies suggest that there are three attitudes to privacy: fundamentalists (about 25% of the population), pragmatists (~57%) and unconcerned (~18%). And that their concerns can be categorised as excessive collection, secondary use, errors, improper access and invasion. Addressing those questions for those groups of users looks like a good way to explain what our systems are (and are not) doing.
Users can be further helped by providing tools that support their intuitions about privacy. This can be surprisingly simple and subtle: a button marked “continue” (with the alternative being “cancel”) is a very obvious invitation to click with no suggestion that there might be consequences. Just changing the labels to “release my data” and “don’t release” turns out to be much more effective in alerting the user that this is a decision they might want to think about. A
fascinating paper from CMU’s Cylab
discusses these issues, and explains why so many of the warning messages our computers show us are unhelpful or even encourage us to do the wrong thing.
Privacy managing tools should illustrate the benefits of federated access management, in particular moving from disclosure of “identity” – which sounds like “who you are” no matter how much we argue that its technical meaning is different – to disclosure of “attributes” – relevant things about you. But those tools must avoid being perceived, whether the user is a fundamentalist
or
an unconcerned, as “getting in the way”. Smart use of defaults and visual, rather than text, representations help a lot in this. Text information for those who really want to know the details can be provided as popups or links. That way fine-grained control, both of what attributes are released and how often the user wants to confirm/change their settings, can be satisfied through the same interface as the unconcerneds’ desire to “just get on with it”.
These ideas have been implemented in a pilot “Privacy Lens” interface (based on uApprove), a
Cylab demonstration
can be downloaded from the conference website. To a technical person it may not look radically different – it’s managing the same information after all – but tests with non-technical users suggest it should be perceived as significantly clearer and more trustworthy, which has to be a good thing. Future research will investigate how Privacy Lens is actually used, and whether tools such as trustmarks and reputation (“based on your choices for that site…”, perhaps) can build further confidence among users.
#203 - Managing Federated Authorisation for Research
Originally posted: 17 June 2014 in category
Articles
Research, and particularly the on-line collaborative research referred to as e-science, creates a new challenge for federated access management systems. In teaching, the authoritative statement whether an individual is entitled to access an on-line resource comes from their home organisation: are they a member of that course? are they covered by that institutional licence? Thus it is natural to provide a source of authorisation attributes alongside, or even as part of, the home organisation’s authentication systems. In collaborative research, by contrast, the authoritative source of permission is an individual – the principal investigator or group leader – not an organisation and the group to whom he wishes to grant permission are unlikely to all belong to the same institution. This requires a different type of attribute source, which may not be linked to any particular home institution. At the TERENA Networking Conference this year presentations, discussions and a birds of a feather session considered what such an attribute authority might look like.
The basic function of a group management tool is to allow the group manager to select which individuals are members of the group and to allocate permissions among them. In an e-science context the manager is likely to be the Principal Investigator (PI) and the permissions to be managed might, for example, include the ability to read, modify, or create documents, directories or datasets, or to use a portion of the project’s allocation of storage space or CPU time. Providers whose services the group uses should then be able to obtain this permissions information from the group management tool and implement the appropriate technical access rules and quotas automatically, rather than requiring individual manual configuration.
Since the group management service provides the PI’s interface to establish and manage her group of collaborators, two additional functions seem a natural fit. It is unlikely that all the PI’s desired group members will be registered with the group management service, so there needs to be a way for her to invite others to join. This is most often done by e-mail: the PI might, for example, list the e-mail addresses of those she needs as group members, with the system sending invitation e-mails to those who are not already registered. Using an invitation interface even for those who are registered may, in fact, be preferable for privacy and operational reasons, since displaying a list of all registered users for the PI to choose from will rapidly become unmanageable. Some group members may not have federated logins at all, either because their organisation is not a member of a research and education federation or because they conduct their research as an individual. For these individuals – who are selected, authenticated and authorised by a Principal Investigator – the group management system may be the best place to either issue a username and password or to link to an external authentication source such as a social network.
Whereas the functions of Identity Provider and Service Provider are naturally associated with specific organisations, the group management function has
several possible locations
. A presentation by Bob Hulsebosch looked at the advantages and disadvantages of each. A group management service could be provided by the Principal Investigator’s home organisation. This works well where all or most of the group members belong to the same organisation, since the group management service can link to local directories (for example to automatically add “all members of my department”) and policies. For groups that span many organisations, however, this benefit is lost and the home organisation can end up running a complex service with many external dependencies for comparatively little benefit. Requiring all, or most, home organisations to run their own group management service, each supporting only a small number of groups, does not seem efficient. Another alternative is for the group management service to be run by the service provider, since here it can be tightly linked to the service’s own role and permissions systems. However this location means that a group is tied to a particular service; if the same group wish to use another service then the membership is likely to have to be recreated from scratch on that service’s management platform. Finally the group management service could be run as an independent entity, allowing cross-organisational groups to be established and used on multiple services. This would, however, require all relevant identity and service providers to implement common standard interfaces for group management and it appears these are not yet widely available. Since the group management service plays a critical role in protecting the interests of home organisations, services and researchers, the organisation running it must be strongly trusted by all of these.
The
range of software packages currently used for group management
was highlighted in a presentation by Kristof Bajnok. Some have been specifically written for a particular service; others borrow the functionality they need, for example from mailing list managers. A few projects have tried to implement general group management functions, but apparently suffer from a lack of standard ways to communicate group membership information to services: ways of doing this range from mailing unix group files to LDAP or SAML queries. It seems that, at present, anyone considering an independent group management service should plan to spend significant effort on configuring individual interfaces to the services its users want to access. An attempt to improve collaboration between some of these developments is being carried out as a
GEANT Open Call project
, but it seems there is still work to do both on defining what a group management system should do, and on making them a bit easier to work with.
Originally posted: 17 June 2014 in category
Articles
One of the challenges in finding an appropriate legal framework for incident response is that for many types of incident you don’t know in advance what information you are likely to receive. Rogier Spoor of SURFnet discussed one of the most common situations –
cleaning up after a botnet infection
– at the TERENA Networking Conference last month. Although SURFnet’s approach is designed to comply with Dutch, rather than UK, law, it seems a reasonable fit for our legislation too.
Many of those unexpected and rather vague e-mails you receive inviting you to open an attachment or visit a website are trying to persuade you to install a small piece of malicious software, known as a (ro)bot, on your computer. If they succeed then your computer will join thousands of others waiting for instructions from the person who controls the botnet. Bots may be instructed to do many things, including sending spam and launching denial of service attacks; however they are also used to extract information from files, e-mails or user activity on the local machine and send it to some location where the botnet controller can collect it. Sometimes it’s possible for those collections of stolen information to be recovered by incident response teams, who would like to use it to let the owners of the information know what has been taken.
The problem for incident response teams is that they, unlike most botnet controllers, want to act within the law. Depending on where the bots were installed and what they were instructed to collect the information recovered could be anything that was on the infected machines: personal data, credit card numbers, or even medical data. Normally Data Protection law doesn’t allow that kind of information to be handled unless individuals have been informed first, but the incident response team doesn’t know whose information may involved until after it processes it. Fortunately the law does recognise circumstances that require processing before notification, and EU law explicitly says that
incident response is one of those
. However any handling of information must be for a clearly defined purpose, must be limited to what is necessary for that purpose, and must not involve disproportionate risks to individuals’ privacy.
SURFnet’s original approach was simply to inform their customers that a collection of botnet data had been found and where it could be obtained. However this meant that each interested customer had to download the whole collection (probably including personal data of others) without being able to assess whether their portion of the information was sufficiently important to justify either their own effort or the invasion of users’ privacy.
Following discussions with customers and legal experts, SURFnet concluded that they could perform a useful (and lawful) service by obtaining the collections of botnet information themselves, separating out the information associated with each customer’s IP address range, and then informing each customer which of their IP addresses has had information taken and when. Each customer can then decide, based on their own information about the sensitivity of the information likely to have been present on those machines at that time, whether to ask SURFnet to provide the full data for any or all of their IP addresses. Any information that is not requested before a designated deadline is deleted by the team, though of course it may remain available to the botnet controller. This two-stage approach reduces the amount of processing needed to let individuals learn of data losses, while ensuring that such processing as does take place has a clear and limited purpose. It also fits rather neatly with the fair processing requirement in UK law that anyone who obtains personal data other than directly from the individual must try to inform them as soon as possible.
Originally posted: 23 May 2014 in category
Articles
A thought-provoking
talk at the TERENA Networking Conference
by Barry Smyth of the
Insight Centre for Data Analytics
suggested both the possibilities and the problems of big data, and some of the decisions that society needs to make soon about how we do, and do not, use it to maximise benefits and minimise harms. A couple of examples highlight the scale of what might now be possible: the smartphones we have in our pockets have sufficient CPU power to measure our lung function – to within 6% of the accuracy of a clinical device – from the sound of us blowing into the microphone; every six hours humanity generates around an Exabyte of data, that’s roughly the number of words uttered by the entire human race, ever!
With that amount of data and processing power, it turns out that algorithms no longer have to be particularly good in order to extract valuable information from messy and diverse input. In education, universities are already using data from libraries, VLEs and other student histories to identify students who may have problems keeping up with their course. Areas of teaching and materials that are unclear become obvious if 2000 students on a MOOC all give the same wrong answer to a question. Algorithms can use students’ current performance to identify who needs help and what sort of additional support will give them most benefit, increasing top grades by more than 25% in some studies. Conversely there is a risk that inappropriate interventions may cause significant harm; Professor Smyth suggested as a guideline that big data should only be used to fill in the gaps in our knowledge, not to override the decisions that humans are best placed to make.
Larger datasets create the possibility of “listening to signals from the crowd”. Previously unknown side effects of drugs were identified by correlating 82 million queries entered into search engines by 6 million users. High resolution real-time maps of air pollution can be derived by connecting sensors that report when asthma inhalers are used with simultaneous location data from their users’ mobile phones.
These types of application hint at the ethical challenges now emerging. Health and location are highly sensitive aspects of personal data, yet by analysing them it’s possible to warn others of temporary environmental conditions that could trigger anything from discomfort to serious medical harm. Leaving it to individuals to decide whether and how to make their contribution to their own, or society’s, big data may not be the best approach when both the potential benefits and harms, both short- and long-term, may be hard to assess and explain. In those circumstances individuals’ choices may easily be both too generous and too restrictive for their own, and society’s, good. In medicine there are already some decisions that are taken out of our hands: the law does not allow us to decide to sell our own organs, nor to keep secret the fact that we have a notifyable disease. Analysis of big data is now approaching those levels of benefit and harm to society: there are, or soon will be, things that systems can, but should not, do. Society needs to decide soon where the limits should be drawn.
#200 - Is there a “Right To Be Forgotten”? I don’t know
Originally posted: 22 May 2014 in category
Articles
A number of people have asked me what the recent European Court judgment in the
Google “right to be forgotten” case
means; here’s why I have been answering that I don’t know!
The case concerned a fifteen-year old article in a Spanish newspaper about a named individual who had got into financial difficulties. The individual, whose circumstances are now apparently different, asked the Spanish courts to order under Data Protection law that the article be removed from the newspaper’s on-line archive and that Google must stop linking to it. The national court concluded that the newspaper was not required to remove the article, but asked the European Court’s view on whether Google might be. That court has now made its ruling, which almost all commentators seem to regard as a simple “yes”, and that the court has therefore found that a “right to be forgotten” already exists under European law.
My problem is that the
Court’s judgment
doesn’t seem to make clear where in law that right is to be found. They refer to three requirements of data protection law:
personal data must be accurate;
personal data must not be kept longer, or in greater quantity, than is required for the purpose of processing;
the legitimate interest of an organisation in processing personal data may, on occasion, be overridden by the interests of the individual whose data are processed.
The first two of those ought to be simple questions of fact, applying equally no matter who the person is. If information is wrong, or you no longer need to keep it, you must correct or delete it. However the Court’s discussion says that the right to delete isn’t equal – it “may vary, in particular, according to the role played by the data subject in public life” [para 81]. That doesn’t seem to match either the “inaccurate” or “unnecessary” reasons for deletion.
The
Court’s own press release
talks mostly about a balancing test between the rights of the individual and those of the search engine and the readers of the article. That sounds more like the third, legitimate interests, argument. However the court also says that the right to deletion does not require “that the inclusion of the information in question in the list of results causes prejudice to the data subject” [para 96]. If the individual is not going to suffer any harm, then how can they “win” a test of balancing interests?
Chris Pounder
is the only commentator I’ve found who looks at this angle and his argument seems sound to me. It’s just that everyone else seems to be reading the case the other way!
I just hope that when the case returns to Spain, the court there makes a better job of explaining its reasoning, so I can work out how it might apply to different circumstances.
[UPDATE] The UK Information Commissioner says “
there is no absolute right to have links removed
“, and that Data Protection Authorities will be working together to produce guidance “to ensure search providers take the right approach”. That’s good news, but the guidance needs to be clear and simple for search engines to follow, otherwise there is a risk that they will simply delete
any
link that is the subject of a complaint. That ‘allege and takedown’ response was sufficient of a problem under defamation law that a
new Act had to be passed
last year to restore the balance of incentives for hosting providers. It would be a waste if this judgment now recreated the old, unbalanced, legal position for a diffferent group Internet intermediaries
and
for those who want to make, and find, critical statements online.
I was recently invited by the
Groningen Declaration Network
to join a panel discussing privacy issues around the exchange of digital student records. Like the discussion, this summary is a collaborative effort by the panel team.
Two main use cases were discussed during the meeting: transferring records between education institutions when students apply to or take courses at other institutions, and providing statements of student achievement to support their applications for jobs or other appointments. There is an increasing need for these to work internationally: the Organisation for Economic Cooperation and Development expects eight million students to be studying outside their home country by 2025 and some countries already have more than 20% of their student body coming from overseas. The Dutch education ministry estimates that each overseas application costs €450 to process.
Opportunities
The motivation for the Groningen Declaration Network was recognition that existing paper-based processes are unsatisfactory: inefficient and with significant risks. Transferred paper records can go astray in the post or be entered incorrectly (even associated with the wrong student) when they arrive; the more people and processes involved, the greater an opportunity for errors. Transcripts may be misinterpreted or may not contain the information the recipient needs. Degree certificates can be copied or forged, damaging the reputations both of the issuing organisations and those students who obtained their qualifications legitimately. If the information were transferred in digital form then existing technologies might offer ways to adjust processes and ‘documents’ to significantly reduce these problems. For example:
A digitally-signed degree certificate could be effectively unforgeable: non-graduates couldn’t claim to have a degree and graduates couldn’t improve their own results. This should also avoid endless processes where an employer asks for a letter confirming the validity of a certificate, then requests confirmation that the validity letter was itself genuine… (apparently this does happen!);
Digitally-signed certificates can be relied upon even if they are not obtained directly from the authoritative source; they can be verified without contacting the issuing institution every time. This could allow new patterns of information flow, for example a graduate might not have to reveal to their university just how many job applications they have made;
Digitally-expressed qualifications could provide different granularities of information. Some processes may only need to know that a qualification was awarded, others may need more detail or supporting information. Stanford University is developing PDF transcripts that include explanations of course content and links to the student’s work in an institutional repository. Transferring students between educational institutions may need even more detailed information, for example to allow a ‘home’ institution to award appropriate credit for study elsewhere;
Digital transfers of information should be less likely than paper to go astray; organisations and individuals could use cryptographic techniques to ensure they are delivered to, and only readable by, the intended recipient.
As well as these benefits for privacy and efficiency, the effect of digital systems on existing threats to privacy needs to be considered. For example:
Digital systems for storing or issuing information need to be protected against attack by technical means, particularly if they can be accessed and attacked over the Internet. A large collection of digital information may increase the impact of a successful attack by exposing more records, however security measures are often more efficient at large scale so those running large systems should also be more able to implement appropriate protection. Conversely if digital qualifications are held by individuals it may be challenging to identify a format that is both safe on consumer devices and does not suffer from compatibility issues;
Existing paper systems are already subject to “
blagging
” attacks, where people with no right to see information attempt to persuade human operators to release it. Where organisations exchange digital information between their computer systems it should be possible to establish strong technical measures to ensure that this only occurs with proper authorisation, though such approaches need to cope with both large and small flows of information. The Erasmus programme includes around 4000 institutions, but some only exchange 25 students a year. Verification of certificates by third parties is more challenging, since it may not be possible for the institution to verify their identity or authority to receive the information. In these cases individual graduates may be better placed to control who they wish their information to be disclosed to;
Processes involving collections of “big data” can raise concerns that the holder of the information has different incentives to those of the individual data subjects. In the cases of student application/transfer and qualification verification the institution and the student appear to have a strong shared interest in making the process quick, accurate and efficient. Both processes will normally be triggered by some action by the student (e.g. applying for a place or job) so there is an opportunity to inform them of the resulting data transfers before they occur. A clear explanation of the obvious direct benefits for all parties should minimise concerns. If student/graduate information is used for other purposes these also need to be clearly explained and justified to avoid the risk that these may damage trust in the core functions of the digital system.
Choices
Digital systems have the potential to support many different architectures including central depositories, portals linking institutional systems, clearinghouses or information held by individuals. Different applications may well suit different architectures. Each architecture will also have its own implications for privacy – both intended and unintended – because of what the choice implies for what information is stored, exchanged and disclosed, and by whom. Complex architectures may run the risk of “ethical dilution”, as those further from the source may be less aware of the constraints on how it should be used. The implications of data, data flows and information about them (often referred to as “metadata” and carrying its own significant privacy issues) should be carefully considered early on in the design process.
For example, consider a credentials checking company that verifies the validity of student credentials on behalf of potential employers. If such a company represents many employers, it may learn a lot about the number and type of job applications by an individual. Government organisations may be interested in this type of data from a completely different perspective: social security. If, for instance, those that rely on social security must apply for a certain number of jobs to qualify for benefits and/or if they have to accept jobs below their level of training or education after a certain amount of time then accessing this kind of metadata may be tempting. Choosing instead to package digital student credentials as ‘tokens’ that can be validated without third party intervention might reduce the creation of this kind of metadata, but involve more work for employers and more inconvenience for users if they lose their token.
It can be hard to foresee which other uses data exchange – or metadata deriving from the data exchange – may have, especially if you are concentrating on functional goals. During the discussion we concluded that there is a parallel here with the different perspectives that software and protocol designers have from those taken by ethical hackers. Designers have a constructivist view on systems whereas ethical hackers look at systems with an eye for how they can exploit features of the system to gain elevated privileges or access data they should normally not be able to access. Perhaps, when considering the exchange of personally identifiable information an ethical hacker should also look at the proposal to consider what other uses the exchanged data (or metadata generated by the exchange) can have.
Conclusions
The conclusion of our discussions, both in the panel session and in informal conversations afterwards, suggested that technological tools exist that could improve the effectiveness, efficiency and privacy of exchanges of student data. The challenge is to identify which processes can obtain most benefit from the many technical possibilities. Although we should aim for inter-operability in the long term, it may still be too soon to commit to formal standards. New developments should, perhaps, be approached in the “skunkworks” style, with organisations being prepared to scrap or replace developments that turn out to be unsuccessful. Members of the Groningen Declaration Network are already conducting various pilot studies to identify promising areas and are committed to sharing the results of these at future meetings. It was suggested in particular that including stakeholders (including students) in these pilots might help identify approaches that are more likely to succeed.
The Network is also developing a set of privacy/ethical principles to inform its work, to ensure that students/graduates remain aware and in control of what is done with their information and that the information is treated appropriately by all those who have custody of it. Systems should never contain unpleasant surprises, but this should not depend solely on “notice and choice”. Ethical considerations may indicate that some options be excluded as a matter of principle, even if some users might be persuaded to agree to them. And, as the security field has discovered, asking users to “agree” too often trains them to be click-happy and not give due consideration to the choices that really matter.
#198 - Legitimate Interests and Federated Access Management
Originally posted: 24 April 2014 in category
Articles
I only wish the Article 29 Working Party had published their
Opinion on Legitimate Interests
several years ago, as it could have saved us a lot of discussion in the federated access management community.
Any organisation that processes personal data needs to have a legal justification for this; in access management that applies both to Identity Providers and to those Service Providers that receive personal data. UK and EU law provide six possible justifications (listed in Article 7 of
Directive 1995/46/EC
) but none of them is an obvious fit for federated access management. “Consent” might look OK, since the user has requested access to the service, but both UK and EU law are rightly nervous about whether an employee (or a student with a deadline to meet) is really in a position to give “free consent” if refusing may harm either their job prospects or their study outcome. Similarly “necessary for a contract” (either of education or employment) might be OK, but are all the pages you access via federated access management strictly “necessary” for your job/study?
For a while I’ve been wondering whether the
“legitimate interests” justification
might be the way out of this problem, and the Working Party seem to confirm that:
…an appropriate assessment of the balance under Article 7(f), often with an opportunity to opt-out of the processing, may in other cases be a valid alternative to inappropriate use of, for instance, the ground of ‘consent’ or ‘necessity for the performance of a contract’. Considered in this way, Article 7(f) presents complementary safeguards – which require appropriate measures – compared to the other pre-determined grounds. (p10)
So what are those “complementary safeguards”? The legislation says “except where such interests are overridden by the interests for fundamental rights and freedoms of the data subject” (Art 7(f)). Expanding that, the Working Party describe it as a balancing test: the stronger the legitimate interest being pursued by the data controller and the less harm the processing does to the interests of the data subject, the greater the likelihood that the activity will be lawful. Interestingly
The purpose of the Article 7(f) balancing exercise is not to prevent any negative impact on the data subject. Rather, its purpose is to prevent disproportionate impact. (p41)
Strong legitimate interests include those recognised as fundamental rights, in the public interest, or norms in the community concerned. The impact on the individual will depend on the nature of the personal information, how it is processed and what the individual would reasonably expect. It can be reduced by safeguards such as data minimisation, privacy enhancing technologies (for example pseudonyms), transparency and a right to opt-out. Those claiming legitimate interest should be able to explain their interest and how it satisfies this balancing test.
In the federated access management case it seems to me that both Identity Providers and Service Providers have a legitimate interest in providing the service that their users have requested. The need to provide information about the current user (in particular that they have authenticated) is generally recognised. The impact on the individual should be positive rather than negative, fully in line with their expectations – they are getting the service they requested – and most federation rules restrict any unexpected secondary uses. Data minimisation and privacy enhancing technologies are encouraged by the federated model: service providers can provide user accounts without needing to know anything about individual users. And there is the possibility of opting out by not accessing that service.
Relying on legitimate interests still means users have to be informed about what their personal information is being used for: transparency is required by both general data protection law and the legitimate interests balance.
The Working Party describe legitimate interests as a
balanced approach, which ensures the necessary flexibility for data controllers for situations where there is no undue impact on data subjects, while at the same time providing sufficient legal certainty and guarantees to data subjects that this open-ended provision will not be misused. (p10)
Indeed I’d suggest that the case-by-case analysis required by the legitimate interests justification might even provide better protection than trying to squeeze processing into a pre-defined justification that doesn’t fit, where the pre-defined safeguards may also be stretched to, or beyond, breaking point by the attempt. As the Working Party make clear, legitimate interests is neither a last resort justification nor an open door to processing: for some situations it provides the most appropriate protection for everyone’s interests.
Originally posted: 14 April 2014 in category
Articles
At present only public telecommunications providers are required by European law to notify their customers of security breaches affecting their privacy, including breaches that the confidentiality, integrity or availability of personal data. In the UK the Information Commissioner has published
recommendations on handling privacy breaches
, including when to notify those affected. Requirements to notify privacy breaches are, however, contained in a
number of draft laws
currently being discussed by the European Parliament and Council, including the draft
Network and Information Security Directive
, draft
eSignatures Directive
and the draft
Data Protection Regulation
.
The formal effect of the Article 29 Working Party’s new
Opinion on Personal Data Breach Notification
will depend on the outcome of those legislative discussions. However its discussions of various breach scenarios are already useful in identifying the kinds of impact a breach may have and, in particular, the sorts of technical and organisational safeguards that organisations can put in place to reduce those impacts. According to the working party, these include
Data Minimisation
Pseudonymisation
Least Privilege
Awareness Raising
Vulnerability Management
Code Review
Encryption (provided state of the art algorithms are used and keys kept secure)
Salted, hashed password storage
Shredding (and other forms of secure disposal)
Backups
Incident Response
None of these should be unexpected but it’s helpful to have them all recognised as contributing to privacy protection. The wide range of the measures also highlights the need for organisations to use a variety of tools, chosen to provide a consistent level of privacy protection. Relying on a single tool, or a single part of the organisation, is likely to leave information open to other types of attack.
Testing for, and exploiting, well-known vulnerabilities in networked systems now requires little or no technical expertise as point-and-click testing tools are freely available. The best known of these led Josh Corman to propose “
HDMoore’s law
“, that the capabilities of the Metasploit tool now define a minimum acceptable baseline for technical security. Wendy Nather then suggested that this establishes the security “poverty line”. Any organisation that cannot maintain its systems’ security at or above this level – whether because of insufficient patching, technology, knowledge, manpower or willpower – is unlikely to be living sustainably on the Internet: instead it is in security debt.
And, like financial debt, security debt grows at a compound rate. The more trivially-exploitable vulnerabilities there are, the more effort the organisation will spend cleaning up after incidents, the less effort will be available to remove vulnerabilities, and the more vulnerabilities there will be. As with financial debt there are a number of ways out of this downward spiral: most are unattractive but the history of IT includes examples of all of them. The organisation (or its staff, by finding other jobs and incidentally making the situation even worse) can declare security bankruptcy; the organisation can struggle on until its customers or suppliers decide it is no longer safe to work with; the organisation can spend more money, though this is unlikely to be enough as security debt isn’t just about not having enough “blinky lights”; the organisation can change its way of operating to bring it up towards the poverty line, and it can be innovative in how it thinks about, and does, security to reduce or eliminate the deficit.
Clearly these last two options, probably in combination, are the best option for an organisation that wants to escape the vicious spiral and get back to a sustainable position. And, as Rodrigo Bijou commented via Twitter,
viewing security as something that contributes to the organisation’s products
, rather than just its compliance process, can bring benefits to the organisation and a much greater sense of achievement to all those involved in security. Indeed once you are in security profit, it strikes me that that may have a compounding effect too!
#195 - Passive DNS: improving security and privacy
Originally posted: 4 April 2014 in category
Articles
[Updated with further information and suggestions provided by CSIRTs: thanks!]
One incident response tool that seems to be growing in value is passive DNS monitoring, described in Florian Weimer’s
original paper
. As described in the references at the bottom of this post, patterns of activity in the Domain Name System – when names change, move or are looked up – can be used to give early warning of phishing campaigns, botnets, malware, and more. And this is achieved with a negligible impact on the privacy of Internet users.
DNS is sometimes described as the phone book of the Internet: it’s the distributed public database that lets us humans type in
www.bbc.co.uk
and our computers know that they need to contact the much less memorable 212.58.244.71. If DNS is all the phone books in the world, then passive DNS monitoring is a bit like a traditional reference library where you’re asked not to put books back on the shelf so that staff know which books have been referenced but not who read them or which other books that individual read. Similarly, passive DNS records only what questions were asked the Domain Name System and what the answers were at the time (in my example the pDNS record would be “6/3/14 15:30:21
www.bbc.co.uk
A 212.58.244.71″). Any information about the source of the question or anything that could link it to other DNS questions I might ask is either not collected at all, or immediately discarded.
A couple of examples show why even that information can be very useful. If the answers to “where is
www.bbc.co.uk
?” suddenly changed country then we might wonder whether something had gone wrong. If a previously unknown IP address is suddenly of interest to many different computers and its domain name looks like
my-online-banking-service.we4se8934ds.com
then we might suspect that a new round of phishing e-mails have just been sent. Although there may be legitimate explanations for these kinds of unusual patterns, they definitely highlight things worth further investigation.
Logging IP addresses may seem to raise issues around protecting personal data but the kinds of information collected by passive DNS should not involve privacy or compliance risks:
No information is logged about either the individual who made the query or their computer so there are no identifiers or patterns that could be used to link queries to those who made them;
The great majority of DNS queries, and therefore of the answers logged by passive DNS, are for the IP addresses of multi-user servers (web, e-mail, etc.) that are not associated with an individual person;
The proportion of responses relating to client machines can be further reduced if organisations exclude queries for local names and addresses from their passive DNS logs. If one of the organisation’s own addresses is behaving strangely then it should fix the problem, not just log it!
Everything logged by passive DNS is extracts from public databases maintained by those responsible for the addresses and names.
These precautions cannot completely eliminate the possibility of processing personal data. For example if an organisation names computers with public addresses after their individual owners then these are likely appear in the public DNS database and may be captured by a passive DNS sensor. Such “user-assisted” privacy infringements are, however, a necessary consequence of a technique that is very effective in helping incident response teams detect and mitigate the much greater privacy breaches that result from the phishing of bank account credentials. Both the
e-Privacy Directive
(Recital 53) and draft Data Protection Regulation recognise incident detection and response, protecting both systems and data, as a legitimate reason for processing personal data; the minimal processing of personal data involved in passive DNS should be considered clearly proportionate to that aim.
It may be possible to further tune passive DNS systems to exclude records that are unlikely to be relevant to incident response or carry a higher privacy risk. For example:
not recording error responses, which may include typing errors that expose private data (see
Merike Kaeo’s paper
for how this can happen);
not recording responses from DNS servers known to return wildcard responses to requests containing typos;
not recording (or at least not sharing) responses involving private IP addresses or other DNS data not intended to be available on the public Internet;
recording only specific record types known to include indicators of common problems (e.g. A, AAAA, MX, NS).
This does, however, mean that there will be no historic data available if the excluded records do subsequently turn out to be needed for a specific investigation.
Any organisation or network that (unlike Janet) runs its own DNS resolver can collect passive DNS data from it. However the value of passive DNS data increases if it is shared, since patterns such as the start of a phishing campaign are easier to detect with data from a large range of internet locations. Aggregating records also further reduces privacy risk as runs of duplicate records can be reduced to counts: “between times X and Y there were N queries for
www.bbc.co.uk
that returned 212.58.244.71″. Passive DNS sharing is an excellent example of a technique that improves both security and privacy.
Presentations and papers on using passive DNSIn order of increasing technical complexity:
#194 - Information Security Updates at Networkshop
Originally posted: 2 April 2014 in category
Articles
A strong common (and unplanned, honest!) theme emerged from the information security session at
Networkshop
yesterday: that information security, or information risk, is ultimately the responsibility of individual users. Only they can decide which documents it is safe to read on a train, which phone calls they can make in a public place. The role of information services departments should be to help organisations develop the structures, policies, processes and technologies that make it reasonable to expect users to take that responsibility, increase the likelihood that they will exercise it correctly, and deal with the occasions when they don’t. In that way information security becomes an enabler, helping the organisation to achieve its objectives. The alternative approach of trying to “do” information security for users will, at best, mean the organisation misses opportunities to benefit from its data and people, and at worst that we create incentives for users to work in unsafe ways.
Bridget Kenyon explained how organisations and projects can use ISO27001 to identify information risks and appropriate mitigations, and to comply with other standards and requirements. Sean Duffy reported on Birmingham’s experience of enabling users to make the right security decisions. I spoke about how this approach could be encouraged by new requirements to deliver appropriate security for research data throughout its lifecycle.
The other thing we all agreed on was that universities and colleges are complex places and that ‘enterprise’ approaches that try to impose the same security requirements on everyone are very unlikely to be appropriate. Instead we should be focussing on the information, systems, and activities that present particularly high risks. UniversitiesUK’s recent paper on
protecting sensitive research data
and RUGIT’s
assessment of the SANS/CPNI Top20 controls
provide a good basis for identifying those risks and controls.
#193 - Level of Assurance: are we approaching a limit?
Originally posted: 11 March 2014 in category
Articles
I’ve had several conversations this week that related to what’s commonly referred to as “level of assurance”: how confident we can be that an account or other information about an on-line user actually relates to the person currently sitting at the keyboard. Governments may be concerned with
multiple forms of documentary proof
but I suspect that for most common uses in the education sector that may be over-complicating things. So long as the link between a human and their account is made by a traditional, static, password, and provided that password achieves a pretty basic (though still
by no means universal
) level of non-guessability, it seems to me that the main factor affecting level of assurance may well be how the user behaves with their password.
Once we improve beyond passwords that are open to simple or brute-force guessing, significant threats to the integrity of the link between the human and their account are password sharing and phishing. The risk from both of these depends almost entirely on the user’s behaviour: additional password complexity, stronger proof of real-world identity, etc. don’t help. There are plenty of anecdotes of students sharing passwords with one another, of researchers sharing certificates, and of both falling for phishing attacks. Nonetheless static passwords seem to be good enough for most purposes in both our professional and personal lives: the general level of behaviour, backed up by measures to detect and recover from account compromises, seems to produce a level of risk that both users and service providers find acceptable. The only sector that seems to have changed its standard form of authentication is banking – to access my bank account on-line I need to know a password
and
be in possession of a particular physical device. Using two factors to authenticate reduces the risk of compromise, even without a change in behaviour, but at some cost to users in convenience and considerable costs to the bank in providing and supporting all those hardware tokens.
If we want to reduce risk without moving to two-factor authentication, can we change users’ behaviour, or is it a limit we have to live with? The Anti-Phishing Working Group has an excellent
campaign to raise awareness of phishing
and help users avoid falling for it. But the prevalence of account sharing probably depends on our instinctive perception of how valuable sole use of the account is. That value may not be what we (as service providers) expect: a long time ago I was surprised to discover that what persuaded students that sharing passwords was a bad idea wasn’t giving away the ability to read files or access computers, it was handing a “friend” the ability to send a perfectly-forged e-mail to a tutor or boy/girlfriend! Nowadays we are moving towards single-sign-on, where one password gives access to all our on-line services and accounts. That’s more convenient for the user and allows service providers to quickly secure all the affected accounts once the user realises they have made a mistake. By analogy with the real world, it seems to me that increasing the number of things accessible ought to increase the perceived value of the password and make us more careful: I’m happier to lend someone the key to just my house or just my car than I would be a master key that gave access to both. I’m not aware of any recent surveys that might confirm that idea. If not, it may be that we’ve reached the human limit of what can be done with static passwords. If that’s right, then if that limit isn’t sufficient for your application you may need to look at the cost and acceptability of two-factor authentication.
I reckon the education sector accepted user-owned devices (now known as Bring Your Own Device)
at least fifteen years ago
, the moment we provided remote access and encouraged staff and students to work outside the office. My talk at the Janet/Jisc services day in London therefore looked at how we can do it better, suggesting a three step plan. Your comments and experiences on these ideas would be very welcome:
1. Recognise BYODThe biggest concern with BYOD is that ‘company’ information will be stored on devices owned by employees or students, and thereby be exposed to greater risk. So the first step is to identify where our systems or processes are likely to result in off-server storage. Users may transfer information manually if our processes encourage them to take local copies or work at home; or it may be done automatically by client software that creates an off-line cache or backup. Both of those can be an advantage if we want people to work whenever they have a good idea, even if they don’t happen to be ‘in the office’, and for non-sensitive data those copies may not create additional risks. But where local storage isn’t necessary, or we can provide the same function in ways that don’t require it (e.g. remote desktop services), then it may be possible to reduce it. If local storage is needed we should aim to ensure that it is encrypted and, if possible, that it can be remotely wiped if the device is lost. Many of the issues here are common to all mobile devices so the same solutions may make managed mobile devices more secure as well. One difference is that you can’t insist on wiping or crushing a user-owned device when it is no longer used – the Information Commissioner suggests at least changing any passwords that may have been stored on a device that may be sold or handed down to a relative. It’s also worth identifying and documenting the information and services that
shouldn’t
be available off-site; some may be suitable for managed devices but not user-owned ones, but remember that many security risks (such as reading the wrong file on a train) apply to all forms of portable device, no matter who manages them.
2. Improve BYODI’ve written previously that
BYOD may create opportunities
: modern portable devices support a lot of security technologies, and users ought to be motivated to use them to protect their own information on the device at least as much as to protect their employer’s. The ICO’s excellent
Guide to BYOD
has a list of good practices, all of which look like common sense to me to protect my own information and bills (my summary: passphrases, patches, anti-virus, firewall, safe downloads/configuration, account/directory separation, and viewing information in safe places). If we can help and encourage device owners to do those to protect their own information then any corporate information gets protected too as a side effect. If, having had this simple good practice explained, security measures are still “too inconvenient” for a device owner to protect their own information (which probably includes passwords for e-banking, social networking and personal photographs) then those devices probably aren’t a safe place for the employer’s information either.
3. Adopt BYODUniversities and colleges hope that their users don’t just work in the office, 9-5, but whenever and wherever a good idea occurs. Given that work pattern, BYOD feels like something that we ought to be designing in to our systems and processes. That involves providing guidance and support to users in some of the harder questions: how to backup devices in ways that are safe for both personal and organisational information; how to use wireless and other untrusted networks safely; how to assess security when installing new applications and software. In designing our systems, perhaps we should even be
assuming
BYOD use (“Bring Your Own by Default”?), unless particular information or services are unsuitable for it? I suspect our users may already expect that all systems will be accessible from their devices and many of them are innovative enough to put that expectation into practice. In most cases that will have benefits for the organisation and we should be encouraging it: where it creates unacceptable risks then we need to explain clearly why this system is an exception and users shouldn’t try to work around our security measures.
#191 - EU Parliament committees on Network and Information Security
Originally posted: 3 March 2014 in category
Articles
The various committees of the European Parliament have now published their
response
to the Commission’s
draft Network and Information Security Directive
. Their proposal is much more narrowly focussed than the Commission’s: public administrations are excluded (though individual Member States are allowed to opt theirs in), as they already “have to exert due diligence in the management of their network and information systems” while the Commission’s broad category of “market operators” is reduced to something that looks much more like traditional critical infrastructures: “infrastructure[s] that are essential for the maintenance of vital economic and societal activities in the fields of energy, transport, banking, financial market infrastructures, internet exchange points, food supply chain and health”. Adding internet exchange points suggests a view that that connectivity is now vital to society but social networks aren’t.
The committees are explicitly positive about CERTs and their “existing international and European cooperation networks … which have proven efficient in coordinating international and European responses to incidents”, and concerned that regulatory change must not disrupt these. Rather than the Commission’s proposal for a single “national CERT”, the committees want to ensure that the designated sectors have at least one CERT providing services to them and that those CERTs have sufficient resources to work together both nationally and internationally. To facilitate this there is a suggestion for agreed standards for both technical and procedural interactions.
The committees agree with the Commission that incident reporting is important for improving security but see it as part of developing a “culture of risk management, close cooperation and trust, involving risk assessment and the implementation of security measures appropriate to the risks and incidents”. They also seem aware of some of the ways that reporting schemes can fail, particularly if those reporting do not gain any benefit or are even disadvantaged by their participation. Thus there is a stress on exchange of information between participants, not just one-way reporting; those who report incidents should, where possible, be offered help to resolve them; bodies to whom incidents are reported must consult with reporters before making information public and consider “possible reputational and commercial damages” that might discourage reporters from sharing in future.
The European Parliament is
expected
to vote next week on whether to accept this report, with subsequent discussions likely to be interrupted by the Parliamentary elections in May. Security improvement needs to be seen as a virtuous spiral, from which everyone benefits: these proposals seem to be heading in the right direction.
The Information Commissioner considers that identifiers pose a higher privacy risk if they are “interoperable”. Since the examples given are names, addresses and telephone numbers I think this refers to the range of additional uses to which such an identifier, once collected or disclosed, can be put. For example an e-mail address may be collected as a login name, but it can also be used to send unsolicited e-mails. Using a hash function to derive a non-interoperable identifier is given as an example of how to reduce this risk. Risk is also higher for identifiers that can be used to match information about a single individual on different systems or different organisations.
The standard identifier
recommended by the UK Access Management Federation
, eduPersonTargetedID (ePTID) is low risk on both counts, since the normal way to generate it involves hashing both information about the user and the particular service they are accessing. It therefore prevents matching across either services or organisations, as well as having no “interoperable” uses.
The Information Commissioner doesn’t favour multiple categories of “personal data”, “pseudonyms”, etc., as proposed by the European Parliament to deal with this range of different risks. Instead he recommends a single category with the regulatory burden on organisations being be proportionate for those that use lower-risk identifiers. This should provide both an appropriate level of privacy protection and an incentive for organisations to adapt their systems and processes to use lower-risk identifiers where possible.
Interestingly the Commissioner notes that using low-risk identifiers makes it more difficult – even impossible – to obtain verifiable consent because the whole point of these identifiers is to prevent direct identification (or recording) of the consenting individual. It strikes me that consent management could even be seen as a form of “interoperable” additional use that creates a higher privacy risk than the processing itself requires! Instead the Information Commissioner suggests that legitimate interests will often be a more appropriate and reliable basis for processing of this type of data. Legitimate interests can provide a justification for processing so long as the processor’s interests are not overridden by the fundamental rights of the individual which, when using identifiers that are low-risk by design, is unlikely to occur. When relying on legitimate interests, users still need to be informed what their personal data will be used for but services don’t need to insert an extra interaction to seek consent. The design of the identifier and the legal requirement to protect fundamental rights (including privacy) should give sufficient protection.
Originally posted: 14 February 2014 in category
Articles
The recent
TF-CSIRT meeting
in Zurich included a talk by the Swiss telecoms regulator (like ours, called Ofcom, though their ‘F’ stands for Federal!) on the law covering websites in the .ch domain that distribute malware, normally as the result of a compromise. Under this law a designated authority can order the temporary or permanent suspension of such a domain; where the domain registry has evidence of a problem it may itself suspend a domain for up to five days though a warning is generally given first and suspension will usually be shorter if the site owner removes the malware. This has proved successful in
reducing the prevalence of malware
on Swiss websites and the risk to users from threats that their anti-virus systems do not yet detect.
Unlike proposals by Nominet to use registry contracts to
deal with malware
and
other alleged criminal activity
in the .uk domain, the Swiss scheme is based in specific Telecommunications law, giving it a very precise scope and objectives. In Switzerland, unlike the UK, domain names are considered “addressing elements” so the telecoms regulator has the same power to regulate their use as, for example, telephone numbers. Telecoms regulation can, however, only be used for objectives that are within the remit of the telecoms regulator; regulation of domain names used unlawfully in areas such as banking or medicines would have to be done by the regulators of those sectors under their designated powers and objectives.
to further the interests of citizens in relation to communications matters; and
to further the interests of consumers in relevant markets, where appropriate by promoting competition.
This means that although the Swiss telecoms regulator could, if it wished, propose laws addressing other types of harmful content, it could only do so where the harm relates to communications matters. Malware that infects citizens’ computers clearly does, wider forms of content-based “censorship” that some in the audience were concerned about wouldn’t.
I’ve always felt that the operation of the
Swiss anti-malware scheme
struck a good balance between the interests of domain holders and those of internet users. It seems that its legal basis also gives clarity to the registry while limiting the possibility of mission creep.
Originally posted: 11 February 2014 in category
Articles
Most portable devices – laptops, smartphones and memory sticks – should be encrypted so that the information they contain is protected if the device is lost or stolen. Many countries (including the UK) give their immigration and other authorities legal powers to demand that you decrypt an encrypted device though given the number of laptops that cross borders every day only a tiny minority seem to be subject to such demands. The possibility of decryption being required does mean that you and your employer should assume that a laptop may have to be decrypted when travelling: any information (for example personal or commercial) that you don’t want to have disclosed to foreign authorities should be removed before you leave. The
UK Information Commissioner’s guidance
indicates that this should be an extension of routine practice, laptops shouldn’t contain unnecessary information anyway:
As long as the [personal] information stays with the employee on the laptop, and the employer has an effective procedure to deal with security and the other risks of using laptops (including the extra risks of international travel), it is reasonable to decide that adequate protection exists.
A few countries’ laws go further and place restrictions on the use of encryption. Travel advice from the
UK Foreign Office
and
US State Department
should warn if taking an encrypted device to a country is likely to cause problems. If you are concerned about taking an encrypted device to a foreign country then leave your normal laptop and phone at home. If you need to communicate while you are away take a freshly installed basic device with no encryption and minimal data on it; assume that it will be compromised and malware installed while you are away so don’t use it for any sensitive information or connect it to any protected networks; wipe and re-install it at the end of your trip. Personal data of EU residents shouldn’t be stored on an unencrypted laptop but the
Information Commissioner suggests
that it may be acceptable to store information from those you meet while you are away as they will be used to local, rather than EU, data protection laws:
Where information has been obtained in a third country (i.e. outside the EEA) this will be a relevant factor as the data subjects may have different expectations as to the level of protection that will be afforded to their data than if the information been obtained in the EEA. Where the country (or territory) of origin of the information is outside the EEA it is important to remember that the DPA is not intended to provide a different level of protection for the data subjects rights than that provided by the data protection regime, if any, in the non-EEA country of origin.
Organisations whose staff regularly travel to these countries may find it worth maintaining a loan pool of ‘travelling’ laptops and phones, ensuring that these are wiped and reinstalled between each trip.
Originally posted: 10 January 2014 in category
Articles
As a privacy-sensitive person, I’m concerned that the trend in European Data Protection law seems to be to place more and more weight on my consent as justification for processing my personal data. In theory that sounds fine – given full information and a free choice, I can decide whether or not I’m willing for the processing to take place. Except that in most other areas of law when an individual interacts with a business, the law presumes that it isn’t safe to leave those decisions to the individual because they probably don’t understand all the consequences and they may be pressurised into a decision. Consumer law – and Europe has a lot of that – is all about helping me escape the consequences of decisions that seemed like a good idea at the time. Medical and criminal law go even further and define areas (e.g. to sell my “spare” organs) where I am simply not allowed to make a decision even though I am the only person affected.
The
first draft of the Data Protection Regulation
seemed to be following that approach – according to Recital 34 “consent should not provide a valid legal ground for the processing of personal data, where there is a clear imbalance between the data subject and the controller”. Instead the controller needed to find some other justification that legislators and regulators had either pre-authorised (e.g. “necessary for a contract”) or made subject to conditions (e.g. “not overridden by fundamental rights”). However among amendments that were otherwise seen as enhancing the protection of individuals, the
European Parliament’s draft
deleted that qualification, apparently restoring the current EU position where businesses and employers may be able to “encourage” individuals to give consent (English law retains its long-standing unease about “consent” between employee and employer).
Like the current law, the Parliament’s draft does give individuals the right to change their mind, withdraw consent and terminate further processing. But if the harm that I now regret consenting to has already happened, that’s probably not much comfort.
In fact current data protection laws already contain the outline of a four-step scale that, if used more generally, could provide much better support for individuals than a simple consent/no-consent one. Governments and regulators could authorise (by creating statutory duties/permissions or recognising “legitimate interests”) or prohibit processing at the two extremes of the benefit/risk scale. For decisions in the middle a hint could be given by requiring either an opt-out or opt-in approach, as in the e-Privacy Directive, which requires opt-out for postal marketing but opt-in for e-mail. Complex decisions (e.g. “
may we keep a record of your browsing history in order to offer you personalised pricing?
“) might be better addressed by regulation, leaving consent for the simpler ones where individuals are less likely to be unpleasantly surprised by the consequences.
In computer security we learned long ago that asking users for permission too often results in them clicking “OK” to everything without thinking about the consequences at all. Consent seems to carry a similar risk: if I’m asked too often to “consent” to things that are blindingly obvious (either “yes” or “no”) then I’m unlikely to think about, or even notice, the occasions when I ought to be giving the question serious thought. Using consent less often might lead to better decisions when we do.
Originally posted: 3 January 2014 in category
Articles
The Ministry of Justice have now published
detailed instructions for website operators
who want to use the
new
Defamation Act 2013
process
to handle allegations that third-party postings are defamatory. The instructions set out clearly what information needs to be in each of the communications sent and received by the website operator, and they seem to cover nearly all possible circumstances.
The only situation that UCISA and Janet pointed out that doesn’t seem to be covered is if a complainant repeats their complaint about the same posting before the process has been completed, either by the post being removed or by the complainant obtaining either a
Norwich Pharmacal
Order to force disclosure of the poster’s details. As far as I can see, the operator still needs to forward those repeat complaints to the poster, and the poster needs to repeat their response to the operator. But repeated complaints
before
a post is removed don’t count towards the “repeated publication” threshold so they can’t be used to force the operator to remove a posting more quickly.
Next year Janet will be celebrating its thirtieth anniversary. This made me realise that it’ll also be twenty years since I was first involved in incident response, dealing with attacks against “my” web and email servers at Cardiff University. Over that time the purposes of incident response have stayed pretty much the same: to reduce the number of security breaches where possible and to reduce the severity of those that do still occur. But the range of services and people that need to be involved in doing that has grown far beyond what I could have imagined.
For a recent talk at
ENISA
I sketched out my personal six ages of incident response or, if you prefer, a six layer model. The latter is actually a better way to think about it: these aren’t stages that incident response has passed through, they are nearly all still going on in parallel. And I’m sure there will be more to add in future.
The
host layer
. When I first worked on security, it felt like a one-to-one contest between the attacker and the system administrator. As sysadmin, I controlled all the systems I cared about so they should all have been equally well defended. When a vendor or the CERT Coordination Centre announced a software patch it was my job to edit and recompile the relevant programs or operating system! My aim was simply to make the attacker go away. Groups of sysadmins informally shared information about defensive and attacking techniques.
The
network layer
. After a while it became apparent that attacks were no longer coming directly from the attackers’ machines. Instead they were ‘hopping’ from one compromised machine to the next, presumably to hide their traces. That meant that the systems attacking mine were themselves be victims of a previous attack; they might still have genuine customers on them who needed to know they had a problem. Some IP address ranges did advertise abuse or CERT contacts to whom reports could be made but many didn’t. CERTs and incident responders built their own address books for hard-to-reach networks. If you needed to contact someone then you might be told how or a message might be passed on – a lot of people were doing incident response without it being formally part of their jobs so were cautious about disclosing the fact too widely.
The
operational layer
. To this point attacks had been done by individuals typing commands into their computer: if they were hopping through your computer you could often see traces of them doing it, including typos! But when someone came up with the idea of automating attacks, defenders needed to communicate a lot more quickly. Unlike telling someone that they have a problem with their computer, reporting that you are experiencing a worm or DDoS attack means sharing information about your own current vulnerability. So you don’t just have to find and communicate quickly with the people who can make your problem go away, you also need to trust them not to misuse the information you reveal in ways that will increase rather than decrease the damage.
The
law enforcement layer
. Incident responders have talked with the police for as long as there have been computer crime laws. But formal involvement came more recently, with the realisation that dealing with attacks purely as a technical matter was just teaching attackers how to do it better. Only the possibility of sanctions against individuals seemed likely to make them stop. But the police and CERT worlds are very different: police and their communication channels are generally organised in national hierarchies whereas CERTs talk much more directly, often directly across borders; the objectives of prosecuting an attacker versus getting a service quickly back into operation may conflict; even the way we describe an event may be different, creating plenty of opportunities for mis-communication.
The
legislative layer
. And then we discovered that laws are different and that attacks that are crimes in one country may not be in others. Even in some European countries, unauthorised access may only be a crime if it involved circumventing a protection mechanism such as a password or firewall – not true in the UK, by the way. And laws must allow incident responders to do their work. As a principle that seems to be understood by law-makers – it’s even in a recital to the draft Data Protection Regulation – but explaining how details of proposed changes in data protection, interception and computer misuse laws could unintentionally make lawful incident response impossible is now taking up quite a bit of my time.
The
cloud layer
. With the most recent community to join the incident response world, we’re back at a technology layer. But it’s a different layer. Whereas most incidents follow the topology of networks so the existing contacts between network operators are often useful, with clouds and other types of overlays that’s no longer true. Incidents can, and do, propagate in ways that don’t reflect the underlying network topology. It may also be hard for one layer to interpret an incident without help from the other – even whether a large traffic flow
is
an incident or a successful experiment – which increases the risk that actions taken by incident responders at one layer may interfere with those taking place at another. Understanding the communications we need to deal with incidents in overlays is still a work in progress.
The
next layer
… may be industrial control systems, or internet of things, or…
With each new layer a similar process of enlarging the community has taken place. Initial contacts have been made with individuals; discussions have taken place to understand their field’s interests and language. As it became clear how to incorporate the field into incident response, work has been needed to increase trust – often helped by actually working on incidents – and to expand awareness and coverage within the new field. Eventually this knowledge may be formalised into working procedures, training and benchmarks: a stage that ENISA is now reaching with
law enforcement
.
I don’t see any sign of these developments stopping any time soon. We’re still working to understand the interactions with clouds and lawyers and I’m sure that other fields will be identified before long. Incident response is never routine: it’s a challenging and increasingly important area.
#184 - Defamation Act 2013 – in force 1st Jan 2014
Originally posted: 17 December 2013 in category
Articles
The Government has recently
announced
that the
Defamation Act 2013
will come into force in England and Wales on January 1st 2014.
Section 5 of the Act
addresses a couple of problems that have particularly affected Janet customers who operate websites.
First, the concern that moderating postings from third parties might give rise to liability if the moderator failed to spot a problem has been reduced. Section 5(12) says that defences to defamation claims aren’t lost merely because you moderate. Unfortunately that doesn’t affect other claims, for example of copyright infringement, where the position under UK and EU law remains unclear.
The general aim of section 5 is that legal action for defamation should normally be between the person claiming to have been defamed and the author of the comment to which they object. Thus if the author can be identified sufficiently to bring legal proceedings against them, section 5(2) ensures that the operator of a website can’t be sued for something written by a third party author.
Otherwise a website operator still has the options provided by existing law: to remove any third party content that is the subject of a defamation complaint, or to leave content up in the belief that it isn’t unlawful. In the latter case, of course, they may be held liable if a court subsequently disagrees.
However section 5 also creates possible a new course of action for website operators who would prefer to have a court decide whether an article is unlawful defamation or legitimate free speech. This is likely to be of particular interest to universities and colleges who have a legal duty to protect free speech by their members and guests. It does, however, require a specific series of actions on a relatively tight timescale so organisations that wish to use it need to prepare.
Details of the required process are contained in the
Defamation (Operators of Websites) Regulations 2013
. The following is a summary of how it should work in the situation where the author wishes the article to remain on the website:
Website operator receives complaint: must acknowledge the complaint and forward it to the author of the article;
Author responds, providing contact details and asking for article to remain on the site;
Website operator notifies the complainant that author wishes the article to remain and has provided contact details that are not obviously false; if the author does not wish their contact details to be released to the complainant the site must not do so.
At each stage the operator must act within two working days, the author must act within five calendar days.
Once these stages are complete it is up to the complainant whether they wish to sue the author (if they agreed that their details could be released), ask a court to order removal of the material (under s.13 of the new Act), or ask a court to order the website operator to disclose the contact details (under the existing
Norwich Pharmacal
process). This makes it the job of the court, not the website, to balance the complainant’s right to reputation against the author’s rights to privacy and free speech.
If, at any stage, the author does not follow the procedure then the site needs to remove the article and inform the complainant to keep this defence; if the website operator does not (or cannot, e.g. if they cannot contact the author) follow the procedure then this defence is lost and the operator will need to inform the complainant and switch to one of the existing options. To prevent articles being simply removed and republished, the Section 5 process can only be repeated twice for any given article: the third time, the article is simply removed on complaint without contacting the author.
While this process is undoubtedly more complex than the existing notice-and-takedown approach, for those articles where the balance between free speech and defamation is unclear it allows universities and colleges to have their legal position clarified by a court without risking liability.
Originally posted: 13 December 2013 in category
Presentations
Presenting at the Jisc’s Safer Internet Day event got me thinking a bit more about the shared interests between owners and organisations in a BYOD scheme, and the opportunity that might present. For many years I’ve liked the idea of helping users be safe in their personal Internet lives (where motivation should be a matter of self-interest, rather than “having to comply with policy”) and improving workplace safety as a side-effect. BYOD is an ideal place to do that, since company and personal information are on the same device and protected (or not) by the same behaviours of the device owner.
Thinking about mobile devices, there seem to be five main areas where safe behaviour makes a difference; at least the first three of these have benefits on non-mobile devices too:
Backups
: saving the right information to the right place at the right times;
Security
: knowing how to use passwords etc. to protect access; how to download software and documents safely; how to use patches, anti-virus, firewalls and choose the right configuration options; how to detect when things go wrong;
Separation
: using different accounts and directories/folders to separate information; when to use encryption and what not to view or discuss in public places;
Wiping
: knowing when and how to trigger remote wiping of a device (getting backups right makes this less of a nuclear option);
Location
: knowing when and how to use remote device location to increase the chance of getting lost hardware back.
For BYOD I suspect that organisations probably need to set the rules for wiping and backups, though those rules may still say that the owner does them. Wiping is the ultimate protection for the organisation’s information on the device and, as one
council recently discovered
, getting backups wrong may be the easiest way for the owner to expose that information to unwanted risks. Security and separation offer opportunities to
balance
what the owner is prepared to do against the information and services they are allowed to access from the device. A benefit of making this trade-off explicit should be that if the user understands that certain information requires a level of intrusiveness that they don’t want, there should be less temptation to work around the prohibition. Providing wiping is done, location of a BYOD device seems to be entirely the owner’s choice: it’s their device, after all! That’s a good thing, as the ICO expressed serious concern about potential
misuse of location/tracking functions
on a device that might be expected to be borrowed by the owner’s family or friends.
Originally posted: 13 December 2013 in category
Articles
The House of Commons has published a useful
summary of progress
on the
Defamation Bill
, which will return to Parliament next week. Clause 5 of the Bill proposes changes to the current regime for websites hosting allegedly defamatory postings from third parties. When it was last discussed in the House, before the summer, concerns were expressed that the Bill:
should not move to American model “where free expression always trumps other concerns”,
should not inadvertently require websites to disclose identity of whistleblowers, and
should not websites to be easily censored by casual threats of litigation.
The Bill proposes that there should be an approved process that website hosts can follow after receiving a complaint without incurring liability, but leaves details of this process for secondary legislation. In the Committee stage of the Bill a number of amendments were suggested to include details of the process in the Bill itself, but these have so far not been accepted. Although the Government did identify one possible process (that the website host would inform the poster of the complaint and ask if their contact details could be disclosed, but that the complainant would have to seek a court order if this request was refused), it also stated that it would consult with relevant stakeholders before deciding on the actual process to be adopted.
Clause 10 protects someone who is “not the author, editor or commercial publisher” unless it is impractical to take legal action against one or more of those. It was noted in committee that website operators might fall under both Clauses 5 and 10, and that the interaction between these clauses might need further consideration.
The third reading debate in the Commons may indicate whether Parliament feels any changes are needed following this detailed consideration of the Bill.
#181 - Clouds and the draft Data Protection Regulation
Originally posted: 25 November 2013 in category
Articles
At the moment both cloud computing providers and their business customers in Europe have to deal with at least twenty-eight different interpretations of Data Protection law. And there are nearly as many different national rules and formalities when using non-European cloud providers (the UK approach is described in the Information Commissioner’s
Guide to Cloud Computing
). The current process to develop a European Data Protection Regulation should reduce this divergence as there will be a single law applicable across all member states and national regulators will be able to grant approvals that take effect across the EU. Getting to that stage is taking a long time, as it requires the European Commission, Parliament and Council of Ministers to agree on a complex legal text. Recent publications suggest that the Commission and Parliament have different ideas on how that law should deal with cloud computing.
When the Commission published their
first draft last year
they declared it “cloud-aware”, containing and developing most of the existing legal provisions that are used to support cloud computing. Indeed
Binding Corporate Rules for Data Processors
, which had been developed under the authority of the Article 29 Working Party, appeared for the first time in (draft) law.
By contrast the
European Parliament’s recent response
seems to foresee a different approach, suggested last year by the
EU Data Protection Supervisor
, which would rely much more on providers or contracts being approved in advance by national authorities. The process for obtaining continent-wide approval should be simpler, as it will no longer involve consulting every national regulator. But it will require providers to be willing to seek authorisation and regulators to find resources to grant it (a
concern
that has been expressed by the UK’s Information Commissioner). European businesses who are unable to obtain approval in the two years between the passing of the law and its coming into force (currently foreseen around 2017) may be trapped without a lawful source of the infrastructure they need to provide high-quality cloud-based services to their customers.
Fortunately NRENs such as Janet have already established
relationships with major cloud providers
, who have been willing to adapt their services and agreements to meet our customers’ requirements under current data protection law. The Commission have recently rejected any “
fortress Europe
” approach to cloud computing. So if a future Data Protection Regulation were to require a different approach to compliance we expect that our existing relationships and agreements would let us help both providers and customers find the best way to achieve it.
Originally posted: 21 November 2013 in category
Articles
It has long been a source of frustration that if a Janet connected site wanted to provide connectivity to members of the public this required a separate physical network link to connect those users to a partner Internet Access Provider. Members of the public can’t be given access to the Janet IP service as this would risk changing the network’s status as a private Electronic Communications Service under the
Communications Act 2003
. There could also be damage to the network’s reputation since measures used to enforce the Janet AUP against staff and students are unlikely to work for transient visitors.
Commercial wifi hosting services, and the legal interpretation of them, have now developed to the point where a segregated point-to-point tunnel across Janet may be an acceptable alternative to a separate physical link. This is subject to five conditions, set out in a revised version of the
Janet Eligibility Policy
:
The point-to-point tunnel must be established from the Janet customer’s premises to an Internet Access Provider (for example a commercial ISP) with whom the customer has an agreement;
The tunnel must be encrypted between its endpoints, so that no traffic from members of the public is carried on Janet in plaintext form;
Users of the service must be authenticated, either by the Janet customer or its partner Internet Access Provider;
Traffic from members of the public, when routed to the public Internet, must be identified as originating from the partner Internet Access Provider, not from Janet or the customer;
The customer and Internet Access Provider are responsible for compliance with any relevant laws and policies applying to public Internet access, for example on logging and filtering.
The first two of these conditions ensure that public traffic is clearly segregated, so the legal status of Janet should not be affected. The third and fourth protect the reputation of the Janet network. The fifth ensures that legal obligations for public network providers are not imposed unnecessarily on Janet or its customers.
Customers providing Internet access for members of the public should note, however, that network segments or devices that carry unsegregated public and private traffic are likely to be subject to those obligations. For example both the
Regulation of Investigatory Powers Act
(regulating access to content) and the
Privacy and Electronic Communications Regulations
(regulating use of traffic data) have different rules and penalties for public networks. Local area networks should therefore be designed to segregate the two types of traffic as soon as possible.
Several commercial companies provide wifi hotspot services that piggy-back on existing IP connectivity, which may satisfy the Eligibility Policy requirements. The requirements can also be achieved using suitable configurations of common networking devices if a Janet customer wishes to partner with another organisation acting as a public Internet Access Provider and can do so in a way that is compliant with
State Aid law
.
#179 - Life-long identifiers in Research and Education
Originally posted: 19 November 2013 in category
Articles
There are several situations when it would be useful to have a life-long identifier that doesn’t change when we move house, employer or even country. Most of us already have life-long identifiers to link together all our interactions with the health service and the tax office; in research and education linking together our achievements would also be useful when preparing a CV or research proposal. However these applications have very different consequences if the link between individual and identifier fails; they also need to resist different types of threat. When using a life-long identifier it’s important to know the types of problem it was designed to address and be particularly careful when moving beyond those. Indeed in the UK both tax and National Health Service identifiers are restricted by law to the purposes for which they were originally designed.
In the offline world the authority responsible for each identifier still tends to send out pieces of paper to inform us of our tax or NHS number; we can then show those pieces of paper to service providers if required. Online it’s more usual to log in to the authority’s database and either obtain service from them, or have them vouch for our identifier value to a third-party service provider. Rather than remembering where we put the vital piece of paper we need to remember the password to log in to the authority.
Processes for Identifiers
In any system of identifiers enrolment – when a new identifier is created and allocated to a particular individual – is a critical process that establishes what reliance subsequent users can place on the identifier. Life-long identifiers are also likely to need to be transferred or linked between authorities since few of us have a life-long relationship with a single authority: without leaving the UK I’ve attended six different educational organisations under three different national education authorities! The transfer/linking process as I and my identifier move from one authority to another needs to preserve the level of confidence established by the original enrolment.
Designing an
enrolment
process involves two main questions: do you need to know who someone is in the real world? And does it matter if one person has more than one identifier? For some applications it may be sufficient to know that a series of on-line actions were performed by the same person, and acceptable that they may have performed other actions under a separate identifier. If so, it may be possible to do enrolment entirely on-line. For health and taxation that’s not good enough so their enrolment processes must include real world checks of “identity” and “same person”. For research and education, it probably depends on the application.
Processes for
transfer
of an identifier can create risks even if the owner’s identity doesn’t matter. I might well be interested in boosting my own publication record by claiming to be a prolific researcher who has moved institution. Weak on-line transfer processes have been used to
take over e-mail and Twitter accounts
and even
domain names
by forging a transfer request that appeared to come from the legitimate owner. Note that taking over an identifier can result in harm to the rightful owner, the organisation issuing the identity, or others who may rely on it. Probably the best way to transfer an identifier is to have the owner log in simultaneously to their old and new accounts and authorise the transfer or link between them, but this has to be done in what may be a narrow time window when both accounts exist.
Even having a single authority and allowing a person to have multiple identifiers is unlikely to avoid the need for secure processes during the lifetime of the identifier. If multiple identifiers are accidentally created for the same individual they may want to
link
or
merge
them; if the individual loses or forgets their password there needs to be a
password reset
process to re-establish the link between them and their account. Each of these processes needs to address the same risks as during transfer or linking, and provide an equivalent level of protection, in order to maintain confidence that the identifier is still controller by its intended owner.
In addition, of course, each authority needs to ensure that the systems issuing and using the identifier have adequate technical and organisational security to resist technical or social engineering attacks on the authority and its users.
What’s the risk?
The risk to any life-long identifier depends very much on what it is used for and what incentives that creates for someone to try to misuse it. Incentives to misuse may not be limited to the academic community: criminals have found ways to make money from processes for
grants
and
loans
, and by
reselling fraudulently obtained services
. The following scenarios suggest how some possible uses of life-long identifiers in education might be misused.
Using a life-long identifier to index publications doesn’t appear to create much incentive to misuse, though there might be advantages for my status if I can claim a Nobel Prize winner as joint author on one of my papers! However if the quantity or academic standing of ‘my’ papers is used as a basis for awarding grants, contracts or employment then there could be a financial motive to ‘borrow’ the status of others.
Using a life-long identifier to monitor or report usage of a resource can create various incentives. If there is a free trial period for each new identifier then there is an obvious incentive to create multiple identifiers; conversely if there is a bulk discount then I do better to share my identifier with others.
Charging against any identifier creates an incentive to quote another person or organisation’s identifier value so they get the bill.
As in the criminal examples above, using an identifier to authorise access to valuable processes or data creates a correspondingly large incentive to attack the identifier and the authorisation process. Competitors and campaigning organisations have been willing to expend a lot of time and effort, not always lawfully, to get access to raw research data. If that can be done by guessing the password for my identifier or forging a message to transfer control of my account then it seems likely that they will try.
Each of these examples involves a different type of misuse that the processes around the identifier must protect against. Those processes must provide a consistent strength of protection, as a mis-user will simply exploit the weakest link. Identifying the right strength involves a balance: too lightweight and the system will not provide sufficient assurance, too heavyweight and it will either not be used or will encourage workarounds such as password-sharing that undermine the intended assurance. Making this choice effectively determines what types and intensity of attack the system will protect against, and therefore what applications the system is, and is not, suitable for.
Once the cost of attacking a system has been designed in by the choice of processes and technologies, it is very hard to increase it without starting again from scratch. New applications must therefore be careful not to raise the benefits of attacking the identifier system to near or above that cost. Once the potential gains justify the cost of running a phishing campaign, forging a transfer request, cracking passwords or hacking servers, then someone will do it.
ORCID
With these thoughts in mind I’ve been looking at the best known life-long identifier in the research world:
ORCID
. According to its website, the main purpose of ORCID is to avoid confusion between people with the same or similar names:
As researchers and scholars, you face the ongoing challenge of distinguishing your research activities from those of others with similar names. You need to be able to easily and uniquely attach your identity to research objects such as datasets, equipment, articles, media stories, citations, experiments, patents, and notebooks.
The ORCID home page says you should be able to create a life-long identifier in 30 seconds (mine took a bit longer because I was studying the excellent privacy statement!). It’s clear that this is designed as a lightweight process, suitable for widespread adoption. In fact the basic ORCID process contains no assurance of an individual’s real-world identity: since the purpose is to distinguish people whose real-world identities may cause confusion, that’s actually quite logical! What ORCID does provide assurance of is that a series of claims made by an ORCID identifier were made by the same person. And, provided users choose good passwords and use them safely, that assurance should be pretty good.
With the basic ORCID system, all claims about an identifier (the name of its owner, the claim that the owner was the author of that paper, etc.) are self-asserted by the owner with no external check. Perhaps surprisingly, for indexing and even low-levels of charging, that may well be sufficient. So long as you can send an invoice to the same ORCID identifier as ran up the bill, then it may not matter who the person actually is. Indexing of publications may even be self-correcting: the purpose of ORCID is to reduce confusion, so it would be paradoxical for someone to register an ORCID and then try to use it to create confusion. Furthermore claims to authorship are public and ORCID has a challenge process to dispute claims that the academic community think are untrue.
ORCID are introducing a process for third-party verification of claims so, for example, my employer could publicly confirm the claim that my ORCID does belong to the Andrew Cormack who works for Janet, and who was joint author of RFC3067. That could be useful for the original name de-confliction purpose (“Ah,
that
Andrew”) and perhaps to give service providers confidence that there is a third party who may be able to compel me to pay my bills. But the process for registering a verifier needs to be different from the one for registering a basic ORCID identifier, otherwise I could simply create another Id, claim it belonged to “Janet” and then use it to verify my claim to work for “them”. Processes relating to verifiers do need confirmation of identity that isn’t just self-asserted, and need to be strong enough to preserve that confirmation through transfers, links, mergers and password resets.
So as far as I can see, ORCID seems well designed for the problems it’s intended to solve. It’s quick and easy to use, and can provide the level of assurance needed to distinguish scholars and (given an appropriate verifier process) to verify their claims to authorship. But the idea of using ORCID as the gatekeeper to permit or deny access to valuable data or resources worries me. That application greatly increases the incentive to attack the ORCID processes and technologies. Probably those processes and technologies could be strengthened – you could build a system around face-to-face identity vetting and two-factor authentication – but that would sacrifice the ease of use that is critical to ORCID’s main purpose.
Originally posted: 30 October 2013 in category
Articles
I’ve had a few discussions recently where people talked about the ‘new risk’ of Bring Your Own Device (BYOD), but then mentioned risks – loss/theft of device, use in public place, etc. – that already exist on organisation-managed mobile devices. Turning that around, it struck me that one way to develop a BYOD policy might be to start from the mobile device policy you already have. I’d be interested in comments on how this approach might work.
And if you don’t think you have a mobile device policy, check if you have some official laptops or phones, or provide a webmail service. If so, then how you provide and manage them is likely to have established a
de facto
mobile policy, and maybe even a BYOD one, even if it’s not written down!
A mobile device policy can be summarised under four main headings:
Which services and information you make accessible from mobile devices;
What controls are implemented on the servers and networks providing those services;
What controls are implemented on the mobile devices themselves;
What controls are implemented by the users of the devices.
For a mobile device policy each service or information that you make available is protected by the combination of controls implemented by the server, the device and the user. That protection is presumably sufficient for the organisation’s risk appetite, otherwise the service wouldn’t have been made available on mobile devices in the first place.
With BYOD the server, network and user controls are the same as for mobile. The only difference is that rather than the organisation managing the controls on the device it has to rely on the device owner to do it. That may still be sufficient, particularly where owners know that the same behaviour will protect their own information on the device. If it isn’t then the organisation either needs to compensate by strengthening the other controls (presumably those on the server and network) or else decide that that particular service or information can’t safely be provided on BYOD.
On the server side there are several different options for providing mobile access. Here they are illustrated with access to e-mail, but similar approaches can be used for calendar, filestore and most other types of information service:
Don’t provide the service at all: e-mail can only be accessed from fixed desktop machines;
Provide the service as a virtual desktop or application: the organisation’s virtual desktop includes an e-mail client where the organisation can limit functions such as local save and ensure that anti-virus is kept up to date;
Provide a web interface: indeed webmail may now be the norm for many Internet users;
Provide a dedicated application: for example providing e-mail access as part of a campus smartphone app;
Permit access from a native application: i.e. allow remote access to the mail store by the native e-mail clients on smartphones, tablets and laptops.
At each stage the users’ control increases so information security becomes more dependent on their behaviour and the controls implemented on the device itself. In particular if the service is provided to an application running on the device, then information is likely to be automatically cached there too. This enables off-line access, which may well be convenient or essential, but also increases the impact if the device is stolen. Though, of course, even a tightly-controlled virtual desktop can’t prevent a user reading a sensitive document on a crowded train.
How the organisation chooses to provide a service therefore influences the controls that are needed on the device itself. Depending on the device and the software it runs, some or all of the following may be available:
Password/PIN to prevent a casual passer-by or thief from obtaining immediate access to the information;
Encrypted communications (e.g. TLS/SSL) to protect passwords and other sensitive information transmitted across networks;
Encrypted storage to protect stored information against more determined thieves who can remove disks to another device;
Remote wipe to reduce the opportunity for information on a lost/stolen device to be misused;
Separate application containers to reduce the threat from other, possibly malicious, programs running on the same device;
Controls on what applications can be installed or run, to prevent unauthorised or insecure use;
Monitoring of use, or of information transferred on or off the device;
Remote discovery of the location of the device.
These don’t map directly to the server-side categories, though decisions on one side to affect the requirements on the other: for webmail it may be sufficient if devices have a PIN and encrypted communications; for a native e-mail client with off-line storage that storage may need to be encrypted and capable of being wiped remotely. CPNI have a paper on the
technical controls likely to be available on mobile devices
and Intel have a paper on deciding which information and services require which BYOD controls, available from
http://www.intel.com/IT
.
Once you have written (down) your mobile device policy, extending it for BYOD should just be a case of reviewing the controls you need on the device. The same server and network controls are still available and you still have the same reliance on users/owners behaving securely with information. Since you are relying on owner behaviour already it may be acceptable to rely on the owner to manage some of the device-side controls, too. But some controls may need to change if:
The control isn’t available, for example the owner’s chosen device may not support separate containers for applications;
Relying on the owner to implement and manage a control may be too great a risk;
The control may be unsuitable for a BYOD setting, for example the
Information Commissioner’s BYOD Guide
expresses concern about employers monitoring the usage or location of a device that the owner may well lend to members of their family (the list of device controls above is roughly in increasing order of intrusion into the owner’s privacy and use of their personal device).
If a control can’t be implemented on BYOD then it may be possible to shift it back to the server, either just for BYOD or for managed devices too. Or you may have to conclude that that service can’t be provided safely on that type of owner-managed device. In that case you need to configure the server and network to restrict access only to suitable devices, and you need to explain to device owners why they shouldn’t try to get around those controls.
Once you’ve made those decisions, I think you pretty much have your BYOD policy. And it should be consistent with your use of other mobile devices, too.
As was discussed at
UCISA’s BYOD conference
earlier this year, you also need to provide both network and human support for a wide range of devices and to protect the network from equipment that may be insecure or hostile. But you’ll need that anyway to support visitor and student machines. Choosing not to allow/support BYOD probably won’t significantly reduce the demands on your wireless network.
#177 - Legislating for Indirectly-linked identifiers
Originally posted: 28 October 2013 in category
Articles
A law that promotes Privacy by Design and Data Minimisation ought to encourage the use of indirectly-linked identifiers, which allow processing to be done separate from, or even without, the ability to identify the person whose information is being processed. However European Data Protection law has never really worked out what these identifiers are. The resulting regulatory uncertainty discourages the use of indirectly-linked identifiers to protect privacy and may even result in obligations that create new privacy risks.
The current
Data Protection Directive
declares indirectly-linked identifiers to be the same as directly-linked identifiers. Both are personal data according to Article 2(a), so both are subject to the same legal duties. That immediately creates a problem as some of those duties are impossible to fulfil: if I only have an IP address, I can’t proactively contact you to report a security breach, for example. Indeed some duties, such as subject access requests and the proposed rights to transfer and erasure, are positively harmful if they are applied to identifiers that (like IP addresses under
Carrier Grade NAT
schemes) may be shared between large numbers of individuals. Such duties can only help what the UK Information Commissioner described as a
“pervasive and widespread ‘industry'”
already exploiting identifiers that aren’t sufficiently tightly bound to a single individual.
The latest
draft Data Protection Regulation
applies a quick fix to the first of these problems by declaring (in Article 10(2)) that if a duty is impossible for certain types of personal data then it doesn’t apply. This doesn’t help with the second problem where a duty can be fulfilled but, in the interests of privacy, probably shouldn’t be. It also raises concerns that some of those disapplied duties might be important privacy protections and, rather than simply deleting them, alternatives should be found and imposed.
The challenge is that, depending on how they are created and used, indirectly-linked identifiers can be nearly as privacy-protecting as fully anonymised data or nearly as privacy-harming as direct identifiers. Hence the apparent paradox of a regulator promoting them as a
privacy-enhancing technology
at the same time as some uses, including profiling and automated decision making, are considered so hazardous that they require specific additional regulation (e.g. Article 15 of the
Data Protection Directive
).
Given this range of privacy benefits and threats, legislation that treats all indirectly-linked identifiers alike, whether as personal data (“assuming the worst”) or non-personal data (“hoping for the best”), seems bound to fail. Instead the law needs to look both at the identifiers and their uses, developing a set of rules that are necessary and safe for all indirectly-linked identifiers and then applying additional restrictions on uses that involve a particular risk (for example where re-identification is intended). That way we can get the privacy benefits of identifiers that don’t identify while still reducing the risks of them being misused.
#176 - Encrypted Information: Law enforcement access
Originally posted: 22 October 2013 in category
Articles
The amount of information stored in encrypted form is steadily increasing, supported by
recommendations from the Information Commissioner
and others. When deciding to adopt encryption, it’s worth planning for what might happen if the police or other authorities need to access it in the course of their duties.
Normally the
existing access rules
under section 22 of the
Regulation of Investigatory Powers Act 2000
(RIPA) or sections 28 and 29 of the
Data Protection Act 1998
will be sufficient. When an organisation receives an order or request to disclose information that is encrypted it will simply decrypt it and provide that version (securely!) to the police.
There are three situations where that won’t work:
If someone else encrypted the information and the organisation doesn’t have a key to decrypt it;
If the information was encrypted using someone else’s public key, so the organisation (not having the private key) can’t decrypt it;
If the organisation used to be able to decrypt the information but the key has been lost/forgotten/destroyed.
If the police believe that you are refusing to decrypt information, then they can make a disclosure order under
s.49 of RIPA
. Failing to comply with an order is a criminal offence so if you actually can’t decrypt it then it’s important to be able to explain that. Ideally that explanation will prevent anyone serving an s.49 notice on you in the first place. But even if a notice is served you don’t need particularly strong evidence, just “sufficient evidence to raise an issue” (s.53). Then the prosecution need to prove, beyond reasonable doubt, that you are lying.
Unfortunately neither the legislation nor the very limited case law (the Open Rights Group maintain a
list of cases
) provide much guidance on what your evidence might look like. But it should help to have a consistent, well-documented explanation of your encryption practice and how it resulted in you being unable to decrypt the required information. For example:
If you are advising others on encryption, make sure the guidance tells them how to keep the key secure without revealing it to others (that way there should be less chance of anyone thinking that an organisation can decrypt anything that happens to be on its systems);
If you are sending a message to someone else’s public key and not keeping a copy encrypted to yourself there’s little point in keeping the message you sent: without their private key you’ll never be able to read it anyway;
If you are encrypting information that you intend to be able to decrypt in future, make sure the keys are kept securely and in a way that’s appropriate to the circumstances in which you expect to use the information. Encrypting something that you don’t plan to use for months but expecting nonetheless to remember a long and complex key without writing it down doesn’t make operational sense and is unlikely to be a plausible story in court;
And if you discover at any stage that you are no longer able to decrypt the information then record that at the time, don’t wait till after you’ve been served with a notice!
Finally, if you are using digital signatures, it’s probably a good idea to use different keys for signing and encryption. According to s.49(9) an order can’t be made to disclose a key that “is intended, and has only been used, for creating digital signatures”.
At the
VAMP workshop
last week I was asked to
review legal developments
that might affect access management federations. On the legislative side the new European Data Protection Regulation seems to be increasingly mired in politics. The Commission’s
proposed law
from January 2012 needs to be discussed with the European Parliament and Council of Ministers and neither of those bodies has yet been able to agree its initial negotiating position. Recent revelations have added questions about Government spying on internet users to the mix, even though these are outside the formal scope of both the Directive and the draft Regulation. It seems unlikely that there will be time to debate all these questions (and the 3000+ amendments that have been proposed to the Commission’s draft) before the Parliamentary elections next year. Privacy experts have even suggested that it might be better to
start again from scratch
.
Whatever privacy law eventually emerges, some basic privacy principles for federations seem likely to help them, and their members, towards compliance:
Ensure information is only transferred if it is necessary
to deliver the service the user has requested. The current European Directive requires that personal information processing not be excessive; privacy by design approaches tend to refer to data minimisation. Research and Education federations already provide a
rich range of identifiers and attributes
from those (such as e-mail or name) that directly identify individuals, to strongly pseudonymised labels allowing only recognition, to anonymous attributes indicating only what group a user falls into. Identity Providers and Service Providers should ensure that they are choosing appropriately from this selection.
Avoid surprising users
by using information in unexpected ways. This need not involve obtrusive privacy notices: as the UK Information Commissioner points out, some uses of personal data are
obvious from the request the user has made
– “send me a book” (or an e-mail) obviously requires some processing of personal data. Less obvious processing, and particularly any use of personal information for secondary purposes, does need to be described and possibly actively brought to the users’ attention.
Treat privacy as a benefit/risk issue
, not an absolute yes/no one. Users already understand (possibly only subconsciously) that to access services on the Internet they need to provide some information about themselves and trust the service provider to use it properly. Federated access management can reduce the amount of personal data required and provide a stronger basis for that trust, knowing that organisations have signed a federation agreement. However, and especially given the widening definition of “personal data” in European law, it’s not going to be possible to avoid that law entirely. The Information Commissioner has an example where transfer of personal information benefits the user as a
routine part of their job or study
. If the regulator and the user both consider that the benefits can justify the risk, it’s unfortunate if the access management system insists on a different approach.
Many of the presentations during the workshop already contained these ideas.
Jens Jensen
,
Remco Poortinga
and
Marco Fargetta
considered different ways to ensure that only adequate and relevant information was transferred.
Heather Flanagan
observed that for some applications a project-specific attribute might be more accurate and less privacy-invasive, though coordination between projects will be needed for this approach to scale.
Marco
asked whether treating exceptional circumstances, such as user mis-behaviour, separately could reduce routine information transfer; this led to an
open space discussion
I’ve written up in another posting.
Jens
suggested that service providers might also take a risk-based approach and offer greater access to users with a history of good behaviour, rather than insisting on detailed information disclosure about everyone, just in case.
Jens
and
Johannes Reetz
discussed ways to let individuals and communities control some aspects of information disclosure and location, while noting that they might choose incompatible options, such as refusing release of an attribute that is essential to authorise access. Careful configuration, good error messages and support are likely to be needed.
Heather
described a project that in previous versions had offered its users both too much and too little information and control: the latest release hopes to achieve the ‘Goldilocks’ level. Finally
Bob Cowles
noted that the whole basis of Federation is trust – accepting the risk of relying on someone else to act in a way that doesn’t harm you. Treating information disclosure as a benefit/risk question should fit naturally into the federated environment.
My conclusion: it seems that the scientists and engineers have made more progress on privacy in the past year than the legislators.
Originally posted: 4 October 2013 in category
Articles
If you look up “interception” in most dictionaries you’ll find that it happens before an action has completed: in sport a pass can no longer be “intercepted” once it reaches a teammate. In a legal dictionary, however, that turns out not to be true. According to
section 2(2) of the
Regulation of Investigatory Powers Act 2000
(RIPA)
interception can take place at any time when a message is “in transmission”, which is explained by section 2(7):
“For the purposes of this section the times while a communication is being transmitted by means of a telecommunication system shall be taken to include any time when the system by means of which the communication is being, or has been, transmitted is used for storing it in a manner that enables the intended recipient to collect it or otherwise to have access to it.”
“the period of storage covered by [section 2(7)] does not come to an end on first access or collection by the intended recipient, but it continues for so long as the system is used to store the communication, and whilst the intended recipient has access to it in this way” (para.28)
The
Edmondson
case concerned voicemail messages, but its conclusion that a message remains subject to interception law so long as it remains accessible on the server seems to apply equally to modern e-mail systems such as IMAP and webmail. The judge thought e-mail was different, but seems to have had in mind older POP systems that delete messages from the server when they are first read by the client. With webmail or IMAP, like voicemail, the server “is used to store the communication, and … the intended recipient … ha[s] access to it” after it is first read. Indeed that seems to last until the message is deleted from the server either by the user or by some webmail providers that implement time- or quota-limited storage. And, as far as I can see, that still applies if the user moves the message to a different folder on the server: there’s nothing in the definition that restricts it to the Inbox.
The change shouldn’t make much difference to universities and colleges that operate mailservers. Even after a message ceases to be covered by RIPA a public sector organisation is still required to handle it in accordance with the
Human Rights Act 1998
. That imposes very similar privacy requirements: not surprising, as RIPA was passed to ensure UK law complied with the Human Rights Convention!
However it does seem to affect the possibilities for law enforcement agencies to access the content of mailboxes. So long as a message falls under RIPA, law enforcement authorities need a warrant under s.5 to order its disclosure (or, according to RIPA s.1(5), a search warrant or production order under the
Police and Criminal Evidence Act 1984
– see also page 10 of the
Home Office Interception Code of Practice
). For personal data not covered by RIPA, a police officer can ask the organisation holding the information to disclose it. Under
s.29 of the
Data
Protection Act 1998
, the organisation is allowed to disclose the information if it believes that doing so is necessary and proportionate for the prevention, detection or investigation of crime. But if the
Edmondson
case means that all mailboxes and folders on the receiving server are covered by RIPA, then it seems that the DPA s.29 option may no longer be available for law enforcement to access those.
I’m still trying to confirm this with the Home Office but would be interested to hear if anyone has received a s.29 request for mailbox contents recently?
Note that this doesn’t affect the process for disclosing traffic data – who sent e-mail to whom, and when – which is covered by a
different chapter (s.22) of RIPA
that doesn’t depend on the “interception” definition and when it ceases to apply. That process, and the information accessible under it, remains the same.
#173 - Managing Incident Response in Identity Federations
Originally posted: 3 October 2013 in category
Articles
In talking with service providers at this week’s conferences on federated access management in Helsinki it’s become apparent that many of them are asking identity providers to supply not only the information that they need for normal operations, but also information that will only actually be needed if a problem occurs. For example it seems that some service providers may request every user’s real name just in case a user mis-behaves and breaks the service provider’s policy.
Since most service providers won’t have a direct relationship with their users – indeed the service provider and user are increasingly likely to be in different countries – there’s probably a better way to deal with problems. The identity provider, who is likely to have a contract or other agreement with their student or member of staff, is much more likely to be able to talk to them face-to-face and, if necessary, impose a punishment for misbehaviour. And if the identity provider agrees to deal with problems there may be no need for every user’s real identity to be disclosed every time they access a service; indeed it may not even be necessary to disclose it if a particular user mis-behaves so long as the service provider trusts the identity provider to work out which user caused the problem and deal effectively with them.
This approach has been used for many years with federated network access under the
Janet eduroam policy
. Each time a user is authenticated their home organisation passes a session identifier to the visited organisation; if the user causes problems then the visited organisation can report the relevant log extracts and the identifier and the home organisation is obliged by the policy to deal with the user as if they had breached their Acceptable Use Policy at home. The policy thereby
reassures organisations offering visitor services
that problem users will be dealt with, while protecting the privacy of every user of eduroam. Stefan Winter of RESTENA gave a presentation on
how to trace a mis-user
at a TF-CSIRT seminar in 2010. If a home organisation fails to deal with a problem their breach of the policy can be reported to the eduroam operator; if the misuse is an immediate serious threat to the visited organisation they are able to temporarily suspend access by all visitors from that home organisation.
The same bargain, where a home organisation agrees to deal with individual problems with the possibility of a general suspension if they fail to do so and pose a risk to others, is also used by the
Janet Security Policy
. Under clause 9 connected sites agree to deal effectively with reported policy breaches, and the policy allows network operator to restrict or suspend service if they fail to do so.
Some identity federations already have agreements that cover incident response, for example the
UK Access Management Federation Rules of Membership
require that members “must give reasonable assistance to any other Member investigating misuse” (clause 3.5) and the
Recommendations on Use of Personal Data
suggest that problems should be reported to, and dealt with by, the user’s home organisation (section 4). Where a federation agreement doesn’t contain similar provisions it may be possible for service providers to seek assurances from either the federation operator or individual identity providers. This should permit the service provider to request less personal data as a matter of routine, thus complying with data protection law’s minimisation principle, reducing the compliance risk to both service provider and identity provider, and perhaps making the identity provider more willing to release the information that is needed for routine access to the service. Agreeing effective incident response measures to permit reduced routine data transfer seems like a win for all: service providers, identity providers and users.
Given the benefits of agreeing a different process and information flow for handling policy breaches, it may be worth considering whether there are other exceptional circumstances that could be treated in the same way. One situation that was mentioned is where a virtual organisation needs to check which user(s) have incurred costs or used quota with a service provider. Here there needs to be an exchange of information between the service provider and the VO (and possibly the IdPs as well): agreeing the exception process in advance may both give more confidence that it will work, and allow a reduction in routine information transfers.
There seems to be agreement that there is a role for the EU in Network and Information Security, in particular in ensuring that requirements are harmonised both across countries and across legislation. For example any reporting requirements in a NIS Directive must not duplicate requirements under data protection and sector-specific regulation. However there are also important activities at both national and international level that EU action must fit into. National NIS strategies, CERTs and competent authorities are seen as good things so long as the Directive’s requirements do not result in duplication of existing facilities.
The Directive’s proposal for mandatory notification of information about security breaches causes more concern. Respondents (and the BIS impact assessment) note the success of existing voluntary information sharing partnerships in the UK such as the Cyber-security Information Sharing Partnership (CISP) and the various sector Information Exchanges operated by CPNI. They are concerned that these might be damaged if information in notifications was not kept secure, if it were further disclosed against the wishes of the owner (for example disclosure might be
required under the Freedom of Information Act
) or if one-way notification replaced two-way sharing. Our
response to the European Commission’s original consultation
warned that mandatory notification might distort incident response priorities; others apparently go further and worry that it might turn information disclosure into a matter for the legal or compliance department. “Do we have to disclose this incident?” could replace “could others learn from our experience?”. Paradoxically, reporting costs, sanctions and audits will impose the largest burden on organisations that are best at detecting incidents and could even create an incentive not to look so hard.
As well as sectors such as energy, health and transport generally recognised as part of the Critical National Infrastructure the Directive would cover “internet enablers”. Even BIS appear to struggle to interpret this definition or to find a rationale for the Directive’s examples of organisations that are, and are not, included. Respondents to the consultation note that hardware and software companies also form part of the complex supply chain for internet services; given discussions at TF-CSIRT this week of the dependence of Internet businesses on DNS it is perhaps surprising that providers of that service do not appear to be included. Given this uncertainty, one respondent suggests that “internet enablers” might be better served by voluntary, rather than mandatory, information sharing schemes.
The uncertainty of scope, and of the definition of a “serious incident” that requires reporting, make it hard to assess the potential cost of implementing the draft Directive. BIS’s
impact assessment
estimates that it might require businesses to double their current level of spending on security, with considerable uncertainty whether this investment would be recovered through the resulting reduction of severity of incidents. The impact assessment notes that the UK Government’s policy is only to impose costs on business if they will be recovered twice over though this rule would not apply to transposing an EU Directive.
Discussions of the draft Directive are likely to continue at EU level into 2014, with a further consultation promised if the UK is required to implement it.
Originally posted: 17 September 2013 in category
Articles
Over the past year, Ofcom have commissioned a series of research studies into online copyright infringement. They and the Intellectual Property Office (IPO) held a workshop to present the results of these and other studies and to consider what continuing research is needed to provide an evidence base for future policy in the area of intellectual property.
Ofcom’s
study
used four waves of interviews, both face-to-face and on-line, to estimate how many infringers there are, how much they infringe, whether particular groups are more likely to infringe, how they infringe, where, what their reasons are for infringing and how this might be reduced. The study looked at different types of online media, including music, film, TV, and e-books. More than half of all internet users in the UK have downloaded or streamed one or more of these in the past year, spending on average £77 each. Around 29% have accessed one or more unlicensed files, most of these access a mix of licensed and unlicensed content. Across all downloads and streams, 22% of music files, 35% of film and 13% of books are thought to be infringing.
However infringement is
far from evenly spread
: 10% of infringers (i.e. 2% of internet users) are responsible for 74% of infringements. Most of these only infringe in one type of media and, at least for music and TV, they also spend significantly more than the average on their interest. The top 10% of infringers’ average spend in the year was £847. This group are also significantly more likely to use wifi and mobile networks outside their homes, suggesting that they are more technically skilled.
Survey participants were asked what would make them stop infringing. The top five aspects all relate to dissatisfaction with existing licensed sources: cost, availability of desired material and convenience. There was also considerable uncertainty about which services were legal and what could lawfully be done with content once it had been obtained. Notification or technical measures, as foreseen by the Digital Economy Act, were said to be significantly less likely to change behaviour.
The inconvenience of obtaining content lawfully was confirmed by examples from Further Education Colleges, who have to deal with twelve different licensing bodies for fourteen different types of copyright (two of these have recently concluded an agreement), and from popular TV series where different viewing dates in different countries create a strong incentive for even otherwise law-abiding communities to engage in widespread infringement. The recent
release of all episodes
of House of Cards simultaneously and globally on Netflix is an interesting approach.
Evidence gathered by the
Industry Trust for IP Awareness
to support its education programmes on film copyright appears to support Ofcom’s findings. They found considerable confusion around newer on-line services that were not associated with a recognisable ‘high street’ name. While survey participants were confident that iPlayer and iTunes were lawful, there was much less confidence about Blinkbox (which is). They also suggest that piracy may be habitual: once a customer has had to go to an unlicensed site to get one music track, film or TV programme, they may well continue to use it even for content that could be obtained lawfully. It struck me that one effect of blocking injunctions might be to make these lost customers available again to licensed services?
The Industry Trust data agree with Ofcom’s that high infringers are also film fans; their education campaigns therefore seek to inspire infringers rather than tell them off. Their trailers for new films incorporate messages that this is “worth paying for” and promote findanyfilm.com as “All films; All in one place; All above board”. There are
excellent examples
on their website. A simulation of consumer behaviour indicates that a long-term education campaign can be effective in suppressing infringing but on its own cannot stop it. The move from watching films on DVD to streaming is seen as both an opportunity to reduce infringing behaviour, because subscription services can offer convenience and (once you have watched enough to cover your subscription) effectively free viewing, and a risk because it will require all viewers to adopt the equipment and skills that will enable them to move to unlicensed sites if lawful services do not satisfy demand. With at least 15 million people expected to move to streaming services by the end of 2015 it is vital that this audience is not lost.
It was agreed that Ofcom’s series of surveys have provided a strong evidence base. Their raw data from 20,000 interviews will be made available for further analysis. With that series now at an end, the challenge is how to continue and enhance this type of evidence gathering. Ofcom noted that their survey left unanswered questions around other content types, which locations and networks are used to infringe, what the effect of sanctions would be, and how to improve understanding of lawful behaviour. Some of these cannot be addressed by surveys but will need combined approaches including measurement and behavioural economics. The IPO are developing a revised version of their good practice guide to collecting evidence. However a review of current evidence-gathering by industry indicates that it is more likely to be focused on specific, ad hoc, issues rather than fitting into a framework for an Ofcom-style analysis of trends and changing behaviours over time. Finding the resources and skills to bridge this gap appears to be a significant challenge for the industry and the IPO.
#170 - Draft Defamation Act Regulations for Website Operators
Originally posted: 28 August 2013 in category
Closed
Implementation of the new provisions for website operators under the Defamation Act 2013 has come a step closer, with the Ministry of Justice seeking comments on draft implementing Regulations.
INFORRM
has a summary of the process, with a helpful flowchart. Janet and UCISA have sent a
joint response
pointing out two frequent situations, and one less frequent, that the draft Regulations do not handle well:
Where multiple copies of a complaint are sent (it’s common for complainants to try many different e-mail addresses in the hope that one will work);
Where the notification to the author is returned as undeliverable, possibly several days after sending;
Where the author reacts to a complaint by removing the post, rather than waiting for the website operator to do it.
Our comments from the
last round of consultation
do seem to have been taken into account in the new draft, so I’m hopeful that these will be too.
A number of commentators have expressed disappointment that the new regulations are not a “revolution” in handling alleged defamation on websites, but I think their expectations were set too high. The existing notice-and-takedown process will still exist – indeed it’s required by European law – and I expect it to continue to be used for the majority of complaints. The new process will help universities and colleges, who have a
legal duty
to protect lawful free speech by their members and guests. At the moment, if they receive a complaint about an article that appears to be subject to that duty they have to try to predict how a court will rule on the complaint and risk legal penalties if their prediction is wrong. Under the new process so long as the university or college is able to contact the author who cooperates by providing their postal contact details within five days (these can be kept private, if desired, unless a court orders their disclosure), then the article can continue to be published until a court decides whether to order its removal. The new process does require more ‘paper’work, since websites using it will need to track complaints and keep records of removed content but that may be a reasonable trade-off for the increased legal certainty it should provide.
Originally posted: 15 August 2013 in category
Articles
A
recent news story
reported that a small number of litter bins in London were collecting a unique identifier from passing mobile phones and using these for some sort of “footfall analysis”. There doesn’t seem to be much detail about the plans: it struck me that a helpful application could perhaps be look for the same phone passing slowly and repeatedly past, and display an “are you lost?” map on the bin’s advertising screen! The story triggered a discussion among lawgeeks as to whether the information constituted personal data, something the Information Commissioner is apparently investigating. My tentative conclusion suggests that whichever answer is right, in these edge cases data protection law may neither be a good guide to when privacy concerns will arise, nor to how to address them.
What the bins seem to have been collecting is the
Media Access Control (MAC) Address
, a unique number that is built into every network interface by the equipment manufacturer. Back in the days when all networks were Ethernet, we used to refer to them as Ethernet Addresses, but now they appear in many other technologies notably the interfaces for IEEE 802.11 radios that allow your laptop, tablet or phone to connect to wifi. Since the wifi MAC address is included in every transmission, if your device’s wifi is on then any radio within range (50-100m or so) that’s tuned to the right frequency can ‘hear’ it. And, since the whole point of a MAC address is to ensure that every device has a unique number, a series of radios down a street could, indeed, ‘follow’ your phone as you walked along.
So is a MAC address personal data? Under UK law, at least, that’s far from clear. It’s tempting to compare MAC addresses with IP addresses, but there are two significant differences. First, MAC addresses are only visible to other devices on the same local network segment: they aren’t (at least for IPv4, some IPv6 options do use the MAC address as part of the IP address) carried across the Internet to remote servers. Web servers and other remote systems can’t use your MAC address to distinguish you or to link your activity across different services because they’ll never see it. On the other hand, again unlike an IP address, your MAC address doesn’t change when you move to a different network. So two hotels in different countries could, if they cared to exchange logs, work out that the same laptop had visited both of them. At least they could if it had connected to both
wireless
networks, because each
interface
on a laptop has a different address: a wired network sees one MAC address, a wireless network sees a different one. Interestingly, I don’t think my home broadband provider can see either of those addresses: all it can see is the MAC address of the router/access point that I manage. So MAC addresses don’t travel as far across networks as IP addresses, but they may persist for longer.
That means that the group of organisations likely to be able to link the MAC address to the person carrying the device (thus making the MAC address personal data in their hands, according to the UK Data Protection Act) is different from those who can link the IP address. A hotel whose wireless network requires you to give a room number to log in probably will be able to make the link; even if you don’t need to log in, they could potentially link you to the customer who caused trouble in another hotel last week! But none of the websites that you accessed during your stay can, even if you logged in to accounts on them, because they don’t see the MAC address. Unless the bin company had an information sharing agreement with nearby hotels, it seems unlikely to me that MAC addresses were personal data in their hands (the system has now been switched off because of privacy concerns, hence the past tense).
Even though the Data Protection Act may not have applied, the
privacy issues
do seem to have worried people. So just because you aren’t processing something classed as personal data doesn’t mean you can ignore privacy. This is one of the things that should be picked up by a Privacy Impact Assessment: checking early in the design process whether affected people are concerned about a system may be more useful than a detailed analysis of whether the letter of the law applies.
Furthermore when dealing with these not-quite-personal identifiers, the law may anyway give paradoxical guidance. If the MAC address did constitute personal data then what the bins are doing would count as processing location data, which has special status under
European and UK law
. In particular you can only process the location of identifiable individuals if you have their consent and on condition that they can withdraw consent at any time. But if all you have is a MAC address, you can neither ask them for their consent nor validate their request to withdraw it: for that you would need an e-mail address or phone number that let you contact the device’s owner. In fact the bins do provide an opt-out: there is a webpage where you can enter a MAC address and prevent it being tracked. But you have to enter the address manually because, as above, a website can’t see it, so there’s nothing to stop you entering someone else’s MAC address. That probably doesn’t matter for an opt-out. However the draft Data Protection Regulation suggests automating Subject Access Requests for information associated with personal identifiers: would that let me type in someone else’s MAC address and see where they had been walking?
So it seems that if the MAC address of a phone were classed as personal data, it would be impossible for a system following the location of MAC addresses to comply with Data Protection law, because it would have no way to communicate with the individual. So the law would effectively prohibit that system. But, ironically, if mobile phones instead broadcast their e-mail address or phone number then it
would
be possible for a tracking system to comply, by seeking consent, even though the information collected by that system would allow also much more intrusion into private lives. Should the law really encourage systems to use more privacy-invasive identifiers than it needs? Around the edges, the over-simplistic model where information is either personal or it isn’t can produce some very odd effects.
#168 - Directive on Attacks on Information Systems
Originally posted: 5 August 2013 in category
Articles
The EU has finally
adopted
a new Directive on attacks against information systems, first proposed in 2010. The Directive will require Member States, within two years, to ensure they meet its requirements on
Activities that must be considered crimes;
Effective sentences for those convicted of the crimes (including higher maximum sentences for aggravating circumstances such as widespread or seriously damaging attacks or those on critical infrastructures);
Collection of statistics on the number of offences, registered, prosecuted and convicted;
Completing and improving the existing cross-border collaboration between judiciary and police.
As far as I can see, all the criminal activities in the Directive are already crimes under various UK laws, with maximum sentences that at least match the Directive’s requirements, so I don’t expect much to have to change here:
Unlawful access to information systems and unlawful interference with systems or data (Articles 3 to 5), under sections 1 & 3 of the
Computer Misuse Act 1990
. These were included in the preceding EU framework decision as well, though the EU text of Article 3 appears to allow a member state to require that unlawful access must involve “infringing a security measure”, something UK law doesn’t require. Even if an account or system has been left without a password, unauthorised access to it is a crime under UK law;
Making, supplying and obtaining tools for use in such offences (Article 7), under
section 3A of the
Computer Misuse Act 1990
. As I
wrote
when the draft Directive was published, the EC text seems less likely than the UK one to capture legitimate actions by system and network administrators, because it requires “intention that [the tool] be used to commit [an] offence”. The Commission’s concern appears to be botnets, though the UK definition of “tools” goes much wider;
Inciting, aiding, abetting, attempting the commission of such offences, under existing rules on inchoate offences.
Article 9(5) comes close to activities currently being examined by UK law, as it relates to the misuse of personal data to obtain the trust of a third party and cause prejudice to the rightful “identity owner”. However this appears only to be an aggravating circumstance if used to interfere with a system or data (Articles 4&5), not to just gain unauthorised access to data (Article 3). So I suspect it just misses the ‘blagging’ of personal data, currently covered by
section 55 of the
Data Protection Act 1998
, whose maximum sanctions are widely regarded as much too lenient.
Articles 10 and 11 require the possibility of serious sanctions against organisations for whose benefit any of the crimes are committed, ranging from placing the organisation under judicial supervision to winding it up. These may discourage organisations from any policy of “striking back” against those apparently attacking them; in fact such attacks will normally only harm fellow victims whose compromised systems are unknowingly being used as tools in the attack.
Better statistics on cyber-crime would be welcome, but Article 14 has had some caveats inserted that may mean if covers no more than “existing data”, which is distinctly sparse.
#167 - Response to IPO on education copyright exemptions
Originally posted: 31 July 2013 in category
Closed
I’ve just submitted a
response
to the Intellectual Property Office on their
proposed amendments to the education exemptions to UK copyright law
. These aim to extend the same permissions for distance learning as currently apply to the premises of an educational establishment. From Janet’s point of view as operator of a network and an access management federation, there are a couple of
odd wordings
:
The proposed exemption talks about ‘networks’ when it is actually referring to access management functions;
The exemption covers remote learners, but doesn’t cover remote tutors (or even local ones who happen to be working from home when developing their courses).
I’m told that both points were raised at a recent meeting with the IPO and that their intentions are indeed that the exemptions should cover the current ways that distance learning is delivered.
#166 - Proposed Copyright Amendments for Distance Learning
Originally posted: 27 June 2013 in category
Closed
I’ve been looking at the Intellectual Property Office’s
proposals to update copyright exemptions for education
, to see if there’s anything I need to comment on. My initial observations are as follows, but I’d be very grateful for comments if I’ve missed something.
I’m not an expert on copyright exemptions or education licensing, but I am a distance learning student and we are supposed to be one of the beneficiaries of the change. At the moment copyright law (specifically
sections 32-36A
of the
Copyright Designs and Patents Act 1988
) contains some exemptions for education, but some of these are restricted to activities “
at
an educational establishment”, so distance learners – who may be sitting at home, in the office or even on trains or planes – can’t benefit from them. The Hargreaves Review of Copyright pointed out the problem several years ago, and the IPO have now published proposed amendments to fix it. Generally these seem OK, but there are a couple of wordings that strike me as odd and perhaps not really matching how distance learning happens.
If you’re translating exemptions from a bricks and mortar classroom to an on-line one then it’s reasonable to require equivalent access control to ensure that only teachers and pupils benefit from the exemption. The original
consultation
on implementing the Hargreaves Report mentioned Shibboleth and Athens authentication and authorisation systems as acceptable ways to do that. To access an on-line Virtual Learning Environment I run up my web browser, type in my username and password (assuming I’m not already logged in through single-sign-on) and get access to the teaching materials. No username/password, no access.
However the IPO draft amendment, while still apparently intending the same thing to happen, describes that process as gaining access “by means of a secure electronic network which is only accessible to staff or pupils of the establishment”. Now my access is indeed secure and limited, so the rightsholders’ interests are protected, but that’s achieved by authenticating to the VLE server, not having a private network between me and the content. Depending on where I am, the “electronic network” that I use to get to the VLE may be BT ADSL, or a hotel wireless network, or 3G on a train. None of those is “only accessible to staff and pupils of the establishment”. As far as I can see neither the Act nor the amendments contains a definition of the term “electronic network”, which means it should be given its every day interpretation. Fitting that to what actually happens several layers higher up the network stack seems a bit of a stretch.
The second oddity is in the exemption for showing recordings of broadcasts (for example in lectures). At the moment, again, that is limited to the physical premises. The new amendments would allow access to remote users of a VLE but only if the recording is “communicated … by a person situated within the premises of an educational establishment” (c35(1A)). In an amendment that’s supposed to fit the law to the Internet, it seems the brick walls are still there. What if my tutor happens to be working from home or, indeed, is a distance tutor as I am a distance student? Do we both lose the protection of the copyright exemption? In this case it appears that it would be possible to comply with the strict wording if all recordings were placed on the server by an on-site service (we used to call them ‘library’ or ‘audio-visual’) and the tutor then just linked to them. But for a document modernising copyright, that still feels a bit old-fashioned. Since the current s35(1) will still require the recording to be “made by or on behalf of an educational establishment for the educational purposes of that establishment” and access will be limited to those either on the premises or with a valid staff or student login, I’m not sure what is achieved by the extra constraint on the location from which the recording is uploaded.
Originally posted: 25 June 2013 in category
Articles
Bug bounty schemes have always been controversial. In the early days of the Internet someone who found a bug in software was expected to inform the author and help fix it, as a matter of social responsibility. Suggesting that those researching vulnerabilities be paid for their time and effort seemed rather grubby. Unfortunately not everyone shared those scruples. Taking valuable information out of companies, building botnets and spam networks are all a lot easier if you know about software vulnerabilities that others don’t, so once criminals had worked out how to make money out of those activities it made economic sense for them to pay, or even employ, researchers to find bugs. It took a bit longer to work out an economic model that paid vulnerability researchers to remove problems, but eventually commercial vulnerability brokers appeared who paid researchers for information and then provided it, on a commercial basis, to companies supplying protection systems for networks and computers.
Both those existing markets are mostly concerned with vulnerabilities in production software. If you are a criminal then you want exploits that will give you control of lots of Internet-connected systems. If you are trying to sell a protection product, then protecting against vulnerabilities that aren’t yet in your clients’ systems isn’t a great sales pitch. Instead of adding to these markets,
Microsoft’s new bug bounty programme
looks earlier in the software life cycle: before programs are released as products. Microsoft already makes code available in pre-release (known as ‘beta’) condition, but apparently neither criminals nor brokers will pay much for vulnerabilities discovered at this stage because there is a reasonable probability that they will be discovered and fixed (or the vulnerable code removed for other reasons) before the product is released. If researchers find a vulnerability in pre-release software, the only way to get paid is to wait and hope that it is not discovered before it acquires a market value.
By offering a bounty for vulnerabilities in beta code, Microsoft are therefore creating a new opportunity for researchers who want to do the right thing and have a financial reward for their time and effort. In return, Microsoft add another tool to their software process: like code review and penetration tests, vulnerability researchers bring independent eyes that may spot bugs that developers, who know how the code is supposed to work, may not. It strikes me that fixing bugs in beta code is also very effective for the “good of the Internet” motive we started out with. Once vulnerable code is installed on customer computers many, perhaps most, will never be fixed. If computers or their operators do not regularly install patches as they become available then the bug will persist, and may be exploitable, for ever, or at least until the computer hardware fails. Discovering bugs at beta stage, when all the vulnerable code is still firmly in the vendor’s control, means none of us need to worry about their impact on the Internet or the systems we connect to it.
Originally posted: 25 June 2013 in category
Articles
The theme of this week’s
conference
of the Forum of Incident Response and Security Teams (FIRST) is “Sharing to Win”. Perhaps inevitably, I’ve had a number of people (and not just Europeans) tell me that privacy law prevents them sharing information that would help others detect and recover from computer security incidents. If that’s right, then those laws are working directly against the privacy they are supposed to be protecting.
If a computer or account has been taken over by someone else, then the legitimate user has a serious and growing privacy problem. Telling someone (usually via their ISP or incident response team) that they have a privacy problem will help them fix it. If the computer or account is being used to attack others then sharing information that’s needed to defend against those attacks will reduce the number of people whose privacy is breached in future.
Not only does incident response protect privacy, the information that needs to be shared to achieve this benefit normally represents at most a minor intrusion into privacy. IP addresses are the most commonly needed information. The issuing ISP will often be able to link that to the individual account holder, but they are also the organisation who can do most to remedy that individual’s privacy problem. Other incident response teams are unlikely to be able to link an IP address to an individual, but they can use it protect others from being dragged into the expanding privacy breach. In each case the benefit to privacy seems much greater than the risk. Account numbers or names may be slightly more revealing than IP addresses, but again the benefits of sharing within a community that can be trusted not to misuse them should far outweigh any privacy harm.
European privacy law recognises this kind of balance. Article 8 of the
European Convention on Human Rights
grants every individual a right of respect for their private life and communications, but permits interference with that right where it is necessary to protect the rights (including the Article 8 right) of others. European data protection law also permits processing personal data that is necessary in the legitimate interests of others, provided it does not override the fundamental interests of the individual. The vital work of Computer Emergency Response Teams (CERTs) in “preventing unauthorised access to electronic communications networks and malicious code distribution and stopping ‘denial of service’ attacks and damage to computer and electronic communication systems” is highlighted in recital 39 of the
draft Data Protection Regulation
.
When a credit card number is stolen, it’s routine to let the issuing bank know to stop the owner’s financial losses; stolen card numbers are also routinely shared with merchants to protect them against future losses. The overwhelming benefit of that sharing doesn’t seem to be questioned. If the Internet is going to remain a relatively safe place to conduct our business and social lives – in private to the extent that we choose – then we need to get the same routine recognition by regulators, CERTs and individuals that sharing incident information among trusted CERTs is one of the best and most important privacy-protecting tools we have.
Most incidents involve computers, passwords, credit card numbers and so on falling into the hands of the wrong people. That’s clearly a serious privacy problem for the legitimate owners and users, so a law that aims to protects privacy ought to help incident response teams do their work of detecting incidents, informing the victims and helping them recover. The
Commission’s draft Regulation
recognises (in Recital 39) that:
The processing of data to the extent strictly necessary for the purposes of ensuring network and information security … by public authorities, Computer Emergency Response Teams – CERTs, Computer Security Incident Response Teams – CSIRTs, providers of electronic communications networks and services and by providers of security technologies and services, constitutes a legitimate interest of the concerned data controller.
The Parliament’s amendments add some rather specific examples of attacks, but then say that the permission should only apply “in specific incidents”. Unfortunately this seems to create a chicken-and-egg situation, because you need to collect data (for example about network flows) and analyse it for anomalies in order to find out about incidents in the first place. Knowing that there has been an incident should lead to (and justify) additional processing of the specific information related to it, but if that’s the intention this seems an unfortunate way to phrase it.
In fact one of the most common questions in incident response is which information is covered by personal data law anyway. European law has never been entirely clear whether an IP address counts as personal data (the Commission’s draft unhelpfully says in Recital 24 that they “need not necessarily be considered as personal data in all circumstances”). The Parliament try to improve on this, suggesting that they will be personal data if they “can be used to single out natural persons” even if those natural persons can’t be identified. Only if “identifiers demonstrably do no[t] relate to natural persons” will they not be considered personal data. However Parliament’s example then restores the confusion by giving as an example “IP addresses used by companies” – do they mean addresses of servers, NAT devices or DHCP pools? Under UK law the third and possibly second of those would be personal data in the hands of the company though probably not anyone else. And, unfortunately for the anyone trying to comply with the law, once they leave the company all those addresses look pretty much like any other ones, they certainly aren’t demonstrably different.
The Parliament do add in Article 4(2a) a new concept of a ‘pseudonym’, which is an identifier that can be used to single out but not to identify. The lack of that distinction in the current Directive causes a lot of
problems
. Unfortunately IP addresses don’t qualify as pseudonyms under this definition, as they are not “specific to one given context”. And in fact the new definition is used very little in the rest of the Regulation, despite a suggestion in the commentary that pseudonyms offer “alleviations with regard to the obligations for the data controller”. The only change I can see is in Article 10, which already recognised that there were identifiers that don’t allow identification (like IP addresses) and excused data controllers from the legal duties that those identifiers didn’t permit (e.g. proactively communicating with the data subject).
So it seems that incident response teams will need to treat most of the things they deal with as personal data. That means they need to have a justification for processing them, and Recital 39 suggests that should be the legitimate interests of the team, as data controller (Article 6(f) in the Regulation, a new Article 6(1a) in the Parliament’s amendments). However the Parliament seem concerned that that justification has been abused in the past (personally I’ve seen many more abuses of the “consent” justification) so have added extra conditions to it. Article 6(1a) requires that anyone using the justification must “separately and explicitly” inform all those whose data they process. For some incident response data, such as IP addresses, that won’t be technically possible so presumably the obligation is waived under Article 10. But if investigating a compromised system that has been used for spamming means you have to send another e-mail to every recipient of the spam to let them know that you are processing their personal data then this makes the incident worse, not better.
Another, apparently minor, change to the wording of the justification will further restrict what incident response teams can do to protect privacy, though it seems this one was made by the Commission rather than the Parliament. Compromised computers are frequently used in phishing attacks to collect passwords (for example for on-line banking) and credit card numbers. Many incident response teams will voluntarily let the affected services know about these, even though it doesn’t affect the security of the incident response team’s own network. Under Article 7(f) of the current Data Protection Directive that is clearly lawful because the team is allowed to process personal data “in the legitimate interests of the third party to whom the data are disclosed”. Unfortunately that part of the justification seems to have been removed, and I can’t see any other justification that covers this situation. So an action that currently contributes to privacy could become unlawful under this change.
The legitimate interests justification has always been more limited than the others because it requires both that processing is “necessary” and, even if necessary, that it does not override the rights of the individual. The Parliament’s amendments would require those using the justification to publish how they were protecting the individuals’ rights (I made some suggestions on this in a
paper for TERENA’s CSIRT Task Force
). And, to “give clearer guidance and provide legal certainty”, the Parliament have provided two lists: one in Article 6(1b) of circumstances in which legitimate rights will “as a rule” prevail and one in Article 6(1c) of circumstances when fundamental interests will. There’s no indication of what should happen when an activity appears on neither list or, as could easily happen, on both. Compared with the current law, where organisations need to consider the balance between the two factors for each activity, the lists seem to me to reduce, rather than improve, privacy protection. Someone who has been harmed by activity on the Internet might note that the first list includes “necessary for the enforcement of the legal claims of the data controller…, or for preventing or limiting damage by the data subject to the controller”, and conclude that any privacy-invading action to protect their systems or legal interests will be permitted. Under the current Directive there have been a number of
European cases
making very careful and detailed judgments on when privacy may, and may not, be required to give way to other legal rights. It would be unfortunate if a privacy law were to replace those with something that looks like a blanket permission.
In fact, on closer inspection, that item on the list won’t cover most incident response activities anyway, since it’s not usually the data subject (the registered user of the IP address) who is causing damage to networks and services, it’s someone else making unauthorised use of their computer.
In this article I’ve concentrated on just one internet service, though one that’s widely recognised as essential to protect the security of individuals, organisations and governments on-line. In legislation that aims to regulate so widely (essentially any activities using internet protocols will be covered) and at such a fine level of detail, it seems inevitable that there will be similar unexpected and undesirable consequences for many others. It’s important that as many as possible of these are spotted and fixed before the proposal becomes law.
#162 - Uncertainty, Risk Assessment and Breach Notification
Originally posted: 18 June 2013 in category
Articles
Two talks on the first day of the
FIRST conference
highlighted the increasing range of equipment and data that can be found on the Internet, and the challenges that this presents both for risk assessment and, if incidents do happen, assessing the severity of the possible breach and what measures need to be taken.
Eireann Leverett discussed Industrial Control Systems. When, under the alternative name of SCADA, these devices first acquired IP connectivity, the fear was that they were all used to control heavy industrial processes involving high temperatures and pressures and dangerous chemicals. That turns out not to be true – on various national and manufacturer estimates only between one in seven and one in fifty involves that level of safety criticality. The majority do things where disruption or compromise could cause discomfort or disruption – for example turning off the fans in an office – but probably nothing worse. The problem is that it’s probably impossible from the network side to work out which is which. Identical Heat/Ventilation/Air-Conditioning (HVAC) controller modules may be keeping office workers comfortable or pumping fresh air into a road tunnel. A rental agency remotely setting thermostats in empty properties may well be reducing the overall risk of serious injury as compared with having an employee drive to visit each one: having those controllers on the Internet, even if they contain vulnerable code, may be rational. But for the unknown one in seven or one in fifty, which may be controlling the temperature in a plant manufacturing medical devices, it definitely isn’t.
Scott McIntyre looked at the problems caused by mixed data. A few years ago Telstra discovered that an order tracking system was accessible without authentication from the Internet. That was clearly an incident and the vulnerability was quickly fixed. But then there was the challenge of working out what personal or other sensitive data might have been accessed and notifying affected customers what can be done to remedy the problem. For structured fields in the database that is straightforward, but unfortunately there were also unstructured fields where helpdesk operators made notes of support calls and how they had been resolved. Most of the content is harmless information on the progress of orders, but there may also be things like “password temporarily set to elephant123”. The volume of information is far too big to be scanned by human eye, so how to instruct a computer to find all such problems, without too many false positives? If “password” is written in full that may not be too hard, but helpdesk staff may instead write “pwd”, “pw” or anything else that humans (but perhaps not computers) will recognise. Worse, the system also sometimes copied users’ own e-mails into the field, including things like “while we’re talking, could you charge my account to card 1234567890111234?”. There was a strong feeling that, eighteen months on, Scott is still coming up with new searches he needs to run.
Both talks suggest that there may be a problem with over-simplified breach notification requirements that, like the
proposed European Data Protection Regulation
, require an immediate report of what information has been exposed, what the implications are, and what both the provider and user need to do about it. I’ve written before that such reports are likely to be incomplete: these examples suggest that on short timescales like the 24 hours required by the draft Regulation they may well be hopelessly wrong.
Originally posted: 11 June 2013 in category
Articles
The Domain Name Service (DNS) which translates names to IP addresses (among many other things) is critical for humans using the Internet. Research by Slavko Gajin and Petar Bojovic presented at the TERENA Networking Conference indicates that
mis-configurations are more common
than we might hope. Getting DNS right often requires different organisations to have matching configurations: if my name server says that part of the name space is delegated to your name server then your name server needs to agree! So it’s easy for human error creep in. Often the redundancy and resilience that we build into the DNS can hide these problems: so long as there is one way to resolve a name then users may only experience slowness or intermittent failures, which they may not report. Only when a component in that critical path fails will we discover that mis-configurations mean we have less resilience than we thought, after all our websites have become invisible and all e-mail is being returned as wrongly addressed.
Discovering these hidden problems requires a tool that checks all advertised routes to resolve a name, rather than just seeking out one working one. The University of Belgrade team have written such a tool and used it to check more than ten thousand domains across European NRENs. As well as looking for errors that may cause DNS to be less reliable than intended they investigated support for DNSSEC and IPv6, as well as servers that provided public zone transfers or open recursion that can be
used by attackers
. It is good to see evidence of Janet CSIRT’s recent campaign to reduce the number of open recursive resolvers, in that the percentage of servers in .ac.uk is lower than many other networks. However it is still well above zero! Results per NREN for various tests are shown in the
slides
: to check your own domain a web interface to the tool is available at
http://live.icmynet.com/icmynet-dns
Originally posted: 7 June 2013 in category
Articles
A wide-ranging panel discussion at the TERENA Networking Conference considered the
stability of the Internet routing system
at all levels from technology to regulation. The conclusion seemed to be that at the moment the Internet is stable because two systems, technical and human, compensate effectively for each others’ failings. While improvements to increase stability may be possible, they must beware of disrupting the current balance or introducing new ways that it can fail.
One of the concerns at the technical level is that as the Internet grows, the number of routing updates will also grow, perhaps beyond the capacity of routing equipment to handle it. Amund Kvalbein from Simula has been studying records of route announcements between 2003 and 2010, a period when both the number of IP address prefixes and the number of autonomous network operators responsible for them more than doubled. An initial plot of the number of routing updates per day is very noisy and suggests a greater rate of increase, however most of this turns out to be due to three types of event:
Duplicate route announcements, which add no information to what has already been seen. These do not present a significant threat to stability;
Spikes caused by ‘large events’, where a significant number of prefixes change route at the same time, either as a result of a technical incident (e.g. a cable cut) or a change in routing policy. These are the events that the routing protocols are designed to handle, and they appear to be doing it well; in particular these spikes are local in effect and do not spread across the Internet;
Changes in level, caused by a small group of prefixes becoming unstable so that their routing ‘flaps’, causing a rapid sequence of continuous updates that may persist for months if the originating networks are not well managed. Fortunately such networks rarely carry much traffic, so their overall effect on the Internet is low.
Once these three types of event are removed from the trace, the rate of growth of router updates is slower than the growth of either prefixes or networks. Growth in router adverts does not seem to be a threat to Internet stability.
David Freedman from Claranet explained how human actions deal with these problems. Major networks routinely stress test new equipment before using it in their production networks, subjecting it to higher levels of traffic than are expected to occur. As a result, many more technical problems are identified before they can affect the Internet. Networks’ technical staff increasingly know and trust one another, through Network Operator Groups, peering forums and mailing lists. This allows many problems to be resolved by a quick phone call. Major disruptions – whether caused by earthquakes, wars or terrorism – will often see competitors working together to protect the Internet rather than their short-term commercial interests. David noted that human networking may resolve some problems more effectively than technology. Technical measures to deal with flapping routes can easily replace a degraded service to users by no service at all, whereas using human contacts may well be able to fix the problem at source. Economic theories about commons suggest that such cooperative approaches will only be stable if there is the possibility of punishment for those who do not cooperate. David confirmed that networks that are a regular source of problems may be threatened with a loss of peering (which would mean they had to pay more for transit connectivity).
Thomas Haeberlen (ENISA) looked at how regulators can help to improve Internet stability. First he noted that new technical approaches often change sources of instability rather than removing them: for example rPKI makes it harder to deliberately hijack the routing system but also increases the risk that mistakes in handling certificates will result in valid routes being rejected. Also, any new technology must work with what already exists on the Internet and be capable of being deployed gradually, in both technical and economic terms. Aiming to improve the whole internet by regulation is almost certainly too ambitious, particularly as there are wide variations between different countries’ approaches and attitudes to regulation. Instead national regulators should concentrate on measuring and improving the resilience of those parts of the Internet that are most important for their citizens. Preserving reliable access to national banks and national broadcasters during an incident may be both more valuable and more tractable. A rough initial estimate of resilience, and whether there are obvious single points of failure, can be obtained from public BGP information. This needs to be supplemented by organisations’ private information about non-public peerings, routing policies, bandwidth, etc. which may reveal that the network is either more reslient or less than the public information suggests. Bottlenecks and dependencies also need to be checked both above and below the network connectivity layer: do two apparently resilient routes actually share the same cable or duct, or do Internet services rely on connectivity to particular applications or datacentres? Such dependencies and potential failures may not be apparent to individual providers, who cannot combine private information from multiple sources. ENISA plans to work with national regulators to test this approach.
Originally posted: 6 June 2013 in category
Articles
Robin Wilton
of the Internet Society gave a talk at the TERENA Networking Conference on the
interaction between privacy, regulation, and innovation
. It’s a commonly heard claim that regulation stifles innovation; yet the evidence of premium rate phone fraud and other more or less criminal activities suggests that regulation can, in fact, stimulate innovation, though not always of the type we want. So perhaps our focus, rather than resisting regulation, should be on devising regulation that promotes socially beneficial, rather than socially harmful, innovation.
It is generally considered that markets are more flexible and efficient than regulation, so regulation should only be used where there is a social need that the market does not give sufficient weight. That does seem to be the case for privacy, where society’s interest in the protection of individuals is greater than the value that the market assigns to it. Saying that “
personal data is the new oil
” suggests, perhaps unintentionally, both the high economic value of exploiting it and the need for that exploitation to be regulated to avoid serious harm. At the moment, innovation in the intrusive use of personal data seems to be taking place more quickly and more widely than innovation in protecting it.
Unfortunately regulating privacy, particularly on the Internet, has turned out to be hard. Robin suggested two principles that should make this easier: regulate risks rather than threats, and behaviour rather than technology.
It’s very tempting, and good rhetoric, to look for particular threats to privacy that we want to be regulated. Unfortunately the fact that regulation can stimulate anti-regulatory innovation means that there will be an ever-growing list of threats in any one area, so this approach ensures a regulatory arms race which probably will frustrate beneficial innovation. Rhetoric also naturally leads to an antagonistic approach where positions diverge and I can only ‘win’ if you ‘lose’.
Technology is also a tempting target for regulation, but regulators should be aware of the programmers’ mantra: there’s more than one way to do it. Unless it is
actually
the technology that might cause harm (high voltages, radiation, etc.) then someone with sufficient economic motivation can almost certainly find a different, unregulated, technological way to achieve their goal, causing at least the same harm in the process.
The EU’s attempt to regulate cookies provides a striking illustration of both problems. Rather than looking at a particular risk arising out of Internet profiling and regulating that, the law decided to target one specific technological approach to profiling and to regulate all threats that happened to use that particular technology. Regulators have since recognised that many of those threats were actually negligible and some were significant benefits to users, but cannot change the law. Anyone trying to innovate with cookies is now faced with confusing regulatory advice; meanwhile those involved in profiling are free to move to other technologies such as super-cookies and browser fingerprinting that are harder for the user to control and may well be even more intrusive.
Innovation needs experiment and a willingness to do things differently. According to
Julie Cohen
“privacy … shelters the processes of play and experimentation from which innovation emerges”. Privacy needs to be protected by regulation, but it must be the right sort of regulation.
Originally posted: 1 June 2013 in category
Articles
In what sometimes seems like a polarised debate on the draft Data Protection Regulation, it’s good to see the Article 29 Working Party trying to find the middle ground. The subject of their latest advice note is the contentious topic of
profiling
, which has been presented both as vital to the operation and development of Internet services and as an extreme violation of privacy. The problem is that with a wide definition of profiling, both those opinions may be correct.
Unlike the Cookie Directive, which required consent for both harmful and harmless cookies and left it to users to somehow work out which was which, the Working Party suggest that this time the law should make the distinction. While recognising that it is the collection of profiles, not just their use, that can present a threat to privacy, the Working Party suggest that there are some uses of profiling that do not significantly affect individuals’ privacy and should, subject to meeting the usual data protection principles, be permitted as routine. Requiring consent only for profiling where there is a significant risk of harm gives a signal to both users and service providers that such uses should be approached with caution.
This, of course, requires someone to distinguish between profiling that does and does not significantly affect privacy, and the Working Party offer to take on that task if the law is written to require it. Guidance from them on profiling and other activities that involve a wide range of potential effects on privacy would help service providers who wish to be innovative but not intrusive and users who want a good Internet experience without placing themselves at risk.
Originally posted: 8 May 2013 in category
Articles
The UCISA Networking Group’s conference
BYOD: Responding to the Challenge
looked at new developments in an area that has actually been an important part of Higher Education for at least fifteen years. Student residences have offered network sockets since the 1990s and staff have been using family PCs for out of hours work for at least as long. This has always created two challenges – supporting users on an apparently infinite range of hardware and software, and ensuring that user-owned devices do not create an unacceptable risk to users and information. More recently the growth in the number of devices per user has challenged wireless network provision (Loughborough University recently exceeded 8000 simultaneously connected wireless devices), but here it seems that new designs, standards and technologies are available to help.
On support and managing risks the best approaches seem to depend on engagement with device owners rather than technology. Since it is impractical to offer the same level of support for all devices and all applications, service users need to be involved in setting priorities. Here it is worth looking both for quick wins and applications where ‘BYOD-friendliness’ will have a high value to users and the organisation. Creating self-supporting communities of users is particularly helpful – IT services can facilitate this through on-line groups and face-to-face surgeries, then concentrate efforts on guiding users to the right approaches, rather than trying to provided detailed instructions for everything.
Working with device owners also seems to be critical to keeping information secure. BYOD could represent a risk to both the owner’s information and that of the organisation so there should be a shared interest in security measures such as good passwords, screen locks when devices are idle, encrypted communications and storage. The ability to remotely wipe a lost device can protect both owner and organisation, but there needs to be agreement on when and how it will be triggered (Mobile Application Management software may in future allow wiping of specific applications and their data). Sharing a device requires both the owner and the organisation to accept limits on how they will behave: organisations that insist on excessive monitoring and control represent a threat to device owners and family members who may share the device, just as owners who behave unsafely with information represent a threat to organisations and themselves. If the mutual benefits of convenience and efficiency are not sufficient to make these limits acceptable then BYOD is probably not the right solution.
An approach used by commercial organisations is to group services based on the technologies and behaviours required to protect them: access to calendars or room booking systems may only need encrypted communications (to protect passwords) and the ability to disable access if the device is lost; access to corporate applications may require additional authentication, filtering and the ability to remotely wipe stored information. Access can then be granted or denied based on the capabilities of the device and its owner and the importance of that individual having access to that application. The best approaches protect both owner and organisation, for example agreeing to keep personal and business information separate allows both parties to keep reasonable control of their information. Getting these benefits right will require discussions with owners on how they use their devices, how BYOD might change that and the supporting advice and services they will need. Pilot studies with volunteers seem most likely to produce effective approaches. BYOD will not be appropriate for all applications: if particular information or services require more intrusive protection than can safely be applied on a personal device that is likely to be shared with family members, then it’s in both parties interest to do that on a separate, organisation-owned device.
Originally posted: 2 May 2013 in category
Articles
I was asked recently how I saw current legal developments in Europe affecting the work of incident response teams, so here’s a summary of my thoughts.
Understanding Data Protection law has always been a problem for incident response. Some of the information needed to detect and resolve incidents is personal data but laws are unclear and sometimes even contradictory on which. Fortunately there is now recognition in the amended Telecoms Privacy Directive and the draft
Data Protection Regulation
that detecting and responding to incidents are important tools in protecting privacy (if your computer has been compromised, so has your privacy) that need to be supported by the law. The proposed Regulation should reduce the differences in legal interpretations that cause concern when working across borders; it should also provide a clearer basis for working with teams outside Europe. Incidents rarely stay within a continent.
One area where I do see potential problems is a trend to treat “national CERTs” (a term with many different definitions) as different in law. The reform of data protection law will continue the current special status of organisations involved in justice and home affairs, who will have different data protection rules from the rest of us. Some countries have gone as far as creating specific legislation to set out the powers of their national CERT. That could make it
tricky to share information
between the two types of CERT: if I have a particular duty to protect information and you don’t then it could be risky for me to share the information with you. One way to address this would be formal information sharing agreements to maintain the protection of information. I wouldn’t be surprised to see these becoming more common, especially as most national CERTs rely on others for a lot of their information about what is happening.
Finally there seems to be a very wide range of political opinions on what information network operators need to collect about their users. The Data Retention Directive, which requires public phone and data networks to keep call logs from their phone and e-mail services, became law in 2006 but a number of European countries have still not implemented it, or have had their implementations overturned by constitutional courts, on the grounds that it is a disproportionate interference with privacy. At the same time, successive UK Governments have
proposed laws
requiring networks to do much more than is already in the Directive. The Directive was supposed to solve the problem of different evidence retention practices; if anything those policies seem to be more diverse now than they were in 2005. It’s not clear whether these developments will increase the amount of information available to incident responders, leave it the same, or decrease it (if logs are now locked away in “law-enforcement only” containers). But adding confusion – for example “I have the information but don’t know if I can share it with you” – rarely helps.
So, on the whole, I’m reasonably positive, but there are still some things that need watching.
European data protection law requires that any export of personal data from the European Economic Area be covered by adequate measures to protect individuals whose data is held by organisations that are not directly subject to EU law. This is known as the eighth data protection principle. For the situation where a data controller within the EEA wants to export personal data to an overseas company, model contract clauses have been agreed to provide this protection. However these are less appropriate for exports that take place within a multi-national company or group of companies, as commonly happens with cloud, social network and similar large service providers. The idea of Binding Corporate Rules (BCRs) is that those providers can have their internal rules and processes certified by a national Data Protection Authority as providing adequate protection. The provider can then give its customers assurance that Principle 8 will be satisfied.
However, as with any national or international transfer, satisfying Principle 8 isn’t the only issue. Any organisation disclosing personal data to another needs to ensure that this satisfies the other seven principles as well. If the recipient organisation is acting as a data processor then this requires a contract (which the Working Party call a Service Agreement) between the organisations to specify what processing will be done, what security measures are required, etc.
Approved BCRs make international transfers within a data processor company or group easier, but they don’t replace all the duties. The data controller needs to be informed of what countries are involved, and may object if there are particular issues with any changes. The data processor must inform the controller and the accrediting Data Protection Authority of any local law that may prevent it fulfilling its contractual obligations. Some countries – fortunately not the UK – require that international transfers be approved by national authorities, even if Principle 8 is satisfied. If the data processor wishes to transfer to external sub-processors then this needs to be covered by a separate contract ensuring that all the processor’s duties extend to the sub-processor.
BCRs need to be followed within the organisation, so authorities approving them will expect to see information, training and disciplinary sanctions, particularly in countries where EU standards are not the norm. They also need to be legally enforceable by both data subjects and the data controller. Individuals must have the right to sue for any breach that causes them harm, and the BCRs must form part of the contract or service agreement with the customer so that a breach of BCRs is a breach of contract. The document also has further guidance on what the BCRs are expected to contain on compliance, audits, complaint handling, duty to cooperate with controller and DPAs, liability, jurisdiction and transparency.
BCRs for Data Processors seem to offer regulatory clarity for those considering moving services to cloud providers. It would be good to see both cloud providers and regulators using them.
Originally posted: 29 April 2013 in category
Articles
The
Digital Economy Bill
has been taking up a lot of my time since the start of the new year and I’m pleased to report one result. The Bill gives the Secretary of State powers to intervene in the operations of a DNS registry where a serious failure of the registry is likely to affect the country’s or consumers’ interest. Unfortunately the definition of the registry in the original
clause 18
managed to capture any organisation that ran the primary nameserver for any domain within .uk!
I was able to work with the London Internet Exchange (LINX) to draw this to the attention of the Bill team, and the Government has now tabled
amendments
(starting with amendment 214A and going through to 225C!) that effectively reduce the scope of the power to only the top two levels of the .uk domain hierarchy. So JANET(UK), as operator of .ac.uk and .gov.uk, is still covered (we’ll just have to behave ourselves), but those further down those domains aren’t.
Unfortunately that’s not the only unclear definition in the Bill – my next task is to find out whether under
clause 16
universities and colleges are going to be grouped with ISPs (“Internet Access Services”), virtual ISPs (“Communications Providers”) or households (“Subscribers”!), and what this means for us and you.
Originally posted: 29 April 2013 in category
Articles
I had a meeting with Ofcom this morning as part of their
review of section 17
of the
Digital Economy Act 2010
. That section, if enabled by the Secretary of State, would allow courts to order a service provider “to prevent its service being used to gain access to [an Internet] location”. This power could only be used against locations involved in a “substantial amount” of copyright infringement (s17(4)), and only after consideration of “whether the injunction would be likely to have a disproportionate effect on any person’s legitimate interests” (s17(5)). Persons whose interests might be affected would presumably include both the service provider who was required to implement the block and any third parties whose lawful use of the location would also be stopped.
Interestingly the Act doesn’t say how an “Internet location” would be specified. It seems to me that there are at least three ways this could be done, that these would have different effects (and costs) for service providers, lawful and unlawful users, and that the courts might therefore reach different conclusions on that test of proportionality:
a) An “internet location” could be specified by URL, as is currently done with the
Internet Watch Foundation’s
list of indecent images of children. This is the most precise form of blocking, with very little risk of accidentally blocking other material, however it is also the most expensive for ISPs to implement, as it requires all traffic to be analysed at the application layer and could require a different blocking system for each Internet protocol. It is also probably the easiest type of block to circumvent – the IWF notes that its list can only protect against accidentally tripping over material and will not stop those actively seeking it. Anyone deliberately evading this type of block would also expose themselves to all other URL-blocked material. And, of course, the operator of the blocked location can relatively easily change its URLs.
b) An “internet location” could be specified by its domain name. Blocking access by domain involves modifying the process of domain name resolution (for example returning either a no-such-domain response, or one pointing to a notification page), rather than the traffic to and from the location itself. For a service provider that (unlike JANET) controls the DNS resolution process used by its users, this may well be simpler and cheaper. However it is also more likely to block lawful use by those not infringing copyright, especially if the domain name hosts multiple services. For users, getting round a DNS block requires a little more technical knowledge at present but could be done in a way that did not impact on other URL blocks; providers of blocked services would need to change domain (
as wikileaks recently did
) if they wished to avoid the block.
c) Finally an “internet location” could be specified by IP address or range. Implementing such a block could be as simple as telling routers to drop or re-direct all traffic to that address or range. The potential impact of this is wider again, since a single IP address may serve many different domains all of which would become inaccessible to all services. Indeed once such a block was in place it could be tricky to send the location operator an e-mail to tell them about it! I also suspect that, unlike a DNS block, there is no way to work out in advance what the extent of such over-blocking might be. For determined users, many of the same techniques as used for avoiding URL blocks are likely to work for an IP address block; changing the IP address of a blocked server may be a little harder than changing its domain name (in IPv4 space, at least, the supply of addresses is limited whereas DNS domains are not).
Thus there seems to be a trade-off between the cost to the service provider of implementing the block and the likelihood that over-blocking will cause significant damage to other parties. And none of these forms of blocking actually meets the Act’s requirement to “prevent” access – both users and hosts can work around any of them. If the courts are ever called upon to use these powers it will be interesting to see how they judge this balance.
Finally, it’s worth noting that this part of the Act refers to “service providers” (a term defined in the
Electronic Commerce (EC Directive) Regulations of 2002
) rather than the terms
“ISP”, “Communications Provider”
, etc. used in the rest of the Act. So there is a possibility – though at the moment it seems unlikely – that a court might be able to make such an order against JANET or a connected site even if we are not subject to the other copyright enforcement provisions of the Act.
Originally posted: 29 April 2013 in category
Closed
Nominet have published an interesting
analysis of the legal issues
around any possible process for
suspending domains associated with criminal activity
. This raises the rather worrying issue that the legal position is not clear if a registry is informed of unlawful conduct somewhere in their domain and decides that the evidence is not strong enough to justify them acting. For networks, hosts and caches the liability position is clear, thanks to the eCommerce Directive, but the law appears to be silent on the position of a DNS registry if it is informed of either criminal activity or a civil wrong. Neither issue appears to have arisen in court, so there is no precedent either. In these situations it is possible that action by the registry might disrupt the unlawful activity but, as discussed in
my previous post
, there could also be a high likelihood of extensive harm to innocent users of the same domain. This feels a little like closing a road bridge because there has been a bank robbery on the other side of it – it might hinder the bank robbers, but will have a massive collateral impact on everyone else.
My
response
therefore points out that although a registry may have the possibility of acting to disrupt unlawful action, the likely extent of collateral damage and resulting disproportionality means it is probably the last place that action should be considered. However there may be a few situations where the registry is, indeed, the only place that effective action can be taken, so a process for handling these situations is required. But that process must ensure (if necessary by providing legal protection) that the registry is not compelled to take action that may turn out to be disproportionate.
Originally posted: 29 April 2013 in category
Articles
The Chief Executive of OFCOM, Ed Richards, gave evidence to the House of Commons Culture, Media and Sport Committee last week, in which he reported on progress on the copyright enforcement and web blocking parts of the
Digital Economy Act 2010
.
He first confirmed that the
Initial Obligations Code
was completed and passed to the Government “some months ago” and, now that the Judicial Review of the Act requested by BT and TalkTalk has
confirmed that the Act is lawful
, the draft Code would be reviewed by the Department and also sent to the European Commission for their approval. The Judicial Review did find that the
requirement for ISPs to pay
25% of Ofcom’s costs was against European law, so that a replacement for the current draft statutory instrument on cost sharing would be required. Ofcom also need to set up the independent body to hear appeals against copyright infringement notices. These three activities are expected to run in parallel but all will take several months so it is thought likely to be another twelve months before the first Copyright Infringement Notice is sent out by an ISP.
On website blocking, Mr Richards confirmed that the
report on practicality
of this would be sent to the Secretary of State “this month”. He said that this would not provide a “silver bullet” since blocking cannot be 100% effective, but nor is it likely to be completely ineffective, though he recognised the ability of blocked organisations to change rapidly to “a fractionally different URL”[sic. Does he actually mean domain?]. The report will therefore aim to provide a balanced assessment of the various technical possibilities and the consequences of each of them. A member of the Committee, Louise Bagshawe MP, said that the British Phonographic Industry (BPI) were only seeking for 10-12 websites to be blocked, however Mr Richards pointed out that this number would significantly increase once the wishlists of film and sports rightsholders, book publishers, etc. were added.
A
recording of the session
is available on Parliament TV: copyright enforcement is just after 10:49, web blocking at 10:55. Shortly after 11 the questions move on to media ownership, so I’ve not listened to anything after that!
Expedited suspension of a domain is regarded as a last resort, to be used only where alternative approaches via the registrar or registrant have failed or where there is an urgent need to address a risk of “serious consumer harm”. That seems a good way to express a concept I was struggling to describe: that the crimes involved must involve a sufficiently serious and fast-acting harm to members of the public that the extra time required to have the suspension ordered by a court might significantly increase the harm done. I had only come up with two examples – botnets and phishing sites – but the issue group have added unsafe pharmaceuticals and unsafe (at least I hope they are including that restriction) counterfeit goods.
Requests for suspension should only be accepted from UK law enforcement bodies, through an established route (the Single Point of Contact scheme used for Regulation of Investigatory Powers Act requests is cited as a good example) and requesters will be required to confirm that each request complies with standards of necessity, proportionality and urgency. Suspension may only be requested in relation to criminal acts and the process excludes crimes relating to freedom of speech and certain other offences where the permission of the Attorney General is required for a prosecution.
Finally, the importance of transparency is recognised, with recommendations that there should be an appeals process for individual suspensions and that the whole scheme should be monitored and reported on.
Contrary to our original submission, it seems that compromised domains/websites (i.e. those not originally indended for the criminal purpose they are now facilitating) may also be eligible for suspension. I am somewhat reassured, however, by the recommendation that these domains should only be suspended if contacting the registrar or registrant is ineffective, and by the
evidence
from Switzerland that their temporary suspension of compromised domains has not led to the sorts of
problems
I had feared.
The issue group will meet later this month to consider final comments before submitting their recommendations to the Nominet board.
[Update] It seems I was optimistic in presuming that it was only unsafe counterfeits that were covered. The
latest version of the recommendations
makes all counterfeit goods a separate category (para 7b), more or less admitting that the “immediate serious harm” test from para 7a doesn’t apply to those. That seems a confusing mixture of messages. If I were operating a site that relied on user-generated content (or if I were a registrar selling a domain name for such a site), I think I’d want to be clear if I ran a risk of having my domain name taken away because of the activities of my users. Under the new proposals that depends not just on whether those activities present a risk of “immediate serious harm” to others, but whether the site is “directly involved in the criminal distribution of counterfeit goods”. Given the number of
contradictory cases
on whether eBay, Google, et.al are liable for sales of counterfeits and the different possible interpretations of “directly involved” I’m not sure that second question has a simple answer. A shame, because in other aspects, each draft of the proposals has got better. I hope the next draft will have a tighter wording, more clearly restricting this class of takedowns to domains that have only been registered in order to facilitate the criminal purpose.
Originally posted: 29 April 2013 in category
Articles
With various Governments looking at the Domain Name Service (DNS) as a tool to implement national policy (for example the USA’s SOPA and PIPA proposals) Rod Rasmussen’s talk at the FIRST conference was a timely reminder of the possible problems with this approach.
DNS is a critical part of the Internet, providing the conversion between the names (e.g.
www.ja.net
) that humans use to refer to Internet services and the numeric addresses (212.219.98.101 or 2001:630:1:107:1::65) that computers actually use to communicate with each other. DNS is often explained as a distributed database – to find out the address of
www.ja.net
you have to ask Janet’s (ja.net) part of the database, to find where that ja.net database is you need to ask the authoritative source for .net, and so on. It’s rare for individual PCs to do those lookups – normally they ask for help from a resolver provided by their organisation or Internet Access Provider.
Of course the resolver doesn’t *have* to ask other servers before it sends an answer to the requesting client. Many resolvers will answer immediately if they have recently been asked the same question by another client (known as caching). Or, if its policy requires, a resolver can give an incorrect answer – either saying that a site does not exist or returning a different numeric address. This can be used, for example, when users look up a domain that has been reported as a phishing site to either deny that the site exists, or to send the user instead to an
education page
.
Modifying DNS responses is a very blunt instrument that needs to be used with care, however, since it will affect all information and all services provided from the affected domain. All web pages in the domain – both legitimate and non-legitimate – will become invisible, e-mail may well be impossible to send or receive, and any subdomains are also likely to be affected. If users want to access the blocked information, it is very easy for them to choose an alternative resolver that does not implement the block. Indeed a number of services now offer alternative resolvers specifically to allow users to subscribe to a subset of the Internet that has been filtered to exclude particular types of content. Using DNS filtering against the wishes of users is likely to be ineffective, and may indeed place users at greater risk if it gives them an incentive to move to an alternative resolver that may misuse their personal data: a DNS resolver will see a complete list of the domains you access, and a malicious one may be able to harvest sensitive information such as passwords and credit card numbers. Finally, one of the major current efforts in Internet security is to improve the security of DNS itself by having replies signed to prove that they are valid (known as DNSSEC). Using DNS filtering to return incorrect results will result in DNSSEC validation errors: at best this means that re-direction pages will be invisible, at worst it could make users think that DNSSEC errors are normal and should be ignored (as most users now ignore certificate validation errors).
OFCOM
considered this risk too high to recommend DNS filtering as anything more than a short-term measure for blocking access, despite its apparently attractive simplicity.
DNS filtering can be a valuable tool when it is done for reasons that align with users’ wishes, and where the content to be filtered has its own domain. At present phishing sites and some malware command and control systems are most likely to meet these requirements. Attempting to use it to enforce a policy on unwilling users will not work, and is likely to expose users and the Internet to even greater risks.
#148 - Defamation Act 2013: help for website operators
Originally posted: 26 April 2013 in category
Articles
The passing of the
Defamation Act 2013
this week removes a couple of areas of legal uncertainty if you run a website, blog, etc. and someone else posts an article or comment that may be defamatory. First, provided you aren’t acting maliciously, you don’t risk liability merely by moderating what is posted. Second, the Act tries to ensure that defamation claims are settled either between the author and the person allegedly defamed, or by the courts. Only if both of those approaches are impossible should the website operator have to make the legal assessment whether a post is, or is not, defamatory.
To benefit from the new law’s protection website operators will either have to insist that all contributors publish their names and contact details, or else follow a process that the law will define to allow the complainant to take action against the author. That hasn’t been published or debated yet but, as I
mentioned at Networkshop
, discussion in Parliament of an earlier draft seemed to indicate that although it would require some record-keeping, it shouldn’t be unreasonably onerous.
The law doesn’t affect the existing defences for website operators, so you can still decide to simply remove anything that is the subject of a complaint. But for universities and colleges, who have a legal duty to promote free speech by their members and guests, the new process, which should offer legal certainty, may be more attractive.
This new UK law only applies to defamation, not to other wrongs that authors may commit, and at the moment it’s not clear whether it will apply in Scotland and Northern Ireland. However the European Commission consulted last year on a general
“notice and action” policy
to address the same concerns about the position of website operators, so there should be something that applies more widely in the pipeline.
My
talk
at
Networkshop
looked at some of the changes going on in the law, especially in the measures that those who operate parts of the Internet are expected or required to take to help deal with unlawful activities on line. The law recognises a couple of general roles: Internet Access Providers who provide Internet connections to individuals are required by section 22 of the
Regulation of Investigatory Powers Act 2000
to disclose information about their users to law enforcement officers dealing with crimes, though at present for private networks this only covers information they already have for their own purposes, e.g. enforcing Acceptable Use Policies. Hosting providers who publish content for third parties (e.g. students) on websites, blogs, etc. are protected from legal liability for content they don’t know about, but when notified need to choose between taking the material down or risking potential liability if they leave it up.
The
Digital Economy Act 2010
adds further duties for some Internet Access Providers when informed that their users are breaching copyright. The Act has two aims – to discourage low level infringers, and to allow courts to concentrate on more serious and repeat infringers. Unfortunately the definitions of “ISP” and “subscriber” in the Act are very unclear when you try to apply them to a network such as Janet, and in 2010 it was suggested that Janet might be required to act as ISP and pass on only a subset of infringement reports, thus preventing universities and colleges dealing with individuals under the Janet AUP. However Ofcom’s new draft implementation code confirms that this will not happen, and that we can continue to follow what is recognised as a very effective approach. If universities and colleges get connections from other ISPs, for example as a backup or to provide connectivity to the public, then they need to ensure that they agree on the roles that each will take under the Act, otherwise a university could find itself subject to the same thresholds as a single house.
The
Defamation Bill
provides two new options when hosting providers receive allegations that material they are hosting is defamatory. At the moment they have a simple choice between leaving material up and taking it down. The former may risk liability for defamation, the latter may risk liability for damaging free speech, something universities and colleges have a special duty to protect. Unlike other conflicts between legally protected rights, the law doesn’t seem to allow the host to ask the courts to decide. If the Bill becomes law, posts that are attributed will no longer be the host’s problem – any legal case is between the author and the person they have allegedly defamed. However it seems that “attribution” will require sufficient information to serve a legal complaint on the author, not something many blogs provide at the moment. A more promising approach is a prescribed notification process, where the host is required to pass the complaint on to the author. If the author provides their contact details to the host, then the host is protected from legal claims. The claimant can seek a court order either to have the author’s contact details disclosed, or to have the material removed. The Bill would also mean that hosts couldn’t acquire liability simply by moderating posts, something that has been recognised as a problem with the current law for more than a decade.
Finally, following a number of cases where individuals were arrested or even convicted for comments on social networking sites, the Director of Public Prosecutions has issued new guidance to prosecutors on dealing with online comment. Comments that constitute threats, harassment, or contempt of court should be “prosecuted robustly”; but comments that are merely offensive need to meet a higher threshold for prosecution to be appropriate – they must be grossly offensive, not just shocking, disturbing, rude or distasteful. The guidance has generally been welcomed, though there are still concerns that the crime of “offensive communications” in s.127 of the
Communications Act 2003
may be less suitable for the Internet than the telephone networks for which it was originally created. Posters on social networks can, of course, still be sued for civil wrongs such as defamation, even if a post is only seen by a few hundred followers.
Originally posted: 12 March 2013 in category
Articles
The Information Commissioner has published helpful new
guidance
on how organisations can support the use of personally-owned devices for work, commonly known as Bring Your Own Device (BYOD). This appears to have been prompted by a survey suggesting that nearly half of employees use their own devices for work, but more than two thirds of them have no guidance from their employers. Since the law requires an employer to keep control of personal information for which they are responsible, it’s clear there is a problem.
A BYOD Policy must balance two privacy requirements: protecting the personal information for which the employer is responsible, but also protecting the employee’s own information from the employer.
The policy should start with an audit of what information is involved, and what devices might be used to access it. What corporate information can safely be processed on a personal device; and what personal information might the organisation inadvertently end up processing? Some corporate information and systems may need to be excluded from BYOD, either because it cannot be adequately protected, or because protecting it would represent too much of a threat to the personal use of the device.
The policy should consider where information might be stored: on the device, on organisational storage, or on a public cloud. In each case appropriate measures will be needed to protect it, for example when the device is lost, shared with family members or sold, or if it remains logged in to a remote storage server. Information also needs to be protected when it is transferred: the policy needs to address both deliberate attacks (so encrypted protocols should be used for transfers and some interfaces may need to be disabled by default) and accidents (such as an e-mail being sent to the wrong person).
The policy should also consider how the device will be kept technically secure: some devices and operating systems do not have security patches available, owners may wish to ‘jailbreak’ their devices, or to install applications of their own choice. Each of these may reduce the security of the device, so employers need to provide guidance on how to balance them with the sensitivity of the information the employee wishes to access. Those who expect to access more sensitive information or services may need to accept more restrictions on their choice and user of device.
Technical measures may help, but need to be planned carefully, both because they may need to be set up in advance and because they may themselves represent a threat to privacy. For example one approach to protecting transfers is to monitor the content of network traffic and report or block any apparent leakage of sensitive data. However using this monitoring during an employee’s (or a member of their family’s) personal use could represent a serious and unlawful breach of their privacy. Similarly, technology to securely delete information when a device is stolen is a good way to protect both the employer’s and the employee’s data, however it is often accompanied by location tracking software that could be a serious threat to privacy and safety if it were inappropriately used. Employer and employee need to agree that such measures are proportionate and adequately controlled.
Policy, supported by technology, is the most important tool for using BYOD safely. The policy should be developed with IT, HR and end users. It should contain guidance for both employee and employer on what can and cannot be done with a personally-owned device and how to do it. Since such devices contain information that is valuable to the employer and the employee, a good BYOD policy will benefit both.
#145 - Template for Cloud Privacy Level Agreements
Originally posted: 26 February 2013 in category
Articles
Last year the Article 29 Working Party published an
Opinion on Cloud Computing
expressing concern at the information available to those considering moving services to the cloud about the protection that cloud services offered for their data. The
Cloud Security Alliance
have now produced a template for service providers to provide the information that the Working Party were asking for.
The aim is for Cloud Service Providers to publish a Privacy Level Agreement (PLA) as an appendix to their service contracts, setting out the privacy arrangements for each service. By putting these PLAs in a standard form it should be easier for organisations to determine which services meet both their internal (“is this a safe place for my data?”) and external (“does this satisfy my legal obligations?”) privacy and security requirements. It should also be easier to compare different services – the CSA suggest that providers might offer different PLAs for different services.
According to the template, the PLA should provide various different types of information:
Categories of personal data that may be uploaded to the service: in fact this suggests listing types of information that the service is
not
suitable for, an interesting idea;
How information will be processed in the cloud: including whether the cloud provider is a data processor or joint data controller and how the duties of those roles are delivered;
Data location, transfer, retention, monitoring and security measures: including measures such as Safe Harbor, Binding Corporate Rules and security certifications;
Personal data breach notification: how any breaches will be notified;
Data portability, migration, and transfer back assistance: what options (including additional charged services) are offered;
Accountability of the cloud provider;
Law enforcement access: in what circumstances law enforcement may obtain access to information, and when customers will be notified if this occurs;
Remedies available against the provider in case of breach of the PLA.
Throughout the template there are extensive references to the Working Party Opinion and to publications by national data protection regulators including the
UK Information Commissioner’s Guide
to help providers and customers interpret what is required.
Having Privacy Level Agreements in a form that can be compared with each other and with European guidance on the use of clouds should help both cloud providers and customers. Even better will be if these PLAs are a step towards cloud providers being formally recognised under European laws through measures such as
Binding Corporate Rules
and other provisions in the new Data Protection Regulation.
Originally posted: 20 February 2013 in category
Articles
ENISA’s
Critical Cloud Computing
report examines cloud from a Critical Information Infrastructure Protection (CIIP) perspective: what is the impact on society of outages or attacks? The increasing adoption of the cloud model has both benefits and risks. A previous
ENISA report
noted that the massive scale of cloud providers makes state of the art security and resilience measures more efficient. However the dependency of many customers on a small number of suppliers will increase the impact of any problems that do occur.
Reporting (both in the press and to regulators) concentrates on a few large incidents rather than many small ones, so doesn’t provide useful evidence for the net effect of these opposing trends. However it is clear that cloud providers will become part of countries’ Critical Information Infrastructure (CII) – if they are not already – both because most other organisations will depend on them to some degree, and because of some of the services running on clouds will themselves be in critical sectors such as health, energy and finance. Infrastructure as a Service (IaaS) and Platform as a Service (PaaS) providers are likely to be the most critical because of the number of customers that depend on them and the higher level cloud services they support.
Looking at the four main threats to CII, ENISA conclude that clouds are likely to provide better protection against local power failures and natural disasters, because physical resilience and geographic diversity are a routine part of cloud provision. The elasticity of clouds can also help to protect against denial of service attacks and flash crowds. However the dependence on a small number of platforms is likely to increase the impact of any software flaws, administrative or legal disputes, where problems involving one customer may have side-effects for others.
ENISA conclude that countries need to include clouds in their CIIP programmes and will need information about dependencies among services to assess which are the most critical. Critical cloud providers should be included in exchanges of threat information and best practices on protection, and in exercises to test those measures. ENISA note a tension between increasing standardisation – which allows customers to move between platforms in case of problems – and the risk that systems implementing the same standards may also share the same vulnerabilities. Although large clouds already offer physical redundancy, the possibility of implementing logical redundancy to protect against these common failure modes should also be examined. Finally ENISA stress the importance of encouraging incident reporting, not just through legal requirements but also by rewarding organisations that do report incidents and thereby help improve industry best practice. This is a very welcome turnaround from early laws that saw incident notification as a way to name and shame, thus encouraging organisations to hide their problems.
#143 - ICO on pseudonyms, consent and legitimate interests
Originally posted: 15 February 2013 in category
Articles
It’s interesting to read the
Information Commissioner’s comments on the draft European Data Protection Regulation
, which have just been published. A number of the comments address issues we’ve been struggling with in providing Internet services such as incident response and federated access management. These are widely recognised as benefitting privacy, but they don’t fit easily into a privacy regime that thinks in terms of individuals having pre-existing relationships (or at least chains of relationships) with all those who process their personal data.
The Information Commissioner seems to recognise the problems
Article 4: … there is clearly considerable debate about whether certain forms of information are personal data or not. This is particularly the case with individual-level but non-identifiable – or not obviously identifiable data – such as is found in a pseudonymised database. We prefer a wide definition of personal data, including pseudonymised data, provided the rules of data protection are applied realistically, for example security requirements but not subject access. If there is to be a narrower definition it is important that it does not exclude information from which an individual can be identified from its scope. However, it is important to be clear that a wide definition plus all the associated rules in full would not work in practice. This is a real issue in contexts as diverse as medical research and online content delivery.
On-line content delivery can often be done using pseudonyms, thus protecting the privacy of individual users. Ironically defining those pseudonyms as personal data and on the full range of data protection controls may well mean that a service provider has to collect more personal data than they would otherwise need, thus
increasing
the risk to privacy.
Article 6: There is a danger that processing which is necessary for public authorities but not provided for by law will be prevented. We would like to see explicit recognition that processing may take place where it is clearly in the data subject’s interests and does not override his or her fundamental rights and freedoms.
The draft Regulation would prevent public authorities from using the “legitimate interests” justification for processing personal data. The European Parliament’s amendments would restrict that justification even further for all types of data controller. Both
access management
and incident response could be affected by those changes – telling someone that their computer or Twitter account has been compromised is indeed in their interests, but
restricting legitimate interests too much
could make it illegal.
Article 7: We are in favour of a high standard of consent. We do need to be mindful of the implications of paragraph (2) though. This would mean that if consent is relied on when you buy a book online, for example, there would have to be separate consent to use your details to despatch the book and take payment. Consent could not be implied from the customer’s decision to buy the book. This could be onerous and in many cases pointless. Again, in cases like this the ‘legitimate interests’ condition could be important as an alternative to consent.
Despite some slogans, consent isn’t the only way to legitimise processing of personal data. The ICO points out that using it when it’s not appropriate can produce unusable interfaces. It can also be dangerous for privacy because provided you can persuade the data subject to consent then there is no limit on what you can do. A recent article suggesting that
informed consent should be scrapped
explains the problems but, I think, comes up with the wrong solution. As with suggestions that overuse of legitimate interests means that justification should be scrapped, it seems to me that the right approach is instead to enforce the law’s existing controls – that consent must be freely given, and that legitimate interest cannot override the interests of the individual. That way the justifications can each be used in the situations where they are the right way to protect privacy, rather than forcing use of an inappropriate justification which may well present a greater privacy threat.
Originally posted: 7 February 2013 in category
Articles
The European Commission’s
Cyber Security Strategy
aims to ensure that Europe benefits from a “robust and innovative Internet”. The Strategy has five priorities:
Achieving cyber resilience
Drastically reducing cybercrime
Developing cyberdefence policy and capabilities related to the Common Security and Defence Policy (CSDP)
Develop the industrial and technological resources for cybersecurity
Establish a coherent international cyberspace policy for the European Union and promote core EU values
The first of those is most directly relevant to network operators. Here the Commission see three requirements, to be implemented by way of a
draft Directive
:
Ensuring that all Member States have a basic Network and Information Security capability to include a national NIS strategy, an NIS authority and “a well-functioning CERT”;
Ensuring that those national authorities cooperate to prevent, detect, mitigate and respond to incidents;
Improving preparedness and engagement of the private sector operators on whom the Internet depends.
Breach Notification
The Commission’s
press release
has a detailed list of those “key internet companies”, who will be subject to similar NIS requirements as are already in place for public electronic communications service providers:
Cloud service providers (Dropbox, iCloud, Flickr etc.)
VoIP and other communications services
Social Network providers (oddly Blogger is explicitly included but WordPress is explicitly excluded)
Video and music sharing platforms
Major on-line games
Application stores.
These will be required to demonstrate that they take appropriate measures against NIS risks in designing their services, and to notify the national authority if they suffer “incidents having a significant impact on the security of core services”. The aim is to allow the identification of risks and best practice, as in ENISA’s recent
report on the telecoms sector
. The national authority may decide that the incident also needs to be publicly announced, but only after vulnerabilities have been fixed and taking due account of confidentiality. No time scale is set for these notifications but the text presents them as an extension of the arrangements for telecommunications providers, rather than those in the draft Data Protection Regulation whose 24 hour limit seemed to create a serious risk of
distorting incident response priorities
.
Incident Response Teams
Given that ENISA’s
2012 inventory
lists nearly 200 CERTs in Europe it’s rather odd to find the Strategy and Directive requiring each member state to “set up a CERT”. In fact the
Impact Assessment
reveals that only three member states don’t already have one.
The tasks required of this national CERT are set out in Annex I of the
draft Directive
:
Monitoring incidents at a national level,
Providing early warning, alerts, announcements and dissemination of information to relevant stakeholders about risks and incidents,
Responding to incidents,
Providing dynamic risk and incident analysis and situational awareness,
Building broad public awareness of the risks associated with online activities,
Organising campaigns on NIS
In the UK, at least, those are currently done by a variety of different organisations: it’s not clear whether the Directive would mean changing that.
The draft Directive does recognise that there are already “informal and trusted channels of information-sharing between market operators and between the public and the private sectors” but if the idea is indeed to set up single ‘national CERTs’ then these will need to be very careful not to disrupt the existing relationships that are already deal effectively with many Internet incidents.
#141 - Using technology to enhance incident response
Originally posted: 7 February 2013 in category
Articles
At last week’s TF-CSIRT meeting, Gavin Reid from Cisco suggested that we may have been over-optimistic about how much technology can do to detect and prevent incidents. Automated incident prevention systems can be effective at detecting and preventing automated attacks but are less effective against targeted attacks that use human intelligence rather than brute force. In the worst case an organisation that relies too much on automation may end up designing its security stance to suit the available automation systems, rather than the other way around.
The presentation was a reminder that technology should aim to enhance the abilities of human incident responders, not to replace them. This gives computers two roles: to perform basic analysis of simple threats themselves and to help humans investigate more complex ones. Cisco’s logging of internal systems and networks has been increased: they now record two trillion log records and thirteen billion flow records every day. Transmitting this volume of information to a central logging system could itself cause problems for the network so it is instead held in local and regional databases around the world. Incident responders can then run distributed queries across all these databases to obtain correlated information about particular events from networks, servers, personal computers and customised monitoring systems. Having complete information about network traffic even allows negatives to be proved: for instance that between the time when a system was compromised and when the compromise was discovered there were no network flows that would indicate the export of sensitive information from it.
This approach needs lots of systems and storage, and smart incident responders to use them, but given that most reports suggest that cybercrime is at least as great a threat as physical crime, shouldn’t we be prepared to spend an equivalent amount to protect against it?
Originally posted: 1 February 2013 in category
Articles
An interesting, though depressing, figure from
Verizon’s 2012 Data Breach Investigations Report
is that 92% of information security breaches were discovered and reported by a third party. Not by the organisation that suffered the breach, nor by its customers who are likely to be the victims of any loss of personal data, but by someone else. In many cases, I suspect, the information will have come from observant system and network administrators who, while looking out for problems on their own systems, saw signs – scanning, malware transmission or spam runs – of problems on others’. Fortunately, many of those people feel that helping clean up problems on the Internet is important, even if it’s not formally part of their job.
So it’s vital for privacy that third parties are able to report information about security breaches to the affected organisation, its network or incident response team. At the moment European privacy law does seem to allow that. Although incident response is only explicitly mentioned in a
Directive covering telecommunications operators
, Article 7f of the general
Data Protection Directive
allows personal data (which in many countries includes IP and e-mail addresses) to be disclosed to an organisation if it is in the legitimate interests of either the sender
or
the recipient organisation, provided doing so doesn’t injure the fundamental rights of the individual. Reporting a security breach will generally be in the interests of both the organisation suffering the breach and its affected customers so that justification seems to fit the bill.
The
draft Data Protection Regulation
changes the wording of this section, removing the separate mention of the sender and the recipient of the personal data. Instead, according to Article 6f, disclosure will be allowed so long as it is in the legitimate interests of
a
data controller. I very much hope that includes the data controller who receives it, otherwise the Regulation’s new statement on incident response in Recital 39 will be of much less value. The new draft also places further conditions on using the legitimate interests justification, some of which will be impossible for third party reporters to satisfy: if what you have found is an IP address, username or credit card number then you can’t “explicitly inform” the owner, only try to pass the information on to their ISP or bank. Such provisions need to be very carefully drafted and explained, otherwise they risk choking off information flows that are essential to protect privacy.
There are several current proposals for European laws to require organisations to notify regulators and customers when they suffer security or privacy breaches. The Verizon figures are a reminder that these can only be effective if the law also supports and protects third parties who discover and report the breaches in the first place.
Originally posted: 29 January 2013 in category
Articles
Darknets are well known as a place to look for Internet threats, but a
presentation by RESTENA and CIRCL
at this week’s TF-CSIRT meeting suggested they may also show up other kinds of problems. Darknets are parts of the IP address space that are routed but not used, so there should be no legitimate packets arriving at those addresses. Packets that do show up may relate to scanning, or be responses to attacks forged to appear to come “from” the darknet addresses. Or they may simply be the result of accidental misconfiguration of Internet devices, for example by administrators mistyping their own IP addresses.
At first sight that might seem harmless – surely the worst that can happen is that the service won’t work? – but examining a year’s traffic to two darknets suggests that such typos can result in significant information leakages, or even create opportunities to attack the network where the mistake was made.
For example if someone mis-types the address of a DNS resolver, then any machine listening on the ‘wrong’ address will get a list of the domain names that users are looking up. That may even include machines inside the organisation’s firewall, so an external listener may be able to discover information about the internal network that the firewall is is supposed to hide. And that won’t just be intranet servers: most of the traffic captured by the darknet was intended for network infrastructure servers such as domain controllers and time servers, indicating that network services running on the misconfigured computer were also using the incorrect address and leaking information about important infrastructure services. DNS configuration errors may not be detected by the organisation. Most machines will have more than one resolver configured so as long as at least one of those is correctly configured their users will not report any problems. The misconfigured addresses will just carry on silently announcing what the user is doing.
Other services may leak even more important information. Printers, routers and firewalls are often configured to report their status to a logging server using the Syslog protocol. If the logging server’s address is mistyped then information reported to an external address may range from paper jams to attacks detected by the firewall, or even the complete configuration of the device including the passwords used to update it. Logging systems often use the private address spaces defined by RFC1918, which all firewalls should block from leaving the local network. But if you mistype the network part of an RFC1918 address then that protection, too, is lost.
Errors in configuring DNS and several other services can also be used to attack the misconfigured network. If a machine is sending DNS requests to the wrong address, then a machine at that address could easily send back wrong answers, potentially directing it to hostile websites, mail servers, or anything else.
Using these kinds of error to attack a specific organisation would probably be tricky, since there’s no obvious way to find out what misconfigurations it may have. But the evidence of this study is that there are enough of them around that opportunist attackers might get lucky. Organisations should monitor their network traffic for critical services such as DNS, syslog and SNMP to check that flows, particularly those leaving the organisation, only go where they are supposed to. That way they should detect dangerous configuration error before their enemies do.
#138 - Defamation Bill – process for website operators
Originally posted: 18 January 2013 in category
Closed
[Updated to add clause 6 on peer-reviewed scientific and academic journals]
The
House of Lords debate
of clause 5 of the
Defamation Bill
this week suggested that the Bill might make it easier for universities and colleges to support vigorous debate through their websites.
As Lord May (once the government’s chief scientific advisor) pointed out, publicly telling someone they are wrong is an essential part of developing knowledge. That is why universities and colleges are required by the
Education (No.2) Act 1986
to promote free speech by their members and guests. However under the current eCommerce Regulations a website that does not take down an article after receiving an allegation that it is defamatory may share liability with the author. As both Simon Singh and Nature have discovered, defending scientific criticism in such cases can be very expensive. At present, therefore, universities and colleges may have to choose, without any help from the courts, between their legal duty to support criticism and their legal duty to protect others from unlawful defamation.
Although details of the Government’s proposed process under clause 5 of the Bill have not been published, it seems these would create new options. On receiving a complaint that an article on a website is defamatory, the operator of the website will be required to contact the author if it’s not possible for the complainant to do so direct. For articles by members or guests of universities and colleges this shouldn’t be a problem. The author may either agree to the removal of the article, or ask for it to remain. Provided the author gives their name and legal contact address to the website operator, the operator may leave the article up without risking liability. The author can choose whether or not to allow the website operator to pass those details on to the complainant: in either case the complainant can then take action in court against the author, either immediately or after obtaining a Norwich Pharmacal Order to have the contact details disclosed by the website operator. Provided the operator follows the prescribed process it remains protected from liability until a court orders that the article be removed.
There are some obvious issues about how this would apply to the particular situation of universities and colleges as opposed to the millions of other websites that will be covered:
For most members and guests it’s likely that a university or college would already have the required contact details without asking, though they would be prohibited by data protection law from releasing them without either the author’s agreement or a court order;
For those members who are employees, I suspect that the normal rule that an employer is vicariously liable for what employees do in the course of their employment will take precedence over the new rules for website operators. However
clause 6
of the Bill also contains measures to protect “peer-reviewed statement[s] in scientific or academic journal[s]”; the House of Lords debate seems to confirm an intention that this will cover both print and electronic formats, as well as identifying some of the new types of journal that are now emerging.
The Ministry of Justice have invited comments by the end of the month so I’ll be submitting these. Any other suggestions?
Originally posted: 10 January 2013 in category
Articles
ENISA have published a useful set of
controls and best practices
for managing the risks in a Bring Your Own Device (BYOD) program. They identify three groups of controls
Governance
Legal, Regulatory and HR
Technical (Device, Application, User and Data)
Throughout, the focus is on the owners, not the devices, which seems right. If the owners don’t understand the need for behavioural and technical controls and aren’t provided with the skills and motivation to follow them, then with full control of the device they can ignore or override them anyway. For example it may be cheaper and more effective to support staff in appropriate use of social networking tools rather than to try to impose software on all their devices to prevent loss of business information. BYOD programs should therefore be voluntary, with owners making a positive choice to share their devices with their organisations, understanding and accepting the responsibilities that brings.
There are some interesting ideas on how to encourage participation in the programme, including provision of support, offer of additional services, or even financial benefits! It strikes me that at least the first two have beneficial side-effects for the organisation too. Making things work well for those who participate in the official scheme may bring into the fold those who would otherwise try to connect their devices unofficially (I remember universities achieving successful deployment of quality wifi by a similar technique). Providing or recommending services such as webmail and storage means that the organisation can direct users to options that satisfy the security requirements of both users and the organisation.
There are interesting ideas on keeping organisational and personal use separate, not just in technical terms but also in policy. An explicit policy that organisational support staff and management software will only look at organisational data and applications should help staff/owners trust that their privacy is being respected and encourage them to respect the organisation’s interests in return.
Finally there’s a recognition that this is a very rapidly changing area where new technologies and practices quickly move from brand new to completely routine. Organisations need to work with their staff to incorporate BYOD into their existing systems for managing information security to ensure this is done in a way that benefits both.
There are relatively few changes to the existing text, in particular the four ICC categories of cookie remain the same. Cookies essential for load-balancing, multi-media display and social media sharing are now listed in category 1. Consent is still considered essential for cookies that target or display advertising (category 4) but, like other authorities, there is little practical guidance on how to obtain it. In particular, following the Information Commissioner and Working Party guidance the guide notes that implied consent is not likely to be appropriate for these cookies.
Possibly the most useful addition is an attempt (on page 6) to explain the tricky question of which countries’ laws will apply to cookies. According to the guide there should be a table of different Member States’ implementations of the law somewhere on the
ICC website
, but I’ve not been able to find that yet.
#135 - Art.29WP on Cookies – specific and pragmatic advice
Originally posted: 3 January 2013 in category
Articles
The e-Privacy Directive’s
provisions on cookies
exempt two classes of cookies from the requirement to gain consent (though if they relate to individual users, websites still need to inform users about them, under data protection law):
CRITERION A: the cookie is used “for the sole purpose of carrying out the transmission of a communication over an electronic communications network”.
CRITERION B: the cookie is “strictly necessary in order for the provider of an information society service explicitly requested by the subscriber or user to provide the service”
The Article 29 Working Party has now provided
very detailed interpretations
of a number of common cookie functions and whether they are likely to be covered by those exemptions. I don’t think any of the outcomes are surprising if you’ve been reading the
Information Commissioner’s guidance
, but it’s helpful to have this clear statement of both the guidance and the legal reason for it.
It’s well worth reading the document, as the analysis will only apply where a cookie is only used for that specific purpose and where its lifetime is kept to the minimum necessary, and there may be other restrictions. My summary is as follows:
User-input cookies (e.g. shopping carts): probably exempt under Criterion B (but note comments on cookie lifetime);
Authentication cookies: probably exempt under Criterion B if used within a single browser session; need to warn the user beforehand (i.e. get implied consent) if the cookie will persist across browser sessions;
User-centric security cookies (e.g. to detect repeated login failures): may be exempt under Criterion B, but need to check specific details;
Multi-media Player Session Cookies: probably exempt under Criterion B, but make sure they aren’t used for other purposes;
Load-balancing Session Cookies: probably exempt under Criterion A;
UI Customisation Cookies: short-lifetime cookies probably exempt under Criterion B, for longer lifetimes obtain implied consent as for authentication cookies;
Social Plug-in Sharing Cookies: may be exempt under Criterion B, but only if they are restricted to logged-in users and limited to a session;
Social plug-in tracking cookies and advertising cookies are explicitly said to not be exempt, and the Working Party stress that this includes cookies that are used only to collect profiling information but do not display adverts to the current user.
Finally, and apparently with considerable regret, the Working Party conclude that first-party analytic cookies are not covered by either exemption. However:
the Working Party considers that first party analytics cookies are not likely to create a privacy risk when they are strictly limited to first party aggregated statistical purposes and when they are used by websites that already provide clear information about these cookies in their privacy policy as well as adequate privacy safeguards. Such safeguards are expected to include a user friendly mechanism to opt-out from any data collection and comprehensive anonymization mechanisms that are applied to other collected identifiable information such as IP addresses.
There’s even a suggestion that when the Directive is next revised
the European legislator might appropriately add a third exemption criterion to consent for cookies that are strictly limited to first party anonymized and aggregated statistical purposes
#134 - New Guidelines on Social Media Prosecutions
Originally posted: 20 December 2012 in category
Articles
Following criticism of a number of recent arrests and prosecutions relating to postings on social media sites, the Director of Public Prosecutions has published
new draft guidelines
. These confirm that postings that break criminal laws on threats, harassment and breaching court orders should generally be “prosecuted robustly” under the specific legislation for those crimes.
When considering the more general offence of improper use of a public electronic communications network under
section 127 of the
Communications Act 2003
, the DPP points out that a communication will only break this law if it is
grossly
offensive. This high threshold for criminality requires a communication to be more than offensive, shocking, disturbing, rude or distasteful. The DPP also notes that it may not be in the public interest to prosecute where a communication was not intended for a wide audience, or where swift action was taken either by the author or others, such as service providers, to remove access to it.
Postings on social network sites may also, of course,
breach the civil law
, which is not affected by these guidelines.
Comment on the new guidelines seems generally favourable (e.g. from
Paul Bernal
), but also questions whether the broad s.127 offence (which apparently originates in a law to protect telephone switchboard operators) is still appropriate for the widely available mass publication offered by the Internet.
#133 - Human Rights Committee report on Defamation Bill
Originally posted: 12 December 2012 in category
Articles
The Joint Committee on Human Rights has published its
conclusions on the Defamation Bill
. Among other changes the Bill intends to clarify the position of websites that accept posts from third parties and make it less likely that lawful posts will be removed because of fear of liability. The Committee are “glad to see steps taken to protect website operators who are merely hosting content”, however they are concerned that the new proposals may actually reduce the protection of posts where the host is unable to contact the author.
This is because under the Bill the website operator may lose its defence to liability if it receives a complaint that a post is “defamatory” (
clause 5(6)(b)
). Since there are circumstances in which a defamatory statement may nonetheless be lawful – for example if it is true – this could result in website operators removing lawful material from their sites. The Committee recommend that complaints should be required to explain why the statement is unlawful, in other words both that it is defamatory and that there are no defences available to the poster. The European Ecommerce Directive uses this higher threshold and a
High Court case
earlier this year found that a web host did not have “actual knowledge of unlawful activity” because it could not determine whether any defences applied to the article complained of.
The Committee also note that the actions that will be required of a webhost if it is able to contact the author will be set by Regulations, which are not yet available. Since these Regulations will have a significant effect on the balance between the human rights of privacy, free speech and reputation, the Committee consider that they should be debated in Parliament rather than adopted by default.
Finally, the Committee recognise the particular problems that the Bill would create for universities and colleges who would have
conflicting legal duties
to promote free speech but also to remove defamatory material. They recommend that the Government provide statutory guidance for universities and colleges on how to respond to complaints of defamation, rather than them having to risk liability for a breach of one or other of these duties.
The Bill is due to start its committee stage in the House of Lords next week. The government is also expected to consult on the Regulations for website operators.
Originally posted: 11 December 2012 in category
Articles
The
Joint Committee on the Draft Communications Bill
has published its report, concluding that while there is “a case for legislation which will provide the law enforcement agencies with some further access to communications data” the current proposal needs “substantial re-writing”. The Committee address three of the four concerns raised in our
Janet evidence
.
They are concerned that clause 1 “goes much further than it need or should”, in giving the Secretary of State “sweeping powers to issue secret notices to communications service providers (CSPs) requiring them to retain and disclose potentially limitless categories of data”. Instead they recommend that any Bill brought to Parliament should be limited to the categories of data for which a case can be made now, specifically:
Information to allow the subscriber using a particular IP address to be identified. This information ought to be already covered by the Data Retention Regulations, so it’s not clear whether the concern is information from networks using NAT or networks that do not log their allocation of IP addresses to subscribers. However the Committee seem persuaded that this information should be covered by a new law;
The Home Office identified “data identifying which services or websites are used on the internet” as information that may be important for investigations. The Committee interpret this as “what websites a person has accessed, and also contacts with other internet services, such as smart phone applications”. They note that requiring an ISP to collect this information “would place massive storage demands on CSPs and would be costly” and that even a list of websites visited can be highly sensitive. They consider that Parliament is the right place to debate and decide how to balance these costs against the benefit to law enforcement;
Information from overseas providers of webmail and social networks to users in the United Kingdom. According to the Home Office evidence many of these services already provide information voluntarily in cases of emergencies or serious crimes; there would also be a jurisdiction problem in trying to compel retention or disclosure as it is unlikely that UK law could formally be enforced against a foreign service provider. The draft Bill therefore contains options both to obtain communications data directly from such foreign services and to require UK access networks to collect the information (presumably using deep packet inspection though this is technically challenging and would be expensive to keep up to date). The Committee conclude that the latter option “makes CSPs rightly nervous” and say that rules limiting when the option would be used must be given statutory force.
Rather than the draft Bill allowing the Home Office to add new data types or authorities allowed to access them, the Committee consider that any extension should be subject to effective Parliamentary scrutiny.
On the system for obtaining access to stored data, the Committee consider that current best practice under the
Regulation of Investigatory Powers Act
should be made a statutory requirement. Authorities that make frequent use of data access powers should have trained Single Points of Contact (SPoCs) to check that requests are correct, authorities that use their powers less often should be required to use shared SPoCs such as the current National Anti-Fraud Network (NAFN) who can maintain the required expertise. Inspections of SPoCs should be used to build public confidence that powers are being used correctly and that any invasion of privacy is necessary and proportionate. Other supervisory powers and processes should also be strengthened and a specific criminal offence of misusing communications data be created.
The Committee quote, and agree with, our view that the current definition of “communications data” is flawed and even go further, concluding that the “language of RIPA is out of date” and that the classes of communications data “should be re-drafted” in a way that reflects the different levels of privacy sensitivity of different data types. However they make no comment on the other definitional change – that data retention requirements currently only applicable to public electronic communications services could in future be imposed on any “telecommunications operator”, a term defined in the draft Bill so as to include any person or organisation who connects two computers together. The Home Office seem to have admitted this broadened scope by saying that they might issue notices to “CSPs which are not covered by the EU Data Retention Directive”. The draft Bill places no limit on such notices, but the Home Office suggested private networks might only “be asked … to retain for 12 months data which they already create for business purposes” (in other words to behave according to the current Data Retention Regulations). If the restriction to public networks were to be removed then such a notice might cover Janet though we have no information about individual users of university or college networks.
The
Intelligence and Security Committee
has also reported on the draft Bill, and from the summary that has been published it seems they have similar concerns. News reports suggest the Government has agreed that the Bill
will need to be re-written
in the light of the Committees’ reports. Since the Joint Committee strongly recommended a further consultation before it is brought to Parliament, we should have the opportunity to provide further comments on any revised version.
#131 - Law Commission on Contempt of Court and the Internet
Originally posted: 6 December 2012 in category
Articles
The Law Commission have published an interesting consultation paper on how the
law of contempt of court is affected by the internet
. Anything that “tends to interfere with the course of justice” may be considered contempt: the
Contempt of Court Act 1981
deals in particular with communications addressed to the public at large or a section of the public, published while proceedings are active, which create a substantial risk that the course of justice will be seriously impeded or prejudiced (s.2). Courts may make orders (for example under sections 4 and 11) warning that publishing particular information will be considered contempt (you’ll often here these referred to in press coverage as “reporting restrictions”).
Historically it has only been the traditional news media – newspapers, TV, radio – who were able to “address the public at large” so current procedures and punishments for contempt are designed for them. Internet publication, for example through blogs and twitter, now means that individuals may also be able to communicate sufficiently broadly that they may fall within the definition of contempt. While noting that “not only are professional journalists potential publishers for the purposes of the 1981 Act, but so is any citizen who writes a blog or posts emails or tweets to a section of the public” (3.33) the Law Commission suggests that it be left to courts to decide in each case whether a communication has been made to “a section of the public”. The number of recipients of the communication is likely to be a factor, thus e-mail is thought unlikely to reach the threshold but a message on Facebook or Twitter might (3.28). As the Attorney-General pointed out earlier this year, users of those, and similar, media need to be
careful when commenting on current cases
.
If individuals now have the publishing tools to commit contempt, they at least need to be able to find out when a section 4 or 11 order has been made. At the moment the Law Commission discovered that even media companies may have problems finding notices (or, more important, being confident that a particular case is
not
subject to a notice), so they recommend at least adopting a Scottish pilot system that lists on a website all cases where notices are in force (2.102).
Publishing on the internet typically involves a number of different parties (author, host, various access providers, etc.) so there are often challenges in applying any law regulating “publication”, to ensure that duties are assigned to the appropriate parties. It turns out that the Act’s requirements for knowledge seem likely to ensure that hosts and access providers are protected from strict liability – to be liable a publisher must “know or have reason to suspect that relevant proceedings are active” while a distributer must “know or have reason to suspect that what they distribute contains infringing material”. Even if these particular tests fail, the usual eCommerce Directive provisions for hosts and networks should apply.
However the definition of contempt does create a problem because of the requirement that “proceedings … are active … at the time of publication”. The current law on on-line defamation holds that “publication” occurs every time an article is read (“multiple publication”), which the
Defamation Bill
would change to be only when the article is originally posted (“single publication”). For contempt of court, the Law Commission seem unhappy with either of these options. A multiple publication rule would mean that authors would have to remember everything they had posted and consider whenever an arrest was made or legal proceedings begun whether old articles might need to be temporarily withdrawn. On the other hand a single publication rule would leave the courts no way to block articles that were lawful when written but now represent a serious risk to justice. This problem could already occur with newspaper archives however the Law Commission consider that these are subject to a “fade factor” so that an old newspaper article is less likely to interfere with justice than an internet posting, both because it is obviously “old” and because it may be harder for a juror or witness to find. By contrast, internet searches can as easily find material published yesterday or years ago, with little to distinguish the two.
To strike a balance between these options the Commission suggest (3.68) that courts might be given the power to order either an author or intermediary to temporarily remove a publication. Contempt would then only be committed if the recipient of an order did not act on it, without having a reasonable excuse to justify their behaviour. This sounds like the familiar notice and takedown approach to internet hosts, however the Commission suggest that “in some cases” it might be necessary to make an order against “anyone who has sufficient control over the accessibility of the specific publication”, including internet access providers (as has been
done for copyright infringement
) or even DNS registries. Since these methods can result in
disproportionate damage to legitimate material
and businesses it is important that legislators and courts take at least as much care in drafting and using them as they have for copyright cases.
Originally posted: 4 December 2012 in category
Articles
The Committee on Advertising Practice (CAP) has announced new
rules on online behavioural advertising
. UK advertisers will be expected to comply with these rules from 4th February 2013. Unlike the much-discussed
cookie law
, the CAP rules are technology neutral, concentrating instead on the actions involved in providing on-line adverts that are targeted to individuals’ patterns of behaviour across multiple websites.
The rules apply both to the display of targeted adverts, and to the collection of information from which patterns of behaviour are derived. Wherever a third party organisation collects behavioural information across the websites of multiple companies, the third party organisation must document this both on their own website and in or around the resulting adverts. Individual advertisers are required to cooperate with the Advertising Standards Authority to identify third parties if required. Users must be able to opt out of both having adverts displayed and of having their browsing habits collected. Where collection is done in a way that will capture substantially all an individual’s browsing history – for example in collaboration with their ISP – this may only be done after the individual has given their explicit consent.
Originally posted: 20 November 2012 in category
Articles
ENISA’s study on the “
Right to be Forgotten
” contains useful reminders that once information is published on the Internet it may be impossible to completely remove it. Implementing a right to be forgotten would involve four stages:
Identifying and locating the information to be removed;
Tracking all copies that may have been made, including unauthorised copies and modified versions;
Determining who has the right to request removal (for example if a photograph shows two or more people, which of them is entitled to delete it?);
Removing the information, including all copies and modified versions.
The report notes that Internet technology allows anyone – without requiring any form of authorisation – to copy, modify and republish information, and that technology cannot keep track of these activities. As a result it is generally impossible to even locate all copies and versions of information, let alone find any organisation with the authority or jurisdiction to ensure all of them are removed.
The report concludes that a law (such as the
proposed EU Data Protection Regulation
) might be able to make information harder to find, though a national or European law would still be limited to Internet search and hosting services within its jurisdiction. But ultimately if you want to be certain of keeping control of information, don’t put it on a public website.
Although the Directive claims to regulate “transfers” of personal data out of the EEA, it is not clear what constitutes a transfer. Although discussion sometimes concentrates on the location of disk drives, “from a service perspective, it is more relevant to consider from where the data can be accessed. However, the hosting location of data remains relevant with respect to the applicability of national law. This is even more obvious where (national) authorities would need physical access to data”;
The Directive asks whether the country to which information is transferred has adequate protection, but for a cloud service with data centres around the globe, which country should be checked?
The Directive expects the cloud client, as data controller, to select appropriate security measures even though when using a cloud “it is not realistic to expect from a large provider with many customers to tailor its technical infrastructure or organisation to meet the specific compliance requirements of each customer on the basis of individually negotiated contracts.”
The Opinion suggests that the draft Regulation might help with all of these:
There is more scope to use contracts, rather than geography, to ensure adequate protection. These might use model clauses approved at EU or national level, or be individually negotiated. National regulators or the Commission might help by developing model contracts specifically designed for cloud services;
Cloud providers with an establishment in an EU country could use
Binding Corporate Rules
to cover processing by their whole global organisation and might even extend these to external sub-contractors;
The new requirements to notify regulators of security breaches and, if necessary, to implement minimum security measures will help cloud clients know what security measures they need to take and what they can rely on from their provider.
Finally the Opinion looks at the issue of access to personal data by law enforcement and other state authorities. Within Europe such access is governed by the Rule of Law and subject to scrutiny by regulators. The EU DPS suggests that these same requirements should be included in future bilateral and international negotiations of Mutual Legal Assistance and trade agreements.
#127 - Defamation Bill – Joint Committee on Human Rights
Originally posted: 15 November 2012 in category
Consultations
Parliament’s
Joint Committee on Human Rights
has asked for evidence on the
Defamation Bill
, so I’ve sent in a
Janet submission
pointing out the human rights issues that could be raised by the Bill. Although the aims of the provisions on websites are to increase the protection of free speech while ensuring that genuinely defamatory statements are dealt with quickly, it’s not clear from the current draft that this will be achieved. In particular
Website operators need to be sure of the circumstances when they can rely on the defence that the statement was posted by someone who can be “identified”;
The process for dealing with complaints about statements whose posters cannot be identified must not create a greater risk to the privacy rights of both alleged defamers and (since the process may well be misused) of those who are the subject of unwarranted complaints; and
A website operator who wishes (or is required by law, as for universities and colleges) to promote free speech must be able to leave a posting up until it has been considered by a judicial authority, without risking liability as under the present notice and takedown regime.
Originally posted: 13 November 2012 in category
Articles
An interesting
paper from ENISA and the NATO Cyberdefence Centre
illustrates the narrow space that the law allows for incident response, and the importance of ensuring that new laws don’t prevent incident response teams from protecting networks, systems, their users and information against attack. By comparing the details of German and Estonian law, the report also highlights just how different national laws can turn out, even when they are aiming to implement the same international legislation. The report looks specifically at the problem of deal with botnets, which may involve laws on surveillance, examining network traffic, processing personal data, and accessing or modifying computers. These laws are the subject of international instruments – EU Data Protection and telecommunications law and the EU Framework Decision on Cybercrime.
Detecting compromised computers that are part of a botnet involves looking at patterns, and sometimes content, of their network traffic. The first question raised by the report is whether this activity might fall within surveillance law. Normally it should not, since the subject of investigation is computers, not people. However it is possible that over-broad drafting of either law or judgments could bring network investigations within scope. Investigations, particularly if they involve looking at content, are likely to be covered by laws on the privacy of communications. German communications law protects traffic patterns (who sent packets to whom) as well as content but fortunately the law does allow network operators to examine this information where this is necessary “to recognise, limit or eliminate a disturbance or error of the telecommunication systems”. The Supreme Court has recognised “sending of spam, the dissemination of malicious software (trojan horses, viruses etc.) and the misuse of computer systems for running DDoS” as causing such disturbances. German law therefore allows network operators to retain and use all logs for seven days, and those relating to a particular incident for as long as it takes to resolve the incident. Disclosing information (unless it is first anonymised) or breaking encrypted or password-protected traffic are still illegal.
The German telecommunications law only extends to network operators, however, not to the operators of websites and other networked services. These organisations only have the general data protection law to rely on, and the authors are concerned that this may not give them a justification for looking at network traffic, producing a “lack of synchronisation” in the law. Estonian law seems to have a similar problem, though here the data protection law only provides for civil, and not criminal, sanctions. Hosts and networks could take the view that neither a botmaster nor a victim is likely to sue them for unlawful processing of personal data – a risk that the authors think “rather theoretical”. It would be better if these anomalies were fixed and incident responders given a secure basis for what they do (note that this is contained in the proposed Data Protection Regulation).
A common way to investigate botnets and other malicious network traffic is to set up a honeypot – a computer that offers itself as vulnerable but is in fact configured to collect information about attempts to compromise it. Honeypots seem to fall outside communications privacy laws, since the honeypot is a party to the communication so cannot intercept or surveil itself. This leaves data protection as the relevant law, so honeypots should be careful only to collect traffic that is necessary for their purpose.
The desired outcome of a botnet investigation will usually be to take down its command and control servers. Incident response teams are unlikely to be able to order an ISP to disconnect a server, though authority to do so is often included in ISP contracts. The report suggests that police may be able to order the disconnection of a command and control server (or to do it themselves) under general powers to protect the public order.
It is sometimes suggested that since botnets often include the ability to update software on infected computers, this technology could also be used to ‘clean up’ the botnet if access is gained to its command and control servers. The report warns that the law may prohibit this since the clean up will involve modifying the content of computers without the consent of their owners. Unauthorised modification of a computer is one of the best established cybercrime offences, and laws don’t usually consider why the modification is being done, only whether the person doing it knows they are unauthorised. A ‘good worm’ or botnet update will commit exactly the same crime as a bad one. Furthermore laws are now being implemented to criminalise the creation of tools, not just their use, so disinfection seems likely to face even more legal hurdles in future.
#125 - How to Succeed in Federated Identity Management
Originally posted: 13 November 2012 in category
Articles
A paper on “
Economic Tussles in Federated Identity Management
” provides some interesting insights into which FIM systems succeed and which fail. A simplistic summary would be that success requires a win-win outcome, where every party (Identity Provider, Service Provider and User) gains some benefit from adopting a federated approach. Viewing federations as a two-sided market provides some deeper insights and perhaps pointers to how such outcomes can be achieved.
A two-sided market has two groups of participants, each group gets increased benefit as the number of participants in the other group increases. So a Service Provider (SP) will only be interested in a federation if it contains Identity Providers (IdPs) to whom the SP wants to provide service, and vice versa. Such markets are likely to involve conflicts of interest (referred to in the paper as tussles) between the two groups. For example in identity federations:
Who gets to collect transactional data?
For services that rely on profiling users either for direct income or to improve their service to attract more users, information about which users do what is very valuable. The parties may not have free rein in this area since Governments may (and in EU do) regulate what is done;
Who gets to set rules of authentication?
In general IdPs reduce costs by making registration and authentication of users to be as easy as possible; SPs reduce risk if those processes to provide strong guarantees. However there is a significant first-mover advantage, so an IdP that can offer a large number of users may persuade SPs to accept lower strength authentication;
What happens when things go wrong?
Both IdP and SP are likely to suffer damage both if an authorised user cannot gain access or if an unauthorised user can. Each would naturally prefer the other to carry the burden of this damage. Federations where there is a shared interest in restoring proper service and less concern about allocating blame/cost suffer less from this tussle.
Who gains/loses from interoperability?
If anyone loses then federation is unlikely to succeed, no matter how large the incentives for other participants are.
Even if it is not possible to agree common positions on these tussles individually then federation may nonetheless succeed if parties recognise that the overall balance is fair: for example if the parties that gain the most also carry most of the risk. Different examples of successful federations suggest that there can be very different ways of achieving this.
Education federations (InCommon and WAYF are the two cited) are seen as succeeding because they align nearly all of these interests. In particular service providers see significant benefit in not having to maintain accounts for each individual user (indeed for site-licensed content the SP may not even know who individual users are). This contrasts with the apparent failure of OpenID, where despite a very large number of users, service providers seem to have perceived reduced user information as a significant loss. For SPs who rely on advertising OpenID’s release of name, country, e-mail address and perhaps language, gender or picture, even though it is far more than most educational IdPs will release, appears to be insufficient. This is contrasted with the success of Facebook as an IdP, which shares “name, gender, list of friends, and all public information stored by Facebook; all profile information, including birthday, education and work history”. This set of attributes is apparently rich enough to compensate SPs for their reduced profiling ability.
The authors conclude that, contrary to Tolstoy, every successful federation is successful in its own way. That suggests that linking even successful federations together may be quite a challenge.
#124 - Cloud Computing Security: Benefits and Risks
Originally posted: 11 November 2012 in category
Articles
An interesting
presentation
by Giles Hogben of
ENISA
at TERENA’s
CSIRT Task Force
meeting in Heraklion last week, looking at security issues when moving to the public cloud computing model.There have been several papers on technical issues such as possible leakage of information between different virtual machines running on the same physical hardware (for example by
Ristenpart et al
), but the talk suggested that the major impacts actually come from the organisational change.
Here there are both risks and benefits: both arising from the fact that using a cloud (as with any type of outsourcing) means that you are depending on someone else to provide security. That could be seen as a risk, since the outsourcing organisation no longer has direct control of security measures and clouds are a “big juicy target” for attackers. However it may well be that the cloud operator is actually better at doing security than the outsourcer: many security measures such as patch management and filtering scale very well to large systems and a cloud provider is more likely than a small or medium enterprise to be able to recruit and retain a team of security experts.
So cloud security may not be either “better” or “worse” but it’s definitely different. ENISA’s full
report
is definitely worth reading.
Originally posted: 9 November 2012 in category
Presentations
[This is the approximate text of an internal company talk, which I’ve been asked to make more widely available]
One of the odd things about how people talk about the Internet is that you’ll hear it described both as “the Wild West” where there are no rules and unlawful behaviour is rife and as a “1984” situation where everything we do is monitored and our privacy routinely trampled on. But how can the same thing possibly be both of those?
It seems to me that one of the problems is that the Internet tears up one of the fundamental planks of how we have done laws and regulation in the past: geography! If you look at a
map of Europe
it is easy to point to the answer to “Where does UK law apply?”. It is also easy to point to the answer to the less obvious question “Where does UK law
not
apply?”. That’s everywhere else: just hop over to France, Belgium, Netherlands, …
But if you look at a
map of the Internet
, both those questions become a lot harder to answer. Suddenly there’s nothing we can point at and say “that is the UK”. Nor, since computers physically in the UK can have addresses and connectivity from all over the globe (think of multi-national companies with internal networks) is there anything we can point at and confidently say “that
isn’t
the UK”. This might explain why both the “Wild West” and “1984” views are prevalent…
If you look at the Internet map and conclude that “UK is nowhere” then you might well conclude that UK law is nowhere too. And if you can’t punish behaviour that breaks your rules, you might be tempted to try to modify the system to make it harder to break those rules in the first place. Thus, for example, courts in the UK, Netherlands, Finland and other countries are ordering ISPs to block traffic from their customers to certain websites that the courts have found to breaching copyright law.
Other parts of the internet infrastructure can also be used to try to prevent law-breaking. Since the .com top level domain is managed from US territory, US law enforcement authorities have been able to order that certain .com domains, considered to be breaching US law, should no longer point to the original websites but to a page warning visitors that they may be acting illegally. Unlike ISP-based blocking, that change applies to users everywhere in the world: there is only one .com. And it turns out that it can also apply to websites all over the world – two of the domains that were transferred belonged to Spanish and Canadian companies, both of which were acting lawfully according to their home courts. So which law should apply to them?
So far domain name suspensions seem to be done manually, at human speed. However a number of content hosting sites now process complaints and remove material automatically. Software has been used for a long time to search the Internet for apparent copyright infringements and to generate reports. If an automated reporting program encounters an automated takedown program then humans may have difficulty regaining control: this seems to have been the problem that interrupted live streaming of a science fiction awards ceremony and the Mars landing, as well as the temporary disappearance of over a million education blogs.
On the other hand you could look at the Internet map and conclude that the disappearance of the English Channel and all other geographical features means that law need no longer be constrained by any real world features. This seems to lead to the “1984” view: that the law can go anywhere. In a number of cases, courts seem to have agreed: French courts found a US company liable under French anti-Nazi law for adverts posted by US users, while an Australian court found another US publisher liable for defaming an Australian businessman even though there seems little doubt that the publication was protected by US laws on free speech. Such extra-territoriality works both ways: American laws against on-line gambling have been used to detain senior executives of companies whose activities are entirely lawful in their European homes. In the real world law enforcement powers have always been strictly contained by geography: dealing with International crime is notoriously difficult as a result. The Internet’s absence of obvious borders seems to be relaxing these rules – it is reported that Dutch police will be allowed to install monitoring software on computers that may be outside the country, while the UK’s draft Communications Data Bill seeks to have overseas providers collect and retain information about e-mails and other forms of communication.
You might hope that the Wild West and 1984 views would cancel each other out, but in fact they seem to reinforce each other through the medium of technology. The effect of the UK court order blocking access to The Pirate Bay appears dramatic: according to a
BBC report
, traffic to the site dropped by 75% as a result. Apparently UK law can, after all, be enforced against a site based in Sweden. Except that when a similar block was implemented in the Netherlands there was
no obvious effect
on the volume of peer-to-peer traffic, which is the main way TPB material is distributed. Why this apparent contradiction? It seems likely that blocked sites, and their users, respond by switching to technologies that aren’t affected by the block. For example TPB has recently announced that it will be moving its servers to the cloud, making any block harder to implement and much more likely to affect other, lawful, sites. Even more worrying: if, as seems to have occurred, individuals respond by adopting technologies that get around blocks those technologies are likely to eliminate
all
blocks, including those implemented by organisations and ISPs to protect people and their computers against serious harm.
So it seems that making laws that work on the Internet, without serious side-effects, is going to be hard at least until we work out the different characteristics of this new space. It’s tempting to leave this to professional law-makers – it’s their job, after all – but the evidence so far suggests that they need help. It is not so long since a European briefing note suggested creating a single European cyberspace with a secure Schengen perimeter. At least there are some signs of recognising that the on-line world is different, though if you are seeking certainty then “online identifiers need not necessarily be considered personal data in all circumstances” may not seem promising! My
on-line blog
records my activities with Janet, its customers, its peers and law and policy-makers to try to help.
Personally I hope that both the “Wild West” and “1984” views are wrong, and that we can come up with something that works a little more like the real world. There personal and social behaviour, with a bit of law enforcement when needed, means we mostly get along OK.
Originally posted: 5 November 2012 in category
Articles
There was an excellent line-up of speakers at Janet CSIRT’s conference this week.
Lee Harrigan (Janet CSIRT) discussed how the team are now monitoring Pastebin for signs of security problems affecting Janet sites. Pastebin can be a useful place to share large files, however some users apparently don’t realise that things posted to the site are publicly visible. This means that posting documents containing passwords or other sensitive information is not a good idea. Pastebin is also used by some Hacktivists to advertise embarrassing information they have taken from their targets. Around 90% of the alerts that Janet CSIRT obtain from Pastebin appear harmless, however giving Janet-connected organisations early warning of the other 10% may help them reduce the impact.
DI Stewart Garrick talked about the work of the Police Central eCrime Unit (PCeU). The unit, though part of the Metropolitan Police in London, provides support to forces across the country in dealing with computer crime where life, the economic survival of an individual or business, or more than £1M are at risk. Their processes are designed to deal with the particular challenges of computer crime, for example their forensic procedures produce early results within hours rather than weeks and they have quick and effective working relationships with forces in other countries. Investigations and prosecutions no longer stop at the UK border. It also seems that courts are recognising the seriousness of computer crimes, with those convicted being sentenced to several years in prison.
Rich Hutchinson talked about the MRC/UCL epiLab-SS service, used to handle medical research data. The sensitivity of this information needs particularly good security and the team decided this was best provided by running servers in a secure third party data centre, accessed from UCL using thin client systems. To reassure funders and those whose information may be stored in the system the service has now been certified as compliant with ISO27001. The support of both management and researchers was critical in this achievement.
Tony Brookes (University of Derby) has been studying data security breaches reported to the Information Commissioner’s Office (ICO) by various parts of the public sector. Most of these result from human error – sending personal information to the wrong recipient or losing files on paper, USB sticks or laptops – rather than technical failures. Nor does preventing or mitigating these require advanced technology – standard disk encryption is recommended in nearly every ICO report. Failure to learn lessons, both from your own incidents and those of others, now seems likely to result in a monetary penalty from the ICO. Since these can now be up to £500K this is a risk that organisations should be aware of and taking steps to reduce.
Graham Cluley (Sophos) reviewed the past, present and future of viruses, starting in the days when Doctor Solomon’s anti-virus was updated each month (by floppy disk!) to add around 200 new viruses. Today more than a hundred thousand new viruses are discovered each day – fortunately anti-virus programs now detect most of these by their suspicious behaviour and do not need to be updated individually for every one. Propagation methods have changed: effective anti-spam filters mean that many fewer infected e-mails reach users’ inboxes (though you should still beware of clicking on unexpected attachments). Instead viruses are now concentrating on social media (Facebook, Twitter, etc.) both because technological solutions are less well developed and because users are much more likely to click on links sent by their friends or those they follow. Once one account is infected, the virus can send itself through genuine messages from that person to everyone in their network, as well as collecting all the personal information that may have been stored in each infected account. From monthly updates in the post to daily updates by download we may now need to move to live checking by our browser every time we visit a new URL.
Chris Wakelin (Reading University) finished the day with a look at the techniques that malware uses to try to evade detection. Complex encoding schemes are used to hide the fact that a file contains executable code, with Java and PDFs being the most commonly infected files. Ensuring these applications are kept up to date is essential to reduce the number of successful infections. Monitoring network traffic patterns can often confirm that an infection was successful and, by looking for similar patterns elsewhere, detect other infections by the same malware. Once a computer has been infected modern malware makes so many subtle changes that the only way to be sure that it has been cleaned is to wipe the disk (including the boot record) and re-install from a clean backup. Patches, flow monitoring and backups remain vital security tools.
#121 - Justice Committee: “Back to the drawing board” on Data Protection Regulation
Originally posted: 2 November 2012 in category
Articles
The House of Commons’ Justice Committee has published a critical
report on the European Commission’s proposals for a new Data Protection Regulation and Directive
. While recognising the potential benefits to be had from reducing the current differences between Data Protection laws in different Member States the Committee considers the current text to be much too prescriptive and to place too great a burden on both organisations and regulators.
On the Regulation (applicable to most processing of personal data):
11. The Regulation is necessary, first to update the 1995 Directive and take into account past and future technological change; and secondly to confer on individuals’ rights that are necessary to protect their data and privacy as stipulated in the Lisbon Treaty and the EU Charter of Fundamental Rights. (Paragraph 102)
12. However, the Regulation as drafted is over-prescriptive as to how businesses and public authorities should comply to ensure these rights are upheld. We have been told that the Information Commissioner’s Office will require substantial extra resources, and businesses have argued that many administrative burdens will be imposed on them. (Paragraph 103)
13. We believe that the European Commission has a choice: It can continue to pursue the objective of harmonisation through a Regulation by focusing on the elements that are essential to achieve consistency and cooperation across Member States, whilst entrusting the details on compliance to the discretion of data protection authorities and the European Data Protection Board; alternatively, it can use a Directive to set out what it wants to achieve in all the areas contained in the draft Regulation, but then leave implementation in the hands of Member States, and forgoing an element of harmonisation and consistency. (Paragraph 104)
On the Directive (applicable to processing for policing and justice):
20. From the point of view of the data subject, the draft Directive provides a weaker level of data protection in comparison to the draft Regulation. We recognise the significant differences in the handling of sensitive personal data by law enforcement authorities, but in a number of respects this lower level of protection does not appear justifiable. During negotiations, the Government should seek to amend the draft Directive so that data protection principles are as consistent as possible across both EU instruments. This will additionally ensure that the rights set out in the Lisbon Treaty are upheld. (Paragraph 149)
21. The Government’s position is that the Directive will have limited application to the UK, due to Article 6a of Protocol 21 of the Treaty on the Functioning of the European Union. If this is the case, we believe it will be beneficial to the UK as law enforcement authorities will not be bound by over-prescriptive measures contained within the Directive. This would also mean that EU law will not apply to the domestic processing of data, such as between police forces. Domestic processing for criminal justice matters will continue to be covered by the Data Protection Act 1998. (Paragraph 150)
Given these concerns and the Commission’s apparent wish to have the legislation agreed before the next European Parliament elections in 2014, it has been
suggested
that an urgent change of approach will be needed.
Originally posted: 24 October 2012 in category
Articles
October 24th is the annual
Internet Watch Foundation
awareness day. Discussion of the IWF often highlights, and rightly so, its success in
reducing the availability of indecent images of children on the internet
. But the most important result of reporting images to the IWF is when the police, notified by the IWF and its peer hotlines in other countries, are able to rescue real children from real abuse. As Suzie Hargreaves, IWF CEO, wrote last year, that’s what
truly motivates
the IWF’s analysts to do their unpleasant jobs.
As a member of the IWF, Janet is proud to support that work financially and with our staff time and, most importantly, by encouraging our customers, should they encounter illegal images on the Internet, to
report them to the IWF hotline
. Thanks.
Originally posted: 17 October 2012 in category
Articles
Malicious software, generally shortened to malware, is involved in a wide variety of security incidents, from botnets and phishing to industrial sabotage. Analysing what malware does and how it can be detected, neutralised and removed from infected computers is an important part of keeping networks and computers secure.
However there are many millions of different items of malware. Many are variants of a single program, others form families apparently derived from or inspired by each other, some may be unique. Teams analysing malware therefore need to be able to work together both to avoid repeating analysis of a sample or family that has already been done, and to allow specialists in particular areas to combine their skills on particularly complex samples. Malware repositories, where samples can be submitted and kept securely for collaborative analysis and documentation, are increasingly important. A common model is for any member of the public to be able to submit a malware sample to a repository but only analysts trusted not to misuse samples or information are given access to read and analyse the submissions.
production, sale, procurement for use, import, distribution or otherwise making available of … a device, including a computer program, designed or adapted primarily for the purpose of committing any of the offences …
as well as the possession or use of such programs. Fortunately for malware analysts and all those who benefit from their work the Treaty and most laws in this area allow circumstances when production, possession, supply and use will be lawful. Malware repositories involve both the possession and supply (to analysts) of malware; the analysis process may well involve using malware against test systems and creating malware samples to check defences. It’s therefore important that laws designed to discourage and punish criminal uses of malware also recognise and allow the vital work of defending computers, networks and users against it.
Member States shall take the necessary measure to ensure that the production, sale, procurement for use, import, possession, distribution or otherwise making available of the following is punishable as a criminal offence when committed intentionally and without right for the purpose of committing any of the offences referred to in Articles 3 to 6
Well-run malware analysis and repositories should fit comfortably within that, as their activities are definitely not “for the purpose of” committing the defined offences. Indeed the
European Parliament’s committee
scrutinising the proposal explicitly recognised the problem:
Given the possibility to use programmes in dual forms, i.e. for legal as well as criminal purposes, the possession of a tool should as such not be punishable. In addition, the purpose of the actions described in this article should only be punishable when it is clearly aimed at committing an offence.
and proposed amending Article 7 to remove possession entirely and require “clear purpose” to commit an offence. This draft legislation seems to be heading in the right direction.
The UK amended its
Computer Misuse Act
in 2006 in a less satisfactory way. The new
Section 3A
of that Act has different requirements for making, supplying and obtaining to each be a crime:
For making a software program, s3A(1) requires the person to “intend” to commit an offence;
For obtaining a program, s3A(3) requires them to have “a view to” commit an offence;
But for supplying a program, s3A(2) only requires that they “believe that it is likely” that it will be used to commit an offence.
[mere possession of malware is not an offence; under s3 of the Act testing it will not be an offence so long as a the tester is authorised by the owner of the system (preferably, the tester will be the owner of the system) and takes appropriate measures to prevent the test infection spreading]
Guidance to prosecutors
published by the Crown Prosecution Service recognises that there may be both good and bad reasons for having the same software, and gives a number of factors that may indicate the intention (relevant to the acts of “making” and “obtaining”) of an organisation when deciding whether or not to prosecute.
Robust and up to date contracts, terms and conditions or acceptable use policies…
and awareness of the law are good signs that responsible malware repositories should already have. However “supplying”, which a malware repository does each time an analyst downloads a sample, needs a bit more thought, as here the test is not the supplier’s intention but whether recipients are “likely” to use the sample to commit an offence. It would seem hard to argue that an open repository that let anyone download samples was not “likely to be used” to commit offences, but restricting access to trusted analysts should be enough to change that to “unlikely”. The CPS guidance confirms that prosecutors should consider
what, if any, thought the suspect gave to who would use it; whether for example the article was circulated to a closed and vetted list of IT security professionals or was posted openly.
Written policies and records on granting access to the repository are likely to be valuable evidence of appropriate care being taken.
Thanks to
CIRCL
for asking an interesting question.
#118 - Information Commissioner on Backups and Deleted Files
Originally posted: 17 October 2012 in category
Articles
The Information Commissioner has published new guidance on
when information will be ‘held’ by a public authority
for the purposes of the Freedom of Information Act (note that Scotland has its own law and guidance). Paragraphs 28-36 of the guidance deal with the tricky topic of deleted computer files and backups.
The guidance suggests that the focus should not be on whether it might be technically possible to recover a file, but on whether the authority’s behaviour indicated an intention to do so. Thus leaving a file in a computer’s recycle bin does indicate an indication to recover it, but emptying the recycle bin is a sign of no further intention (even if it might be technically possible to reconstruct the file from hidden information on the disk).
For off-line storage the guidance distinguishes between backups, where the information is only kept as a “safeguard against disaster”, and archives, where there whole purpose of storage is to allow future recovery. Identifying which storage is which, and treating it in accordance with that identification, is therefore important. The guidance highlights a recent Tribunal case where the absence of a “fixed policy on the deletion and reuse of the backup tapes” seemed to indicate that the tapes were actually being used as an archive.
Although it will be up to a future Tribunal case to determine whether this was actually the reason for the decision, documenting and following a clear deletion and reuse policy for backups may be important if you don’t want to have to search them to respond to Freedom of Information requests.
#117 - EU Network and Information Security legislation
Originally posted: 12 October 2012 in category
Closed
I’ve submitted a
Janet response
to a European consultation on
a future EU Network and Information Security legislative initiative
. The consultation itself seems to suffer from “if you only have a hammer” syndrome: if you’re a legislator then it must be tempting to think that all problems (lack of reporting of “cybercrimes”, insecure end-user computers, etc.) can be solved by legislating. Our response suggests that it may be more productive to deal with the why and how – show organisations and individuals the benefits of being secure, and explain how they can do it.
The good news is that in a number of areas there is now evidence of that working: I’ve pointed out end-user services such as
GetSafeOnLine
and Germany’s
anti-botnet service
. It was also recently
reported
that most of the reports of privacy breaches to the UK’s Information Commissioner are now voluntary: organisations that don’t have a legal duty to report breaches are nonetheless seeking the Commissioner’s help when they happen. Reporting, whether of breaches or attacks, seems much more likely to work where reporters see direct benefits in terms of improved information and guidance on securing their own systems, as in ENISA’s new report on
major outages in European telecommunications services
.
Originally posted: 11 October 2012 in category
Articles
The
Defamation Bill
arrived in the House of Lords this week. Most of the
debate
concentrated on how to reform the definition of defamation and the court processes for dealing with it. However Lord McNally (at Column 934) gave a good summary of the twin problems affecting websites that host content provided by third parties:
It is also a fact that our current libel regime is not well suited to the internet. Legitimate criticism sometimes goes unheard because website operators, as providers of the platforms on which vast amounts of information are published, often choose simply to remove material which is complained of rather than risk proceedings being brought against them. Meanwhile, individuals can be the subject of scurrilous rumour and allegation on the web without meaningful remedy against the people responsible.
Clause 5 of the Bill proposes measures to try to find a better balance but, as in the Commons, there was general regret that the Government has not yet provided details of how this will be achieved. The Government aims to have consulted on these by the end of the year.
A couple of speeches seemed to suggest that the solution was to disclose the identity of the author whenever a complaint was received – the Bill iself is silent on whether this is what is intended – but Viscount Colville spotted (at Column 944) that this would replace a freedom of speech problem with a privacy problem:
However, I ask the Minister to be aware that the clause could be used by people who want to unmask the identity of an anonymous individual, maybe a whistleblower or someone like that, by using a spurious defamation claim to force a website operator to do so. There needs to be some burden of proof when making the claim that a remark is defamatory before it should be removed.
The detail of the Bill will now be examined in the Lords’ Committee stage.
#115 - Thinking about “Privacy in Context” and Access Management Federations
Originally posted: 8 October 2012 in category
Articles
One of the big challenges in designing policies and architectures for
federated access management
is to reconcile the competing demands that the system must be both “privacy-respecting” and “just work”. For an international access management system to “just work” requires information about users to be passed to service providers, sometimes overseas. The information may be as little as ‘this user has authenticated’, but it will usually include an anonymous ‘handle’ so the service can recognise the same user on future visits, and may sometimes include the user’s real name and e-mail address. Since in some circumstances disclosing that information would definitely be perceived as
not
respecting privacy, the challenge for a federated access management system seems to be to work out where that line is, and not cross it.
In search of help, I’ve been reading
Helen Nissenbaum’s book “Privacy in Context”
. To greatly (over-)simplify her model, she proposes that our lives involve many different contexts, each of which has norms for the kinds of information flows that are expected. So the information flows within a family are different from those in a school, or a workplace or a doctor’s consulting room, but in each one we nonetheless have a sense that our privacy is being protected. If, on the other hand, information flows in a way that we don’t associate with that context (either unexpected information, or to unexpected people or in unexpected ways) then we feel that our privacy has been violated because, in terms of the model, “contextual integrity” has been broken.
This does seem to match my instincts and how I see others behave, and explains why my notes on privacy have for a long time said “surprise makes it worse”. The book gives a number of examples where new technologies violate existing contextual norms and thereby cause unease or offence: smartcard systems for toll roads pass more information to more parties than paying cash; Google Streetview (and, I think, paparazzi long lenses) violate the norm that information flow in a public place is symmetric – if you can see me, I can see you. When designing technologies for existing contexts, we need to be aware of any new data flows and be very sure that they support the purpose of the context.
However it seems to me that the model doesn’t yet offer much help with predicting how people will perceive privacy in completely new contexts, or when a technological system covers multiple contexts. Thinking in terms of contexts and norms suggests there could be four ways things could go wrong:
The user and service agree on the context and its norms, but one of them breaches the norms. This is the all-too-familar situation where organisations suffer monetary penalties under the Data Protection Act;
The user and service agree on the context, but disagree what the norms for that context are. This could easily happen due to cultural differences (for example in Scandinavia individuals’ salaries and taxation are routinely known but in the UK they are widely regarded as private). In the real world it takes a bit of effort to get to a different culture where norms may be different and we are generally aware when we do – hence “when in Rome…” – but on-line it seems to me there is greater risk of tripping over this problem. I suspect these will show up as outraged users with services genuinely puzzled what they did wrong;
The user and service disagree on which context applies. I think this is what the book is hinting at by pointing out that “friends” on a social network service may not be “friends” (i.e. covered by the norms of the “friendship” context) in real life. And I suspect this may also explain a lot of the unease and concern about secondary uses of information by on-line services: my norms for the “customer” context may not match the shop’s norms for its “business” context when it comes to gathering and using information about patterns of customer behaviour;
And finally there are new services that don’t obviously reproduce an existing real-world context. Here I suspect the book’s model suggests that each party will start with what they feel is the most relevant context, with huge possibilities for confusion and offence as different users and the service provider may choose differently. For example I’m bewildered by Twitter where I am consciously adopting my “speaking at a conference” context (if I wouldn’t say it from a podium then @Janet_LegReg won’t tweet it) but others seem to use “press release” context, “water-cooler” context, “domestic” context, or even all of those at once! What on earth are the norms here and how could a service be designed to respect them?
I’ve a nasty feeling that federated access management may be one of these multi-context systems. Although we are currently developing and using it for research and education, there is interest in working with other types of service (for example with commercial suppliers offering student discounts). And even within R&E there are at least two contexts and three different sets of information flows: student, teacher (asymmetric flows are common in the classroom so the expected information disclosure by the two is different) and researcher. Researcher is a particular puzzle since it appears to require both deep collaboration and intense secrecy, at least before publication.
The book hints at two possible approaches to these kinds of hard question: either treat the system as a neutral infrastructure (like the telephone) and leave it to users to decide what their norms are, or else develop existing norms in a way that promotes the purpose of the context. Unfortunately the first of those seems to rule out active participation by the infrastructure in ensuring that things “just work”, while the latter involves trying to work out and, to some extent, codify into systems’ architectures and policies what real-world context(s) and norms users think/feel they are inhabiting.
#114 - Information Commissioner Guide to Cloud Computing
Originally posted: 4 October 2012 in category
Articles
The Information Commissioner has published new
Guidance on the Use of Cloud Computing
for organisations who are, or are considering, using cloud services to process personal data. The benefits of clouds are recognised: these may include “increased security, reliability and resilience for a potentially lower cost”. However cloud customer organisations may also “encounter risks to data protection that they were previously unaware of”. The guide uses a wide definition of cloud computing – “access to computing resources, on demand, via a network”, and recognises that clouds may be layered, for example software as a service may run on infrastructure as a service from a different cloud provider.
The starting point is that moving processing from in house to a cloud service does not change the organisation’s legal status as data controller for any personal data. The same organisation still has overall responsibility for data protection compliance, even though as a cloud customer processing may be shared with cloud providers acting either as data processors or data controllers. Moving to cloud may even create new processing (for example of users’ access and activity logs) and introduce new compliance requirements.
The law requires that there be a written (which includes electronic “writing”) contract between the cloud customer organisation and the cloud provider. Cloud customers should “take care” of entering into contracts that are not negotiable or that allow the provider to change the contract terms without the customer’s agreement. If necessary the organisation should choose a provider based on the appropriateness of its contract. Performance of the contract should be monitored and reviewed to ensure that expectations and contractual duties are being met; for layered services the cloud provider needs to inform the customer of any changes to its arrangements for the underlying platform(s).
The Guide’s approach to compliance is based on risk: “often, the question may be not whether the personal data should be put into the cloud but what the data protection risks are and whether those risks can be mitigated”. The cloud customer should select and document which data and which processes are done by which provider: there may be some processing and data that need to be kept in house because they represent a particular risk. For large or complex services, a formal Privacy Impact Assessment may be appropriate.
Assessing and mitigating risks is mostly about understanding what will and may happen to information and what measures are in place to protect it. Security (both electronic and physical) of the cloud service is obviously an important issue, though it may be more appropriate for the provider to have this audited and monitored by a third party rather than individually by every customer. Customers should know what access control and encryption (both for information in transit and at rest) are used and ensure they are suitable for the sensitivity of the information. Where security or access tools are available to the customer, staff should be trained in how to use them correctly. The service’s policies on data deletion (especially if the customer withdraws from the service) and access by the provider (for example for support services) should be checked. Additional processing by the provider should only be permitted with the agreement of the customer. These questions are summarised in a helpful one page checklist.
International transfers of information are often a concern in using cloud services, but here the Information Commissioner’s Guide continues its risk assessment approach. Cloud customers should know where data may be processed, under what conditions and subject to what safeguards. The Guide includes examples on page 19 and 20 of processing both inside and outside the European Economic Area and shows the kind of safeguards that may be appropriate. Finally there is a recognition that cloud providers in any country may be required to disclose information to law enforcement authorities; the Guide concludes that provided the customer had contracted for appropriate safeguards and the provider had only disclosed in response to a legitimate legal requirement, regulatory action against either would be “unlikely”.
The Guidance is a positive approach to an important new technology.
Originally posted: 4 October 2012 in category
Articles
Earlier in the year I
wrote
about the German ISP Association’s scheme to remove the economic disincentive for ISPs to inform their customers of botnet infections on their PCs by providing a centrally-funded helpdesk. In Latvia a different approach has been taken: providing a “responsible ISP” mark that consumer networks can use on their websites and other promotional materials. To be entitled to use the mark an ISP must satisfy three conditions:
When notified by the Latvian hotline for child abuse imagery of illegal material on web hosting services, remove it;
When notified by the Latvian national CERT of a computer infected by malware, inform the relevant customer;
Provide content filtering services to customers who request them.
Interestingly, Latvia report the same problem as Germany: that if an ISP contacts a customer and recommends installing anti-virus or other security software, this is sometimes interpreted as a sales call rather than a security warning. The same solution has been adopted – to refer customers to advice provided by an independent third party, in this case the National CERT.
#112 - Progress on a European approach to Cloud Computing
Originally posted: 28 September 2012 in category
Articles
The ASPIRE study on the future of National Research and Education Networks calls for European NRENs to work together on a
common approach to cloud computing
. The European Commission has just published a
Cloud Strategy
that also seeks a common European approach, noting that “faced with 27 partly diverging national legislative frameworks, it is very hard to provide a cost-effective cloud solution at the level of digital single market”. This is helpful progress for those who want to use clouds to provide services, but there still seem to be some differences in what national laws and regulators regard as the right approach.
Most of the differences in interpretation seem to fall in two main areas: how much monitoring of the cloud provider each customer organisation needs to do, and how to deal with the geographically dispersed nature of clouds (particularly, but not only, the fact that clouds may include components outside the EEA). Clearly the two are linked, one of the
Article 29 Working Party’s concerns
was that because cloud resources move around, the customer wouldn’t know which physical location(s) they needed to check and monitor.
Unfortunately those two areas are also critical to the economics that make clouds work. Cloud providers do simple, standard things on a massive scale, with very limited customisation. It seems highly unlikely that security monitoring by every customer could be compatible with that business model. Clouds also use geography as part of their service model – high-speed global networks mean that users can access their information and services no matter where on the globe they are so services use geography as a benefit rather than a constraint: putting equipment wherever power and cooling are most cost-effective, and operating their own services from wherever the necessary skills can be found. A requirement to only store information in Europe might be feasible within that model – Europe covers climate zones where computers can relatively easily be kept at the right temperature and also has regions where electricity (including from renewable sources) is reasonably cheap. However a requirement to only operate equipment from within Europe could be more of a problem: clouds are expected to run 24 hours of the day and Europe only covers three different time zones. For operations over(European)night it looks a lot more cost-effective to have support staff working on other continents during their office hours, responding to requests, monitoring services and, where necessary, accessing them remotely. At least some European case law suggests that that non-European access might trigger regulatory problems.
So what might a model, acceptable to European regulators, European customers, and international cloud providers, look like?
All the recent guidance now seems to agree that security accreditation and monitoring by a third party, against a globally recognised standard, is preferable to requiring every customer to check for themselves. How best to resolve the geographical requirements of the law seems less clear, with a number of different alternatives being mentioned. The Article 29 Working Party produced a template for
Binding Corporate Rules (BCRs) for Data Processors
, which the Commission now seem to favour. According to the current Data Protection Directive an approved set of BCRs will satisfy the requirement that personal data be protected according to European standards. However the Commission also seem to be encouraging the development of standard contracts for cloud services – another approach the law recognises as acceptable. Meanwhile both the
Dutch
and, particularly,
UK
regulators have recently stressed the need for customers to do a risk assessment to satisfy themselves that exporting personal data from Europe is acceptable. For this risk assessment approach, at least, a model where information is stored in Europe and only accessed from outside in clearly defined circumstances seems helpful.
Although there doesn’t yet seem to be complete agreement, there do now seem to be ways to address both the geographic and monitoring issues, and do so in a way that fits the economic model I’ve suggested above. A single BCR approval and security certification/monitoring would satisfy all customers (so scales well); individual customers need to assess the risks to personal data they process whether they use cloud services or not; support services (even if not storage) could continue to benefit from geography because, wherever in the world they were, support staff would be subject to the BCRs.
Originally posted: 20 September 2012 in category
Articles
ENISA have published an interesting report on
cyber incident reporting
. Their scope is wide – incidents range from the failure of a certificate agency to storms creating widespread power (and therefore connectivity) outages. In each of these areas they find a common pattern, where governments are trying to encourage (or mandate) notification of incidents in order to learn lessons and improve both the Governments’ and the respective industries’ ability to resist and recover from such incidents in future. It’s good to see recognition of this function of incident reporting, since its requirements are different from those involved in notifying customers how to protect themselves from the consequences of incidents. Improving technical and business practice requires sharing detailed information about how incidents occurred and were treated – information that could be both commercially and nationally sensitive. This is most often done either by reporting to a trusted third party (often a national regulator) who can analyse the information and disseminate lessons learned without disclosing their source, or by sharing information within industry exchanges covered by strict confidentiality agreements.
The European Commission seems to have recognised that diverse national reporting schemes may create an unnecessary burden for infrastructure companies and organisations that often work in more than one European country. However ENISA point out that the current European approach, which involves a mixture of general and sector-specific regulation, may still leave the same organisation having to report the same incident through a number of different reporting schemes. The problem seems particularly severe for telecommunications services:
Public Electronic Communications Networks and Services (PECN/S) are already required to report incidents affecting service availability under Article 13a of the Telecoms Framework Directive. Different member states have different procedures, though there is a standard template and notification process for national regulators (in the UK’s case Ofcom) to report to ENISA;
Those networks and services are also required to report incidents affecting privacy to national privacy regulators (the Information Commissioner in the UK) under Article 4 of the Telecoms Privacy Directive;
The proposed Data Protection Regulation would require
all
organisations to report incidents affecting privacy to their national regulator, though the thresholds and timescales for reporting are currently different from those in the Telecoms Privacy Directive;
The proposed Regulation on Digital Signatures and Electronic Identities also contains an incident reporting requirement, potentially to yet another national regulator. Given the wide definition of electronic identities in the Regulation it is likely that many telecommunications providers will also be covered by this;
And the current Cyber-Security strategy consultation suggests that there should be further mandatory incident reporting for critical infrastructure sectors, networks and “services critical to the functioning of the Internet” including e-commerce and social network sites. Again there are obvious overlaps with the schemes above.
This complexity and overlapping doesn’t seem helpful for something companies and organisations ought to be participating in for their own benefit (it’s encouraging to see that the vast majority of
privacy breach notifications
to the Information Commissioner are now voluntary). Indeed it’s tempting to think that if reporting incidents is so hard that organisations need to be compelled by law to do it, then maybe we’ve got reporting processes wrong!
ENISA point out another reason why reporting needs to be made simple and cost-effective, both for the creators and recipients of reports, which is that you want to be able to set the thresholds for reporting low enough that you get sufficient reports to extract patterns and trends. One of the characteristics of the Internet that has challenged law enforcement for years is that it allows a criminal to cause significant harm by committing large numbers of small crimes. Statistics and responses that focus only on individual large incidents will miss these, even though in aggregate they may cause much more damage, suffering and loss of confidence in the e-infrastructure.
Finally I’m delighted to see explicit recognition that reporting is less urgent than actually fixing the incident: that incident response must “not [be] slowed down by legal reporting requirements”. As I noted in our
response to the Data Protection Regulation proposal
, if organisations with limited resources have to choose between fixing an incident and getting fined for not reporting it within 24 hours then some may well be tempted to do the wrong thing. A premature incident report is likely to be worthless for learning lessons anyway, as if the incident response hasn’t been completed then it’s very unlikely that the organisation will know what happened or how it could have been prevented.
#110 - Cooperation between CERTs and Law Enforcement
Originally posted: 17 September 2012 in category
Presentations
I participated in an interesting discussion last week at ENISA’s Expert Group on Barriers to Cooperation between CERTs and Law Enforcement. Such cooperation seems most likely to occur with national/governmental CERTs but I’ve been keen to avoid recommendations that they be given special treatment, not least because of the risk that such treatment might actually
create barriers
between them and other CERTs. The need for cooperation is recognised by both sides but seems surprisingly hard to achieve.
It seems that a fundamental problem may be the ways in which the communities naturally transfer information. CERTs tend to concentrate on problems within their own constituencies and to send information about other constituencies to the CERTs for those constituencies. Information generally flows proactively
into
the constituency where the problem is. At least when seeking prosecutions, law enforcement authorities tend to work in the opposite direction – after an event has occurred in a particular part of the Internet, asking the relevant CERT to provide information about its own constituency. It’s not surprising that processes set up to transfer information in opposite directions have problems lining up. A further difficulty arises if the information is needed as evidence, because there are still different legal formalities about how evidence needs to be collected, preserved and documented. In some countries evidence that does not meet the local standard is unusable.
An easier area to start with may be Law Enforcement’s increasing role in disrupting criminality (for example through the UK’s
Serious Organised Crime Agency
). For this, agencies are interested in information/intelligence, rather than evidence. The distinction may not always be clear – one of the most often cited reasons for not sharing information with law enforcement is a fear of loss of control, particularly that information shared in confidence may end up becoming public as evidence in a trial. A number of projects have addressed this, from the UK’s National High-Tech Crime Unit Confidentiality Charter (
unofficial copy
) to the NISCC
Traffic Light Protocol
, which is useful as a simple bridge between the different classifications used in public and private sectors. Organisations that have developed Memoranda of Understanding with regular partners reported that the process itself was very useful in building both trust and understanding.
Another key concern is that law enforcement may be unable to reciprocate in any information sharing. Information about current investigations clearly needs to be kept confidential until it is used in a trial, perhaps years later. However letting CERTs know that information they provide is useful will help them both to justify effort spent on sharing and guide what information it might be valuable to share in future.
It was felt that both of these issues would be helped by promoting the idea of “information exchange”, rather than “disclosure” or “sharing” that might be seen as either uncontrolled or one-way.
Finally there still seems to be a problem in expressing what sort of information would actually be of interest to law enforcement rather than overwhelming them. Law enforcement are concerned with crimes, incident responders are concerned with network policy violations, but both can only deal with the subset that are “interesting”. Every attempt by a virus to infect a computer is both a crime and a policy violation, but neither a CERT nor a Law Enforcement Agency could possibly deal with every one individually. The need to explain to each other our subconscious “that’s interesting” filters may be one of the harder barriers to overcome.
Any exchange of information clearly needs to be done in accordance with the law. In the UK the position for network information is
relatively clear
: for information about the use of a network law enforcement can order disclosure using a notice under section 22 of the
Regulation of Investigatory Powers Act 2000
, for other personal data a network operator may disclose it under section 28 or 29 of the
Data Protection Act 1998
if persuaded that it is necessary and proportionate for national security or crime prevention purposes respectively. However as in ENISA’s study on
information exchange between CERTs
, it seems that variations in national data protection laws and their interpretation – particularly in their treatment of Internet identifiers such as IP addresses – can cause significant uncertainty and problems. Since 2009 there has at least been a statement in EU law (though not always reflected in national transpositions) that responding to network and computer incidents is a legitimate reason for processing personal data where this is necessary and proportionate; this is strengthened in the
proposed Data Protection Regulation
. Unfortunately the inconsistencies may be even greater when dealing with law enforcement agencies because current European law does not require their national data protection provisions to be harmonised. Even the revision of the Data Protection framework seems unlikely to resolve this issue, as law enforcement will still be treated separately, so common data exchange agreements satisfying the data protection requirements of all parties may be the best approach for the foreseeable future.
Originally posted: 17 September 2012 in category
Articles
The US Government’s CIO Council has published an excellent
toolkit
to help organisations develop appropriate policies for employees to use their own laptops and smartphones for work (known as Bring Your Own Device or BYOD). The toolkit identifies three different technical approaches to controlling the security of the organisation’s information:
Use virtualisation so that the device acts only as a terminal and information is never stored locally; or
Allow local storage but only within organisation-controlled software (referred to as Walled Gardens); or
Require only limited separation between organisation and personal data that can be implemented by a combination of policies, practices and technical controls agreed with the user/owner of the device.
Each of these (and indeed the fourth option of prohibiting BYOD) will be appropriate for different organisations and different information.
However the toolkit recognises that BYOD is not just, or even mainly, about technology. Moving from a mobile computing policy, where staff use company-owned and controlled laptops and smartphones, to BYOD may involve considerations of training, support systems (including cloud), shared financial contributions (for equipment purchase, connectivity charges and maintenance) and taxation, privacy, ethics (acceptable use on a device used for business may be different to a purely personal one) and even laws on employment, health and safety, freedom of information and evidence. The toolkit contains case studies of three US Government agencies with successful, but quite different, BYOD programmes and examples of the kinds of policies that may be required.
The toolkit reports that “in the right environment, BYOD programs can be an enormous success”. It should help other organisations in both government and industry to identify whether their environment is suitable and, if so, to achieve similar results.
#108 - Defamation Bill – Clarifications on Third Reading
Originally posted: 14 September 2012 in category
Articles
The
Defamation Bill
completed its passage through the House of Commons this week with only minor changes to the provisions for third party postings on websites:
A new power (
New Clause 1
) will be created for a court to order takedown of an article if it has been the subject of a successful defamation case. This avoids the situation where a claimant wins their case but the defendant does not remove the defamatory article;
There is a helpful clarification (
Amendment 6
) that web hosts can moderate posts without risking losing their defence to defamation (note that this won’t apply to copyright and other legal liabilities);
It has also been clarified (
Amendment 5
) that the author of a post will be considered “identifiable” (so the webhost doesn’t need to do anything) if the article has sufficient information for a claimant to initiate legal proceedings against the author (so a name and address would be enough but I’m not sure about an e-mail address or other online identity).
So it seems that the Bill envisages three possibilities when a web host is notified that an article may be defamatory:
If the article contains sufficient information to initiate legal proceedings against the author, the website can wait for the outcome of those proceedings;
If the author cannot be identified then the host must (as at present) decide whether it wants to take the risk that the article will be found defamatory;
If the article does not identify the author, but the web host has sufficient information to contact them, then the host may follow a specified process to avoid liability. Unfortunately this process has not yet been published by the Government – the opposition noted that this means the Bill “deals inadequately with the treatment of website operators”.
The Bill now moves to the House of Lords, where there seems likely to be more discussion of the website provisions. The process for situation (3) will be critical for protecting free speech, victims of defamation and whistleblowers. If the process is too onerous for web hosts then they are likely to continue with their current notice and takedown approach. The process must therefore be simple, but somehow permit victims of defamation to obtain a remedy without stopping use of the web to highlight genuine problems. The Government has said it hopes to consult with stakeholders before the end of the year.
Originally posted: 10 September 2012 in category
Articles
Last week’s
REFEDs
and
VAMP
meetings in Utrecht invited identity federations to move on to the next series of technical and policy challenges. Current federations within research and education were mostly designed to provide access to large commercial publishers and other services procured by universities and colleges for their individual members. Services and arrangements are often structured nationally, whether because of procurements, licensing or simply language. In these cases the home university or college both authenticates the user and grants them permission to use the service (so contributes to both authentication and authorisation). Each home organisation will have a relatively small number of agreements with service providers, each agreement benefitting a large number of users and lasting for a number of years. For both the service provider and the home organisation it is worth spending time and effort on technical, social and legal issues to get this large-scale, long-term relationship right. Federations have therefore tended to form around organisations and service providers in national groupings.
The VAMP meeting highlighted another use case where identity federation could be very useful: international research collaborations. These vary from large global experimental collaborations – such as CERN or LIGO – to informal groups or researchers wishing to continue discussions after a conference. Neither of these actually want to do their own identity management: LIGO’s excellent
analysis of risks and benefits
points out that doing less system administration means they can do more and better science. However research collaborations differ from publishers in a number of significant ways:
The use of a particular service is likely to be initiated by individual users, rather than their home organisations. Users may wish to collaborate in “strong groups” – which have their own funds, legal status, etc. – or “weak groups” that are much more informal;
Authentication and attributes may not originate from home organisations. Some members of the group may not have a Home Organisation so will need to authenticate either at a “home for the homeless” or through a social network provider; some authorisation decisions may rely on attributes that home organisations cannot provide, for example identifying
which
“Andrew Cormack” (yes, there are several of us in Internet-land!) is to be accepted as a member of the group. Systems and organisations that provide only authentication or only attributes need to be incorporated into the federation infrastructures;
Collaborations are more likely to be international, so have to work across the existing framework of national federations. Some will have stronger requirements than existing federations provide (e.g. on authentication credentials, or process audits): others may not need so much, or be unable to satisfy the requirements for membership;
There are likely to be far more collaborations than publishers and their members are likely to be sparsely distributed across organisations. Enabling access to each particular collaboration will therefore benefit only a minority of the organisation’s members, so it needs to be much simpler. Standards for “types” of collaboration service may make configuration easier: Internet2 are already working to define a “research and scholarship” category, but there may be others.
These differences raise the question of how much of the existing federations’ technical and social/legal infrastructure can be re-used. Two extremes would either be to require every collaboration service to join every national federation where it may have members (as commercial publishers sometimes do) or to create a new federation per collaboration and require organisations to join all those in which their members want to participate. Neither of these seems ideal, though for the first few participants either might appear simpler than approaches that will scale better in the medium and long terms. Participants will need to accept that although one quick-fix may make their lives easier, ten different quick-fixes will be a lot more painful than adopting a general approach in the first place.
For scalability we need to re-use existing components, either by providing gateways to translate between them (in both technical and legal terms, as appropriate) or by accepting that other people’s approaches are “close enough” (a well-established European legal approach called “harmonisation”), and only invent new mechanisms where there are genuinely new requirements. The challenge for federations and collaborators will be to identify the sweet spots where a system or agreement can offer enough commonality to be useful, but not demand so much that it excludes some people or organisations who need to participate. For this reason I was nervous to hear a desire that federation should work “like a social network” – anything that comprehensive seems bound to exclude some people (who may be in other equally good, and equally exclusive, social networks of their own).
With large federations already having tens or hundreds of members, and millions of users, it seems highly unlikely that we will all be able to switch to a new approach in a big bang. Instead we need to accept that a hybrid approach will be needed for some time, while identifying the small steps that will move us closer to a global federated identity system that can support research collaborations of all types and scales. Such a system must be international: groups such as REFEDs and VAMP will be important to share national ideas, requirements and experiences and develop them into an increasingly internationalised framework.
Originally posted: 29 August 2012 in category
Closed
I’ve sent in a Janet response to the EU’s consultation “
A Clean and Open Internet
: Procedures for notifying and acting on illegal content hosted by online intermediaries”. At the moment the E-Commerce Directive (transposed into UK law as the
Electronic Commerce (EC Directive) Regulations 2002
) says that websites aren’t liable for unlawful material (either criminal or civil) that is posted to their sites by third parties until they are either notified of alleged illegality or gain knowledge of it by other means (including their own investigations). Once they do know about the material they must remove it “expeditiously” to avoid liability thereafter.
This has been criticised both for discouraging sites from moderating or checking what is posted, and for encouraging them to remove material as soon as any complaint is received. The latter problem was highlighted as a
human rights
issue by the Law Commission in 2002, and I’ve recently discovered that the OFT pointed out that it could also be a
consumer protection
one (if reports of bad service are suppressed by legal threats) last year.
Within the limits of what is mostly a checkbox form for responding, I’ve tried to highlight those problems, particularly as they affect education organisations who may be expected (and sometimes required by law) both to proactively check content and to promote free speech. At the moment both of those are actually discouraged by liability law.
However in designing a better system it seems to me that there are two different kinds of illegality that may need to be dealt with separately. For one kind it’s actually impossible to tell from the posted content alone whether or not it is unlawful. For example content can’t be defamatory if it is true, and it can’t breach copyright if the poster has permission to post it. The website host can’t determine those from the information it has. For that sort of material I’ve suggested that the poster does need to have a “right of reply” to an allegation of law-breaking, whether that is established by a right to have material put back after take down (as in US law for copyright) or by requiring the poster to be contacted before material is removed (as seems to be the idea for the UK’s new
Defamation Bill
). For the other kind of material – which includes malware and indecent images of children – it is clear from the material itself that it is unlawful, so a right of reply would simply delay the process of removing something that is plainly unlawful to publish or distribute.
The consultation also asks about systems for reporting problems to websites. From the responses I’ve had from members of the Janet community it seems that most websites do react quickly when told of problems (given the legal position it would be odd if they didn’t), but that it can be difficult to find where to send reports. I’ve therefore agreed with the Commission’s suggestion that reporting mechanisms should be made more obvious, but pointed out that these may need to be suitable both for a human to enter a single problem report and for an automated system to report a batch of problems, such as a range of phishing sites. The consultation suggests that sites that provide reporting interfaces should only have to respond to reports sent through them – I’ve suggested that at least a report by another channel shouldn’t trigger loss of liability protection.
I’ve made a
Janet submission
to the joint Parliamentary Committee considering the draft Communications Data Bill. It’s actually quite hard to predict what the effect of the Bill would be, as the Bill creates extremely wide powers for both the Home Secretary and Law Enforcement and the impact will depend on how those powers are used. However there does seem to the possibility of significant disruption to the operation of networks and to the current processes for obtaining communications data, as well as a couple of definitions that make the scope of the draft Bill a lot wider than the Government’s accompanying notes suggest is intended. Since this is a draft Bill I hope that those will be fixed before the actual proposal for legislation is published.
The draft Bill would allow the Home Secretary to order pretty much any action to “facilitate the availability of communications data”. From the little that has been said by the Government, the intention seems to be to use the powers to add equipment into ISPs’ networks to collect information about the use of other communications services such as webmail that aren’t covered by the current Data Retention Regulations. I’ve pointed out that networks such as Janet are designed to provide very high reliability and speed and inserting new equipment (whose reliability is unknown) or requiring changes to network designs to facilitate that could have a significant effect on that important design goal. Since the aim of the Bill is to increase the amount of communications data available for investigating crimes, it seems inevitable that it will result in larger collections of data and that those collections will themselves be targets for criminals especially if, as some of the Government’s comments in evidence to Parliament’s Joint Committee seem to imply, the systems will be storing information about traffic that would otherwise be encrypted. So network operators will not only be faced with new requirements to re-engineer their networks, they’ll also be faced with new security challenges. That seems likely to require staff effort to be diverted away from the operators’ main business.
The Bill would create a single piece of legislation covering both data retention and access by law enforcement to the retained data. At the moment those are separate (in the Data Retention (EC Directive) Regulations and the Regulation of Investigatory Powers Act respectively) which has caused problems where the two acts don’t line up. However rather than the current single process for data access under RIPA s.22, the new Bill seems to permit the creation of as many processes as senior officers can think of. That is likely to make data access slower, since it will be much harder for those receiving requests or orders to disclose information to set up standard processes to handle them. It is also likely to create more opportunities for unauthorised people to impersonate legitimate processes, as the Information Commissioner highlighted in his report “What Price Privacy Now?” a few years ago. The Home Office’s current code of practice for accessing communications data strongly discourages the use of any process other than RIPA s.22 for both these reasons.
Finally a couple of definitions have been simply copied from the existing Acts into this new one, with unfortunate effects. At the moment Data Retention only applies to public networks, and RIPA data access to all networks. The draft bill applies the RIPA definition to both retention and access, which means that it would give the Home Secretary the power to order collection of communications data from the internal networks of any company and most houses. There’s nothing in the notes on the draft Bill to suggest that that is actually what is intended! Second, and definitely not what the Government intend, is that the definition of Subscriber Data seems to have been copied from the existing Data Retention Regulations. In Regulations that only apply to Internet Access Providers it may have been acceptable to have a definition of “everything else that the organisation holds about the user”, but in a Bill that is intended to cover webmail and social network providers it clearly isn’t. Subscriber Data needs to be defined positively as something like “the identity and contact details of the subscriber”.
#104 - Ofcom report confirms risk of IP address over-blocking
Originally posted: 16 August 2012 in category
Articles
Ofcom’s 2010 report on
“Site Blocking” to reduce online copyright infringement
concluded that using IP addresses to block infringing sites “carries a significant risk of over-blocking given that it is common practice for multiple discrete sites to share a single IP address” (page 5). They have now published a report commissioned from CMSG that shows the level of IP address sharing in various top level domains and confirms that the risk of over-blocking is indeed high.
Although humans navigate the Internet using names, such as
www.example.ac.uk
, computers communicate with each other using numeric addresses, traditionally written in the form 127.0.0.1. Conversions between the two are done by a system known as the Domain Name Service (DNS). There’s no requirement in DNS that every Internet name has to have a unique numeric IP address, however the original web protocol, HTTP, did make that assumption. If multiple names translated to the same IP address, then they would all see the same web content. Around 1996 a new header was introduced that allowed many different sites (e.g. example.com, example.co.uk, example.ac.uk) to share the same IP address, but the web server program could now see which name had been used and serve different content to different names. Since IP addresses (at least the still common version 4 ones) are a relatively scarce resource this option became very popular; for companies whose business is to host thousands of websites for their customers, it is essential.
The new report confirms that for the .org, .com and, .net top-level domains – 113 million websites in total – 97% of sites now share an IP address with at least one other site (in other words only 3% of websites do not share their IP address). Excluding IP addresses that are thought to be “domain parks” holding currently unused names reduces this slightly, but the most optimistic estimate is still that 92% of websites share their address with an average of 7.5 sites per address. Comparing with a survey from 2003 shows a decrease in unshared sites from 13% to 3%. Since the number of sites has grown from 20 million to 121 million in that time, I think that means that even the number of unshared sites, not just the percentage, has fallen.
A different method was used to obtain the list of websites in the .uk domain but the percentages are very similar: 97% of .uk websites share an IP address with at least one other, discarding addresses thought to be domain parks reduces this to 94% and there is an average of 8.5 sites per address.
The survey admits that it is likely to underestimate the amount of sharing. First, only websites of the form
www.example.com
were considered so running sales.example.com on the same IP address would not count as sharing. And since only four top level domains were considered, sharing an IP address with a website in any other top level domain would also have been missed.
I don’t expect this confirmation will come as a surprise to anyone: Ofcom and judges in both
European
and
UK
courts have already been alert to the risk of over-blocking. Indeed in the UK cases where blocking orders were made there was an explicit check that the blocked addresses were only used by a single site. However it’s good to now have the figures and trend as a reminder of the problem.
Originally posted: 13 August 2012 in category
Articles
I’m pleased to report that the Internet Society has published a
discussion paper
looking at different methods being proposed around the world to respond to the use of the Internet to breach Intellectual Property Rights. For each of the approaches – graduated response and suspension of access, traffic shaping, blocking, content identification and filtering, and DNS manipulation – the paper looks at the implications for the Internet, Internet technologies, access and use.
It was interesting working with ISOC and other members of the Internet community to develop the paper – I hope it’ll be an equally interesting read.
No one else seems to have mentioned Incident Response specifically, but there was a suggestion that expanding Subject Access Requests to cover IP addresses (a consequence of the expanding definition of “personal data”) might let cyber-criminals find out when their attacks have been discovered by making SARs in respect of significant IP addresses. It’s an interesting idea – I suspect I’d be particularly keen to ask for proof of identity if I were ever to receive one of those 😉
On Internet Identifiers:
Most respondents commented on the ambiguity of the definition of personal data, when coupled with Recital 24 which states that: ‘identification numbers, location data, online identifiers or other specific factors…need not necessarily be considered as personal data in all circumstances’. Most Respondents from the legal sector have asked for clarity as Recital 24 seems to contradict Article 4 and could lead to legal uncertainty as to when and for whom information is, or is not, personal data.
On Breach Notification:
Many also expressed the view that 24 hours is an over-ambitious window for data controllers to investigate a possible data breach, which could involve data forensic officers and other third party organisations providing intelligence into the nature of the breach. These respondents felt that 24 hours is simply not enough time to determine if a data breach has occurred, and if so who was involved and the scale of the breach. Overwhelmingly, respondents have asked that the Regulation adopts the use of ‘without undue delay’ rather than ‘not later than 24 hours’ as an approach to responding to data breaches.
On Clouds:
Finally, one of the reoccurring themes in responses to the Call for Evidence has been the emergence of cloud computing and the potential threat that the proposed Regulation brings to innovation in this area of technology. Various respondents argued that, as it stands, cloud computing represents a new and economically viable way of processing data in any part of the world. This means it has become easier for countries outside the UK’s jurisdiction to process data belonging to EU citizens. Respondents have suggested that by introducing a prescriptive Regulation, the EU runs the risk of hindering a generation of technological innovators.
The majority of respondents welcomed the new derogation for transfers which are necessary for the purposes of the legitimate interests pursued by the controller or processor where the transfers are not classed as ‘frequent or massive’ (Article 44(1)(h)); however respondents asked for a clearer definition of ‘frequent or massive.’ Respondents, especially those who represented Cloud computing services, asked that the proposal take into consideration the sensitivity of the personal data being transferred, rather than purely the quantity and frequency of the transfer.
#101 - Draft Identity and Privacy Principles from Government Data Service
Originally posted: 13 August 2012 in category
Articles
The Government Data Service have published draft
identity and privacy principles for federated access management
(FAM) systems. It’s interesting to compare these with the approach that has been taken by Research and Education Federations to see whether we have identified the same issues and solutions.
The first thing that caught my eye was that the authors seem to share, even exceed, my
doubts about whether Consent is the right legal basis for on-line services
. Even when users explicitly agree: “We are
very
concerned that many Users do not know what permissions they have given nor do they read privacy policies of organisations based outside the EEA” (personally, I’d be very surprised if privacy policies inside Europe are any better read!). Since consent has to be informed and freely-given, that suggests that a lot of the “consent” that services currently rely on isn’t actually valid in law. The first principle “User Control” therefore avoids the word “consent” and says instead that users must “approve” any processing of their personal data. However the commentary confuses things by saying that this does actually mean “consent”. The legal commentary gives what I hope is actually the intention – that processing will be based
either
on consent
or
the fact that processing is necessary for the purposes of a contract with the user (for necessary processing, information still has to be available, but it’s less critical that every user reads it). Given that the Principles are written in the context of government services, I’m surprised they don’t also mention the justification (provided by both the EU
Data Protection Directive
and UK
Data Protection Act
) that processing is necessary to fulfil a legal obligation. Renewing my TV or driving licence and submitting a tax return – uses of current Government on-line identity systems – don’t feel much like contracts to me. Nor do they feel like the sort of Exceptional Circumstances covered by Principle 9 which is the only other place where justifications for processing are introduced.
The second principle, Transparency, is a clear legal requirement, but the commentary makes the good point that it is also an important factor in “engendering trust” among users of on-line systems.
The Principle of Multiplicity isn’t a legal requirement, but can be seen as another aspect of trust-building. The Principle requires that users have a free choice of Identity Provider and can choose multiple Identity Providers if they wish. Service Providers are allowed to insist that the chosen Identity Provider must offer sufficient Level of Assurance for the particular service, but cannot insist on a particular Identity Provider. This seems to be intended to protect users against inappropriate compulsion by Service or Identity Providers to disclose more information than is necessary (Principle 6 on Portability in fact prohibits anyone from compelling disclosure) and also to prevent Service or Identity Providers from collating information about an individual’s use of different services. Research and Education federations have looked at the same problems, but addressed them by assuming that the Identity Provider (typically the user’s university, college or school) is “on their side” and will use technical measures such as
unique per-service opaque identifiers
to prevent linking by Service Providers and to minimise the information disclosed. The idea of Multiplicity also seems to break down where, as is normal in Research and Education, the Identity Provider additionally provides authoritative attributes about the user: for example that they are a member of the organisation that operates the Identity Provider. For these attributes there only is a single authoritative source – only my university can assert that I am covered by its site licence for on-line content, only the Engineering Council can assert my professional status – so the Principle may need modification for them. I suspect the final clause of the Principle also says more than it intends: “A Service Provider does not know the identity of the Identity Assurance Provider used by a Service-User to verify an identity in relation to a specific service”. If this actually means what it says – that a Service Provider must not know who it is relying on for an Identity Assertion – then the required technology and legal processes are going to be very complex. I suspect the intention is actually that one Service Provider must not be able to find out which Identity Provider I used for
other
services.
Data Minimisation is another Principle derived directly from law. The rationale also contains another hint that the authors really are thinking of a distinction between processing on the grounds of necessity and processing on the grounds of consent, since it allows a user to “request [an Identity] Provider to hold information beyond the minimum necessary”: in other words to
process some information because of necessity and other information because of consent
.
Data Quality (Principle 5) looks like a reflection of the legal requirement, but the wording of the Principle seems to allow a user to do nothing and deliberately leave their information out of date. At least for those Identity Providers who are committed to providing accurate information, I would expect there to be a requirement for the Identity Provider to check accuracy periodically and to warn relying Service Providers where information may be too stale to be relied on for a particular use. Since I commit a criminal offence if I do not update my driving licence details when I move house, I would expect the DVLA at least to want reassurance that address information it received from an Identity Provider had been checked recently.
The portability part of the Access and Portability Principle (Principle 6) implements a proposal that has been suggested for Service Providers in the proposed
Data Protection Regulation
where it has been noted that it requires a new way of working, and perhaps technology changes, for them. The Principle also applies it to Identity Providers, and apparently to all information they hold, which may involve further technical, process and legal challenges. For example if I decide to transfer my identity information from one provider to another, does the second provider have to rely on the identity verification done by the first one? And if I transfer all an Identity Provider’s records of my activity (which appears to be envisaged by the commentary) then what will be the position if a recipient Identity Provider is required to present them as evidence of something that happened before the transfer? In discussion of
lifelong identifiers
, Research and Education federations have identified the point of transfer between Identity Providers as an opportunity for loss of identity or masquerading. Since we haven’t yet worked out a robust solution to this problem, it will be interesting to learn if the Government sector have.
The Governance/Certification Principle sets a high standard, that all Service and Identity Providers must be certified, including independent audits of their design and processes. While there has been some discussion of audits in Research and Education federations these have concluded that, other than for services with particularly sensitive or high-value information, the cost of external audits was not justified. Again, this may reflect the fact that our users will normally have a deeper and significantly stronger relationship with their Identity Provider. We have tended to assume that if the organisation’s systems and processes are good enough for the more intense and more sensitive information processing involved in the employee/employer or college/student relationships then they are likely to be more than sufficient for the organisation’s also acting as Identity and Attribute Provider.
The Problem Resolution Principle reflects a concern that as federated identity systems get more complex, it may be hard for the user to work out who they need to contact to resolve a problem. In the Article 29 Working Party’s
Opinion 1/2010 on the Concepts of Controller and Processor
their solution appeared to be to identify key decision making organisations and place particular responsibility on them (see, in particular, Example 15). The GDS Principles envisage an even more distributed system where there are no such key points of control/responsibility, so instead propose an Ombudsman (or Ombudsmen!) who can require participants to deal with problems. Research and Education systems tend, again, to rely on the close relationship between the user and their “home” organisation and the shared interest they are presumed to have in resolving problems.
The final Principle covers “Exceptional Circumstances”, where processing may take place that is not in accordance with the Principles. This will only be permitted if the processing is authorised by legislation (since the commentary mentions “Parliamentary Scrutiny” I’m not sure whether the intention is to limit this to
primary
legislation), is linked to one of the justifications for privacy invasion contained in Article 8(2) of the
European Convention on Human Rights
, and is subject to a Privacy Impact Assessment by all relevant Data Controllers (it’s not clear what will happen if those data controllers do not agree that the Impact is proportionate!). The authors note that law enforcement powers are likely to involve Exceptional Circumstances; another area where problems seem likely is where current powers to disclose information are created by common law, rather than legislation (e.g.
Norwich Pharmacal
and other production orders). A recent
European case
has ruled that a Directive requiring information to be kept for law enforcement purposes does not stop that information subsequently being accessed for different purposes under different laws.
Summarising, I don’t think the GDS Principles highlight any new issues that we haven’t considered in designing and linking Research and Education federations. There are some differences between their solutions and ours, but these all seem to arise from the stronger relationship between user and Identity Provider in our case, and the fact that our Identity Providers may also procure services and be authoritative sources of attributes on behalf of their users. Rather than contracts or legal duties arising directly between the user and the service provider, situations such as site licences and professional qualifications mean that service providers often have stronger relationships with the organisation than the individual. In turn, our users have a stronger relationship, and more common interest, with their Identity Providers than the GDS can assume. That gives us alternative ways to protect users’ privacy (one of the main benefits of Federated Access Management is that service providers no longer need to manage accounts and personal details for individual users). However because there may well be no direct contract or legal obligation between the user and service, we have to use a different legal provision (
“necessary for the legitimate interests” of the IdP and SP
) – which itself contains additional protection of the user’s rights – to justify the personal information that we do process and disclose. Interestingly the new draft Regulation contains a hint of a
“contract for the benefit of the individual”
(Art 44(1)(c)) which might one day provide a common framework for both types of federated access management system.
Originally posted: 10 August 2012 in category
Articles
As the BBC are pointing out, there has been a
lot to celebrate
on Twitter recently. However there have also been quite a few instances of tweeters (the French refer to us/them as “twittos”) getting it badly wrong. We should all know that “email is like a postcard”, but sometimes it seems that “Twitter is like a megaphone” might be as useful a reminder.
Pinsent-Masons have come up with a handy list of
ten things not to do on Twitter
(or any other form of publication) if you want to stay out of legal trouble. It’s perhaps not quite concise enough for a post-it stuck to your keyboard, but before you hit “send” it’s definitely worth thinking:
Member States shall not impose a general obligation on providers … to monitor the information which they transmit or store, nor a general obligation actively to seek facts or circumstances indicating illegal activity.
However recital 47 says that
“this does not concern monitoring obligations in a specific case”
Clearly the dividing line between “general obligation” and “specific case” is significant. The European Court of Justice has previously ruled that an order to monitor for and prevent copyright breaches was a “general obligation” and therefore prohibited. A French court has now
extended that prohibition
to cover a requirement to monitor for re-posting of specific material that had previously been removed for copyright breach; the fact that this would involve monitoring all users seems to have made it qualify as a “general obligation”. However a German court had previously ruled that the same host could be ordered a host to monitor for previously notified material and pro-actively notify the rightsholder.
It is not clear whether a future European court hearing will be able to find a difference between the cases and thereby mark a clear line between general and specific duties, or whether the decisions will be found to be incompatible. Alternatively the situation may turn out to be more complicated and involve a balance of the rights of the claimant, the host and the privacy rights of users whose activities would be monitored. This would make it harder to predict the outcome if the UK Parliament decides to take up the recent recommendation of the
Joint Committee on Privacy and Injunctions
that search engines be ordered not to index copies of material they have previously been told infringed privacy and were subject to a court injunction. If the law does turn out to require a balance, rather than a simple dividing line, it seems possible that a privacy injunction might carry more weight than a notification of copyright breach.
Originally posted: 25 July 2012 in category
Articles
A couple of developments in network neutrality.
The Broadband Stakeholders Group have announced an update to its
Open Internet Code of Practice
, which has already been signed by a number of UK ISPs. The previous version of this voluntary code concentrated on transparency, by requiring those who signed up to document their traffic management practices. The new code requires additional commitments that those who sign will only describe products as offering “Internet access” if that access is subject to no more than a specified level of traffic management, and that such products will form the majority of their portfolio.
The latest meeting of the
UN Human Rights Council
has also confirmed its support for network neutrality by adopting a
declaration
that recognises “the global and open nature of the Internet as a driving force in accelerating progress towards development in its various forms” and calls for human rights, in particular free speech, to be respected on line as they are off line. Declaring something to be a Human Right doesn’t mean it must be provided, but does mean that there are only certain reasons for which it can be restricted or withdrawn.
Originally posted: 23 July 2012 in category
Closed
I’ve just sent off a
Janet response
to Ofcom’s consultation on the latest draft Initial Obligations Code under the
Digital Economy Act 2010
.
On the wording of the Code itself there are just a couple of minor observations. There seems to be a drafting hiccup that means any ISP that becomes Qualifying in the second or subsequent years (but not in the first) won’t get the additional grace period that everyone seems to agree will be needed in order to set up systems to receive and process Copyright Infringement Reports for the first time. And I’ve repeated the observation that merely telling a reporter “I couldn’t identify a subscriber from that information” doesn’t help them to improve reports in future. The
UCISA standard response templates
include different responses to tell the reporter, for example, that they need to provide more information or fix a bug with their reporting system. To save wasting everyone’s time sending and receiving unusable reports it would be better if recipients that have that sort of information could feed it back rather than waiting for Ofcom’s next annual check of the reporting system.
And on the wider supporting paper I’ve welcomed the
explanation
of how the Act applies to universities, colleges, schools and other “public intermediaries”. These seem to make clear that, even if Janet were one day to be classed as a Qualifying ISP under the Act, we would be able to treat our customer organisations as either ISPs or Communcations Providers, not as Subscribers, and continue to expect them to receive and
deal effectively
with reports of copyright infringement under the
Janet AUP
. Public intermediaries that get connectivity from current Qualifying ISPs may find that those ISPs assume that all their customers are Subscribers, but Ofcom also make clear how to explain to such an ISP that this status isn’t appropriate; ultimately, knowingly mis-classifying a customer may even breach the Act.
#96 - Pseudonymous Identifiers and the DP Regulation
Originally posted: 18 July 2012 in category
Articles
Statewatch have published what appears to be a
document
from the Council of (European) Ministers containing comments on the proposed Data Protection Regulation. It’s interesting to see that there seems at last to be a recognition that the current legal treatment of indirectly linked identifiers is unsatisfactory. At the moment European law has been interpreted as saying that identifiers such as IP addresses are either personal data or not, and once their status is set it can never changed no matter who holds them. A comment attributed to the President of the Council highlights why this isn’t right:
To the original data controller, identification will most likely never be disproportionate, but this may be the case for third parties that e.g. only see an id number or some other “abstract identifier”, which they cannot use to identify the data subject
In other words it may well be reasonable to impose all the duties of data protection law on parties (such as the ISP that assigns the IP address to a user) that know the link between the identifier and individual, but not on other parties who have only the identifier and no way to make the link. There are even promising suggestions that such identifiers should be distinguished by having a different name – “pseudonymous identifiers”. This would both create an incentive to use these privacy protecting identifiers, and make systems that use them (for example federated access management) a lot easier to use.
However there doesn’t seem to be any agreement on the right way to treat pseudonymous identifiers. The original draft Regulation says (without giving any clue why or when) that “identification numbers, location data, online identifiers or other specific factors as such need not necessarily be considered as personal data in all circumstances”. The Council’s views seem to diverge widely, with some proposing to revert to the current position and others suggesting tests involving how much effort would be involved in making the link or whether the link is actually made (current UK law considers the likelihood of linking). My own preference, which would depend on the risk of harm (i.e. how likely is it that the link will be made and how much would that damage privacy) doesn’t seem to have been suggested. But at least the problem seems to have been recognised and discussion of solutions started.
Originally posted: 16 July 2012 in category
Articles
Ofcom’s
draft Digital Economy Act Code
recognises that the real Internet is more complex than the Act’s model, and that there may be a variety of “communications providers”, “Qualifying ISPs” and “non-Qualifying ISPs” involved in getting packets (and possibly Copyright Infringement Notices) delivered to “subscribers”. This post describes some of the combinations likely to be experienced by Janet-connected organisations.
University/college/library/etc. providing its members with connectivity via Janet
. According to Annex 5 of the Code (para A5.40), such organisations will normally have an agreement with their users, which means that the organisation is the “ISP” and the user is the “subscriber”. Since Janet only provides connectivity to such organisations, it isn’t an ISP (it has no Subscribers). The right place for rightsholders to send Copyright Infringement Reports (CIRs) to is therefore the organisation but, since no Janet-connected organisation is on the initial list of Qualifying ISPs, you aren’t bound by the Code when responding (it may be worth pointing this out to the reporter, as in
UCISA’s template responses
). You are bound by the
Janet Acceptable Use Policy
, however, so are expected to respond in accordance with our recommendations on
responding to copyright complaints
.
University/college/library/etc. providing its members with connectivity via a Qualifying ISP
. Provided the organisation has an agreement with its users, as above, it will still be an ISP. Para A5.46 of Ofcom’s Code is clear that “the Qualifying ISP is not required to process a CIR” if it receives a report that relates to another connected ISP, and that it should respond to the person reporting by pointing out that they should contact that other ISP (under section 18(d) of the Code). Since, as above, the organisation is unlikely to be a Qualifying ISP, it will not be bound by the Code if it subsequently receives a CIR. Ofcom also recognise in para A5.56 that the Qualifying ISP may not always spot when this situation arises; in this case the Qualifying ISP may incorrectly send an infringement notice to the ISP; the ISP should remind the Qualifying ISP of its status and that the CIR is invalid as a result. Ofcom also invite discussion (in para A5.57) if there are any difficulties in resolving these situations.
University/college/library/etc. providing visitors with a service from a commercial hotspot provider
. This is a relatively common situation, where a university shares its wireless infrastructure with a commercial hotspot provider. Here the hotspot provider has the agreement with the end-user so the end-user is the Subscriber, the provider the ISP, and the organisation does not need to be involved in any of the actions required by the Code. However Ofcom have stated that wireless internet providers will not be included in the initial list of Qualifying ISPs, so this arrangement is unlikely to be covered by the Act at least until the list of Qualifying ISPs is revised.
University/college/library/etc. providing open-access wifi
(note that offering open access using a Janet connection is prohibited under the
Eligibility Policy
). Here there is unlikely to be any agreement with users; without an agreement the organisation will not be acting as an ISP. Depending on the agreement the organisation has with the ISP from which it gets its connectivity it may be classed either as a Communications Provider or as a Subscriber to that ISP. In the latter case, if the ISP is a Qualifying ISP then the organisation will effectively be in the same position as a domestic broadband subscriber: the Qualifying ISP will be required to send infringement notices to the organisation, and to add it to the serious infringers list (which may be disclosed to rightsholders) if multiple CIRs are received over a number of months.
#94 - Hacking the law for Federated Access Management
Originally posted: 10 July 2012 in category
Articles
One definition of a “hacker”,
according to Wikipedia
, is someone “who makes innovative customizations or combinations of retail electronic and computer equipment”. I was recently asked by TERENA to have a think about the legal issues around using federated access management to control access to resources in eResearch. This has quickly come to feel like hacking (in that sense) the law: making it do something it didn’t know it was capable of…
Data Protection law generally looks at bilateral relationships between an individual and an organisation that processes their personal data. If any other organisations get involved, it tends to be as a sub-contractor to the primary data controller and the legal duties stay with that data controller. That far the law is reasonably well known and understood. However federated access management tends to involve three or more parties, and in a variety of different relationships.
In the UK, at least, the most common application for federated access management has been to give students and staff access to on-line resources licensed by the organisation of which they are a member. This involves relationships between three parties – the publisher (acting as service provider), the organisation (acting as identity provider) and the individual. However these relations are already a bit different from those envisaged by activities such as the UK Government’s
Identity and Privacy Principles
, where the individual has (as a key principle) the ability and right to choose which identity provider they use and then directs that identity provider to release information to a particular service provider. In that model the relationship between the IdP and SP is therefore mediated by the user. In education, by contrast, the IdP and SP are likely to have an existing direct relationship, which may well be contained in a commercial contract, and the user may have no relationship with the SP other than being required as part of their study to access a particular SP under a particular IdP’s licence. This relationship is better characterised as organisation-mediated. Since law is all about relationships, this already suggests that different legal arrangements may be needed.
In eResearch, it is common for a fourth party to be involved, since access to research resources (equipment, experiments, high-performance computing, datasets, etc.) may well be granted to a project, rather than to an individual. The project (sometimes referred to as a Virtual Organisation) then decides how to allocate those resources between its members, but still using their home organisations as identity providers to provide and check individuals’ login credentials. This seems to imply that there will be strong relationships between the organisation and the user, the user and the project, and the project and the service provider, with weaker or no relationships between other pairs of parties. The project/VO therefore seems likely to mediate the relationship between the user and the service, but (unlike services procured by the organisation) the user may well mediate the relationship between the organisation and the project/VO.
It seems clear that the number and complexity of relationships involved in this eResearch model will require that any legal framework be, as far as possible, based on these existing relationships rather than imposing new ones purely to satisfy the law. So we’re a long way from the simple bilateral model of data protection law. However my impression is that, with sympathetic interpretation, EU law does provide the components that could be “hacked” into a suitable framework. As with all the best hacking projects there are sure to be some hiccups to overcome, notably that different European countries may have implemented the necessary parts of EU law differently. The
full TERENA paper
has been published as part of a wider study of AAA platforms, and I’ll be presenting some of these ideas at a
workshop
in September to get some feedback and see how the ideas might develop.
Originally posted: 6 July 2012 in category
Articles
A new
Opinion on Cloud Computing
from the Article 29 Working Party highlights a number of difficulties in applying current data protection law to the cloud computing model and suggests that changes are needed both to cloud contracts and to European law. The main concerns are over lack of control by the client using the service and lack of information about what the service will involve. Interestingly, these concerns apply whether or not the cloud provider is established in the European Economic Area. Indeed the working party note that one possible solution, the use of standard contract clauses, currently works better for providers who are not in the EEA as that is the application for which the current model clauses were developed.
The Opinion sets out a detailed list of provisions that ought to be in cloud contracts and encourages all cloud providers to work towards these. The Opinion also calls for changes in the law, not all of which are in the
proposed Data Protection Regulation
, and for the consideration of a pan-EU Government cloud to ensure that sensitive information about EU citizens does not need to be exported from the continent.
The European Commission have opened a
consultation on “notice and action” procedures
(in the UK we tend to refer to them as notice and takedown) by those who host content on the Internet. Since Janet customers may see a different side of the issue from us as operators of the network, it would be helpful to get your comments to inform our response.
First there are some specific questions from the consultation:
What sort of material do you complain about to others (copyright, phishing, etc (Q5 has a full list))?
Can you find how to complain?
Does it get taken down quickly?
What sort of material do others complain about to you?
Do you get complaints apparently intended to remove legal material?
On more general points my inclination at the moment is to suggest a couple of changes to current law: first that some better way should be found to protect sites that want to moderate or check what appears on their sites (at the moment, doing so carries some legal risk that you may be liable for anything you miss); and second that where it’s not obvious whether content is illegal because it depends on external factors – defamation, copyright, etc., as opposed to malware or indecent images of children – it should be possible for the content provider to ask the host to put it back without the host becoming liable. This is currently done for copyright material in the US and was suggested for defamation in the UK.
Answers to the specific questions and discussion of the general approach would be very welcome, either in comments to this post or you can e-mail me if you don’t want your answers to be public. Comments received by August 17th will be taken into account in our response, thereafter it’ll depend on how much time I have. I look forward to hearing from you, thanks
A pseudonym is an identifier (often randomly generated) whose value is unique to me, but which isn’t any of the identifiers (name, address, etc.) that I use in the real world. Membership numbers are an example of a pseudonym that we frequently encounter: the organisation that issued it knows that member 002684 is me, but no one else can make either the link between that number and me, or between it and my membership numbers of other organisations.
EU law
says that anything attached to the membership number is always personal data, because there is someone on the planet who can link it to me. The Article 29 Working Party even
seem to suggest
that it would be personal data without the link, because the membership number distinguishes me from all other people. UK law agrees that it’s personal data in the hands of anyone who can make the link (me, the organisation and – if I told you which organisation it was – any reader of this article). But if you don’t have, and aren’t likely to obtain, the linking information then the membership number isn’t regarded by the
Data Protection Act 1998
(DPA) as personal data in your hands.
Indeed the Consultation document is explicit that “There is clear legal authority for the view that, where a data controller converts personal data into an anonymised form and publishes it, this will not amount to a disclosure of personal data – even though the disclosing organisation still holds the ‘key’ that would allow re-identification to take place. This means that the DPA no longer applies to the disclosed information”. Where the information might cause harm if a recipient were somehow able to perform re-identification without the key (for example by spotting unique patterns in the anonymised information) or by obtaining the key from somewhere else, the Code suggests “only disclos[ing] within a properly constituted closed community and with specific safeguards in place” but still allows the disclosure to take place outside the scope of the DPA. Several examples in the Code demonstrate how this could work.
Computer systems don’t care what identifier is used – they are all just sequences of bytes. Lighter regulation of pseudonyms could provide a strong encouragement to use those in place of direct identifiers, with immediate improvements for privacy. Unfortunately so long as there is a difference in interpretation across Europe this is unlikely to be achieved.
Originally posted: 26 June 2012 in category
Articles
Ofcom have at last published the
Initial Obligations Code
on how ISPs must deal with copyright infringement reports under the Digital Economy Act 2010. The accompanying notes, and in particular Annex 5, provide welcome recognition of the work that is already done by universities and colleges to reduce infringement on the Janet network, as well as clarifying how the
Act’s definitions
apply to the network and its customers.
Paragraph A5.40 confirms that an internet access provider will be classed as an ISP under the Act where the service is provided by means of an agreement with the subscriber, even if that agreement is oral or implicit. Thus “public bodies like libraries or universities are likely to be ISPs, providing internet access under an agreement with their readers or students respectively”. Paragraph A5.2 notes that such public intermediaries will not meet the initial qualification threshold (400000 broadband lines), so will not be required to comply with the initial Code. A5.48 says that when the Code is revised, the new qualification threshold is likely to relate to numbers of infringement reports received, so provided public intermediaries continue to act effectively against such infringements as are reported (as they are
required to by the Janet AUP
) they are likely to continue to fall below that qualification threshold. This interpretation therefore encourages us to continue and improve our existing measures to deal with copyright infringement, rather than forcing us to adopt a completely new approach.
More generally, the Code has improved some features from the 2010 draft, as we suggested in our
response to that consultation
. In particular it will now be possible for an ISP to be rewarded for reducing the rate of infringement by its users by dropping below the qualifying threshold and outside the scope of the Code. The procedures rightsholders use to detect infringements will now need to be checked and approved by Ofcom and standards for the systems to be used by both rightsholders and ISPs may be produced. The new Code also confirms that the Act does not require ISPs who do not currently collect personal details from their users (for example wifi scratchcards and pay-as-you-go mobile phones) to start doing so.
Finally the requirements for the content of an Copyright Infringement Report (para 16 of the draft Code) have been strengthened, in particular by the requirements to include the start and end times when the alleged infringement took place and that all timestamps must be given in UTC to avoid problems of synchronisation or timezone differences. However the reasons for rejecting a CIR as invalid don’t seem sufficient to let the reporter know what the problem was. A single response that “the ISP has not been able to identify the subscriber” (Para 18(d) of the Code) seems to have to cover the different situations where the ISP doesn’t have the necessary logs, or the CIR information could refer to two or more subscribers (for example if NAT/PAT devices or proxies are used), or the CIR information did not match the ISP’s own flow data (suggesting that there may be a problem with the reporting system, such as a faulty clock). To improve the number of reports that can be actioned, it would be helpful to be able to feed that information back to the reporter.
In a related development, the Department for Culture, Media and Sport have announced that they plan to
repeal sections 17 and 18 of the Act
. These created a power to order the blocking of internet locations, but have never been turned on. Since it is now
clear
that that power already existed under section 97A of the Copyright, Designs and Patents Act it seems to have been decided that they are redundant.
Originally posted: 22 June 2012 in category
Articles
A number of talks at the
FIRST conference
this week have mentioned the value of Domain Name Service (DNS) logs for both detecting and investigating various types of computer misuse: from users accessing unauthorised websites to PCs infected with botnets to targeted theft of information (see, for example,
Google’s talk
).
DNS is sometimes described as the distributed phone book of the Internet – it’s how computers convert use-friendly names like
www.ja.net
into the numeric IP addresses that are actually used to move packets around the network. Every time a user or program converts from an Internet name to an IP address their computer has to make a request to the DNS, and that request can be logged. So how much of a privacy issue is this?
There are actually two types of DNS logs – logs of requests (which computer requested translation of which name) and logs of responses (what numeric address the name translated to at a particular time). Request logging clearly can have an impact on privacy: if you can link the IP address of the requesting computer to the person who was logged on then you can see what websites and other Internet hosts they were accessing. However the DNS request log can’t tell you which pages, or even how many pages, the user accessed. So it seems like less of a privacy invasion than collecting web proxy or e-mail logs, which many organisations and ISPs already do. Request logs are actually more like logs of traffic flows, which also show which machines communicated with which other machines (indeed a flow will normally be logged very soon after a DNS request!). There are a couple of differences: traffic flows (unlike request logs) say how much information was exchanged, while for hosts that contain a number of different websites the DNS query log, unlike the flow log, will reveal which of those sites was requested.
DNS response logs can be much less of a privacy issue, because they can be collected in a way that reveals only what translation request was made and not who made it. Such a log can’t be used to find problem users or local machines, but can be used (see, for example
Florian Weimer’s original paper
) to detect external threats such as rapidly moving phishing sites.
So it seems that logs of DNS requests, at least, should be considered as raising some privacy issues: organisations and incident response teams should only collect and use them if they have
a clear need and proportionate processes
for this. However in many cases that need and processes will already have been established for the collection and use of proxy or flow logs. DNS logs therefore seem to offer a significant help to security and incident response teams without creating a significantly greater privacy threat for internet users.
#88 - Defamation Bill – Committee Discusses Moderation
Originally posted: 22 June 2012 in category
Articles
One of the perverse effects of the current law on liability of website operators is that it discourages sites from checking comments and posts provided by others. Instead the law encourages the operator to do nothing until they receive a complaint. Earlier this week the
House of Commons Select Committee
considered whether an amendment was needed to the new
Defamation Bill
to address this problem.
The Opposition noted that “Post moderation is something that should be encouraged. Many consider it best practice and so it would be a great shame if this Bill ended up creating a chilling effect of its own while failing to protect those who moderate posts” and proposed that the law should explicitly protect moderation:
(2A) The defence provided in this section is not affected by the operator having a policy of amending content (“moderation”) after it has been published provided that any changes made as a result of the actions of the moderator—
(a) do not significantly increase the defamatory nature of the words complained of;
(b) do not remove a relevant defence to an action for defamation in relation to the words complained of; and
(c) do not significantly increase the extent of the publication of the words complained of.
The Minister agreed “that responsible moderation of content should be encouraged” but argued that the Bill already provided the necessary protection. However this only applies if the website operator follows a set procedure which has not yet been published (or, it seems, provided to the Committee), so it’s not yet clear whether it will be sufficient to encourage moderation or whether operators will continue to rely on the existing un-moderated approach.
#87 - Defamation Bill – Hints at Definitions and Processes
Originally posted: 22 June 2012 in category
Articles
The
21st June sitting
of the Commons Defamation Bill Committee provided some hints at answers to my
questions
about the Bill’s definitions and process.
On the question of who will be a “website operator”, able to benefit from the new defences, the Minister suggested this should be left to the courts, who can adapt to changing technology, rather than writing current definitions into the Act. However he did indicate that at present
Those would include website operators such as Facebook or Mumsnet, and online newspapers and bulletin boards that enable users to post and read messages
On the meaning of when a poster is “identifiable” and a claimant will be expected to deal directly with them rather than involving the website:
I want to make it clear that the word “identify” in subsection (3)(a) is intended to mean that the claimant has sufficient information to make contact directly with the individual who posted the material. What constitutes “sufficient” will obviously depend on the facts of the particular case. On a local discussion forum, where all users are known to one another, a name might in some cases be sufficient form of identification, but on a much larger forum, it is likely that some additional information, such as an e-mail address, might be required.
And although the process that website operators will be required to follow when they receive a complaint about a post whose author cannot be identified is still not available, the Minister indicated that this will not simply involve the site operator releasing contact details whenever a complaint is received. Instead it seems that the operator will be required to ask the author whether they are willing for their contact details to be released to the complainant. If they are not the complainant will be expected to ask a court to order disclosure of the information using the existing Norwich Pharmacal process, thus ensuring that the competing rights of protection of reputation and privacy are assessed by a judicial authority. Members of the Committee pointed out a number of problems with this – including the cost of a Norwich Pharmacal hearing and the fact that that poster may turn out to be in another country where a defamation case cannot be brought. It seems to me that there could also be problems if the process assumes that the website operator knows who the author is, though some members of the committee suggested resolving this by compelling (somehow) every poster to provide their real identity to the website. It seems the actual process is not yet settled and the Minister repeated his undertaking to
seek, in due course, the views of stakeholders—internet organisations, claimant lawyers and the libel reform campaigners—on the terms of draft regulations
Originally posted: 14 June 2012 in category
Articles
The
Defamation Bill
had its
second reading in the House of Commons
on Tuesday. Most of the MPs who talked about the new defences for website operators (clause 5 of the Bill) seemed to appreciate the complex balance between protecting reputation and protecting free speech, and agreed with the Justice Secretary:
our current libel regime is not well suited to dealing with the internet and modern technology. Legitimate criticism sometimes goes unheard because the liability of website operators, as providers of the platform on which vast amounts of information is published by users, puts them in the impossible position of having to decide when to defend or censor information. Meanwhile, individuals can be the subject of scurrilous rumour and allegation on the web with little meaningful remedy against the person responsible.
There were also a number of helpful comments that any duties on website hosts must be proportionate, but it’s clear that there are still some MPs who think that websites should be subject to the same liability regime as newspapers. Some of these mentioned horrific cases where criminal bullying and harassment had been committed through on-line services; both the Minister and his shadow stressed that the current Bill only deals with defamation, which is not a criminal offence, and that if there are gaps in the criminal law or its enforcement then these need to be addressed separately.
The Bill will create a new process that website hosts can follow when they receive a complaint; Julian Huppert MP stressed that this must not replace the existing options (either immediately removing material that is clearly illegal or alternatively leaving up material where a complaint seems to have no merit). The Regulations setting out this process haven’t been published so there was some confusion over what they will involve. The Justice Secretary said it would be “a procedure to put complainants in touch with the author of allegedly defamatory material”, whereas his shadow suggested that “[the author’s] details will be passed on to a potential claimant bringing an action”: very different! Both recognised that the process must protect “genuine whistleblowers”, but no one mentioned the need to protect the privacy of
all
web authors against those who will try to misuse the process to discover their identity. At the moment the identity of the author of a web page is protected by the
Data Protection Act
, and is only disclosed for alleged civil wrongs once the severity of the wrong and of the privacy breach have been balanced by a court applying the
Norwich Pharmacal
process. It’s particularly important that the Bill doesn’t pass that responsibility to the website host who has no access to the relevant facts or law and could inadvertently create a breach of the privacy or even (as some MPs noted, online disputes can escalate into real physical threats) the safety of their authors.
The Bill will be considered by a Committee of the House of Commons next week. The Government undertook to provide that Committee with “a note on the new process”, and that “draft regulations [implementing the process] will be published for consideration by stakeholders in due course”.
Originally posted: 13 June 2012 in category
Articles
Under current defamation law, if a website wants to avoid all risk of liability for material posted by third parties then its best approach is to not moderate postings when they are made, and remove them promptly when any complaint is made. As I’ve pointed out in various responses to consultations (and as now seems to be
recognised by law-makers
both in Westminster and Brussels) that’s not ideal either for removing obviously harmful material, or for protecting contentious but lawful comment.
The
Defamation Bill
that is currently being debated in Parliament seems to offer a number of new approaches that a website could adopt, while still being protected from liability. Note that the Bill isn’t yet law, may change before it is, and will only apply to defamatory statements, so don’t rely on these just yet!
Only accept posts from “individuals who can be identified” (the Government has been asked for more clarity on what this means). Clauses 5(2) and 5(3)(a) of the Bill then mean you are protected from liability even if you do moderate postings;
Allow anonymous posts and moderate them, but follow a process that will be specified in legislation (unfortunately for debate, no draft has yet been published) when you receive a complaint. Clauses 5(2) and 5(3)(c) then protect you from liability;
Allow anonymous posts, don’t moderate, and follow the prescribed procedure in response to complaints;
Use some other mechanism to ensure that it’s “reasonably practical” for the complainant to take legal action against the author of the posting, while ensuring that you don’t qualify as either editor or publisher. Clause 10 only permits suing someone who *isn’t* the author, editor or publisher if it’s not reasonably practical to sue one or more of those;
Allow anonymous posts, don’t moderate, and remove promptly when a complaint is received (the existing process under the Defamation Act 1996 and e-Commerce Directive).
As far as I can see, you need to choose one of these approaches and stick to it: you can’t, for example, accept anonymous posts, moderate them, and then remove in response to complaint (switching from (2) to (5) when you receive a complaint).
Other behaviours will, of course, remain possible; for example moderating material and only publishing posts that you believe are lawful, or deciding that material that’s the subject of a complaint is actually lawful. However in those cases you’re relying on your interpretation of the law matching that of the judge should the case ever come to trial.
Originally posted: 12 June 2012 in category
Articles
The European Commission have proposed a
draft eIdentity Regulation
, to replace the current
eSignatures Directive
(99/93/EC). While the proposal is mostly concerned with inter-operability of national electronic IDs and improving the legal significance of digital signatures, timestamps, documents, etc. there are also some new requirements on “trust service providers”.
According to Article 3(12), Trust Services comprise “any electronic service consisting in the creation, verification, validation, handling and preservation of electronic signatures, electronic seals, electronic time stamps, electronic documents, electronic delivery services, website authentication, and electronic certificates, including certificates for electronic signature and for electronic seals” and according to Art 3(14) a Trust Service Provider is “a natural or a legal person who provides one or more trust services”.
Art 15 requires all Trust Service Providers to “take appropriate technical and organisational measures to manage the risks posed to the security of the trust services they provide”, which looks similar to the requirement of the current
Data Protection Directive
on anyone processing personal data. For those who fail to implement such measures, Art 9 makes them liable for “any direct damage caused to any natural or legal person” resulting from the failure, unless they can demonstrate that they did not act negligently. Art 15(2) also requires security breaches with a significant impact to be reported to the supervisory authority for trust services, the national body for information security, and the data protection authorities, on the same tight timescale as proposed in the new
Data Protection Regulation
, but to additional regulators.
What puzzles me about this is that, unless there’s some hidden meaning in the word “service” (for example that it must be commercial, or must be provided to a separate third party), the definition of a trust service provider seems to cover anyone who issues a digital certificate, even if it’s only to members of the organisation to access services provided by the issuing organisation (for example I have a certificate issued by my employer to ensure that I only enter username and password when connected to genuine
eduroam
services). In most of the circumstances I can think of, a security breach of those certificates would only affect the organisation that issued them (so it would be unlikely to sue itself) and the breach would be unlikely to have a “significant impact”. But it seems to me there could still be some unexpected consequences (for the Commission, regulators and people who didn’t previously realise they were trust service providers) of legislating so widely. Unless someone can point out the limitation on scope that I’ve missed?
[UPDATE]
I’ve now spotted Article 2(2), which may provide the limitation I was looking for:
2. This Regulation does not apply to the provision of electronic trust services based on voluntary agreements under private law.
I think that means that the examples I was thinking of would be outside the breach requirement and liability requirements.
Originally posted: 11 June 2012 in category
Closed
Two consultations have come along at once – one from Westminster and one from Brussels – that both seem to recognise the problems with incentives that current liability rules create for sites that host third party content. Under both the UK
Defamation Act 1996
and the European
eCommerce Directive
(2000/31/EC) hosts are discouraged from themselves checking what others put on their site until they receive a complaint, and then encouraged to remove whatever is complained of without considering whether the complaint is justified. The title of the Commission’s consultation, “A clean and open Internet”, neatly summarises what current incentives fail to promote!
The first consultation is by Parliament’s
Joint Committee on Human Rights
, which has chosen to look at the human rights issues of the
Defamation Bill
published by the Government following the Queen’s Speech. That Bill does seem to offer better protection for authors whose statements are the subject of unjustified complaints, but hosts will need to be sure that all the required conditions are met before they rely on it. Since this clearly relates to the human right of free speech, I’m planning to send a Janet response recommending greater clarity on this point.
The
consultation by the European Commission
expresses concern about unwarranted removal of material, and also asks about the problem of self-checking before a complaint is received. It’s likely to be some time before we see draft European legislation resulting from this, but a change to European law could cover all types of complaint, not just defamation.
Originally posted: 6 June 2012 in category
Articles
In discussing a
legal framework for federated access management
we’ve concluded that the right approach to use as a basis for exchanging attributes is that a particular attribute is “necessary” to provide a service. That implies both that service providers shouldn’t ask for attributes they don’t need, and also that where there is a choice of attributes that could be used they should choose the one that includes the smallest amount of unnecessary information.
Identifiers are one area where this choice may well arise, since the
eduPerson standard
contains a range of different identifiers that can all be used to distinguish one user from another. Since the purpose of an identifier is to link together a series of actions by the same individual, it seems to be the range across which those links need to be made that should guide the choice of identifier.
If the requirement is only to link different visits to the same service by the same individual (for example to remember the choices or searches I made on my previous visit) then what’s needed is a label, unique to me, that will always be provided when I use that service. However the same label doesn’t need to be provided to any other service and I don’t need to know what the value of the label is. eduPerson provides a unique, opaque, per-service label,
eduPersonTargetedID
.
If the requirement is to link together my activities on different services then the per-service uniqueness is not wanted but all the other characteristics are. In particular I still don’t need to know the value of the label. As far as I know, eduPerson doesn’t contain this type of identifier (from some identity providers
eduPersonTargetedID
may have these characteristics but that can’t be relied upon), so services with this requirement tend to use the next one…
Next is an identifier that can be used to link services and which I know myself. In other words it’s still unique, but it’s not opaque. This type of identifier is most useful for solving the “invitation problem”, where the operator of an on-line service wants to grant access to me, as a real-world individual. One solution is for me to tell the operator a unique identifier which will then be shared between our two computers. To make them memorable, such identifiers are often constructed in the same way as an e-mail address, with a unique local name an @ character and the domain used by my identity provider. However it’s important to remember that they aren’t e-mail addresses: sending e-mail to them may well not work. eduPerson’s human-friendly unique identifier is
eduPersonPrincipalName
.
Finally there’s the identifier that can be used if I want to link my real world relationships and reputation into the on-line world, for example if I want to continue an off-line discussion in an on-line collaboration tool. In the real world we use personal names for that, so this is one of the few kinds of service where knowing my personal name really is necessary, rather than a just an optional personalisation. Unlike the identifiers above, though, personal names aren’t unique so it’s important for the computer also to have one of those identifiers as well, which is unique, to ensure that my stuff isn’t mixed up with someone else who happens to have the same name. In fact name isn’t really a good thing for a computer to try to process at all, because I may well give different versions, using full names or initials and perhaps even different orders, at different times and in different places. Humans can (usually) recognise that they all refer to the same person, but that’s really hard for a computer to do.
These different characteristics and purposes can be summarised as follows:
Originally posted: 6 June 2012 in category
Articles
The European Commission seems to be revisiting ground covered by the UK’s 2006
amendment to the Computer Misuse Act
, attempting to criminalise certain acts relating to devices/tools used for committing offences against information systems. The problem is that many computer programs – for example for identifying vulnerable computers, monitoring wireless networks or testing password strength – can be at least as valuable to those trying to secure networks and computers as to those trying to compromise them. The only difference between legitimate and not is in the intention and authorisation of the person using the tool. The UK law recognised intent as a key factor in whether those making (s.3A(1)) or obtaining (s.3A(3)) tools were committing a crime, but not for those supplying tools to others (s.3A(2)). This resulted in the removal from the UK of at least one website listing tools and techniques for incident response teams.
First impressions of the
Commission’s proposal
aren’t very encouraging. In Article 7a the Commission seek to regulate items “designed or adapted primarily for the purpose” of committing offences. That formulation (which was discussed and rejected in the UK) assumes that the intent of the original designers or adapters (supposing that can even be determined) is what matters, not the intent of the person who supplies or uses the tool. Indeed it could even protect those who carry out attacks using tools designed for legitimate purposes – for example both ping and DNS have been used for highly successful denial of service attacks. This flawed wording of the Article is particularly odd, as Recital 9 has the better formulation of “’tools’ that can be used [my emphasis] in order to commit the crimes listed in this Directive”, recognising that tools themselves can have both good and bad uses.
More positively, Article 7 does specify that, in order to be a crime, the “production, sale, procurement for use, import, possession, distribution or otherwise making available” of such tools has to be done “intentionally and without right, for the purpose of committing” one of the offences defined in the previous articles. That does seem to limit criminality to those who intend to commit crimes – indeed Recital 10 (and in European law recitals are as much part of the law as Articles) is explicit that “this Directive does not intend to impose criminal liability where the offences are committed without criminal intent”.
In Recital 10 the Commission also gives helpful examples of non-criminal use of tools relating to “authorised testing” or “protection of information systems”; the
draft report of the European Parliament’s Committee on Civil Liberties, Justice and Home Affairs
proposes to further clarify the former to “testing in accordance with law” in order not to “undermine the effectiveness and practicality of selftests without criminal intent”. The Committee also proposes to amend Article 7 to so that mere possession is not an offence – “given the possibility to use programmes in dual forms, i.e. for legal as well as criminal purposes, the possession of a tool should as such not be punishable” – and “the purpose of the actions described in this article should only be punishable when it is clearly aimed at committing an offence”.
Both the Commission and the Committee therefore seem to have understood the issue of dual-use tools and be aiming for something much better defined than the UK’s crime of “suppl[ying] … any article believing that it is likely to be used to commit, or to assist the commission of, an offence under section 1 or 3” (
CMA s.3A(2)
). As I pointed out at the time that could both criminalise Microsoft’s issuing of patches (since it is well-known that those are immediately reverse engineered to facilitate attacks) and give authors the possibility of denying that they had any idea their products might be misused!
There is still debate and possible revisions to take place before this becomes European Law, so the important safeguards that are in the current text could still be lost, either in that process or in the transposition to national law. In the UK we should definitely be alert to it being used as a reason to enable our, significantly worse, version from 2006. Rather surprisingly it seems from the
Government’s official database
that the s.3A tools amendment of the Computer Misuse Act has never actually been brought into force!
[UPDATE: on further investigation, it seems that s.3A was
brought into force
on 1st October 2008, but I can’t find any reports of prosecutions in which it has been used]
#80 - Internet Invariants – things worth fighting for
Originally posted: 31 May 2012 in category
Articles
Leslie Daigle, Chief Internet Technology Officer of the Internet Society (ISOC) talked about the Society’s eight “
Internet invariants
” in the closing plenary session of TERENA’s Networking Conference 2012. The invariants are key features of the Internet that make it such a good platform for innovation and whose loss might harm the network’s ability to support unexpected developments in future. To stress how important this is, Leslie asked whether the originators of Twitter, Facebook or even the web would have been able to persuade bankers or venture capitalists to invest in their idea? The Internet as it was then, and mostly still is, meant they didn’t have to – they only needed to persuade users to adopt it.
At present discussion of the Internet’s uniqueness tends to focus on technical principles such as “end-to-end” or “smart edge/dumb middle”; this can result in policy makers and technologists debating which technology to choose to implement a policy (e.g. whether to block illegal websites using DNS or BGP), rather than whether the policy itself is a good idea. ISOC has consciously tried to move away from this into expressions of policy choices, whose consequences both policy makers and technologists should be able to appreciate and debate. The resulting invariants are summarised as Global reach and integrity; General purpose; Permissionless Innovation; Openness/Accessibility (to consume and contribute); Interoperability; Collaboration; Building Block Technologies; No Permanent Favourites.
As an example of how these can be used to discuss very high level policies Leslie gave the example of Governments’ frequent wish to apply physical geography (and jurisdiction) to the Internet. This can arise in both positive (enforcing our laws on our Internet) and negative (excluding others from enforcing their laws on our Internet) forms. A recent draft EU paper suggesting a “digital Schengen boundary”, which appears to have been sithdrawn when the consequences were realised, may have contained both! Considering the effect on the invariants suggests that this is simply the wrong way to think about the problem – applying national borders would constrain Permissionless innovation and Collaboration; remove Global Integrity; might, depending on the country, challenge Openness and create (local) Permanent Favourites. Although the resulting network might retain Interoperability, General Purpose and Building Block Technology at a technical level, in practice it would be a series of national islands, with communication between them possible but severely limited.
The invariants can also be used to discuss the importance of technical issues, such as the
exhaustion of IPv4 addresses
discussed by Geoff Huston earlier in the conference. The measures being adopted to maximise use of the few remaining addresses, rather than manage an orderly transition to IPv6, threaten Permissionless innovation, Interoperability, General Purpose and Global Reach, as well as declaring IPv4 to be a Permanent Favourite.
On a brighter note, the continuing history of publishing on the Internet shows what can be achieved so long as the invariants are protected. Gopher was replaced by the web, which enabled Google, amazon, Facebook and Twitter and now supports everything from revolution to knitting. All were developed at the edge of the network, not in the laboratories of network providers or large companies. Indeed now even those edge technologists may have lost control – the success or failure of a new Internet service now depends on the choice of millions of users. Which is a good thing: there never should be a master-plan for the Internet.
Tuesday morning at the TERENA Networking Conference 2012 began with an entertaining and important call to action by
Geoff Huston
, on why we may have left transition to IPv6 too late and the serious consequences for open Internet connectivity that could result. It was recognised as early as 1992 that the 32-bit address space of IPv4 was going to be insufficient, indeed in those days this was expected to happen about 2002. The problem was postponed by the change from classful to CIDR routing, which was so successful that at one time the supply of addresses was expected to last till 2050. However the widespread adoption of home broadband and mobile connectivity increased the rate of usage and IANA issued its last block of addresses last year.
The solution to the problem – the greatly increased address space offered by IPv6 – has been known and deployable for many years. Indeed it is estimated that at least 50% of end user devices and 50% of backbone providers could already use it. Unfortunately between user devices and the backbone is the “last mile” where support is much less common. As a result most estimates suggest that less than 0.5% of Internet traffic uses IPv6. Most plans for an orderly transition from IPv4 to IPv6 included a period (perhaps several years) of parallel running, where those systems that supported both protocols offered them both and traffic gradually migrated as more and more paths became possible through v6. Unfortunately that relies on new devices being able to obtain both a v4 and a v6 address so long as they were needed to ensure that they could reach those services that did not yet have full v6 connectivity; in most regions of the world that will soon become increasingly difficult.
Instead there seems a significant risk that ISPs will try to maximise the use of the few remaining IPv4 addresses by re-using them through technologies such as Network Address Translation (NAT) and Application Gateways. NAT is already common at the edge of the network, in home routers and mobile connectivity, and can already limit what protocols can easily be used. UDP suffers particularly badly. Moving NAT further into the core of the network, with the likelihood that a given path will have to cross multiple NAT steps, seems likely to increase these problems. Application gateways cause even more problems because only those applications the gateway has been programmed to recognise can be used at all. Thus both developments are likely to reduce the Internet’s ability to support the development of new applications and services, since it will no longer be possible to achieve widespread use without persuading ISPs to support them in their application gateways.
This suddenly starts to sound like the
network neutrality debate
that has been taking place among European legislators and telecoms regulators, except that pressures to create a non-neutral internet now come from technological issues, rather than from economic ones. Perhaps the political interest that has emerged in encouraging ISPs to consider the open Internet as more important than short term financial interests might also be used to encourage them to adopt a long-term, rather than short-term, approach to the IPv6 transition?
Originally posted: 29 May 2012 in category
Articles
With enforcement of the UK’s new law on internet cookies due to begin this week, on Friday the Information Commissioner published a new version of his
guidance on compliance
. Although the Information Commissioner says the new version is a clarification, others have described it as a “
striking shift
”.
The most significant change appears to be the explicit statement on pages 9&10 of something that was hinted in the previous version – that “implied consent”, rather than “explicit consent”, may be acceptable for cookies used to analyse visits to websites. To clarify this, the section on “implied consent” has been extended. To give explicit consent a visitor must actually sign/say/click “I consent”. For implied consent:
there has to be some action taken by the consenting individual from which their consent can be inferred. This might for example be visiting a website, moving from one page to another or clicking on a particular button. The key point, however, is that when taking this action the individual has to have a reasonable understanding that by doing so they are agreeing to cookies being set.
So, using examples from the previous version of the guide (now on pages 21&22), if a website has a checkbox for “remember my settings (uses a cookie)” or a link to “shopping basket (uses cookies)”, then a user who selects that option will also give implied consent to the storage of the cookie. The new guidance makes clear that for this implied consent to be valid, the site must be sure that the visitor did understand the consequences, and that it can’t rely on the visitor having read a particular section of the privacy policy.
For analytic cookies the same applies: if the site wishes to rely on implicit, rather than explicit, consent it must give sufficient notice and explanation to achieve a “common understanding” between the visitor and the site as to what the cookie will be used for. And “it must always be possible for the user to decline to accept cookies”, either at browser or site-specific level. The guidance does continue to distinguish between analytic and advertising cookies, so I suspect the extension of implicit consent doesn’t apply to the latter.
The guidance doesn’t seem to have changed its position on whether sites can imply consent from the fact that a visitor hasn’t set their browser to exclude cookies (Not yet: “At present, most browser settings are not sophisticated enough for websites to assume that consent has been given to allow the site to set a cookie”), nor whether visitors can be assumed to know about cookies and recognise when they are likely to be used (Not yet: “current levels of awareness of the way cookies are used and the options available to manage them is limited”). So if a site wants to rely on implied consent, it needs to provide both descriptions of its cookies and notice when the visitor approaches an area or function of the site where they are used.
While the new guidance will be welcomed by those still struggling to comply with the law (and those fearing a blizzard of pop-ups), it’s unfortunate that it couldn’t have been issued earlier. For the past two years the ICO has been trying to persuade websites to solve hard technical and user interface problems in order to comply with the law. This last minute change to what “compliance” means seems likely to make that argument even harder next time.
Originally posted: 29 May 2012 in category
Articles
With enforcement of the UK’s new law on internet cookies due to begin this week, on Friday the Information Commissioner published a new version of his
guidance on compliance
. Although the Information Commissioner says the new version is a clarification, others have described it as a “
striking shift
”.
The most significant change appears to be the explicit statement on pages 9&10 of something that was hinted in the previous version – that “implied consent”, rather than “explicit consent”, may be acceptable for cookies used to analyse visits to websites. To clarify this, the section on “implied consent” has been extended. To give explicit consent a visitor must actually sign/say/click “I consent”. For implied consent:
there has to be some action taken by the consenting individual from which their consent can be inferred. This might for example be visiting a website, moving from one page to another or clicking on a particular button. The key point, however, is that when taking this action the individual has to have a reasonable understanding that by doing so they are agreeing to cookies being set.
So, using examples from the previous version of the guide (now on pages 21&22), if a website has a checkbox for “remember my settings (uses a cookie)” or a link to “shopping basket (uses cookies)”, then a user who selects that option will also give implied consent to the storage of the cookie. The new guidance makes clear that for this implied consent to be valid, the site must be sure that the visitor did understand the consequences, and that it can’t rely on the visitor having read a particular section of the privacy policy.
For analytic cookies the same applies: if the site wishes to rely on implicit, rather than explicit, consent it must give sufficient notice and explanation to achieve a “common understanding” between the visitor and the site as to what the cookie will be used for. And “it must always be possible for the user to decline to accept cookies”, either at browser or site-specific level. The guidance does continue to distinguish between analytic and advertising cookies, so I suspect the extension of implicit consent doesn’t apply to the latter.
The guidance doesn’t seem to have changed its position on whether sites can imply consent from the fact that a visitor hasn’t set their browser to exclude cookies (Not yet: “At present, most browser settings are not sophisticated enough for websites to assume that consent has been given to allow the site to set a cookie”), nor whether visitors can be assumed to know about cookies and recognise when they are likely to be used (Not yet: “current levels of awareness of the way cookies are used and the options available to manage them is limited”). So if a site wants to rely on implied consent, it needs to provide both descriptions of its cookies and notice when the visitor approaches an area or function of the site where they are used.
While the new guidance will be welcomed by those still struggling to comply with the law (and those fearing a blizzard of pop-ups), it’s unfortunate that it couldn’t have been issued earlier. For the past two years the ICO has been trying to persuade websites to solve hard technical and user interface problems in order to comply with the law. This last minute change to what “compliance” means seems likely to make that argument even harder next time.
Originally posted: 11 May 2012 in category
Articles
The new
Defamation Bill
promised in the Queen’s Speech has now been published. Although it also contains changes to what statements can give rise to liability for defamation, the most interesting part for network operators is likely to be the new provisions on liability for those who host third party content on web sites and blogs.
Section 1 of the current
Defamation Act 1996
essentially gives hosts two options when they receive a complaint that a statement on their site is defamatory:
remove or modify the statement promptly, and be sure that they cannot incur liability for the defamation;
leave the statement untouched and risk being found liable for publication if it is subsequently found to be defamatory.
Paragraph 5 of the Bill would create two more options:
If it is possible for the claimant to identify the person who posted the statement, then the host is protected from liability and does not need to do anything;
If it is not possible for the claimant to identify the poster, then the host is protected from liability so long as they follow a process or processes that will be specified in a subsequent Statutory Instrument.
While the new options are welcome, the current wording creates three obvious questions:
What is included within the scope of “website”? And how will this affect future publication technologies that haven’t yet been invented?
Is the “operator” of a website the person that runs the server, the website software, the main author of a blog, etc.? I would hope that at least those three are covered.
What is meant by “identifying” the person who posted the statement? This posting says that it was written by “Andrew Cormack”, but searching the web reveals several individuals with that name. Or is it sufficient that a complainant could request a Norwich Pharmacal Order against the operator of this site and discover which of them it is? I would imagine that a website operator would want to be very sure that the poster was indeed sufficiently “identifiable” before they left an allegedly defamatory statement untouched.
Section 5(4) of the Bill also specifies what needs to be in a notice in order to trigger this process: a welcome clarification.
During the
consultation process that led to this Bill
, it was also suggested by the Joint Parliamentary Committee that it might change the current legal position that encourages a website operator to wait for complaints rather than proactively checking for defamatory statements. I’ve a feeling that the double negatives (“you have a defence… unless” )in the Bill do actually have that effect, but I need to study them a bit more to be sure. If so, as noted below, this would only apply to proactive checking for defamatory statements, not to other types of unlawful publication.
The consultation also suggested that there might be a process to allow a website operator to ask for a judicial ruling on whether an anonymous posting was defamatory, if it felt that there was good reason not to remove it (for example because of the statutory duty on universities and colleges to promote free speech). That doesn’t seem to be in the Bill, but it could still be included in the Regulations.
And, of course, this Bill only affects liability for defamation, not for other types of civil or criminal illegality, such as copyright breach. Those will continue to be covered (by default) by the notice and takedown procedures in the eCommerce Directive.
Originally posted: 4 May 2012 in category
Articles
Given the outcome of previous hearings on copyright infringement, the court’s conclusion this week that the UK’s major ISPs should be ordered to block access to The Pirate Bay was no surprise. However the
judgment
raises an interesting technical issue. In a previous hearing, it had been pointed out that there was a way to get around blocks on individual web pages that would not be possible if the block instead referred to the IP address of the website as a whole. IP address blocking is recognised as carrying the highest risk of blocking legitimate material (“overblocking”) but it seems that the current IP address of The Pirate Bay is only used by the site, so the judge was prepared in this case to permit blocking of all access to those addresses.
However there are many other evasion techniques that get around both URL and IP blocks and the legal action against The Pirate Bay has been accompanied by a lot of publicity for those. According to a BBC report, there has been
a significant increase in their use by young people
in recent years. Unfortunately such techniques don’t just open up access to sites blocked for copyright reasons, they inevitably evade all other filters implemented by ISPs as well. So those using them may well increase their risk of exposure to images listed by the
Internet Watch Foundation
(earlier orders explicitly required ISPs to use the same systems to block copyright and IWF material), malicious code, and phishing sites that steal banking and other passwords. ISPs can no longer protect these users by filtering: all that will be left is any protection that may be implemented on the individual’s computer, smartphone, etc. Techniques such as the Virtual Private Networks described by the BBC also mean that the VPN operator can see all the user’s Internet traffic, creating a significant privacy threat if the operator, or their country, doesn’t protect that information as the user expects.
Originally posted: 4 May 2012 in category
Articles
A bot is a program, maliciously installed on a computer, that allows that computer and thousands of others to be controlled by attackers. Bots are one of the major problems on the Internet, involved in many spam campaigns and distributed denial of service attacks, as well as allowing attackers to read private information from the computer’s disk and keyboard. Some bots even allow cameras and microphones to be monitored by the attacker. Detecting and removing bots is therefore in the interests of both individuals and internet providers.
RFC6561
describes the technical issues around detecting and notifying Internet users whose computers may have been infected by a bot, and also highlights the need to take account of legal, economic and reputational issues when doing so.
One of the main problems with bots is that they are now very good at concealing themselves alongside legitimate programs and internet traffic. The RFC notes that
With the introduction of peer-to-peer (P2P) architectures and associated protocols, the use of HTTP and other resilient communication protocols, and the widespread adoption of encryption, bots are considerably more difficult to identify and isolate from typical network usage. As a result, increased reliance is being placed on anomaly detection and behavioral analysis, both locally and remotely, to identify bots.
Unfortunately neither anomaly detection nor behavioural analysis can be perfect: both may be triggered by legitimate Internet activity that happens to generate patterns that look like those of a bot. This means that any detection and notification process must be aware that some of the computers “detected” will not be in fact be infected. Even for computers that are infected, removing the bot may require more than the average level of technical skill, or involve actions such as deleting and re-installing the operating system that users are not willing or able to do. As an increasing number of devices are connected to the Internet, it seems likely that bots will infect equipment that the user simply cannot disinfect, such as games consoles, set-top boxes or smart meters.
Detecting infected systems also raises significant legal and technical concerns. Since Internet Service Providers know who their customers are, examining their traffic to identify devices that may be infected will involve processing of personal data; detailed inspection of traffic may even come within the scope of Interception law. Such laws may have exemptions for particular actions by network operators, but these are likely to be tightly constrained and require additional privacy protection. Even if the action is lawful, attempts to protect users in this way can be mis-understood – either as unjustified “snooping” or as an attempt to sell security services – resulting in end-users rejecting them.
There are some examples of
successful botnet mitigation schemes
, and a
UK Parliamentary committee
has recently called for ISPs to do more in this area. However it’s clear that any scheme needs to be very carefully designed, with input from technical, legal and communications experts.
I did a presentation at the
EEMA eID Interoperability conference
last month on alternatives to “consent” in federated access management. At the moment consent seems to be the most often cited justification for processing personal data – websites frequently say that “by using this site you consent to…”. The problem with this is that the individual using the site may not have much choice about using the site if doing so is a legal requirement, necessary for their job, or even just an inevitable result of a decision. Once I choose to book a hotel room and pay by credit card it’s inevitable that the hotel and the card processor will both process my personal data: I can’t withdraw my “consent” without cancelling the whole booking. Regulators are increasingly pointing that out: the Article 29 Working Party’s
Opinion on Consent
states that consent cannot be used when there is either direct or indirect pressure on the individual to agree (for example if the individual is an employee); the Information Commissioner’s
guidance on Privacy Notices
warns against offering individuals an appearance of choice that they don’t actually have (as in the hotel booking example).
Consent, in its true legal sense, is actually a poor basis for many services anyway. In law,
consent must be freely-given
which means it can also be withdrawn at any time; consent therefore doesn’t work for services that depend on a long-term relationship with their users. As above, consent is often also inappropriate where the site and the user have an existing relationship which may create pressure, or where decisions have any sort of complex consequences. These types of service are much better suited to the other justifications for processing personal data that are provided by the
European Directive
(in Article 7) and UK Law (
Schedule 2 of the Data Protection Act 1998
): for example that the processing is necessary:
for the performance of a contract (often the case for employer/employee);
to satisfy a legal obligation; or
in the legitimate interests of the organisation or a third party, provided these are not overridden by the fundamental rights of the individual (for example to provide a service that the individual has requested, but not formally contracted for).
One reason why these justifications are not more widely used may be that they are not consistently applied in different member states, indeed in some member states the “legitimate interests” justification has been limited or omitted when transposing the Directive. However a recent
judgment of the European Court
on Spain’s restricted transposition of the “legitimate interests” justification notes that all of them are required for the “operation of the internal market” and calls for more consistency. The current Directive also omits “legitimate interests” as a justification for transfers outside the EEA, with the result that many overseas transfers claim to be based on consent even though the individuals may not be in a position to give it.
However the
new Data Protection Regulation
proposed by the European Commission would fix both of these problems. Since the new law is a Regulation, it should be implemented much more consistently. For the first time it allows “legitimate interests” to be used for overseas transfers so long as they are not “frequent or massive”, which seems to fit many federated access management applications. The proposal also codifies in law most of the limitations on consent that have been developed by regulators and courts in the seventeen years since the current Directive was passed.
It therefore seems like a good time to review any systems that we currently claim are based on “consent”, to check whether other justifications might, in fact, be more appropriate. Where personal information is genuinely required to provide a service, another justification will often be a better fit. Consent can then be left for its proper purpose where information is genuinely optional and the user is really able to make a free choice. This has benefits for both service providers and users. Interfaces for strictly necessary information processing only need to inform the user what will happen as an inevitable consequence of their use of a service: they don’t need to provide “I agree” buttons or other interactions that spoil the user interface. Where a service uses both necessary and optional information there are
familiar examples
from the real world of how to express this – we are all used to paper (and online) forms that have some (necessary) fields marked with asterisks and others left to us to choose whether we want to fill them in. Making this distinction clear avoids users feeling pressurised to disclose information that they aren’t comfortable with – something that at best encourages us to provide false information and at worst can put us off using a site at all.
Considering all the options the law provides could have benefits for everyone.
Originally posted: 26 March 2012 in category
Articles
The
annual report of the Internet Watch Foundation
was published yesterday. The highlight is news that through closer collaboration with hotlines and Internet industries in other countries, the average time for removal of an illegal indecent image of a child from the Internet has dropped from over a month to twelve days. That is the average world-wide: in the UK such images are removed in hours.
As chair of the IWF’s Funding Council, I not only attended the launch event, but had the interesting experience of following two Government Ministers in giving a speech welcoming this achievement.
Originally posted: 14 March 2012 in category
Articles
Having been studying Europe’s
proposed Data Protection revision
for several weeks, it’s interesting to compare it with the proposed
Consumer Privacy Bill of Rights
recently published by the White House. This, too, recognises that the Internet is different to the paper-based world, but it seems to me to put this in a more positive way than the European Commission manage:
Companies process increasing quantities of personal data for a widening array of purposes. Consumers increasingly exchange personal data in active ways through channels such as online social networks and personal blogs. The reuse of personal data can be an important source of innovation that brings benefits to consumers but also raises difficult questions about privacy. The central challenge in this environment is to protect consumers’ privacy expectations while providing companies with the certainty they need to continue to innovate.
Notably, there’s an early and explicit recognition that this balance is what enables a lot of the free services we have become used to the Internet providing. If advertisers weren’t willing to pay for the patterns we generate when we use those services then, as in the real world, we’d probably have to pay for the services ourselves. So the Bill of Rights has objectives to both protect consumers and benefit businesses:
Strengthening consumer data privacy protections and promoting innovation require privacy protections that are comprehensive, actionable, and flexible.
The Bill contains seven Rights, which may look surprisingly familiar to European readers:
Individual Control: Consumers have a right to exercise control over what personal data companies collect from them and how they use it.
Transparency: Consumers have a right to easily understandable and accessible information about privacy and security practices
Respect for Context: Consumers have a right to expect that companies will collect, use, and disclose personal data in ways that are consistent with the context in which consumers provide the data
Security: Consumers have a right to secure and responsible handling of personal data
Access and Accuracy: Consumers have a right to access and correct personal data in usable formats, in a manner that is appropriate to the sensitivity of the data and the risk of adverse consequences to consumers if the data is inaccurate.
Focused Collection: Consumers have a right to reasonable limits on the personal data that companies collect and retain.
Accountability: Consumers have a right to have personal data handled by companies with appropriate measures in place to assure they adhere to the Consumer Privacy Bill of Rights.
Anything linkable to a specific individual is considered personal data, including information linked to a specific computer or device.
However the way in which those Rights would be implemented and enforced look very different to Europe. In the USA, current privacy law is specific to sectors of activity so, for example, there is a law (FERPA) on
personal data processed by education organisations
and a separate law (HIPAA) on health data. In other sectors there may be little or no regulation. The new Bill of Rights is not intended to replace these sector laws – unless they fall below the minimum standards – but to allow other parts of the private sector to develop their own Codes of Conduct to support the Rights. Once Codes of Conduct had been developed, it would be up to a business whether or not it chose to abide by an appropriate Code, but if it advertised itself as doing so then any breach of the Code could be punished by the Federal Trade Commission under existing laws on deceptive and unfair practices (as for the current
US/EU Safe Harbor
agreement):
“The FTC brings cases based on violations of commitments in its privacy statements under its authority to prevent deceptive acts or practices. In addition, the FTC brings data privacy cases under its unfairness jurisdiction, which will remain an important source of consumer data privacy protection”
Codes of conduct would be developed by a “multi-stakeholder process”, explicitly like the way that US policy for the Internet is developed. It is expected that this will “produce solutions in a more timely fashion than regulatory processes and treaty-based organizations”, which seem also to produce “fragmented, prescriptive, and unpredictable rules that frustrate innovation and undermine consumer trust” [Hmmm, I wonder if they have something particular in mind?]
There’s also a striking statement that both businesses and consumers have responsibilities for privacy (something Europe tends, at least officially, to be rather coy about):
The Consumer Privacy Bill of Rights also recognizes that consumers have certain responsibilities to protect their privacy as they engage in an increasingly networked society … In a growing number of cases, such as online social networks, the use of personal data begins with individuals’ decisions to choose privacy settings and to share personal data with others. In such contexts, consumers should evaluate their choices and take responsibility for the ones that they make. Control over the initial act of sharing is critical. Consumers should take responsibility for those decisions, just as companies that participate in and benefit from this sharing should provide usable tools and clear explanations to enable consumers to make meaningful choices.
Since the Bill of Rights won’t apply to the whole of the USA, it seems unlikely to result in a declaration under Europe’s Data Protection Directive that the country provides equivalent protection of personal data. However the White House does suggest that there could be mutual international recognition of Codes of Conduct – the provision in the Directive allowing that is pointed out – and international participation in their development. Safe Harbor is seen as an “early example” of this type of agreement. Both the US and EU’s recent documents on developing privacy law identify cloud computing as a challenging and important sector to address:
Further complicating matters is the proliferation of cloud computing systems. This globally distributed architecture helps deliver cost-effective, innovative new services to consumers, companies, and governments. It also allows consumers and companies to send the personal data they generate and use to recipients all over the world. Consumer data privacy frameworks should not only facilitate these technologies and business models but also adapt rapidly to those that have yet to emerge.
So perhaps that will be an early business sector taking advantage of the proposals on both sides of the Atlantic?
Internet Identifiers
: still no clarity on when IP addresses etc. are personal data, but at least more realistic provision for when they are;
Incident Response
: good to have this explicitly recognised as important for protecting privacy and building trust, but some risk that legislation may
create barriers
to necessary and proportionate sharing of information about incidents;
Breach Notification
: concern that timescales for reporting (and penalties for not meeting them) are unrealistic and may skew incident response priorities;
Cloud Computing
: looks helpful for consumer clouds, but leaves the existing uncertainties for those outsourcing to cloud providers.
#69 - Government Response on Draft Defamation Bill
Originally posted: 5 March 2012 in category
Articles
The Ministry of Justice has published their
response
to the Joint Parliamentary Committee’s comments on a proposed Defamation Bill. As discussed in a
previous post
, those comments included a novel suggestion that third party postings on websites be treated differently depending on whether the posting is attributed or anonymous. For organisations that allow such postings on their websites this would have reduced the current pressure to immediately remove postings when any complaint is received; it would also have reduced the risk that arises at the moment if an organisation decides to proactively check what is posted (more detail about these risks can be found in the
Janet response to the original consultation
).
The Government agrees with the Committee that the aim of reform should be to
strik[e] a balance which provides an effective means for people to protect their reputation where this is defamed on the internet, while ensuring that internet intermediaries are not unjustifiably required to remove material or deterred from properly monitoring content because of the fear that this will leave them potentially liable.
and that
on balance we accept that the current position in the law is not satisfactory, and that a greater degree of protection against liability for intermediaries is appropriate.
However they consider that the Committee’s recommendations would prove impractical and instead propose only an alternative way of handling complaints that doesn’t seem to address the problem of proactive checking.
The suggestion is that a new process be included in the Defamation Bill (the original consultation had planned to deal with on-line publication later, so at least the urgency of change has been recognised). At present an unaware hosting provider is protected from liability until they receive a complaint about specific material on their site. Under the proposal this protection would continue provided the host informed the poster of the complaint and attempted to resolve it. If this was not possible within a short time, the hosting provider could inform the complainant of the poster’s identity and would then be protected while a court decided the case between the poster and complainant.
This approach clearly leaves truly anonymous postings (where the website is unable to identify or contact the poster) in the same position as at present: likely to be taken down at the first complaint. It also seems to me that the process for dealing with attributed postings will have to be carefully designed: the Government recognise that safeguards will be needed, for example to protect whistleblowers, but if those make the required communications too onerous then hosting providers may conclude that the extended protection isn’t worth it and continue to behave as at present.
The alternative process might give some help to universities and colleges who (unlike commercial ISPs) have a statutory duty to protect free speech by their members and guests. If taking down a posting in response to a complaint seemed likely to harm free speech then the university could, perhaps, invite the poster to make themselves known to the complainant and have the balance of rights decided by a court. However this doesn’t help those who want to go further and check postings before they receive a complaint.
Originally posted: 21 February 2012 in category
Articles
The
latest case
brought by rightsholders under the Copyright Designs and Patents Act 1988 has found that bittorrent tracker site The Pirate Bay does infringe copyright according to the Act. Following this decision it seems likely that rightsholders will seek injunctions under s97A of the Act requiring ISPs to “block” access to the site, as they have already done for Newzbin.
Perhaps the more interesting aspect of the judgment is the report it gives of injunctions that have been granted since the
widely reported case involving BT and Newzbin
. BT were ordered last year to use URL blocking (implemented on their existing system for blocking IWF-listed material) to obstruct users’ access to Newzbin. This should ensure that only URLs associated with the Newzbin site were blocked. However subsequent injunctions against Sky and TalkTalk appear to have added blocking at the IP level (commonly known as blackholing). According to paragraph 3 of the judgment Sky were ordered to implement
(i) IP blocking in respect of each and every IP address from which the said website operates and which is:
(a) notified in writing to the [ISP] by the [Rightsholders] or their agents; and
(b) in respect of which the [Rightsholders] or their agents notify the [ISP] that the server with the notified IP address blocking does not also host a site that is not part of the Newzbin2 website.
While in TalkTalk (paragraph 4) the restriction that a notified IP address must only host the Newzbin2 site appears to have been relaxed to include “any IP address the sole or predominant purpose of which is to enable or facilitate access to the Newzbin2 website” though the rightsholder is still required to notify that the server hosts that no other website will be affected.
IP address blocking has been widely recognised (for example in
Ofcom’s report on website blocking
) as carrying a significant risk of unintentionally blocking access to lawful material. Blocking access to an IP address means, at least in principle, that all services using that IP address will become inacessible, so not just web, but e-mail, FTP and anything else. What makes this worse is that it is relatively common for many, completely unrelated, sites and services to be operated on the same hardware: companies that provide external web-hosting services are unlikely to operate a single machine for each of their customers. In both the
Scarlet and Netlog cases
in the European Court the risk of overblocking (and the resulting infringement of users’ right to receive and communicate information) has been a significant factor in refusing an order. In the Sky and TalkTalk injunctions it appears that the UK judges were satisfied that the Applicant rightsholders could determine that the IP addresses they sought blocks for were not being used in this way.
However there’s no certain way (other than asking the operator of the equipment) to take an IP address and find all the websites that run on it. The daily operation of the Internet requires the conversion in the other direction – if you know you want to access
www.ja.net
then your computer has to be able to discover that that has the IP address 212.219.98.101. There’s an Internet system called the Domain Name Service (DNS) whose job it is do to that. But the DNS doesn’t provide a way to start from 212.219.98.101 and discover, for example, that it is also the host for
www.nhs-he.org.uk
, a website apparently in a completely different top-level domain. Since the original version of this post I’ve been pointed at services such as
http://www.domaintools.com/research/reverse-ip/
that seem to do a reasonable job of finding other sites that share a given IP address. That claims to use a “patented algorithm” though it doesn’t give any further details; however all the algorithms I can think of depend on assumptions about Internet use that may not always be true.
I’ve not been able to find a full report of either the Sky or TalkTalk cases to see whether this issue was discussed; the addition of “or predominant” to the TalkTalk injunction suggests that it may have been. But unless the rightsholders have spotted something I haven’t, an assertion that a particular IP address “does not also host a site that is not part of the Newzbin2 website” seems to contain a certain amount of risk.
#67 - ECJ on Copyright Injunctions: Hosting Providers
Originally posted: 16 February 2012 in category
Articles
After ruling last year on the balance between the rights of copyright holders, users and network providers, the European Court of Justice has now ruled on the same question applied to the
case of a hosting provider
, the social network Netlog. As in the earlier
Scarlett case
, the copyright collecting society (SABAM) had asked the Belgian court to order Netlog to actively prevent the infringing use (in this case publication) of copyright materials by its users. Since this appeared to constitute a general duty to monitor content, prohibited by Article 15 of the
E-Commerce Directive (2000/31/EC)
, the Belgian court asked the European Court whether it could lawfully make the order.
In reaching its decision, the Court closely and explicitly followed its approach in Scarlett. It first considered what the order would require Netlog to do, concluding that
[the] filtering system would require the hosting service provider to identify, within all of the files stored on its servers by all its service users, the files which are likely to contain works in respect of which holders of intellectual-property rights claim to hold rights. Next, the hosting service provider would have to determine which of those files are being stored and made available to the public unlawfully, and, lastly, it would have to prevent files that it considers to be unlawful from being made available.
The Court felt this “would result in a serious infringement of Netlog’s freedom to conduct its business” by requiring it “to install a complicated, costly, permanent computer system at its own expense”. It would also infringe the rights of users “to protection of their personal data and their freedom to receive or impart information” since the system “could lead to the blocking of lawful communications”. As in Scarlett, the court concluded that an order involving such interference with the rights of the provider and users
would not be respecting the requirement that a fair balance be struck between the right to intellectual property, on the one hand, and the freedom to conduct business, the right to protection of personal data and the freedom to receive or impart information, on the other.
This confirms that key questions in any blocking order are the cost and disruption to the service provider and the level of privacy breach and overblocking for users.
Originally posted: 8 February 2012 in category
Articles
An interesting talk by Ken van Wyk on
threats to mobile devices
at the
FIRST/TF-CSIRT meeting
last week. While it’s tempting to treat smartphones just as small-screen laptops (let’s face it, users do!) there are significant differences in the threats to which the two types of devices are exposed. These need to be recognised in any plan to secure the devices and the information they store and have access to. OWASP have therefore used Microsoft’s
STRIDE threat model
to analyse mobile devices and come up with a list of the top
10 risks to them and their information
, and suggest things that can be done to reduce the problem.
The two major differences between smartphones and laptops are
Smartphones, being smaller, are much easier to lose, and
Smartphone applications tend to make less use of encryption when storing and transmitting information.
Clearly those two differences combine to make security issues a lot worse – if a device is easy to lose, so more likely to come into the wrong person’s hands, then encrypting information to protect it should be more, not less, important.
Unfortunately even though most smartphone platforms do offer secure containers, file permissions and encryption, these aren’t commonly used. This is particularly unfortunate as users tend to treat smartphones as universal authentication devices – it’s very tempting to store all your passwords on a device that feels psychologically attached to your body (despite
statistical evidence
that it isn’t). Unless you, and the developers of the applications you use, know what you are doing, that could be a really bad choice. Storing sensitive information on the removable storage device is a particularly bad idea – not only can a storage card be removed and read on another device, but the filesystem most commonly used allows any application on the phone to read any file, so a single bad application can compromise all the information on the storage card.
The whole point of a smartphone is to communicate, so you might expect things to be better there. Unfortunately the story is the same: phones can do encryption, but very often don’t. For some reason a lot of known good practice for computers and wired networks – like recognising that session authentication tokens are just as important as passwords or that certificate validation failures indicate a problem – don’t seem yet to have caught on on smartphones, even though the networks they use, being based on radio transmissions, are more likely to expose information to unwanted listeners.
The good news is that many of the OWASP mitigations can be achieved by individual smartphone users choosing carefully which applications they use and how they use them. However this would be easier if smartphone developers took note of the OWASP recommendations and implemented them in their products.
#65 - Data Protection Proposal: Federated Access Management
Originally posted: 3 February 2012 in category
Articles
The European Commission’s
proposed Data Protection Regulation
supports recent thinking in
moving away from using consent
as a basis for federated access management systems. The consent of the data subject is still one of the legitimate grounds for processing personal data but it cannot be used “where there is a significant imbalance” between the organisation and the individual (Article 7(4)) – for example between employer and employee – or where “the individual has no genuine or free choice and is subsequently not able to refuse or withdraw consent without detriment” (Recital 33, following the
Article 29 Working Party’s Opinion
).
Instead of consent, access management systems seem better suited to the grounds that either processing is necessary for the performance of a contract to which the individual is party (Art 6(1)(b)) or necessary in the legitimate interests of the service provider (Art 6(1)(f)). As in the
current Data Protection Directive
, the legitimate interests justification must not be used if this would be contrary to the interests and fundamental rights of the individual, however where processing is necessary to deliver a service the user has requested this seems unlikely to be the case. Although there is a legitimate interests provision in the Directive not all Member States have implemented it, so a Regulation that ensured all countries provided it would make a consistent framework for access management significantly easier to achieve.
The legitimate interests justification has also been extended, for the first time, to cover transfers of personal data outside Europe. Art.44(1)(h) allows such transfers, provided they are not “frequent or massive” so long as the European organisation releasing the personal information – normally the user’s home organisation in a federation – has assessed the risks and taken appropriate measures to protect the user. If transfers are “frequent or massive” then the identity provider and service provider seem likely to enter into a “contract concluded in the interest of the data subject”, making the transfer legitimate under Art.44(1)(c).
At present transfers of personal data to registered commercial organisations in the USA may be done under the
US/EU Safe Harbor
agreement, however this is not mentioned in the draft Regulation and it has been suggested that the agreement will be reviewed. Replacing it by more general arrangements, based either on the legitimate interests or contracts justifications of Article 44 or a declaration that an organisation provided adequate protection under Article 41(3), might be helpful to international federation agreements since it would no longer be necessary to treat the US commercial sector as a special case. In particular service providers within the US education sector, which cannot register under Safe Harbor, might be able to use these more general arrangements.
Finally, the Regulation seems unlikely to clarify the
status of pseudonymous identifiers
that are used by service providers to distinguish individual users without being able to determine their real-world identities. The current Directive says that such identifiers are personal data if the person “can be identified” (i.e. if there is any possibility of identification) whereas the draft Regulation narrows this to “can be identified … by means reasonably likely to be used…” (still wider than the definition in the UK’s
Data Protection Act 1998
, however). Recital 24 confirms that “It follows that identification numbers, location data, online identifiers or other specific factors as such need not necessarily be considered as personal data in all circumstances”, but does not explain the circumstances when such identifiers will, or will not, be personal data.
Originally posted: 1 February 2012 in category
Articles
In dealing with breaches of privacy the Commission’s enthusiasm to protect and reassure Internet users seems to run the risk of having the opposite effect. Article 4(9) of the
proposed Regulation
defines
‘personal data breach’ means a breach of security leading to the accidental or unlawful destruction, loss, alteration, unauthorised disclosure of, or access to, personal data transmitted, stored or otherwise processed;
According to Article 31, every personal data breach must be reported to the national privacy regulator (in the UK, the Information Commissioner), and a written explanation provided if this notification is not sent within 24 hours. Those breaches that are “likely to adversely affect the protection of the personal data or privacy of the [individual]” must then be notified to the individual “without undue delay” (Article 32(3) notes that this may not be needed where the personal data were encrypted so as to be “unintelligible to any person not authorised to access it”). The notification to the regulator must at least
(a) describe the nature of the personal data breach including the categories and number of data subjects concerned and the categories and number of data records concerned;
(b) communicate the identity and contact details of the data protection officer or other contact point where more information can be obtained;
(c) recommend measures to mitigate the possible adverse effects of the personal data breach;
(d) describe the consequences of the personal data breach;
(e) describe the measures proposed or taken by the controller to address the personal data breach.
The notification to individuals must include at least items (b) and (c) from that list.
The first problem with this timetable is that for many breaches the required information will not be known within 24 hours. If a system containing different types of personal data has been compromised it may take considerable forensic investigation to work out which information, and about which users, was actually disclosed to the intruder. Accurate answers to (a), (c), (d) and (e) cannot be provided until that results of that investigation are known. To meet the Regulation’s 24 hour target it seems likely that organisations’ answers will be estimates at best and, depending on their other motivations, may either be too optimistic or too pessimistic.
It is also important not to rush the process of notifying affected users. If organisations feel under pressure to publish something, they are likely to simply announce that they have suffered a breach affecting the security of personal data. As many past examples have shown, this kind of bland announcement is more likely to worry users and make them suspect the worst than to help them take appropriate measures to protect themselves.
Concentrating on notification also risks changing the priorities of those dealing with the incident. In most incident response plans, the first step is to contain the incident, to stop it spreading and increasing in severity. After that has been done, the organisation can secure evidence, investigate the breach and provide appropriate notifications informed by what has been discovered. If, instead, the organisation’s first priority is notification to comply with the law, then containment may be done later or less carefully so the scale and impact of the incident may actually be worse than it needed to be. Recital 68 does recognise that “the need to implement appropriate measures against continuing or similar data breaches may justify a longer delay” in notifying users; it will be important to ensure that this balance is recognised in implementing the Regulation.
It is interesting to compare the Regulation’s approach to breach notification with the approach taken in amending the
Privacy and Electronic Communications Directive
in 2009 (Directive 2009/136/EC); this had the same objectives but only applied to electronic communications service providers. In 2009 the requirement was for breaches to be notified to the regulator “without undue delay”: the decision on actual timescales was left to those regulators. In the UK, the
Information Commissioner’s guidance
is that only serious breaches need to be reported immediately, with minor breaches being reported monthly as part of a continuing log to avoid “unnecessary delay”. Clearly this is significantly different. Since the breach notification provisions of the 2009 Directive should now be in force in all Member States, results from those should at least be used to inform the development and implementation of the provisions in the Regulation. The new legislation must encourage organisations to help their users, not force them into early publication of either alarming or falsely reassuring information.
Originally posted: 31 January 2012 in category
Articles
Cloud computing, whose whole point is to be independent of geography, does not fit comfortably into current data protection law. The
Commission’s new proposal
at least shows signs that clouds were a use case that was considered during drafting, so it is more obvious which provisions apply to them. These seem to offer a mixture of carrots and sticks to try to bring clouds within the European data protection regime.
The most obvious benefit to cloud providers is that the Regulation would create a consistent law across all the Member States, so providers would only need to design their services and contracts to satisfy that single set of rules. At the moment a provider may have to satisfy 27 different data protection laws and formalities, without being completely clear which of these applied to which users. Under the current law a provider that wishes to store or process data outside the EC is supposed to incorporate a very specific set of provisions into its contract – it’s not clear that any actually do so – but under the proposal there would be much more flexibility, with the opportunity to combine contract terms and technical measures to deliver the required level of protection for the data. There is even a justification in Article 44(1)(c) that seems specifically designed to cover outsourcing arrangements: “the transfer is necessary for … a contract concluded in the interest of the data subject between the controller and another natural or legal person”. Finally it would even seem possible for a cloud provider (which would presumably qualify as an “international company”) to have its systems formally recognised by a data protection authority as providing adequate protection; under the current rules only a country can be the subject of such a declaration which leaves the position very unclear for those cloud providers that have data centres in many different countries.
Bringing cloud services within the EC legal framework also appears likely to increase the regulatory demands on them. Article 3(2) is explicit that even services based outside Europe will be required to comply with EC law if they “offer goods or services to [individuals] within the Union” or have contracts with them or monitor their behaviour. Whereas at present an outsourcing contract is allowed to give the outsourcing organisation all liability, under the proposal even a service with a data processor contract can become directly liable if it does not protect information as the law requires. And if a cloud provider does fail to comply with the law then the penalties under the Regulation are significantly higher than at present: according to Article 80 supervisory authorities will be able to impose fines up to one million Euros or 4% of the organisation’s turnover for intentional or negligent breach of the Regulation.
The new Regulation therefore seems to offer cloud providers the opportunity to design and offer services that fully comply with European law. It remains to be seen whether this possibility will be sufficiently attractive for international providers to take it up.
UPDATE:
Prof Chris Millard
(Queen Mary, University of London) is less optimistic
Originally posted: 30 January 2012 in category
Articles
The Commission’s
proposed Data Protection Regulation
seems very positive for Incident Response. Indeed Recital 39 explicitly supports the work of Incident Response Teams:
The processing of data to the extent strictly necessary for the purposes of ensuring network and information security … by public authorities, Computer Emergency Response Teams … providers of electronic communications networks and services and by providers of security technologies and services, constitutes a legitimate interest of the concerned data controller. This could, for example, include preventing unauthorised access to electronic communications networks and malicious code distribution and stopping ‘denial of service’ attacks and damage to computer and electronic communication systems.
The mention of “legitimate interests” indicates that such activities would be justified by Article 6(f) of the Regulation (as was suggested in my paper on
Privacy and Incident Response
for the equivalent Article 7(f) of the current Directive), and now also supports necessary transfers of information outside Europe (for example when dealing with an attack coming from elsewhere in the world), since those, too, are permitted for “legitimate interests” by Article 44(1)(h). International transfers covered by this article are required not to be “frequent or massive” but this will rarely be the case when responding to an incident, and “appropriate safeguards”, such as transferring to a trusted partner CERT, must be applied. Although a similar recital about Incident Response was
recently added
to the Electronic Commerce Directive, having it in the main Data Protection Regulation confirms that it applies to all CERTs, not just those associated with electronic communications networks.
For those organisations that do not have an Incident Response capability, Recital 69 seems to encourage them to establish one, since if an organisation suffers a security breach that affects personal data, it will be judged on whether it has “implemented and applied appropriate technological protection and organisational measures to establish immediately whether a personal data breach has taken place”. An Incident Response capability could well be one of those organisational measures.
The Regulation also appears to address one of the unusual features of Incident Response – that although it often involves identifiers such as IP addresses that are regarded as personal data, the Incident Response team will rarely be able to identify the individual to inform them that their personal information is being processed. Article 10 recognises that this situation may arise, and clarifies that “if the data processed by a controller do not permit the controller to identify a natural person, the controller shall not be obliged to acquire additional information in order to identify the data subject for the sole purpose of complying with any provision of this Regulation”. It would be perverse indeed if a law on privacy compelled Incident Response teams to seek out the personal identities of all the Internet users who may be associated with incidents!
There is one concern in the apparent contradiction that Recital 39 encourages “public authorities” to also use the “legitimate interests” justification for their incident response activities, while Article 6(f) says that it may not be used by public authorities. If different justifications are used by different CERTs this may create problems for transferring information between them, since a CERT processing information under Article 6(f) – required to ensure such processing is not overridden by the fundamental rights of the individual – may be reluctant to share information with a CERT operating under Article 6(e) which is not subject to that limitation. The potential for difficulties if national CERTs were handled differently from others was highlighted in ENISA’s recent report on
legal aspects of information sharing
and will need to be borne in mind in implementing this part of the legislation.
Originally posted: 29 January 2012 in category
Articles
Last week the
European Commission
published their proposed new Data Protection legislation. This will now be discussed and probably amended by the European Parliament and Council of Ministers before it becomes law, a process that most commentators expect to take at least two years. There’s a lot in the proposal so this post will just cover the general themes. The detail relevant to particular issues including
incident response
,
breach notification
,
cloud computing
and
federated access management
will be in subsequent posts.
The first important point is that the proposal is for a Regulation, not a Directive like previous European privacy laws. A Directive is an instruction to the 27 Member State legislatures to produce a law with particular characteristics. Each of the resulting laws is then interpreted by national regulators and courts, so significant differences can arise between different countries’ implementations. In Data Protection, the Commission feels that that has created problems both for organisations – which may have to deal with different requirements and formalities – and for users whose information may be protected differently just because it, or they, cross a border. To avoid this problem, the Commission are proposing a
draft Regulation
, which would itself become the law in all member states. To further reduce the possibilities for divergence they are also proposing that the advice and actions of data protection authorities will be more strongly linked – advice and decisions from one country should also take effect in the others.
Greater consistency alone would help networked services, which are frequently international, but the Commission also mention IT and the Internet specifically. While still concerned that “technology allows both private companies and public authorities to make use of personal data on an unprecedented scale in order to pursue their activities” they seem to have accepted that successful European businesses need to be able to use technology services in other continents. The new proposal therefore offers much more scope for making international data processing lawful. At present only a whole country can be declared to provide adequate protection for personal data, but the new proposal allows such a declaration to cover “a territory or a processing sector within a third country, or an international organisation” as well. Where a transfer isn’t covered by a declaration of adequacy there is a range of other options, from formal contracts for “frequent or massive” transfers to an assessment of risk for single transfers of small quantities of less sensitive data. In recognising the international reality of the Internet the Commission also proposes to expand the scope of the Regulation to cover any organisation, even those outside the EU, if they “offer goods or services” to individuals inside the EU or monitor their behaviour. What used to look like a data protection cliff in mid-Atlantic seems to be turning into more of a slope.
The aspect of the proposal that has attracted most
comment
and seems likely to be most controversial is the increased requirements on organisations. Although the formal requirement to notify a national regulator will go, every organisation will need to maintain comprehensive documentation for both users and regulators, a data protection officer will become mandatory for all but companies employing fewer than 250 people, and the fines for non-compliance are increased (though not as much as in the
leaked draft
). If this does provoke a lot of argument, it’s to be hoped that the improvements elsewhere aren’t lost in the noise.
Originally posted: 29 November 2011 in category
Articles
The European Court of Justice has set some limits for the sorts of measures that ISPs can be compelled to implement to discourage copyright breach by their networks. Back in 2004 the Belgian rightsholder representative SABAM sought a court order requiring an ISP, Scarlet, to install devices on its network that inspected the content of peer-to-peer communications and blocked any that appeared to contain copyright music. The question of whether this order was compliant with European law worked its way up to the ECJ, which has now released
its judgment
.
The Belgian court had described the required measure as “a system for filtering all electronic communications passing via [the ISP’s] services, in particular those involving the use of peer-to-peer software; which applies indiscriminately to all its customers;as a preventive measure; exclusively at its expense; and for an unlimited period”.
The ECJ confirms that under the
IPR Enforcement Directive (2004/48/EC)
, national courts can make injunctions to prevent copyright breaches. However the scope of those injunctions is limited by three factors:
The impact of the measure on the ISP’s freedom to conduct its business must be proportionate and not excessively costly (Article 3 of the
IPR Enforcement Directive 2004/48/EC
);
The impact of the measure on users’ right to privacy and their right to impart and receive information must be proportionate (Human Rights Convention).
It concludes that the system described by the Belgian court would fail all three of these tests in that it does require the ISP to carry out general monitoring (para 40), that the cost to the ISP (and therefore the interference with its business) was not proportionate to the benefits achieved (para 48), that the interference with users’ right to privacy did not achieve a fair balance (para 51), nor did the interference with their right to impart and receive information. Interestingly the court recognised that a pure technical system may not make accurate decisions on whether a particular transmission breaches copyright because that “depends on the application of statutory exceptions to copyright which vary from one Member State to another” (para 52); thus it was possible that the system would block transmissions that were lawful.
Although this particular order was found to be unlawful, the court’s reasoning seems to leave scope for more limited, less intrusive and less costly systems to be found to be lawful. For example in the recent
UK case ordering BT to use URL blocking
to prevent access to a copyright infringing website the court clearly considered it significant that BT already had a URL blocking system in place and that the additional cost of the order would be a few thousand pounds.
#59 - Processing personal data for third party interests
Originally posted: 28 November 2011 in category
Articles
An interesting reminder from the European Court of Justice (ECJ) that the
Data Protection Directive (95/46/EC)
is supposed to make processing and exchanging personal data easier as well as safer. The Directive contains a number of different reasons justifying processing of personal data (gathered together as
Schedule 2 of the UK Data Protection Act 1998
), including consent, necessity to fulfil a contract with the data subject or to satisfy a legal duty, etc. A recent
ECJ case
has looked at the last of these: “processing is necessary for the purposes of the legitimate interests pursued by the controller or by the third party or parties to whom the data are disclosed, except where such interests are overridden by the interests or fundamental rights and freedoms of the data subject which require protection.” (Article 7f of the Directive, transposed as s6 of Schedule 2 of the UK Act).
This turns out to be useful in a number of situations where there isn’t a direct link between the person doing the processing and the data subject, but where the processing has benefits to both of them. For example when a university wants to confirm to an on-line journal that a particular user is covered by a site licence it would be cumbersome to require a contract between the journal and each user, while consent cannot be freely given if the journal is something a member of staff has to read as part of their job. Similarly if an incident response team identifies that a particular computer is a member of a botnet they would often like to warn the responsible ISP of this even though there is clearly no possibility of obtaining the user’s consent or contract. In both the
federated authorisation
and
incident response
situations, Article 7f fits the bill, while still protecting the data subject by insisting that only “necessary” data are processed.
Unfortunately it turns out that many member states haven’t fully implemented Article 7f. In Spain, for example, there’s an additional restriction that Article 7f can only be used for “data … in sources accessible to the public”. While the ECJ accepts that data from non-public sources will often represent a greater threat to the privacy – something that will need to be taken into account when balancing the risks and benefits of any particular processing – it considers that the current blanket restriction “constitutes a barrier to the free movement of personal data” and is therefore not compatible with the Directive. This should result in more consistent implementations of Article 7f and fewer problems when trying to arrange the transfer of personal data between European countries.
Originally posted: 27 October 2011 in category
Articles
The latest
judgment from the BT/Newzbin case
sets out what BT will be required to do to prevent its users accessing the Newzbin2 website that
an earlier case
found to be breaching copyright. From next month, BT will be required to add the Newzbin URLs to the system it already uses to limit access to child abuse images identified by the
Internet Watch Foundation
. I’ve argued for some time that using blocking for two different purposes is risky since (unlike blocking material that is generally considered abhorrent) it creates an incentive for those seeking free entertainment to discover and use techniques to evade blocks. Anyone who does so is likely to remove themselves from all blocks, including those that protect them from illegal material and security threats to them and their computers.
By being so specific about the technical approach to be used, the judge appears to have set a deliberately narrow precedent. During the case he was asked about extending the block to networks not covered by the current filtering system (paras 7-9) and about ISPs that implement filtering in a different way (para 4). In each case the answer was that that would require a different court order (and, presumably, a further court case). Furthermore the current order also applies only to Newzbin2 “and any other IP address or URL whose sole or predominant purpose is to enable or facilitate access to the Newzbin2 website”. It is not clear whether other ISPs will now implement blocks on their own BT-like systems, or argue that their situation is sufficiently different to require a new case.
#57 - Joint Committee Report on Draft Defamation Bill
Originally posted: 20 October 2011 in category
Articles
The
report of Parliament’s Joint Committee on the Draft Defamation Bill
acknowledges the problems raised in
our response to the consultation
and proposes some novel solutions. As was noted by the Law Commission in 2002, current defamation law encourages Internet hosts to remove material provided by third parties as soon as they receive a complaint that it is defamatory, without investigating the validity of the complaint. Furthermore if a host attempts to check or moderate such content before a complaint is received, it may well acquire liability by doing so. The committee conclude (para 99):
As the law stands, far from encouraging service providers to foster legitimate debate in a responsible manner and removing the most extreme material, it encourages them to ignore any dubious material but then to remove it without question following a complaint. This is contrary to the public interest and an unacceptable state of affairs.
They therefore recommend (para 100) that the Government takes action by:
Ensuring that people who are defamed online, whether or not they know the identity of the author, have a quick and inexpensive way to protect their reputation, in line with our core principles of reducing costs and improving accessibility;
Reducing the pressure on hosts and service providers to take down material whenever it is challenged as being defamatory, in line with our core principle of protecting freedom of speech; and
Encouraging site owners to moderate content that is written by its users, in line with our core principle that freedom of speech should be exercised with due regard to the protection of reputation.
They propose that this be achieved by a new statutory notice and takedown process, which would be the only way that an on-line host can acquire liability for third party content. In particular whether a host monitors or moderates will no longer be relevant, so “correct[ing] the existing disincentive to online hosts to moderate sites”. The process would distinguish between material that is “written by an identifiable author” and material that is not (it’s not made clear what constitutes “identifiability” – is an e-mail address sufficient or does the host need to obtain, or even publish, real-world contact details?):
Where a complaint is made about a posting by an identifiable author, the host will be protected from liability so long as they “publish promptly a notice of complaint alongside that material”. If this is not sufficient the complainant can ask a court to order the removal of the material: if this is done the host must inform the author and then follow the court’s direction. (para 104)
For postings where the author is not identifiable, the host must remove the material when a complaint is received, “unless the author promptly responds positively to a request to identify themselves”, in which case the complaint is treated as above (this implies that the host can communicate with the author, which won’t always be the case). If the host believes that public interest justifies continued publication then they can ask a court to make a “leave-up” order; otherwise the host becomes liable for any defamation if they do not remove the material. (para 105)
This would clearly provide Internet hosts with much stronger protection than at present where the author of a post is known. For anonymous postings the position doesn’t seem to change much, though the Committee’s comments on the difficulty of identifying and pursuing anonymous authors indicate that they expect the host to be the sole defendant in most cases that do make it to court.
There is some help for universities and colleges who are required to promote free speech by their members – a requirement that may make it harder to follow a notice and takedown procedure. A qualified privilege is proposed to protect reports of academic and scientific conferences and peer-reviewed articles in journals (paras 47-49). And where other types of on-line publication need to be made anonymously then there would be the option of seeking a “leave-up” notice when a complaint is received: in effect this would be a judicial decision on whether or not a complaint is justified, something that is not available under the current system without risking liability if the court upholds the complaint.
It will be interesting to see how the Government responds to these proposals.
The committee don’t limit themselves to changing the law: according to paragraph 103 the treatment of anonymous comments is an attempt to change how they are viewed:
Specifically we expect, and wish to promote, a cultural shift towards a general recognition that unidentified postings are not to be treated as true, reliable or trustworthy. The desired outcome to be achieved—albeit not immediately—should be that they are ignored or not regarded as credible unless the author is willing to justify or defend what they have written by disclosing his or her identity
Since it is suggested elsewhere that the measures will “limit the credibility of, and therefore damage that can be caused by, material that is published anonymously” it seems that the hope is to change the attitudes of both readers and subjects. Given that the committee also recommend (para 28) raising the threshhold so that only publications causing “serious and substantial harm” can break the law, perhaps the aim is to take anonymous comments below the threshhold and out of the scope of defamation law entirely?
Originally posted: 3 August 2011 in category
Articles
Last year’s Digital Economy Act 2010 created a power (
s.17
) for a court to order a service provider to prevent access to a “location on the Internet” if that location was being used, or likely to be used, to infringe copyright. That power has not been brought into force and last January Ofcom were asked to report to the Government on whether such blocking could be effective. In the past week there have been two, apparently contradictory, developments.
First, in the case of
Twentieth Century Fox and others v British Telecom [2011] EWHC 1981 Ch
, the High Court decided that it already had the power, under
s.97A of the Copyrights, Designs and Patents Act 1988
, to order BT to “prevent its services being used by users and operators of the website known as NEWZBIN and NEWZBIN2 to infringe copyright”. Newzbin had been found by an earlier case to infringe the copyrights of film studios; shortly after that judgment that site closed and the similar Newzbin2 site appeared. The judge made the order recognising that “prevention” is impossible and that users would find ways around any technical block but nonetheless considered that “the order would be justified even if it only prevented access to Newzbin2 by a minority of users” (para 198).
However a
press release
today from the Department for Business, Innovation and Skills seems to reach the opposite conclusion: that “the [section 17] provisions as they stand would not be effective and so the Government will not bring forward the Act’s site-blocking provisions at this time”. This is based on
Ofcom’s report
, which has also been published. In fact Ofcom’s conclusions on the technical efficacy of blocking seem similar (if anything, more positive) to those of the judge:
Although imperfect and technically challenging, site blocking could nevertheless raise the costs and undermine the viability of at least some infringing sites, while also introducing barriers for users wishing to infringe. Site blocking is likely to deter casual and unintentional infringers and by requiring some degree of active circumvention raise the threshold even for determined infringers.
Instead their concern appears to be that the DEA’s injunction process may be too slow to be effective for rightsholders (real-time streaming of sporting events is identified as a problem), insufficiently clear for ISPs (what must be blocked, for how long, and who bears responsibility for any challenge), and perceived as unfair and/or an invasion of privacy by users, thus providing an additional incentive to circumvent the blocks. Ofcom conclude that addressing these issues would require a much broader package of changes than is provided by the Digital Economy Act.
Both the Ofcom report and the court case consider what technology might be used to implement a block. Ofcom discuss four possibilities: IP routing, DNS resolution, URL blocking and deep packet inspection (DPI). As in my discussions with them, they conclude that none of these is ideal: both IP and DNS risk significant over-blocking, URL blocking is expensive and limited to web traffic, and DPI is very expensive and could affect network integrity. In the short term they seem to prefer modifications to DNS resolvers, perhaps combined with the more expensive techniques, while noting that this will cause increasing problems as DNSSEC is deployed “over the next three to five years”. The court case was originally asked to require URL blocking, using BT’s existing system for blocking URLs on the Internet Watch Foundation’s Child Abuse Image list, however the judge appears to conclude in para 201 that the proportion of non-infringing material on the Newzbin sites is sufficiently low that requiring the studios to provide a full list of those URLs that do infringe would be disproportionate. A hearing on the exact approach to be taken is expected in the autumn, but the judge’s comments seem to suggest that either IP or DNS blocking will be adopted, given the limited over-blocking it will involve on this particular site. Interestingly, the Ofcom paper has some technical details redacted in an apparent recognition (as I have been pointing out to them for some time) that using the same system for both copyright material and child abuse imagery would risk making it easier to circumvent both types of block.
So is this a step forward or a step back for website blocking? At least it seems clear that for now the Copyright, Designs and Patents Act 1988 will be the relevant law. The judge seems to envisage a series of further cases to order other service providers to block access to Newzbin, with perhaps a few more expensive cases to consider whether any other sites are sufficiently serious infringers for blocking injunctions to be made. However commentators have
expressed concern
that the lack of clarity on who would pay the costs in those cases might mean that a threat of litigation is enough for an ISP to take a commercial decision to block “voluntarily” without insisting on an injunction.
Originally posted: 25 July 2011 in category
Articles
Although consent is a key concept in Data Protection, discussions of it often seem confused and legal interpretations inconsistent. For example the European Commission has in the past called both for a crackdown on the over-use of consent and for all processing of personal data to be based on consent! A new
Opinion on the Definition of Consent
from the Article 29 Working Party, probably the most authoritative body short of court cases, falls firmly into the “over-use” camp: “If it is correctly used, consent is a tool giving the data subject control over the processing of his data. If incorrectly used, the data subject’s control becomes illusory and consent constitutes an inappropriate basis for processing” (p2), and “Relying on consent may … prove to be a ‘false good solution’, simple at first glance but in reality complex and cumbersome”(p27). Fortunately consent is only one of six grounds for processing personal data that are provided by UK and European legislation: others include that processing is necessary for the performance of a contract between the parties, necessary to fulfil a legal obligation, and necessary for the legitimate interests of the data controller or a third party (see, for example,
Schedule 2 of the UK Data Protection Act 1998
). The Opinion aims to encourage those currently using consent as their justification to consider the possibility of “other legal grounds perhaps being more appropriate from both the controller’s and from the data subject’s perspective”.
The Working Party also suggest that in some cases a hybrid approach may be needed, with different grounds justifying different processing within the same transaction. Their example, of buying a car, is a little more complex than the
federated access management situation
I discussed recently. For a car purchase, some processing is necessary to create a valid contract between the parties, some (e.g. registering the new owner) is required by law, some (e.g. providing details to third parties who may service the car) takes place in the legitimate interests of those third parties, and some (e.g. collecting e-mail details for related advertising) is based on the buyer’s consent, which can be withdrawn at any time. Since each of those grounds gives the buyer different opportunities to stop processing, the distinction needs to be explained clearly to them.
To determine when consent may be the right choice, the Opinion starts from the definitions in the
Data Protection Directive (95/46/EC)
that, in order to be valid, consent must be “freely given, specific and informed” (p6) and that the person consenting must give an “unambiguous indication” that they have done so. Each of those requirements is then considered in turn:
Freely-given: “Consent can only be valid if the data subject [the person whose information is being processed] is able to exercise a real choice, and there is no risk of deception, intimidation, coercion or significant negative consequences if he/she does not consent”, and the “individual data subject … is subsequently able to withdraw the consent without detriment” (p13). The Opinion notes that questions about the validity of consent may arise when the data subject is under the influence of the data controller, for example as their employee, and where refusal of consent may have financial, emotional or practical consequences (p14). Consent will not inevitably be invalid in these circumstances but using a different justification, if possible, may lead to fewer difficulties.
Specific: “Consent must be given in relation to the different aspects of the processing, clearly identified. It includes notably which data are processed and for which purposes … There is a requirement of granularity of the consent with regard to the different elements that constitute the data processing: it cannot be held to cover ‘all the legitimate purposes’ followed by the data controller. Consent should refer to the processing that is reasonable and necessary in relation to the purpose.” (p17). Although consent does need to be obtained separately for different uses of personal data, it does not have to be sought every time the same use occurs: “It should be sufficient in principle for data controllers to obtain consent only once for different operations if they fall within the reasonable expectations of the data subject” (p17).
Informed: Informing the user is a requirement of most of the purposes of processing, not just consent, however the above requirement that consent be specific clearly means that valid consent is impossible unless appropriate information is provided. The information must be “clear and sufficiently conspicuous so that users cannot overlook it” (p35) and presented in a form appropriate to the context (dense legalese is unlikely to be considered clear). As with the UK Information Commissioner’s
Good Practice Guide on Privacy Notices
, layered notices are suggested for the on-line environment so the user can follow links to more detailed information if they wish. However there is a warning against burying significant features of the processing (for example that may involve disclosure to third parties, or take place overseas) in linked pages that the user can choose not to read (p23).
Unambiguous indication: the Opinion notes that the Directive allows consent to be expressed by “any” action, so long as there is no doubt that it indicates consent. The Working Party see this as allowing for many different approaches to provide user-friendly interfaces. Consent can, therefore, be inferred from a user’s action – such as requesting a particular service – so long as there is no doubt that the user understood and intended the consequences of that action (p21). Thus consent cannot be inferred from an action that might have been taken for another reason (such as entering the range of a Bluetooth transmitter with a device enabled to receive messages (p12)), nor can it be inferred from a failure to act (e.g. not responding to an e-mail warning that processing will take place unless you advise otherwise (p24) or failing to untick a checkbox on a web form (p24)).
Finally the Opinion warns against viewing consent as an easy option: “consent … does not relieve the data controller from his obligation to meet the other requirements of the data protection legal framework, for example, to comply with the principle of proportionality under Article 6.1(c), security of the processing ex Article 17, etc.” (p34), “and it does not legitimise processing that would otherwise be unfair according to Article 6 of the Directive” (p9). Consent remains an important part of data protection law, but it’s far from the whole story.
Originally posted: 11 July 2011 in category
Articles
On a privacy course I teach for system and network managers I suggest a scale of “privacy riskiness”, the idea there being that if you can achieve an objective using information from lower down the scale then you run less risk of upsetting your users and/or being challenged under privacy law. That scale is very much a rule of thumb, derived by a kind of reverse engineering from various bits of European and UK telecommunications law by assuming that the more conditions a law places on a particular type of information, the more privacy invasive it is.
A recent discussion on access management suggested that a similar rule of thumb for that application might be useful, so here it is, with very much the same caveat that it is derived by reverse engineering from multiple sources of varying authority. Those sources, and the reason I have interpreted them as I have, are in the notes below the table:
Type
Example
Notes
Legally
0
Attributes that do not identify a unique user
eduPersonScopedAffiliation
1
Non-Personal Data
1
Indirect identifiers designed for privacy
eduPersonTargetedID
1,2,3
Personal Data
2
Indirect identifiers not designed for privacy
IP Address
1,2,3
3
Direct identifiers
Name, Address
1,2
4
E-mail address & fax number
1,2,4
5
Location information
Mobile phone cell
1,5
6
Sensitive personal data
Health, race, religion, etc.
1
Sensitive Personal Data
Notes
1. The
European Data Protection Directive
(DPD) only defines personal data (classes 1-5, DPD Article 2) and sensitive personal data (class 6, Article 8); since it doesn’t mention non-personal data I have put that in class 0.
2. The
DPD
(Article 2) mentions both information that can itself identify an individual (classes 3&4, sometimes referred to as “direct identifiers”) and information that is unique to an individual but where additional information is required to actually identify the individual (classes 1&2, sometimes called “indirect identifiers”). The DPD doesn’t distinguish between those types, but the Article 29 Working Party’s
Opinion on the Concept of Personal Data
does, and suggests that in some cases (e.g. Example 17) indirect identifiers may represent less of a privacy risk than direct identifiers. Case law across Europe differs on whether IP addreses (the only indirect identifier to be mentioned in court cases, as far as I know) are personal data or not, but this does not affect their position in the riskiness scale.
3. The
Article 29 Working Party Opinion
also recognises the difference between indirect identifiers that deliberately make it hard to make the link (e.g. using “cryptographic, irreversible hashing”, p.20) and those that do not.
4. The
e-Privacy Directive
(Article 13) awards additional protection to e-mail and fax addresses by requiring that consent be obtained before these can be used for direct marketing; for postal addresses the law allows an opt-out regime where marketing can be sent until the recipient objects.
5. The
e-Privacy Directive
(Article 9) requires prior consent, and the ability to temporarily opt-out, of processing of location data. Since these requirements are specified in greater detail than for e-mail addresses, I have put them in a (slightly) more privacy-invasive class.
Originally posted: 11 July 2011 in category
Articles
Federated access management can make things nice and simple for both the user and the service they are accessing. By logging in to their home organisation the user can have that organisation release relevant information to the service – “I am a student”, “this is my e-mail address” and so on. And because that information comes from the organisation, the service is likely to consider it more reliable than information self-asserted by the individual user (especially if being a student entitles you to benefits such as site licences, reduced prices, etc.). Where all this gets a little tricky is explaining to the user – as both good privacy practice and European Data Protection law require – what information about them will be disclosed.
In the off-line world we are all too familiar with forms that seem to demand more information than is actually required (hotel checkin forms that demand an e-mail address are a particular bugbear of mine). In those cases I can simply ignore boxes that seem irrelevant – if the hotel wants to try to persuade me that providing an e-mail address will benefit me then they are welcome to do so. So I’ve been trying to work out what an equivalent interface for federated access management might look like. This, which may not look like any existing tool, is what I’ve come up with:
Clearly the appearance and wording could be made much better: what I’m trying to get my head around is the function. In the on-line world, as off-line, there is some information without which a service simply can’t operate. In the example above I have in mind an electronic journal that is licensed to all students and staff at a particular organisation: obviously if I am not willing to reveal my relationship with the organisation (“affiliation”) to the service provider then I can’t use the service and there’s no point in me trying to log in to it. I’ve taken the view that remembering history for individual users – what searches they have done, how far through a paper they have read, etc. – is a sufficiently key part of the service for an anonymous identifier distinguishing one user from another to be essential too, though it could be argued otherwise. However (as in my hotel example) the ability to e-mail the user updates about the service doesn’t seem like a core part of the service – some users will consider it useful, others a waste of time, some may wish to have the mails sent to a different e-mail address – so this seems like a disclosure of information that the user should have the ability to control. Even users who refuse to provide an e-mail address can still carry on and use the service: my suggested interface therefore provides a check-box to let them choose. Other additional attributes that the service could use but doesn’t depend on could, of course, be added in the same way.
The sets of essential and additional attributes won’t be the same for all types of service. For example authorisation for a particular research group’s collaboration tool may depend on my off-line identity so for these an organisation-verified identity (such as an e-mail address) will be essential while my affiliation is irrelevant.
This leaves the question of who decides which attributes are essential and which are additional. The service provider obviously has to announce which attributes their system can actually understand, but these may not all be essential to provide the service. Here the federated access management system is different to checking in at a hotel, because it is the organisational identity provider that releases information, not me as user. Rather than having every user try to work out which information is essential, possibly causing significant support load when they choose to release too little and the service breaks, it seems more efficient to have the organisational identity provider do that. Since releasing personal data carries some legal risk for the organisation, having the organisation make the decision also gives it the best chance of managing that risk to an acceptable level. Data Protection law sets different rules for essential and additional disclosures – the former are classed as necessary, the latter based on the user’s consent – so there are risks of challenge on both sides, either for forcing a user to “consent” to disclosure when they have no real choice or for disclosing more information than can be justified as “necessary”. Getting the interface right should help avoid those problems.
[UPDATE] The Article 29 Working Party’s new
Opinion on the Definition of Consent
has an example of just this kind of hybrid approach (though their example is quite a bit more complex than mine.
Originally posted: 30 June 2011 in category
Articles
Two recent news stories suggest that the importance of open Internet connectivity is gaining increasing international recognition.
The UN’s
Special Rapporteur on the promotion and protection of the right to freedom of opinion and expression
has published a report stressing the importance both of making internet infrastructure available to as much of the world’s population as possible, and of ensuring that the infrastructure has the least possible restrictions on what content can be accessed. He expresses concern about activities in a wide range of countries that involve “arbitrary blocking or filtering of content; criminalization of legitimate expression; imposition of intermediary liability; disconnecting users from Internet access, including on the basis of intellectual property rights law; cyberattacks; and inadequate protection of the right to privacy and data protection”. Some types of content are recognised as representing such a serious infringement of others’ human rights that statutory restrictions may be necessary, including “child pornography…, hate speech…, defamation…, direct and public incitement to commit genocide… and advocacy of national, racial or religious hatred…”, but even for these there is a preference for dealing with the problem at the edge of the network where perpetrators and victims are located, rather than in the network core. He also suggests that the nature of the Internet may mean that lighter touch regulation is needed than for traditional media.
And
according to the BBC
the Netherlands seems likely to become the second country in the world (after Chile) to use legislation to prevent commercial discrimination being applied to internet connectivity. It is reported that a new bill will prohibit mobile network operators from blocking or charging extra for the ability to make internet telephony calls. In the past the European Commission has
expressed concern about such activities
, but had proposed to see whether market forces would be sufficient to discourage it. It seems that the Dutch Parliament has decided that this is not enough.
Originally posted: 20 June 2011 in category
Articles
Questions about my
last posting on Nominet’s DNS domain suspension discussions
, have got me thinking a bit more about my idea of “domains registered for a criminal purpose”. My suggestion is that these should be the only domains that a top-level registry can remove on its own, rather than asking for the decision to be taken by an independent authority. I’m worried that if a domain was registered for a genuine purpose and has later become involved in a crime (for example because the server has been compromised) then removing the domain to stop the crime will also damage – perhaps seriously if it is the website of an on-line business – the innocent person or organisation using it for the original, genuine, purpose. The registry doesn’t seem to me the right organisation to assess those risks. This seems very different from removing a domain that has no purpose other than to assist in the commission of a crime, where there should be no risk of harming innocent individuals. Furthermore, if the domain appears to have been registered with a criminal purpose it seems unlikely that contacting the registrant will be effective in stopping the crime! So there may even be an opportunity to speed up the removal process.
This requires a different test from those applied in some registries’ rules, which allow domains to be removed if the domain name itself breaks the law. For example
Nominet’s Dispute Resolution Service
may remove a domain name that contains someone else’s trademark. While a domain that emulated the name of a bank and was being used for phishing might well satisfy my “criminal purpose” test, I would also include the domains consisting of random sequences of characters that are used by some malware (the best known is probably
Conficker
) to establish their command and control channels. Here the domain name itself may be legally unobjectionable (if puzzling!), but the fact that it is coded into the malware suggests that it was only generated for that criminal purpose. Another example might be a domain that did consist of words, was involved in criminal activity, and had been paid for with a stolen credit card: the first two conditions could indicate either malicious or genuine registration, but the means of payment suggests that this is not an innocent domain that is now being misused.
[UPDATE: I’ve just discovered another simple algorithm for distinguishing “malicious registrations” in the
latest report from the Anti-Phishing Working Group
– if the criminal activity is reported very soon after the domain is registered. They also confirm my suspicion that the “trademark” test isn’t sufficient to pick up these registrations, less than a third of their malicious registrations include a string related to the target bank that would be likely to fall foul of the “illegal domain” rule]
This might suggest that I am thinking along slightly different lines to
SWITCH’s malware clean up activities
for websites in their .ch and .li domains, since they are specifically looking for compromised servers (i.e. the ones I am trying to exclude by my “criminal purpose registration” test). However I think the two approaches are consistent, as SWITCH do attempt first to contact the registrant and give them a grace period before stopping resolution of the domain. Also, their suspension of resolution is temporary: the domain will start working again after five days, with no change in “ownership”, unless a longer duration is authorised by an independent authority. Perhaps a “criminal purpose registration” test would allow those domains to be removed even more promptly?
There is evidence that concerted campaigns against phishing can be effective – the .hk domain used to be one of the most commonly used but is no longer in the top 10. However Government policies can also have unintended effects, for example one country that requires any recipient of public funds to have a website now has a high proportion of compromised servers hosting phishing campaigns.
Trends are a better measure than single statistics since a single phishing campaign (or the compromise of a registrar) can generate sufficient fake registrations to significantly alter a country’s registration figures. For example trends indicate that action to take down or block phishing domains has had the effect of making criminals change their tactics: free hosting sites used to be popular locations for phishing pages but as these got better at handling notifications the pages moved instead to cheap hosting sites, paid for with stolen credit cards, or compromised hosts. As browsers get better blocking tools, victims are increasingly asked to e-mail or phone their card details or even to upload forms to document sharing or survey systems.
In many ways phishing is showing the same trends as other types of eCrime, so APWG are investigating a more general classification of threats that countries or networks can use to benchmark themselves against aggregated global or regional statistics.
I’ve just submitted a JANET(UK)
response to the Ministry of Justice’s consultation on draft Defamation Bill
. In fact my comments don’t relate to the current draft Bill, but to a longer-term part of the consultation paper (pp 40-47) on whether any changes are needed to the law of liability for Internet intermediaries.
At the moment there are three models of liability, used by both
UK
and
EU
law for defamation, copyright and most other types of liability:
Mere Conduit: Not liable for third-party content they transmit;
Hosting/Caching: Not liable for third-party content they unknowingly host/cache, but potentially liable once they know of an alleged infringement either by being notified or by other means;
Author/Editor: Liable for content they write or third-party content they edit.
Author/Editor is the traditional way that publications are regulated in the off-line world; Hosting/Caching was applied to web hosts and caches by the European
e-Commerce Directive
but is similar to how bookshops and newsagents are treated off-line; Mere Conduit was copied from telephone networks to Internet carriers by the same Directive.
The Law Commission spotted a
problem with the Hosting/Caching model
in 2002: when a web host is notified of allegedly infringing material they have a choice between leaving it untouched (and possibly being found liable in a later court case) and removing it (and being sure they have no liability). Not surprisingly, many hosts therefore remove material as soon as they receive a complaint, whether or not the complaint is justified (see, for example, the
experiments by the Dutch civil rights organisation, Bits of Freedom
). The Law Commission considered that “there is a strong case for reviewing the way that defamation law impacts on internet service providers”, but so far the law remains unchanged. Universities and colleges have an additional challenge, since the law also requires them to “take such steps as are reasonably practicable to ensure that freedom of speech within the law is secured for members, students and employees of the establishment and for visiting speakers” (
Education No.2 Act 1986, s.43
). Unlike commercial hosting providers, they therefore do have to balance two legal requirements, with risks of liabilities on both sides.
More recently, problems have also emerged with the dividing lines between the three classes. A European case has commented that the knowledge required for a web host to acquire liability could be gained through the host’s own “voluntary research” (para 164 of the
Advocate General’s Opinon in L’Oreal v Ebay
), thus seeming to discourage web sites from proactively checking third party submissions for any infringement. A UK case has indicated that a blog host who corrects the punctuation of a third party comment might thereby convert themselves from a Host to an Editor (
Kaschke v Gray & Hilton
[2010] EWHC 690 (QB)
). And there has always been a slight worry over how much filtering or editing of content a network could do without being found to “select or modify the information contained in the transmission” (
e-Commerce Directive
Article 12(1)(c)) and thereby lose its Mere Conduit status.
One possibility being explored by the Ministry of Justice is a revised categorisation used in a Private Member’s Bill by Lord Lester last summer (included as Annex C in the consultation document). The same system of liabilities would apply, but with the classes defined by the degree of control/responsibility, rather than by technical implementation:
Facilitator “a person who is concerned only with the transmission or storage of the content of the publication and has no other influence or control over it” (presumably this would include both transmission networks and neutral web hosts): Not liable for third party content they transmit/store;
Others (anyone who is neither a Primary Publisher nor Facilitator, so possibly including blog hosts in relation to third party comment): Not liable until they receive a written (which includes e-mail!) notice in a prescribed form, then potentially liable;
Primary Publisher “an author, an editor or a person who exercises effective control of an author or editor” (editor is further defined as “a person with editorial or equivalent responsibility for the content of the publication or the decision to publish it”): Liable for third party content they publish.
Provided these definitions do indeed have the effect I’ve suggested, this does seem to clarify the definitional problems and to remove the current incentives against filtering or inspecting. Anyone in the second class is still likely to respond to a notice by removing content irrespective of the merits of the complaint, but if web hosts are considered as (mere) facilitators then the Law Commission’s concerns will have been addressed to some extent.
It’ll be interesting to see what develops from this consultation, in particular whether similar ideas arise in European discussions and in other types of liability (particularly copyright).
#48 - Data Protection: “recognition” or “identification”?
Originally posted: 31 May 2011 in category
Articles
Many of the problems in applying European Data Protection Law on-line arise from
uncertainty
over whether the law covers labels that allow an individual to be recognised (i.e. “same person as last time”) but not – unless you are the issuer of the label – identified (i.e. “Andrew again”). The Article 29 Working Party have recently been considering one particular label, RFID tags, and conclude that recognition is sufficient (Opinions
5/2010
and
9/2011
). However they seem not to have spotted the problem that this creates for international transfers.
Each RFID tag contains a unique number that can be read at a distance by a suitable radio transmitter/receiver. Attached to items in a shop they can be used for all kinds of stock control and inventory purposes; however the Working Party’s main concern is what happens to them when they leave the shop. If a tag attached to a garment is not de-activated then it could be used to recognise the person wearing it, since the person will now be attached to the RFID tag number. However without access to the shop’s purchase records, the number alone cannot be used to identify that person whether by name, address or even credit card number. The release of the information linking purchase to purchaser is, of course, covered by data protection law. However the Working Party have concluded that merely allowing someone to leave the shop with an active RFID tag must also be subject to data protection law since the built-in identifier might allow a third party to (illegally) recognise and track the wearer. The Working Party’s opinion is therefore that the shop must assess the risk to privacy and only leave tags active if that risk is sufficiently low.
A risk-based approach fits with the law’s requirements on protecting personal data from unauthorised processing within Europe. However the law on exporting personal data from Europe seems to be absolute, not risk-based. Article 25 of the
Data Protection Directive
says: “Where the Commission finds … that a third country does not ensure an adequate level of protection …, Member States shall take the measures necessary to prevent any transfer of data of the same type to the third country in question” (my emphasis). Indeed the UK Information Commissioner’s tentative steps to allowing data exporters to do their own risk-based assessments of adequacy appear to be one of the things causing concern over
whether the UK has actually implemented EU law correctly
. I can’t imagine that the Working Party intend shops to ask their customers whether they will be wearing their new clothes to the USA, but this seems to be the result under current law!
RFID tags may not seem terribly relevant to networks, but they have very similar privacy characteristics to the IP addresses of laptops and PDAs. Hence my continuing requests to the Commission and the UK Government to
fix this bug in the law
.
Originally posted: 12 May 2011 in category
Articles
The Information Commissioner has published his
guidance on complying with new European cookie law
, and the news is less good than had been hoped. Although the simplest way for a website to obtain users’ consent to installing cookies would be to rely on them having set appropriate cookie preferences in their browsers – indeed the European Directive specifically mentions this possibility – the view now seems to be that
browser preference controls
will remain inadequate for some time. This, and the need to support users of older browsers, means that websites will need to obtain some sort of consent themselves. The ICO is, at least, resisting the temptation to unleash a user-unfriendly flood of pop-ups: this leads him (reluctantly, I suspect) to suggest that a user who knows what cookies a site uses and continues to use it has, indeed, given their consent. How much value can be placed on such consent if the user has no choice but to use the site is not clear to me!
The guidance provides a helpful categorisation of cookies, with suggestions of how information about them might be provided:
Cookies that are strictly necessary to provide services explicitly requested by the user (e.g. shopping carts): For these there is no change in law. However this class is narrowly interpreted so, for example, shopping cart cookies are included but those to remember user preferences or analyse website usage are not (see below for these).
Cookies that are not strictly necessary for a user-requested service: Some websites will be able to gather information about all cookies they use and place it on the page where users sign up to the website (for example as part of the Terms and Conditions). However this means that any subsequent change to cookie use will need to be reflected in changed Terms and Conditions, and the Information Commissioner’s view is that websites would then be required obtain positive acknowledgement from all users of the change: merely changing the on-line version of the Terms would not be sufficient.
Of course, not all websites have a sign-up page. The others (and even those that do, if they consider the process for updating Terms and Conditions to be too onerous) are likely to have to deal with each type of cookie in a different way:
Cookies storing a setting requested by the user (e.g. personalisation): for these the user can be informed about the cookie on the page where they select a particular setting.
Cookies implementing a feature requested by the user (e.g. remember my details): for these the user can be informed about the cookie on the page where they request the feature.
Cookies implementing a background function (e.g. analytics): if there is no sign-up page that all users have to see (as above), then the advice is that information about these should be made more prominent, for example by “some text in the footer or header of the web page which is highlighted or which turns into a scrolling piece of text when you want to set a cookie on the user’s device”. This can direct the user to further information about the cookie(s), for example on the website’s privacy page. This might include a list of cookies and their function.
Third-Party Cookies (e.g. advertising): the advice regards these as the most challenging, because of the involvement of multiple parties. The website operator must ensure that users are informed that their information will be passed to third parties and that they can obtain the necessary information about how it will be used; all parties should follow industry standards (presumably including the proposed
IAB Code
and
AdChoices system
) as these develop to comply with the new law.
The Guidance notes that different cookies represent different levels of intrusion into privacy: a cookie selecting a preferred language for a website would be considered less intrusive than one that gathered an individual’s entire browsing history. As with other data protection requirements, more information needs to be provided the more intrusive a cookie is.
Finally, although the law is still expected to come into force on May 26th (at the time of writing it doesn’t seem to be on the
draft legislation website
), the Government is planning a “phased implementation” of the changes. This seems to mean that there will be a period when the Information Commissioner will not use his full enforcement powers against organisations that can demonstrate that they are working towards compliance. The ICO’s recommended course of action is therefore:
Check what type of cookies and similar technologies you use and how you use them (possibly including “cleaning-up” any unnecessary cookies);
Assess how intrusive your use of cookies is;
Decide what solution to obtain consent will be best in your circumstances (starting with the most intrusive cookies)
Originally posted: 30 April 2011 in category
Articles
Matt Cook’s talk at
Networkshop
explained Loughborough University’s thinking on how virtualisation might be used to provide both resilience and flexibility by allowing services to be moved between different locations in both internal and external clouds.
Rather than virtualising a single server, this involves creating a virtual container holding the various components required to deliver a particular service. For example a virtualised VLE container would also need to include the underlying database, a DNS resolver giving a consistent view of the world (especially if DNS views differ for ‘internal’ and ‘external’ requests), a mirrored copy of at least relevant parts of the authentication/authorisation system, and a network firewall. Such a container can then be moved relatively easily between data centre hosts, whether in response to load, system faults or simply changes in contracts.
Such flexibility does, however, create significant demands on Internet routing to ensure that the container can be ‘found’ wherever on the network it happens to be (re-)located and, indeed, no matter whether the user is connected to the campus network, elsewhere on JANET, or elsewhere on the Internet. Although this should, in theory, be possible using IPv4 addressing, the near-exhaustion of that address space means it may be hard to find enough contiguous public addresses. Loughborough are therefore planning an initial trial of this approach using IPv6, where it will be much easier to obtain the required addresses while preserving a hierarchical allocation of address blocks (and therefore simple routing tables). Matt also observed that moving a major service such as a VLE, document store or e-mail to a different network location can have significant effects on traffic flows. For example moving e-mail from on-site to off-site added 20-40Mbps to the traffic on Loughborough’s JANET link: organisations need to include this effect and any impact on network components in their out/in-sourcing plans.
Originally posted: 29 April 2011 in category
Articles
A
press release
from the Department for Culture, Media and Sport confirms that the Government is looking to browser manufacturers to provide the main approach to implementing
new European laws on cookies
. However the release also confirms that current tools for managing cookies in browsers are not considered sufficient to obtain the consent that will now be required from users before a cookie is stored on their computer: better information and management options are required.
A “working group with industry” (it’s not clear which industries, though the Internet Advertising Bureau has recently released its own
proposals
) and the Information Commissioner will also be providing guidance on complying with the law.
#44 - .ch and .li domains promoting malware clean-up
Originally posted: 20 April 2011 in category
Articles
An interesting news item from SWITCH, the Swiss NREN and also operator of the .ch and .li TLD registries, on how they are
alerting website owners to malware
and, if necessary, taking action to protect customers from being infected.
Swiss law allows the registry to suspend a domain for five days, or longer if the need to do so is confirmed by the national information assurance reporting centre. A few months ago, SWITCH began scanning websites within their domains to determine if they had been infected by malware (malicious code that can be downloaded to a PC along with the rest of the content of a website) and informing the site owners if problems were identified. If the site owner does not respond within one working day then the domain is temporarily suspended so browsers attempting to visit it get an error page instead. The domain is restored as soon as the owner confirms that it has been cleaned or after five days if the reporting centre does not authorise a longer period. Even if the website is not disinfected, the five day suspension should allow time for users to (auto-)install updates to anti-virus and web browser blocklists to protect themselves.
The process resulted in the prompt removal of 88% of the website infections discovered.
Originally posted: 31 March 2011 in category
Articles
The
Internet Watch Foundation (IWF)
published its
annual report
yesterday, including information on the use of the Internet to distribute indecent images of children. There is quite a lot of good news to report. These images remain a very small fraction of Internet content – fewer than 9000 dealt with all year and only around 500 URLs active at any one time – and the IWF’s work with the UK Internet industry means that under 0.5% of these were hosted in the UK, all of which were removed within a day of discovery.
However it is also clear that the market for such images is increasingly commercial and is using tactics common to other types of on-line criminality such as moving content rapidly between hosting services and compromised computers. The IWF is therefore planning to increase its work with international partners and law enforcement so they can benefit from the UK’s knowledge and experience. Removing these images at source and dealing with those who create and publish them is the best way to keep the Internet safe for all of us.
JANET(UK) is a funding member of the IWF and I’m currently chair of the IWF Funding Council.
#42 - Domain suspension – when might it be justified?
Originally posted: 21 March 2011 in category
Articles
Nominet have published an
issues paper
asking whether there are circumstances in which it might be appropriate to rapidly suspend a DNS domain involved in criminal activity, and the processes that would be needed to ensure such action did not create too great a risk of unfairness. I’m writing this in an attempt to sort out my own ideas, so this is very much “thinking out loud” and the conclusions are liable to change whenever I’m presented with new evidence or a better argument. For now, I’m thinking very much from first principles to work out if and when it might be appropriate to invoke an expedited domain suspension process rather than using the processes that already exist.
The issue appears to have arisen because a number of different criminal activities are now using DNS to dynamically move cybercrime around – whether phishing for bank credentials or controlling botnets – making it very difficult to identify the computers involved to gather evidence or prevent the crimes. In these cases, DNS domains may be the only fixed points where the activity can be disrupted.
However removing a domain that is currently in use is clearly a serious action, since it may have significant and unpredictable consequences. The processes that already exist in the law and some Registry agreements therefore include a number of safeguards to ensure, so far as possible, that suspension is justified and does not have disproportionate side-effects. The only reason for creating a new, expedited, process to supplement those would therefore seem to be if the existing processes are too slow and the harm likely to occur when following them justifies the increased risk of side-effects.
Conclusion 1: an expedited process should only be used if serious harm is likely to occur during the time taken to operate the applicable existing process.
A common threshold for whether “serious harm” might occur from an activity is whether that activity is classed as a crime.
Conclusion 2: an expedited process should only be used when a domain is involved in the commission of a crime (in fact I’m tempted to set the threshold at “serious crime”).
In most cases the quickest way to deal with a problem on a domain will be for the registrar to contact the domain owner. This also seems inherently fairer than taking a domain away without warning. Of course this will not work if the domain owner is part of the criminal enterprise, so
Conclusion 3: an expedited process should only be used when there is evidence that the domain was registered for the criminal purpose (i.e. not where a legitimately-registered domain has subsequently been taken over for criminal use).
If any of those three conditions are not met, suspension should only be done using one of the existing processes, allowing a more detailed examination of the threat posed by the current use, the consequencs of removing the domain, and any alternative actions that may be possible.
As to how the expedited process should work, it seems reasonable to aim for it to have the same long-term result as the non-expedited process, both in terms of the outcome for the domain and in terms of what information flows where. The expedited process may change the order in which information is passed and actions taken, but it shouldn’t result in anything occuring in secret that would otherwise be open. In particular:
Conclusion 4: the registrant who owns the domain, and anyone else affected by the suspension, should receive the same information and have the same opportunities to have their case heard as they would have in the non-expedited process. If it turns out that the non-expedited process would have resulted in the domain not being suspended, the domain must be restored as soon and as completely as possible.
Finally, any process is likely to be attacked by those who would like to achieve its outcome. Why bother going to the effort of a denial of service attack against a domain if you can deceive a registrar into suspending it instead? The police and ISP industry have already addressed this problem for other expedited processes, so the same safeguards should be applied in this case, in particular
Conclusion 5: notices invoking expedited suspension must be sent between known points of contact who are able to identify each other, both of whom have been trained in the proper operation of the process.
That seems to be where my first principles approach leads me – any comments, evidence I haven’t thought of, or other arguments?
#41 - Parliamentary Enquiry into the Protection of Intellectual Property On-line
Originally posted: 17 March 2011 in category
Closed
Parliament’s Culture, Media and Sport Select Committee is carrying out an
enquiry into the Protection of Intellectual Property Rights Online
and, in particular, the effectiveness and proportionality of the
Digital Economy Act 2010
. Since the Act isn’t yet in operation – we are still awaiting the publication of the Implementation Code by Ofcom – it’s rather hard to comment on effectiveness. However I’ve submitted a
JANET response
that re-states our concerns about the likely consequences of the Act and the continuing uncertainty over its definitions.
I’ve again pointed out that a wide interpretation of “subscriber”, which appears to be
favoured by Ofcom
, could damage universities’ and colleges’ current effective processes for reducing infringement, as well as reducing the availability of Internet access in places such as cafes and libraries. The Committee specifically ask about the possible imposition of technical measures against infringement, so I have pointed out the disproportionate effect of these on others who share the connection used for the alleged infringement, and the likelihood that these powers will create an incentive for the widespread use of technologies to evade monitoring and blocking, thus exposing users to considerably greater hazards than copyright infringement.
The Committee was originally scheduled to take evidence in January, but this has been postponed to await the outcome of the
Judicial Review
of the legality of the Act.
[UPDATE (17th March): the evidence gathering has now been further postponed till 6th May, even though the Judicial Review hearings are scheduled for next week 22nd-24th March]
Originally posted: 14 March 2011 in category
Articles
The Information Commissioner managed to greatly raise the profile of the new EU law on cookies last week, warning in a
press release
that “UK businesses must wake-up” to the forthcoming change. However this alarm bell seems to be a bit early, as the Government
admitted
that although it does expect to meet the deadline of May 25th for transposing the European Directive into UK law (possibly simply copying the text of the Directive), it will take longer than that to produce guidance available on what businesses actually need to do to comply with it.
The problem is that the Directive requires users to give “consent” before any cookies are placed on their computers, but it has never been clear
how this consent should be expressed
. When the Directive was passed, some commentators considered that an explicit prompt would need to be given to each user, for example through a pop-up or landing page, whereas others thought that it was sufficient to check whether existing browser preferences permitted the cookie to be loaded. Last week’s
press release
only mentions the latter, “browser-settings” approach, which was also the preferred option in last year’s
Government consultation on implementing the Directive
(see page 57 of the consultation paper). That consultation also distinguished cookies that were “strictly necessary to deliver a service which has been explicitly requested by the user”, while also commenting that more information should be provided on how cookies are used.
Until the UK legislation is published and passed, and guidance on implementing it provided, it seems the best thing organisations can do is review what cookies their websites generate (including any third party links or cookies) and consider documenting what benefits they deliver.
[UPDATE]
Out-law
reports that the Government is indeed “working with browser manufacturers” on a solution
[UPDATE]
Jon Warbrick
has drawn my attention to a
spoof website
set up to show what the world might look like under an extreme interpretation of this law (it’ll only work if you enable scripts…)
Originally posted: 1 February 2011 in category
Articles
The Department for Culture, Media and Sport has today announced that Ofcom will be asked to
review the practicality
of the provisions in
section 17
of the Digital Economy Act 2010 that might in future allow courts to order blocking of infringing sites.
that such blocks were unlikely to be effective, and
that blocking sites that people want to access would promote the adoption of technologies to evade blocks, thereby exposing users and their computers to harmful material that neither they nor their computers wanted to see.
I’ll be keeping an eye out for opportunities to make those comments again in this new review.
JANET’s evidence
focussed on the difficulties of applying data protection law to the Internet: the current law has proved unclear on the status of IP addresses and similar pseudonymous identifiers, and contains a stark geographic distinction between Europe and America that the Internet (and individuals’ use of it) simply does not recognise.
It was therefore a little worrying that only “a small number of respondents” had mentioned these issues. Fortunately one of the others who did was the Information Commissioner, whose representative identified technology, pervasive computing and globalisation as key changes in society that require an updating of data protection law. He called for new legislation to be clear for both organisations and individuals, to provide a high level of protection without complexity, and therefore to be based on actual risks to individual, rather than the current system that often prefers absolute rules.
Both he and the speaker from the European Parliament identified difficulties that were likely to affect progress at European level: a tension between the desire to provide the strongest possible protection for users and not making it impossibly complex to provide services that those users want to use (the Directive is actually supposed to promote a free market in innovative services but is often, and sometimes accurately, portrayed as preventing that); a tension between a desire for complete uniformity of law (as
proposed by the European Data Protection Supervisor
) versus a harmonised approach that still permits differences of national culture; and the temptation to rely entirely on users making appropriate choices (“consent”) even under pressure from services that want to collect more information than is necessary. The Lisbon Treaty creates a challenging starting point for these discussions by requiring a single privacy framework to cover both economic and security issues. Previously these were handled by different European bodies that, on occasion, have reached very different conclusions on balance of rights and proportionality.
All the speakers seemed to recognise the importance of getting new legislation right and to be open to assistance in doing so, so there is plenty of work still to do.
Originally posted: 21 January 2011 in category
Articles
The Department for Business, Innovation and Skills has published the first draft Statutory Instrument (SI) required for the implementation of the Digital Economy Act’s copyright enforcement process. The
Online Infringement of Copyright (Initial Obligations)(Sharing of Costs) Order
is is the SI that covers sharing of costs betwen rightsholders and ISPs: as suggested in last summer’s
cost sharing consultation
rightsholders will have to pay 75% of costs incurred by both ISPs and Ofcom, with ISPs meeting the remaining 25% of both.
There is still no sign of the SI that will contain the initial obligations code specifying the duties of Qualifying ISPs (and possibly identifying which networks will initially fall within that category), or any response to the
consultation on the draft code
that closed last July.
UPDATE: I hadn’t spotted that the text of the instrument doesn’t address the problem I pointed out in our
original consultation response
to Q7, that it gives rightsholders an incentive to under-estimate the number of reports they expect to send. Thanks to
Francis Davey
, who did spot it, and also considers that making ISPs pay part of the enforcement costs may be unlawful under the European Authorisation Directive (which limits the requirements that Governments can place on those wishing to provide communications services).
Originally posted: 29 November 2010 in category
Closed
The European Commission have recently published a more detailed
action plan
to support their
draft Internal Security Strategy
from earlier this year (that’s “internal” as in “within the continent”, by the way!). Most of the strategy covers physical security, including natural and man-made disasters, but one of the five strategic objectives is to “Raise levels of security for citizens and businesses in cyberspace”. Having given
evidence on CSIRTs
to the House of Lords sub-committee last year, I’ve been
asked
for
JANET’s comments
on this new paper as well.
Each of the three Actions for cyberspace on pages 9 and 10 recommends both improvements in provision within countries and the creation of a pan-European body. In each case we’ve suggested that the role of the pan-European body should be to identify and promote best practice and help countries implement it locally, rather than involving itself in individual operations.
Thus on dealing with cyber-attacks it’s good to see more encouragement for filling in the gaps in CSIRT coverage but the proposed European Information Sharing and Alert System (
EISAS
) should help countries to create national resources like
GetSafeOnline
, rather than trying to create a single poly-lingual site for all EU citizens. On empowering citizens there are recommendations to create somewhere that users can report incidents and receive guidance on threats and precautions. Again, language issues indicate that this is better done at national, rather than central level. On improving law enforcement and judicial capability there is a proposal to create a central cybercrime centre, which appears again to be a faciliator for the development of coordinated national operational expertise, though others appear to be interpreting it as having a
more operational role
. Having briefly been responsible for a pan-European CSIRT a long time ago my feeling is that centralising operational activities at that level is likely to be more trouble than it is worth.
[UPDATE] the full
list of written responses
has now been published. Note that they cover a wide range of areas (not just cybercrime) and a very wide range of opinions! Transcripts of oral evidence sessions and the Committee’s final report are also available from the
committee inquiry page
.
Originally posted: 16 November 2010 in category
Consultations
The Home Office have concluded that a couple of aspects of the Regulation of Investigatory Powers Act 2000 need to be fixed in order to comply with European law, and are doing a rapid consultation on the changes. Unfortunately although the
consultation document
is clear about what the problems are it doesn’t give a clear idea (ideally, the proposed revised text) of how they propose to fix them.
Since the “obvious” amendments could actually have serious unintended consequences for network operations and service development, I’ve sent a
JANET response
pointing out the potential problems and asking for more clarity on whether the changes actually suffer from these problems:
Change 1: EC law requires a prohibition on “unintentional interception”, as well as intentional. At the moment
section 1(1) of the UK Act
appears to require two “intentional” steps – that the person intended to do what they did, and that they intended it to have the effect of making content of communications available. As far as I can see, removing either of those intentions could bring a whole host of legitimate and careless activities into scope, for example turning on a wifi laptop in an area where there’s an unencrypted network (intentional act with unintended consequences), or using a device whose software continues to use IP an address after its DHCP lease expires (
iPads
are the most recent of these). There’s also a problem of whether a mistake in implementing what would otherwise be a lawful interception makes it unlawful. The consultation document states that mistakes in implementing an interception warrant would not be unlawful but does not give an explicit assurance for other types of lawful interception (e.g. those required for the operation of a network service).
Change 2: At the moment it’s lawful under
section 3(1) of RIPA
to intercept traffic if you have reason to believe that both the sender and recipient have consented to this. The proposal is to change that to require that both parties actually have consented, so if one user passes the keyboard to someone else then the interceptor is immediately breaking the law. This wouldn’t have a big effect for our current services, since none of those rely on this “dual-consent” provision, but it might stop us or others developing services that are based on the privacy-correct approach of actually asking users for permission!
The consultation also suggests that these new rules would be enforced by the Interception of Communications Commissioner, who currently
oversees
the use of interception warrants and data access powers by public authorities. I’ve suggested that if, as seems likely, most of the breaches will actually be failures of other kinds of privacy controls then the Information Commissioner (who will
soon
have a statutory right to hear about privacy breaches by network providers) is a more appropriate regulator.
It seems that respondents agreed that “traffic management is a necessary and essential part of the operation of an efficient internet” and that its use to address security and congestion issues is entirely legitimate. However there appears to be more concern about the use of traffic management to discriminate between services, for example allowing content providers to pay for priority access to customers, where concerns are expressed both about competition and the potential loss of the Internet’s power to support novel applications. Although respondents seem divided on whether transparency about these practices and the resulting customer choice will be sufficient to ensure that they do not become a problem, there is agreement that new legislation is not required at present, particularly as the new European Telecoms Directives are still being implemented by member states. There is an irony that blocking of peer-to-peer protocols is viewed as harming the development of content services when that blocking may well be prompted by action by Governments on copyright enforcement intended to protect the same content industry!
As this example shows, it may not even be clear what operational and regulatory practices will be in the interests of a single industry so the problem of working out the best approach to the Internet as a whole is even more complex. According to its
press release
the Commission expects to present a formal report, based on this consultation and other discussions, to the European Parliament.
Originally posted: 26 October 2010 in category
Closed
Earlier this year the European Community revised its regulatory framework for telecommunications networks, so the UK Government is now
consulting
on how to implement those changes in UK law. Although most of the changes are not relevant to JANET as a private network, I have
responded
in three areas:
Data breach notification, where the UK seems to be treating notification as a punishment – something I’ve
considered for a while
would set up a very unhelpful incentive to conceal problems rather than help people recover from them;
Cookies, where the UK seem to have come up with a pragmatic interpretation of what appears to be
at best confusing and at worst unenforcible European drafting
. Rather than websites having to seek explicit prior consent for all cookies, as some have interpreted the EC wording, the UK is now proposing that provided users are informed about the need to set cookie preferences, and enabled to do so, then sites can assume that if a user’s browser will accept a cookie then the consent requirement of EC law will be satisfied;
Spam, where the UK Government don’t seem to have noticed that the EC have fixed an eight year old loophole that makes legal protection against spam less effective than it could be. This change is particularly important for universities, colleges and other organisations where a large number of users share a single internet connection. I’ve been pointing out the problem to BIS and its predecessor departments for years so have now encouraged them to make the same correction to UK law.
Originally posted: 8 October 2010 in category
Closed
The Ministry of Justice has been
seeking evidence
to inform its input into the ongoing
revision
of the European Data Protection Directive (95/46/EC). I’ve submitted a
JANET response
, covering three issues where we frequently trip over problems with either the interpretation or the use of the current Directive and the Data Protection Act 1998 that implements it in the UK: the status of IP addresses and other indirectly-linked identifiers, the use of consent as a justification for processing, and the proposed requirement to notify a regulator of security breaches affecting personal data.
The biggest problem for applying data protection law to the Internet is that the law has no appropriate mechanism for dealing with IP addresses and similar identifiers. The organisation or ISP that assigns an IP address to a computer will usually know the identity of the person responsible for it, so there should be little doubt that the address is personal data in the hands of that organisation. However many other organisations will receive and process the address as it is used to navigate around the Internet: many of them will not be able to link the address to a person and
the law is very unclear
whether these are required to treat it as personal data or not. Indeed there is a growing number of court decisions that are simply
contradictory
on this question. The problem is that both answers “yes” and “no” are unworkable – if an IP address is personal data then the law requires that the owner must be notified by all organisations using it and be able to demand full details from them of what is done with it; the originating organisation must also have a contract covering any transfer of the information outside Europe: a requirement that I suspect the Internet breaks billions of times a day! If, on the other hand, IP addresses are not personal data then there is no restriction on what networks and servers can do to gather information about each others’ users or invade their privacy. Our main recommendation, therefore, is to introduce a third category of regulation for indirectly-linked information, where all the requirements are based on the actual level of risk to privacy. This should improve privacy protection both by creating an incentive to use privacy-protecting tools such as pseudonymous identifiers (thereby reducing the regulatory burden), and by making clear that there is still some privacy requirement on information that may previously have been treated as non-personal (and therefore unprotected) because that was the only practical option.
Any new legislative framework should continue to apply to both direct and indirect forms of identification. However, there is evidence of considerable uncertainty in the practical application of the current law to information that identifies people indirectly. … A new Directive should open the way for a more realistic treatment of this sort of information. For example, it might require the security principle to apply to all forms of personal data, but acknowledge the practical difficulty involved in obtaining consent for the processing of, or the granting of subject access to, some information that indentifies individuals indirectly. A simple ‘all or nothing’ approach to data protection requirements no longer suffices, given the variety of information that can now fall within the definition of personal data. The requirements should be more clearly linked to the risk to individual privacy.
(page 3, though the whole paper is well worth reading).
The other concerns relate to areas where data protection law may, perversely, be acting in a way that reduces, rather than improves, privacy. The law allows personal information to be processed on the basis that the owner has given their consent, however this justification seems to be used in many situations where it is not appropriate, either for the individual or the service collecting the information. Unlike other justifications based on necessity (for example to deliver a service or comply with a legal duty), the law entitles users to withdraw consent at any time and without reason. It is therefore unlikely to provide a stable basis for a service. It appears, however, that consent may often be claimed as a carte blanche for any collection or use of personal information, thus avoiding the question of whether it is actually necessary. Although the Information Commissioner recommended some time ago that consent be used only as a last resort, it seems that clearer encouragement on this may be needed.
UPDATE: or, as the Information Commissioner’s response puts it on page 32:
a particular consent may not be adequate to satisfy the condition for processing (especially if the individual might have had no real choice about giving it), and even a valid consent may be withdrawn in some circumstances. For these reasons an organisation should not rely exclusively on consent to legitimise its processing. In our view it is better to concentrate on making sure that you treat individuals fairly rather than on obtaining consent in isolation. Consent is the first in the list of conditions for processing set out in the Act, but each condition provides an equally valid basis for processing personal data.
Finally, the consultation seeks views on the introduction of mandatory reporting of security breaches that affect personal data. As I’ve
discussed previously
, this could be a good idea if it allowed those affected to protect themselves, or encouraged organisations to learn from their, and each others’, mistakes. However public notification has also been suggested as a way to shame organisations into improving their practices, which seems more likely to make them hide problems, possibly even encouraging customers to move from organisations that try to do the right thing to those that ignore the law.
#31 - Personal Data – yet another contradictory decision
Originally posted: 24 September 2010 in category
Articles
For a while there has been one pair of contradictory answers to the question of whether an IP address was personal data. Two different German courts were asked about addresses in the log of a web server: one said that was personal data, the other said it wasn’t.
Now we seem to have another pair. A few months ago a court in Ireland was asked to rule on whether an agency was processing personal data when it examined traffic on a network, identified copyrighted files and reported them, with the originating IP address, to the relevant ISP. The Irish court said that it wasn’t (case:
EMI Records & Others -v- Eircom Ltd [2010] IEHC 108
). Now a Swiss court has been asked the same question and has decided, on the contrary, that the agency is processing personal data, that it has no legal grounds for doing so and must therefore stop its activities (
report on NewTeeVee
). Switzerland (not part of the EC) has its own
privacy law
, so perhaps this difference isn’t surprising, though in fact the Swiss definition of personal data – “all information relating to an identified or identifiable person” – looks pretty similar to the European one.
But what puzzles me is that, particularly in the copyright enforcement cases, the courts seem to be asking the wrong question. Both Swiss and EC law allow personal data to be processed without the user’s consent if the processing is “in the legitimate interests of a natural or legal person, provided that the interests or the rights and freedoms of the data subject are not overriding” (Recital 30 of
Directive 95/46/EC
). Enforcing copyright is clearly in the interests of the rightsholder (a legal person), so the courts could instead have looked at whether or not those interests were overridden by the rights and freedoms of the individual user. That sort of discussion seems to me much more likely to produce a satisfactory and consistent (or at least justifiably inconsistent) outcome and a useful guide to how to approach a lot of other privacy questions. Unfortunately it seems to be a discussion that isn’t taking place at the moment (unless you know differently, of course).
Originally posted: 17 September 2010 in category
Articles
An interesting
presentation
at the TERENA TF-CSIRT meeting on how visited and home sites need to work together to resolve complaints about users of eduroam visitor networks. Stefan Winter is both an architect of
eduroam
and a member of
RESTENA-CSIRT
, so well placed to understand these issues.
Although the JRS and eduroam Policies both require home sites to deal with misuse by their users, a feature of the 802.1X protocol that is a benefit in normal use – that the identity of the visitor is kept private from the visited site – makes this slightly more complicated, as the visited site cannot simply tell the home site which user caused a problem. Instead the visited and home sites need to ensure their systems keep relevant logs and exchange the right information from these to allow the home site to identify the responsible user. The
presentation
describes each of the stages in this process as well as highlighting which information in the logfiles can be trusted and which can be forged by a malicious user.
Originally posted: 15 September 2010 in category
Articles
The Department for Business, Innovation and Skills has published its
response
to the
consultation
on how costs under the Digital Economy Act 2010 should be shared. These are the costs of ISPs’ systems and processes to receive and pass on Copyright Infringement Reports (CIRs), Ofcom’s costs in regulating the process, and the costs of the Appeals body.
The result of the consultation is to confirm the original proposal:
Ofcom will estimate how much it should cost an efficient ISP to process each CIR;
Rightsholders will pay ISPs 75% of this cost, with the ISP covering the remaining 25% plus any additional costs over Ofcom’s estimate;
Costs of Ofcom and the appeals body will also be split 75%:25% between rightsholders and ISPs.
There is no mention of whether the cost per CIR might be varied for different classes of ISP, for example the costs might well be different for a large ISP that implemented a fully automated system as against a small ISP that handled CIRs manually. This is probably not immediately relevant given
Ofcom’s proposal
that the initial qualifying ISPs should be large fixed-line broadband providers, but I suspect that it may need to be revisited if the scope of the Act widens.
On appeals the consultation considered whether there should be a fee for a subscriber to make an appeal against a CIR (refunded if the appeal was successful). It has been decided not to impose a fee initially, though the number and outcome of appeals will be monitored to see whether this policy needs to change.
It has also been concluded that the deadline for introducing the Code needs to be delayed by three months (to the end of March 2011) to allow approval by the European Commission.
Tags:
#28 - Network Neutrality
Originally posted: 9 September 2010 in category
Closed
This seems to be a particularly busy summer for consultations! I’ve just submitted a
JANET(UK) response
to an Ofcom discussion paper on
Traffic Management and “Net Neutrality”
. The quotes are Ofcom’s and I’m reassured to see them because I’ve always suspected the phrase of being something of a banner that can be waved in support of a number of different viewpoints about openness on the Internet.
So why is this relevant to a network like JANET, whose research and education purpose already requires it to be as open and neutral as possible? The first thing to catch my eye was the other phrase in the title – “traffic management”, which is something we do. To avoid mutual disruption, high-bandwidth and experimental uses of JANET are given their own parts of the network through the JANET
lightpath
and
aurora
services. Even on the general-purpose parts of JANET we do block traffic to particular addresses or ports from time to time, as permitted on a temporary basis by paragraph 10 of the
JANET Security Policy
, to give connected organisations time to deal with new security problems that may affect them and others. Connected sites and networks may also use Quality of Service and other prioritisation technologies to make sure their networks deliver the services they need – for example where voice or video traffic shares a network with bursty traffic with less demanding performance requirements, traffic management may be the only way to make voice and video usable. This seems to me necessary, and entirely legitimate, to make networks work. My Ofcom response, therefore, stresses that traffic management technologies are essential, and that any regulation that may be proposed in future in the interests of “Net Neutrality” must focus on undesirable uses of those technologies, not on the technologies themselves.
About half of the discussion paper deals with issues specific to consumer networks, so the JANET experience doesn’t seem relevant. However for my own interest I did read those sections to try to work out what Ofcom thinks are the problems within their definition of “Network Neutrality”. The paper doesn’t explicitly make this distinction, but I think there are two different issues:
unfair competition, most obviously if an ISP offers an application service that competes with a third party service then the ISP might make it more difficult for their customers to access the competitor in order to increase their own business. At some (not always obvious) point that slips from legitimate to unfair competition. Fortunately there is already an extensive range of competition law and cases to decide when competition is unfair and a well-known “toolkit” of transparency and regulation that can be used to keep competition fair;
the harder issue, because it’s a question of what society wants from the Internet, is ensuring that the Internet remains a space that supports innovation and not just by existing providers. Commentators often contrast the Internet, where (at least in theory) any two users can get together and run a new application or protocol, with the old telephone network where both law and technology meant that innovations were impossible without the approval of the network operator. There’s little question that that openness was critical for the rapid development of our current networked society – the World Wide Web was created by a “
mere user
” – but it’s becoming apparent that IP technology doesn’t automatically guarantee the ability to innovate and that there may be economic incentives for network and service providers to try to keep innovation to themselves. The really interesting Network Neutrality question, it seems to me, is how much society needs and wants to preserve that ability to innovate and how that can be done.
Another
consultation response
: this time to a European Commission
review of the e-Commerce Directive
(
2000/31/EC
). The Directive addresses a number of different issues around electronic commerce, but the area of most interest to those who run websites or networks is the rules on liability for content in Articles 12 to 15. For networks, the Directive says that they cannot be liable for any breach of the law by third party content they transmit; for web and other hosts there is no liability until they are informed of a specific problem. These protections are essential for the way the Internet works: for example if web hosts were instead treated like newspaper publishers then they would have to check every item before publishing it.
However, over the ten years that the Directive has been in force, some uncertainties have emerged about how it works in practice. Protection from liability is only available if a network “does not select or modify the information contained in the transmission” and if a web site does not have “actual knowledge” of what is published. Courts in other European countries have apparently used these qualifications to find in some cases that ISPs and hosts might have legal liability for third party content, despite the Directive. Our response therefore asks for greater clarity and, if necessary, strengthening of the liability protections, especially as both users and governments seem to be expecting that in future networks and websites will do more filtering and proactive checking: the same areas where courts have raised liability problems.
The consultation also asks whether technical filtering can be made more effective. Here I’ve pointed out the great difference between filtering to protect users from content they don’t want to see (for example inappropriate material and viruses), and attempting to use it to prevent access to content that users want. Not only is the latter type of filtering bound to fail (Internet technology simply provides too many ways around any blocks), but imposing it is likely to encourage users to adopt filter-evading technology, thereby also exposing them to the risks they actually want to be protected from.
Originally posted: 6 August 2010 in category
Articles
An interesting
report
from the French data protection authority (CNIL) that the European Commissioner has announced a delay in the proposed revision of the European Data Protection Directive 95/46/EC. Rather than publishing a draft Directive later this year, it seems that the plan is now to publish a report this autumn with the draft expected in November next year. Having attended a
consultation meeting
on the revision last month, this seems to me a much more realistic timetable. The discussion at that meeting definitely indicated that the fifteen year old Directive needed quite a lot of work to reflect the realities of the globalised and networked world.
[UPDATE: The Commission has
confirmed
the revised timetable, and indicated that this will allow the incorporation of justice and home affairs issues (formerly a separate area of EU law) into the revised Directive]
I’ve just submitted our
JANET response
to the latest
Ofcom consultation
on the draft Code to implement the Digital Economy Act. The Code contains a lot of the detail that was missing from the original Act and has some significantly different proposals in areas that had been previously discussed in Parliament and elsewhere. In particular:
It’s proposed that the Code will initially apply only to the ‘big 7’ fixed line domestic ISPs (those with more than 400K customers), until it is possible to determine which ISPs actually have a significant level of infringement, and
The thresholds for different levels of seriousness of infringement now depend on whether a subscriber continues to infringe after receiving a warning, rather than the raw number of complaints received about them.
The second change makes the system fairer for domestic-style broadband, but worse for any other sort of “subscriber”. For example if a business or other organisation is classed as a “subscriber” then three different employees, each infringing once, could result in the business being regarded as the most serious type of infringer.
Unfortunately the draft Code has another unsuccessful attempt to make sense of the
definitions
in the Act: Ofcom now seem to suggest that a single organisation can at the same time be a subscriber and an ISP (and possibly a communications provider, though they seem reluctant to use that definition). Since copyright infringement notices for different categories have to be sent to different places, this seems certain to add confusion for rightsholders as well as for everyone else.
We also had a meeting yesterday with Ofcom where we were able to talk in detail about JANET and how the education sector
currently handles copyright infringement
by getting reports as quickly as possible to the organisation that actually knows who the user is. They seemed sympathetic to our view that this is already an effective approach and that completely changing the process would be bad for copyright enforcement and the purpose of the network.
[UPDATE: UCISA have also published
their response
to the consultation]
I was asked at very short notice to provide input into the joint Treasury and Department for Business, Innovation and Skills’ review of
how to promote growth
in the Digital and Creative Industries.
Sadly, the briefing paper’s only mention of the Internet was as a “threat to our ability to protect and monetise creativity”, so the
JANET response
points out the many commercial
suppliers of digital content
who are using the network to increase the “monetisation of their creativity”, both in the UK and beyond, with their intellectual property rights protected by
federated access management
technologies and agreements.
There was also a request to identify regulatory barriers, so I’ve again pointed out the difficulty of delivering privacy-protecting Internet services in compliance with the current Data Protection Act and the likelihood that future innovative distribution technologies will be hindered by the continuing demonisation of novel protocols. Nice to have quotes from the
Information Commissioner
and the
European Commission
respectively to support those points!
Originally posted: 2 July 2010 in category
Articles
I had an interesting day in Brussels yesterday, providing input for the Commission’s
revision of the 1995 Data Protection Directive
. Invitations had been sent to those who responded to the consultation last year, so a wide variety of organisations were present, including banking, marketing, medical, consumer rights, content industries and telecommunications operators.
There was general agreement that technology has progressed since the original Directive to the extent that many of its provisions are close to becoming both unenforceable and ineffective in protecting privacy. In particular there was widespread agreement with my view that the simple divide between “personal” and “non-personal” data is obsolete and that these are now separated by a large category of “
potentially identifying information
“. This intermediate category is developing at both ends – technology now means there is much less need to use identifiers (such as name or e-mail addresses) that directly identify a person, but statistical and other techniques are also revealing that a lot of information previously considered “anonymous” can actually be linked back to an individual. For these types of information the only practical way to protect privacy is a risk-based approach to the Directive’s requirements on security, international transfers and subject access. It seems a perverse result if satisfying a subject access request requires a data controller to strip away an individual’s near anonymity! A risk-based approach would also provide an incentive to improve privacy protection by data minimisation, privacy by design approaches and privacy enhancing technologies. This seems a more future-proof approach than writing particular methodologies or technologies into law.
Given some of the problems we’ve tripped over in trying to expand federated access management internationally it was good to hear recognition that different national definitions and implementations are acting as a significant handicap to the free movement of personal data within Europe. Indeed from some of the examples given I feel we have got off rather lightly! There was also a warning against trying to isolate Europe in terms of data flow: many of the most promising technical developments are taking place elsewhere in the world and it could significantly damage business and consumer opportunities if they law were to prohibit access to these. A better approach to international transfers of information is needed.
There were also some interesting observations on privacy notices. Informing individuals what will be done with their data is currently a legal requirement, and it was suggested that this leads to privacy notices being written in highly legalistic terms. A study by Carnegie-Mellon University estimated that the cost in customer time of reading these is significantly greater than companies’ total advertising budgets! There are some promising examples of more human-friendly notices, often presented as layers from simple to more detailed (see for example the
Information Commissioner’s recent guidance
), but making these a legal requirement doesn’t seem the right way to go.
Finally there was some discussion around how individuals might have more control of their personal data, though noting that some storage and processing is required for society’s benefit – a “right to forget” that a drug trial had been unsuccessful, or that an individual had a history of bankruptcy, could be dangerous. Again, this is an area where balance rather than absolute rules seems necessary.
The Commission are due to report their conclusions later in the year.
For a while I’ve been trying to understand how pseudonymous identifiers, such as IP addresses and the TargetedID value used in Federated Access Management, fit into privacy law. In most cases the organisation that issues such identifiers can link them to the people who use them, but other organisations who receive the identifiers can’t. Indeed Access Management federations spend a lot of effort to make it as difficult as possible for the link to be made, using both technical and legal means to protect the privacy of users.
Both UK and EU law recognise such identifiers, but don’t give them any special status: they are either personal data (just like names or e-mail addresses) or not personal data, depending on whether courts and regulators think that it’s “likely” that the link between the identifier and the individual will be made. This lack of flexibility makes the decision very significant – personal data is subject to a lot of regulation, non-personal data is subject to none. This is producing odd results, with courts seeming first to decide whether the proposed processing is desirable and then finding a way to reach the appropriate decision on whether or not it involves processing personal data. Thus courts in various parts of Europe (as far as I know there haven’t yet been any cases on the question in the UK) have come to contradictory conclusions depending on whether the question is asked in the context of enforcing rights (good) or “surveillance” (bad).
Yesterday I presented a
paper
on this at a law conference in Edinburgh, suggesting that the current situation is unhelpful both for systems designers and for privacy. Instead, I think, the law ought to be working out how much risk there is to privacy and then requiring a proportionate level of protection. Unfortunately that doesn’t seem to be the way that either the Data Protection Act or the European Privacy Directive are being used at the moment. The audience of lawyers seemed to agree both with my analysis and my ideas for how to fix the problem, which will be reassuring for any future discussions with the Commission and UK Regulators.
Originally posted: 17 June 2010 in category
Articles
Cloud computing was the theme of the day at the
FIRST conference
, with talks on security and incident response both concluding that we may need to re-learn old techniques. The adoption of at least some form of “cloud” seems to be inevitable, so we need to understand how to do this with an acceptable level of risk. Unfortunately assessing the risk requires both an understanding of the criticality of data and processes and knowledge of the security measures implemented by the cloud provider; one or both of these may be missing. Clouds are not inherently more or less secure than in-house physical machines: indeed the list of problems looks depressingly familiar – security by obscurity, lack of standards, lock-in, downtime, information leakage, application and platform vulnerabilities, power failures and burglary. These may be either increased or decreased by sharing infrastructure with a large number of other, unknown, parties.
Incident detection and response on traditional computers has increasingly focused on monitoring network traffic, but “network traffic” between cloud virtual machines may never leave memory and even if it does, the physical networks are monitored by a cloud provider with no way to distinguish a denial of service attack from a successful product launch! For the same reason logs from the cloud platform, even if they are available from the hosting provider, are likely to be very hard to interpret. Applications written for clouds therefore need to do their own logging, where possible to external storage since an attack may well result in the virtual machine and its data disappearing without trace. Incident response teams should work with application developers to ensure that relevant information is logged and preserved; ideally each application should have its own Security Response Plan covering logging, incident response tools, access management, fix deployment and escalation. In some cases traditional incident response tools may work on cloud platforms, but teams need to know which will give reliable results and practice using them before they are needed in an emergency.
Originally posted: 8 June 2010 in category
Articles
Regulators and governments are moving towards creating a requirement that anyone who suffers a security breach affecting personal data would have to report it. A number of American states already have such laws, the recent revision of the European Telecoms Framework Directive introduced a breach notification requirement for telecoms providers and the Commissioner has stated that this will be
extended to all organisations
in the forthcoming revision of the Data Protection Directive.
A number of benefits are claimed for mandatory reporting:
Allowing lessons to be learned from security breaches, so others can improve their processes;
Allowing those whose personal data is involved in a breach to protect themselves from the consequences;
Naming and shaming organisations that fail to take proper care of personal data.
Taking each of those separately they look like admirable objectives. However I’m concerned by implications that making notification mandatory will deliver all of them. It seems to me that the incentives and reporting requirements are very different for each of the three purposes, making it unlikely that you can achieve all of them at once. Indeed I suspect it may be impossible to achieve more than one and that attempts to do so will inevitably fail. My thinking is set out in a
draft paper
, which I’d very much welcome comments on.
As with everything else around this Act, a lot of thought has gone into the implications for consumer broadband connections. The consultation document contains several significant improvements for those types of connections. However there seems to be very little thought about the potential impact on business connections – which may or may not be subject to the Act – and some of the changes actually make things significantly worse for them.
To start with the good news: Ofcom have clearly understood that it’s critical that high-quality systems are used both by rightsholders to create Copyright Infringement Reports (CIRs) and by ISPs to direct those reports to the apparently responsible subscribers. So the draft Code would require both types of organisations to submit details of their systems to Ofcom in advance, to have them approved and potentially subject to a third party audit (paras 4.4 and 5.7). Much more detail will also be required in each Copyright Infringement Report, including source address and port, and start and end times during which infringments were taking place (para 4.3). There isn’t currently a requirement for destination address and port, though as far as I know (please let me know if I’m wrong) it’s only the most extreme types of Network Address and Port Translation where that might become a problem. In any case it is explicitly recognised that for some reports it may be impossible to uniquely identify a subscriber from the details provided, and that is one of a number of reasons why reports can be returned to the reporter as undeliverable (para 5.3). These reasons don’t yet appear to include “this report doesn’t match our flow data” (a test commonly used by universities that has, on occasion, detected systemic problems with rightsholder reporting systems), though I’ll be seeking clarification on that from Ofcom (there is “IP address not used by a subscriber at the relevant time”).
The draft also proposes a novel implementation of the three levels of severity of notification: rather than simply counting the number of reports, it is now proposed that a second, more severe, notification will be sent if a subscriber is still reported as infringing a month after receiving a first notification, and then a third notification (at which point the subscriber will be added to the anonymous serious infringers list that may be disclosed to rightsholders) a further month later (para 5.11). I suspect this actually matches quite well how universities and colleges currently regard individual wrongdoers – someone who carries on after a warning is treated more seriously than someone who stops when warned about a burst of activity.
Indeed were JANET connected organisations ever to be required to apply the Code to their users I think there would be little problem for those already implementing our Acceptable Use Policy.
Unfortunately although the consultation paper states (correctly) that “attention must focus on the provider of the final leg of Internet chain” to achieve effective education and enforcement (para 3.25), the paper’s interpretation of the Act’s definitions to organisational, rather than consumer, Internet connections appears to do the exact opposite. Ofcom still seem to think that most organisations are “subscribers” and not “communications providers” (para 3.30). Implementing that Act that way would actually prevent those organisations from educating their users (because they would never hear about most alleged infringements); the new time-based notification system would also mean that three employees, none of whom had ever received a warning, could put their employer into the most serious category of infringer if they downloaded a single copyright file each!
The paper doesn’t mention universities, colleges or schools, but does mention libraries (para 3.28): suggesting that they will be classed as “ISPs” and that they may, if the initial scope of the Code is extended at some future date, be required to collect postal and e-mail address details from all users. Again, this is a side-effect of the change to time-based notifications: Government ministers had previously praised libraries who displayed prominent notices as an effective way to keep infringement below a numerical threshold, however with a time-based threshold the very first report has to be forwarded and so needs to be linked to an address. The paper also admits (para 3.31) that this interpretation will be “challenging” for those providing community networks! So my response to this consultation will again be pointing out the direct conflict between these suggested requirements on the Government’s other policies to combat digital exclusion.
Responses to this consultation are due by the 30th of July, so I’ll be drafting a JANET response over the next month. If you have comments or feel I’ve missed anything in the above, please let me know either by commenting here or e-mailing. Thanks, Andrew.
I’ve just sent off JANET(UK)’s
response
to the Department for Business, Innovation and Skills
consultation
on how the costs incurred in implementing the first stage of the Digital Economy Act 2010 will be shared between rightsholders and ISPs. The consultation covers three sets of costs:
Costs incurred by ISPs in implementing systems to receive and forward copyright infringement reports, and in maintaining the serious infringers list;
Costs of the new body that hears appeals from subscribers against either reports or inclusion on the serious infringers list;
Costs incurred by Ofcom in developing and regulating the process.
There’s a detailed analysis of these in a
paper
commissioned by the Department. The consultation proposes that all three costs will be split between ISPs and rightsholders with ISPs paying 25% and rightsholders 75%.
Our response points out that we cannot yet determine the impact of this on either JANET or its customers, because it is
still not clear
whether either of us fall within the Act’s definition of “ISP”. Given that, the response comments more generally on the incentives that are created by the allocation of costs. In particular it seems to me dangerous to make ISPs pay part of the costs of appeals, since they only way they can reduce the number of appeals seems to be to not tell their subscribers that they can appeal!
I’ve also pointed out some areas where the proposal is either unclear or may not implement the policy objective that it is supposed to.
Originally posted: 26 April 2010 in category
Articles
I’ve been having a look at what the first stage of the Digital Economy Act 2010 will require of qualifying ISPs and comparing it with what JANET already requires of the universities and colleges that connect to the network. And I can’t see that the Act would add anything to our existing measures against copyright infringement, confirming a
statement
by a Government Minister a couple of months ago.
I’ve included references to the legislation in the discussion below, though these are a bit complicated as the detailed section numbers (beginning 124) are actually references to the Communications Act 2003 as amended by the Digital Economy Act. The hyperlinks will take you to the appropriate parts of the Digital Economy Act where you can find the text of the amendments. I hope that makes sense…
All JANET-Connected Organisations (JCOs) are required by the JANET
Acceptable Use Policy
to deal effectively with reports of copyright breach by their users.
The Act would apply to “ISPs” and their “Subscribers”, as defined in
section 124N
.
JANET’s
guidance
states that as a minimum a Copyright Infringement Report should include the source IP address, synchronised time and timezone, and a statement of the reporter’s authority in relation to the content. Since dynamic address allocation and address translation are commonly used by universities and colleges, the guidance points out that including the source and destination IP addresses and port numbers will significantly increase the likelihood of being able to identify a responsible person.
The Act leaves the detail of CIRs to the Initial Obligations Code.
JANET’s only formal requirement is that the action taken by connected organisations when they receive a Copyright Infringement Report must be effective. Our
guidance
recommends that provided that the report appears consistent with the organisation’s own records (e.g. address allocation and network flows) and that the report contains sufficient detail to allow a responsible individual to be identified, then that individual should be informed of the apparent breach and be provided with information about copyright and computer security. We would expect any repeated infringement by the same individual to be treated as a serious matter.
If a report is inconsistent with the organisation’s own records we encourage them to contact the reporter to determine the source of the error.
The Act requires ISPs to inform their subscribers of CIRs, probably through a graduated response process to be defined in the Code.
JANET-Connected Organisations will generally record copyright infringement as part of their staff and student disciplinary processes, and retain records as required by those processes. Repeat infringements after a warning are understood to be rare. The identity of individual users is protected under the Data Protection Act 1998 so is likely to be released only under a RIPA s.22 notice (criminal) or Norwich Pharmacal Order (civil).
The Act requires ISPs to maintain a list of serious infringers, above a threshold to be set in the Code. Anonymised identities of serious infringers can be released to copyright owners on request.
Individual JANET users identified as being responsible for copyright breaches may challenge this informally or formally under their organisation’s disciplinary process (which must comply with the Human Rights Act 1998). Since most organisations check reports against their own flow logs before passing them on, such challenges are understood to be rare.
The Act will create an independent body to hear appeals against notices and inclusion on the serious infringers list.
The costs of dealing with copyright infringement on JANET are met by the organisations that incur them
The Act may require copyright owners to contribute to ISPs’ costs, and both to pay the costs of Ofcom and the Appeal Body. The mechanisms and proportions are the subject of a
consultation
by the Department for Business, Innovation and Skills.
Originally posted: 22 April 2010 in category
Articles
Ofcom have invited me to a meeting to discuss the definitions in
section 16 of the Digital Economy Act 2010
, so I’ve been staring at what the Act says and trying to make sense of how it applies to universities or colleges with JANET connections. Since a
wide variety of answers
to this question have already been given by Ministers and Lords, this is clearly a hard question, so the following are very much my personal (and possibly temporary if anyone points out something I haven’t noticed) thoughts.
For this discussion the interesting extracts from section 16 are as follows:
“internet access service” means an electronic communications service that
(a) is provided to a subscriber
(b) consists entirely or mainly of the provision of access to the internet; and
(c) includes the allocation of an IP address or IP addresses to the subscriber to enable that access.
and
“subscriber”, in relation to an internet access service, means a person who
(a) receives the service under an agreement between the person and the provider of the service; and
(b) does not receive it as a communications provider.
So is a university or college a “subscriber” under that definition? I don’t think so, because it’s clear from the terms for the provision of JANET services that we expect the university to pass on a network service to others, i.e. to act as a communications provider, so failing part (b) of the definition. This, incidentally, means that JANET isn’t an “ISP” because if you don’t have subscribers then you can’t be an ISP under part (a) of the definition of an Internet Access Service.
That’s the important question, since classing universities and colleges as subscribers under the Act would mean completely changing our current processes for dealing with copyright complaints. Complaints would then have to be sent to the “ISP” (JANET(UK)) which is a complete waste of time and money because we can’t identify the individual responsible and we would only pass the complaint on to the university or college using contact details for IP ranges that are published in the WHOIS directory anyway!
Less important – because universities and colleges are anyway bound by the JANET AUP, which is stricter than the Act – is the question of whether universities and colleges come within the definition of “ISP”? Again I think it can be argued that they don’t, because although they do provide an electronic communications service to staff and students, the main purpose of that service is actually to connect to computers and networks in that and other universities, it isn’t to connect to the Internet. So it fails part (b) of the Internet Access Service definition.
If I’m right, this definitely does not mean you can all stop
dealing with copyright infringements
! It just means that it will continue to be JANET(UK) requiring you to do so (with the ultimate sanction under the AUP of disconnecting the university or college from JANET) rather than Ofcom (with a sanction under the Act of a six figure fine). So please keep up the good work 🙂
I’ll update this if I have any further thoughts or, in particular, if Ofcom disagree.
Originally posted: 8 April 2010 in category
Articles
The Digital Economy Bill completed its highly abbreviated journey through the House of Commons last night and now only requires the final approval of the House of Lords to become law. To get enough support from opposition parties
two further amendments
have been made to the later stages of the copyright enforcement provisions:
Clause 11 is amended to require an additional period of Parliamentary scrutiny if the Secretary of State decides after 12 or more months of the warnings process that further technical measures are required.
The contentious Clause 18 on website blocking has, as expected, been replaced by
yet another version
. However
Lilian Edwards
has pointed out that this new version only creates a power for the Secretary of State to create a power for the Courts to order the blocking of problem locations on the Internet. Should the Secretary of State wish to do so, there is an additional set of tests (sub-para (3)) that he must first ensure are satisfied: essentially that there is a serious problem, that creating blocking powers would be a proportionate way to address the problem and that doing so would not prejudice national security or the prevention of crime. If a rightsholder then seeks an injunction to block a particular location the court has to apply a further list of tests (sub-paras (4) to (6)), including at least proportionality and effect on free speech, to that specific request for an injunction.
A number of people asked at Networkshop how a “location on the Internet” will be specified – for example by URL, DNS name or IP address? The law doesn’t say. However it does require the court to consider whether an order will have a “disproportionate effect on any person’s legitimate interests”. Specifying locations in a way that avoids both a disproportionate effect on other sites from over-blocking and a disproportionate effect on the ISP from having to employ very expensive or disruptive technology to implement the block could be an interesting challenge.
Originally posted: 31 March 2010 in category
Articles
The Government has proposed an
amendment to the controversial web-blocking proposals
recently added to the Digital Economy Bill. Instead of creating the blocking powers immediately, the amendment would give the Secretary of State the power to do so at some future date. This would be done by Statutory Instrument (SI) – a process that permits some Parliamentary scrutiny, but less than a full debate on primary legislation.
The amendment sets out a number of things that such an SI must contain, and some that it may contain. For example an injunction must only be granted if prior notice has been sent to both the site to be blocked and the ISP that will be the subject of the order, and the court must take account of proportionality and the effect on free speech (arguably Courts must consider those anyway, under the Human Rights Act). Provisions on costs are one of the optional inclusions, though in an accompanying
letter
the secretary of state states that ISPs “should not have to bear court costs”: a significant, though not yet binding, reversal of the original Amendment 120A proposal.
Most commentators (see the
Guardian article
and its links), seem to regard this proposal as being better than the original Amendment 120A, now clause 18 of the Bill, but note that it is missing some of the safeguards included in the
second Amendment
proposed by Liberal Democrat peers which was never put to the vote in the Lords. As with so much of the Bill, it seems that we will only discover the actual impact of the legislation long after it is passed.
Tags:
#13 - DEB – Government confused, let’s help
Originally posted: 1 March 2010 in category
Articles
Without examining the situation for each university and their relationship with JANET, it is not possible to say whether JANET is acting as an ISP or not; nor is it clear whether a university is a subscriber, ISP or is simply not in the scope of the Bill. As such, we cannot say simply who the ISP is and who is the subscriber, only that this is something that each university would have to look at and establish for themselves.
On the face of it this looks like a nightmare, with a court case potentially needed to for every university and college to determine where its copyright infringement notices should be sent! However there is recognition of the good work we are already doing:
It is clear that JANET and some universities already take far stricter action on copyright infringement than is being proposed in the Bill
and
It does not seem sensible to force those universities who already have a system providing very effective action against copyright infringement to abandon it and replace it with an alternative.
and there is at least a suggestion of how most universities will fit into the Bill’s definitions:
in most cases though JANET is acting more as a communications provider and the university itself might be regarded as the ISP.
In fact JANET-connected organisations do have two important things in common with ISPs for the purpose of the Bill:
Their IP address allocations are published, as are their contact addresses for complaints;
They are able to identify and educate individual users.
So the simplest resolution of this for both organisations and rightsholders appears to be for JANET-connected organisations to continue to receive copyright notices from rightsholders, to
act effectively
to deal with breaches, as required by the
JANET AUP
, and thereby to more than satisfy the requirements that the Bill places on ISPs. One requirement of the Bill may not be covered by current practice – when a single individual has been the subject of more than a certain number of complaints they have to be added to a serious infringers list, an anonymised copy of which must be provided to rightsholders on demand. Details of how these lists will be managed will only become clear once the Bill becomes law and a Code of Practice is approved by OFCOM, but if we can continue to dissuade copyright infringers from repeated offences then there should be little additional burden.
#12 - Non-photographic indecent images of children
Originally posted: 13 January 2010 in category
Articles
I’ve been reminded that
section 62 of the Coroners and Justice Act 2009
, passed last November, created a new offence of possessing non-photographic images of children that are pornographic and fall into one of a number of sexual categories. When the section is brought into force such images will be classed in the same way as indecent photographs and pseudo-photographs of children, already illegal to possess under the amended Protection of Children Act 1972.
The good news is that the government seem to have recognised, following discussions over the Sexual Offences Act 2003, that laws criminalising possession need to provide defences for those who have to secure evidence when it is alleged that computers contain the prohibited material. Section 64 of the new Act contains similar defences to those in the Sexual Offences Act:
That the person had a legitimate reason to possess the image (e.g. investigating a complaint);
The the person had no reason to suspect the nature of the image (e.g. making a routine backup);
That the image was sent unsolicited to a the person and that they did not keep it for an unreasonable time (e.g. e-mail spam, though there is little evidence of such images being sent as spam).
Originally posted: 21 December 2009 in category
Closed
The Commission have been running a
consultation
for several months to inform a possible revision of the
Data Protection Directive (95/46/EC)
, which is now fifteen years old and starting to creak under the strain of new ways of doing business. I’ve sent in a JANET(UK)
response
raising issues we’ve tripped over in developing the UK Access Management Federation and, particularly, in trying to do international authentication and authorisation in a privacy-protecting way. Unfortunately the current law (developed long before there was public awareness of the Internet) at best treats such technologies the same as old-fashioned (and privacy-invasive) individually named accounts, and at worst raises sufficient legal uncertainty that organisations wanting an easy compliance life might actually be put off using them.
In the past I’ve tried to extract good practice for federated access management from the current law for the
UK federation
and for
TERENA
, but in both those documents there remain significant legal uncertainties. The three issues I’ve highlighted to the Commission actually have much wider application than just federated access management. Search engines, behavioural advertising and cloud computing all raise the same questions:
Is something like an IP address or pseudonymous label personal data just because you can recognise me when I return, or only if you can link it to my real world identity? (I’m trying to refer to this as recognition versus identification, and to point out that there are different answers within the same EC guidance document!);
If a label is personal data in my hands (e.g. an IP address held by an ISP that issued it to a particular customer), then is it doomed to be personal data forever, or can someone who has the label but not the linking information treat it as non-personal data? (UK law says the latter, but EC appears to say the former. And two courts in Berlin and Munich chose differently when asked this question!);
Can compliance be based on risk, rather than the current binary choices of “personal data/non-personal data” and “compliant country/non-compliant country”? (which could make working with the US a lot easier and no less safe).
There are significant differences in what laws and guidance have to say about these questions even between different European countries, which rather makes my point that greater clarity is needed in the Directive that they all claim to be implementing. The good news is that the UK Information Commissioner has recognised the problems and is suggesting a pragmatic approach in his recent draft guide to
personal data on line
(that consultation is open till March 5th, so please contribute) though he is obviously constrained by the letter of current legislation. It would be nice to think that one day the Directive and UK law might catch up and support the right ways of doing things.
Originally posted: 27 November 2009 in category
Articles
The
amended EC law
requiring opt-in, rather than opt-out, to non-essential cookies was
criticised
last week as “breathtakingly stupid” because of its implications for advert-funded sites. However advertisers have now
said
that they don’t think the law requires any change to current practice!
So is there a problem, or not? I don’t know, but I have suggested to the Information Commissioner’s Office that some pragmatic guidance would be very helpful by the time this becomes UK law. I’m confident that the ICO will indeed work something out, if only because
their site
uses google-analytics too 😉
#9 - House of Lords looks at network resilience and CERTs
Originally posted: 27 November 2009 in category
Articles
On Tuesday I was invited with Chris Gibson of
FIRST
to give evidence to the
Home Affairs Sub-Committee
of the European Affairs Committee of the House of Lords. They are currently looking at the European Commission’s
proposals to protect Europe from large-scale Cyberattacks
. We spent an hour and a half explaining what CERTs are, how they work together to deal with network security incidents and how groups such as FIRST,
ENISA
and
TERENA
help to make those responses quicker and more effective.
Although the members of the sub-committee seemed surprised that there was no central point coordinating incident response for the whole world, they did seem reassured at the speed with which organisations work together to resolve problems. They raised the concern (legitimate, I think) that heavy-handed intervention by governments could harm existing incident response mechanisms, and seemed to agree that it was better to expand and build on what already exists, sharing experiences with other regions of the world, rather than try to impose a completely new model.
Originally posted: 18 November 2009 in category
Articles
Considerable concern has been expressed about the news that it has apparently been agreed to change European law on cookies as part of the revision of the Telecoms Directives.
The current law on cookies is contained in Article 5 of the
Directive on Privacy and Electronic Communications (2002/58/EC)
and Regulation 6 of the UK’s matching
Privacy and Electronic Communications Regulations 2003
. Those require that whenever cookies are stored and accessed, the user must “[be] provided with clear and comprehensive information about the purposes of the storage of, or access to, that information; and [be] given the opportunity to refuse the storage of or access to that information”. The
Information Commissioner’s Good Practice Note
suggests that this can be done by providing information as part of the site’s privacy policy and allowing users to refuse continued processing once they are on a site, in other words informing visitors and then allowing them to opt out of cookies.
However a
new text
– apparently already accepted by the European Parliament, Commission and Council of Ministers – would change the law to require the information and opportunity to refuse to be provided before any cookies are stored in a browser.This appears to be a well-intentioned attempt to improve privacy protection, but since cookies are now very widely used by websites,
commentators
have raised visions of every website being preceded by a “may we use cookies?” landing page or hidden behind a fog of permission-seeking pop-ups, with the resulting collapse of the advert-funded business model.
Two facts may mean that things aren’t quite that bad.
First, both the old and new texts recognise that some cookies are “strictly necessary” to provide the service that the user wants. Shopping cart cookies are the most obvious example. These cookies are, and will continue to be, exempt from the right to refuse – the only way to refuse these cookies is not to use the service.
Second, EC Directives need to be transposed into UK law, and commentators have expressed the hope that what emerges from this may be a more practical requirement, supported by pragmatic guidance from the Information Commissioner. Most Directives give member states 18 months to transpose the EC requirement into national law, so there are likely to be some interesting discussions between now and 2011.
As an amendment to the existing
Directive 2002/58/EC
the new proposals would apply in the first instance only to public telecommunications networks and services. However, as expected, this draft calls for a wider breach notification law: “The interest of users in being notified is clearly not limited to the electronic communications sector, and therefore explicit, mandatory notification requirements applicable to all sectors should be introduced at Community level as a matter of priority” (recital 59).
The current proposals would require communications providers to notify their national regulator (presumably the Information Commissioner in the UK) whenever they suffer from a security breach that affects personal data. In addition the individuals affected should be informed where the breach could result “for example, [in] identity theft or fraud, physical harm, significant humiliation or damage to reputation” (Recital 61): the draft recognises that there may be circumstances where such misuse is unlikely and therefore notification unnecessary, for example if the personal information was encrypted (Article 2 4(c) on pages 74-76). Notifications should include information about what the provider has done to address the breach as well as what individuals may do themselves.
It has been
argued
that this in fact goes no further than current good practice in the UK, as contained in the Information Commissioner’s existing guidance on
data security breach management
and
notification of data security breaches
. It will be interesting to see what the UK implementation, required within 18 months of the Directive being finally published, makes of this.
Originally posted: 31 October 2009 in category
Articles
The all-party parliamentary communications group (apComms) have published the results of their enquiry into various aspects of internet security – entitled “
Can we keep our hands off the net?
” – to which JANET provided written
evidence
earlier in the summer. We responded on two of the five questions, relating to the work of the Internet Watch Foundation (IWF) and to liability of ISPs for “bad traffic” to and from their users. The report makes a number of recommendation on areas of interest to JANET sites, mostly along the lines suggested in our submission.
The group recognises the
success
of the IWF in removing indecent images of children from UK websites and recommends (rec.6) that this practice be extended to other countries. They also recommend (7) against making network-level blocking against the IWF list compulsory, to avoid damaging the success of self-regulation in this area.
There is a recommendation (10) that ISPs develop a self-regulatory code for detecting and dealing with malware-infected computers, though the report quotes our concerns that technology to do this may make mistakes: both failing to spot some infected computers and incorrectly identifying others as infected. However the conclusions are at least much more narrowly focussed than the original enquiry proposal and only apply to malware infections. Our concern that the tightly defined ‘mere conduit’ protection from liability might be lost if organisations attempt to filter network traffic to protect their users was recognised and the Government is recommended (11) to revise this area of law to give greater clarity.
Although we did not comment on illicit use of peer-to-peer technology to share copyrighted files, suggestions by other respondents that ISPs be made liable for copyright breach are strongly resisted. Indeed the report recommends (2) that the
current government consultations
in this area should be postponed until the European Telecomms Directives have been revised. The report also recommends that the option of disconnecting subscribers for copyright breach be ruled out as incompatible with other Government proposals – a point we have also been making in our
responses
to other consultations on copyright enforcement.
The report also has recommendations on a new, clearer, law on privacy (1); that behavioural advertising be only permitted on an opt-in basis (3); that eSafety be included in school curricula (4) and that eSafety messages be provided at point of sale for mobile phones (5); that Ofcom monitor developments in network neutrality (8) and require ISPs to advertise minimum guaranteed bandwidth (9). Although apComms has no formal authority its reports have in the past had some influence on policy, for example in amending the Computer Misuse Act 1990 to include denial of service attacks. It will be interesting to see which, if any, of these new recommendations are taken up.
Originally posted: 2 October 2009 in category
Articles
The Annual General Meeting of the
Internet Watch Foundation
(IWF) brought some very positive news on efforts to reduce the availability of indecent images of children on the Internet. Thanks to the self-regulatory action of UK hosting providers only a tiny fraction of illegal images reported to IWF are hosted in the UK – down from 18% when the IWF was founded – and those are removed quickly when the IWF notifies the hosting site. It also appears that action by law enforcement and industry is forcing criminals who sell such images on-line to change their tactics, making it less likely that users will accidentally stumble over them.
JANET(UK) supports the IWF with funding and active participation in its Funding Council and Working Groups. As in our
response to the Parliamentary All-Party Communications Group’s Enquiry
we consider that the best long term solutions to illegal content on the Internet are removal at source combined with locally-managed filtering to protect users from accidental exposure to content that is either illegal or inappropriate for them.
#4 - Legislative Options for Illicit Peer-to-Peer Filesharing
Originally posted: 1 October 2009 in category
Closed
Over the summer the government has carried out the latest in a series of
consultations
on what to do about sharing of copyright files on peer-to-peer networks. Under the current law, sharing copyright files without permission is a civil offence and rights-holders can sue those who do it. However the criminal offence of copyright breach only occurs when copyright is broken either as part of a business (e.g. selling bootleg DVDs) or in sufficient quantity to affect the business of the rights-holder. So far no one in the UK has been prosecuted for copyright breach on peer-to-peer networks, but many people have been sued.
Unfortunately for those who create digital material, the process of taking action is long and expensive, since it first involves a court hearing on whether it is proportionate to order an ISP to disclose the identity of their customer (known as a Norwich Pharmacal order), and then potentially a full civil hearing against that customer. The Government has therefore been consulting on three possible areas for improvement: better notification of those accused of breaching copyright, making civil action more efficient, and requiring ISPs to modify the service they provide to those accused of copyright misuse.
On notification, it is suggested that ISPs might be required to pass on to the relevant customers complaints that they receive from rights-holders. Some surveys have suggested that as many as 70% of file-sharers would stop if notified that they were breaking the law. This would not involve any breach of privacy, since the rights-holder would not discover the identity of the user, but since rights-holder reporting systems are largely automated it could involve ISPs handling a large volume of allegations and thereby increase their costs.
On improved civil process, it is suggested that ISPs be required to keep a record of how many complaints have been received about each user. These counts might somehow be made available to rights-holders in an anonymised form so that they could know when they begin the existing two-stage legal process that the target was someone who is a repeat infringer. At the moment rights-holders have no way to know this, since all they have is an IP address and dynamic address allocation means that counting IP addresses is not equivalent to counting users or infringements. If not implemented properly, such a process could result in privacy disclosures (for example if a complaint related to an individual’s personal page), but there does appear to be some scope for better targeting of the existing legal process.
Finally, the consultation suggests that ISPs might be compelled to impose various technical sanctions – including port blocking, traffic shaping, bandwidth limiting and disconnection – at some stage of the complaints process. No court would be involved in this to assess the strength of the evidence either that an infringement had taken place or that a particular individual was responsible for it. This seems much more problematic, indeed the French Constitutional Court has recently ruled that a similar law passed earlier in the year in France breached the constitution and could not be brought into force. Technical measures also seem bound to block innocent actions as well as illicit, since peer-to-peer protocols are used for both lawful and unlawful purposes and measures taken against a particular subscriber will also affect others, such as family members, who share the same ISP connection.
Public
reactions from ISPs
have generally been hostile to these proposals, on the grounds of cost and practicality, and that they should not be forced to act as Internet policemen.
It is not clear whether JANET and its customers would be affected by these proposals. The consultation uses the common term “ISP”, which would not usually include JANET, but then defines that in a way that would in fact include every network connecting two computers, even those in individual homes! In fact, the JANET Acceptable Use Policy already requires connected organisations to deal effectively with complaints of copyright breach, and our
factsheet on dealing with copyright complaints
already goes beyond the suggested notification requirements. JANET sites report very few instances of ‘second offences’, so the provisions on repeat infringers and technical measures may, in any case, be moot.
#3 - House of Lords enquiry into personal internet safety
Originally posted: 28 October 2006 in category
Closed
This is UKERNA’s submission to the House of Lords Select Committee on Science and Technology Sub-Committee
investigation into Personal Internet Safety
. UKERNA is the non-profit company limited by guarantee that operates the JANET computer network connecting UK colleges, universities and research council establishments to each other and to the Internet and inter-connecting regional schools networks. Information about UKERNA is available on the website
http://www.ja.net/
When private individuals connect their computers to the Internet they are entering a public space and are exposed to risks arising out of the nature of that space and the other computers and people who occupy it. As in real-world public spaces the level of risk to which an individual is exposed depends very much on how they behave. In recent years the nature of the most prevalent threats has changed, from technical attacks that target weaknesses in computers and software to ‘social engineering’ attacks that rely on lack of knowledge or careless behaviour by the user to succeed. Viruses, phishing attacks, on-line fraud and trojan horse programs are all examples of the latter type. Software vendors and Internet Service Providers continue to improve protection against technical threats: the greatest opportunity to improve personal internet safety is therefore to improve users’ ability to avoid or resist social engineering attacks that expolit their human nature.
While it might be possible, to a limited extent, to impose Internet safety on users, this would inevitably require restrictions on what they can do and, in particular, make developing new services and ideas very much more difficult. Imposing safety (as is done, for example, when we travel by aeroplane) also makes users psychologically dependent on others for their safety and thus highly risk-averse and intolerant of any failure. The statistically illogical reaction of the public to rail and plane accidents, where safety is imposed, contrasts starkly with the response to the much higher, but apparently acceptable, rate of deaths in road accidents where individual drivers feel in control of their own safety. Any approach that attempts to impose safety on users of the Internet is likely to greatly limit the benefits that users, businesses and governments obtain from the network.
To achieve the full potential of the Internet as a tool that individuals are prepared to rely on for their daily lives – whether for e-commerce, e-banking, e-government, e-health or many other possibilities – it is therefore necessary to ensure that individuals know how to keep themselves safe on-line. Helping users understand that they can make themselves safer, and providing them with the knowledge and tools to do so, will not only improve their safety practice but also increase their confidence in using the Internet. A recent
survey by the British Computer Society
found an increase in confidence among home users and attributed this to “a growing recognition of safe surfing and utilizing available tools to protect against threats”. In a recent paper on social networking for young people, AoC Nilta state that “e-Safety education, not filtering and blocking, will keep young people safe on line”. A population that uses the Internet safely, has a stable confidence in it and does not suffer sudden changes of sentiment is essential if plans to provide private and public services over the Internet are to succeed.
The stable attitude and consistent behaviour of those users who feel in control may be contrasted with the situation where users rely on others, whether Government or service providers, to keep them safe. Ofcom’s
media literacy study
found large discrepancies between the fears expressed by parents and their actual behaviour: 72% of parents were concerned about their children seeing inappropriate things on line, yet only about half made use of content filtering services. Fear of on-line paedophiles is often expressed, but 40% of eight to eleven year olds use the Internet unsupervised and 23% of twelve to fifteen year old girls mostly use the Internet on their own in their bedrooms. Perception may be very different from actual risk. Concern about on-line “identity theft” is widespread but the BCS survey found only 8% of those surveyed had been a victim; in fact the vast majority of cases are simple credit card fraud which is at least as prevalent in the real world and where the individual’s loss is limited by their contract with the issuer.
Advice in Internet safety and easy to use tools are already available but these need to be more widely promoted and adopted. For almost all personal computers tools such as automatic software updates, personal firewalls, anti-virus and anti-spyware are available either free or at low cost and can be used without specialist knowledge. Using these tools and checking advice sites such as
Get Safe Online
and
ITSafe
should be as routine as buying cars with safety devices, servicing them regularly and checking the weather forecast before using them. Demand from educated consumers for effective and usable Internet safety will also encourage and enable suppliers to further improve their products, establishing a virtuous spiral of improved safety.
Safe use of Information and Communications Technology can be taught, but it should also be demonstrated and applied whenever computers or networks are used. The Qualifications and Curriculum Authority’s
consultation on Key Skills
recognises the importance of these skills as a fundamental part of school education. All members of an information society need to know how to protect themselves and their personal information on-line (whether dealing with e-mail, websites or chatrooms), to assess the reliability of information and communications, to respect the personal and property rights of others and to use and maintain basic safety tools and behaviours. All opportunities to raise awareness, skill and confidence levels of users of all ages need to be taken – children who learn safe practice at school should be encouraged to teach their parents and grandparents at home. Childnet’s
Know It All for Parents
is an excellent example of how this can be done.
The confidence of Internet users will also be enhanced if they can see that those who misuse the network are held to account. Visible policing of the real world is now recognised as promoting citizens’ feelings of safety. Unfortunately the policing of the Internet is much less apparent: the National High-Tech Crime Unit no longer publishes notices of successful prosecutions, regional police forces rarely have the resources to accept and investigate reports of Internet crimes and the Information Commissioner has publicly stated that his enforcement powers are ineffective.
Improving all individuals’ ability and confidence to use the Internet safely is essential if society is to make effective use of this powerful communications medium. Unsafe users not only put themselves at risk, but are likely to make their computers and networks available for criminals to use to attack others. Addressing these problems requires citizens of all ages to know and practice Internet safety as naturally as road safety, cycling proficiency or motor car care.
The JNT Association, trading as JANET(UK), is the company that runs the JANET computer network. The JANET network connects UK universities, Further Education Colleges, Research Councils, Specialist Colleges and Adult and Community Learning providers. It also provides connections between the Regional Broadband Consortia to facilitate the DfES initiative for a national schools’ network. As the provider of a large private telecommunications network to the education sector, JANET(UK) welcomes measures that would be effective in reducing the amount of harmful content on the Internet, but is also concerned that the operators of computer networks and systems (both at the national level and within educational organisations) must have a clear legal framework and processes to protect them from personal and legal ill-effects if such material is accessed using their systems.
This response is structured around the questions set out in the consultation document, repeated in italic below.
1. Do you think the challenge posed by the Internet in this area requires the law to
be strengthened?
2. In the absence of conclusive research results as to its possible negative effects, do you
think that there is some pornographic material which is so degrading, violent or aberrant
that it should not be tolerated?
3. Do you agree with the list of material set out (in paragraph 39)?
We consider that the responses to these questions are a matter of personal opinion and therefore not appropriate to a corporate response such as this. However we consider that it is essential that any law should relate to particular types of content, and not to the means (for example the Internet) by which they are obtained.
4. Do you believe there is any justification for being in possession of such material?
The consultation paper itself notes that there is a shortage of research on the effects of this type of material. It is important that legislation does not prevent the performance of such research, done with appropriate authorisation and under appropriate controls to prevent harm. We therefore believe that there should be a statutory “good reason” defence to any new criminal offence of posession so that researchers can have prior assurance that they will not be exposed to criminal liability. Were such research to be carried out in universities, the Acceptable Use Policy for JANET would already prohibit the use of the network to access the material, other than in the context of genuine research. In such cases we would expect, and recommend, the researchers and their organisations to make appropriate arrangements with the Home Office or Scottish Executive.
Where material is discovered on computers or networks, it is essential that their owners or authorised system administrators are able lawfully to take steps to preserve evidence for subsequent Police investigation. Otherwise they will have no lawful course of action other than to immediately destroy the evidence. Any new legislation must therefore provide at least the same protection as contained in section 46 of the Sexual Offences Act 2003. For clarity we strongly recommend that the same legislative and operational provisions are used for this new type of material, and we strongly support the suggestion in the consultation paper that this should “mirror existing arrangements for child pornography”. In particular:
Those who have legitimate reason to handle such material in the early stages of a criminal investigation (which is not just police officers, or any other group who can be identified in advance) must be protected by both statute and a Memorandum of Understanding the same as, or equivalent to, that between the Crown Prosecution Service and Association of Chief Police Officers for indecent images of children;
The Internet Watch Foundation should be recognised as the appropriate body providing both reporting of this new type of illegal content, and a trusted database of sources that can be used by Internet Service Providers as a basis for their own blocking or filtering services.
Options for legislation
5. Which option do you prefer?
6. Why do you think this option is best?
We agree that option 3, a new freestanding Act, is to be prefered as it gives clarity of purpose and definition of the new offence, while reducing the risk of interference with the existing, generally satisfactory, legislation on publication. We also consider that, as with the Sexual Offences Act 2003, the new Act should state that prosecutions may only be initiated by the Director of Public Prosecutions to ensure that “good reason” and other possible defences are considered before a prosecution is launched.
7. Which penalty option do you prefer?
As a matter of logic, the suggested penalties appear to be consistent with those in existing legislation
Further comment
We consider that the creation and enforcement of legislation addressing the “consumer” end of extreme pornography must be accompanied by continued action to address the problem at the “supplier” end. As has been shown in the case of indecent images of children, until there is both international agreement on the types of material that should be controlled and effective enforcement against those who continue to provide it, material will continue to be available to those who are determined to obtain it. Action against individual consumers can be effective, but can also be costly in time and resources as shown by the very large investigative effort required to deal with the results of Operation Ore and similar investigations. We therefore support the conclusion of paragraphs 55 and 56 that international efforts must continue towards a long-term solution.
JANET(UK) is the not-for-profit company that runs JANET, the UK’s education and research network, connecting universities, colleges and research establishments in the UK to each other and to the public Internet. JANET also provides inter-connection between schools networks in England, Scotland and Wales. JANET(UK) operates the JANET Computer Emergency Response Team (JANET-CERT), which responds to misuse of our own network and those of our customers. Our network is the target of both hacking and denial of service attacks, so we are concerned that UK legislation is able to prosecute such activities effectively. Our customer organisations also find it useful to have a clear statement in law that such activities are illegal so they can discourage students and others from attempting them.
We consider that the Computer Misuse Act 1990, as it has been interpreted by case law, covers most of the types of attack we experience. However one growing area of activity that may not be covered is Denial of Service attacks, where an attacker attempts to either crash or swamp a computer, organisation or network. Twenty-one of these attacks have been reported to us in the past three months; some of these were sufficiently serious to make even a large university’s network completely unusable for many hours. The aim of such an attack is to render a computer or network unable to perform its proper function, not to gain access to either computers or data. Although we are aware of legal arguments that such attacks are covered by the existing Act, these appear to depend on particular features of individual attacks. A clear statement in law that covers all deliberate and unauthorised interference with the proper function of an information system would be very welcome. Although we sympathise with the idea of punishing reckless use of computers and networks, as proposed in section 3A(2) of the Computer Misuse (Amendment) Bill published in 2002, we believe that this would be almost impossible to prosecute, as well as risking criminalising legitimate (if ill-advised) actions.
The Computer Misuse Act 1990 relies heavily on the concept of “unauthorised” actions, and the definition of this term in sections 17(5) and 17(8) of the Act has been criticised. The major problem, that a person’s authority to use a computer may only extend to some types of action and not others, appears to have been settled by case law. If a clearer statement were possible in legislation then this would be useful, however this must not be as restrictive as the use of “owner” in the Computer Misuse (Amendment) Bill.
The definitions of computer, data and program contained in the Act seem to have allowed sufficient judicial interpretation to cover the UK cases that have been reported. However we note that the European Framework Decision COM(2002)173 uses the term “information system”, and this wider term may now be more suitable for current and future technology. For example where a Denial of Service attack achieves its purpose by simply filling a communications link to its capacity, it is not clear that this would constitute an attack on a “computer” although it would be an attack on an “information system”. Changes in terminology are likely to be necessary to make UK legislation comply with this Decision.
The large, and growing, number of attacks on information systems suggests that fear of punishment is not an effective deterrent. We believe that this is more likely to be due to the difficulty of prosecution than the severity of sentence that might result from a conviction. We would therefore expect to see greater benefits from improving the ability of the police to investigate and the courts to judge cases involving computers, networks and digital evidence than from simply increasing sentencing powers. However increasing the maximum sentence for the offence of unauthorised access (s.1 of the Act) would result in new powers becoming available to the police, in particular search and seizure (particularly important where fragile electronic evidence needs to be preserved) and international cooperation (most forms of computer misuse are international in scope), which would make investigation more effective. These side effects argue for increasing the maximum sentence for the unauthorised access offence.
Summary of Principal Recommendations
We believe that the law needs a clear statement that deliberate and unauthorised interference with information systems is unlawful.
We believe that the ability of the police to investigate crimes against computers, and hence the effectiveness of the law as a deterrent, would be improved by the additional powers that would become available if the maximum penalty for the crime of unauthorised access to a computer were to be increased.

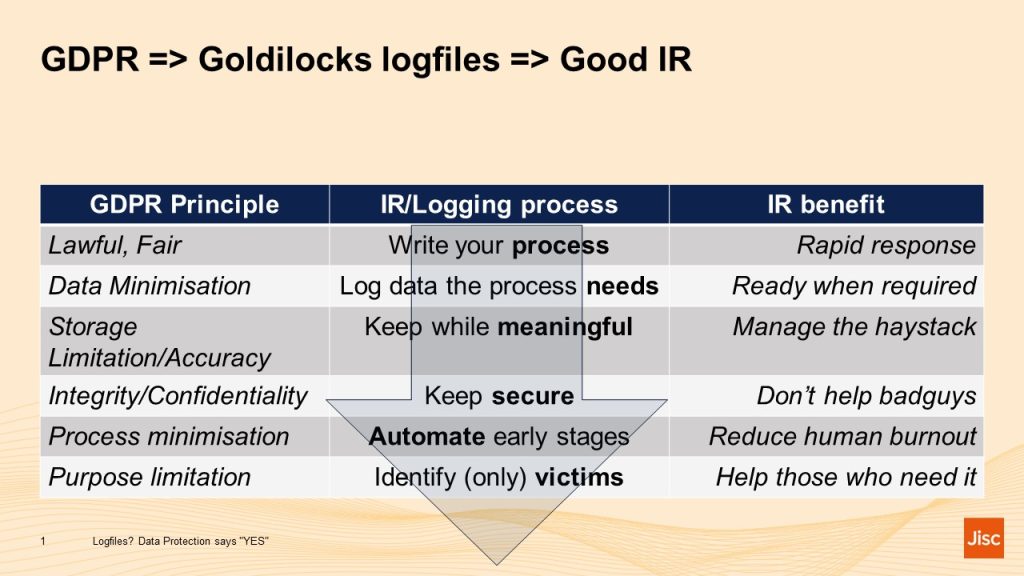




 While colleagues are looking at
While colleagues are looking at

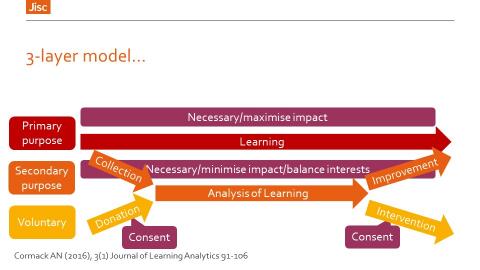
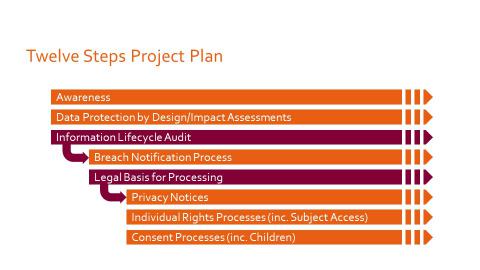
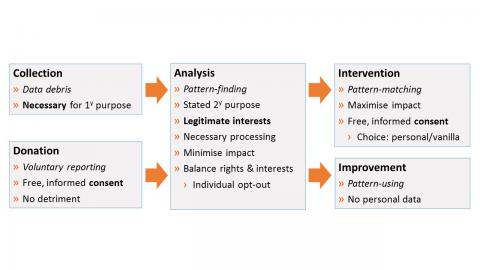


{kind=link}
I’ve now spotted Article 2(2), which may provide the limitation I was looking for:
I think that means that the examples I was thinking of would be outside the breach requirement and liability requirements.